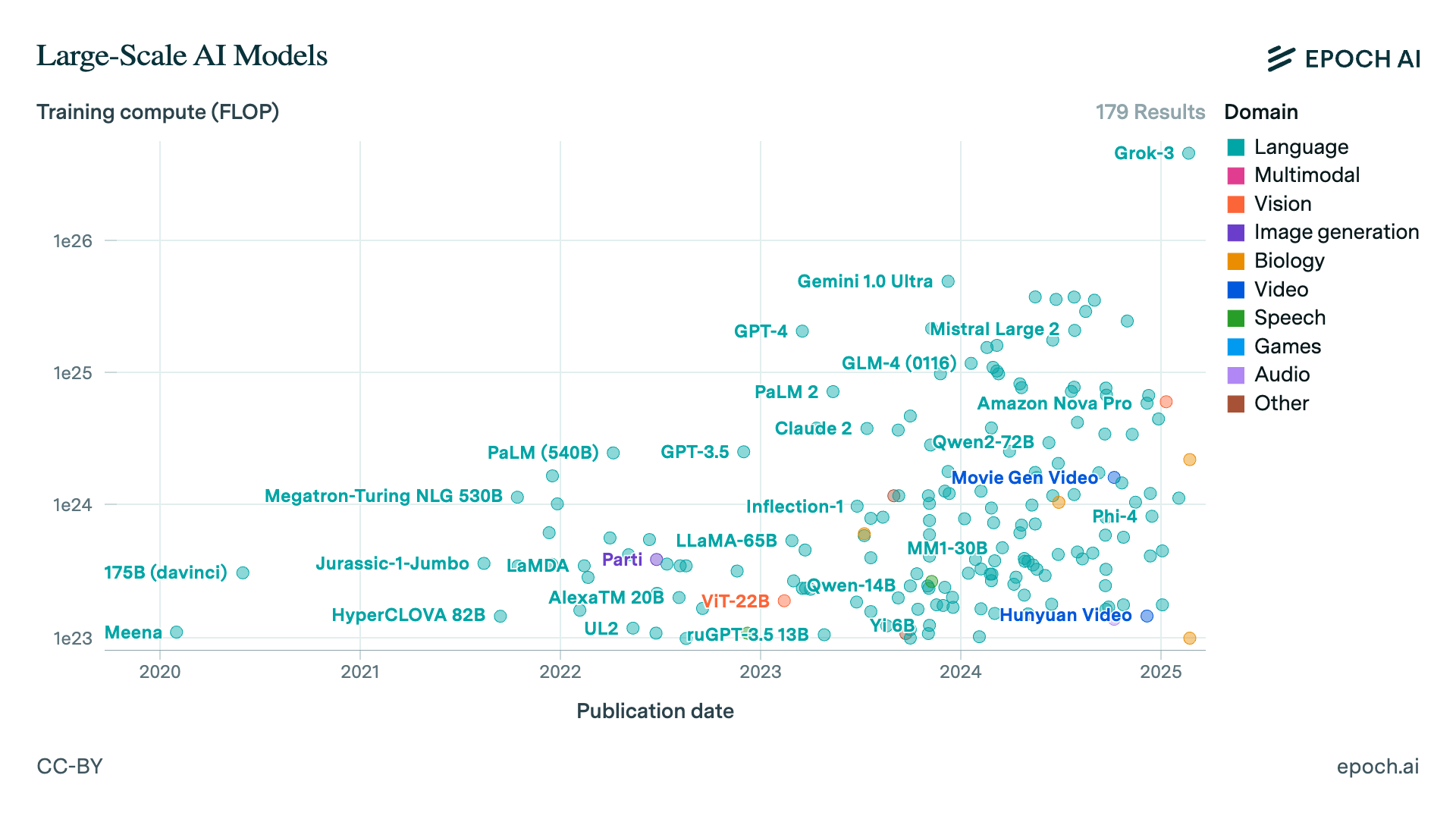
AI is a field where progress happens remarkably quickly compared to the standards of other industries. Even in the past two years, we’ve seen impressive capability gains and cost reductions over models such as GPT-4 that would have been unprecedented in almost any other domain. However, there’s a general sense among observers that progress has been slower than they’ve expected since GPT-4 was released.
