Overview
In 2012, the best language models were recurrent networks that struggled to form coherent sentences. Fast forward to today and language models like GPT-4 assist hundreds of millions of active users and are able to perform tasks across a wide range of domains.
Clearly, progress has been rapid—but what made this possible? One reason is that the compute used to train language models has been scaled up drastically, resulting in better performance. But that’s only part of the puzzle. AI practitioners have developed better model architectures, optimizers, and other algorithmic innovations that reduce the compute required to reach certain performance levels—what we refer to as algorithmic progress.
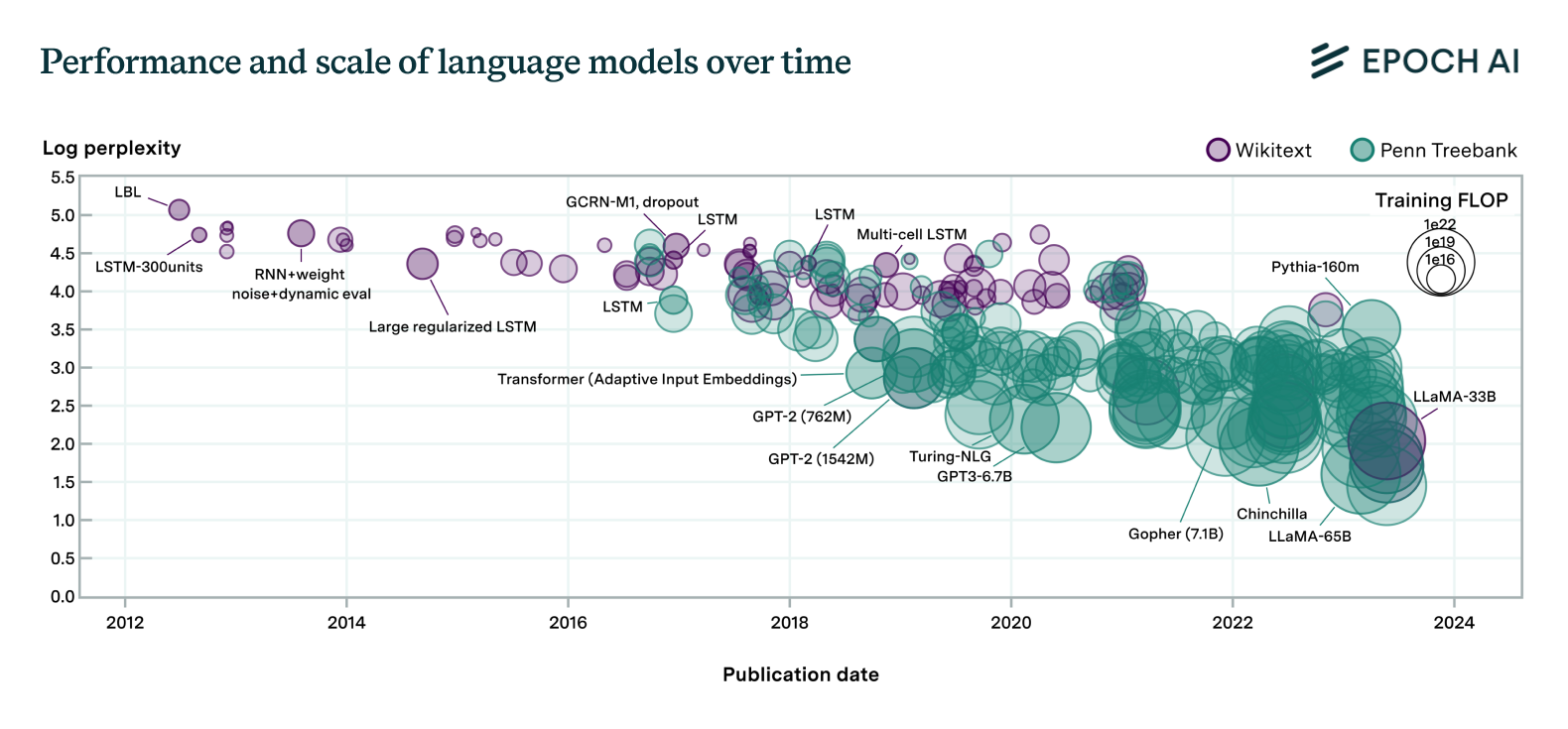
Figure 1. Performance of 231 language models (measured in log perplexity) used in our work against their date and scale (measured in FLOP). Models are both becoming larger and more proficient. It’s unclear to which degree the better results are driven by improvements in scale or in efficiency.
