Model Performance
Model capabilities have grown faster since early 2024.
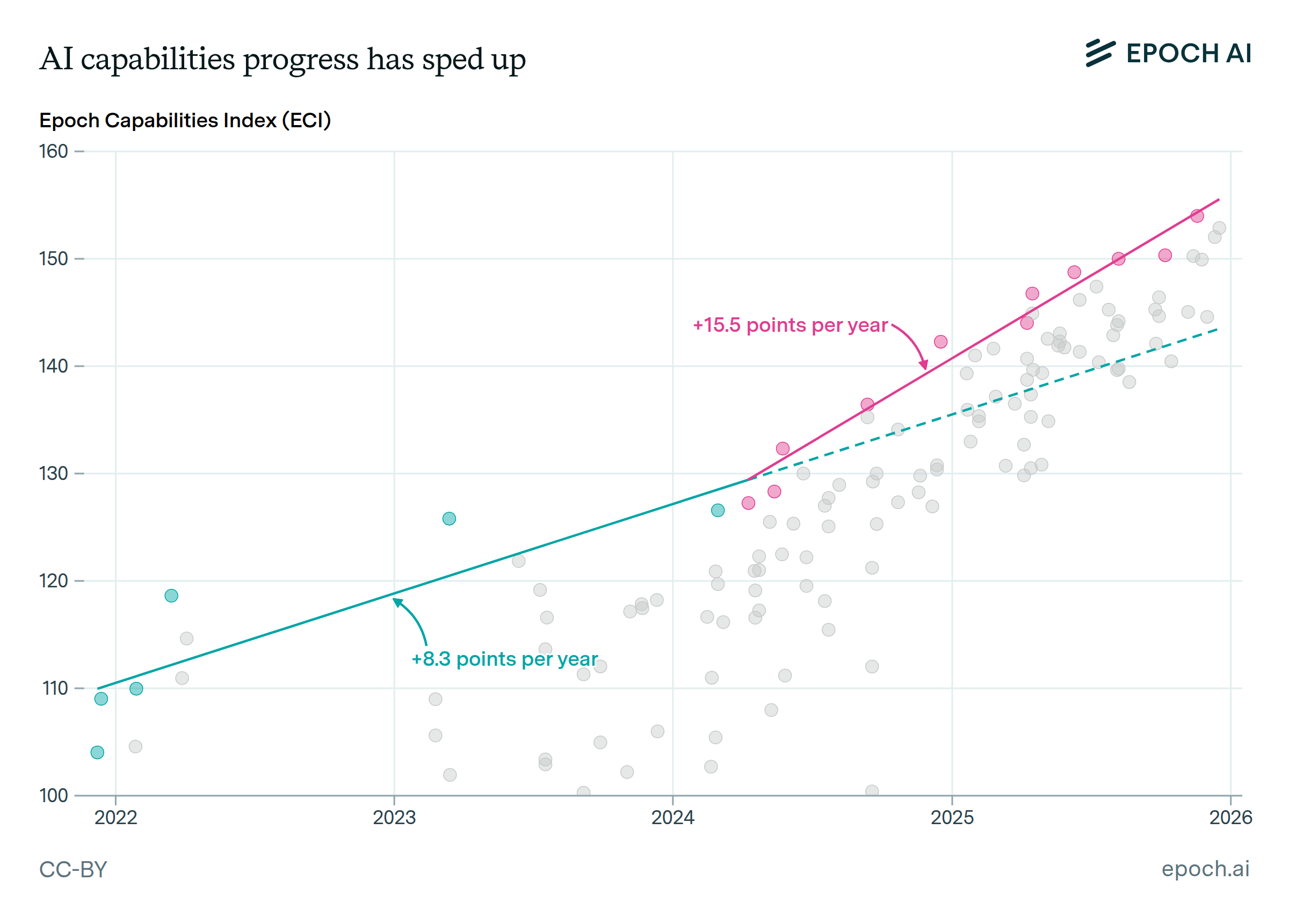
Model capabilities have grown faster since early 2024.
The Epoch Capabilities Index tracks model capabilities across a range of evaluations, enabling analysis of long-term capabilities trends. ECI shows an increase in the pace of progress around April 2024, with state-of-the-art models improving by 15.5 points per year—about as much as the jump from GPT-4 to o1.
