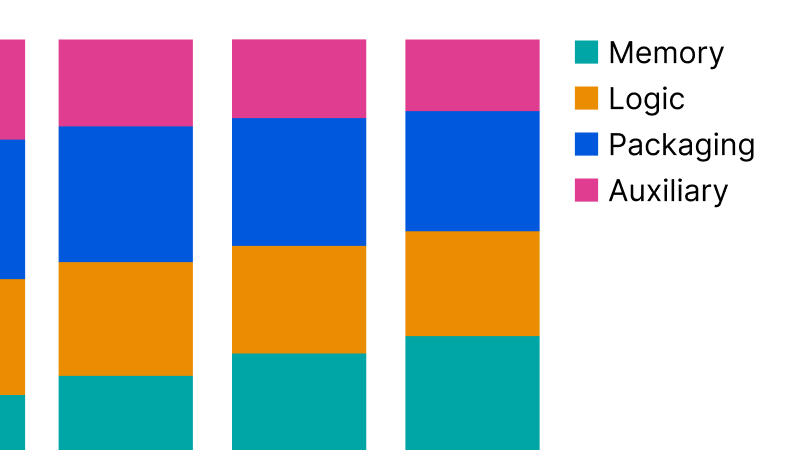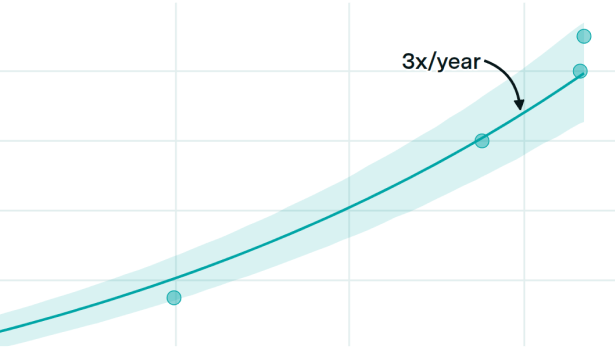Epoch AI’s data insights break down complex AI trends into focused, digestible snapshots. Explore topics like training compute, hardware
advancements, and AI training costs in a clear and accessible format.
Featured
Data Insight
Jan. 9, 2026
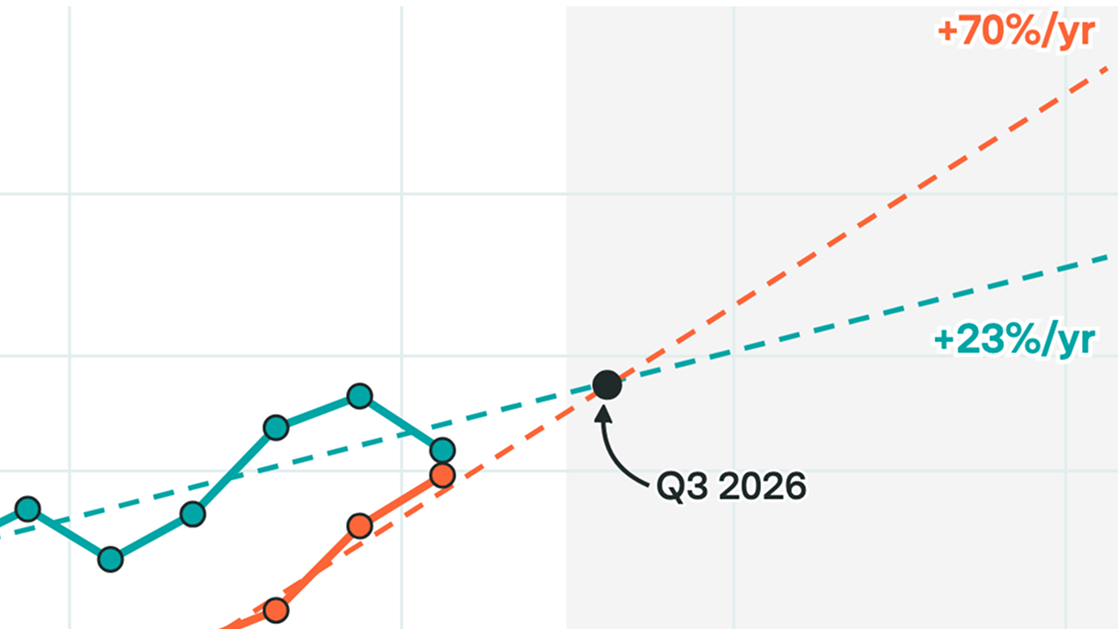
Global AI computing capacity is doubling every 7 months
Data Insight
Dec. 23, 2025
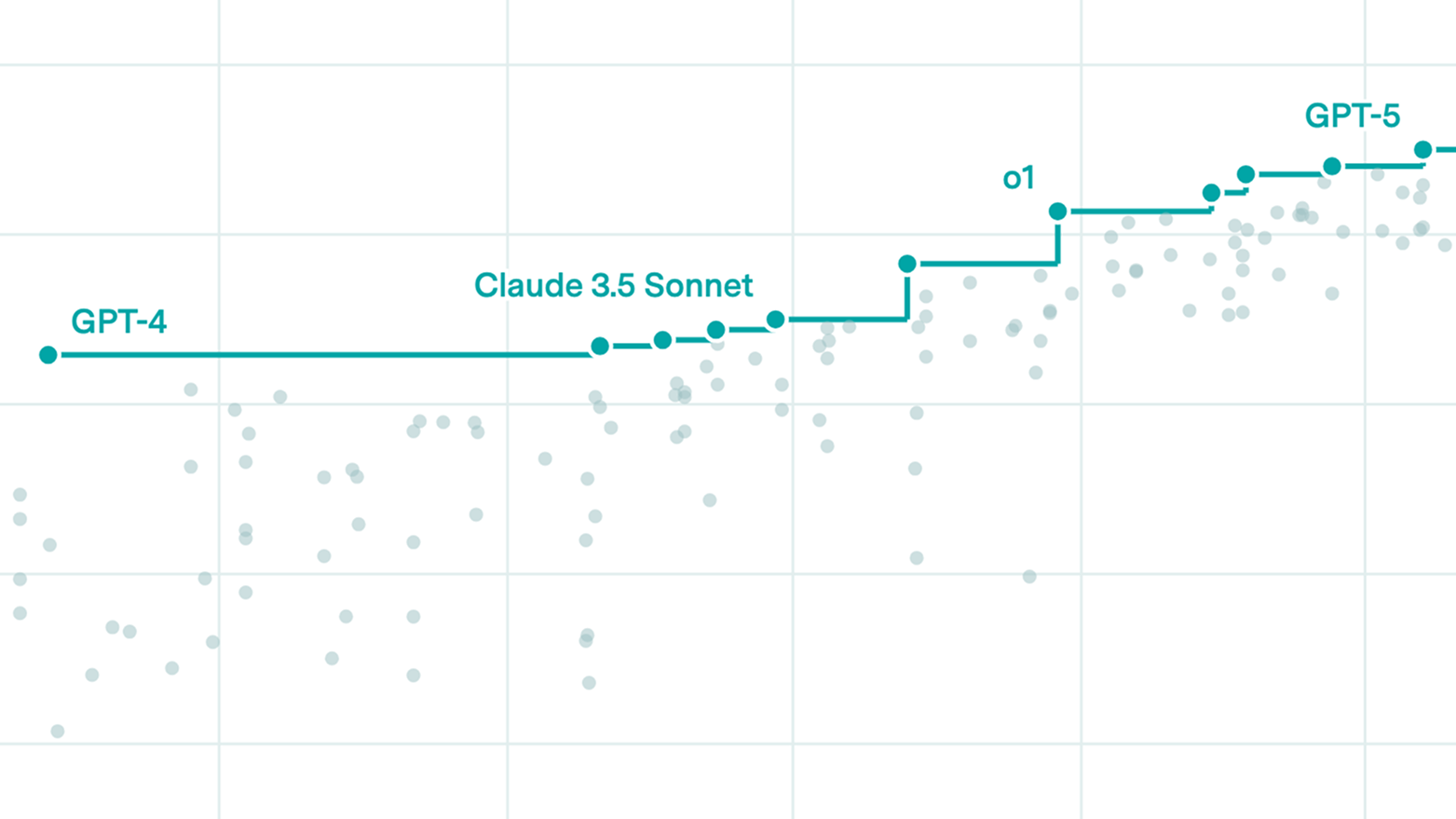
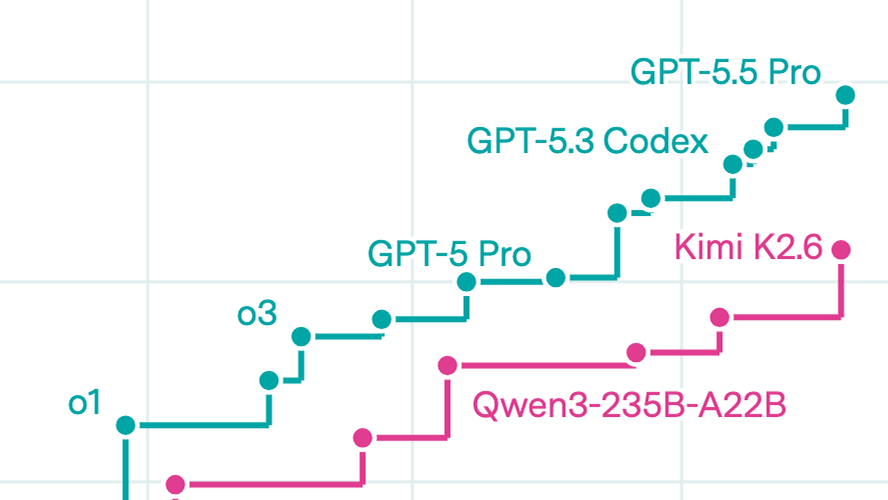
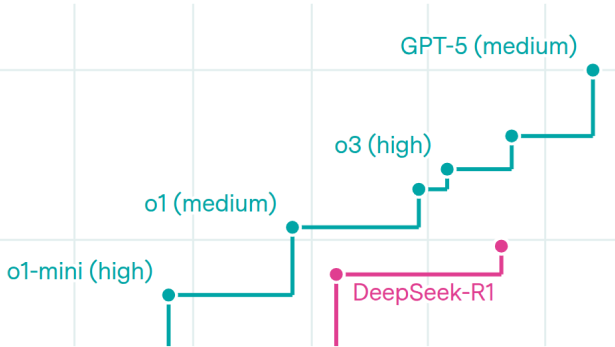
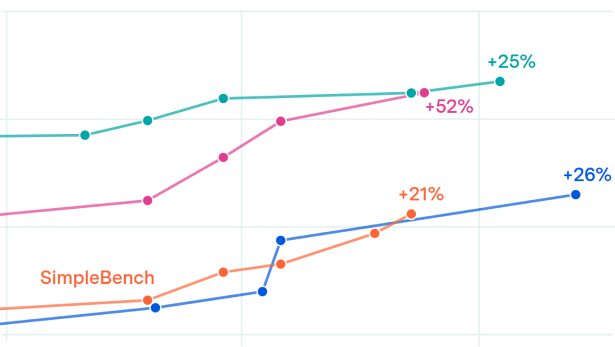
AI capabilities progress has sped up
Data Insight
Mar. 12, 2025
LLM inference prices have fallen rapidly but unequally across tasks
Filter
Topic
0 results
Data Insight
Jul. 7, 2026
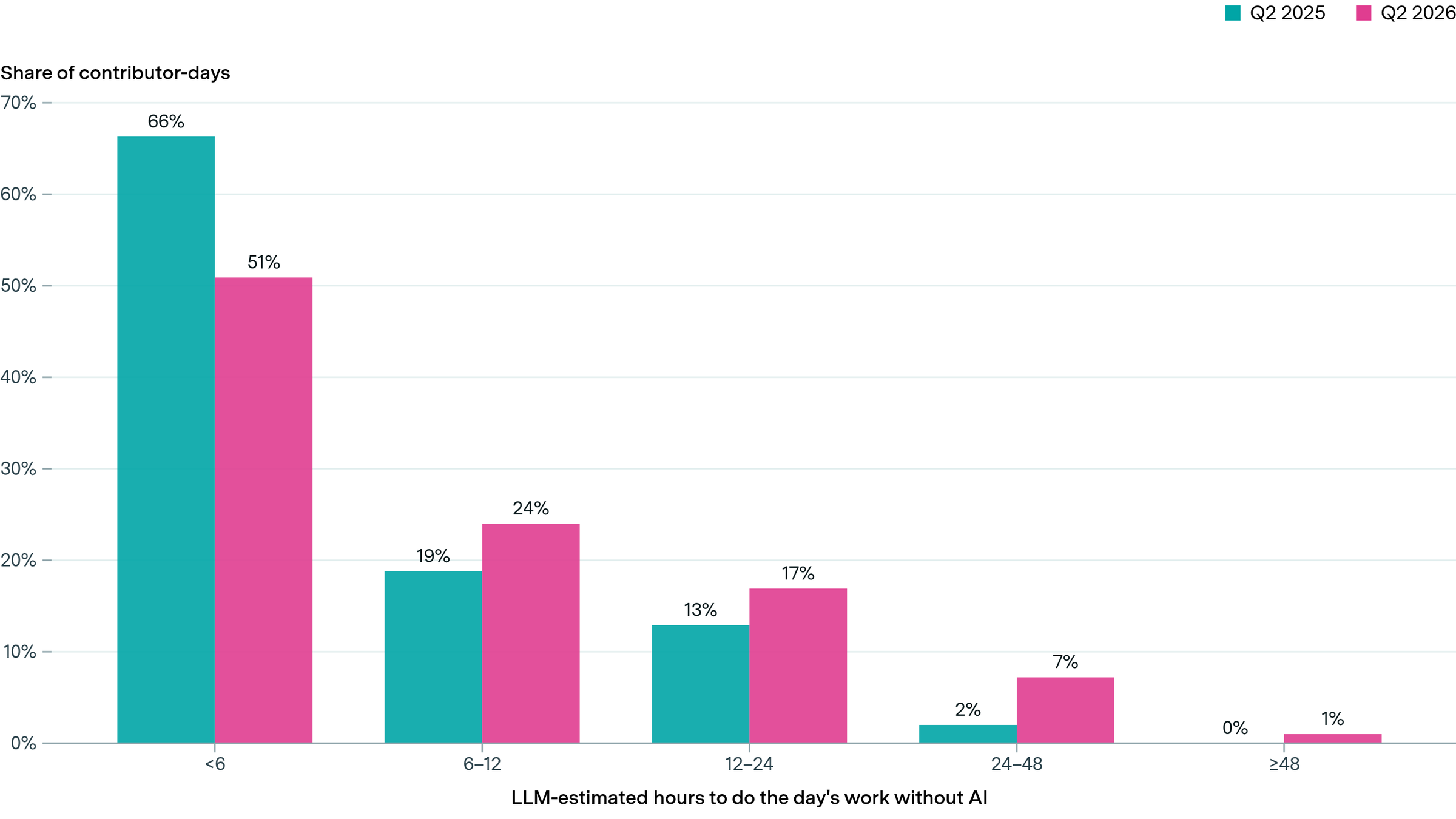
Contributions to OpenAI's Codex codebase show signs of AI uplift
By Jaeho Lee and Thomas Kwa
Data Insight
Jul. 2, 2026
Disclosure of serious cyber vulnerabilities spiked around the release of Claude Mythos Preview
By Luke Emberson
Data Insight
Jul. 2, 2026
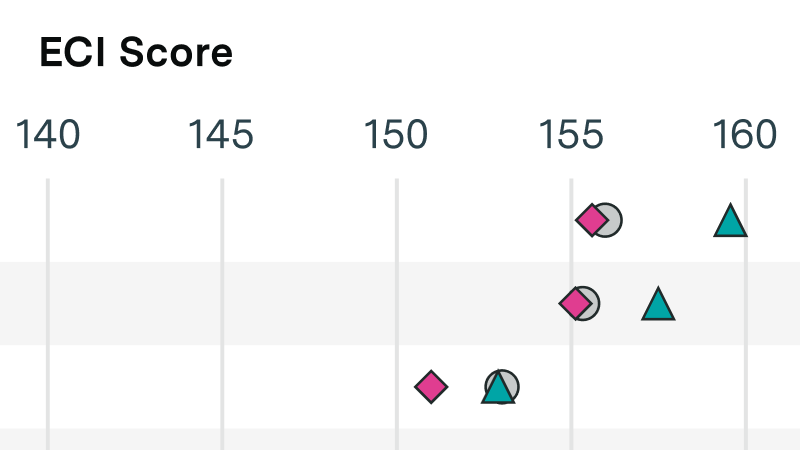
GPT-4 led in ECI far longer than any other model
By Jaeho Lee
Data Insight
Jun. 16, 2026
Hyperscaler capex is on trend to outpace their cash inflows by the end of 2026
By Isabel Juniewicz
Data Insight
Jun. 11, 2026
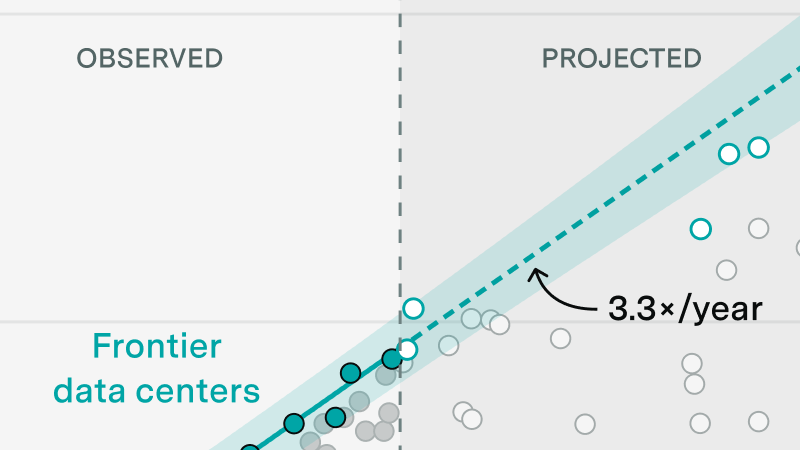
The record for computing capacity in a single data center has doubled every 7 months
By Ben Cottier
Data Insight
Jun. 5, 2026
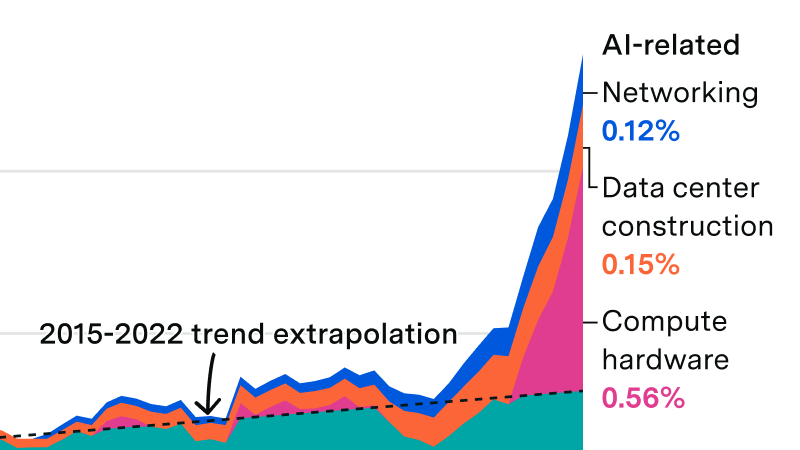
The AI boom has doubled computing infrastructure's share of US GDP
By Isabel Juniewicz
Data Insight
May 29, 2026
Open models lag state-of-the-art closed models by 4 months
By Jack Edwards and Luke Emberson
Data Insight
May 21, 2026
Memory has grown to nearly two-thirds of AI chip component costs
By Venkat Somala
Data Insight
May 15, 2026
Claude overperforms at software engineering and underperforms at math
By Alexander Barry
Data Insight
May 14, 2026
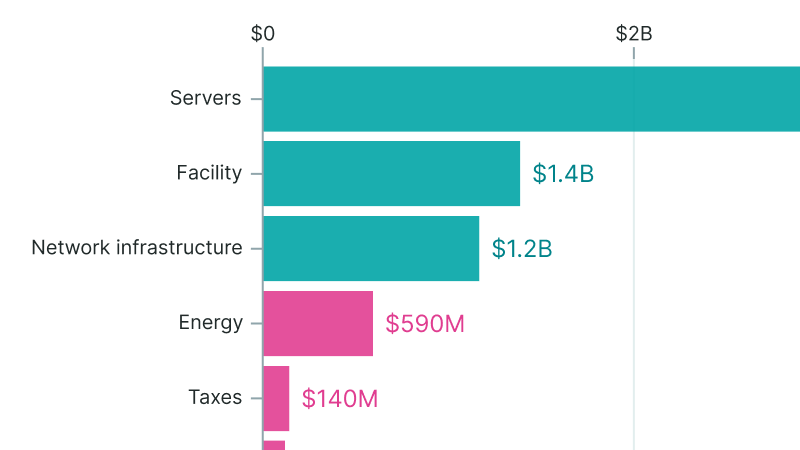
Servers account for 60% of the total cost of ownership of a one-gigawatt AI data center
By Amelia Michael and Ben Cottier
Data Insight
May 8, 2026
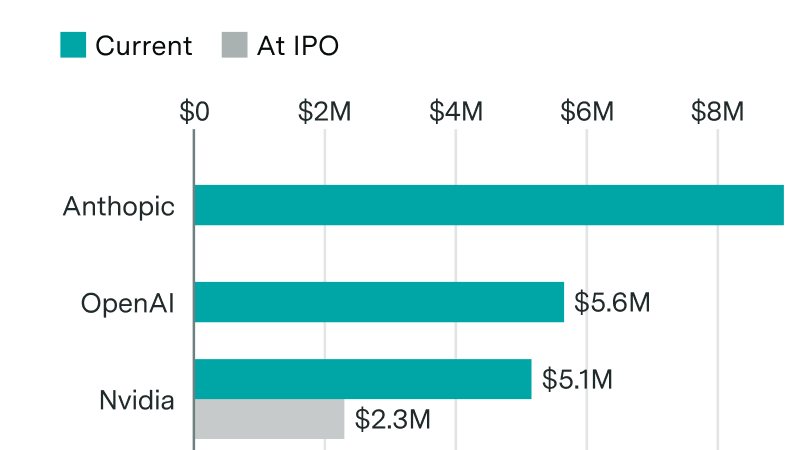
Anthropic and OpenAI earn more revenue per employee than major public tech companies
By Luke Emberson
Data Insight
Apr. 22, 2026
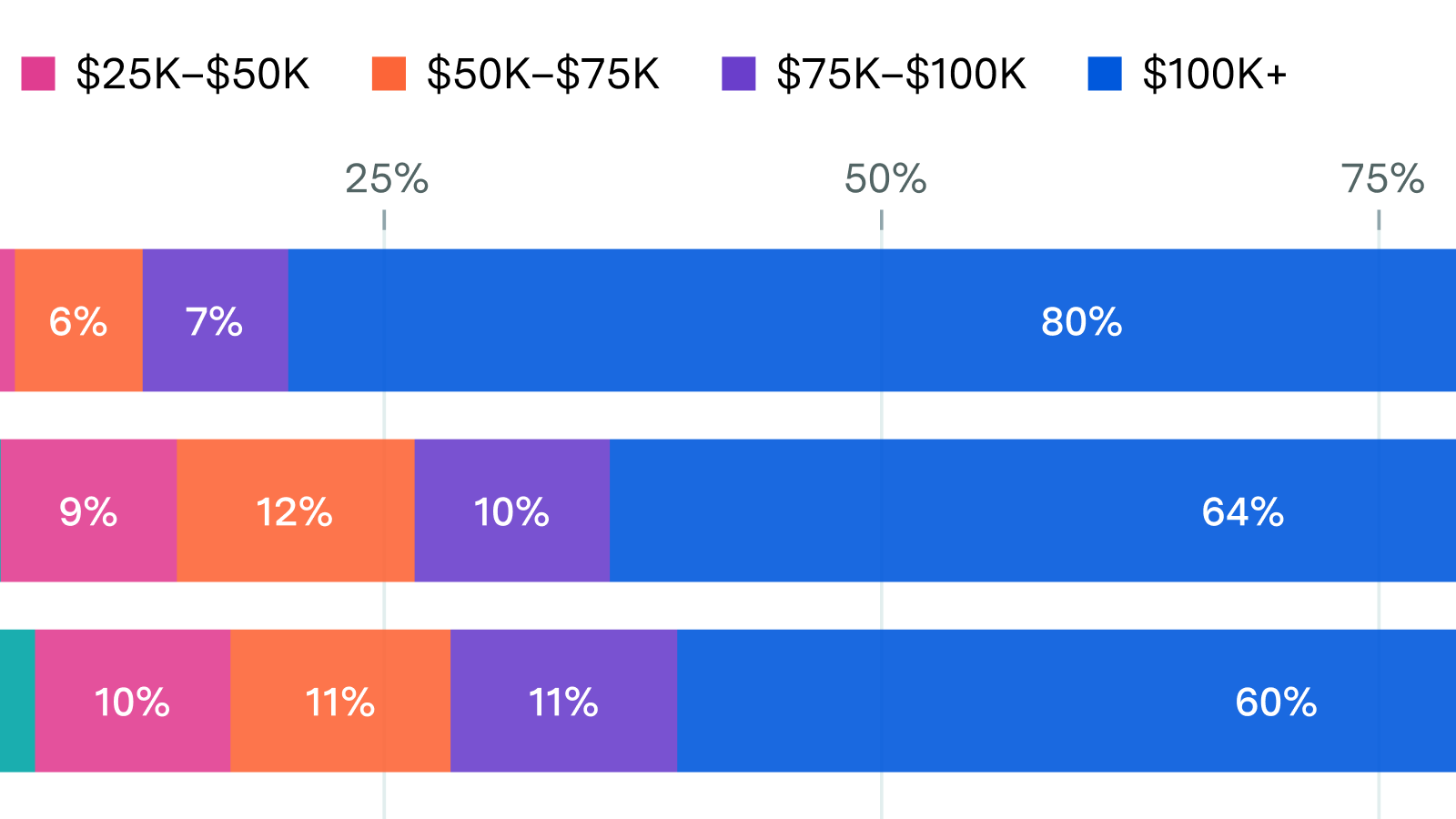
Claude users skew towards higher-income households; Meta towards lower-income
By Caroline Falkman Olsson and Jaeho Lee
Data Insight
Apr. 15, 2026
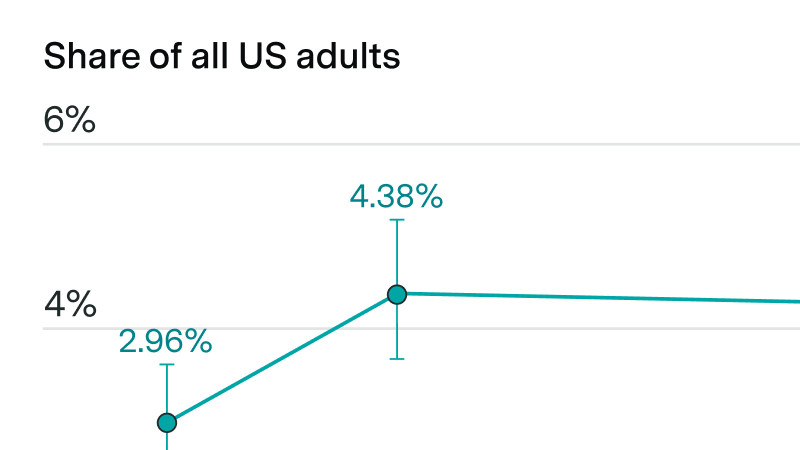
Claude usage rose by over 40% amid increased attention but remains far behind ChatGPT
By Yafah Edelman, Caroline Falkman Olsson, and Jaeho Lee
Data Insight
Apr. 14, 2026
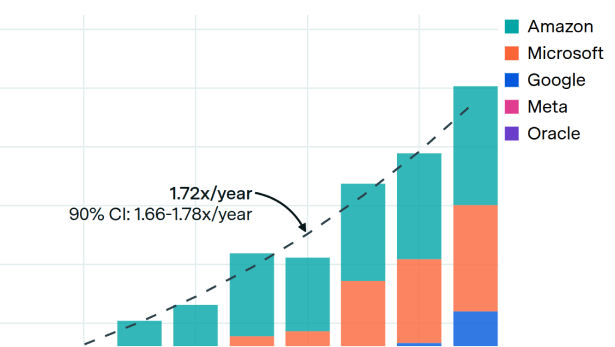
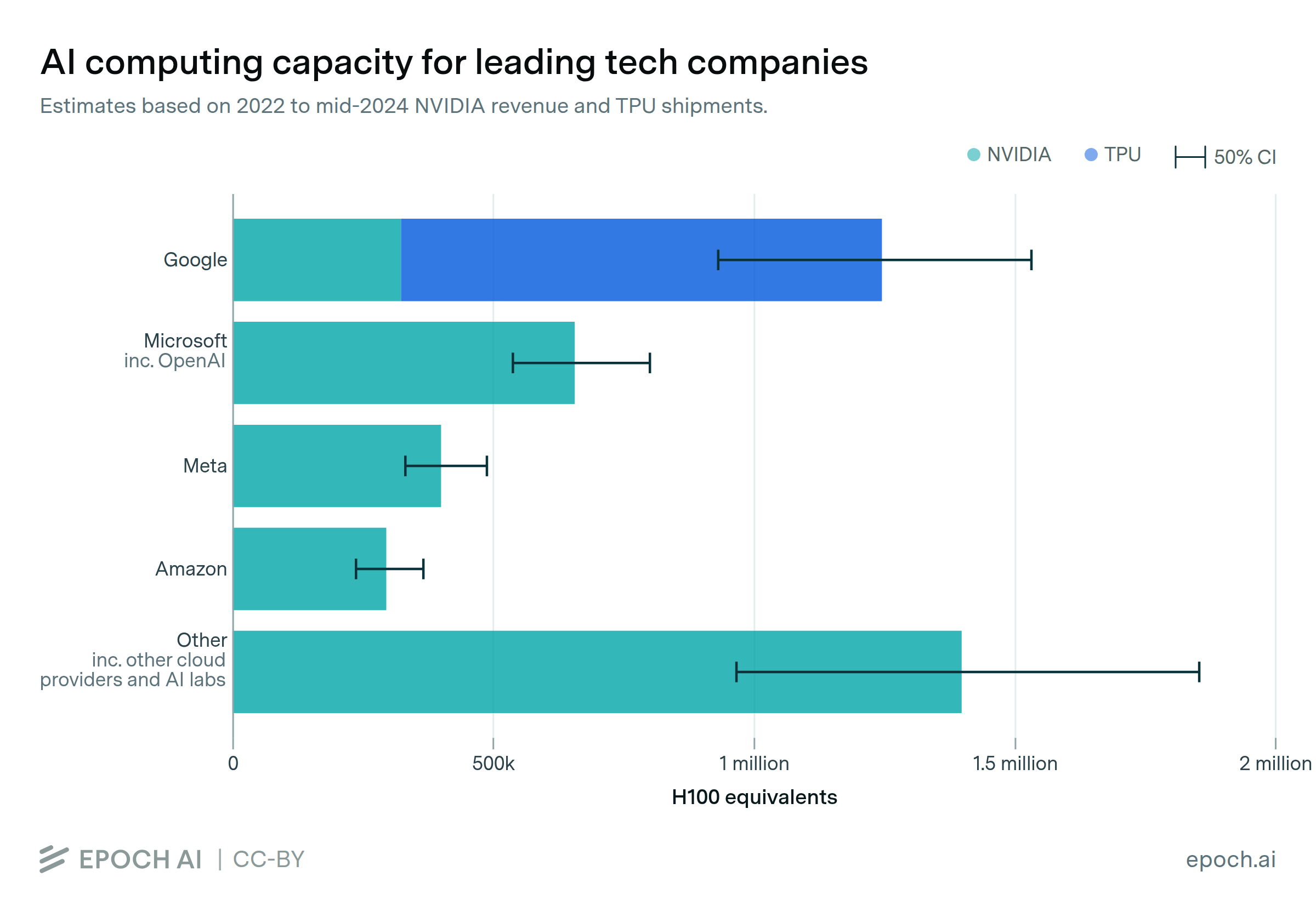
Five hyperscalers now own over two-thirds of global AI compute
By Luke Emberson, Josh You, and Venkat Somala
Data Insight
Apr. 7, 2026
Google controls the most AI computing power, driven by its custom TPUs
By Luke Emberson, Josh You, and Venkat Somala
Data Insight
Mar. 24, 2026
Total AI chip memory bandwidth has grown 4.1x per year, now reaching 70 million terabytes per second