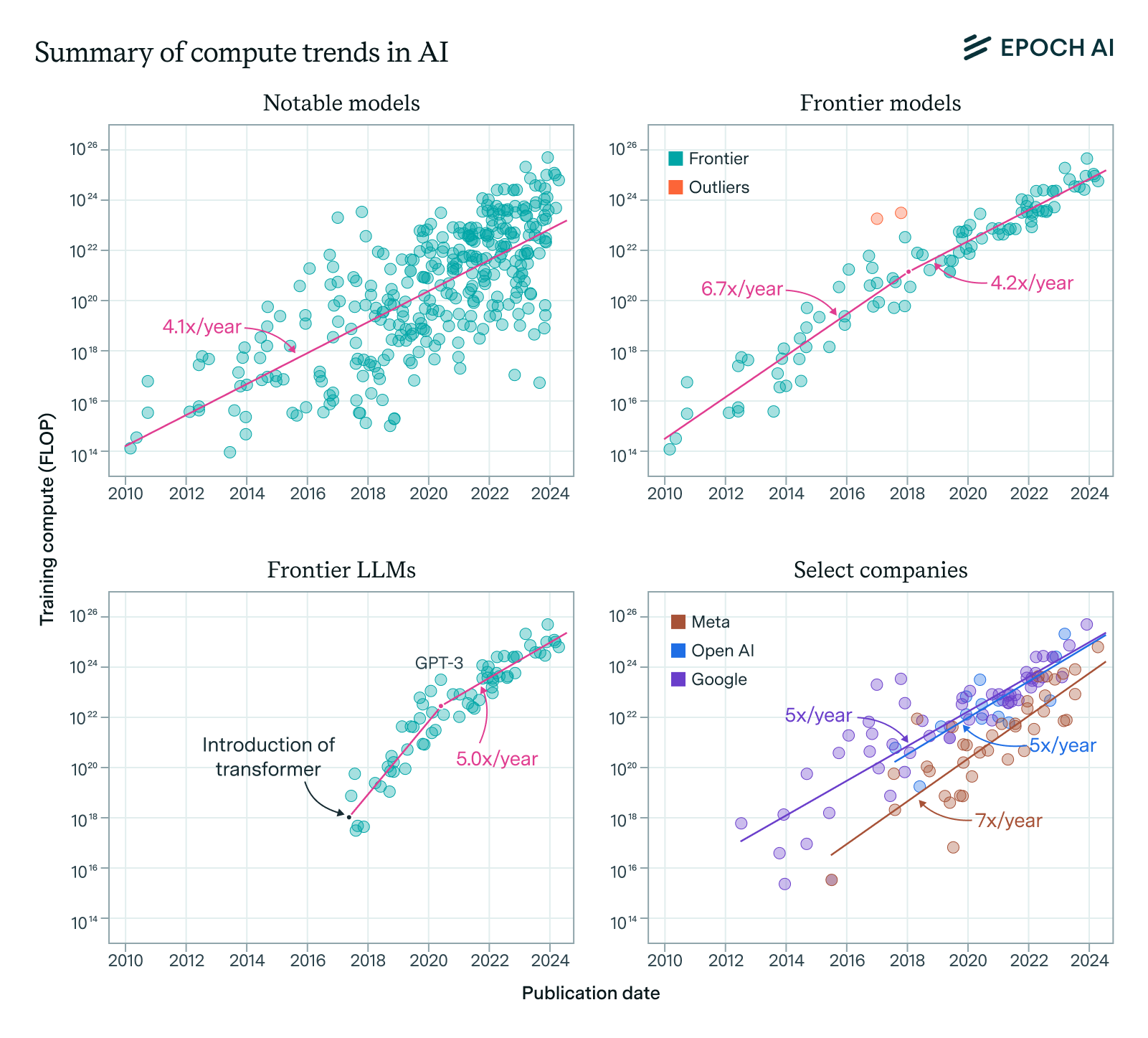
I think this is mostly because compute growth has been slow since then, so we’ve been seeing gains from algorithmic progress and improved data quality rather than large compute scale-ups. The chart below from our article on the compute cost of training frontier models shows this clearly:
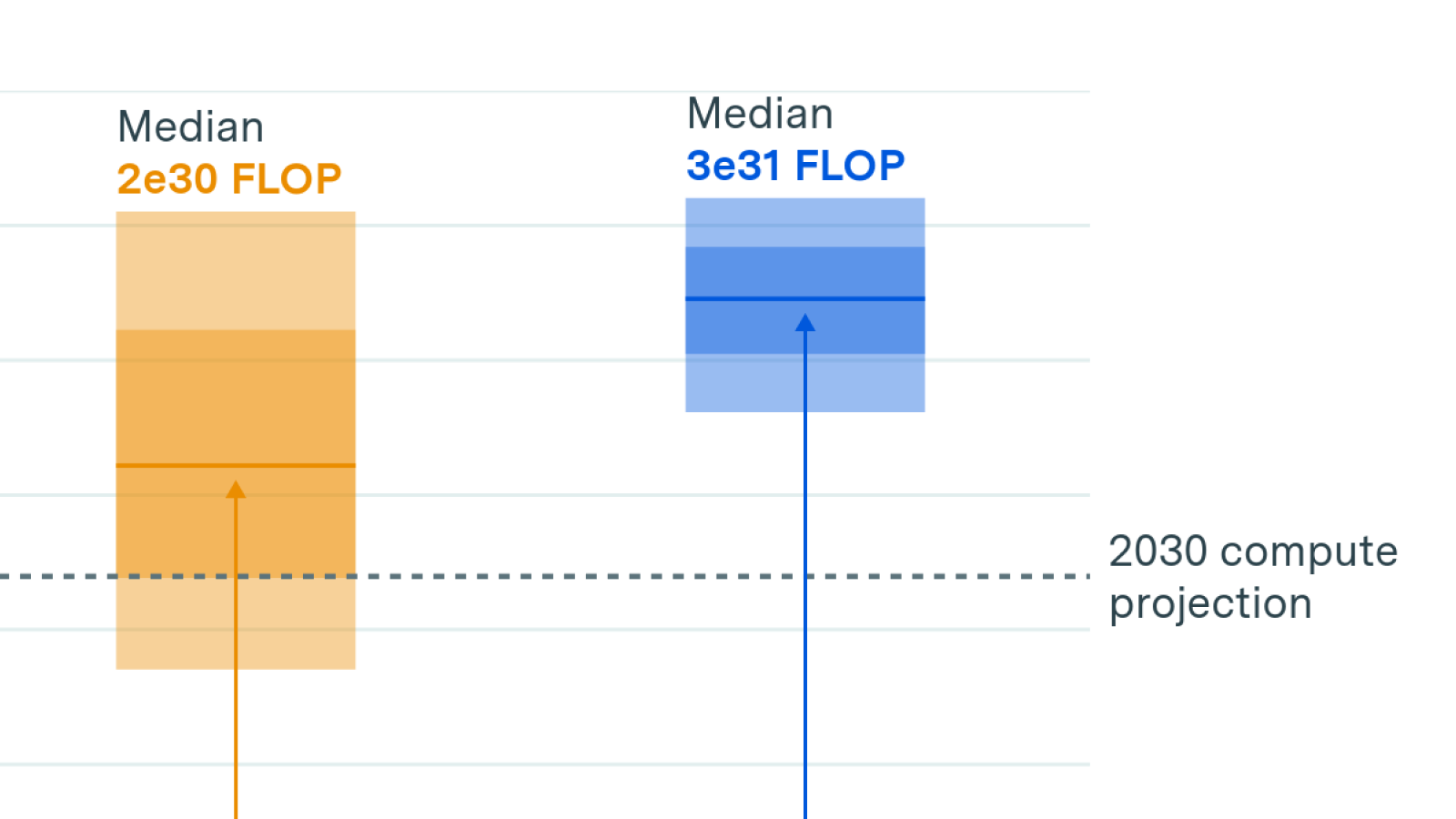
The release of GPT-4 in March 2023 stands out because GPT-4 represented a 10x compute scale-up over the models we had seen before. Since then, we’ve not seen another scale-up of this magnitude: all currently available frontier models, with the exception of Grok 3, have been trained on a compute budget similar to GPT-4 or less. For instance, Dario Amodei, CEO of Anthropic, recently confirmed that the training cost of Claude 3.5 Sonnet was in the tens of millions of dollars, and based on trends in GPU price-performance this means it was likely trained using around twice the compute that GPT-4 used.