AI Companies
The total computing power of the stock of AI chips is growing at a rate of 3.4×/year.
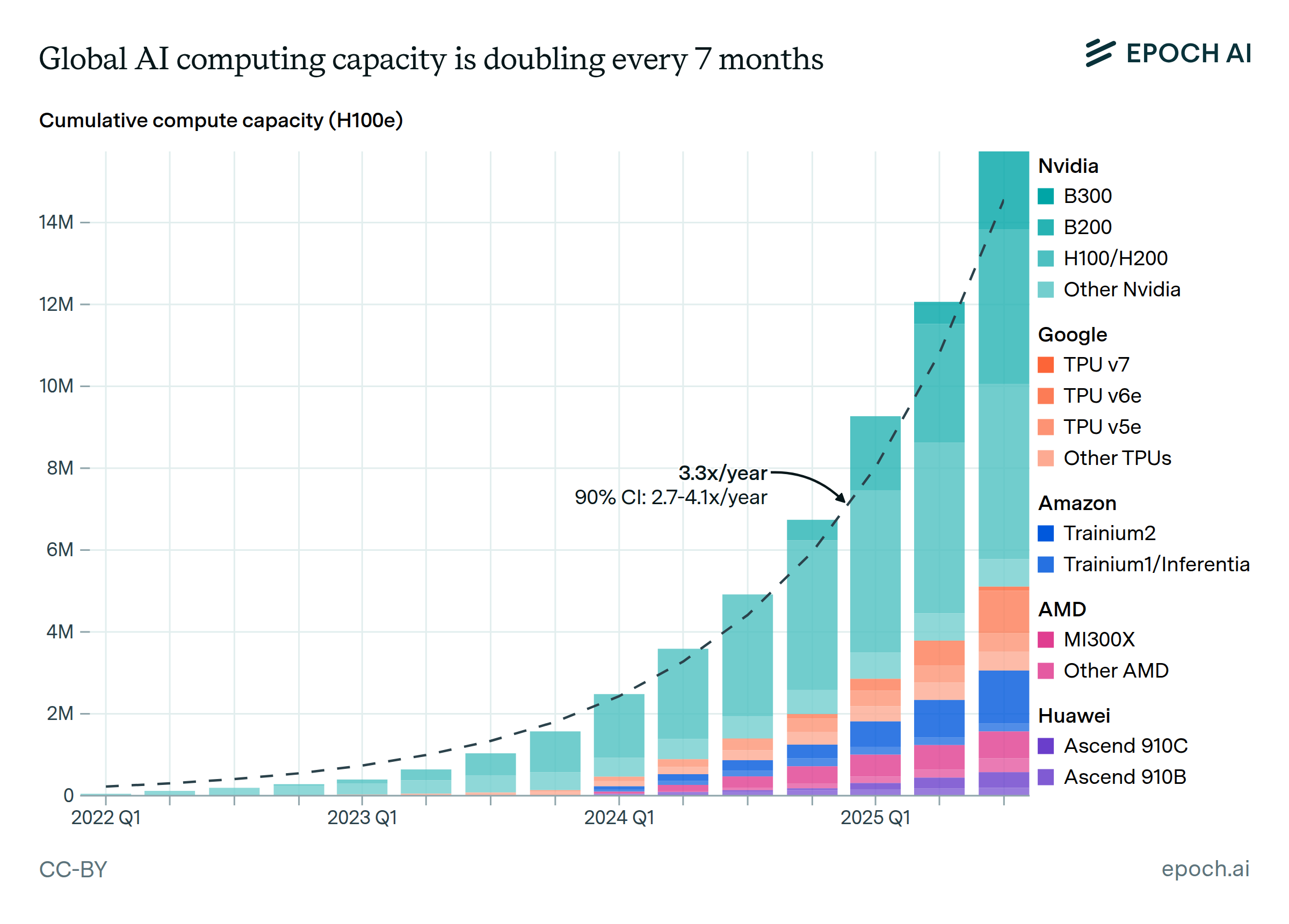
The total computing power of the stock of AI chips is growing at a rate of 3.4×/year.
The computing power of the total stock of AI chips has grown at 3.4x per year, doubling every 7 months since 2022, based on revenue data, other financial disclosures, and analyst reports.