By Luke Emberson
Data Insight
Mar. 12, 2026
Advanced packaging and HBM, not logic dies, were the bottlenecks on AI chip production in 2025
By Venkat Somala
Data Insight
Mar. 5, 2026
Microsoft’s recent $68 billion in physical assets additions were driven by AI-related purchases
By Isabel Juniewicz
Data Insight
Feb. 26, 2026
Hyperscaler capex has quadrupled since GPT-4's release
By Isabel Juniewicz
Data Insight
Feb. 19, 2026
Anthropic could surpass OpenAI in annualized revenue by mid-2026
By Luke Emberson and Yafah Edelman
Data Insight
Feb. 4, 2026
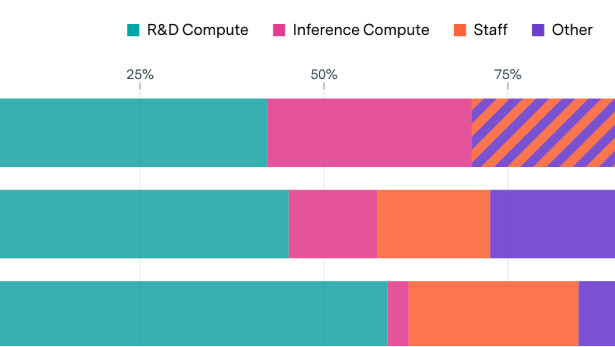
Compute accounts for the majority of expenses of AI companies
By Luke Emberson and Yafah Edelman
Data Insight
Jan. 23, 2026
Benchmark scores are well correlated, even across domains
By Luke Emberson and Yafah Edelman
Data Insight
Jan. 16, 2026
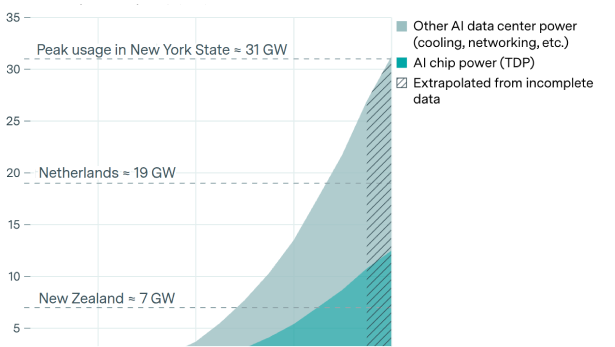
Global AI power capacity is now comparable to peak power usage of New York State
By Yafah Edelman, Josh You, Venkat Somala, and Luke Emberson
Data Insight
Jan. 9, 2026
Global AI computing capacity is doubling every 7 months
By Josh You, Venkat Somala, Yafah Edelman, and Luke Emberson
Data Insight
Jan. 2, 2026
Chinese AI models have lagged the US frontier by 7 months on average since 2023
By Luke Emberson
Data Insight
Dec. 23, 2025
AI capabilities progress has sped up
By Yafah Edelman and Jaeho Lee
Data Insight
Dec. 18, 2025
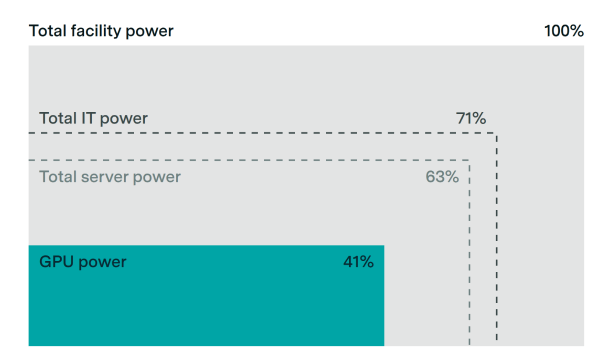
GPUs account for about 40% of power usage in AI data centers
By Luke Emberson and Ben Cottier
Data Insight
Dec. 10, 2025
NVIDIA’s B200 costs around $6,400 to produce, with memory accounting for half
By Venkat Somala
Data Insight
Dec. 4, 2025
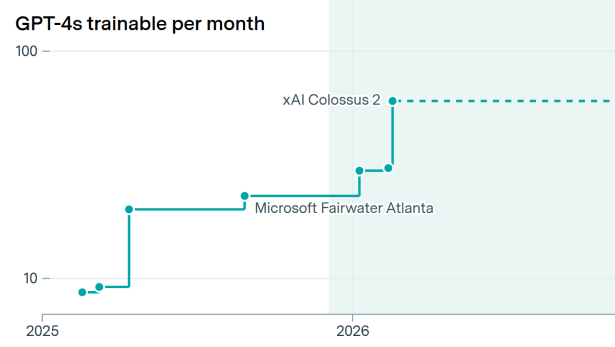
Today’s largest data center can do more than 20 GPT-4-scale training runs each month
By Jaeho Lee
Data Insight
Nov. 26, 2025
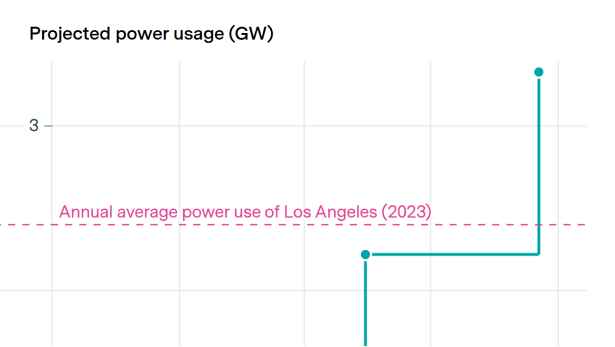
Microsoft’s Fairwater datacenter will use more power than Los Angeles
By Jaeho Lee
Data Insight
Nov. 19, 2025
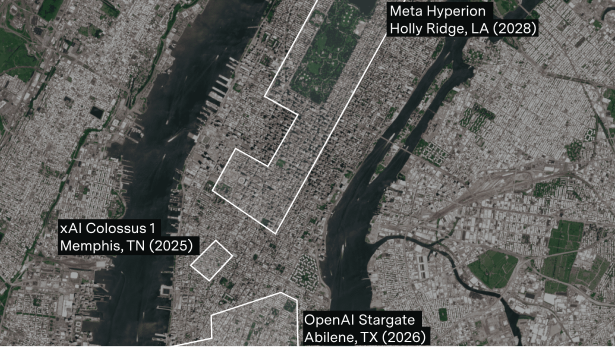
The largest AI data center campuses will soon be a fifth the size of Manhattan
By Ben Cottier
Data Insight
Nov. 10, 2025
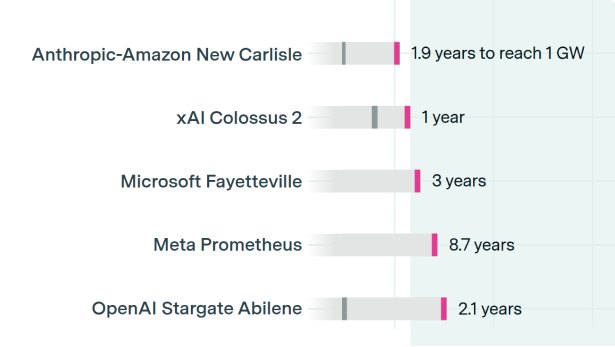
Build times for gigawatt-scale data centers can be 2 years or less
By Venkat Somala and Ben Cottier
Data Insight
Nov. 6, 2025
Epoch’s Capabilities Index stitches together benchmarks across a wide range of difficulties
By Jaeho Lee and Luke Emberson
Data Insight
Oct. 30, 2025
Open-weight models lag state-of-the-art by around 3 months on average
By Luke Emberson
Data Insight
Oct. 14, 2025
OpenAI's revenue has been growing 3x a year since 2024
By Venkat Somala
Data Insight
Oct. 10, 2025
Most of OpenAI’s 2024 compute went to experiments
By Josh You
Data Insight
Sep. 30, 2025
AI capabilities have steadily improved over the past year
By Luke Emberson
Data Insight
Sep. 19, 2025
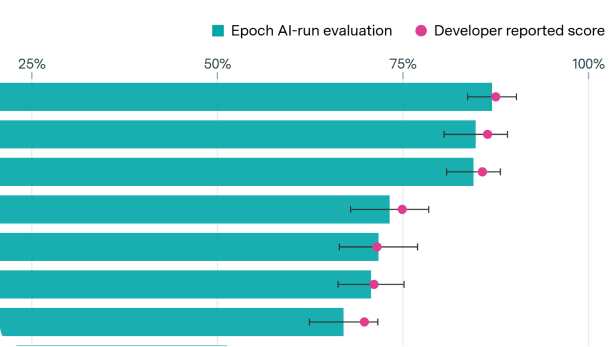
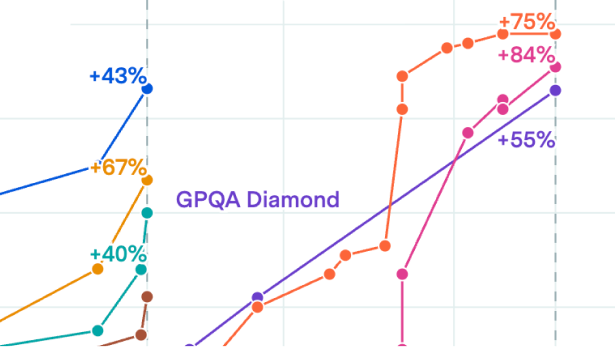
AI developers accurately report GPQA Diamond scores for recent models
By Jaeho Lee and Yafah Edelman
Data Insight
Sep. 12, 2025
What did it take to train Grok 4?