In our new paper, we conduct the most comprehensive analysis of algorithmic progress in language models to date, focusing on algorithmic improvements in pretraining. We find that the level of compute needed to achieve a given level of performance has halved roughly every 8 months, with a 95% confidence interval of 5 to 14 months. This represents extremely rapid progress, outpacing algorithmic progress in many other fields of computing and the 2-year doubling time of Moore’s Law that characterizes improvements in computing hardware (see Figure 2).
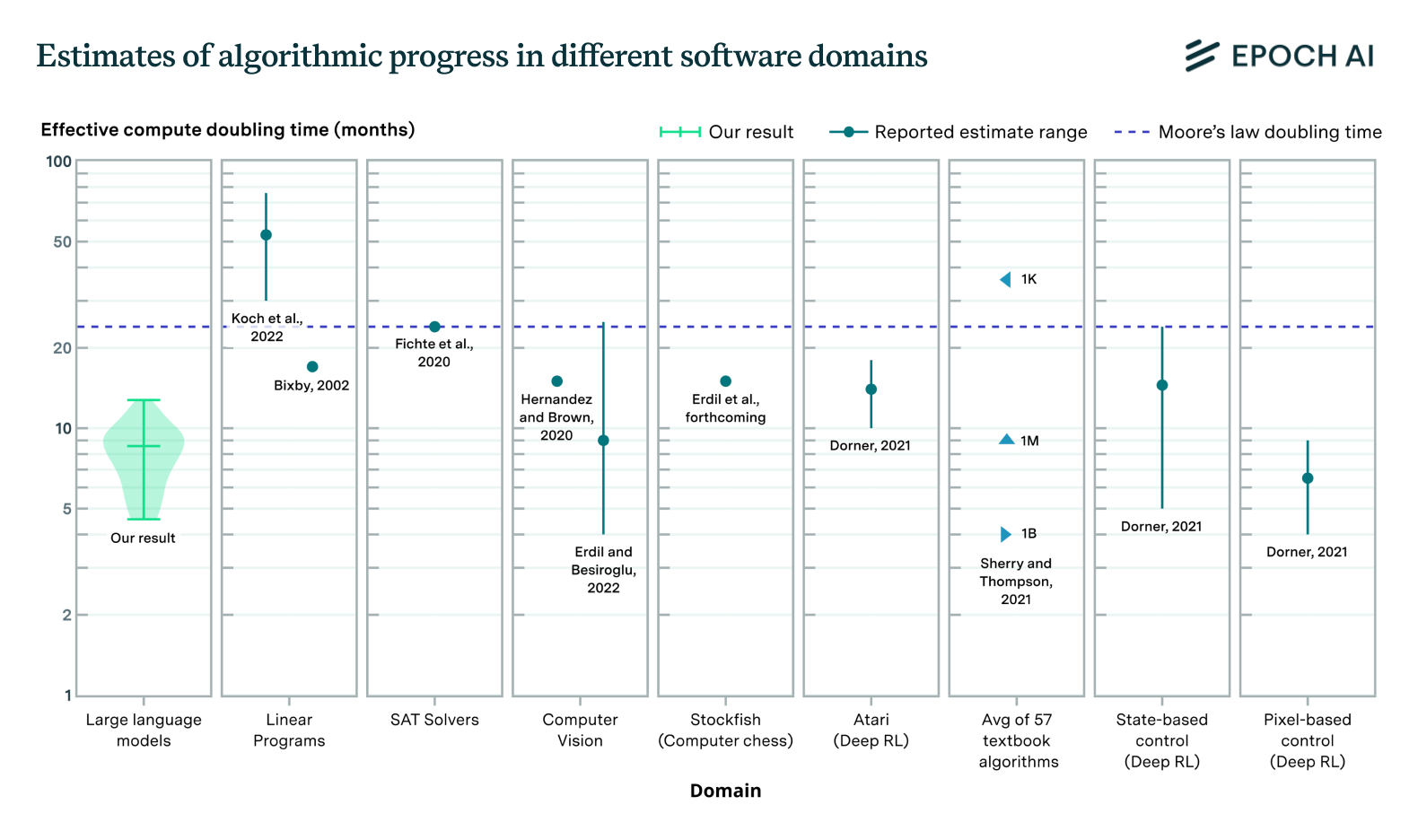
Figure 2. Estimates of the rate of algorithmic progress across different domains. This is measured in terms of the “effective compute” – i.e. the equivalent increase in scale that would be needed to match a given model performance absent innovation.
