Settings
View
Display
Color by
Compute
Data
Filter by owner
Filter by user
Filter by country
Rigorous public data on the world's largest AI data centers. Independent estimates of power, compute, and cost built from high-resolution satellite imagery, permits, and our understanding of how data centers are constructed. Every data point is vetted by our team.








We define an AI data center as a collection of one or more buildings which are located near each other, have a shared hardware owner or facility operator, and which run hardware specialized for AI. This hardware includes GPUs or custom chips like Google's TPUs. These data centers may be used to experiment on, train, and deploy AI models.
We don't use a hard limit for how close together the data center buildings have to be, but a rule of thumb is less than 10 km apart. The buildings may or may not be networked together.
We do not distinguish between campuses of multiple buildings and individual buildings in what we classify as a data center.
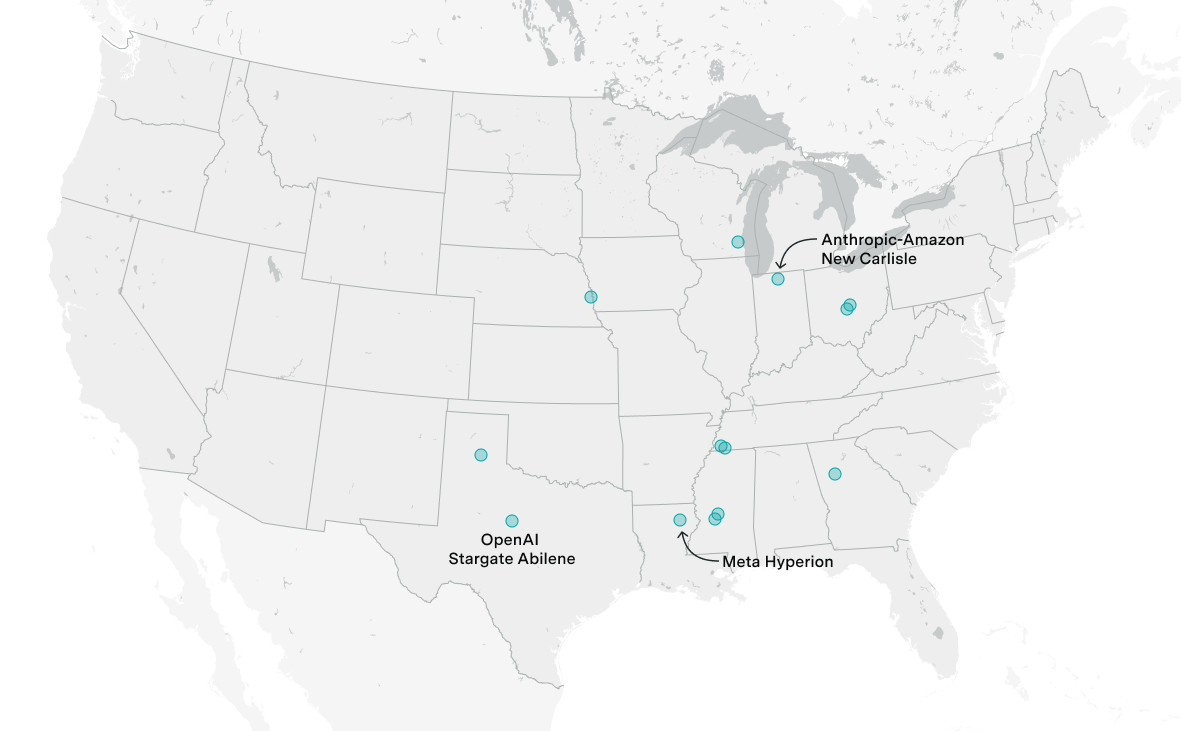
The largest known AI data center by IT power is Colossus 2, owned by SpaceXAI in Memphis, TN, drawing 946 MW. It is followed by Anthropic-Amazon New Carlisle (Amazon, 910 MW), Microsoft Fairwater Atlanta (Microsoft, 636 MW), Meta Prometheus (Meta, 631 MW), and OpenAI Stargate Abilene (Oracle, 421 MW).
The largest AI data center by compute is Colossus 2, owned by SpaceXAI in Memphis, TN, with 1,112k H100-eq. It is followed by Microsoft Fairwater Atlanta (Microsoft, 769k H100-eq), Meta Prometheus (Meta, 763k H100-eq), Anthropic-Amazon New Carlisle (Amazon, 686k H100-eq), and OpenAI Stargate Abilene (Oracle, 509k H100-eq).
