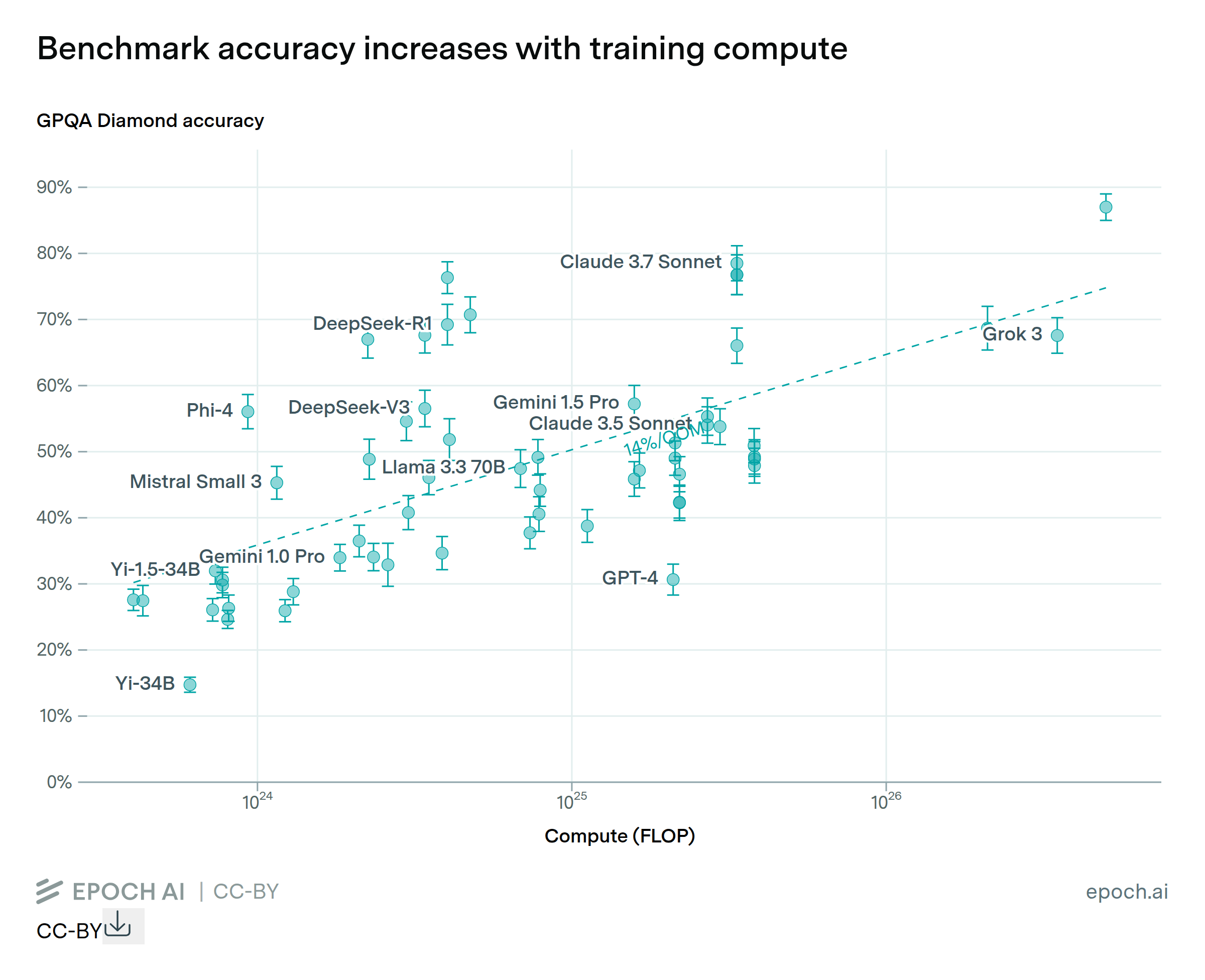
Across benchmarks measuring skills in research-level math, agentic coding, visual understanding, common sense reasoning, and more, AI capabilities have grown rapidly and consistently over the last 12 months.

While these benchmarks do not capture all of the nuanced abilities needed for economically valuable tasks, the clear upward trends reflect genuine improvements in AI’s utility. This growth in capabilities shows no sign of slowing down.
Epoch's work is free to use, distribute, and reproduce provided the source and authors are credited under the Creative Commons BY license.
Learn more about this graph
We show trends in a selection of benchmarks from Epoch’s Benchmarking Hub. These benchmarks are chosen to cover a diverse range of skills:
- FrontierMath tests models’ ability to solve research-level mathematical problems.
- GPQA Diamond poses graduate-level science questions across biology, physics, and chemistry, where answers are designed to be “Google-proof”.
- Aider Polyglot evaluates models’ performance on a set of challenging programming problems.
- SimpleBench is designed to test common sense reasoning by posing problems that are difficult for present-day models but easy for humans.
- The Visual Physics Comprehension Test (VPCT) is a benchmark designed to evaluate models’ understanding of basic physical scenarios.
Data
Assumptions and limitations
Explore this data
Benchmark results featuring the performance of leading AI models on challenging tasks.
Related insights