By James Sanders, Luke Emberson, and Yafah Edelman
Data Insight
Sep. 3, 2025
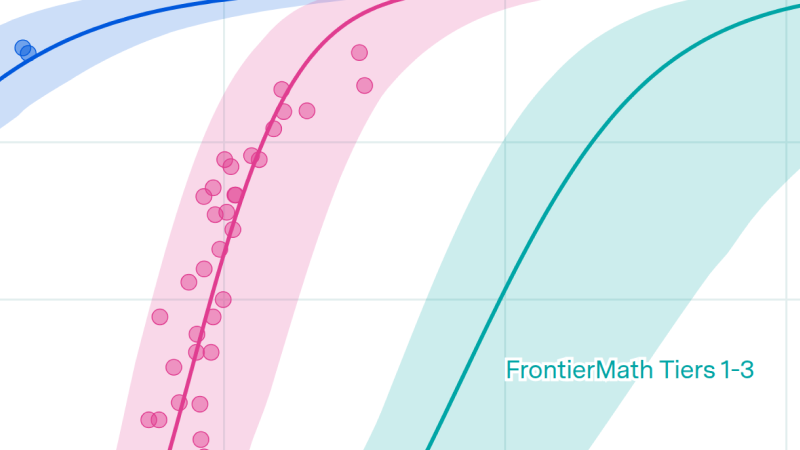
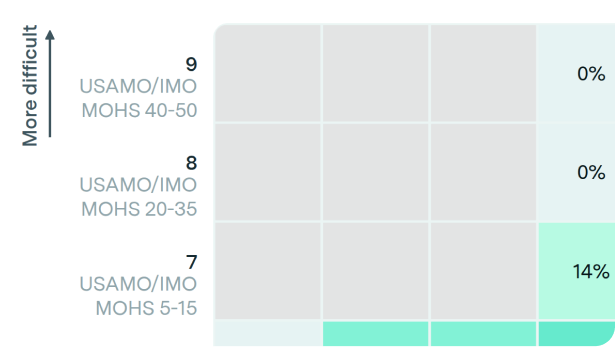
LLMs have not yet solved the hardest problems on high school math contests
By Greg Burnham
Data Insight
Aug. 29, 2025
GPT-5 and GPT-4 were both major leaps in benchmarks from the previous generation
By Luke Emberson and Josh You
Data Insight
Aug. 15, 2025
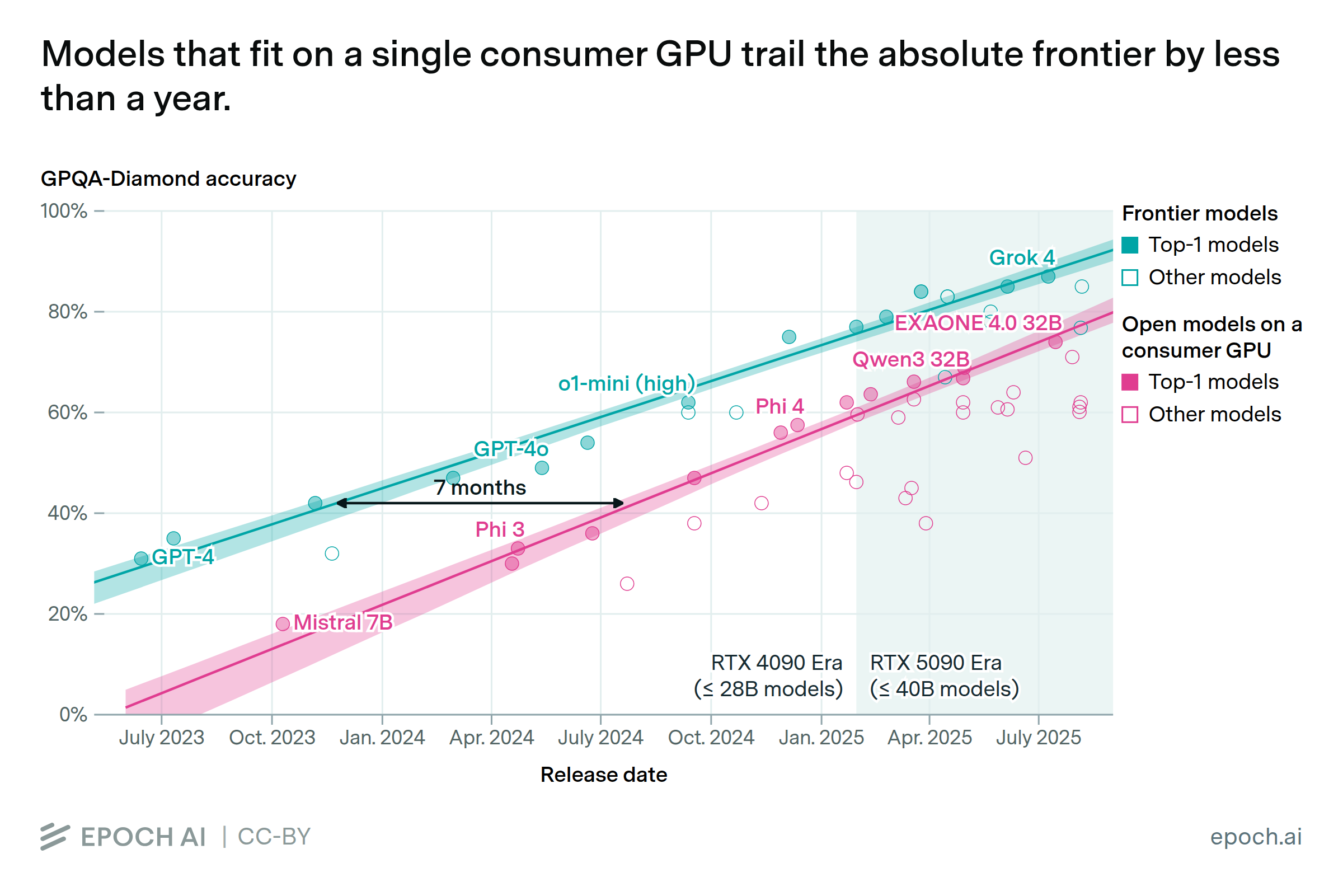
Frontier AI performance becomes accessible on consumer hardware within a year
By Venkat Somala and Luke Emberson
Data Insight
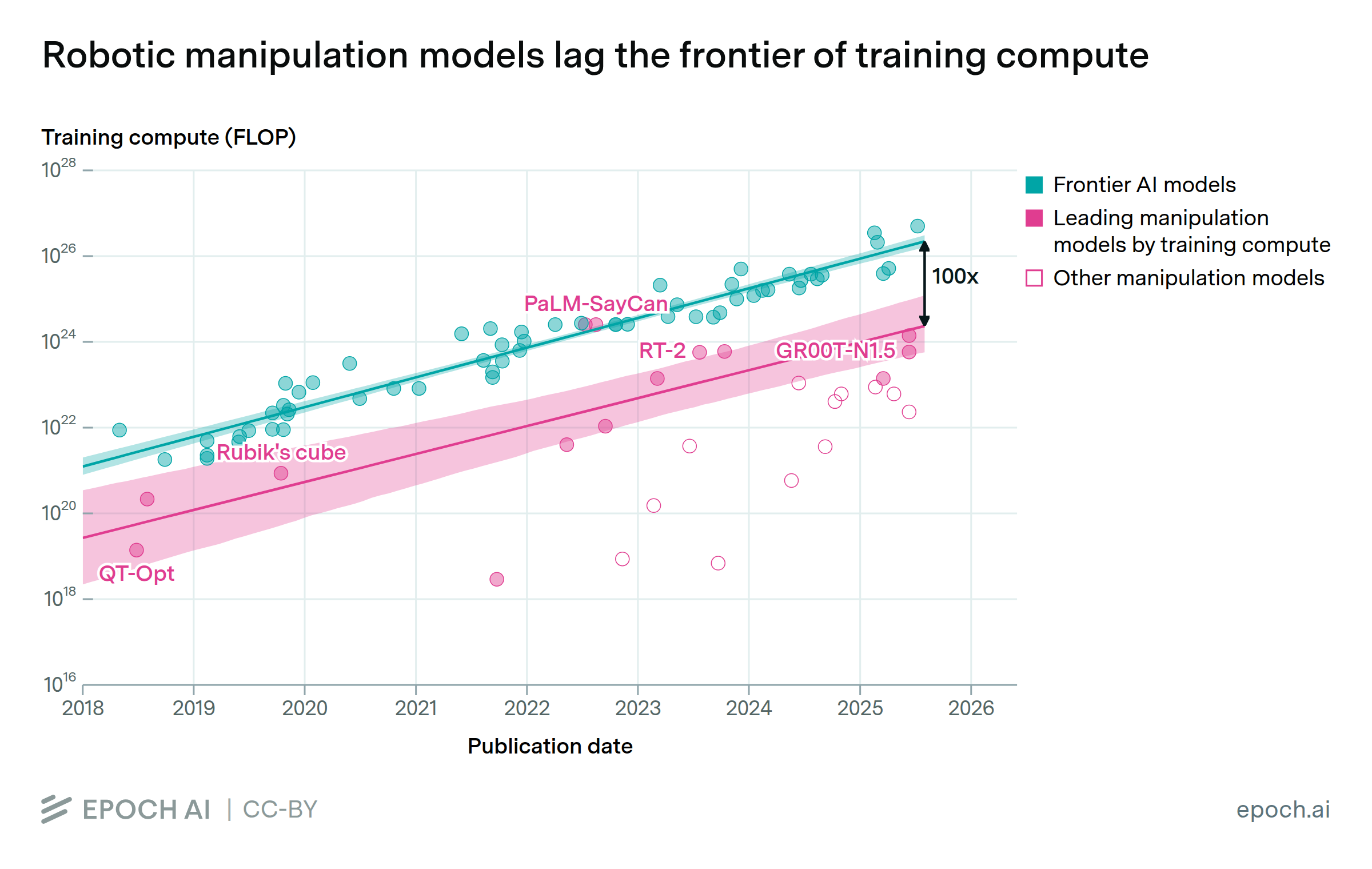
Aug. 8, 2025
Compute is not a bottleneck for robotic manipulation
By Ben Cottier, Scott Longwell, James Sanders, David Owen, Yafah Edelman, and Luke Emberson
Data Insight
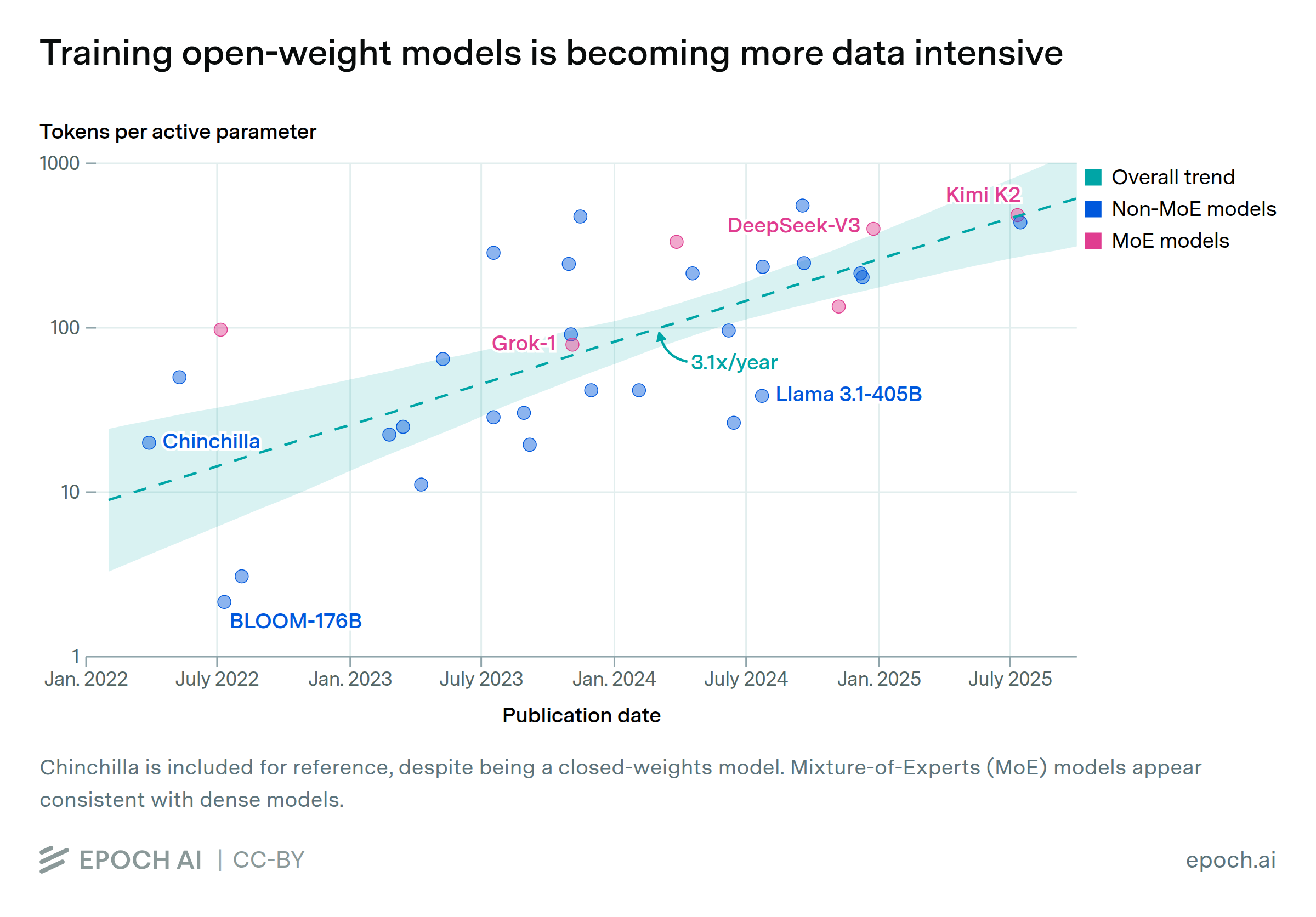
Aug. 1, 2025
Training open-weight models is becoming more data intensive
By Venkat Somala and Yafah Edelman
Data Insight
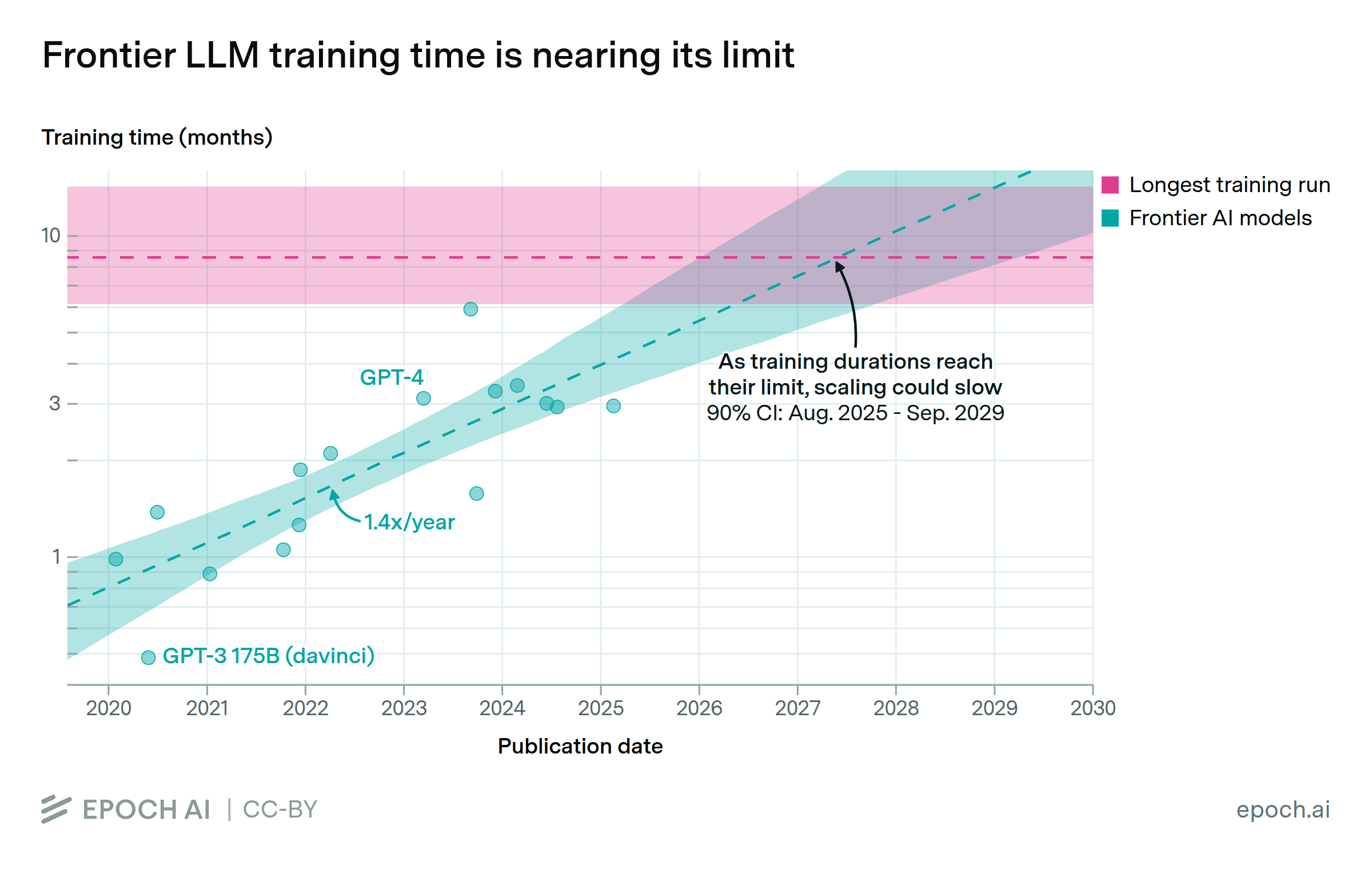
Jul. 25, 2025
Frontier training runs will likely stop getting longer by around 2027
By Luke Emberson and Yafah Edelman
Data Insight
Jun. 25, 2025
LLMs now accept longer inputs, and the best models can use them more effectively
By Greg Burnham and Tom Adamczewski
Data Insight
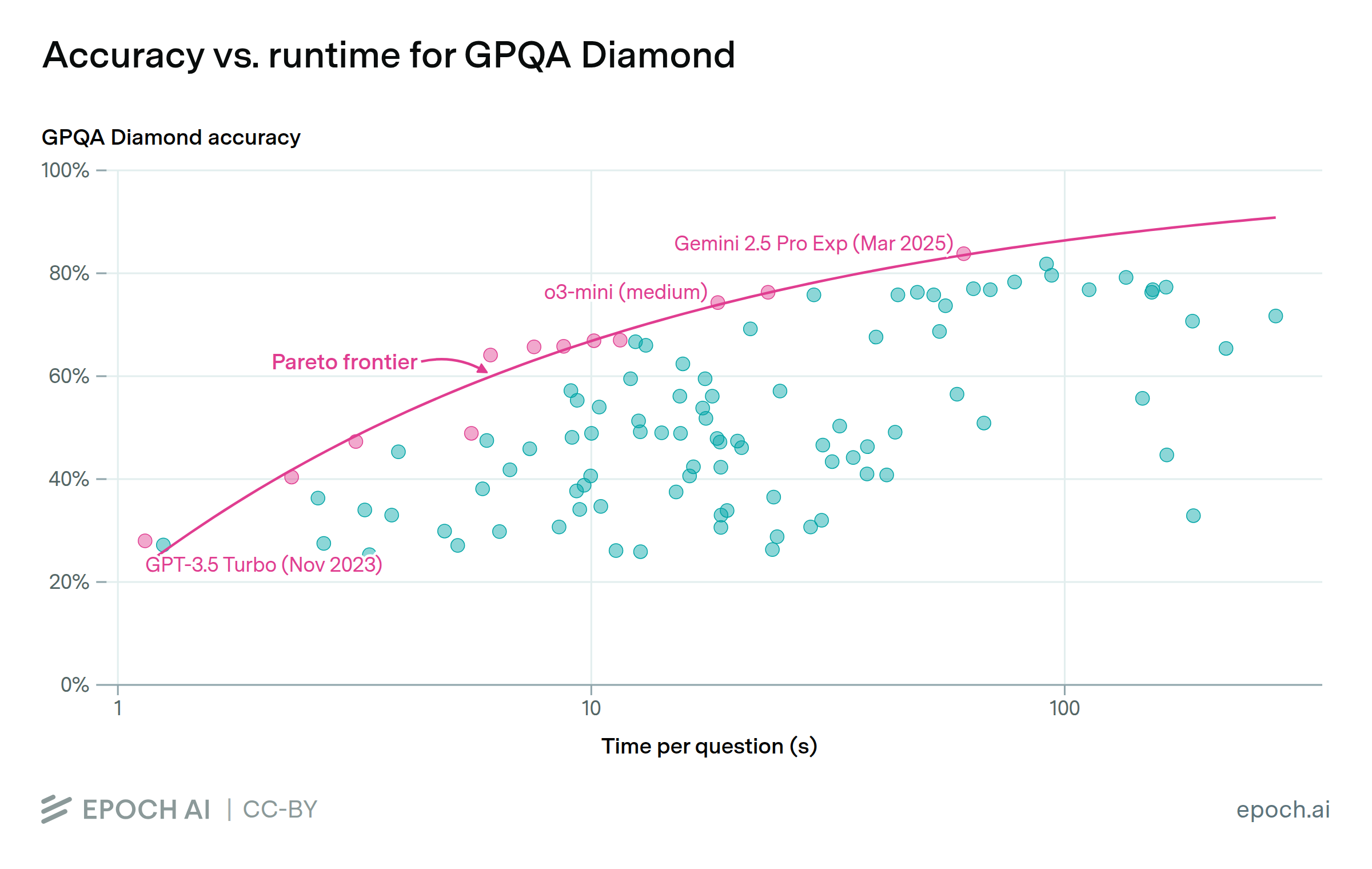