Starting with Grok 3, the next generation of models that will be released by frontier labs this year are going to crack this barrier and represent more than an order of magnitude scale-up over GPT-4, and perhaps two orders of magnitude when it comes to reasoning RL. Based on past experience with scaling, we should expect this to lead to a significant jump in performance, at least as big as the jump from GPT-3.5 to GPT-4.
There are a few important questions to ask about this coming scale-up:
-
Concretely, what capabilities should we expect from the incoming next generation models across different domains?
-
How should Grok 3, the first “new generation” model we’ve seen so far, update us on the capabilities we should expect by the end of year?
-
Why does AI spending seem to scale in fits and bursts, increasing by a lot during specific moments and then being flat for a few years? Should we see the slowdown in spending growth since GPT-4’s release as a sign that training compute scaling has “hit a wall”, and so that we shouldn’t expect much performance gain from next generation models?
What to expect from the new models
On the macro scale, I expect the incoming new generation of models to be trained on around 100K H100s, possibly with 8-bit quantization, with a typical training compute of around 3e26 FLOP. The models are initially going to be perhaps an order of magnitude bigger than GPT-4o in total parameter count so we’ll probably see a 2-3x increase in the API token prices and around 2x slowdown in short context decoding speed when the models are first released, though these will improve later in the year thanks to inference clusters switching to newer hardware and continuing algorithmic progress.
The industry as a whole will continue growing, perhaps at a slightly slower pace than before. My median forecast for OpenAI’s 2025 revenue is around $12B (in line with OpenAI’s own forecasts), with around $4.5B of that coming from the last quarter of the year. I expect revenue growth overall to be primarily driven by improvements in agency and maintaining coherence over long contexts, which we’re already seeing some signs of with products like Deep Research and Operator. These appear to be more important than gains in complex reasoning, though less well measured by concrete benchmarks available today.
If we take the high end of our algorithmic progress rate estimates and assume we’ve had an efficiency doubling every 5 months since GPT-4 came out, then a 10x compute scale-up corresponds roughly to 17 months of algorithmic progress in its impact on model quality. We’ll also have another 10 months of algorithmic progress until the end of 2025, which means the total progress we’ll see until the end of 2025 will be worth more than 2 years of algorithmic progress, i.e. more than the progress we’ve seen since GPT-4 when compute expenditures have been fairly flat.
If we were to do a more detailed breakdown of which domains we should expect how much capability gains in, the obvious domains of progress are those in which current models already show some degree of competence. My default expectation is that the tasks AIs are already showing signs of competence in are going to be “solved”, but progress will be slower on capabilities which have so far remained unimpressive. This means I expect a lot of progress on tasks such as programming, math, complex reasoning and short-form creative writing.
On the other hand, I think meaningful agency and coherence over long contexts will continue posing challenges, as we’ve only seen fairly limited improvements on these dimensions over the past two years and another two years of progress is probably not going to bring them within reach. Unlike complex reasoning tasks, agency and coherence over longer contexts both evolved earlier in animals and have been under significant selection pressure in evolutionary history, so we should expect approaching human-level capabilities on these dimensions to be more difficult by default per Moravec’s paradox.
I provide a more detailed breakdown of my expectations in each domain below.
Programming
We’ll have AIs that can do most self-contained programming tasks such as resolving GitHub issues involving a few files or functions in a codebase competently, but struggle to create and manage complex software projects. Here, as in other domains, I think the short effective context windows of AI systems will continue being a stumbling block for real automation of software engineering work. However, the performance improvements we can expect should be very beneficial for productivity enhancing tools such as Cursor.
