Featured

Data
Updated Jul. 26, 2026
Data Insight
Nov. 6, 2025
Data Insight
Dec. 23, 2025
AI systems can now write code, pass professional exams, and assist with scientific research, and their capabilities are improving remarkably fast. But measuring exactly what AI can and cannot do is genuinely difficult, with benchmarks struggling to keep pace and real-world performance often diverging from test scores. Epoch tracks AI capabilities across tasks and benchmarks, examining how fast progress is happening, how predictable it is, and what it reveals about where the technology is heading.
Expert assessments and cyber benchmarks led us to expect that frontier models were capable of executing this kind of cyberattack
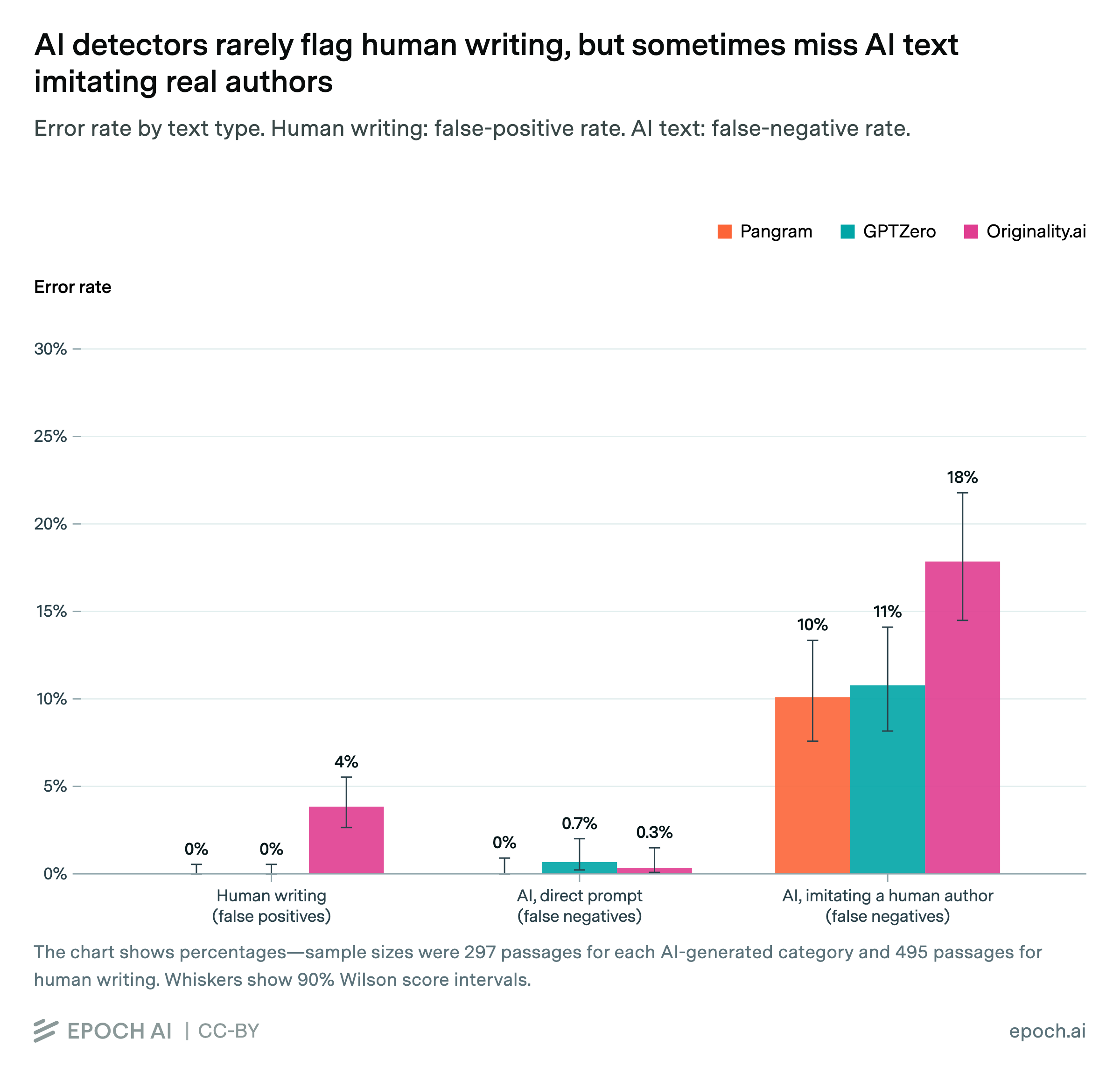


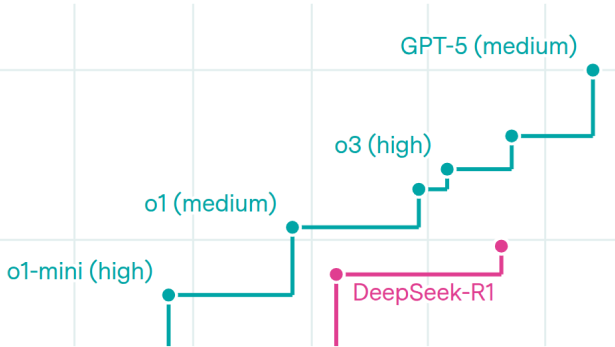
Our latest benchmark suggests AI struggles to learn from experience

MirrorCode is Epoch AI's benchmark for long-horizon coding: AI can reimplement entire programs end-to-end, with no access to the original source code.
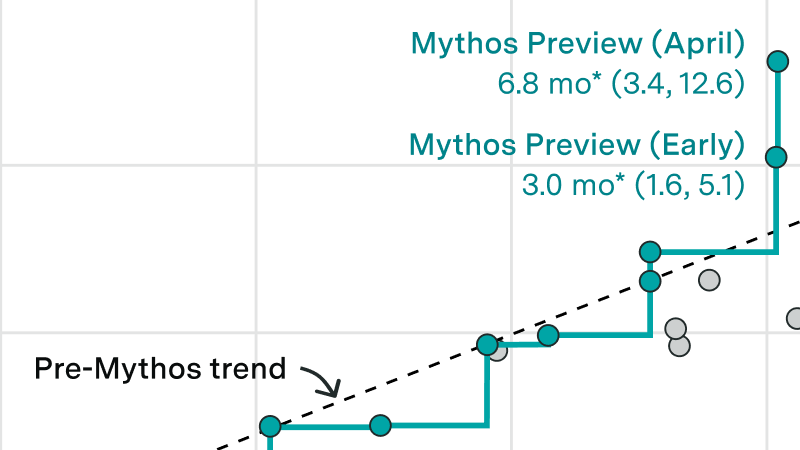
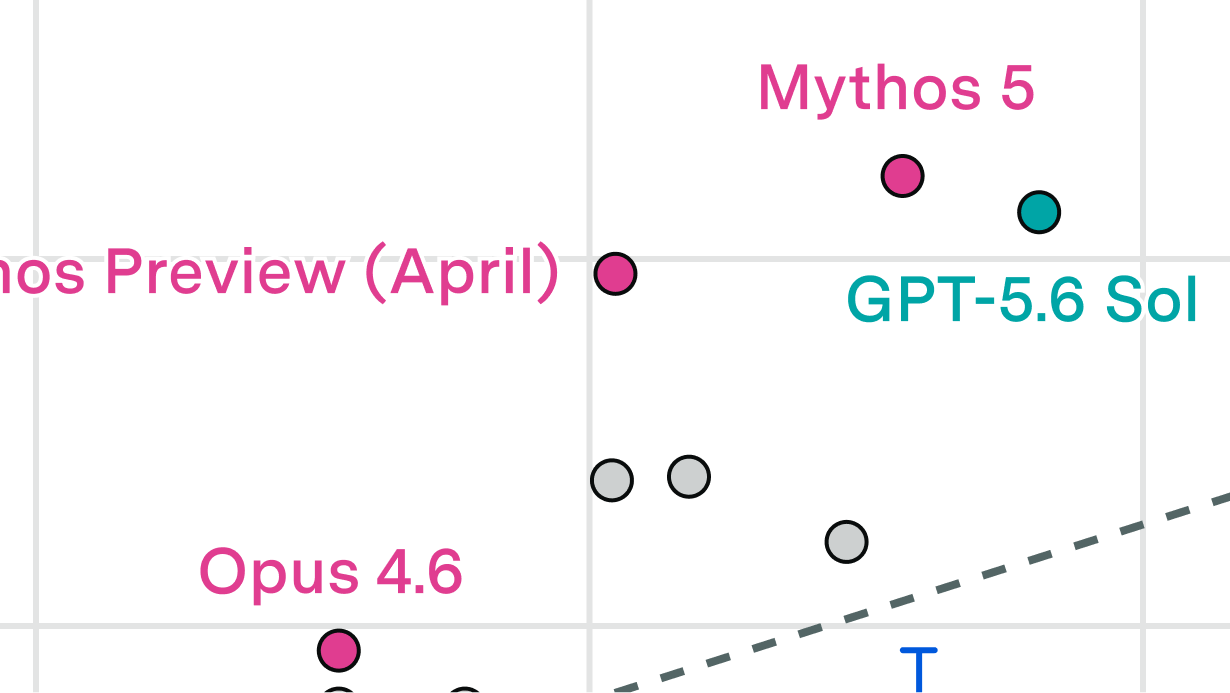
Compiling all the public evidence on Mythos Preview’s cyber abilities
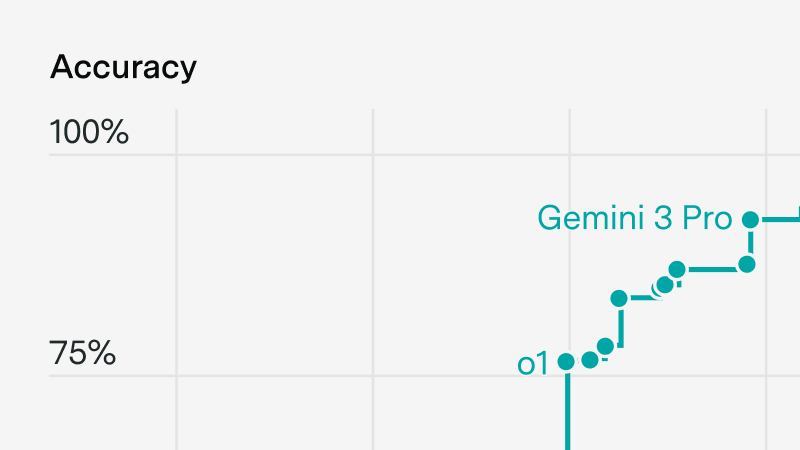
Give up at least one of: text only, short time horizon, easy to grade, and expert human superiority.

In this episode, Greg Burnham and Tom Adamczewski join Anson Ho to push back on benchmark pessimism and dig into what the next generation of AI benchmarks could look like.
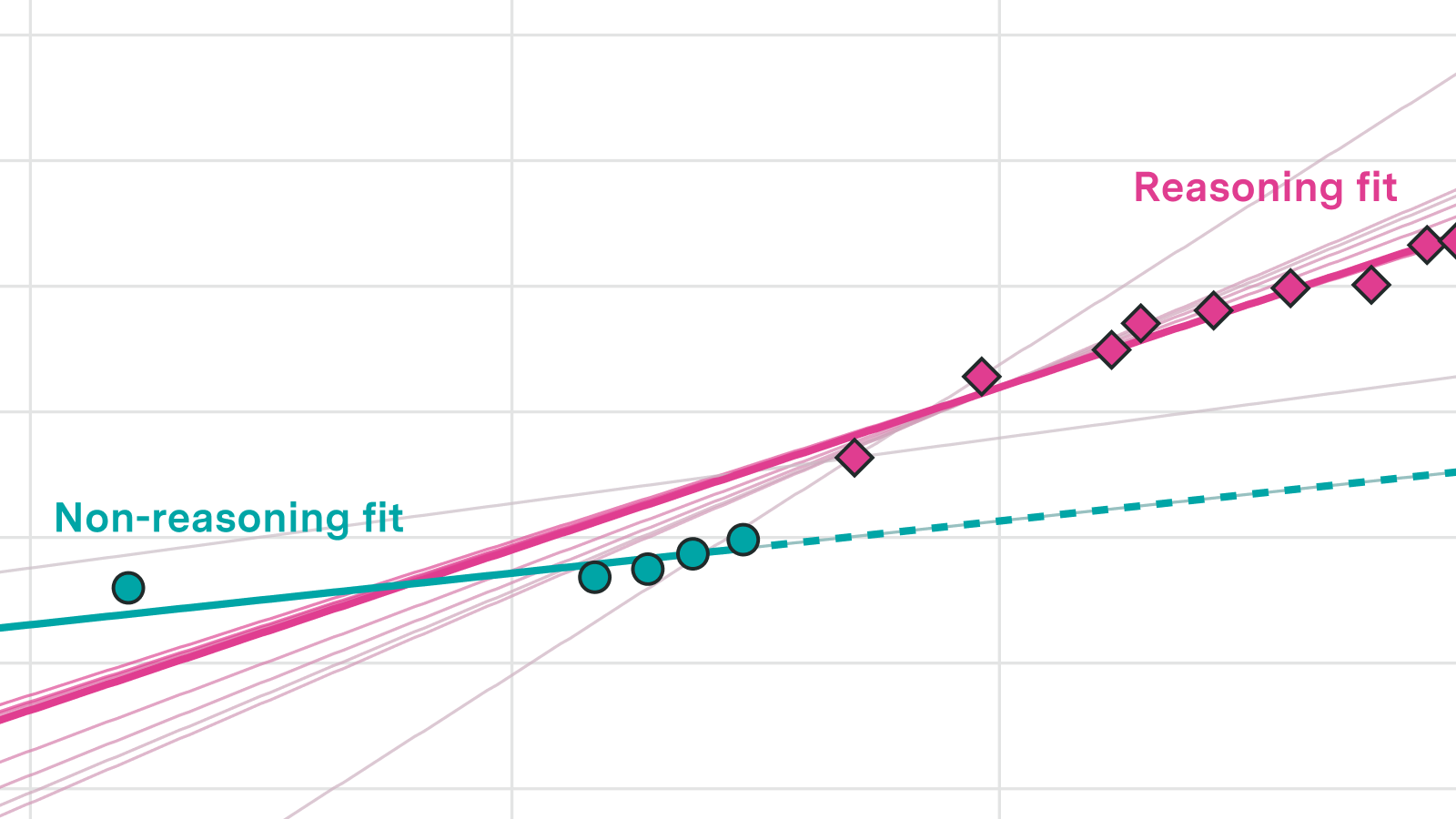
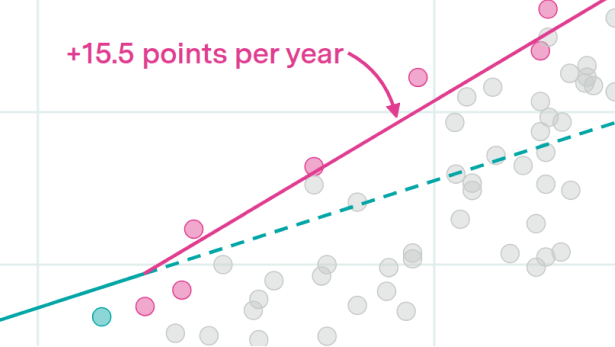
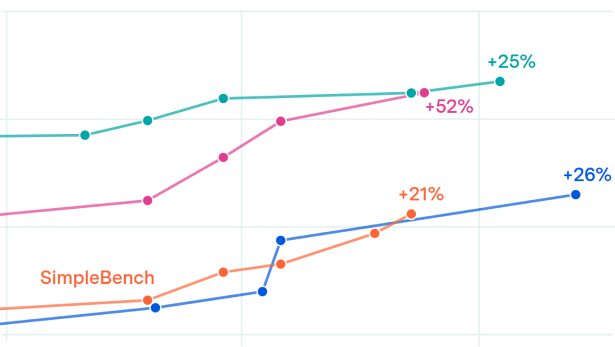
We investigate progress trends on four capability metrics to determine whether AI capabilities have recently accelerated. Three of four metrics show strong evidence of acceleration, driven by reasoning models.