Jun. 11, 2025
LLM providers offer a trade-off between accuracy and speed
By Greg Burnham and Tom Adamczewski
Data Insight
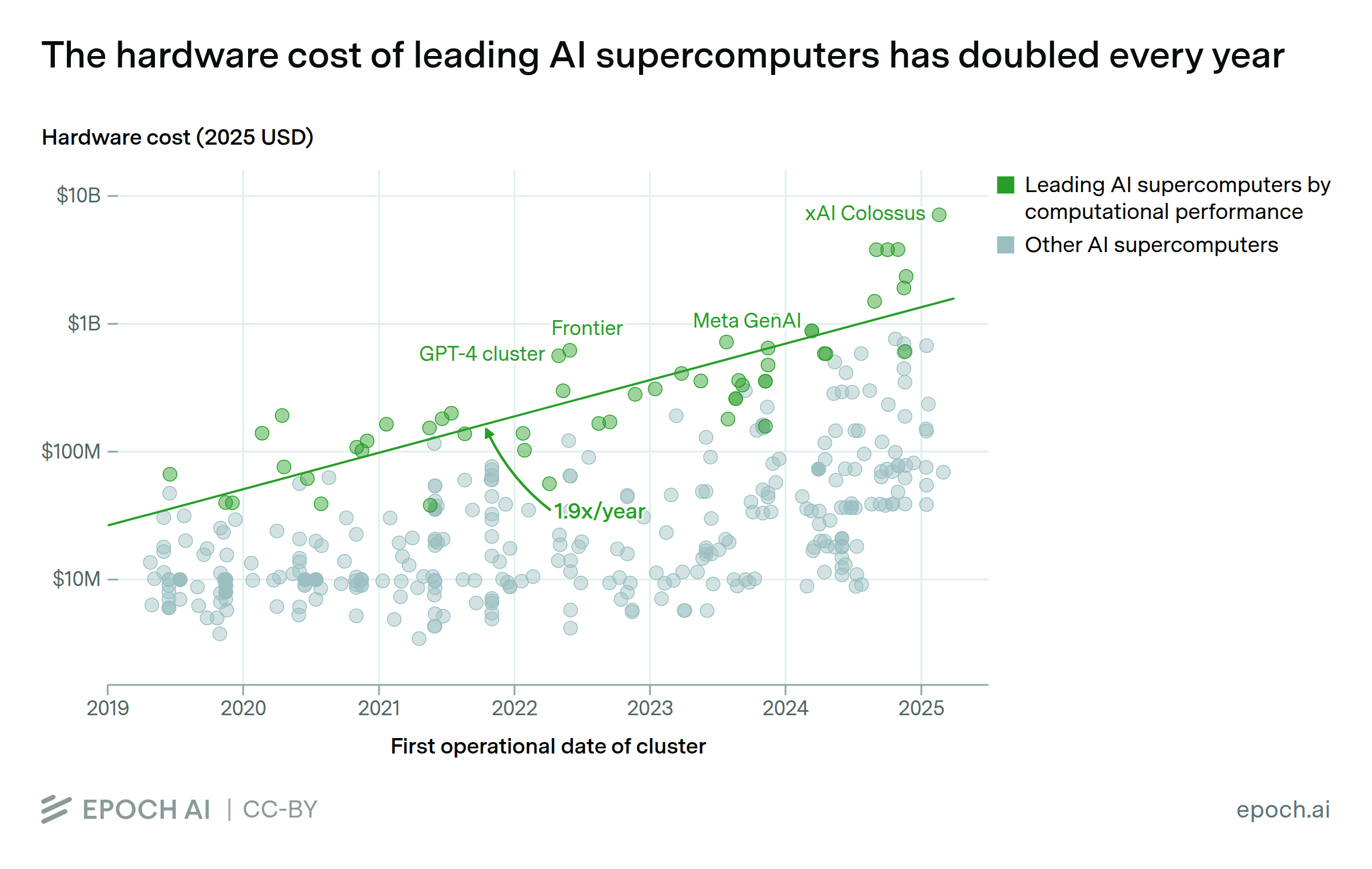
Jun. 5, 2025
Acquisition costs of leading AI supercomputers have doubled every 13 months
By Konstantin F. Pilz, Robi Rahman, James Sanders, Luke Emberson, and Lennart Heim
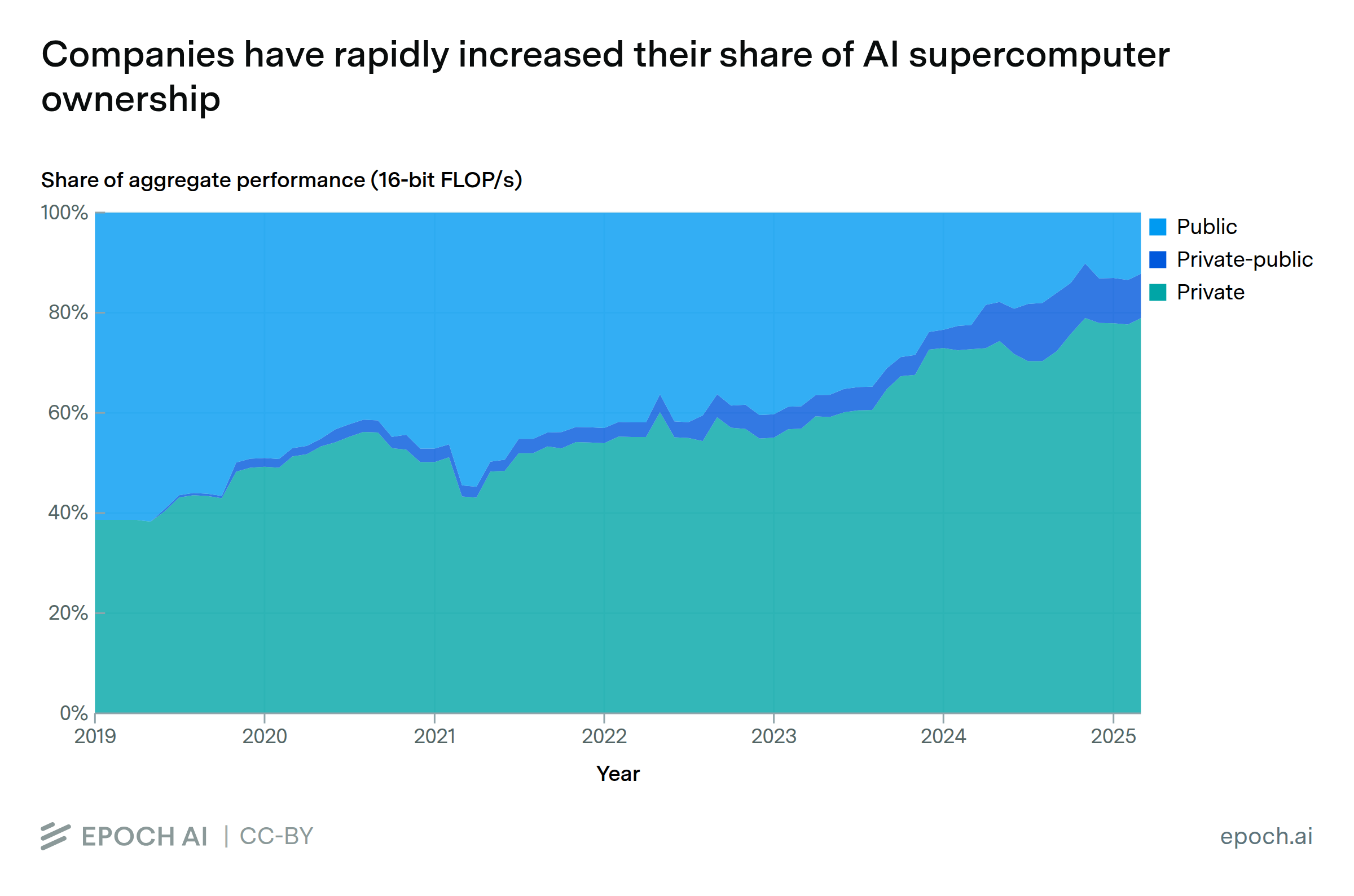
Data Insight
Jun. 5, 2025
Private-sector companies own a dominant share of GPU clusters
By Konstantin F. Pilz, Robi Rahman, James Sanders, Luke Emberson, and Lennart Heim
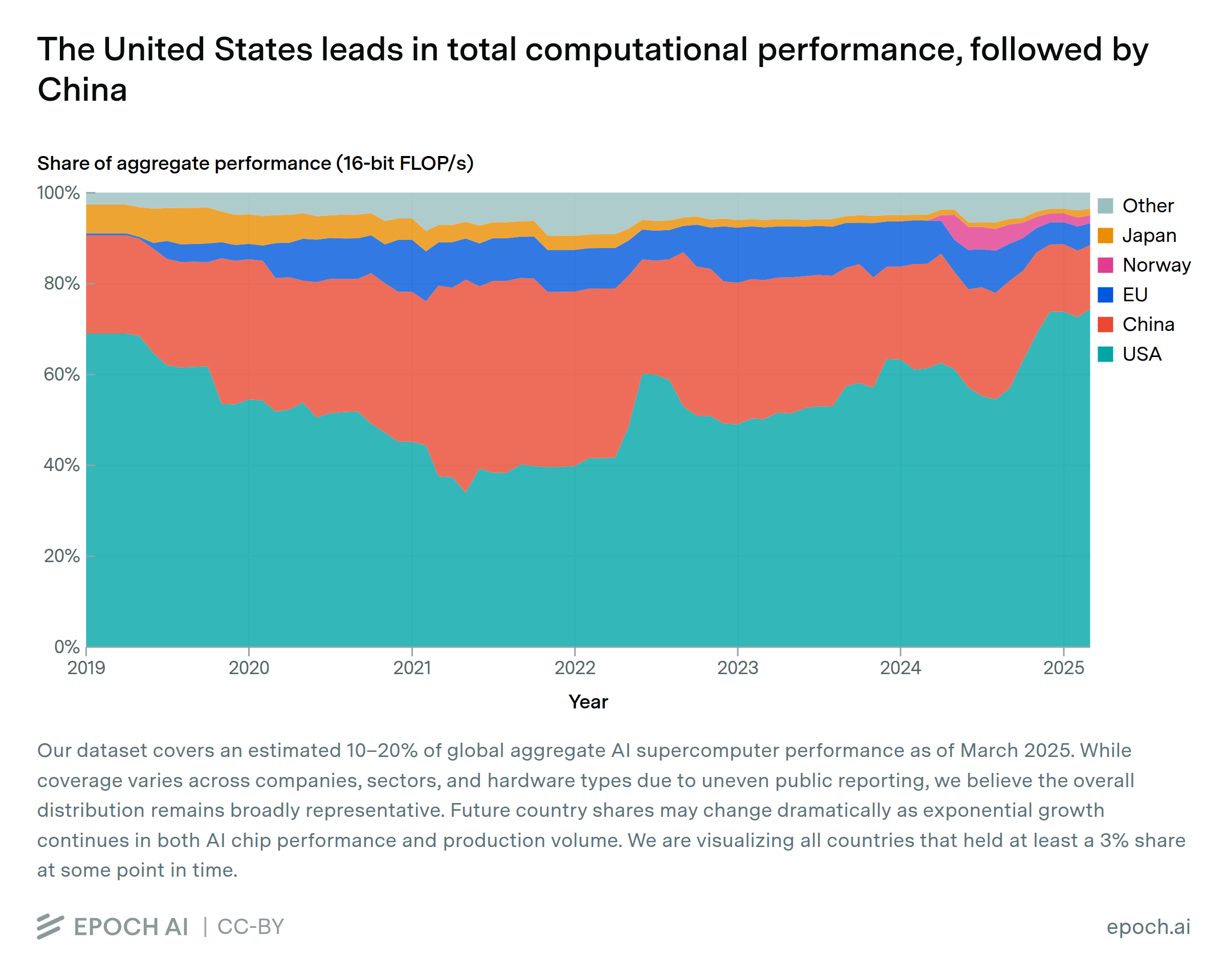
Data Insight
Jun. 5, 2025
The US hosts the majority of GPU cluster performance, followed by China
By Konstantin F. Pilz, Robi Rahman, James Sanders, Luke Emberson, and Lennart Heim
Data Insight
Jun. 5, 2025
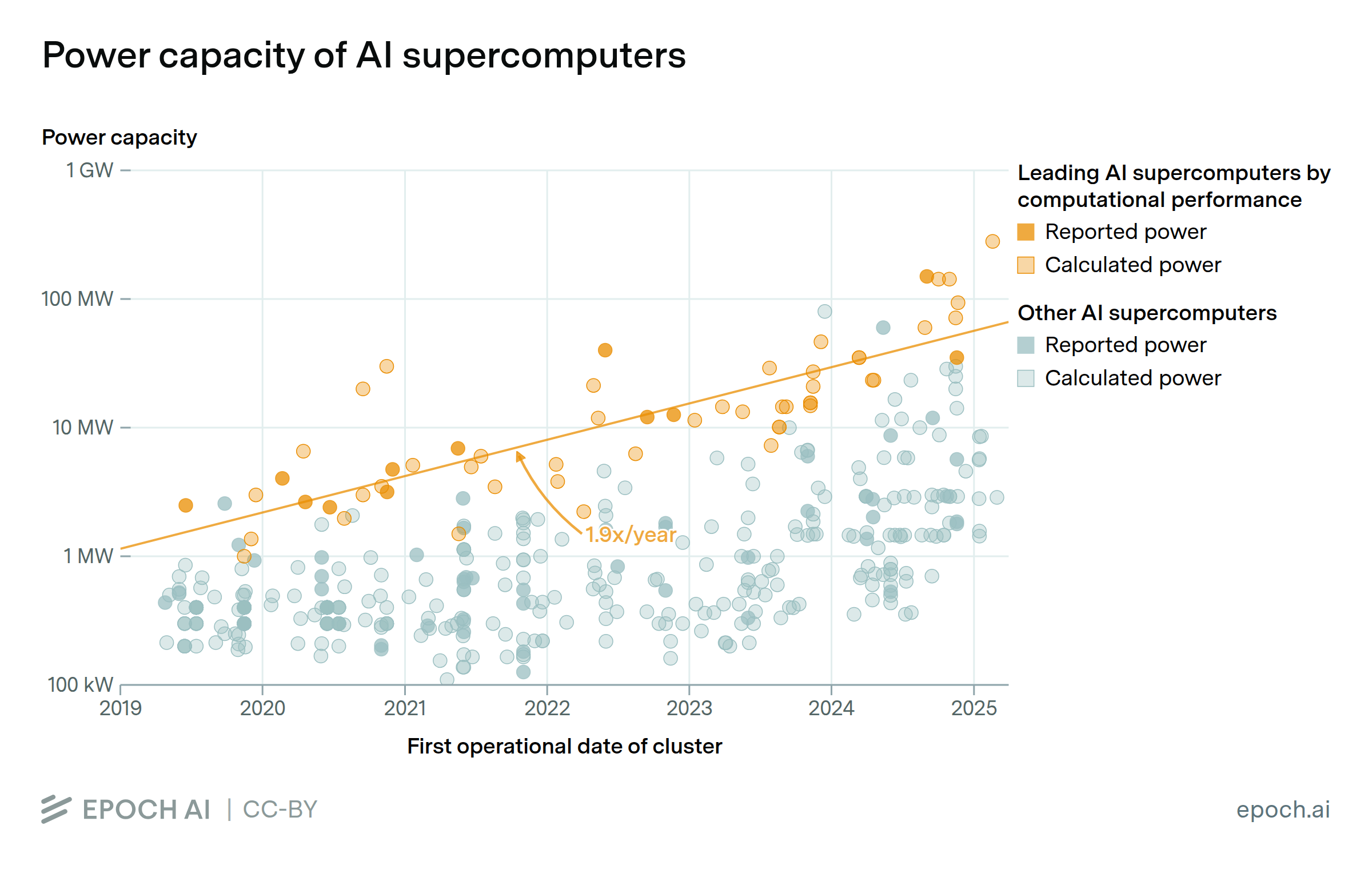
Power requirements of leading AI supercomputers have doubled every 13 months
By Konstantin F. Pilz, Robi Rahman, James Sanders, Luke Emberson, and Lennart Heim
Data Insight
May 28, 2025
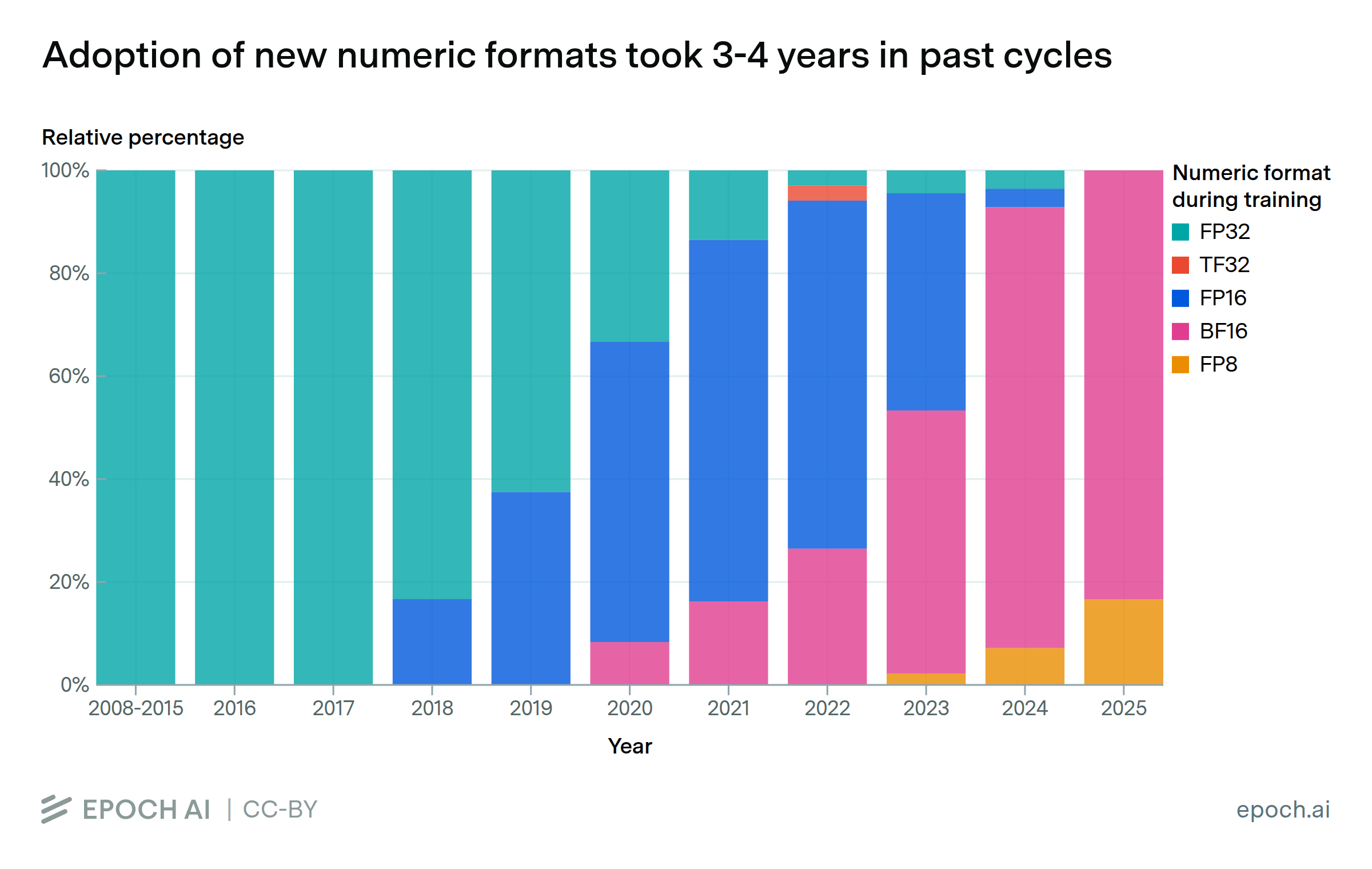
Widespread adoption of new numeric formats took 3-4 years in past cycles
By Venkat Somala and Luke Emberson
Data Insight
Updated Jun. 5, 2025
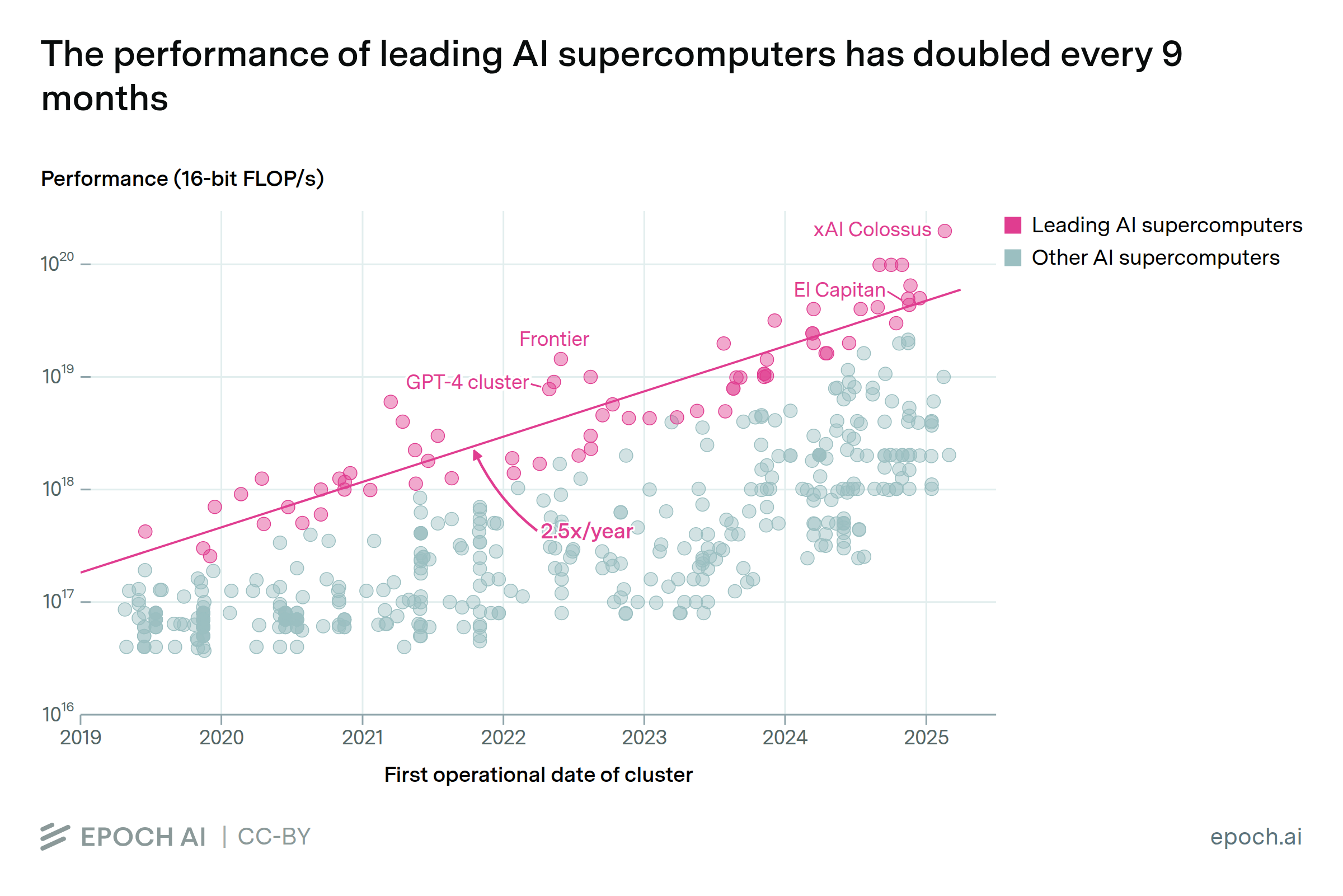
The computational performance of leading AI supercomputers has doubled every nine months