In concrete terms, I expect AI systems to become superhuman at pure competitive programming, possibly by a significant margin, and for SWEBench Verified to approach saturation (my median SOTA by end of year is 90%). In contrast, AIs will still not be able to e.g. write a compiler from scratch for a language roughly as complex as Rust, or develop original video games that could under ordinary conditions get > $100k in sales on Steam.
Math
We’ll see another big qualitative leap over the competence of reasoning models such as o3 as the test-time compute paradigm gets saturated with compute. My median FrontierMath SOTA is around 75% by the end of 2025, and I expect models to become competent enough to assist humans meaningfully in math research, though not to do original math research themselves where the context and agency problems I’ve mentioned earlier will continue being a bottleneck.
I still expect AI systems to struggle with tasks where deep familiarity with a narrow literature is required for success, and partly because this characterizes a large part of frontier math research I think the utility of the AI systems will continue to be limited.
Agents
I think this is a domain where we’ll see enormous progress but the agents at the end of the year will still be rather unimpressive due to how bad the current ones (such as OpenAI’s Operator) currently are. Right now, Operator struggles with the simplest of computer use tasks; but by end of year I think we’ll have systems that can reliably do the below sample tasks fully autonomously:
-
Find a restaurant near a given location meeting certain criteria and book a reservation, assuming this can be done through a website.
-
Prepare an elo graph of the best Computer Chess Rating List (CCRL) chess engine since 2015 with at least one data point per month. This is difficult because the CCRL doesn’t store historical data in a convenient format, but e.g. can be done using the Internet Archive.
-
List all companies with quarterly reports filed with the SEC in the last 90 days, with a market cap between $10 million and $50 million, and with over $10 million in cash and cash equivalents on the latest balance sheet.
On the other hand, here are three sample tasks that I expect to remain beyond the reach of AI agents by the end of 2025:
-
Play a typical single-player video game from start to finish (not just a specific game, but e.g. more than 80% of games published on Steam in 2025)
-
Directly solve nontrivial problems on a user’s computer for them - for example, “figure out why my Ubuntu VM can’t connect to the internet and fix the issue with remote desktop access to the host machine”
-
Do nontrivial photo or video editing tasks - for example, “take this video and change the background music from track X to track Y using standard video editing software”
In general, the tasks that the agents will be able to do are ones that don’t heavily rely on the capabilities that I expect to lag behind: sophisticated visual processing at low latencies, coherence over long contexts, and maintaining a detailed and complex internal model that guides which actions an AI agent should take at which times. For example, humans find it easy to beat Pokemon games, but I expect AI agents to struggle with this task for some time to come.
What should we make of Grok 3?
Since my argument for expecting accelerated progress is based on the incoming compute scale-up, it’s worth examining Grok 3’s capabilities, as it’s the first model release we’ve seen with well over 1e26 FLOP in training compute.
It’s possible to make both a bullish and a bearish for scaling based on Grok 3. The bullish case is that Grok 3 is indeed state-of-the-art as a base model with a meaningful margin between it and the second best models, and this is what we would expect given its status as a “next generation model” with around 3e26 FLOP of training compute. The bearish case is that the gap between Grok 3 and models such as Claude 3.5 Sonnet seems much smaller than the gap between GPT-4 and GPT-3.5, despite both representing roughly an order of magnitude of compute difference.
I think the correct interpretation is that xAI is behind in algorithmic efficiency compared to labs such as OpenAI and Anthropic, and possibly even DeepSeek. This is why Grok 2 was not a frontier model despite using a comparable amount of compute to GPT-4, and this is also why Grok 3 is only “somewhat better” than the best frontier models despite using an order of magnitude more training compute than them.
The right comparison to isolate the effect of scaling alone is to compare models at different scales while holding the lab fixed. If we do this for xAI and compare Grok 2 to Grok 3, which we know from the remarks on the Grok 3 livestream represents a 10-15x compute scale-up, we see massive differences in performance. So what we should expect from the next generation base models of OpenAI and Anthropic is that they will improve on 4o and Sonnet as much as Grok 3 improved over Grok 2. This is probably slightly overstated as part of Grok 3’s progress came from xAI closing their distance with the algorithmic frontier, but I think it’s still in the right ballpark.
