VPCT
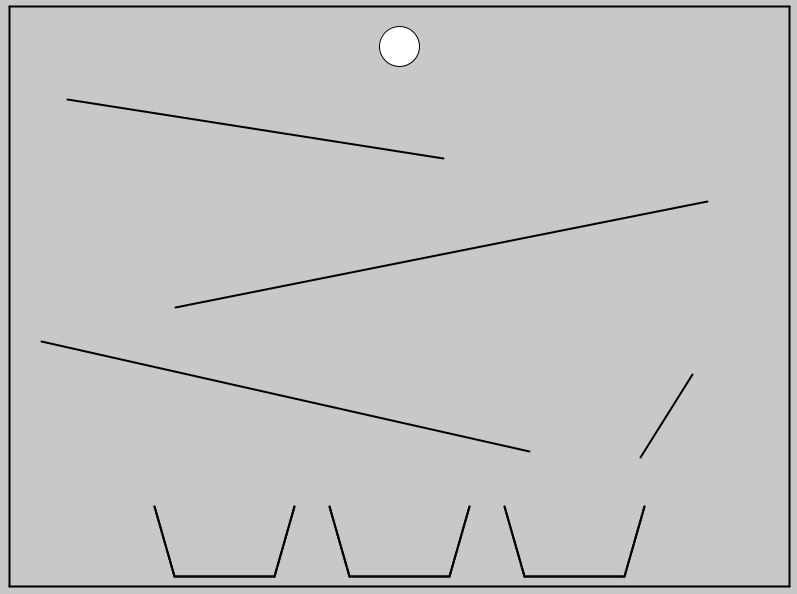
Each problem involves an image with a ball, several ramps and buckets. The task is to predict which of the buckets the ball is going to fall into. The full benchmark contains 100 problems of this format, with different ramp configurations. These tasks require a basic understanding of how a ball would move and change direction while rolling down ramps and falling to the next one.
This type of question is not challenging for most people and a set of three volunteers all scored 100% on the entire benchmark.
Methodology
We add data directly from the Visual Physics Comprehension Test web page.
The prompt used for the evaluation is the following:
You are an expert physics simulator. Looking at this image of a ball-and-bucket physics simulation, predict which bucket (numbered 1, 2, or 3 from left to right) the ball will eventually fall into.
Let’s think about this step by step:
- First, observe the initial position of the ball
- Note any obstacles or lines drawn that will affect the ball’s path
- Consider how gravity will affect the ball’s trajectory
- Think about how the ball will bounce and roll along the surfaces
- Analyze how the placement and angle of each line will guide the ball
- Factor in that the ball has some elasticity and will bounce slightly when it hits surfaces
Based on your analysis, please conclude with a clear answer in this format: ‘answer(X)’ where X is the bucket number (1, 2, or 3).
Explain your reasoning, then end with your answer in the specified format.
Reported model scores are averages over different numbers of runs, depending on the model (several models are evaluated with 2-3 runs but others are evaluated with just a single run). The evaluation code is accessible here.