By Konstantin F. Pilz, Robi Rahman, James Sanders, Luke Emberson, and Lennart Heim
Data Insight
Apr. 17, 2025
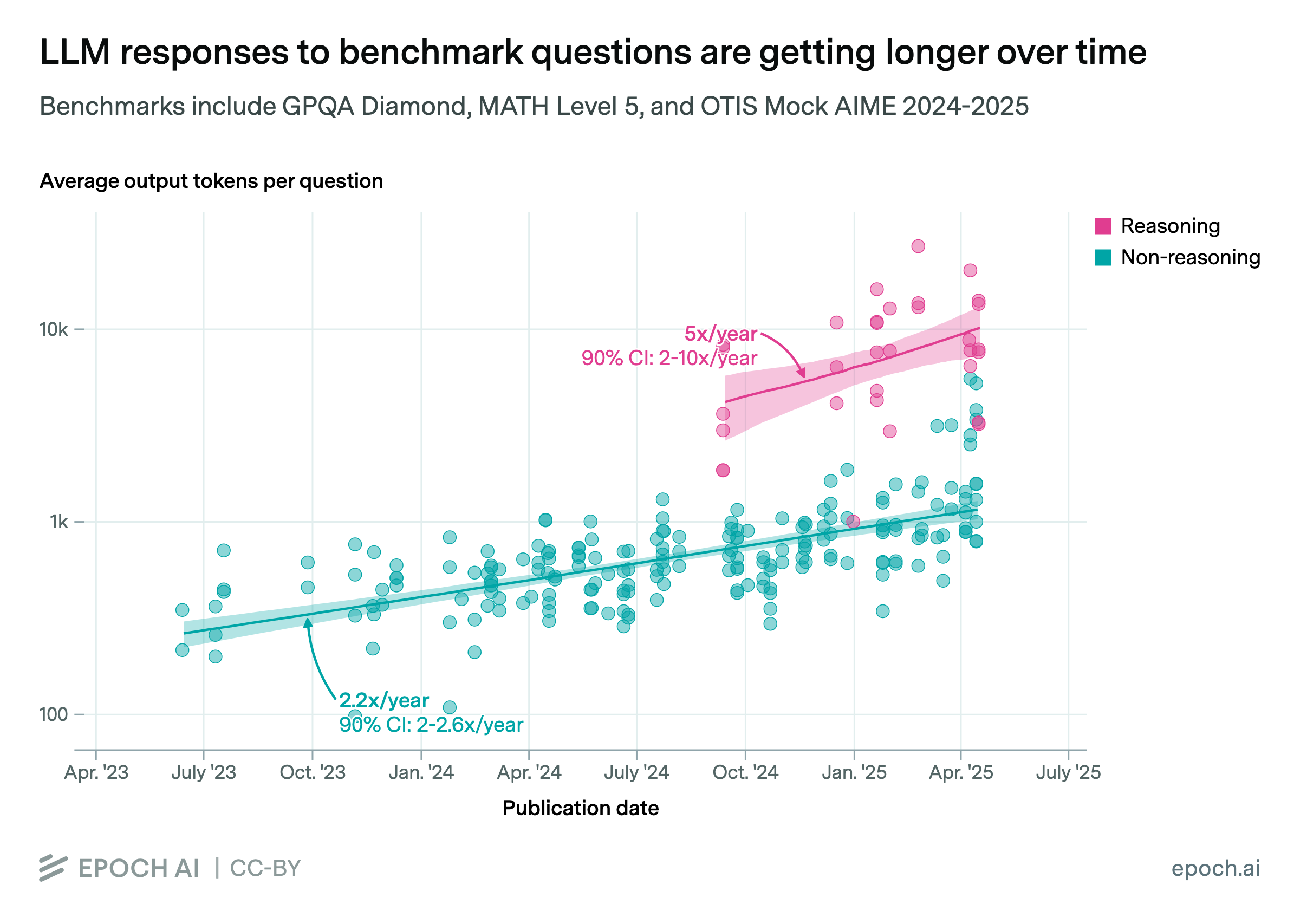
LLM responses to benchmark questions are getting longer over time
By Luke Emberson, Ben Cottier, Josh You, Tom Adamczewski, and Jean-Stanislas Denain
Data Insight
Apr. 3, 2025
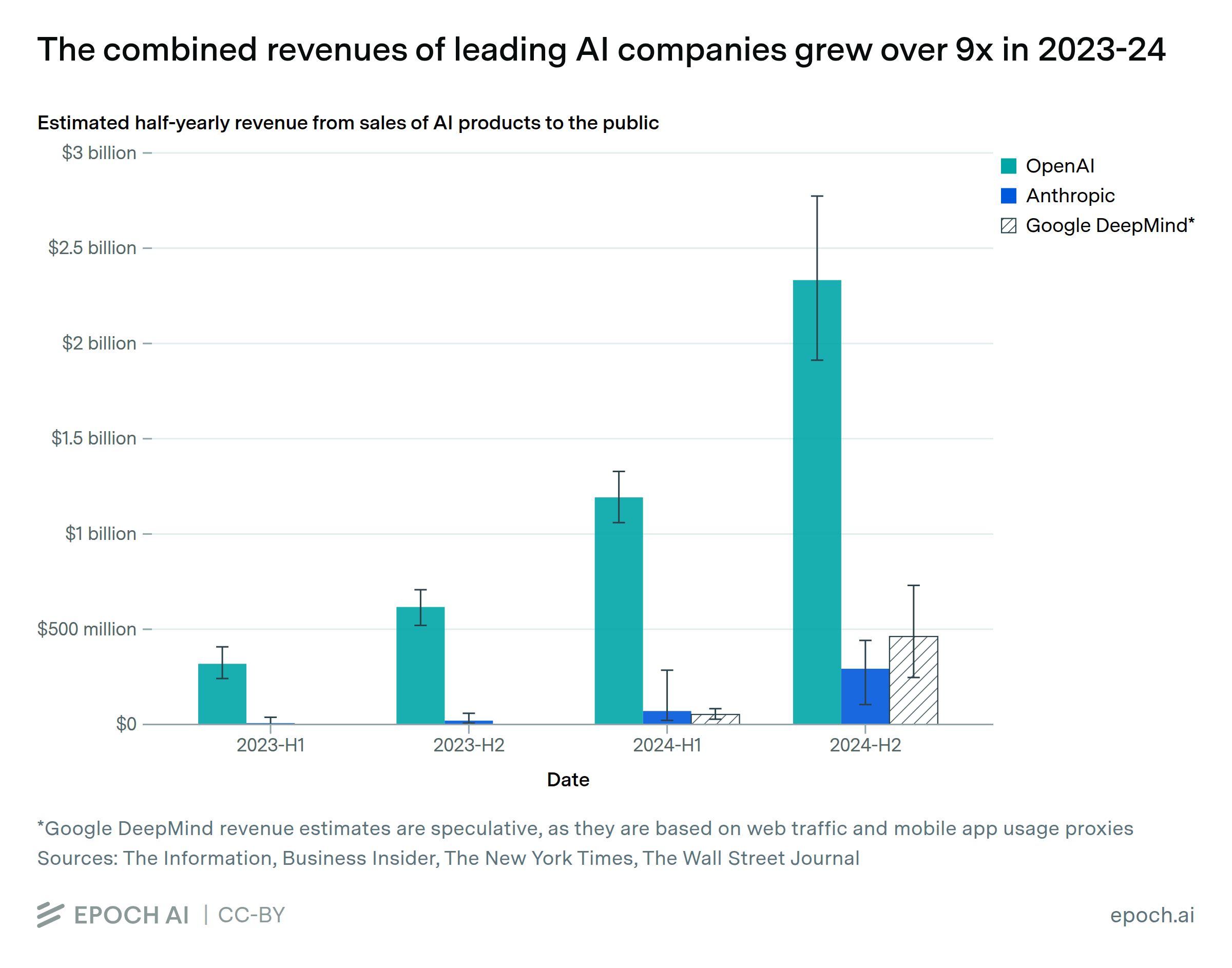
The combined revenues of leading AI companies grew by over 9x in 2023-2024
By Ben Snodin, David Owen, and Luke Emberson
Data Insight
Mar. 12, 2025
LLM inference prices have fallen rapidly but unequally across tasks
By Ben Cottier, Ben Snodin, David Owen, and Tom Adamczewski
Data Insight
Mar. 5, 2025
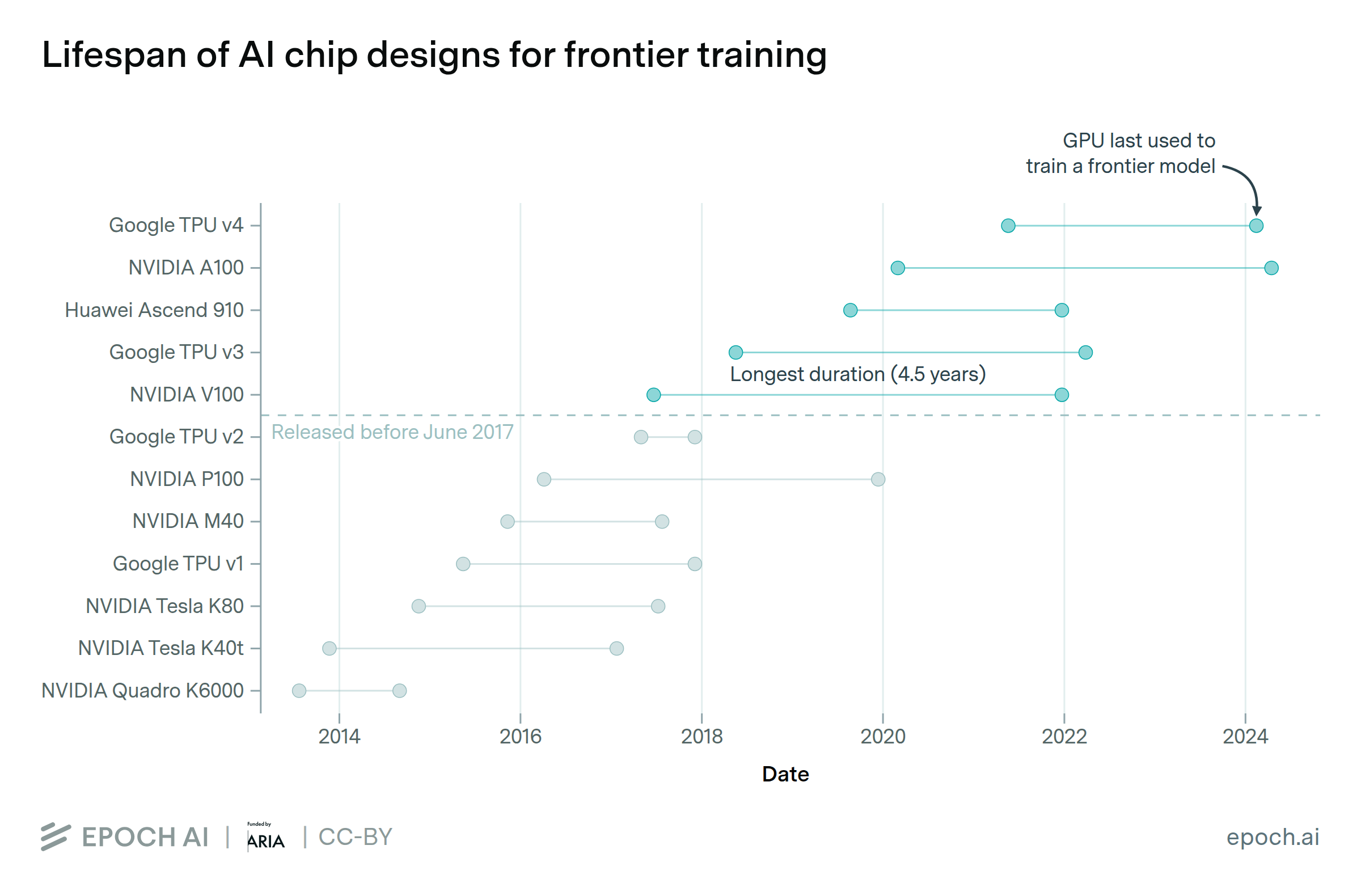
Leading AI chip designs are used for around four years in frontier training
By Luke Emberson, Ben Snodin, and David Owen
Data Insight
Feb. 21, 2025
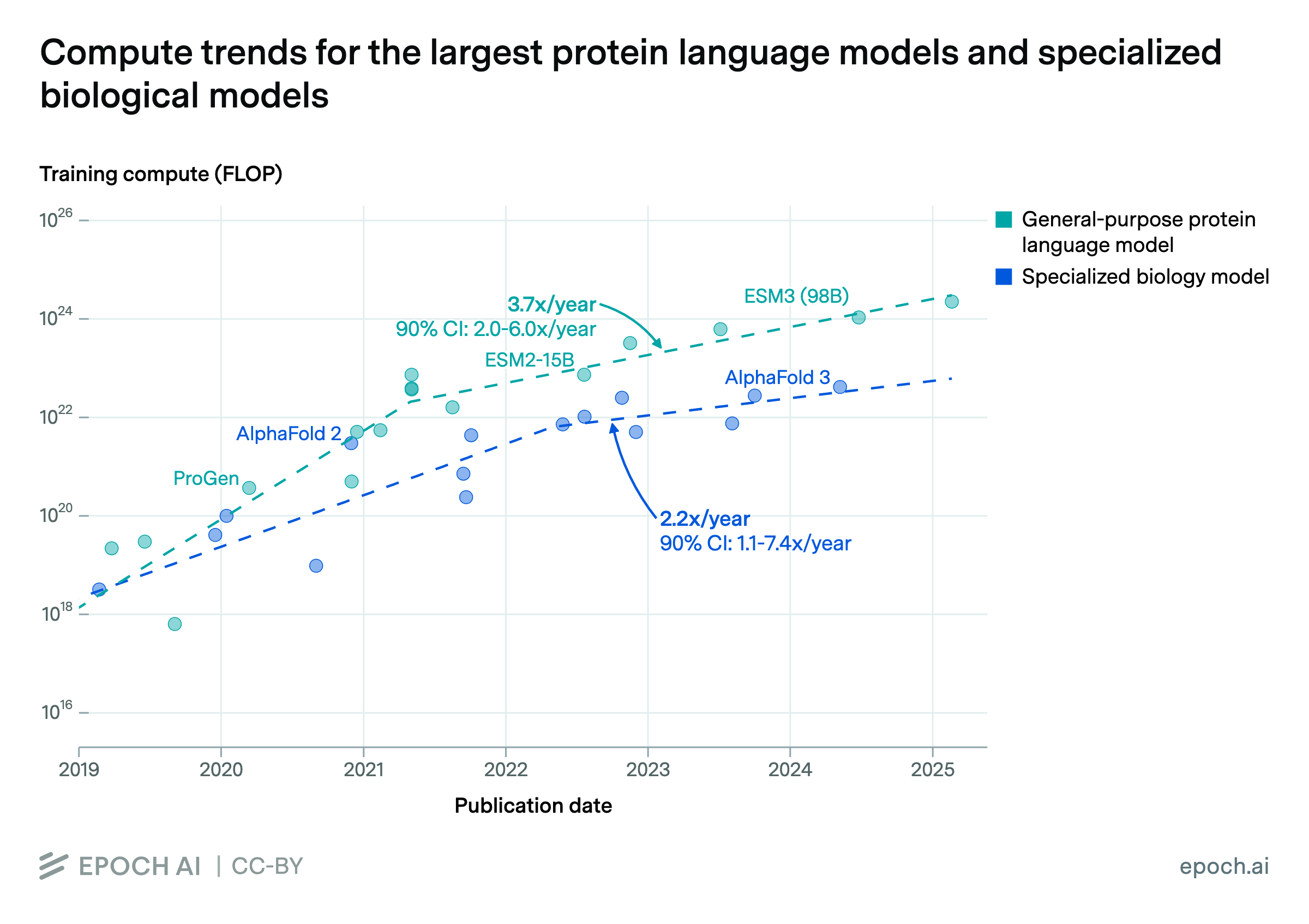
Biology AI models are scaling 2-4x per year after rapid growth from 2019-2021
By Pablo Villalobos and David Atanasov
Data Insight
Feb. 13, 2025
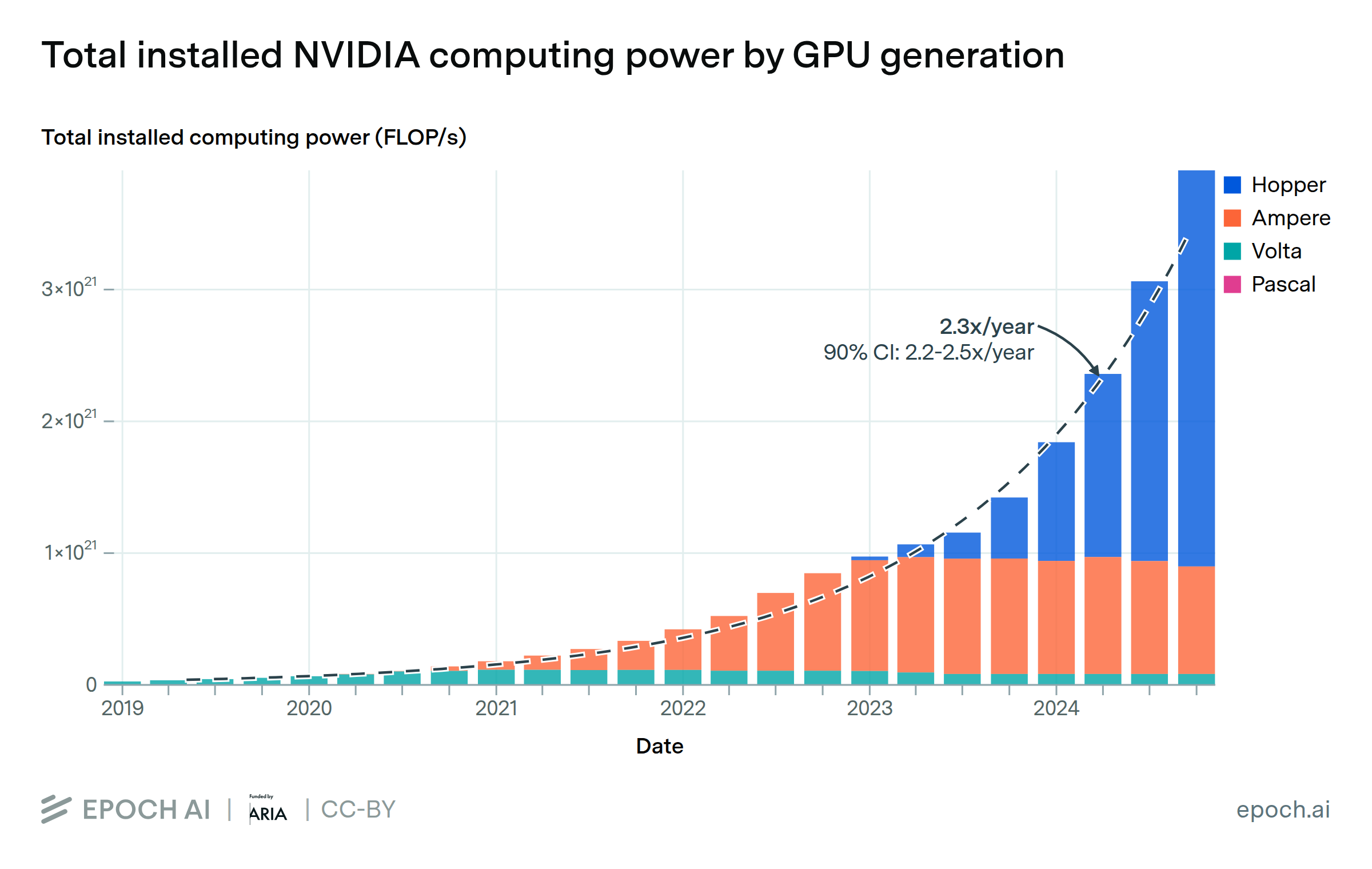
The stock of computing power from NVIDIA chips is doubling every 10 months
By Luke Emberson and David Owen
Data Insight
Updated Jun. 6, 2025
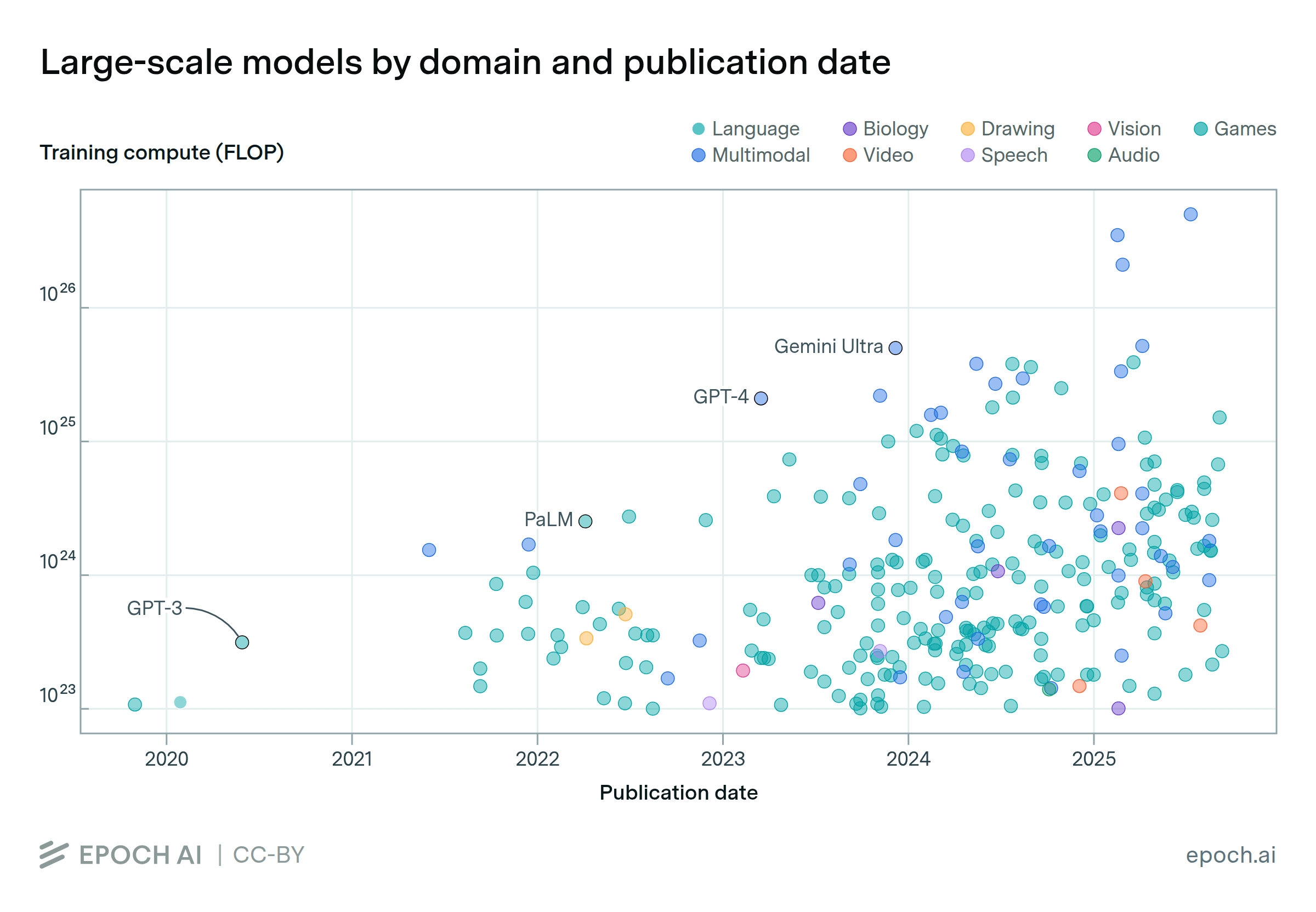