Training Runs
Training compute for frontier language models has been growing at 5× per year since 2020.
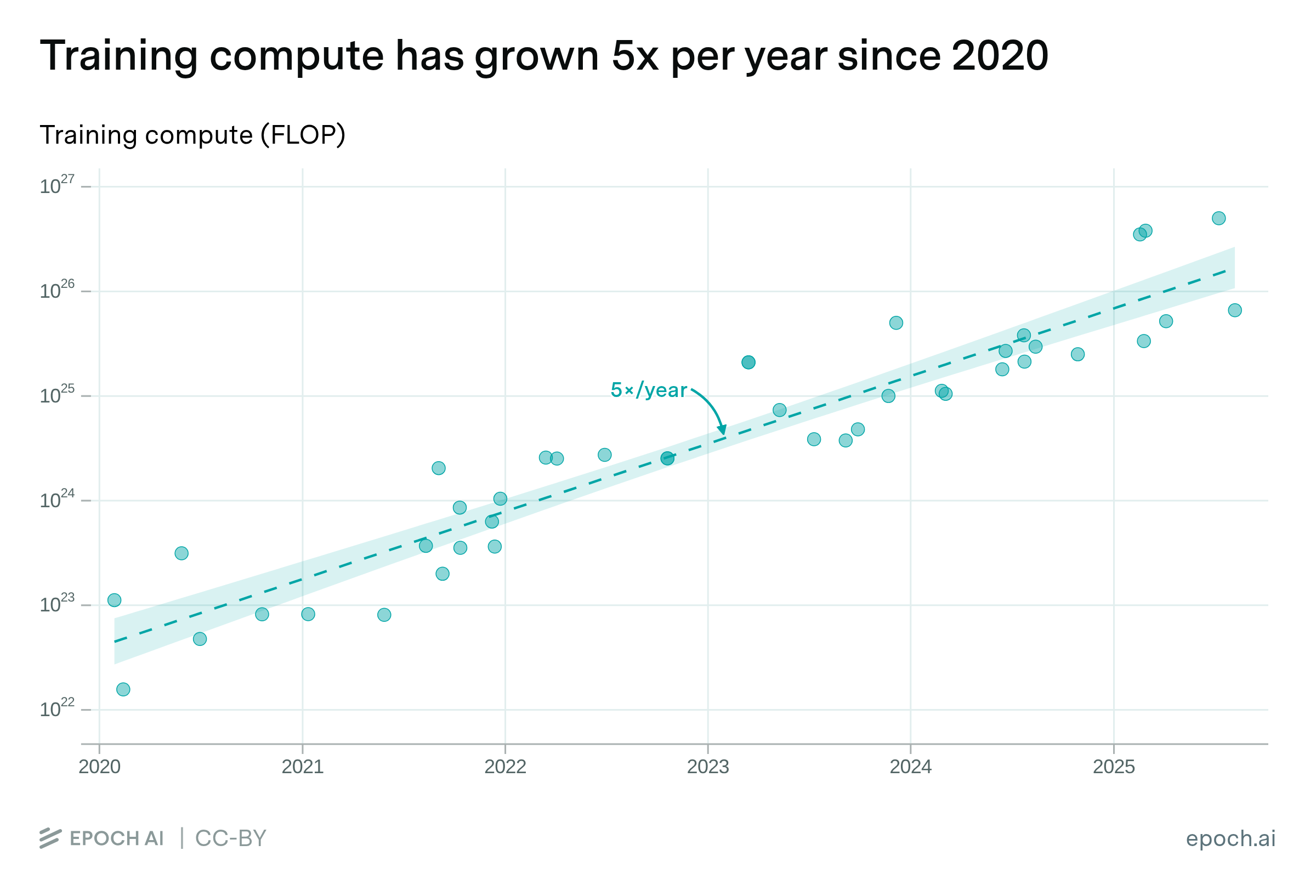
Training compute for frontier language models has been growing at 5× per year since 2020.
The amount of compute used to train frontier language models has grown exponentially. Since 2020, the trend among top-5 models has grown by a factor of ~10,000.
Data Centers
The largest known AI data center has a computing capacity equivalent to 1.1 million NVIDIA H100 chips.