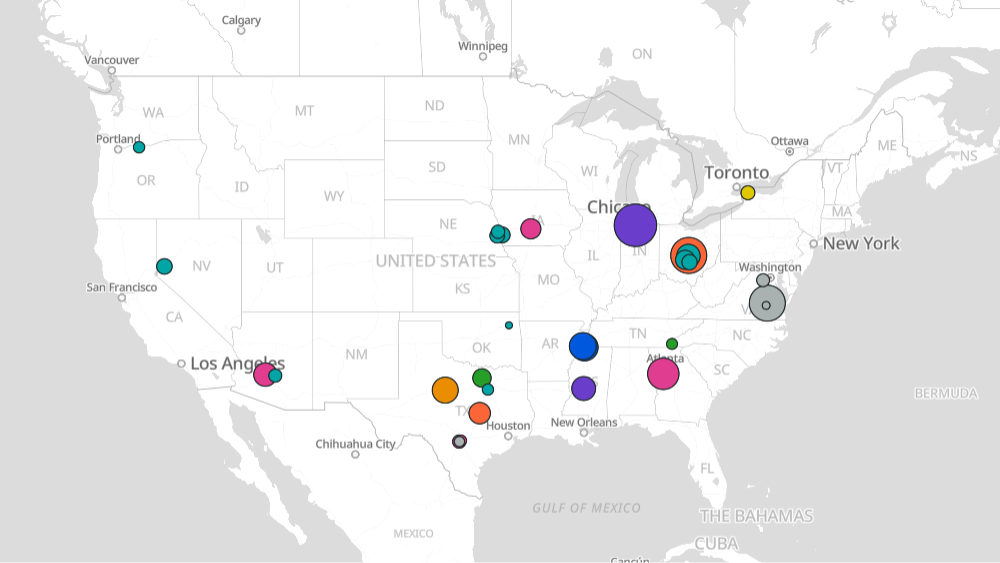
The United States has the most large-scale AI data centers, concentrated in Texas (13 sites covered), Virginia (7 sites covered), Ohio (4 sites covered), Nebraska (4 sites covered), and Iowa (4 sites covered). International facilities include Huawei Horinger in Hohhot, China and DayOne Nusajaya in Johor Bahru, Malaysia. Many new sites are clustered near major power infrastructure and fiber networks in the American Midwest and South.
The 74 AI data centers we cover have a combined 11.9 GW of IT power capacity. Total facility power is 20-50% higher due to cooling and other infrastructure overhead, pushing the real-world footprint of these 74 sites to 15.5 GW of capacity. This is more than New York City's peak demand, at 11 GW. However, the average power consumption of these data centers is typically 60–80% of capacity, due to idle time and maintenance. Individual sites range from under 50 MW—enough to power a small city like Albany, NY—to over 1000 MW, enough to power a mid-sized city like San Diego, CA.
Major AI data centers deploy NVIDIA H100, H200, and B200 GPUs, Google TPU v5 and v6 chips, and AWS Trainium2 accelerators. Hardware varies by owner: Google uses custom TPUs, Amazon deploys Trainium, while Meta, xAI, and Microsoft primarily use NVIDIA GPUs.
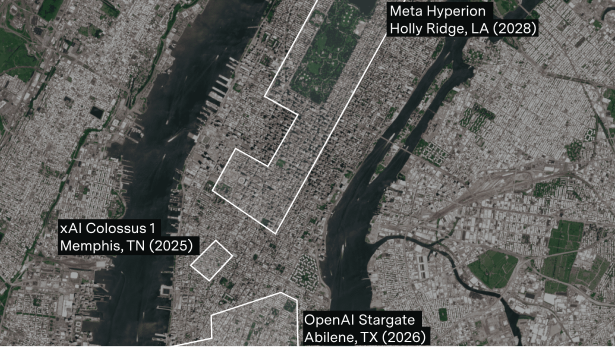
Epoch’s AI Data Centers Hub is an independent database covering the construction timelines of major AI data centers through high-resolution satellite imagery, permits, and public documents.
Epoch AI’s data is free to use, distribute, and reproduce provided the source and authors are credited under the Creative Commons Attribution license.
We mostly prioritize AI data centers by computing capacity. However, we have a lower bar for capacity internationally compared to the US, to achieve more globally balanced coverage. We also limit coverage to data centers that become operational in 2024 or later, with some exceptions. This includes planned data centers, but only if those data centers are under construction and have a significant chance of being completed. In practice, this limits most of the future coverage to 2–3 years from now.
