

GPUs are typically faster when using tensor cores and number formats optimized for AI computing. Compared to using non-tensor FP32, TF32, tensor-FP16, and tensor-INT8 provide around 6x, 11x, and 13x greater performance on average in the aggregate performance trends. Some chips achieve even larger speedups. For example, the H100 is 59x faster in INT8 than in FP32.
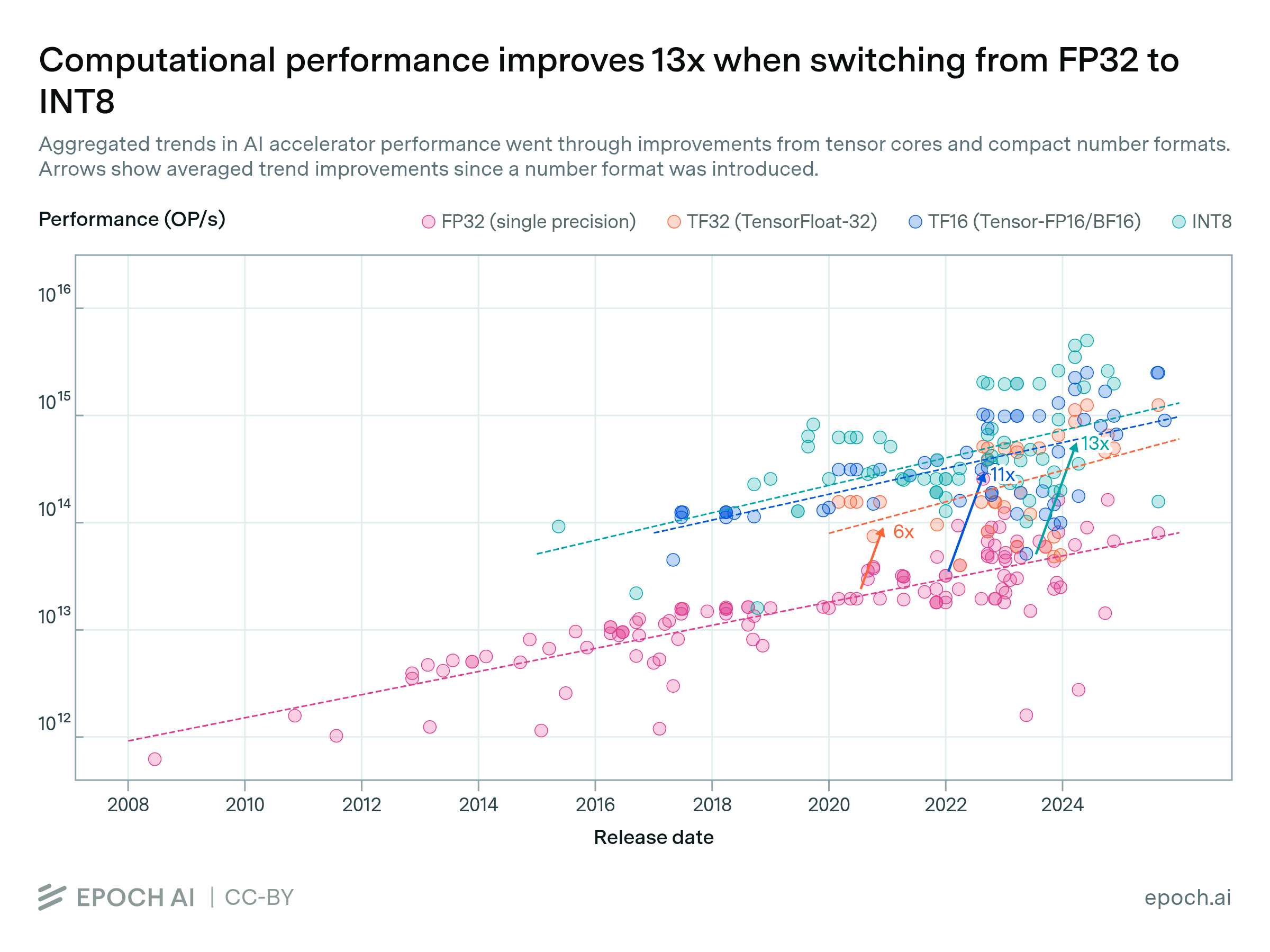
These improvements account for about half of the overall performance trend improvement since their introduction. Models trained with lower precision formats have become common, especially tensor-FP16, as developers take advantage of this boost in performance.
Epoch's work is free to use, distribute, and reproduce provided the source and authors are credited under the Creative Commons BY license.
Learn more about this graph
We estimate the individual per-format trends, then use these to estimate the average performance improvement compared to the non-tensor FP32 trend. This average improvement is evaluated across the limits of the shorter data series, so typically begins around 2016. Note that individual chips can vary significantly in how much they benefit from different number formats.
Analysis
Assumptions
Explore this data

Key data on over 170 AI accelerators, such as graphics processing units (GPUs) and tensor processing units (TPUs).