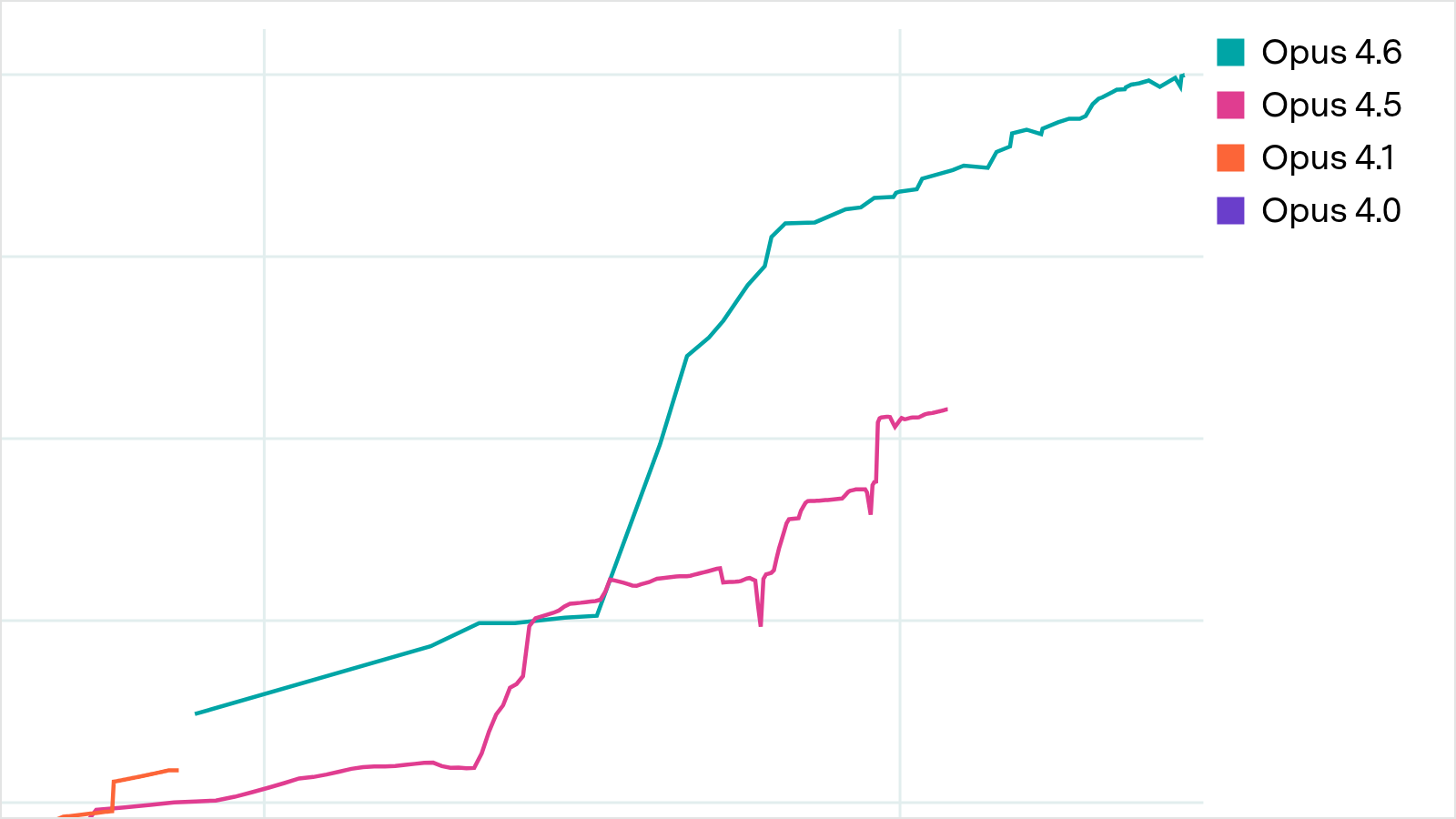
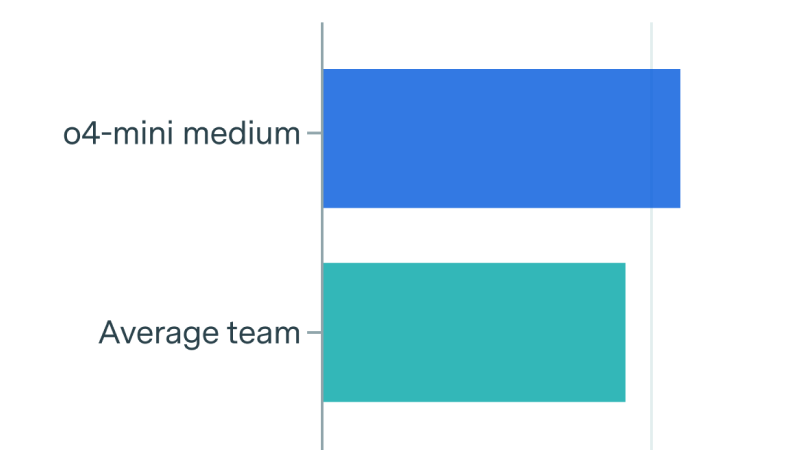
In our new benchmark, MirrorCode, Claude Opus 4.6 autonomously reimplemented a 16,000-line bioinformatics toolkit — a task we believe would take a human engineer weeks.
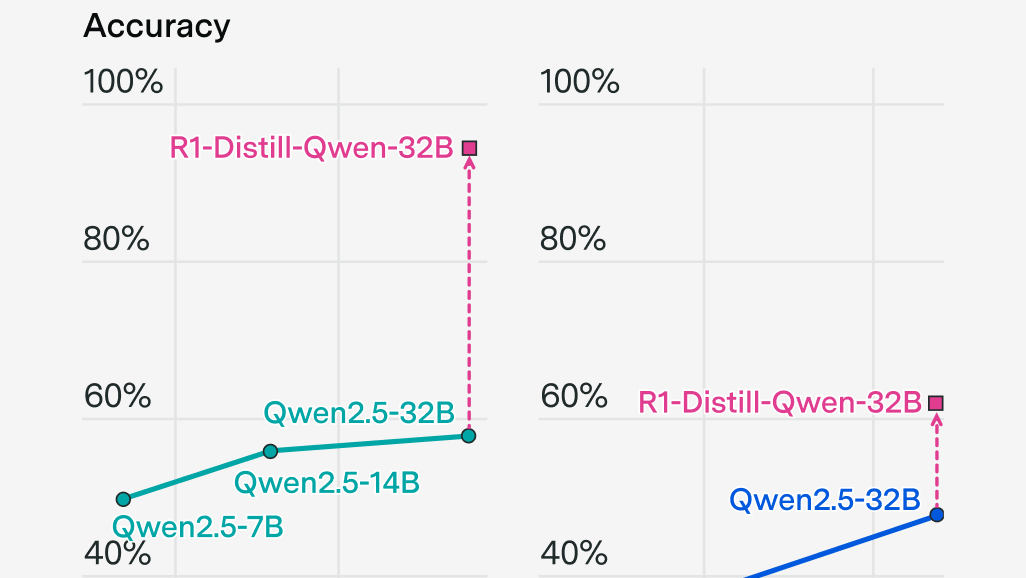
Can Chinese and open model companies compete with the frontier through e.g. distillation and talent?
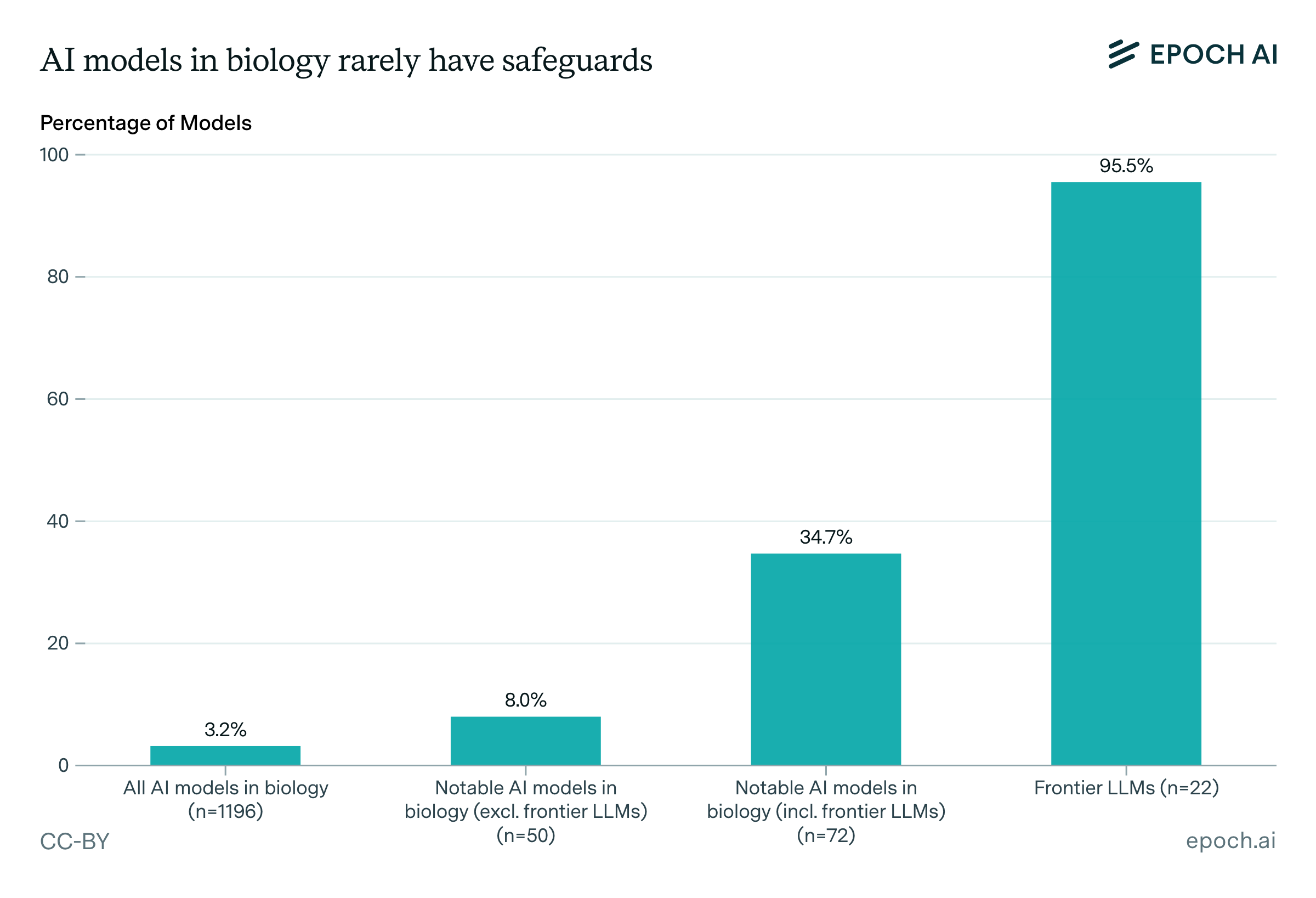
We release a database of over 1,100 biological AI models across nine categories. We analyze their safeguards, accessibility, training data sources, and the foundation models they build on.
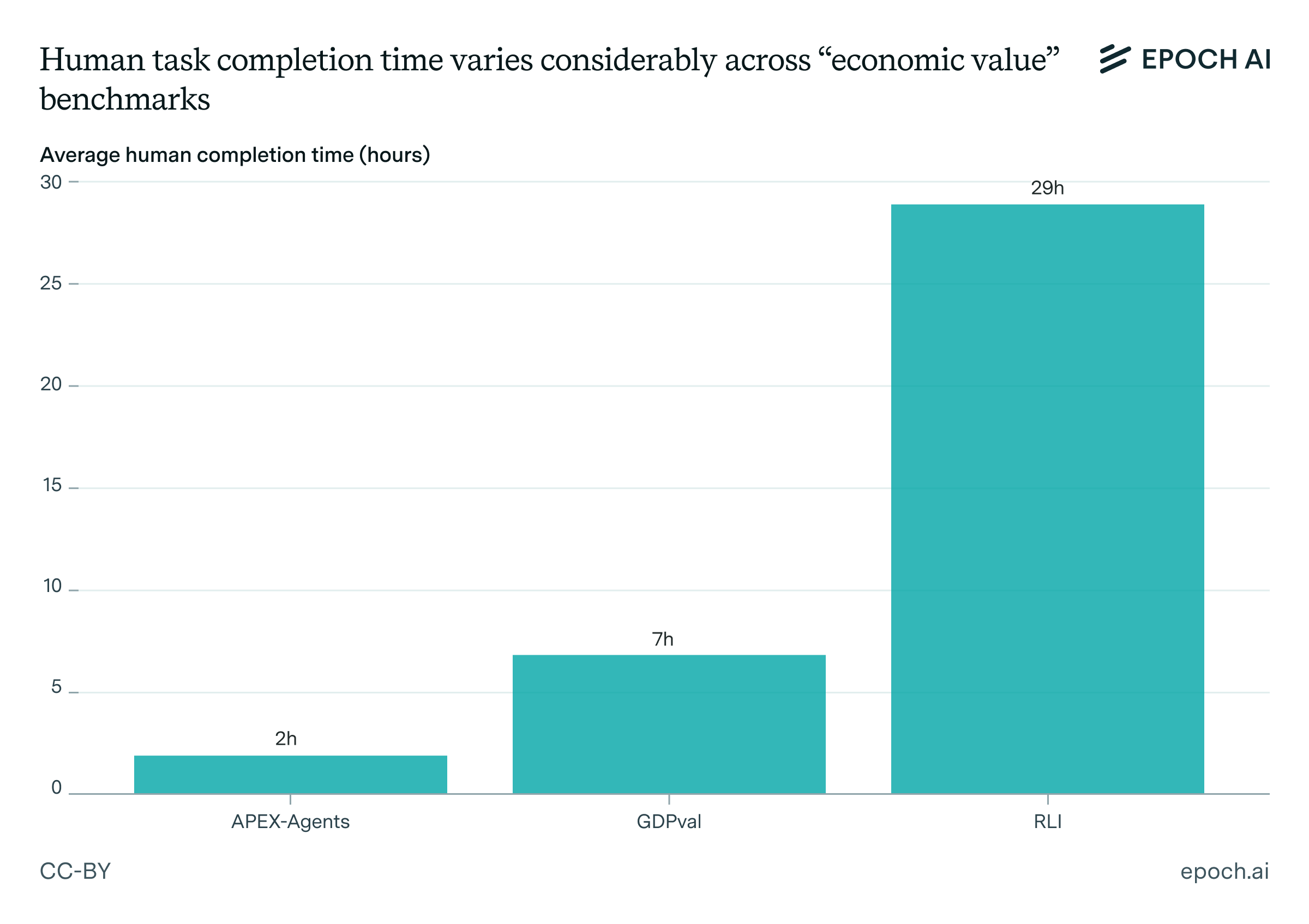
These benchmarks track a wide range of digital work. Progress will correlate with economic utility, but tasks are too self-contained to indicate full automation.

