Related work
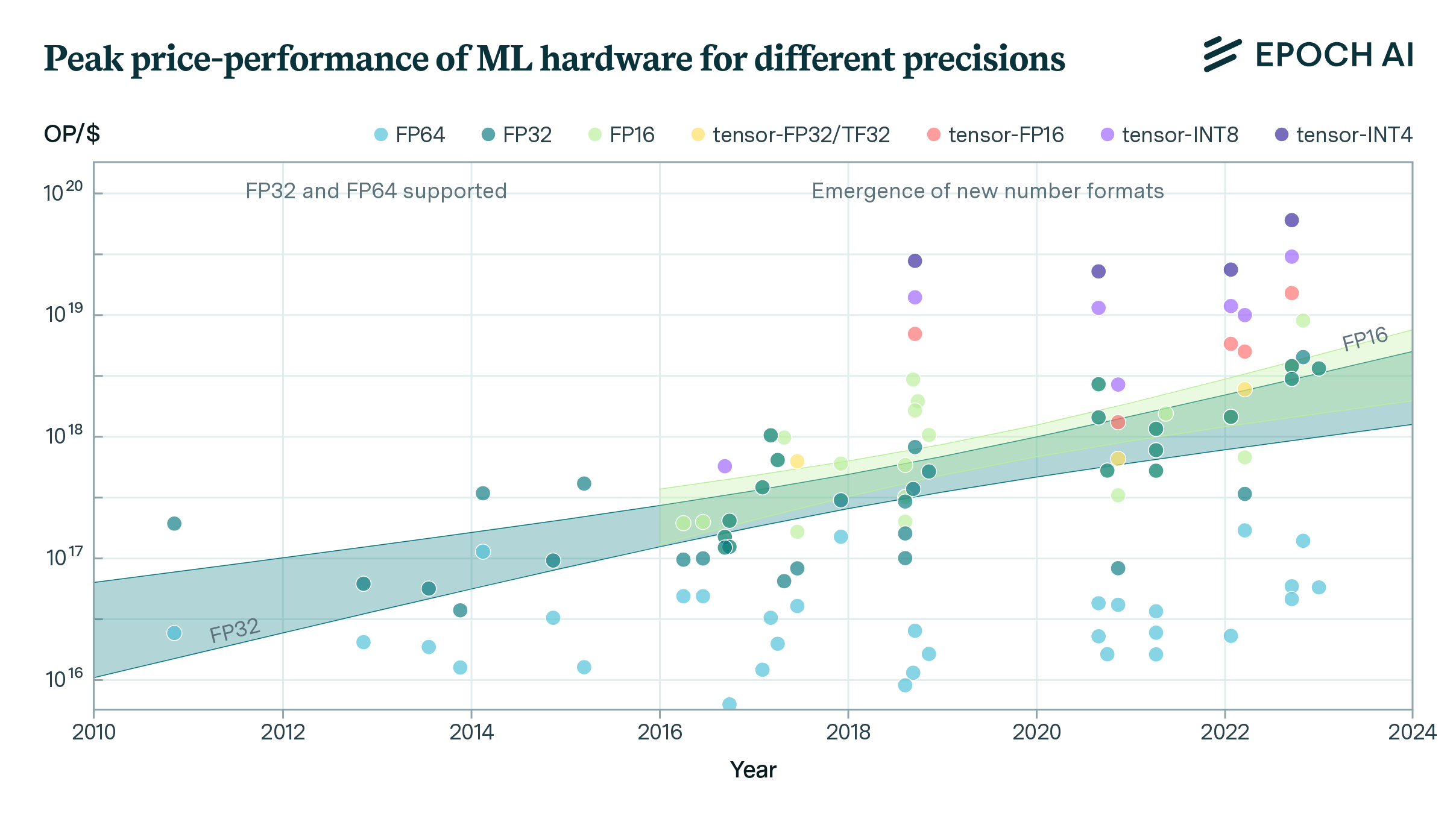
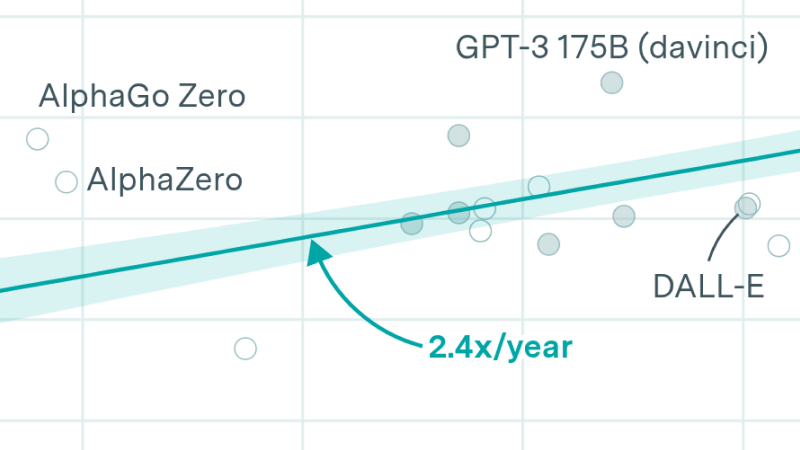
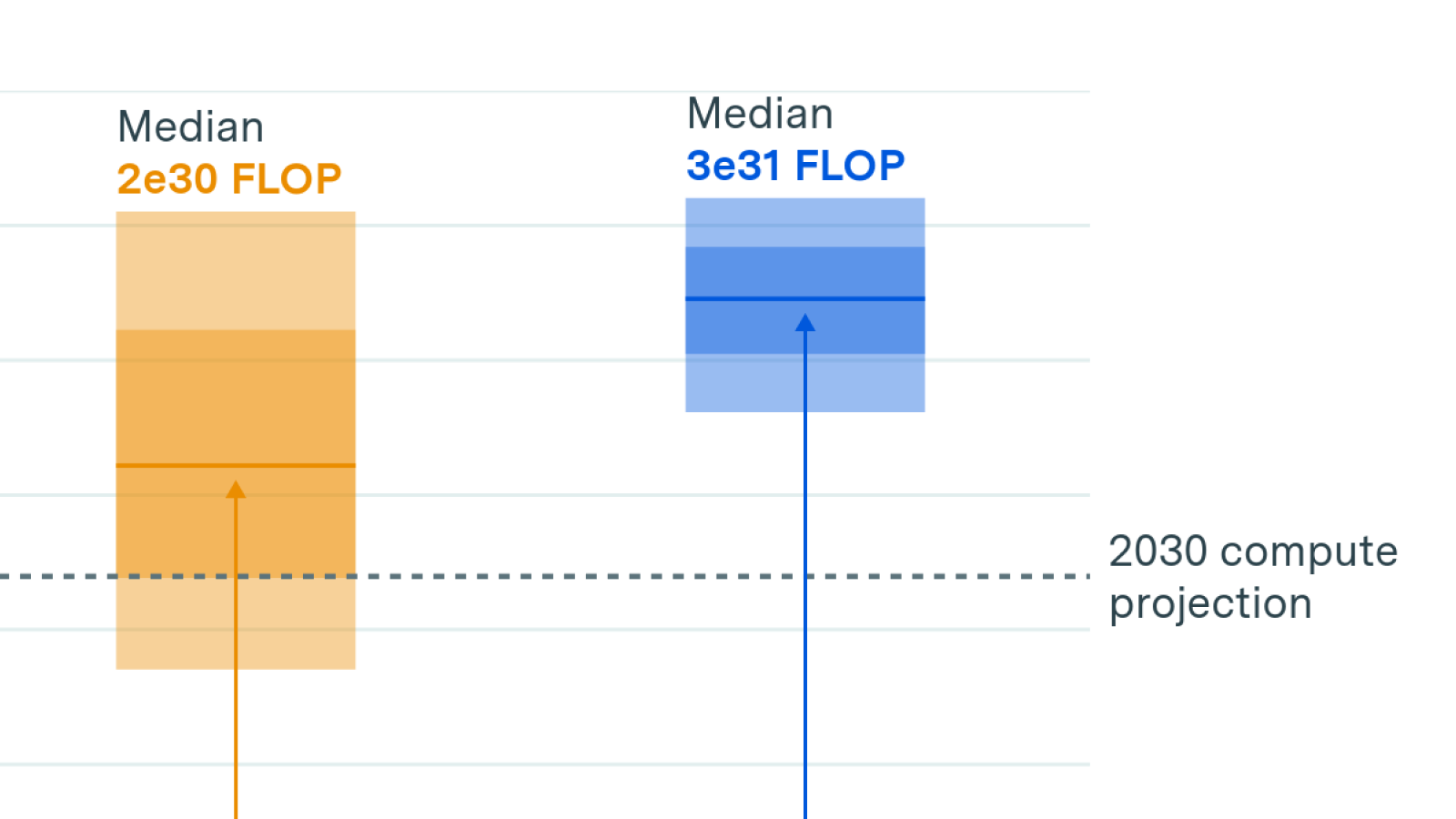
We present key data on over 170 AI accelerators, such as graphics processing units (GPUs) and tensor processing units (TPUs), used to develop and deploy machine learning models in the deep learning era.
To identify ML hardware, we annotated chips used for ML training in our database of Notable AI Models. We additionally added ML hardware that has not been documented in training those systems, but is clearly manufactured for ML - based on its description, supported numerical formats, or belonging to the same family as other ML hardware.
We use hardware datasheets, documented for each chip in the dataset, to fill in key information such as computing performance, die size, etc. Not all information is available, or even applicable, for all hardware, so columns are often left empty. We additionally use other sources, such as news coverage or hardware price archives, to fill in the price on release.
Epoch AI’s data is free to use, distribute, and reproduce provided the source and authors are credited under the Creative Commons Attribution license.
GPUs and TPUs are identified as machine learning hardware if they are used to train a notable ML model, or are offered on a rental basis for ML workloads by major cloud compute providers. CPUs are not included in this dataset.
Numerical values used in computing are represented in several different formats, and these formats vary in the number of bits (0s or 1s) required to represent one number. Higher-bit formats are more precise, but require more storage and more compute to process, and AI developers have been moving to lower-precision formats over time using new hardware optimized for those formats (more details here).
Commonly used formats include FP64, FP32/TF32, BF16, and INT8:
Epoch AI’s data is free to use, distribute, and reproduce provided the source and authors are credited under the Creative Commons Attribution license. Complete citations can be found here.
Download the data in CSV format.
Explore the data using our interactive tools.
View the data directly in a table format.
Feedback can be directed to the data team at data@epoch.ai.
Have a question? Noticed something wrong? Let us know.
We present key data on over 170 AI accelerators, such as graphics processing units (GPUs) and tensor processing units (TPUs), used to develop and deploy machine learning models in the deep learning era.