Over 30 AI models have been trained at the scale of GPT-4
By Robi Rahman, Lovis Heindrich, David Owen, and Luke Emberson
Data Insight
Jan. 22, 2025
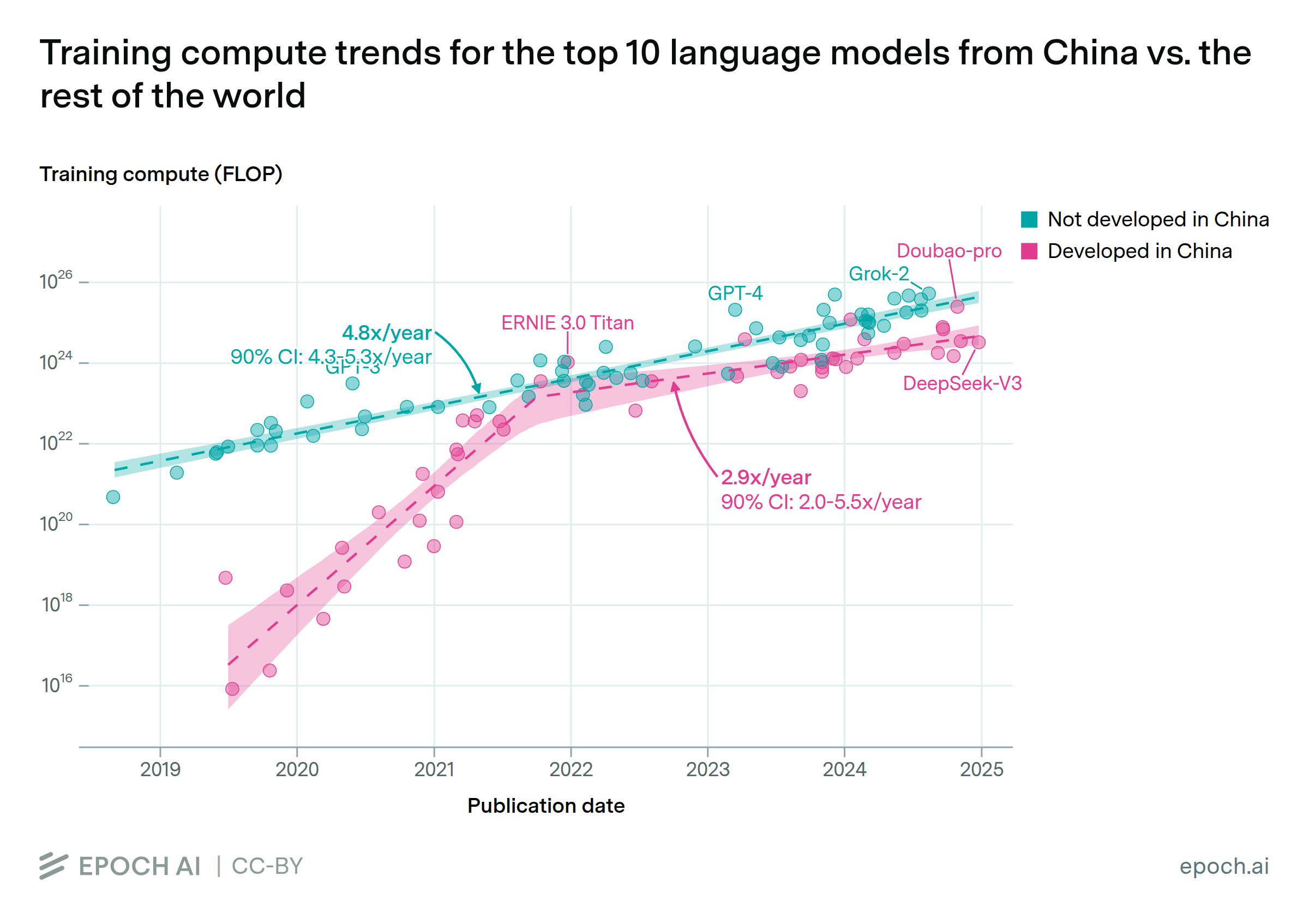
Chinese language models have scaled up more slowly than their global counterparts
By Ben Cottier
Data Insight
Jan. 15, 2025
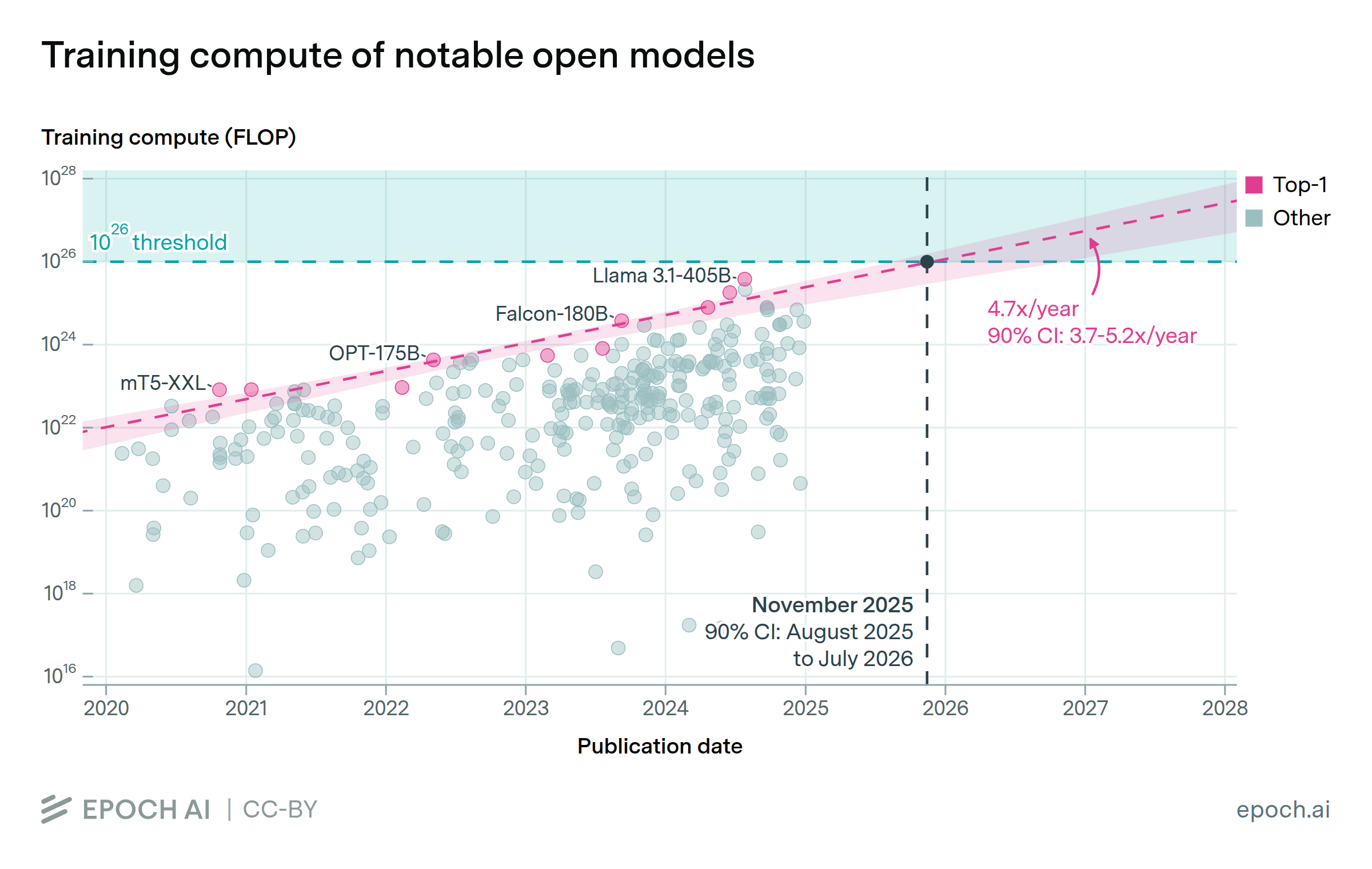
Frontier open models may surpass 1e26 FLOP of training compute before 2026
By Luke Emberson
Data Insight
Jan. 8, 2025
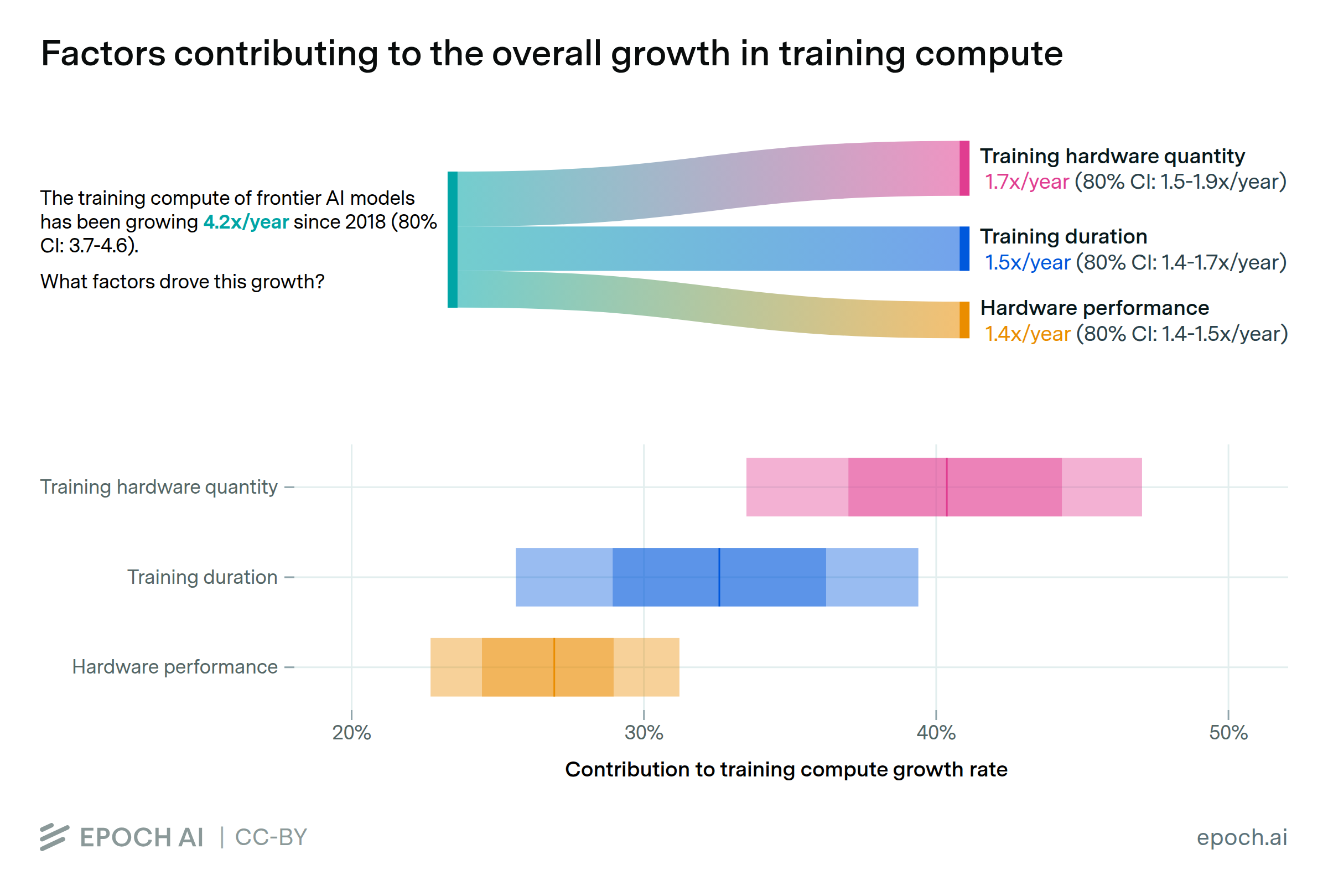
Training compute growth is driven by larger clusters, longer training, and better hardware
By Luke Emberson and David Owen
Data Insight
Updated Feb. 7, 2025
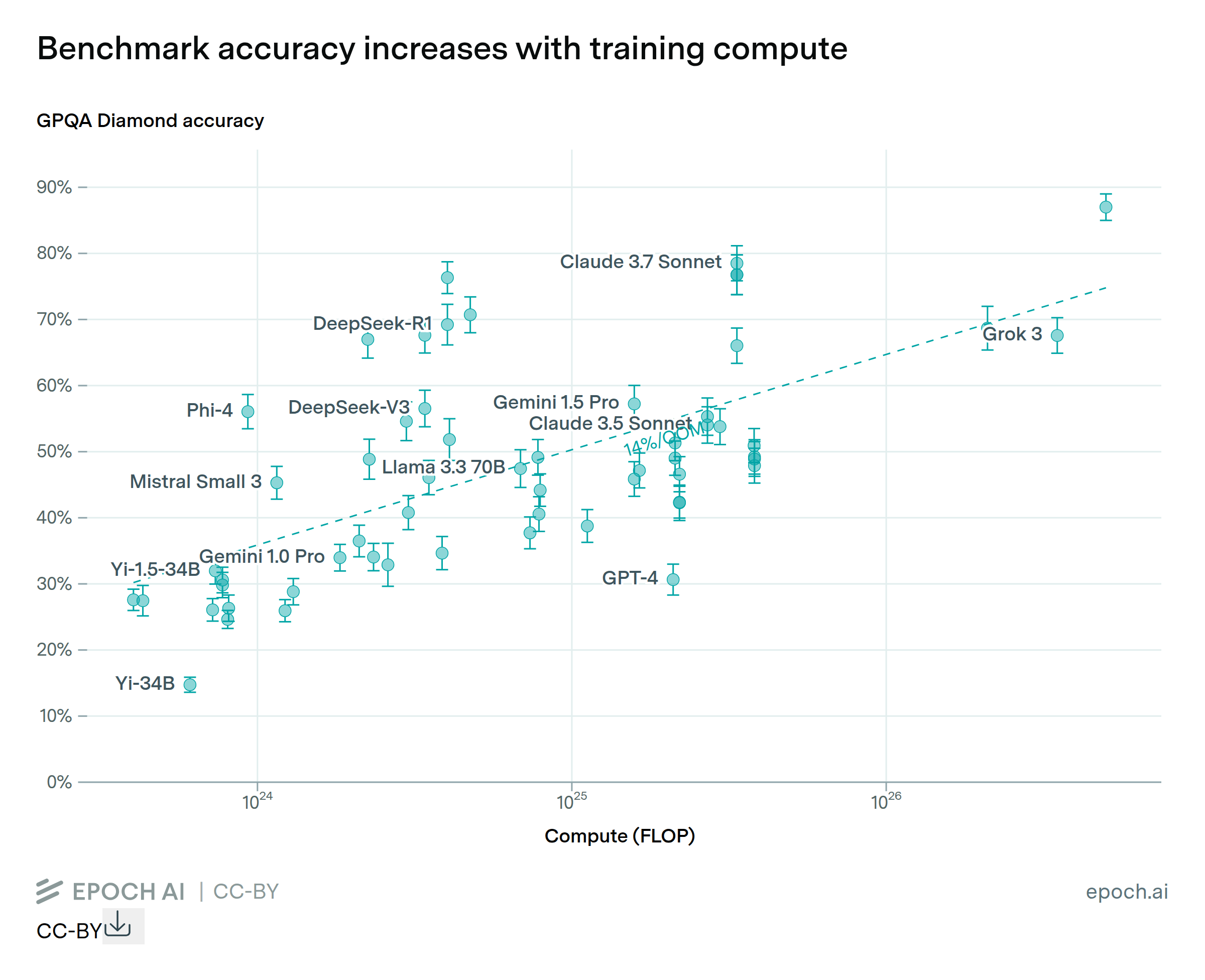
Accuracy increases with estimated training compute
By Jean-Stanislas Denain
Data Insight
Updated Feb. 7, 2025
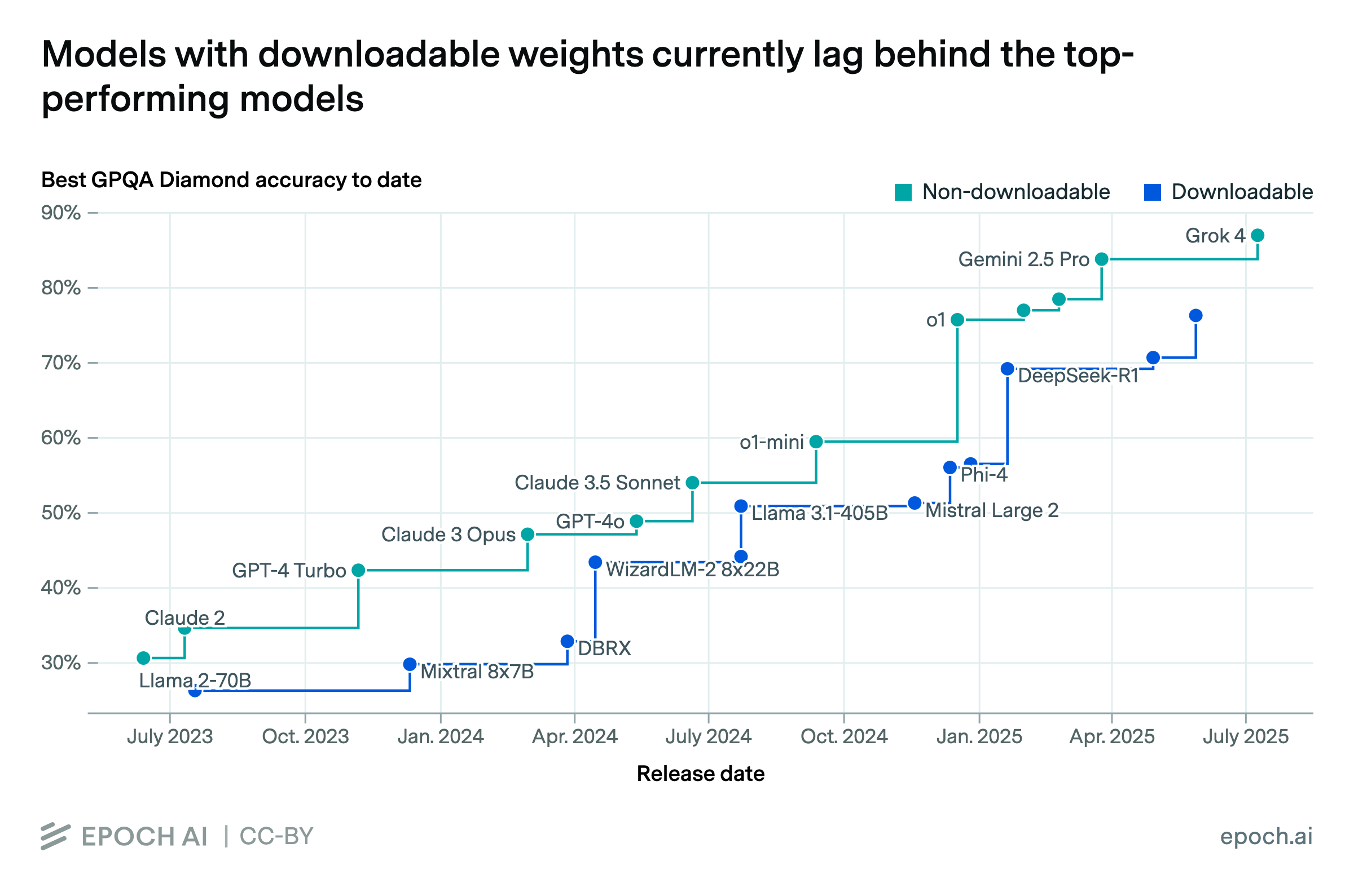
Models with downloadable weights currently lag behind the top-performing models
By Jean-Stanislas Denain
Data Insight
Updated Feb. 7, 2025
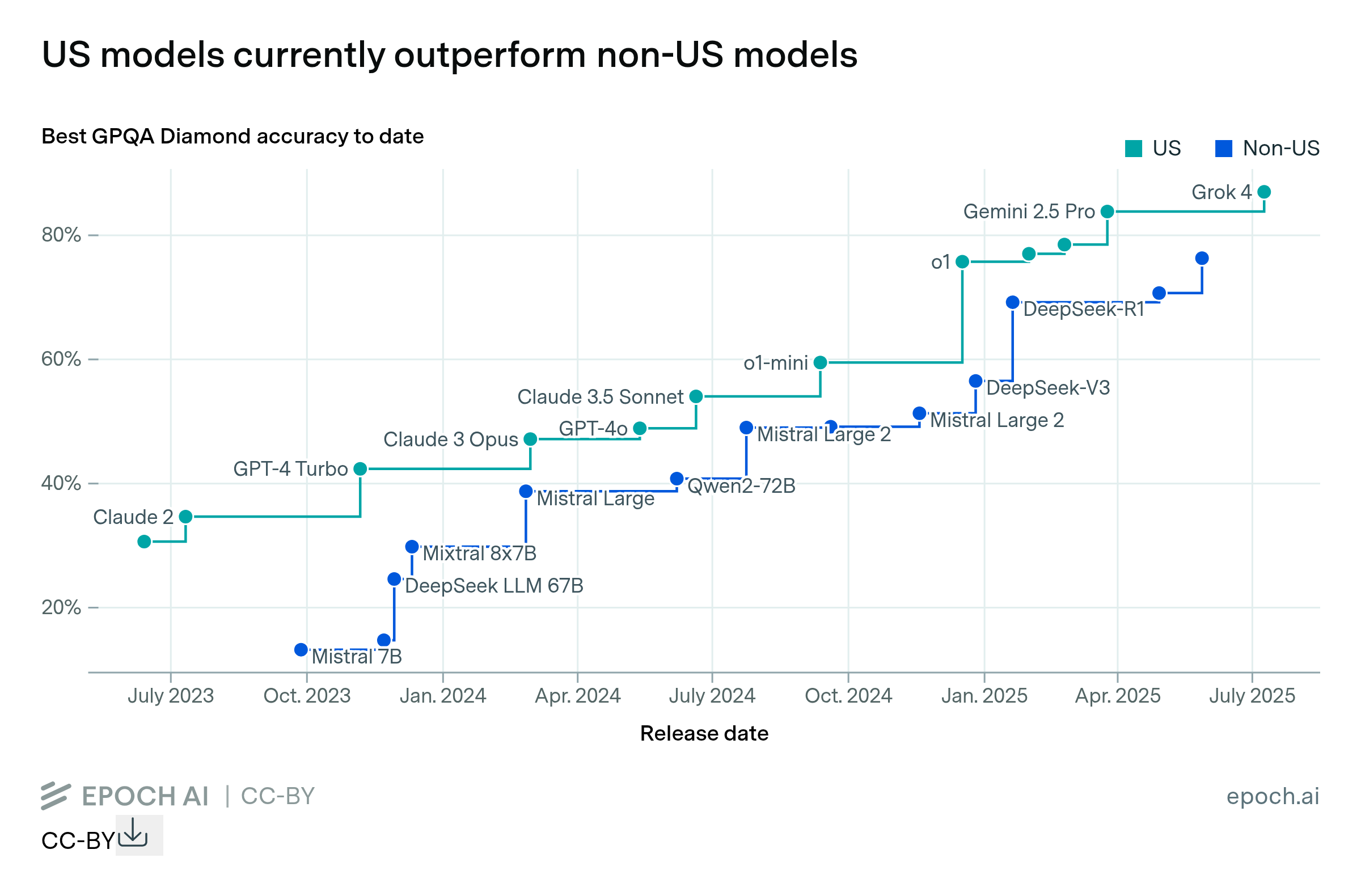
US models currently outperform non-US models
By Jean-Stanislas Denain
Data Insight
Oct. 23, 2024
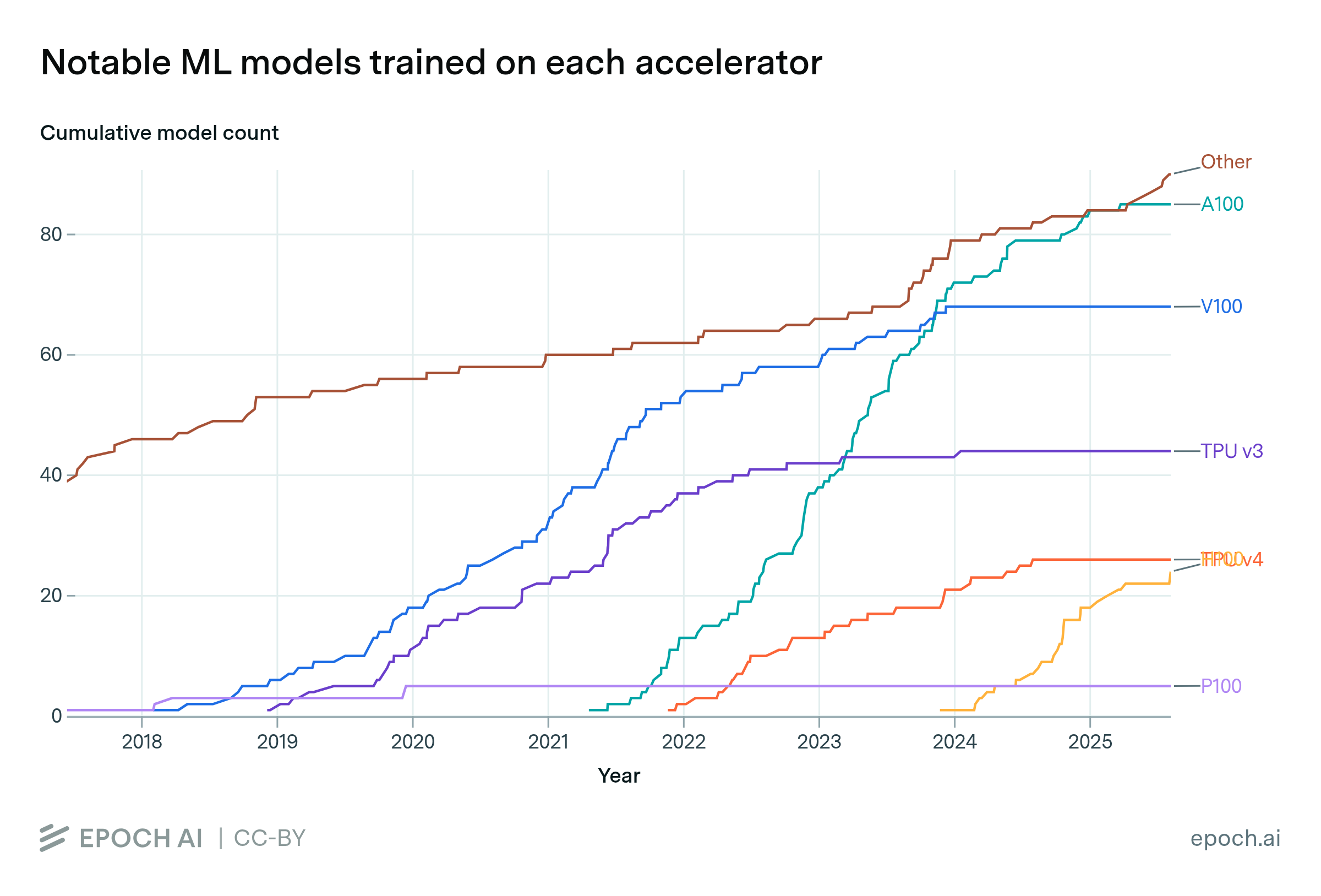
The NVIDIA A100 has been the most popular hardware for training notable machine learning models
By Robi Rahman
Data Insight