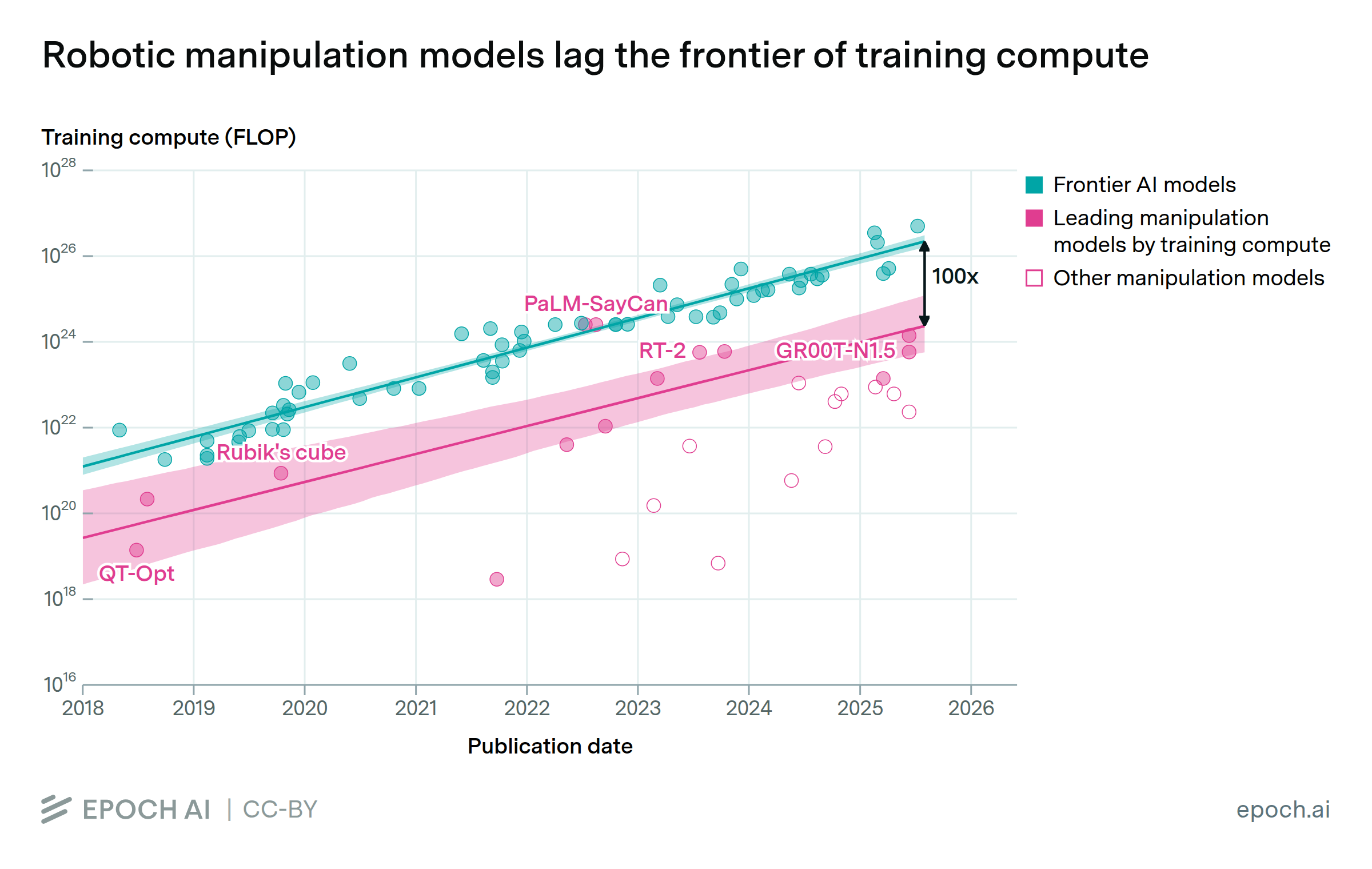
We assess the current state of autonomous robotics by evaluating robot performance on concrete tasks across industrial, household, and navigation domains.
Beyond benchmarks as leading indicators for task automation

In this episode, Daniel Litt chats with the hosts about AI’s limits in mathematics, accelerating math research, and how to measure progress on open problems.
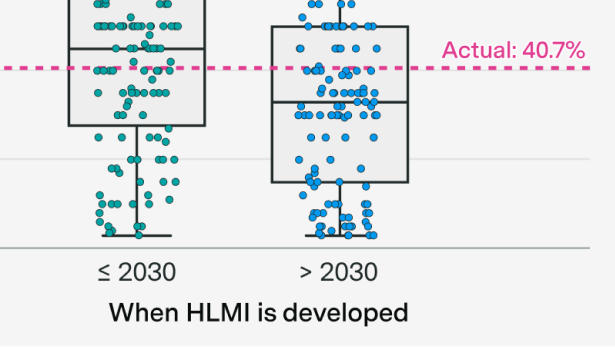
Mostly right about benchmarks, mixed results on real-world impacts

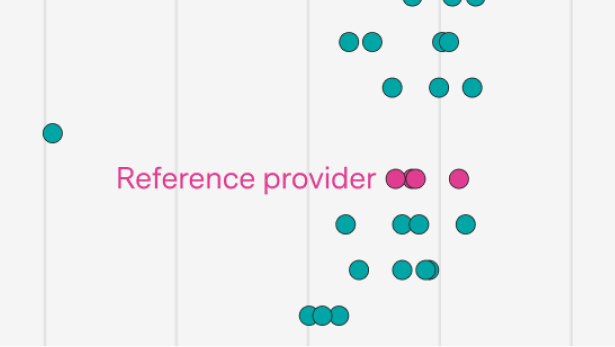
Running benchmarks involves many moving parts, each of which can influence the final score. The two most impactful components are scaffolds and API providers.

Most benchmarks saturate too quickly to study long-run AI trends. We solve this using a statistical framework that stitches benchmarks together, with big implications for algorithmic progress and AI forecasting.
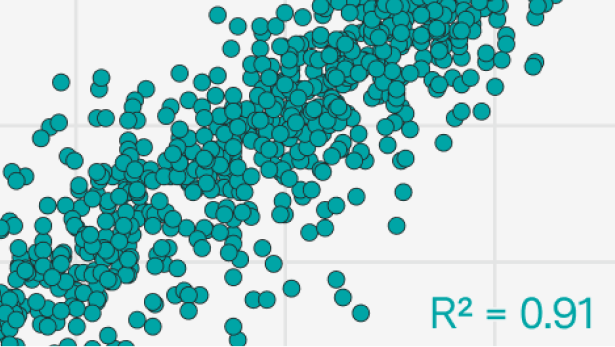
Is this because skills generalize very well, or because developers are pushing on all benchmarks at once?
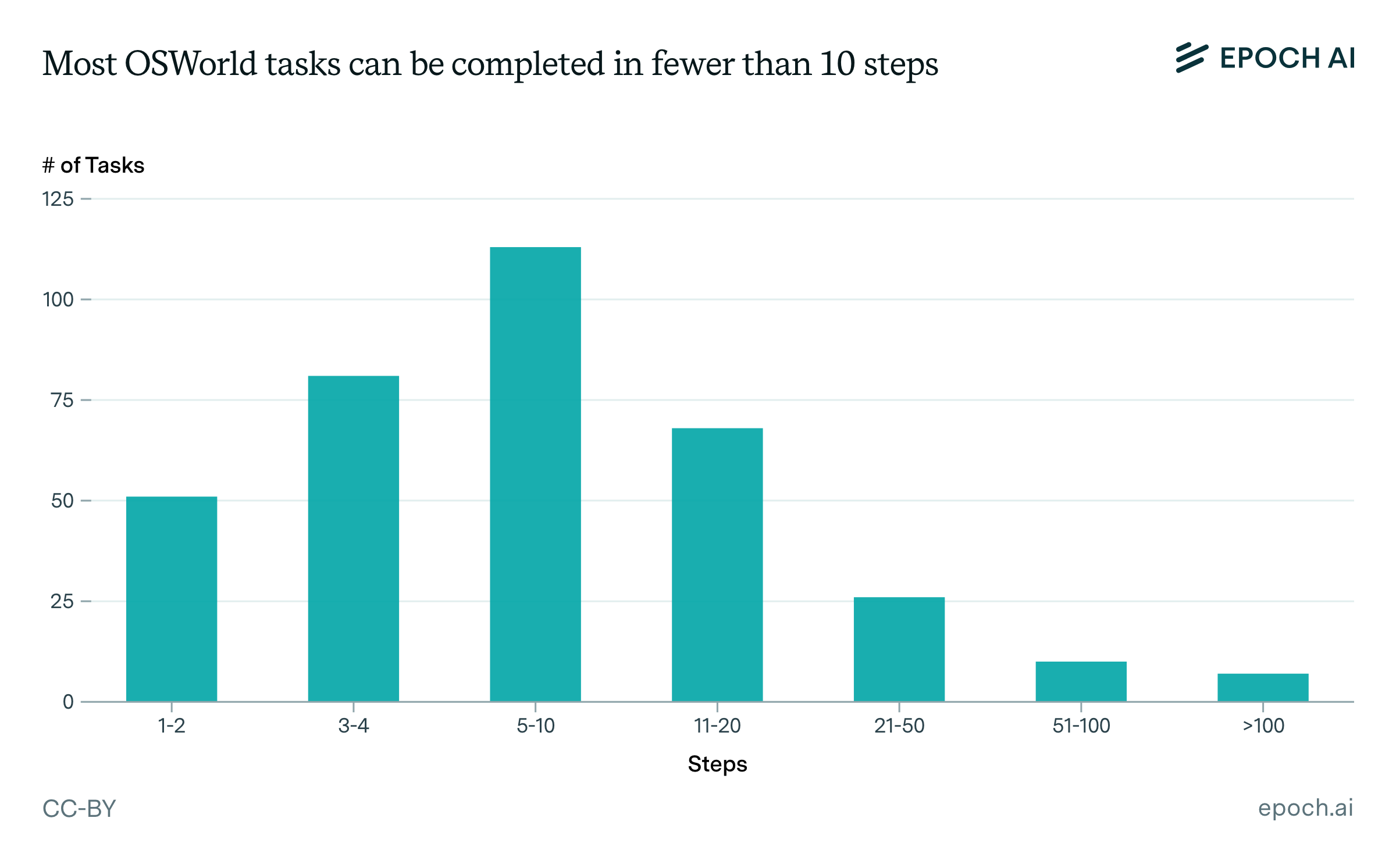
We review OSWorld, a prominent computer use benchmark. Its tasks are relatively simple, many don’t require GUIs, and success often hinges on interpreting ambiguous instructions. It is also not stable over time.
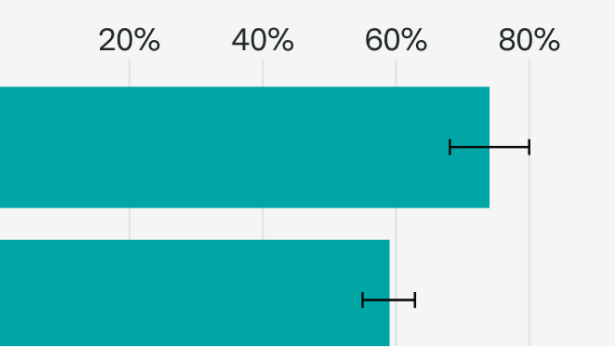
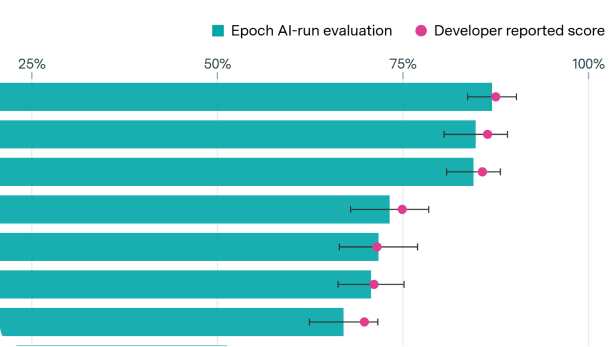
57% of problems have been solved at least once.
It has improved at using background knowledge and doing precise computations. It can be a helpful research assistant and may take a more conceptual approach to geometry. It shows limited creativity and sometimes struggles with citations.
Continual learning, scaling RL, and research feedback loops

If scaling persists to 2030, AI investments will reach hundreds of billions of dollars and require gigawatts of power. Benchmarks suggest AI could improve productivity in valuable areas such as scientific R&D.
Many multi-agent setups are based on fancy prompts, but this is unlikely to persist
The problems gave AI only a slim chance to show new capabilities
Reasoning models were as big of an improvement as the Transformer, at least on some benchmarks
It’s good at involved computations, improving at proofs from a low base, and useful for literature search. It still favors low-level grinds and leans on background knowledge.
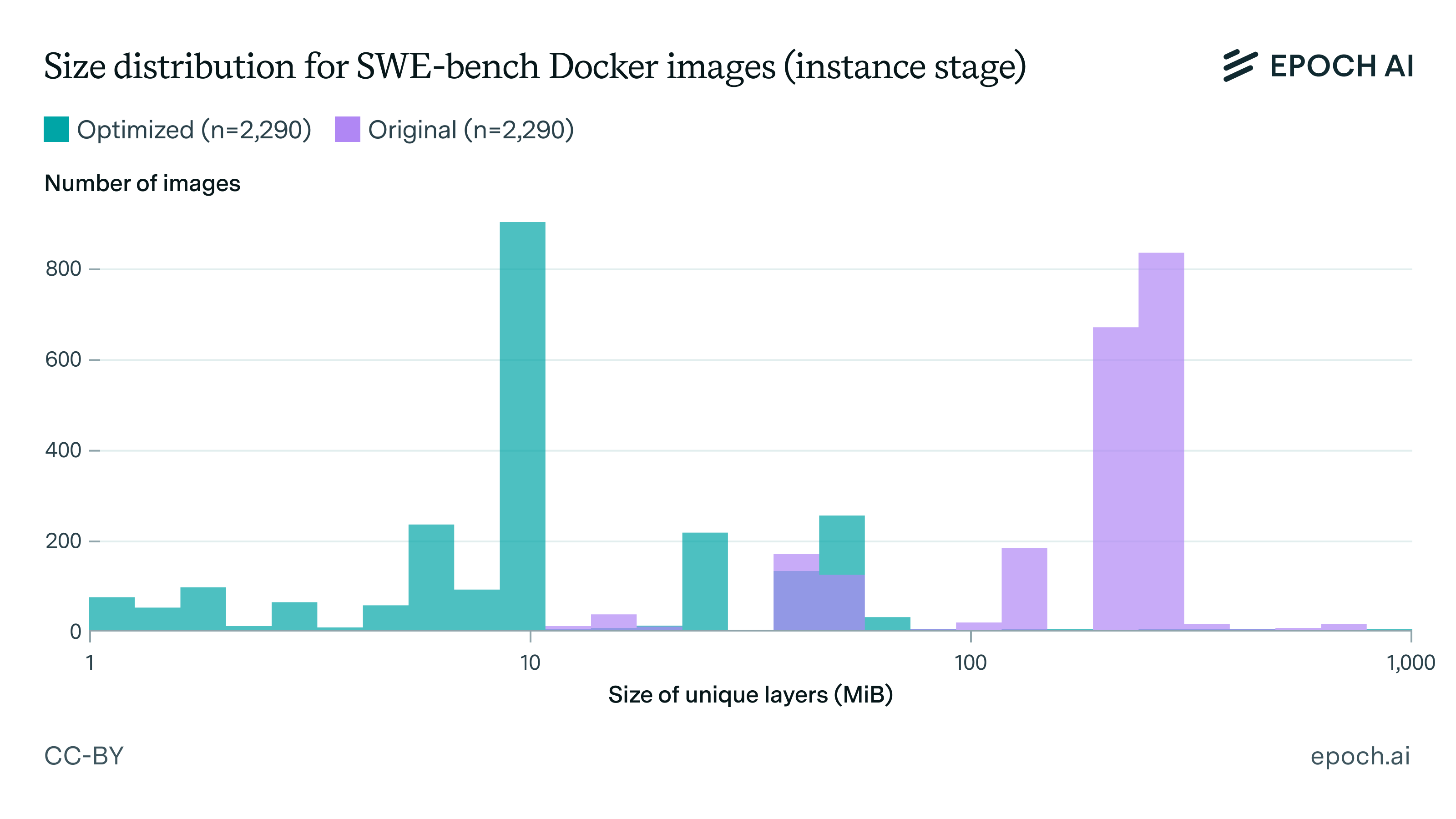
We are releasing a public registry of optimized Docker images for SWE-bench. This allows us to run SWE-bench Verified in 62 minutes on a single GitHub actions VM.