To better understand the role of algorithmic improvements in performance improvements, we compare its contribution to that of compute scaling. A Shapley value analysis suggests that 60-95% of the gains have come from increased compute and training data, while novel algorithms have been responsible for only 5-40% of the progress. In addition, this analysis suggests that the relative importance of algorithmic improvements has decreased over time as compute scaling accelerated around 2018. Overall, we find that the majority of performance improvements in recent years have stemmed more from the massive scaling of compute rather than fundamental algorithmic advances (see Figure 3).
We also analyze two particularly notable algorithmic innovations. The first is the transformer architecture—an innovation that underpins the best existing language models today, such as GPT-4. We find that its introduction accounts for the equivalent of almost two years of algorithmic progress in the field, underscoring its importance. The other innovation is the introduction of Chinchilla scaling laws (Hoffmann et al., 2022), which we find accounts for the equivalent of 8 to 16 months of algorithmic progress.
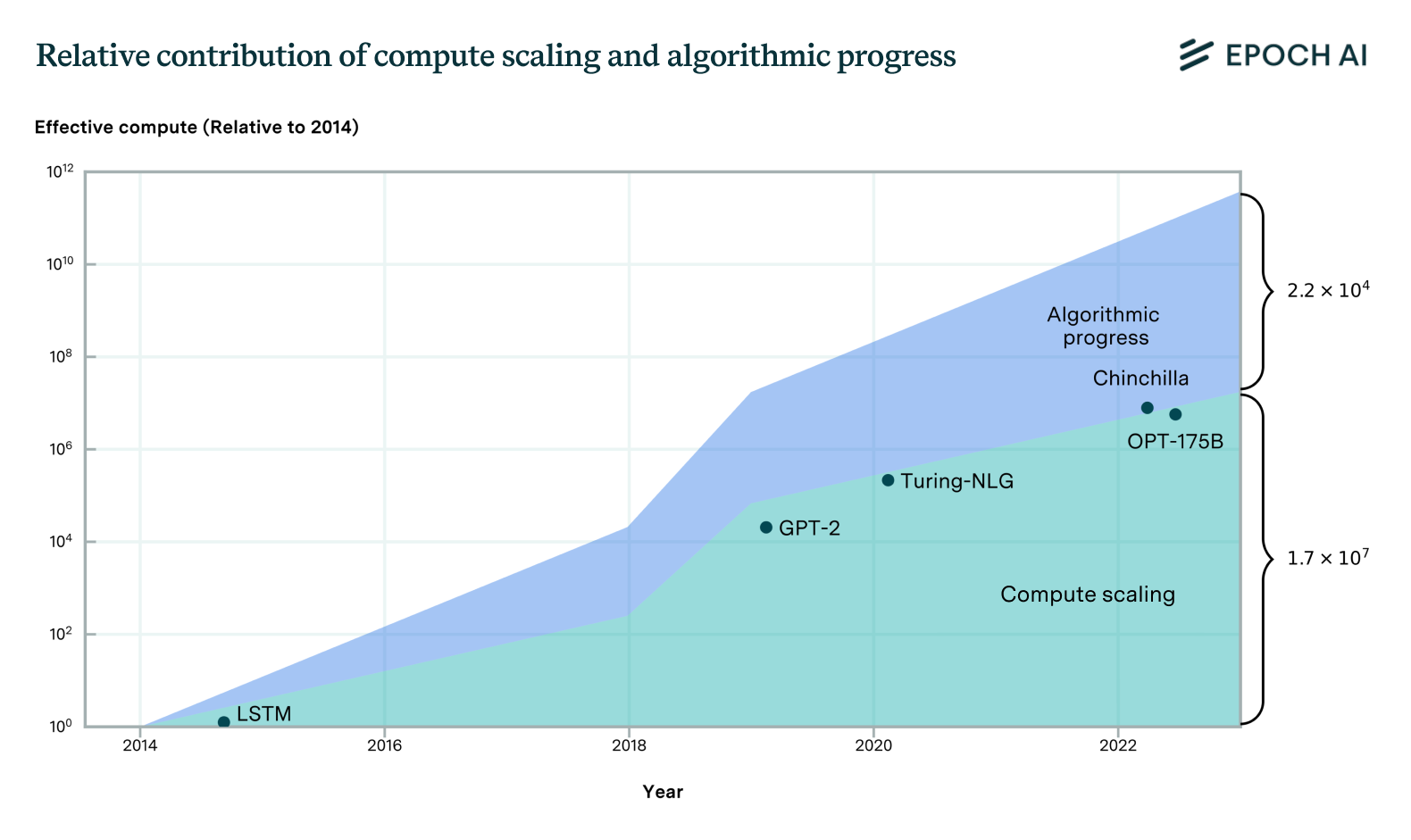
Figure 3: Estimates of the contributions of scaling and algorithmic innovation in terms of the raw compute that would be naively needed to achieve a state-of-the-art level of performance. The contribution of algorithmic progress is roughly half as much as that of compute scaling.
Although our analysis achieves substantial progress in our understanding of algorithmic progress in language models, it is limited in several ways. First, the model cannot reliably estimate the impact of specific innovations. Second, the historical co-occurrence of algorithmic improvements and compute scaling makes it difficult to disentangle their relative contributions. Third, the degree to which different innovations improve performance depends on model scale. This means, for example, that we can’t naively apply our models to predict the performance of models trained on small compute budgets. Lastly, there is substantial uncertainty about the most appropriate way to model algorithmic progress, given that there are many possible approaches with different predictions (see Figure 4). It will be hard to make progress on this without substantially more and better data.