Oct. 23, 2024
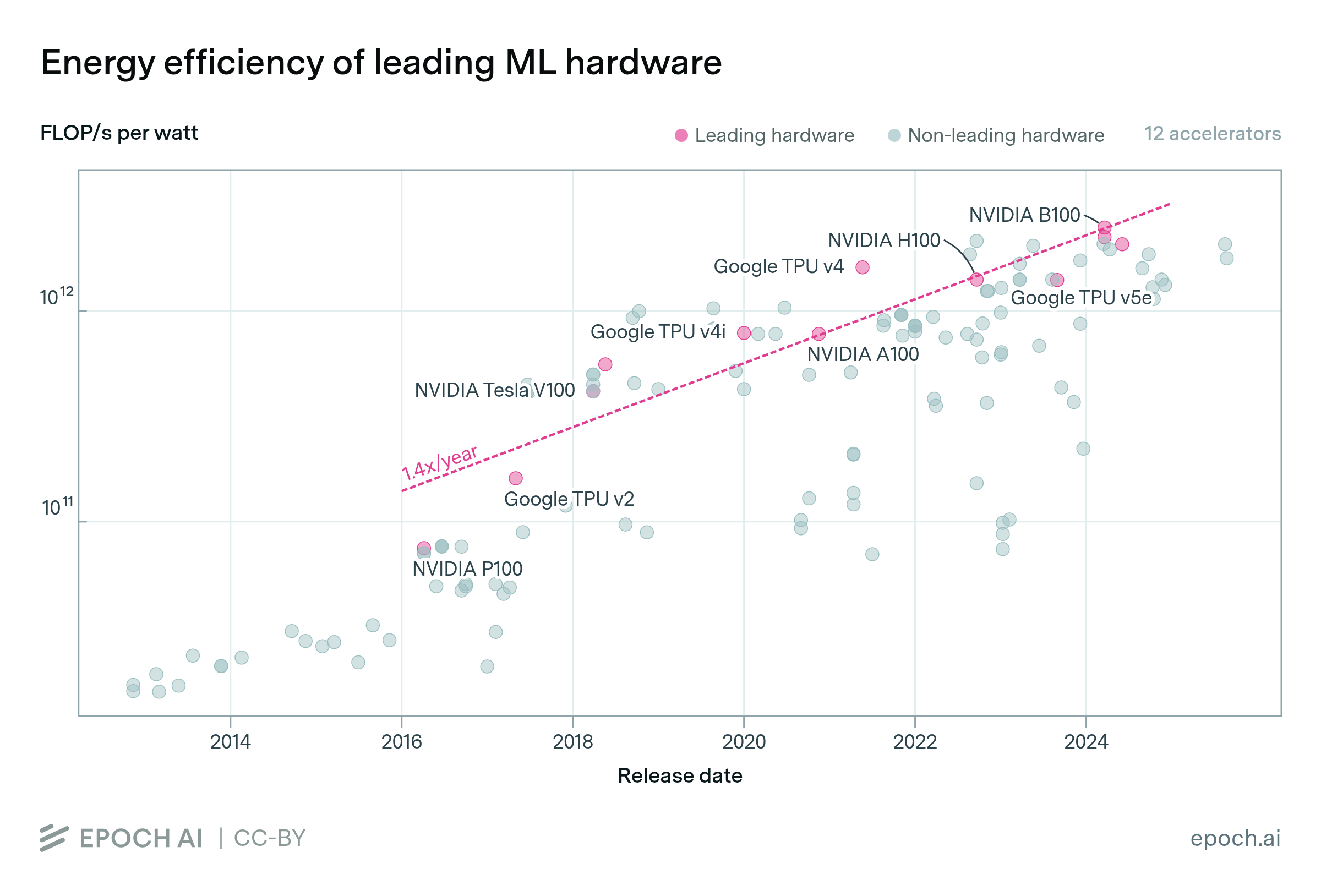
Leading ML hardware becomes 40% more energy-efficient each year
By Robi Rahman
Data Insight
Oct. 23, 2024
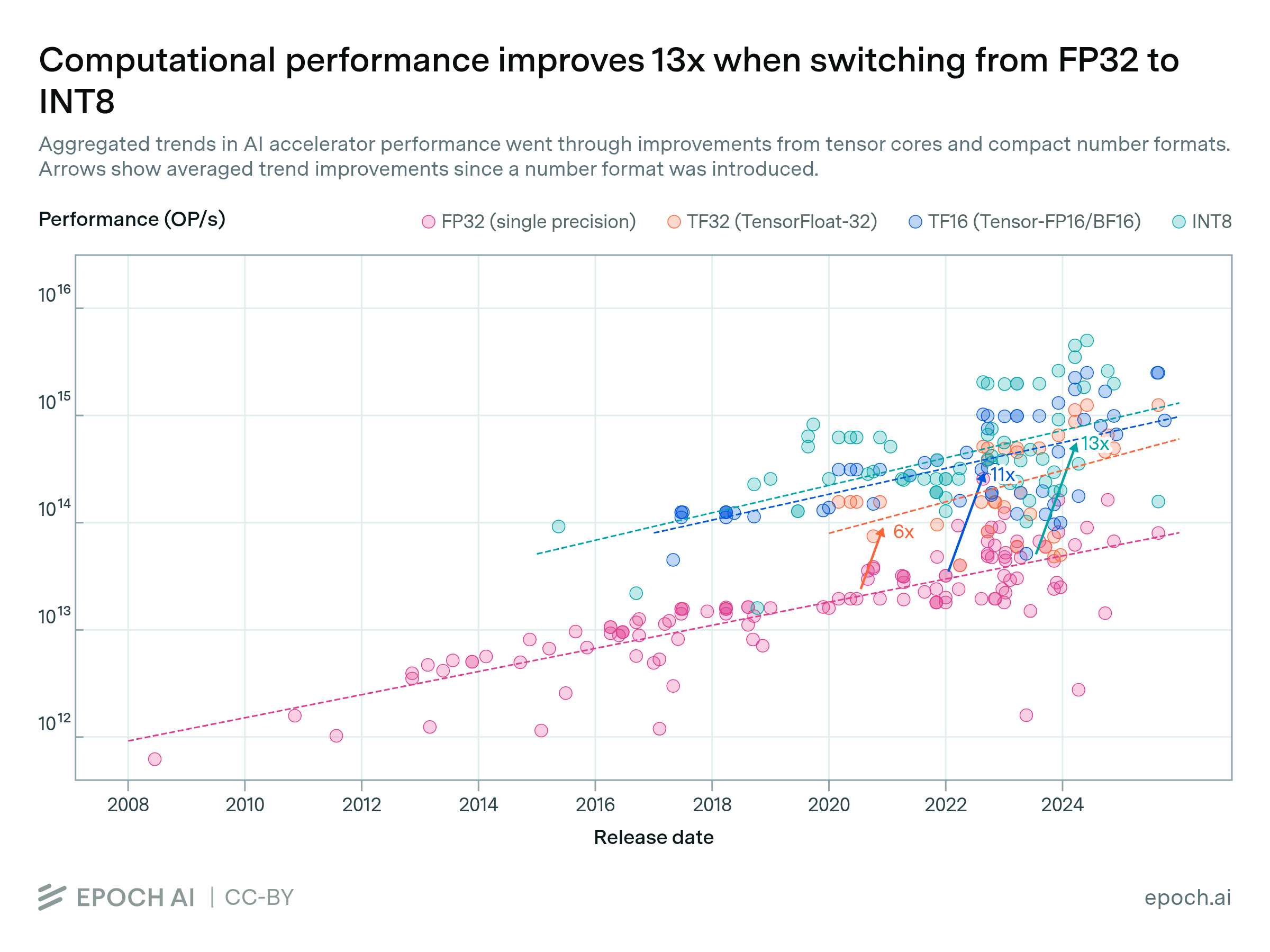
Performance improves 13x when switching from FP32 to tensor-INT8
By Robi Rahman and David Owen
Data Insight
Oct. 23, 2024
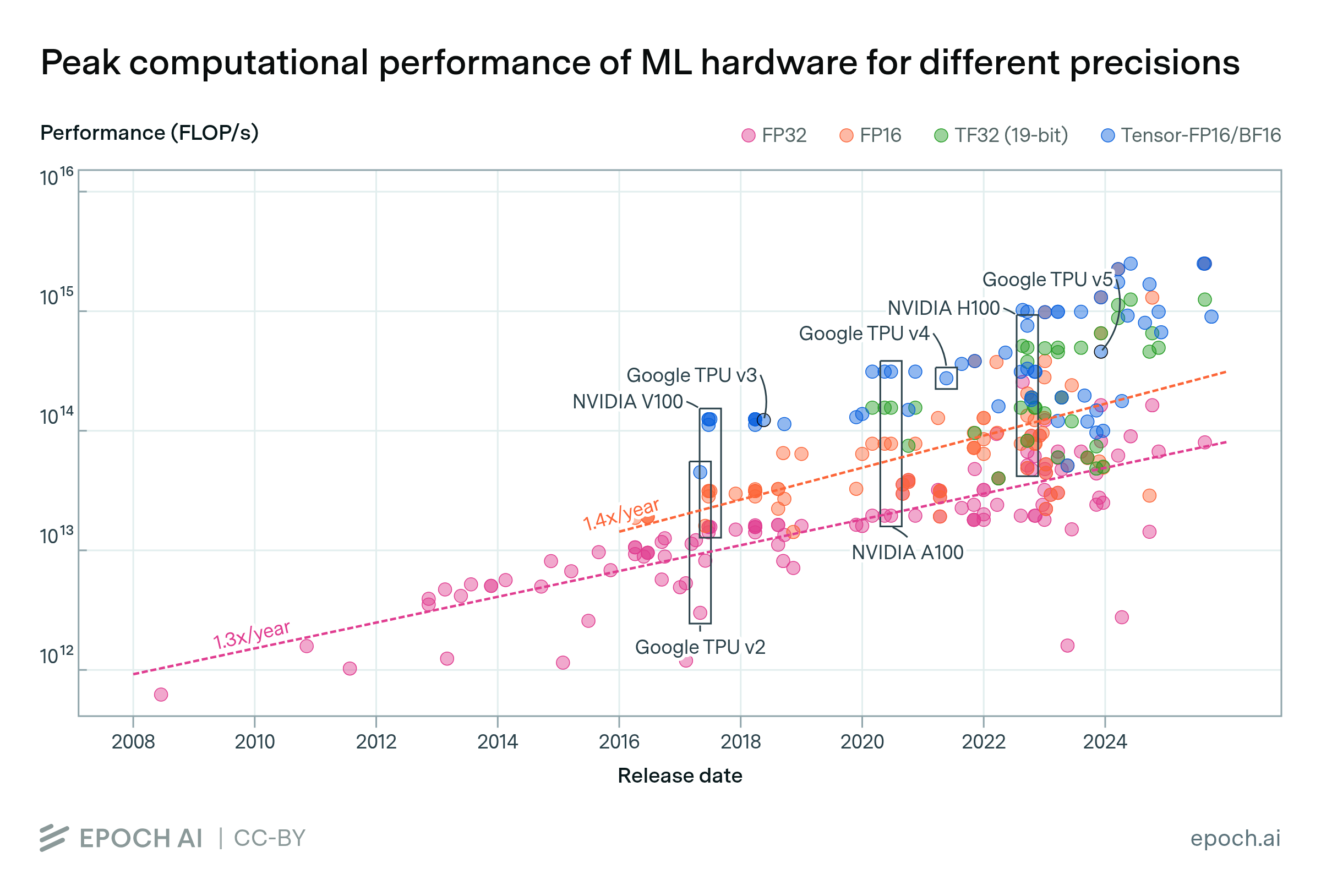
The computational performance of machine learning hardware has doubled every 2.3 years
By Robi Rahman
Data Insight
Oct. 23, 2024
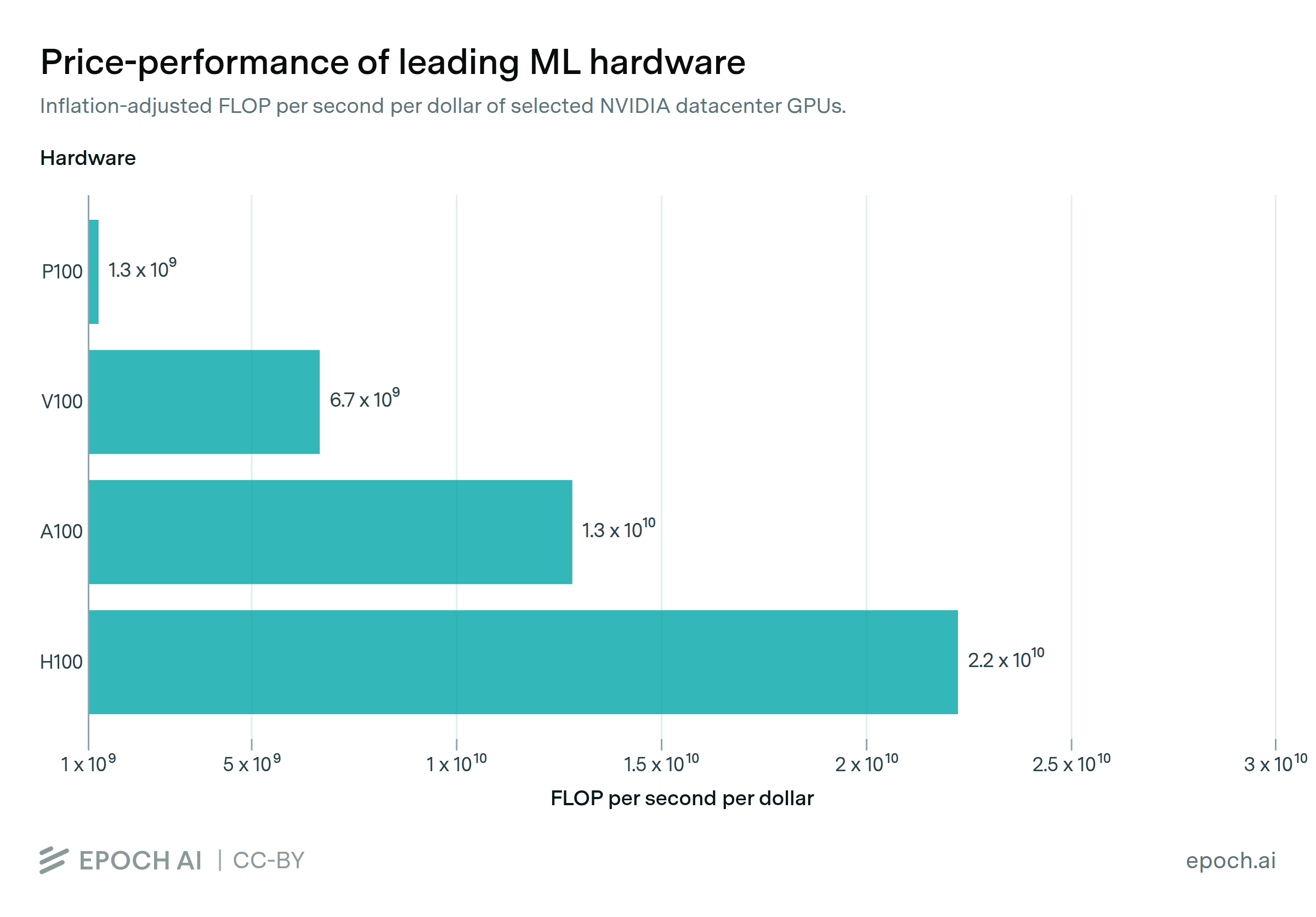
Performance per dollar improves around 30% each year
By Robi Rahman
Data Insight
Oct. 23, 2024
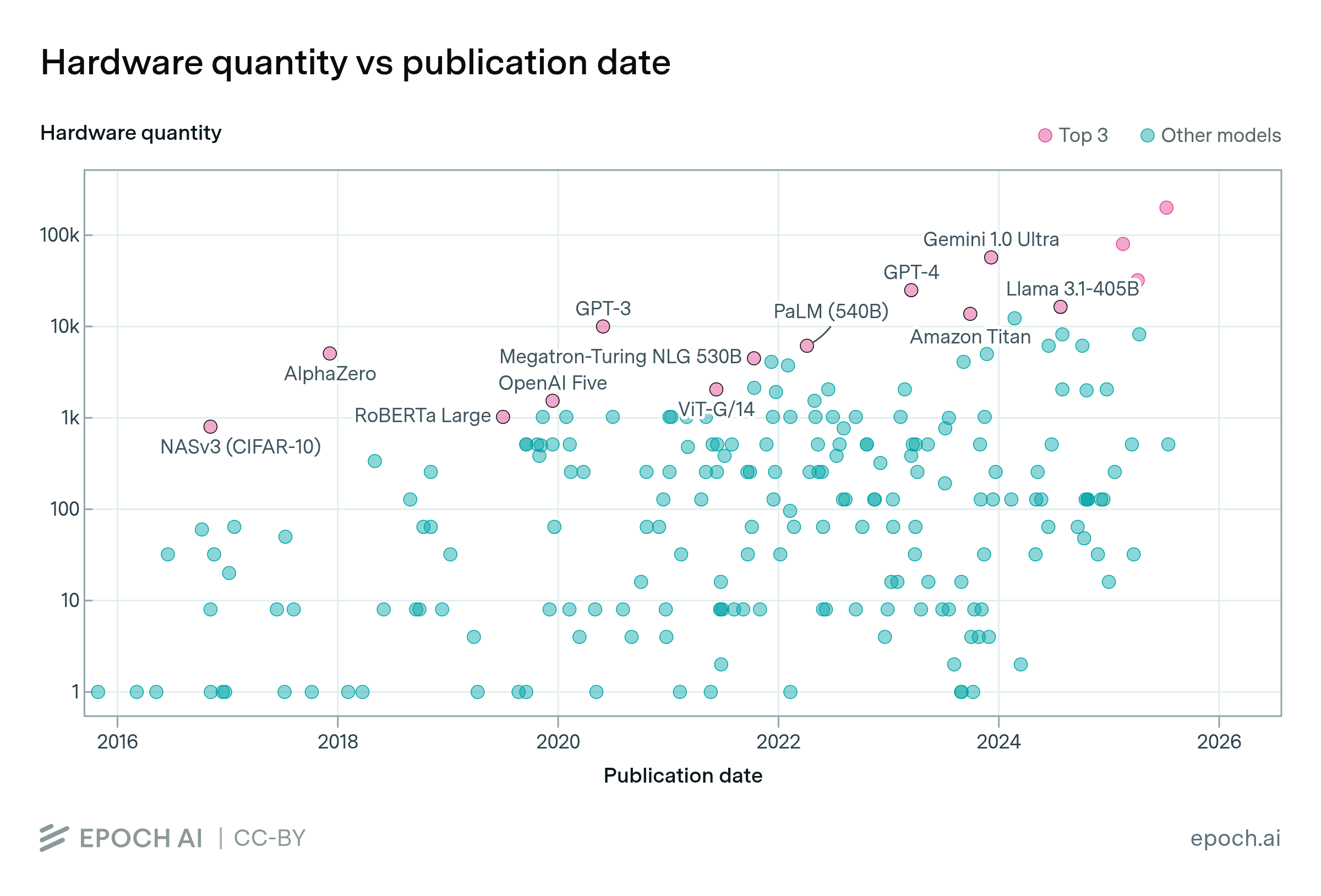
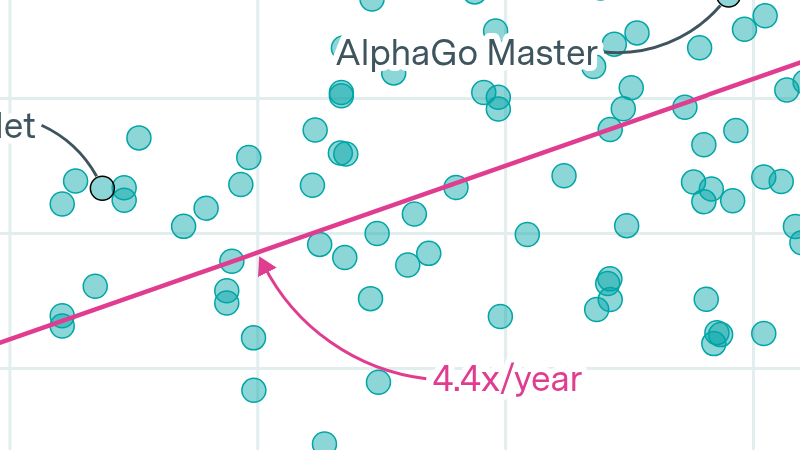
AI training cluster sizes increased by more than 20x since 2016
By Robi Rahman
Data Insight
Oct. 9, 2024
Leading AI companies have hundreds of thousands of cutting-edge AI chips
By Josh You and David Owen
Data Insight
Sep. 19, 2024
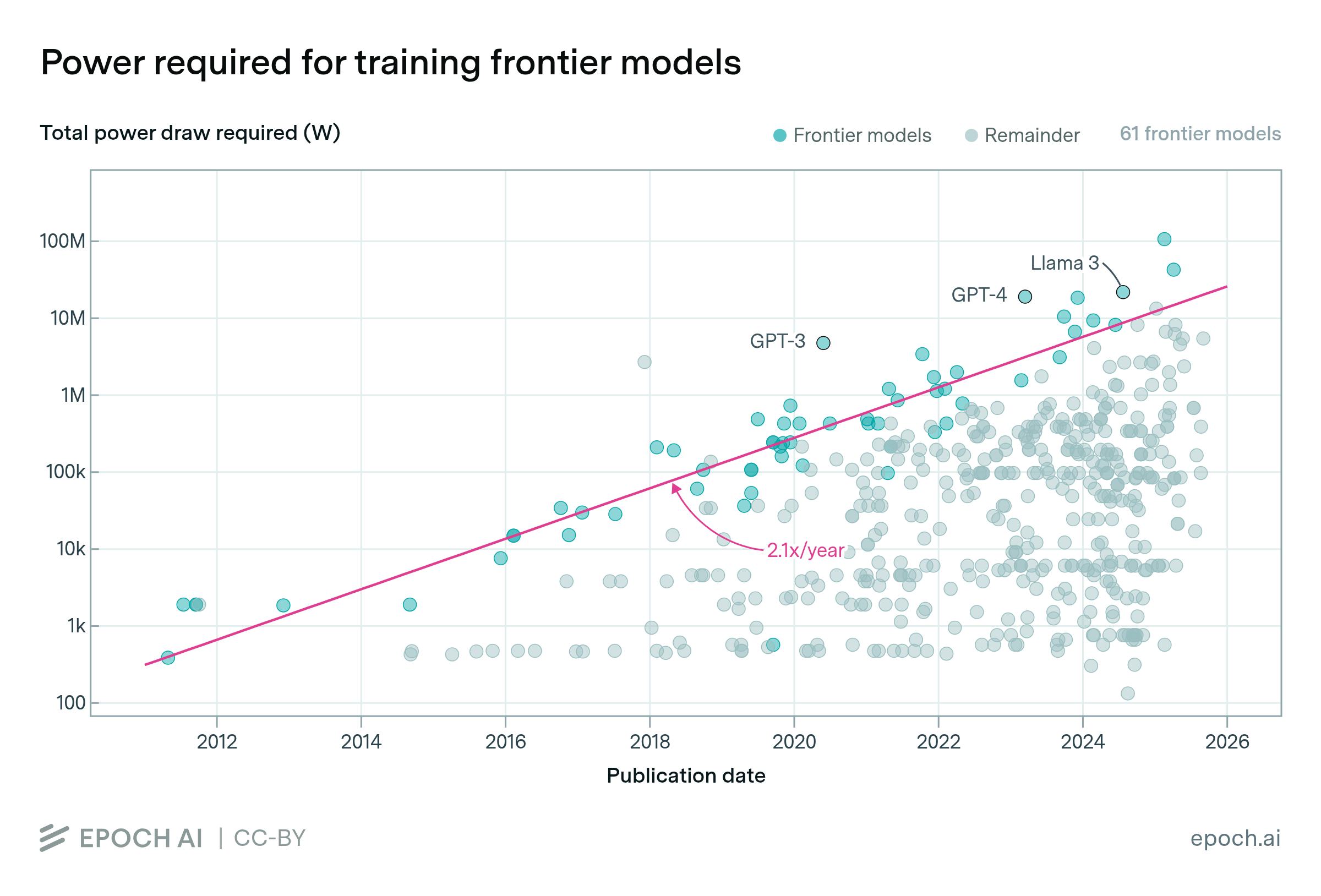
The power required to train frontier AI models is doubling annually
By Luke Emberson and Robi Rahman
Data Insight
Aug. 16, 2024
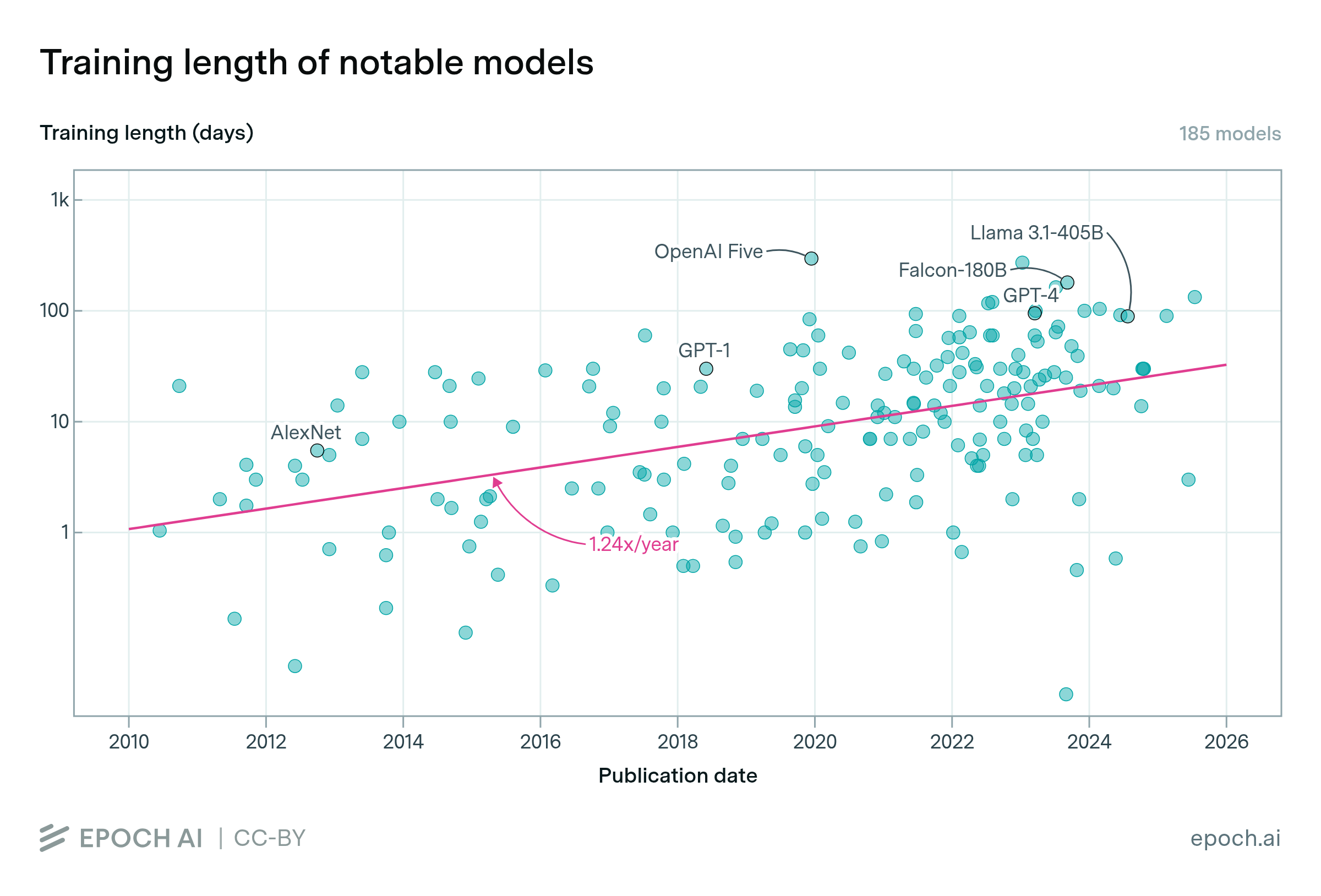
The length of time spent training notable models is growing
By Luke Emberson
Data Insight
Jun. 19, 2024
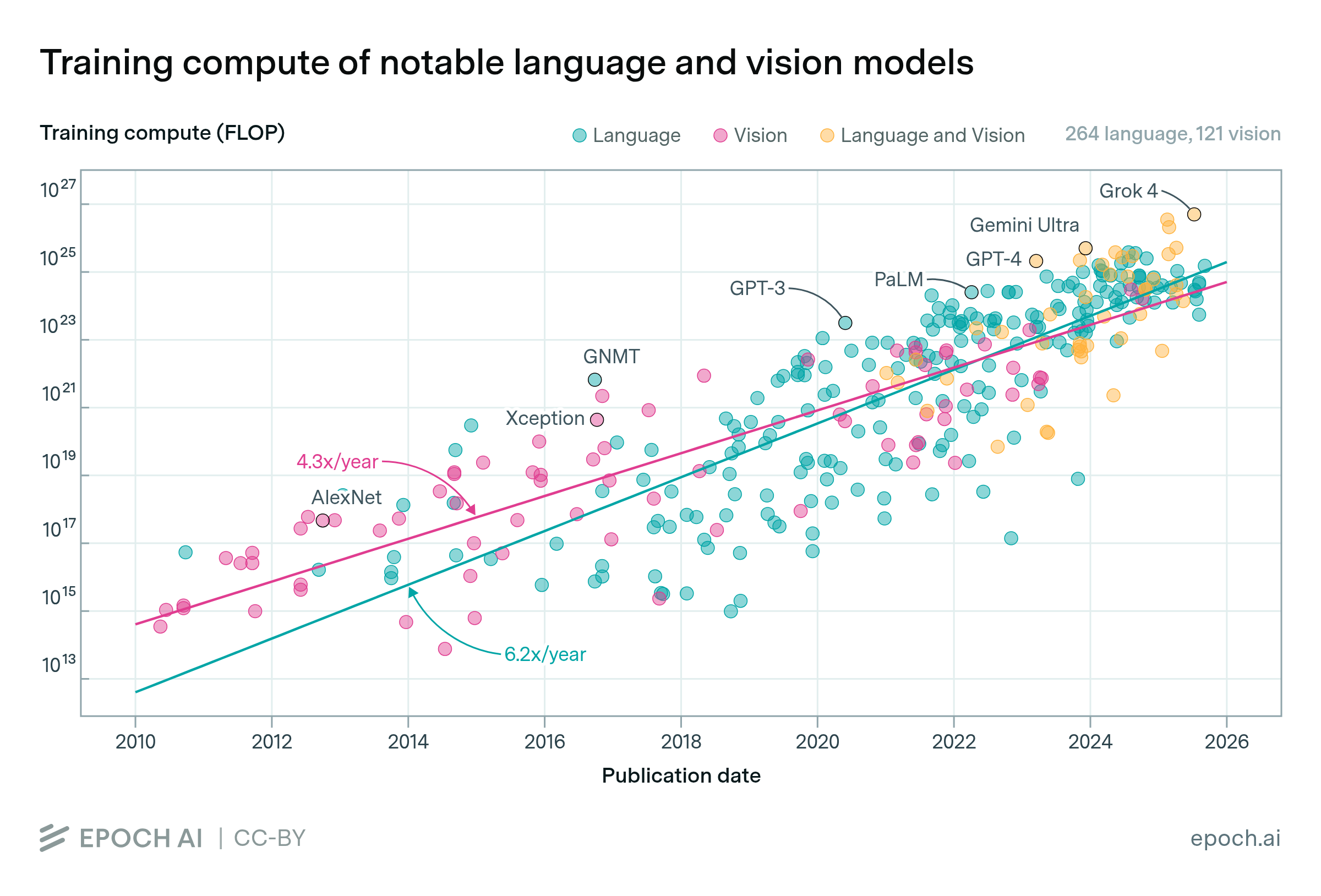