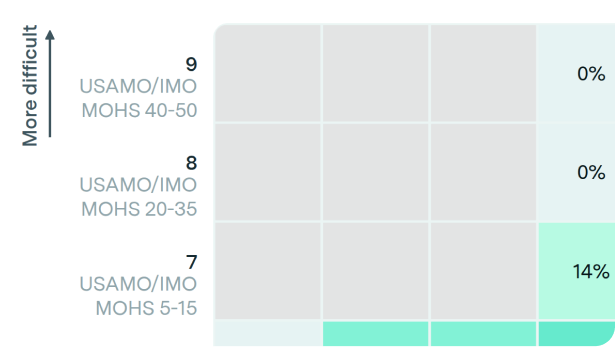
Most discussion about AI and the IMO focuses on gold medals, but that's not the thing to pay most attention to.

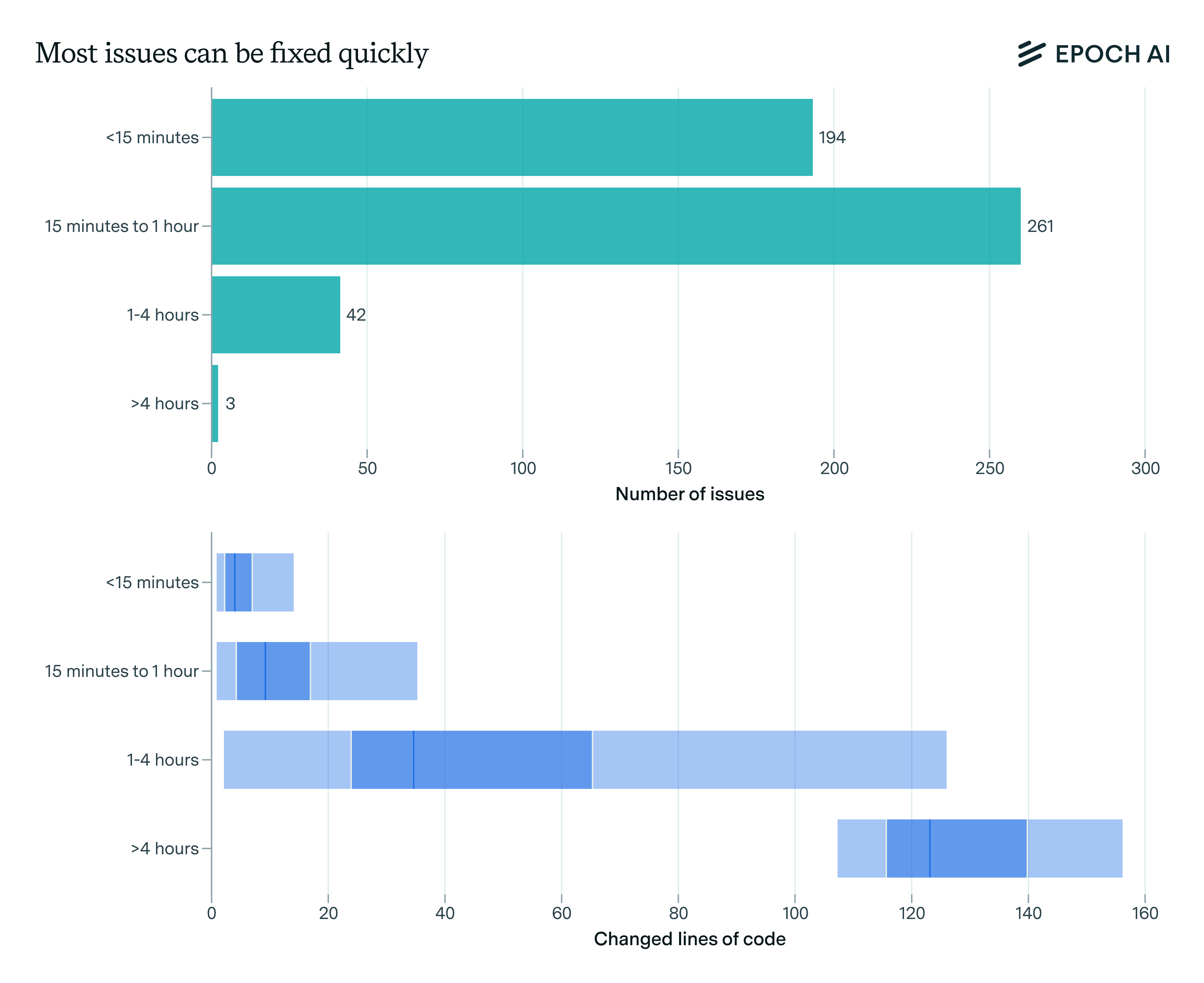
We take a deep dive into SWE-bench Verified, a prominent agentic coding benchmark. While one of the best public tests of AI coding agents, it is limited by its focus on simple bug fixes in familiar open-source repositories.
Assessing if AI labs' biorisk evaluations effectively measure models' potential to enable amateur bioweapons development.
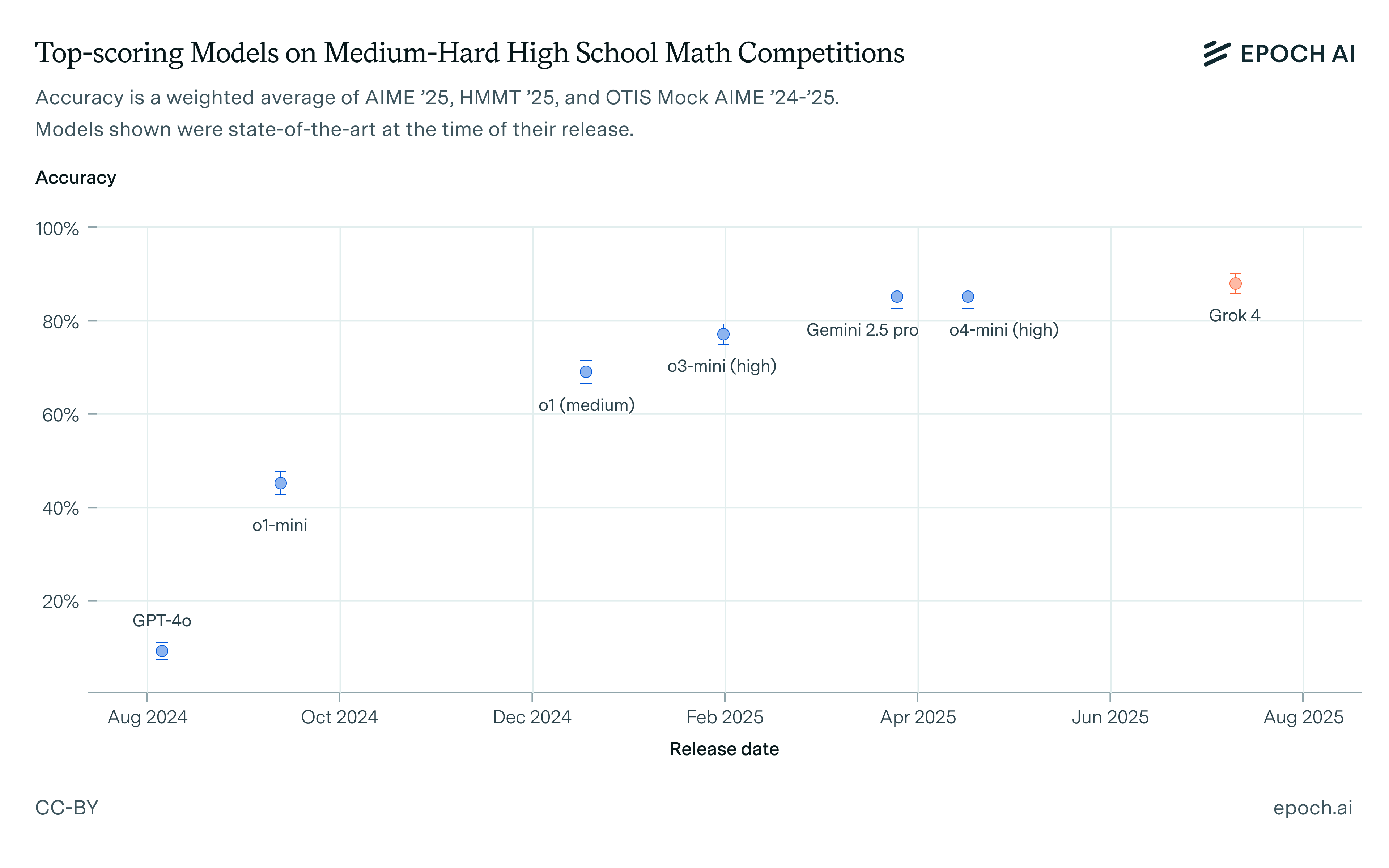
Examining o3-mini's math reasoning: an erudite, vibes-based solver that excels in knowledge but lacks precision, creativity, and formal human rigor.
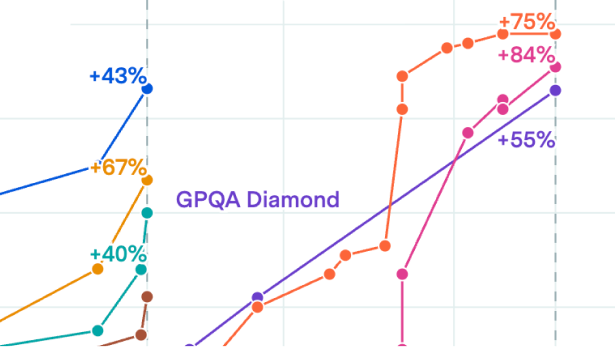
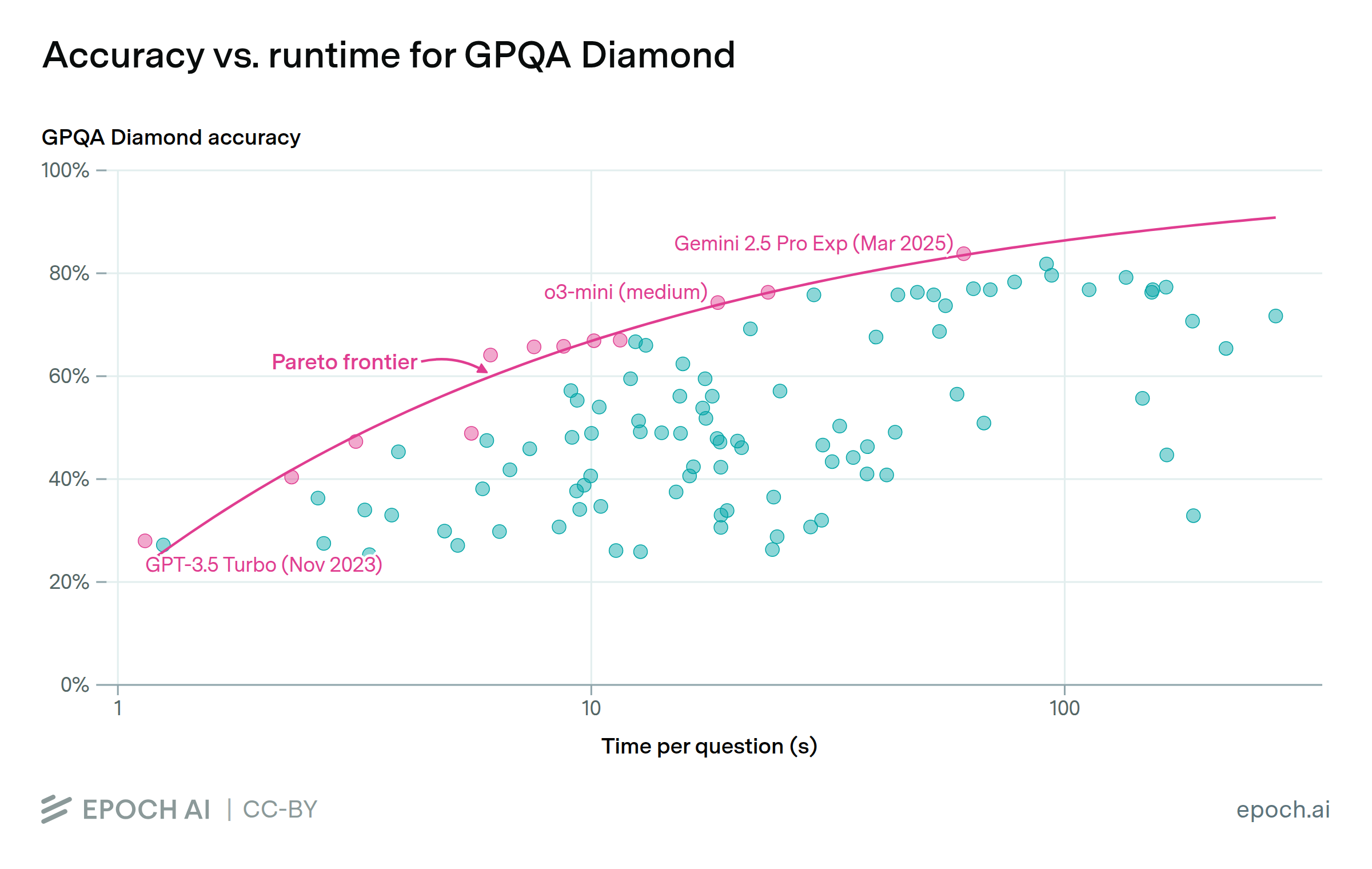
Investigate GPQA Diamond benchmark's validity: uncover flawed questions, model challenges, and why it still informs AI evaluation.