In addition to this, Grok 3 is only somewhat better on reasoning tasks such as the American Invitational Math Exam (AIME) compared to DeepSeek R1, which suggests they haven’t spent substantial resources yet on scaling up their complex reasoning RL. I think this is partly due to RL being more serial and thus harder to scale by buying more GPUs, but there’s plenty of more performance to be squeezed out of even Grok 3 once xAI figures out how to properly scale RL compute spending to the tens of millions of dollars.
Putting all of this together, I think Grok 3 gives us more reasons to be bullish than bearish on AI progress this year.
Why has spending not grown faster before?
Some people have taken the lack of growth in spending on model training compute since the release of GPT-4 as evidence that scaling is yielding diminishing returns. As far as evidence goes, I think this is rather weak because there are many other compelling reasons to expect spending growth to slow down between big releases, and we’ve seen similar lulls in spending growth before, for example after the release of GPT-3.
The most important reason to expect a slow down is that the steady trend of algorithmic improvement incentivizes labs to wait before committing to a new training run, as the same compute spent later will yield greater returns. It’s often better return on investment to spend compute on distillations, inference, experimentation, et cetera rather than to do a more primitive training run which you expect to shortly be superseded. As software progress continues, at some point it becomes less valuable on the margin to continue investing in the ecosystem built around the old models and more valuable to attempt a large training scale-up that will produce a significant leap in capabilities.
In addition, each order of magnitude scale-up takes a certain amount of engineering to execute, both on the hardware and on the software side. Without this, training runs are either infeasible to orchestrate or yield unsatisfactory results. Doing the necessary work takes time, and failed training runs are not uncommon at frontier labs on the way to figuring out how to do a scale-up correctly.
Labs also need to secure the hardware necessary for such scale-ups, and this is not trivial because the upfront capital expenditure required for a cluster to train a model is often 10x larger than the training cost of the model itself. This is because the amortized lifetime of the GPUs in a cluster is on the order of a few years, but training runs only take on the order of a few months. So a model whose training cost, measured in GPU hours times the cost per GPU hour, is $300M requires a capex of $3B or more.
Frontier labs without their own compute, such as OpenAI and Anthropic, need to negotiate deals with hyperscaler partners who might want to see impressive results from earlier AI systems before offering the compute access necessary for such a scale-up. In addition, the hyperscalers themselves need time to build out the required data center capacity - even xAI, which moved remarkably quickly with their buildout, needed four months to bring a cluster of 100,000 H100s online.
When all of these are taken into account, along with the fact that many of the factors (e.g. securing hardware access) are correlated across labs, it’s not too surprising that we haven’t seen more aggressive training runs earlier even if scaling works just fine. There are just many practical factors which could explain a “pause” of around two years.
Concluding thoughts
The picture I’ve painted above is one in which we see a lot of progress on more exciting skills such as math and competitive programming, but less progress on boring skills such as agency and coherence. Due to Moravec’s paradox, I believe this is a general pattern we will see until AIs are able to match human capabilities across the board.
In addition, a counterintuitive prediction I’m willing to make is that most of the economic value of AI systems, in 2025 and beyond, is actually going to come from these more mundane tasks that currently don’t get much attention in benchmarking and evaluations. The smaller improvements in long-context performance, ability to develop plans and adapt them to changing circumstances, a general ability to learn quickly from in-context mistakes and fix them, etc. are going to drive more revenue growth than the math, programming, question answering etc. capabilities that AI labs like to evaluate and demo. In the long run, I expect most of the revenue from AI to come from the enterprise use cases depending more on such mundane capabilities enabling partial or complete automation of human labor, but 2025 is most likely too soon for the consumer use cases to be saturated.
This is not to say that 2025 will not be an exciting year for AI - it might well turn out to be the most exciting year we’ve seen so far, even exceeding 2023. However, I think the excitement will mostly be driven by capabilities that are actually peripheral to the real revenue growth that we will see throughout the course of the year. To keep track of what’s really going on with AI capabilities, my recommendation is to not be distracted by the incoming hype and focus more on underlying core skills that are economically crucial and have seen significantly less capability gains.
About the authors

Related work