Training compute has scaled up faster for language than vision
By Robi Rahman and David Owen
Data Insight
Jun. 19, 2024
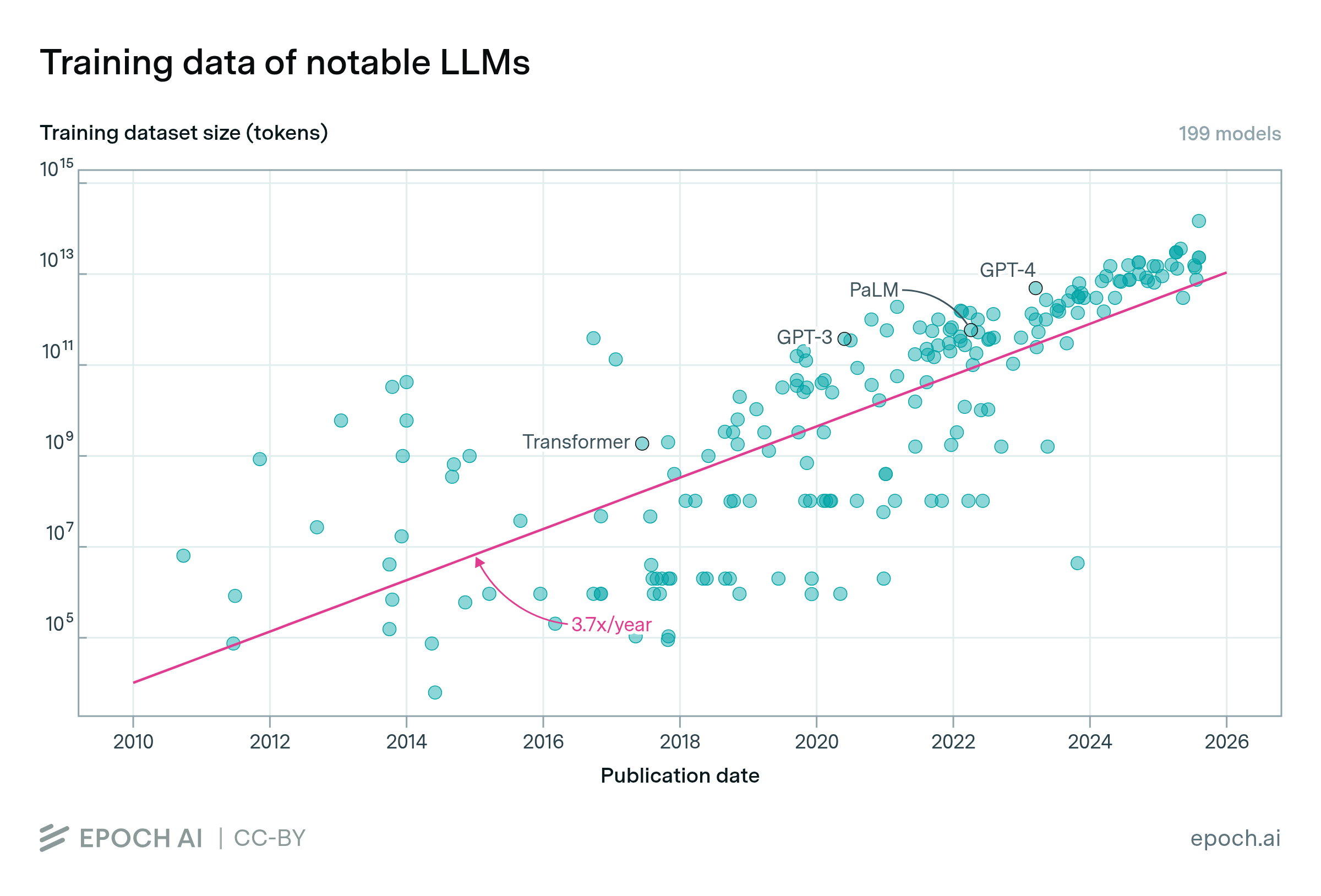
The size of datasets used to train language models doubles approximately every six months
By Robi Rahman and David Owen
Data Insight
Jun. 19, 2024
The training compute of notable AI models has been doubling roughly every six months
By Robi Rahman and David Owen
Data Insight
Jun. 19, 2024
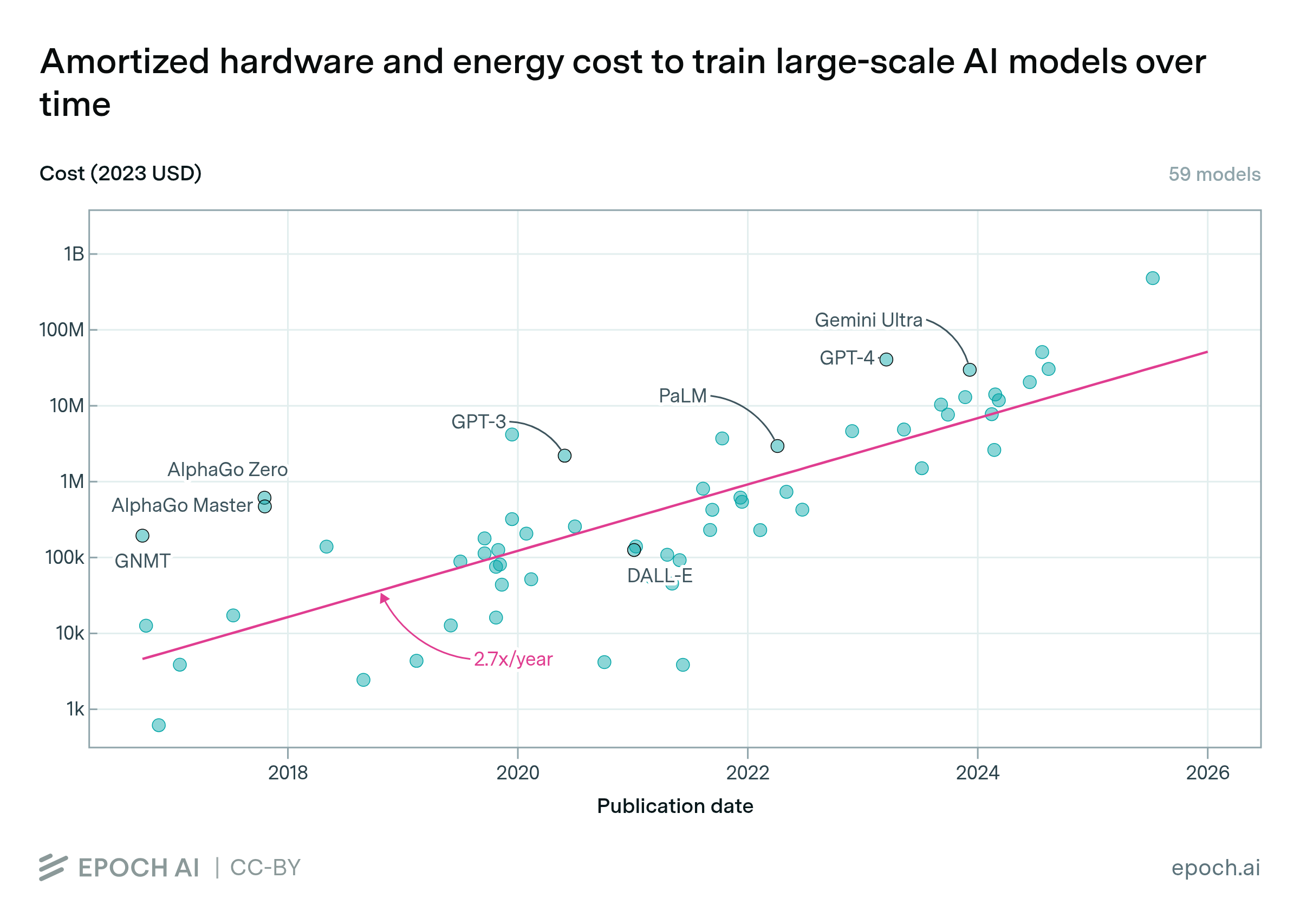
Training compute costs are doubling every eight months for the largest AI models
By Ben Cottier and Robi Rahman
Data Insight
Jun. 19, 2024
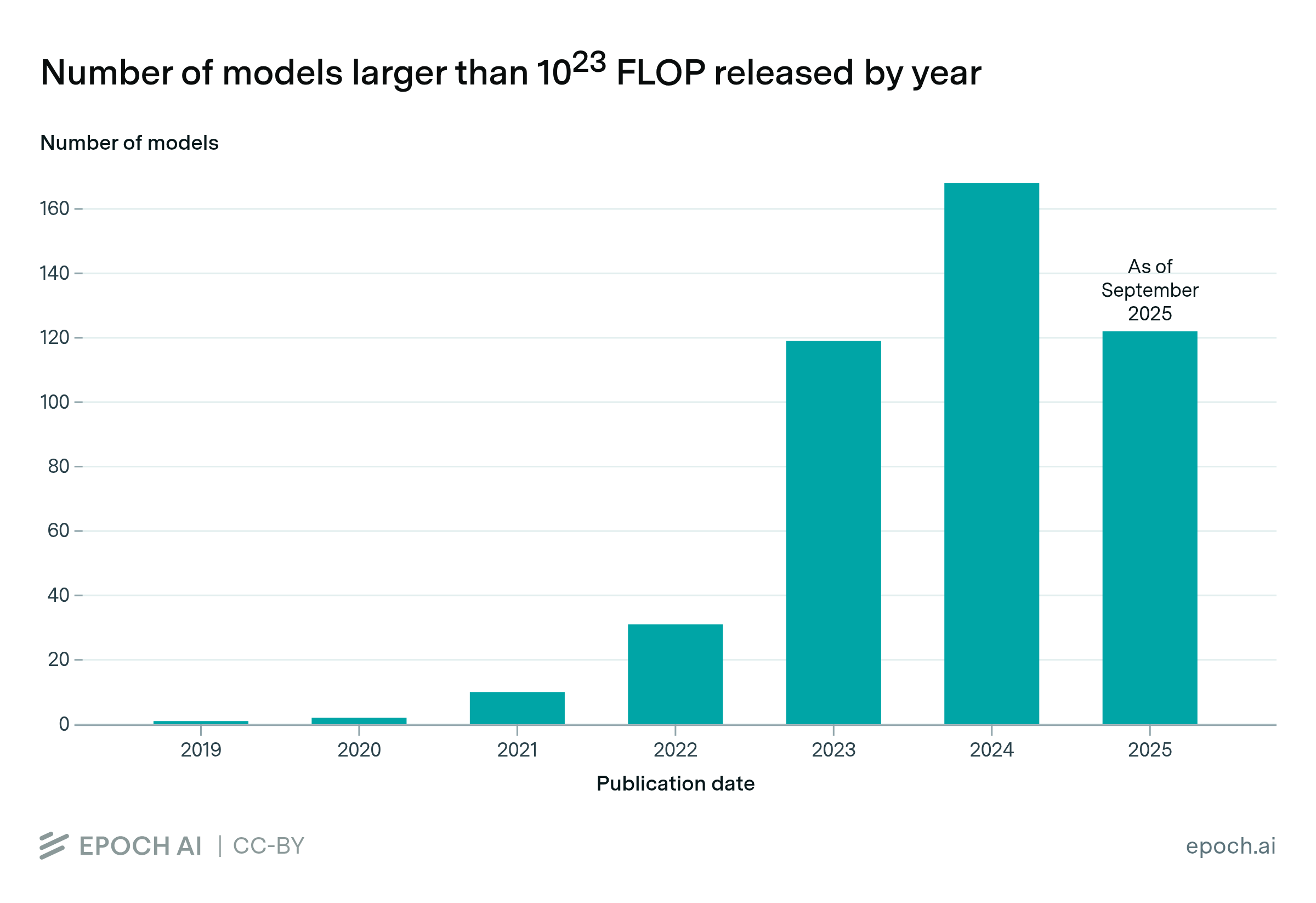
The pace of large-scale model releases is accelerating
By Robi Rahman
Data Insight
Jun. 19, 2024
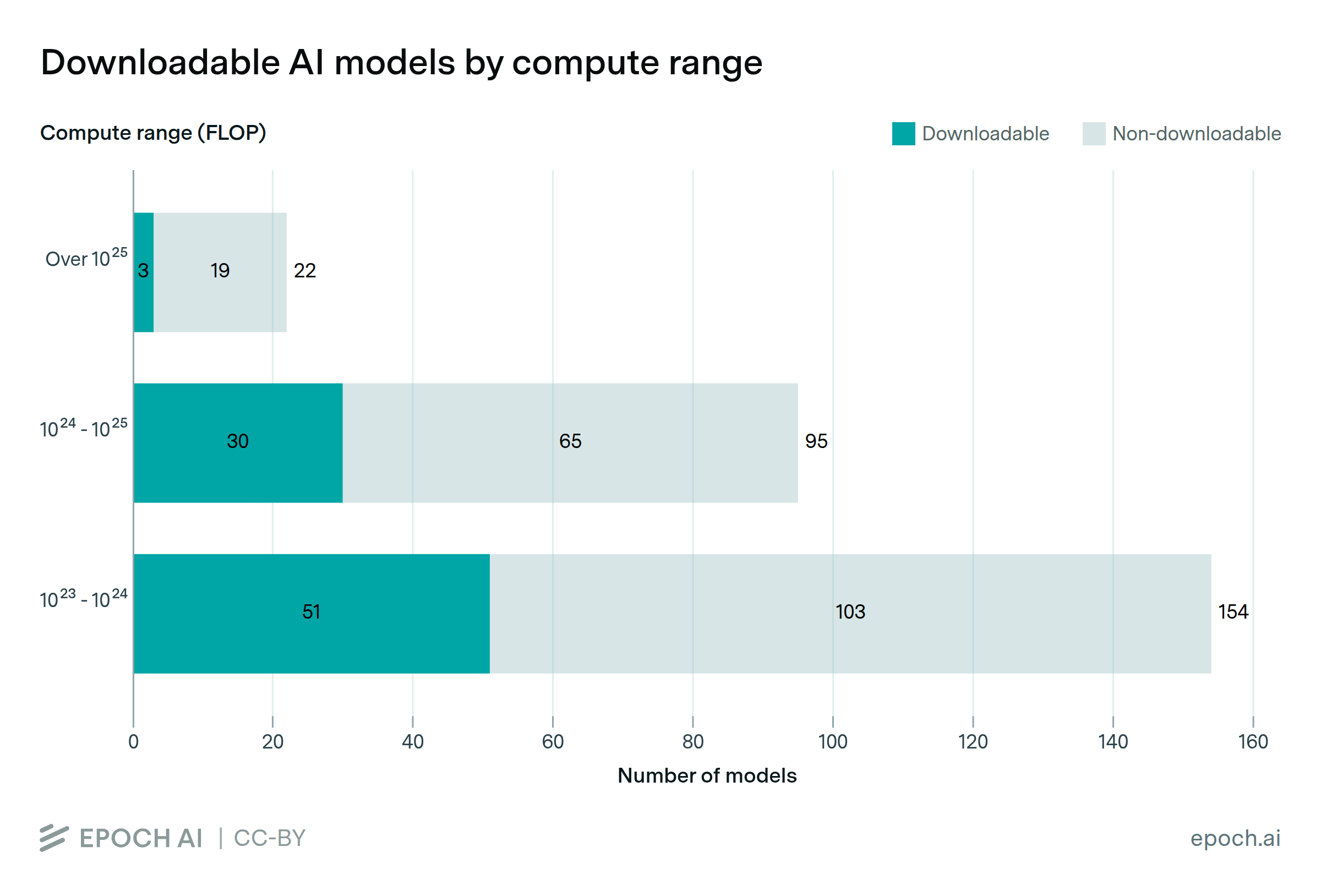
Almost half of large-scale models have published, downloadable weights
By Ben Cottier, Josh You, and Natalia Martemianova
Data Insight
Jun. 19, 2024
Most large-scale models are developed by US companies
By Robi Rahman
Data Insight
Jun. 19, 2024
Language models compose the large majority of large-scale AI models
By Robi Rahman and Josh You
Feedback
Have a question? Noticed something wrong? Let us know.
Data Insights
Epoch AI’s data insights break down complex AI trends into focused, digestible snapshots.