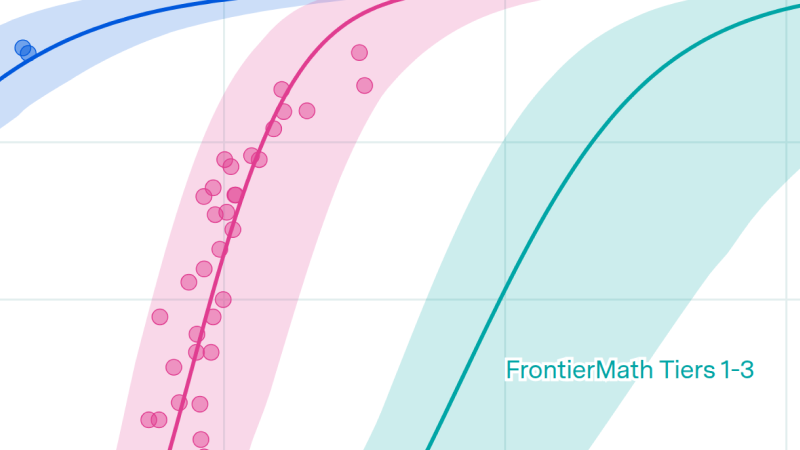
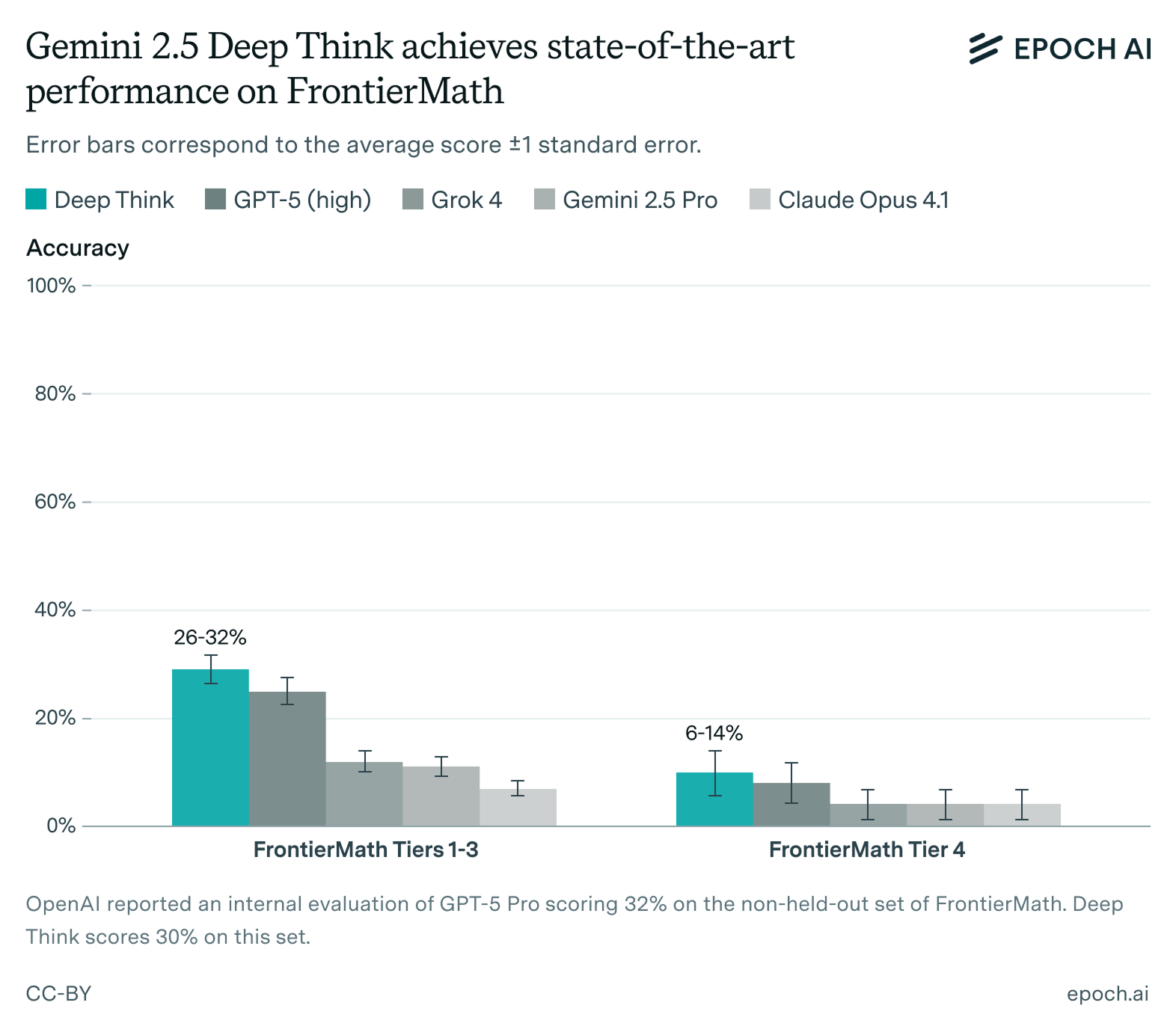
How do humans and AIs compare on FrontierMath? We ran a competition at MIT to put this to the test.
Why don't AIs automate more real-world tasks if they can handle 1-hour ones? Anson Ho explores key capability and context bottlenecks.
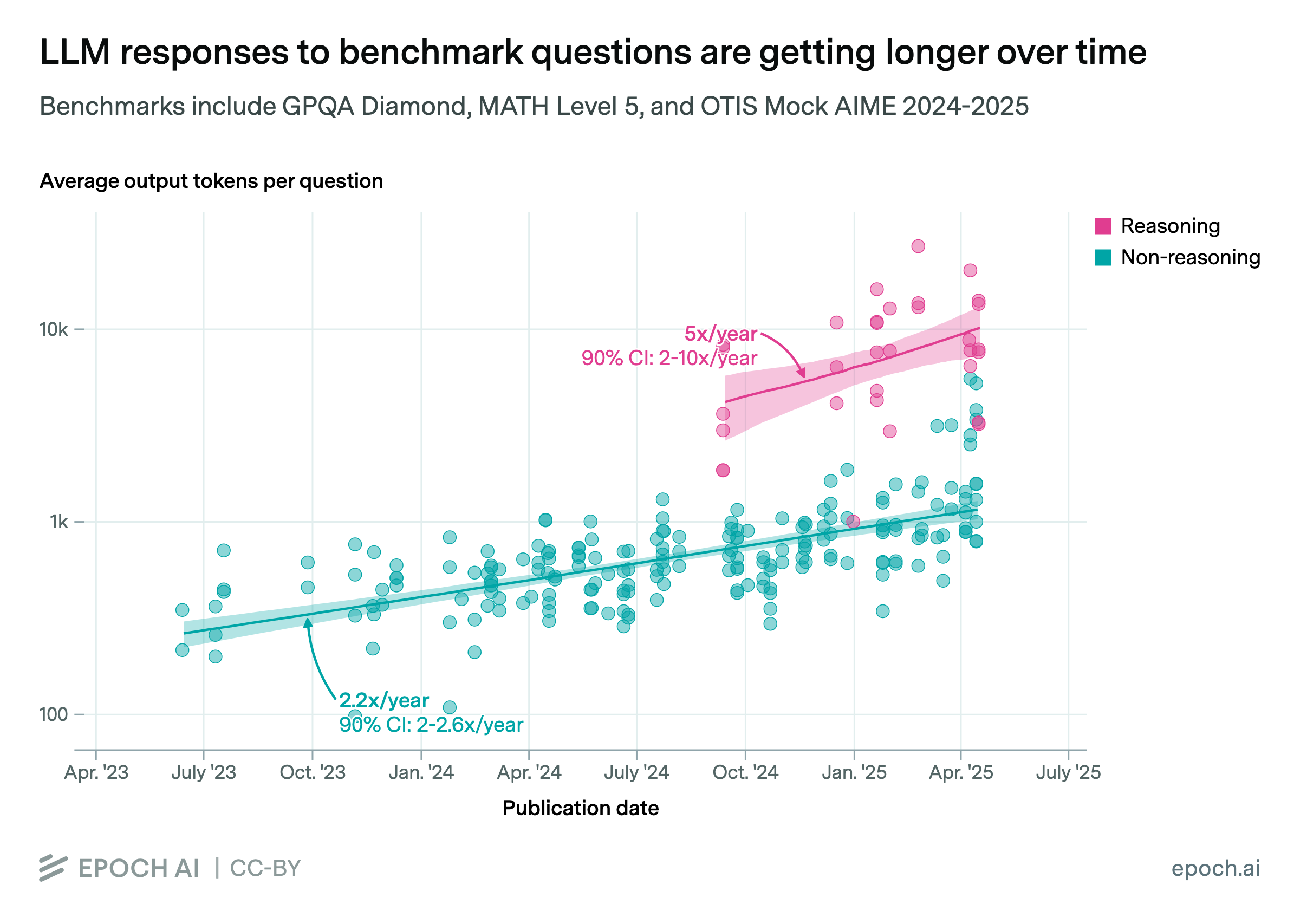
The real reason that AI benchmarks haven’t reflected real-world impacts historically is that they weren’t optimized for this, not because of fundamental limitations – but this might be changing.
Forecasting AI progress requires more than extrapolating current capabilities; understanding fundamental task difficulty is key to predicting future breakthroughs.
AI reasoning models will achieve superhuman performance in math and coding, yet their economic applications will lag behind, limiting real-world impact.
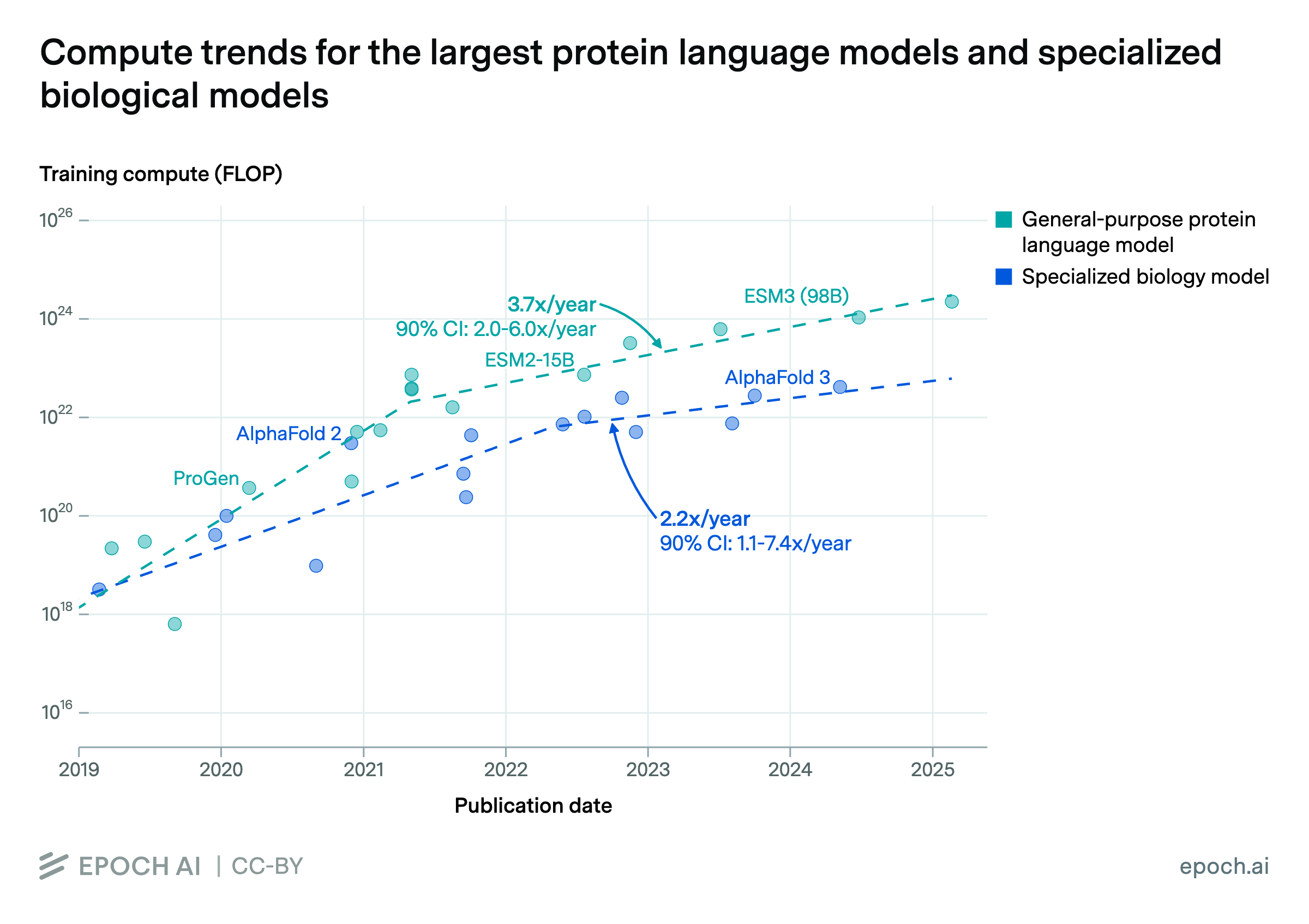
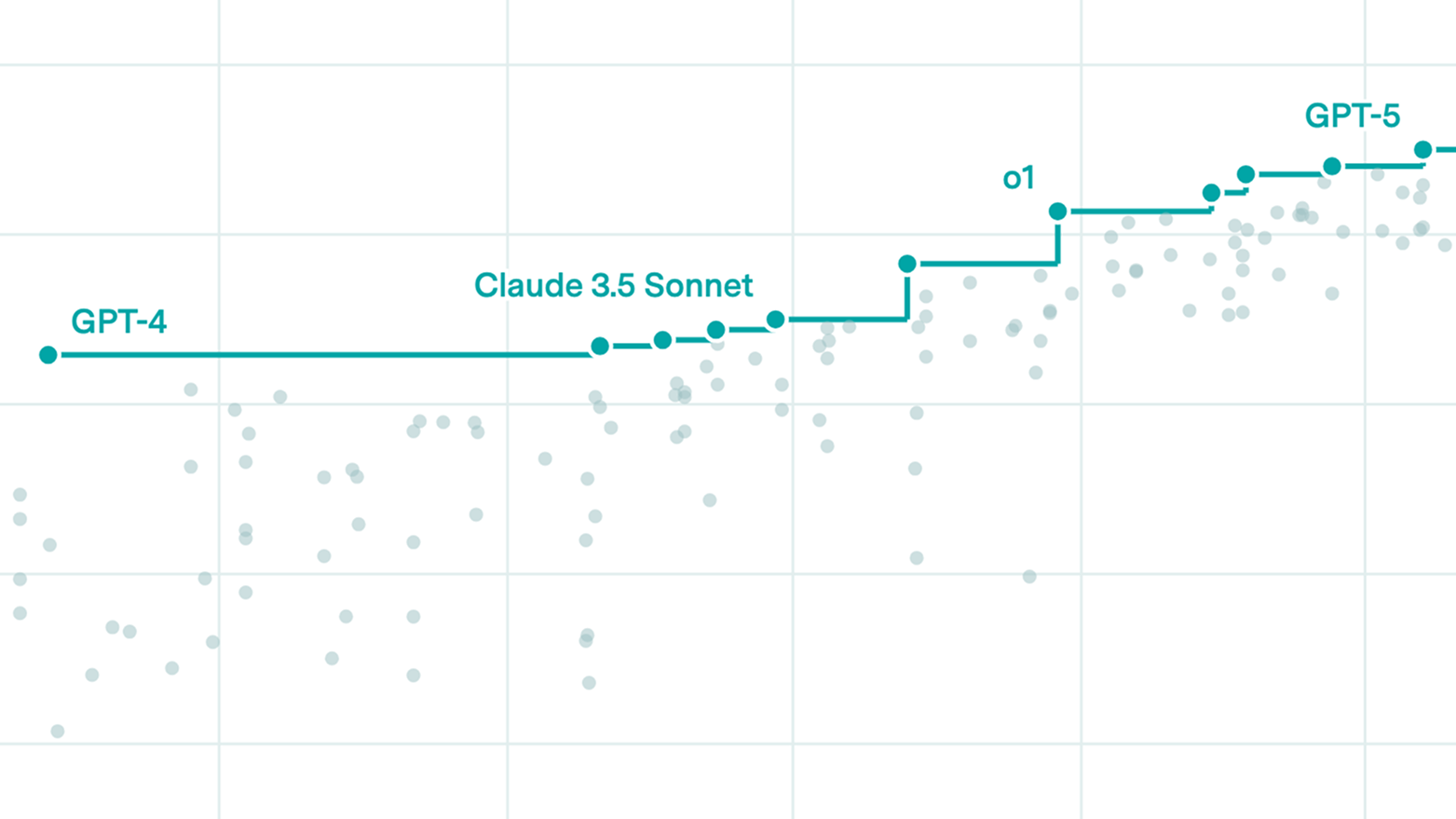
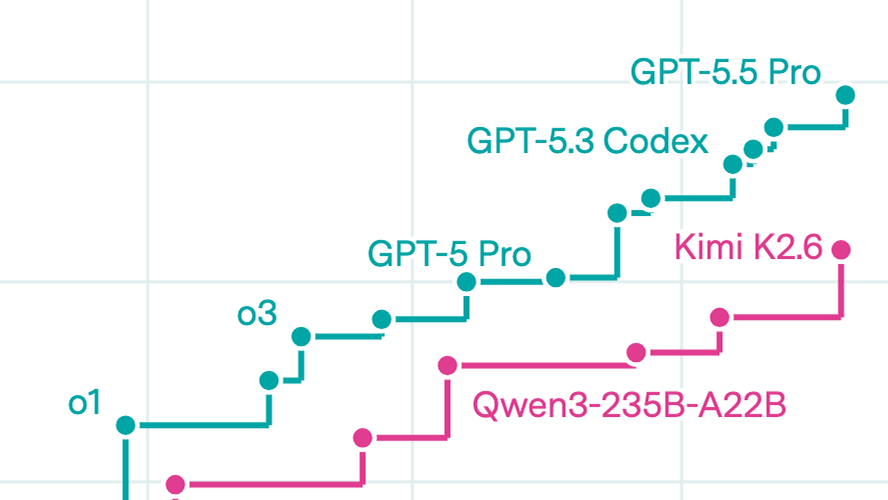
AI progress is accelerating, with next-gen models surpassing GPT-4 in compute power, driving major leaps in reasoning, coding, and math capabilities.