Based on our prior work we believe most, but not all, of the largest data centers are in the United States. Additionally, focusing on the US first allowed us to become familiar with permitting standards, providing an additional source for us to validate our methodology. We continue to expand coverage in other countries.
We collect general information about each data center, such as the location, owner and users. We also collect satellite, aerial and drone images, and estimate key metrics over time as each data center evolves. Every data center we cover has a timeline of total IT power capacity, compute capacity, and capital cost.
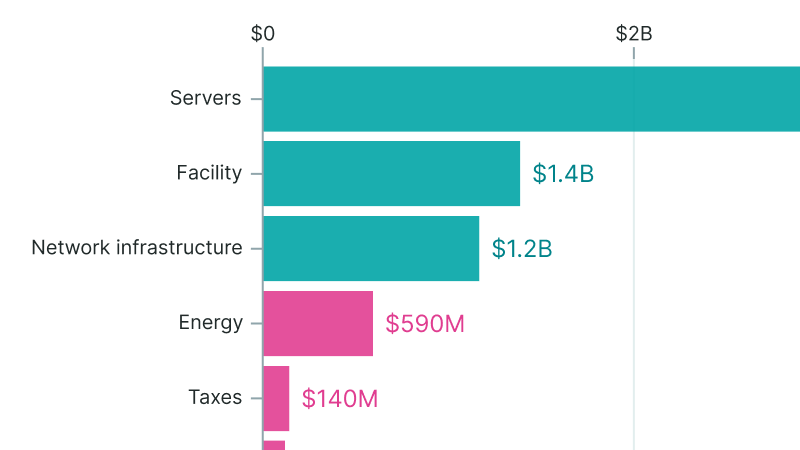
IT power is estimated for each data center based on the available evidence, which may include cooling equipment observed in satellite imagery, permitting documents, and statements from companies. Compute is usually calculated from IT power, based on the energy efficiency of chips that we believe are most likely to be used (which is mostly informed by the Chip Owners dataset). In the uncommon case where the specific type and quantity of chips is reported, then compute estimates are based on that. Capital costs are entirely calculated from IT power, based on a general cost-per-watt model. We estimate construction start dates, operation dates and expansion dates primarily from commercial satellite imagery, but also publicly available imagery and commercial drone imagery. For details, see the methodology.
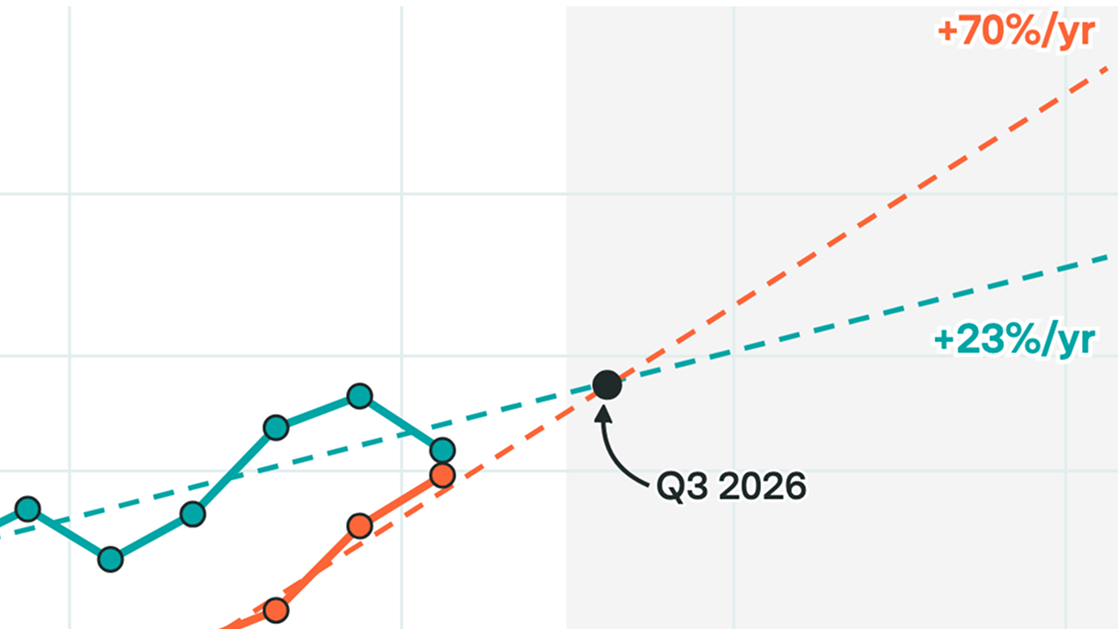
The database is the result of a continuous effort since mid-2025 to cover the largest AI data centers globally, most of which are in the US. Our database covers an estimated 27% of AI compute that has been delivered by chip manufacturers globally as of April 2026, assuming a one-quarter lag from chip sales to deployment. We continue to expand coverage in the US and other countries.