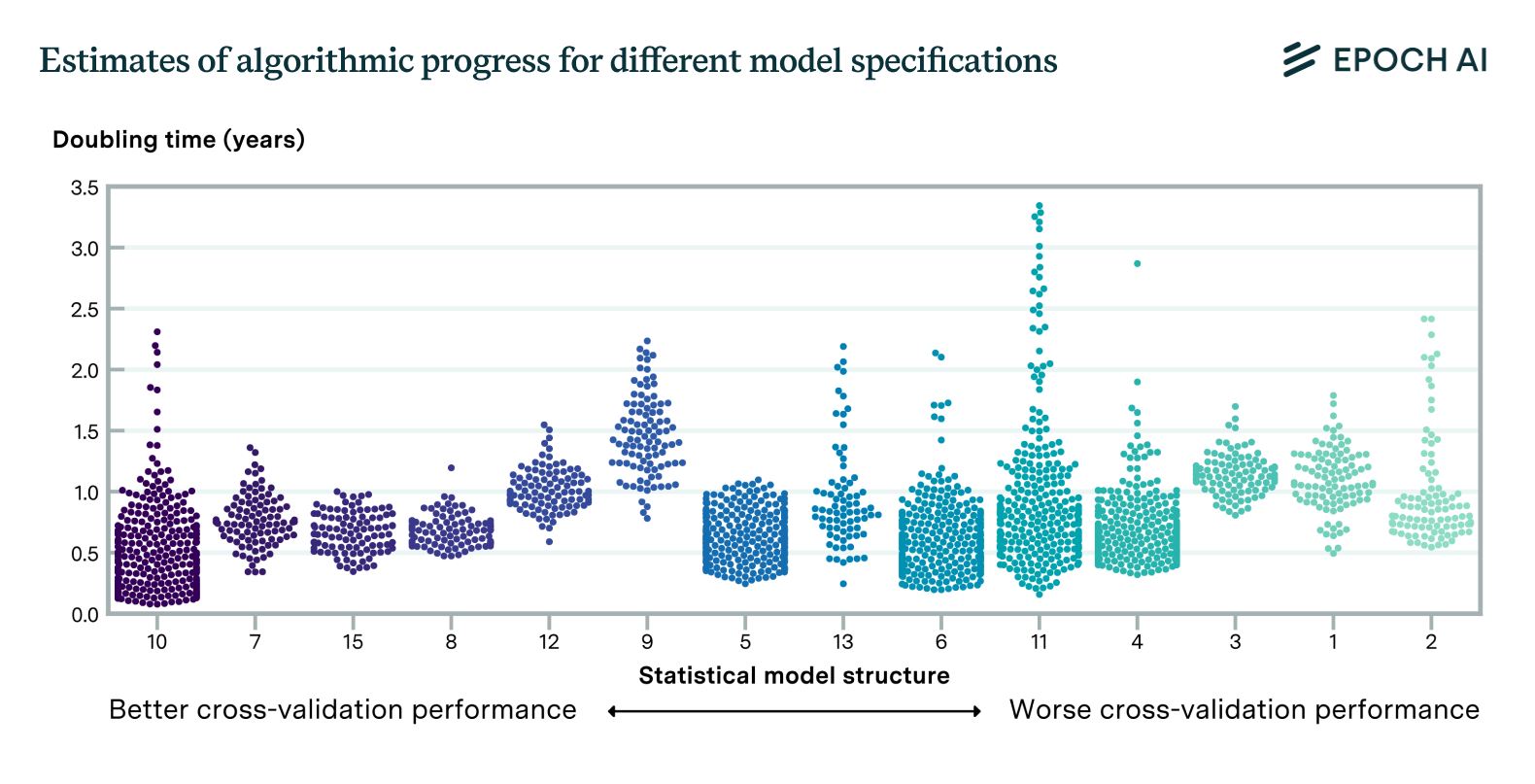
Figure 4. We estimate the rate of algorithmic progress according to dozens of models. We find a wide range of values compatible with the different models we tested.
So should we expect similar rates of algorithmic progress in the future? The answer to this question remains unclear. Future progress—from both compute and algorithms—hinges on the rate of increased investment,1 and on the extent to which AI can substitute for human workers. Moreover, our study focuses on algorithmic progress during pre-training and does not account for algorithmic gains through post-training enhancements, which are another key driver of performance improvements.
Nevertheless, our work provides a rigorous quantitative analysis of the remarkable rate of progress in language modeling capabilities over the past decade. It underscores the immense impact of scale on language model performance and lays a foundation for further research quantifying the sources of efficiency gains in this rapidly advancing field.
In summary, our work helps quantify the importance of improvements in the efficiency of language models. We show that it exceeds the rate of algorithmic improvement in other software domains, yet it has been less important than compute scaling over the previous decade. This helps illustrate the two-fold way we are progressing towards more general and more capable language models.
Read our full paper in arXiv.
-
See Trends in the Dollar Training Cost of Machine Learning Systems for an historical analysis of the growth of model training compute costs.

About the authors








Related work