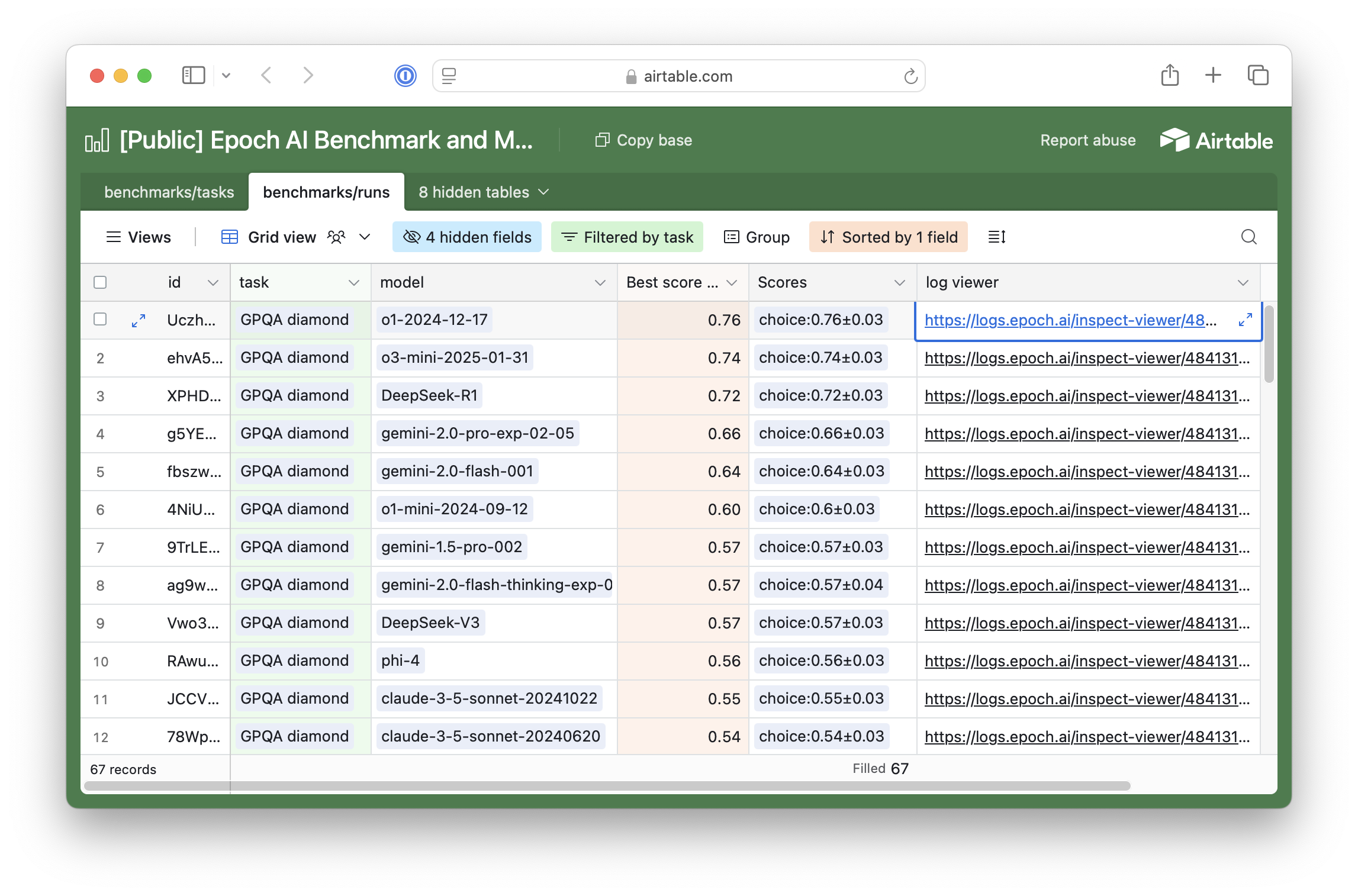
We've overhauled our AI benchmarking infrastructure to provide more transparent, systematic, and up-to-date evaluations of AI model capabilities.
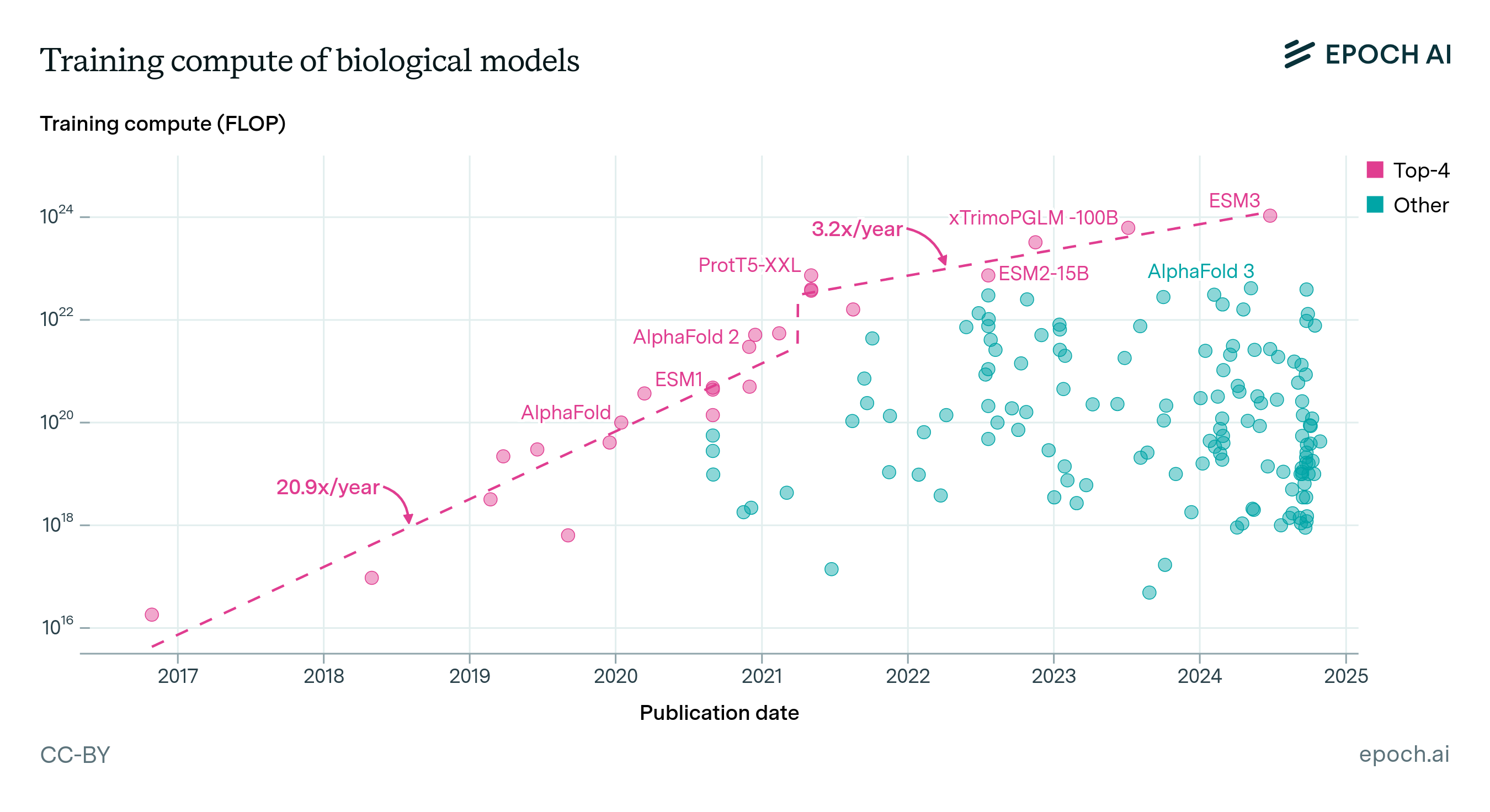
We've expanded our Biology AI Dataset, now covering 360+ models. Our analysis reveals rapid scaling from 2017-2021, followed by a notable slowdown in biological model development.

We clarify that OpenAI commissioned Epoch AI to produce 300 math questions for the FrontierMath benchmark. They own these and have access to the statements and solutions, except for a 50-question holdout set.

We are hosting a competition to establish rigorous human performance baselines for FrontierMath. With a prize pool of $10,000, your participation will contribute directly to measuring AI progress in solving challenging mathematical problems.
This Gradient Updates issue explains Moravec's paradox and offers a speculative picture of how hard various economic tasks are to automate based on the paradox.

How will AI transform mathematics? Fields Medalists and other leading mathematicians discuss whether they expect AI to automate advanced math research.
We are launching the AI Benchmarking Hub: a platform presenting our evaluations of leading models on challenging benchmarks, with analysis of trends in AI capabilities.
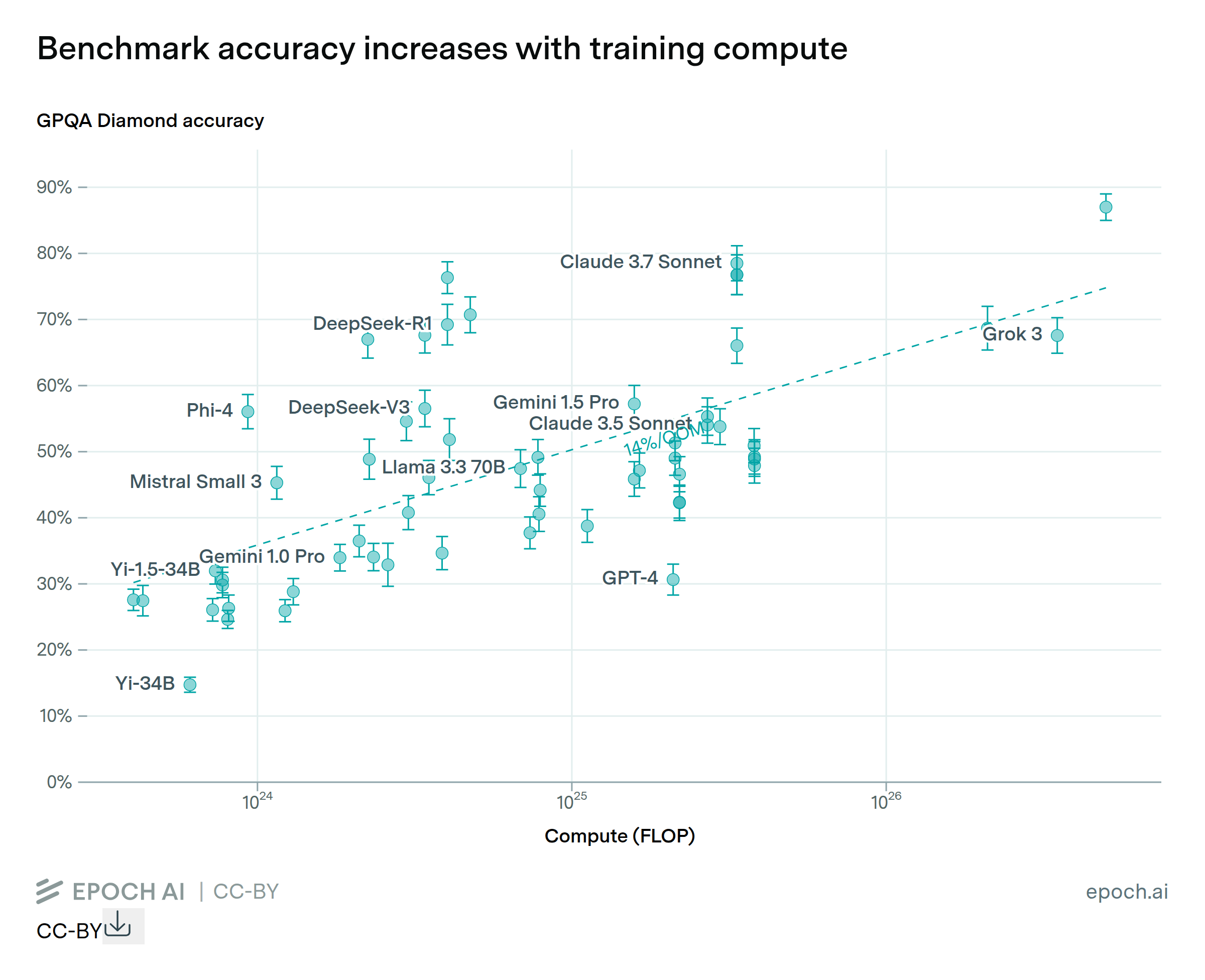

FrontierMath: a new benchmark of expert-level math problems designed to measure AI's mathematical abilities. See how leading AI models perform against the collective mathematics community.