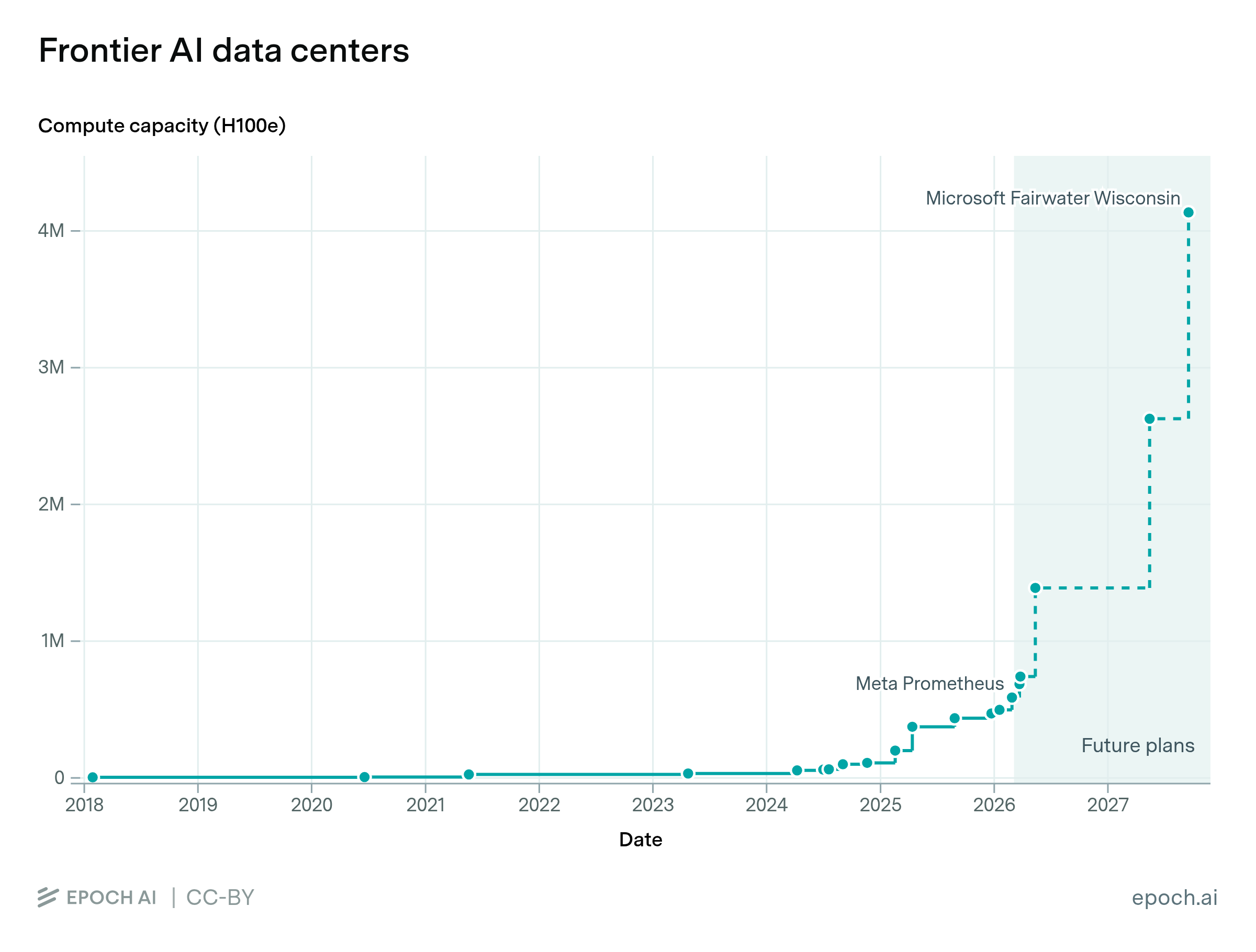
The largest known AI data center has a computing capacity equivalent to 1.1 million NVIDIA H100 chips.
SpaceXAI's Colossus 2 in Memphis, Tennessee has an estimated computing capacity of 1.1 million H100-equivalents, making it the largest known AI data center. Meta Hyperion is expected to have over 3x more computing capacity, at 3.7M H100-equivalents by January 2028.