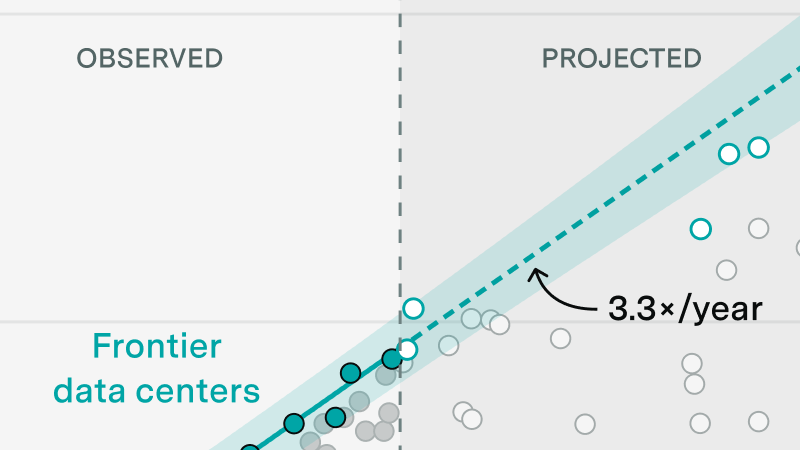
The coverage is strongest for the largest AI data centers between 2024 and 2028, because we have prioritized finding those. We believe the database captures the majority of record-holding facilities (in terms of compute capacity) during that period.
The deprecated GPU Clusters database covers computing clusters used for AI and other applications. These clusters may make up just part of the total compute present in one data center building or campus. GPU Clusters has broad coverage across time and space, but only covers an estimated 10–20% of global compute as of March 2025. In contrast, this database looks at AI data centers at a project level, and focuses on the largest current and upcoming data centers to achieve higher compute coverage. It also uses primary sources much more, including permitting and satellite imagery, to get greater detail and accuracy on individual data centers.
We model our uncertainty both in terms of quantities and construction timelines. We expect that 80% of the time, a given IT power capacity estimate is accurate within a factor of 1.4x. For compute capacity, this factor increases to 1.5x, and for cost, the factor is 1.6x. As for the timelines, we expect that 80% of the time, our estimated date is within 6 months of the actual date.
These confidence levels are informed by data on how our estimates differ from the most credible reference values, and modeling on top of that data. We expect our estimates to become more accurate as we find more data centers and do more research on how they work.
By default, if we list a user, owner, or other affiliate of a data center, we have strong evidence for it. However, sometimes we are uncertain about these affiliations, especially the data center users. We indicate this uncertainty with “Speculative” and “Likely” tags.
“Speculative” means that we have no record of an affiliation, but we have some reason to believe it. For example, we speculate that Anthropic will use two Amazon data centers in Mississippi because the New York Times reported that at least one of the Anthropic-Amazon Project Rainier data centers is located there, but they didn’t specify which ones.
“Likely” means we have some record of an affiliation, but we aren’t confident. For example, OpenAI is a “Likely” user for Microsoft Fairwater because a Microsoft spokesperson stated it “initially will be used to train OpenAI models”, but Microsoft’s partnership with OpenAI has been weakening since 2023.
This is possible, but does not happen often in practice. The total capacity of a data center is more like a cap on the size of a training run in that data center. Data centers often run multiple jobs in parallel and/or get partitioned for multiple users. Even if the entire data center is deployed on a single job, hardware failures will slightly reduce the capacity. Relatedly, when we report the total compute capacity of a data center in 8-bit OP/s, this is the theoretical peak capacity for number formats of 8 bits or above. In practice, the computational performance is typically 20–50% of the peak value, due to inefficiencies.
Need deeper insights? Our team offers custom research and advisory services.
Book a consultationHave a question? Noticed something wrong? Let us know.
Open database of AI data centers using satellite and permit data to show compute, power use, and construction timelines.