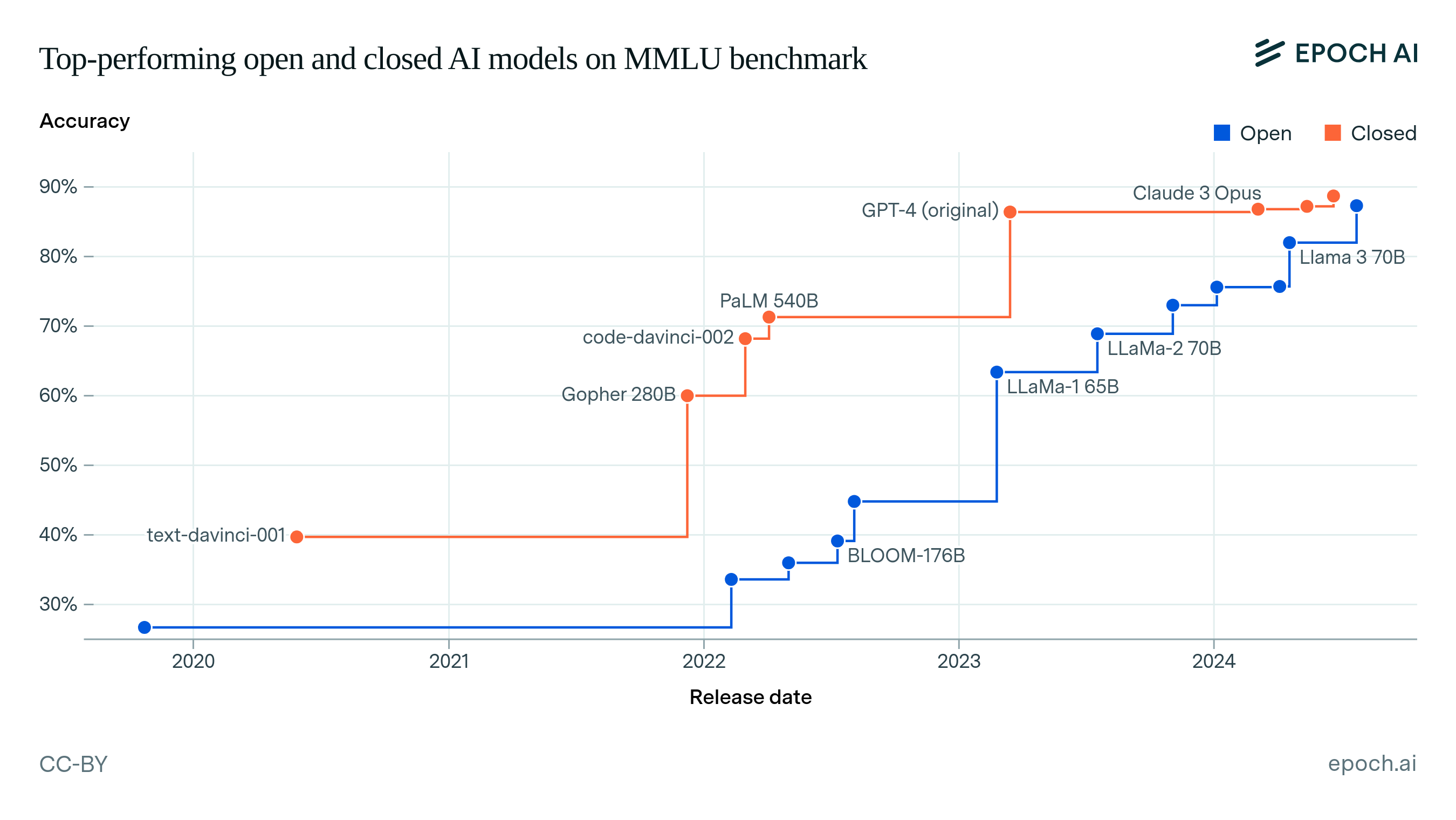
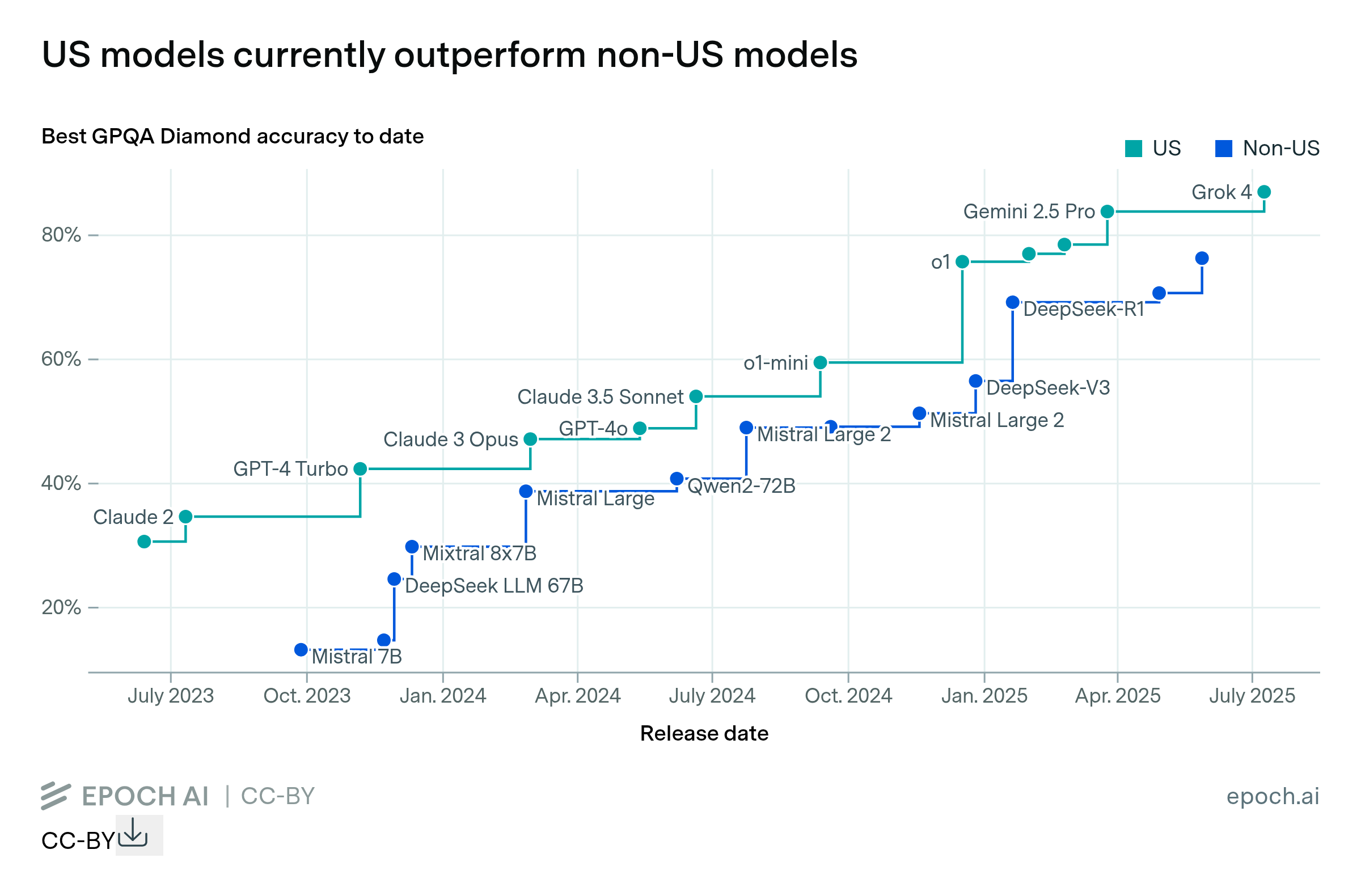
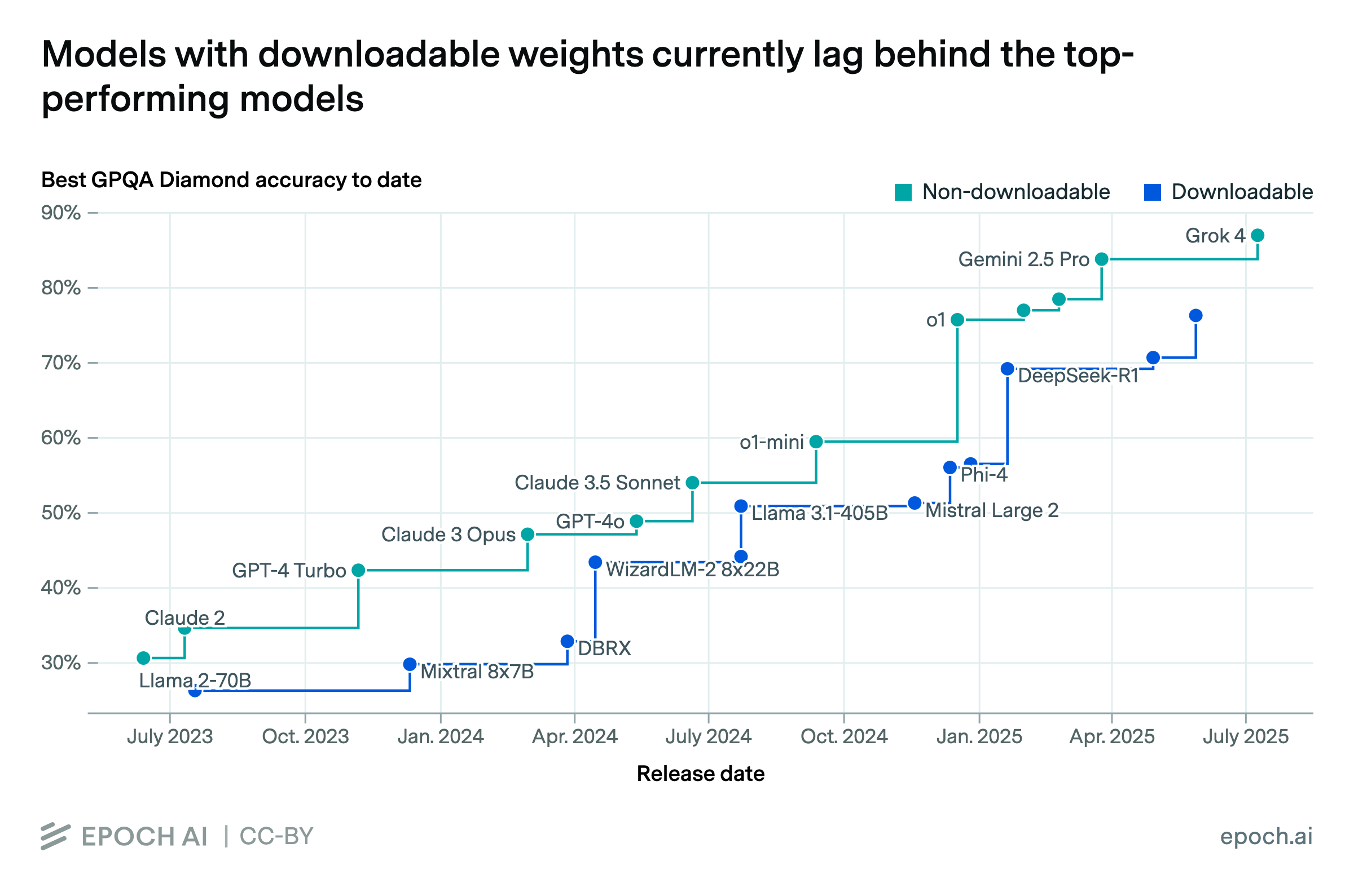
We compare open and closed AI models, and study how openness has evolved. The best open model today is on par with closed models in performance and training compute, but with a lag of about one year.
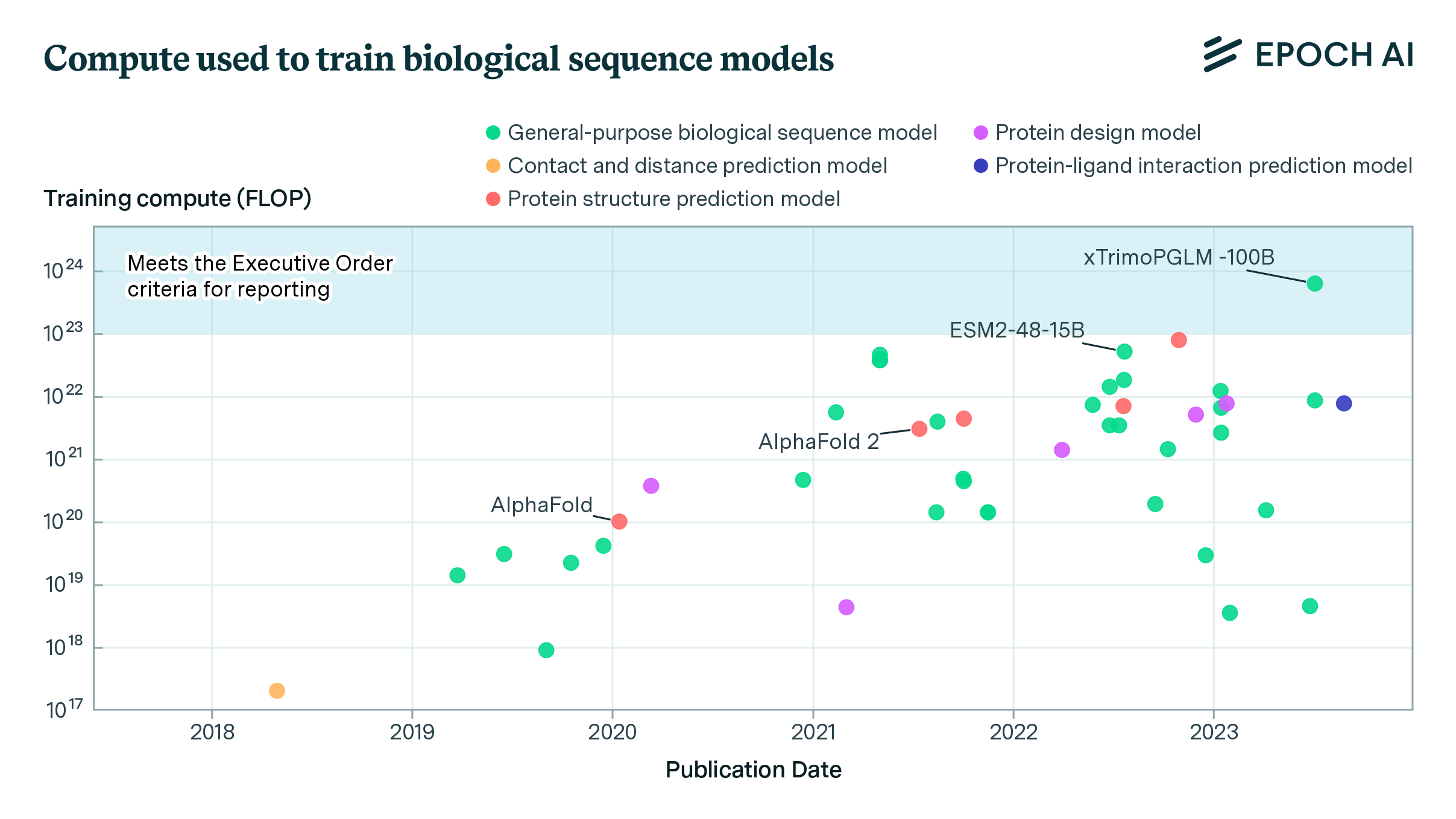
The expanded Epoch database now includes biological sequence models, revealing potential regulatory gaps in the White House’s Executive Order on AI and the growth of the compute used in their training.