Hardware
AI chip performance per dollar has improved by 37% per year.
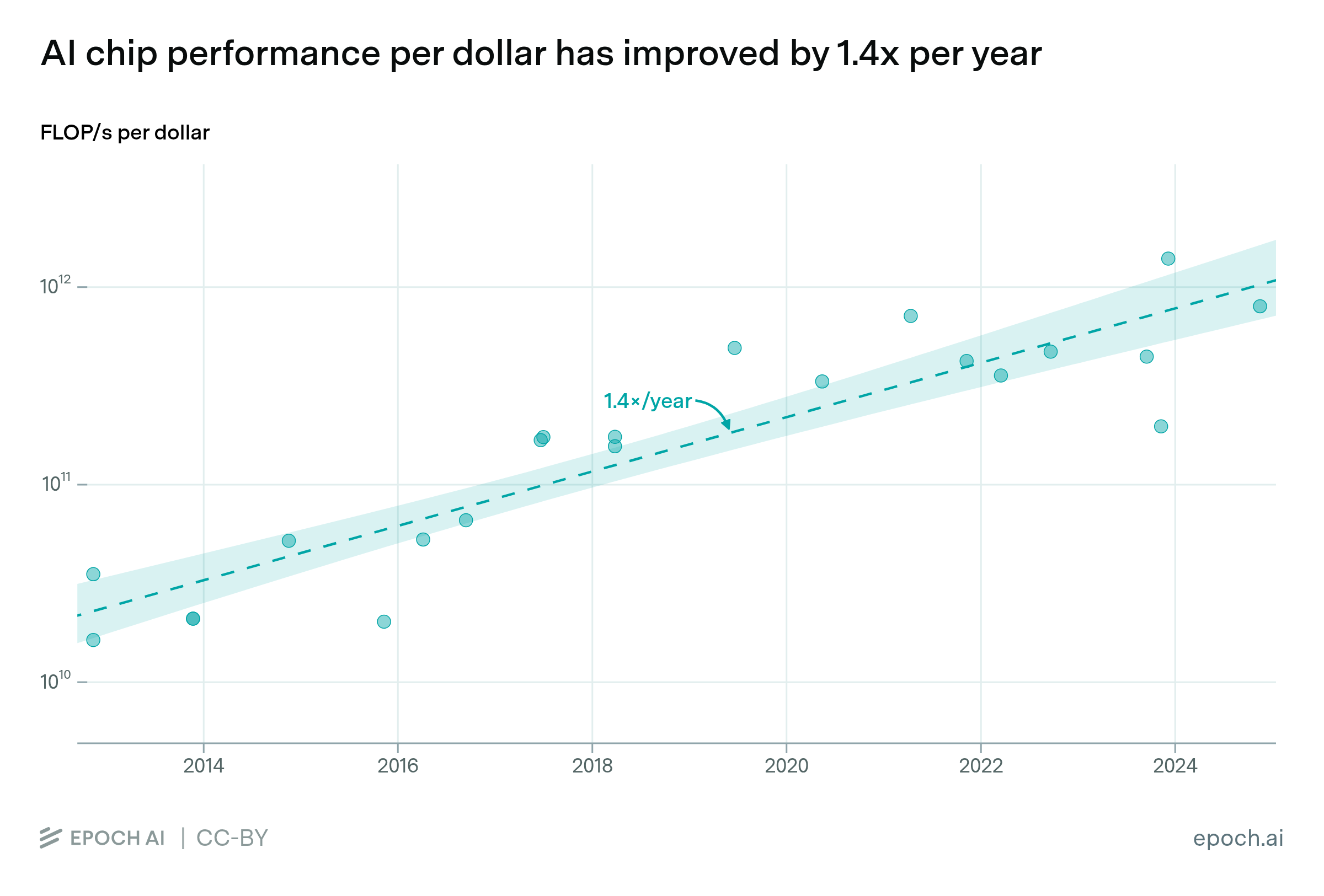
AI chip performance per dollar has improved by 37% per year.
The compute performance you can buy for a dollar has improved by roughly 40% per year across over 20 AI accelerators released between 2012 and 2025. Much of this is driven by manufacturers introducing more powerful and more expensive chips — the GB300 costs nearly 9× the P100's release price, but delivers about 24× the performance per dollar.