
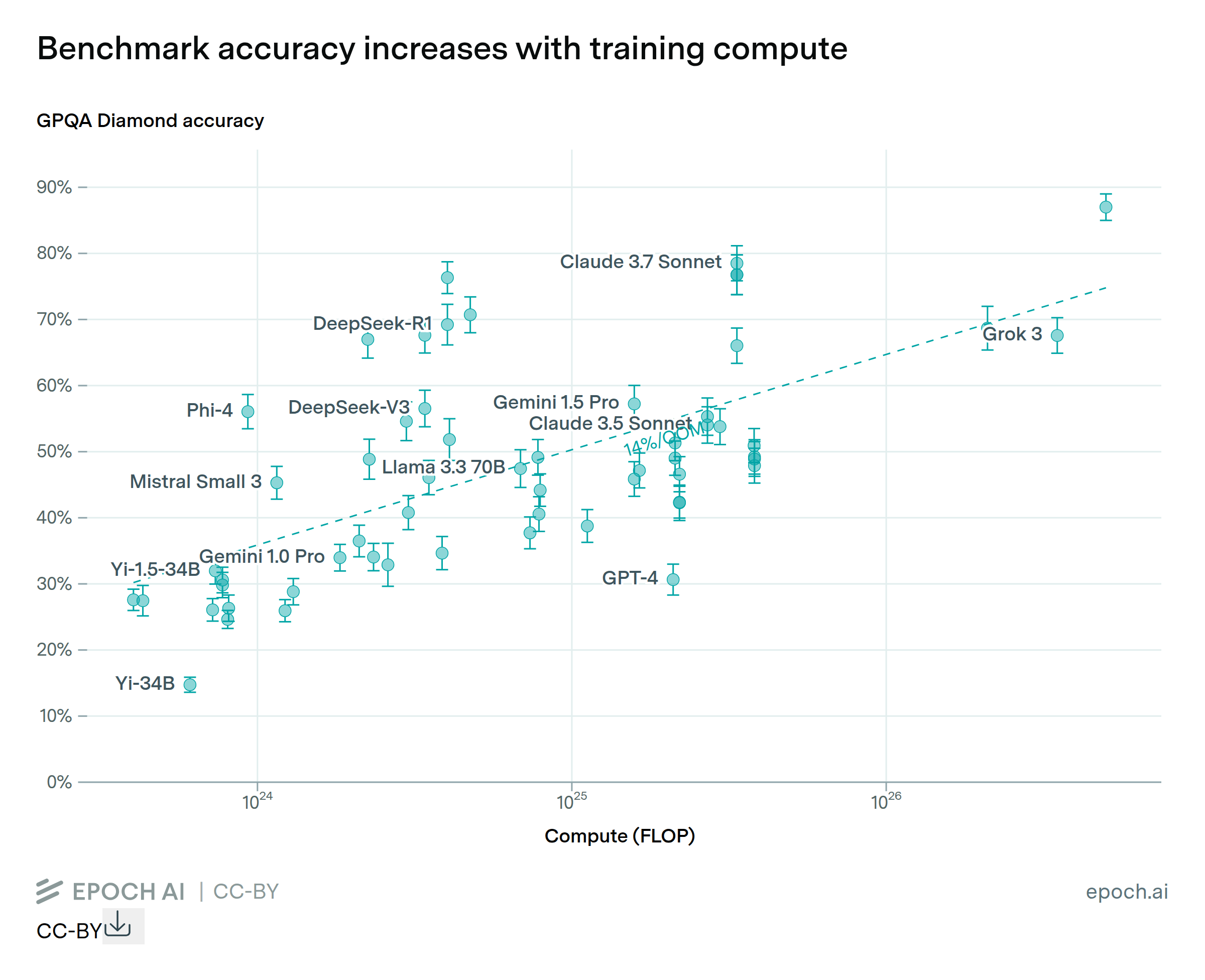
GPQA Diamond and MATH Level 5 accuracies increase with estimated training compute. For GPQA Diamond, below 1024 FLOP most models struggle to rise above random chance performance — or even perform worse than random chance, due to failing to understand question formatting. Past 1024 FLOP, performance increases around 12 percentage points with every 10x increase of compute.

On MATH Level 5, models with high compute estimates also tend to have higher scores: performance increases around 17 percentage points with every 10x increase in pretraining compute. However, the trend is much noisier than for GPQA Diamond.
On both benchmarks, more recent models such as DeepSeek-R1, Phi-4, or Mistral Small 3 outperform older models trained with the same amount of compute, highlighting the role of algorithmic progress. Finally, note that these trends exclude many of the top-performing models, such as OpenAI’s o1, which we lack compute estimates for.
Epoch's work is free to use, distribute, and reproduce provided the source and authors are credited under the Creative Commons BY license.
Explore this data
Benchmark results featuring the performance of leading AI models on challenging tasks.