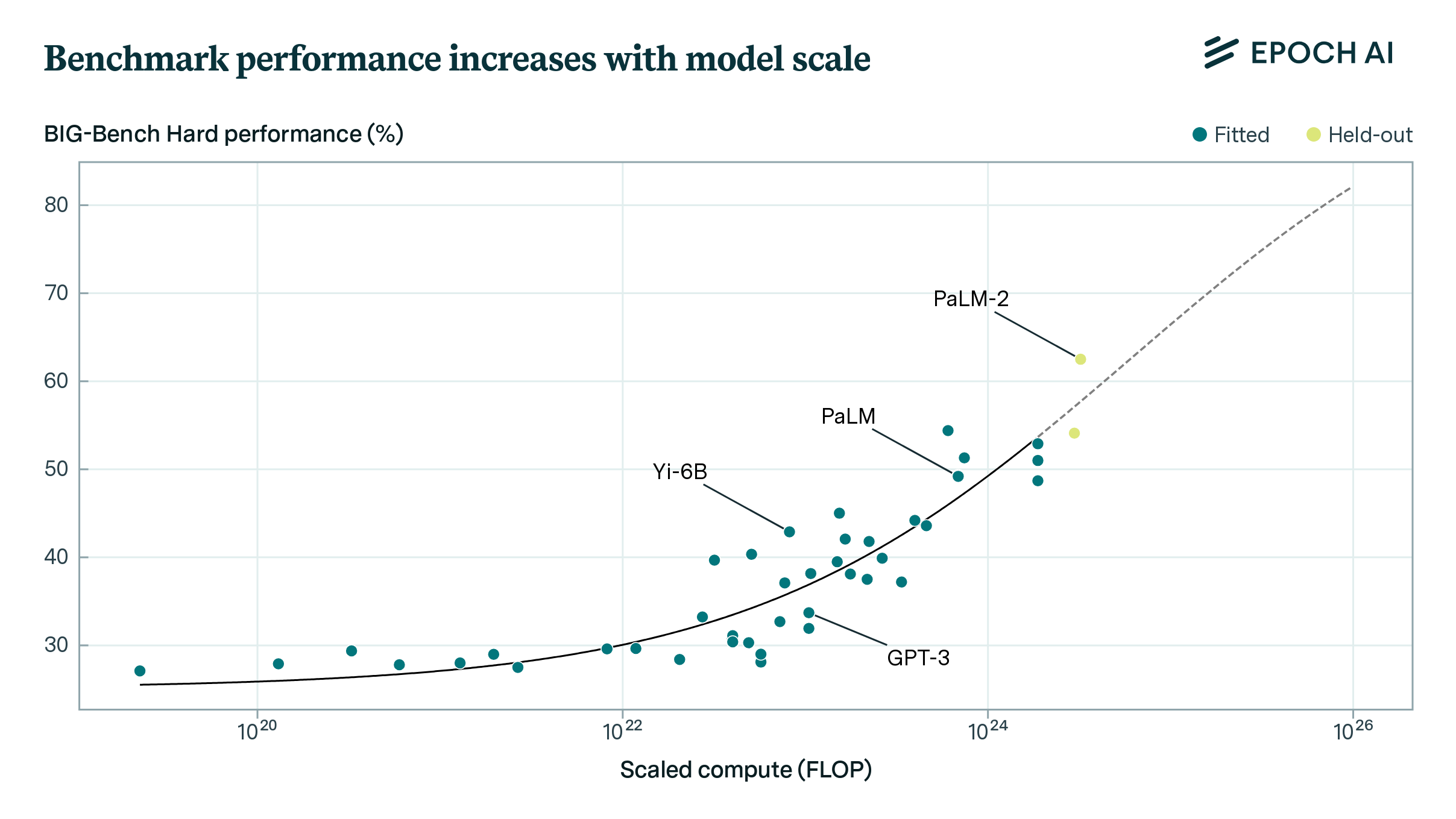
We investigate large language model performance across five orders of magnitude of compute scaling, finding that compute-focused extrapolations are a promising way to forecast AI capabilities.
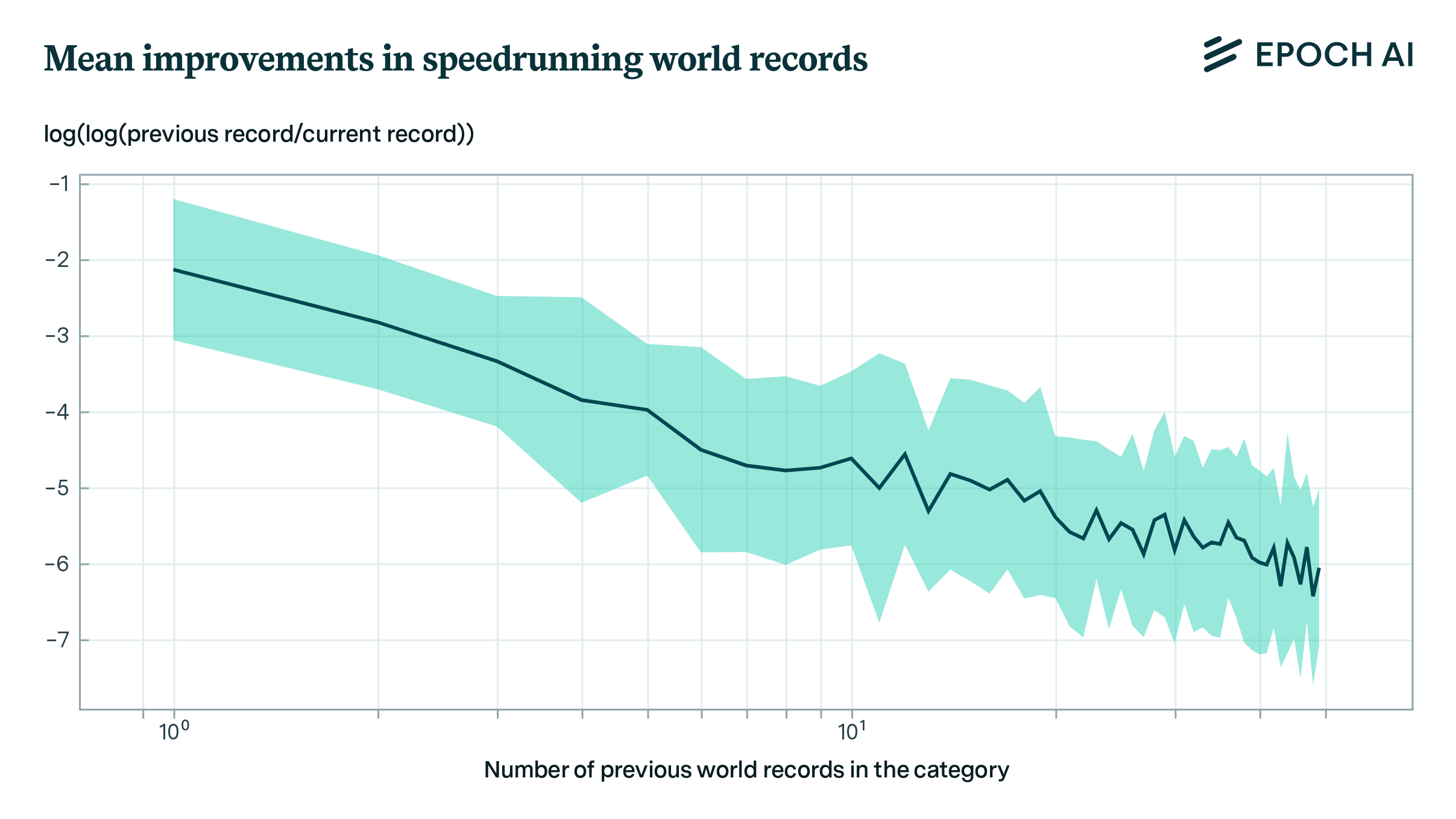
We develop a model for predicting record improvements in video game speedrunning and apply it to predicting machine learning benchmarks. This model suggests that machine learning benchmarks are not close to saturation, and that large sudden improvements are infrequent, but not ruled out.
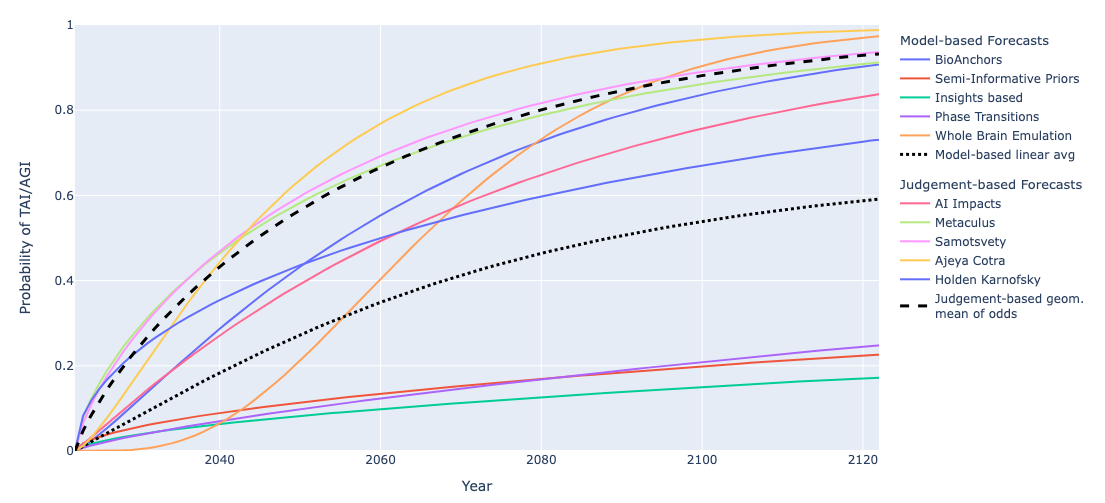
We summarize and compare several models and forecasts predicting when transformative AI will be developed.
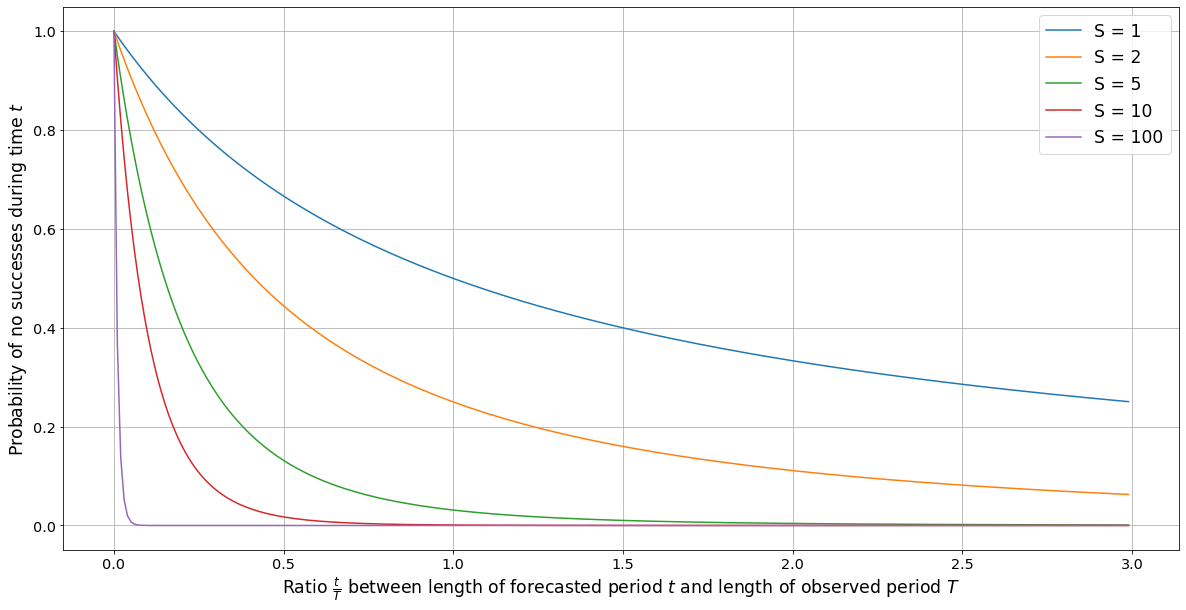
We explore how to estimate the probability of an event given information of past occurrences. We explain a problem with the naive application of Laplace’s rule in this context, and suggest a modification to correct it.
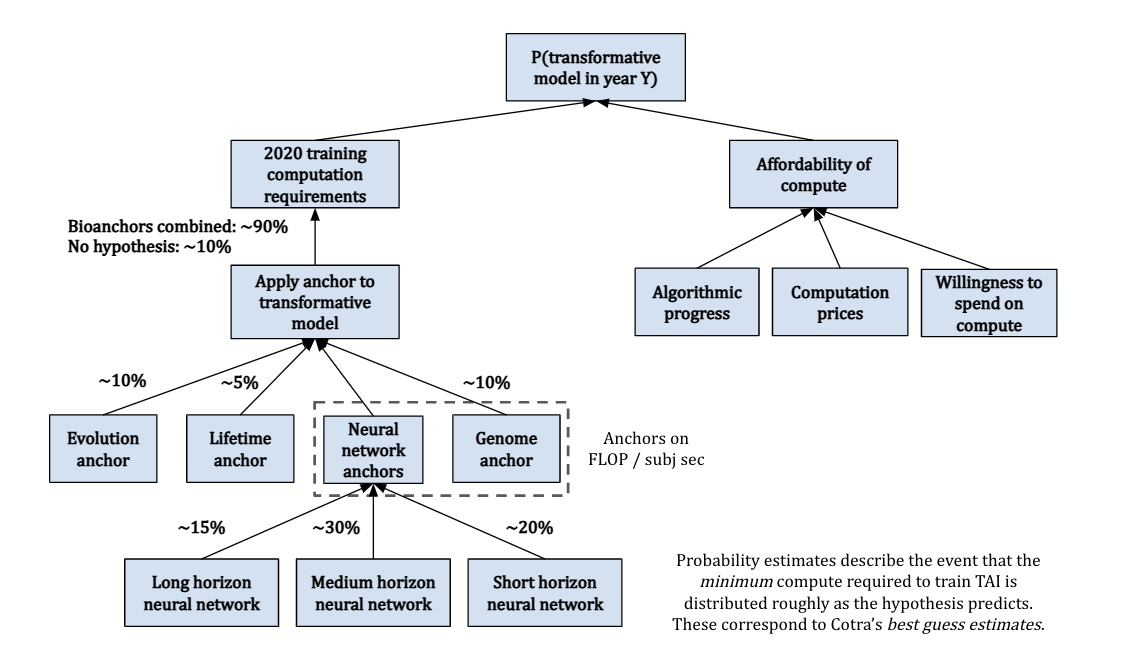
I give a visual explanation of Ajeya Cotra’s draft report, Forecasting TAI with biological anchors, summarising the key assumptions, intuitions, and conclusions.