

The training compute of top AI models trained on biological data grew rapidly in 2019-2021, but has scaled at a more sustainable pace since then (2-4x per year). Training compute for these models increased by 1,000x-10,000x between 2018 and 2021, but has only increased 10x-100x since 2021.
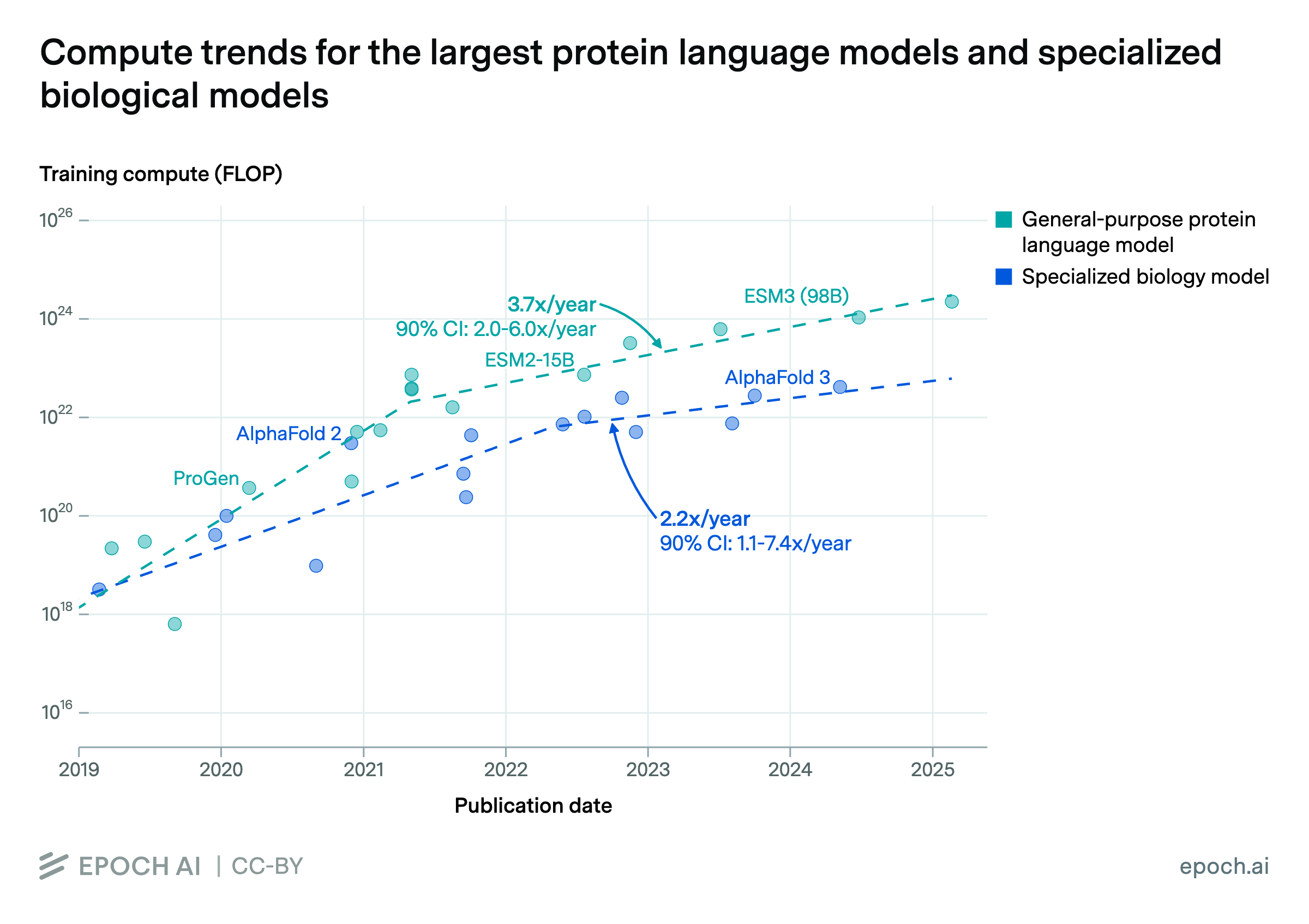
We consider two categories of biology AI models. General-purpose protein language models (PLMs) like Evo 2 learn to predict biological sequences, and can generate embeddings that are useful across many tasks. Specialized models like AlphaFold are optimized for specific predictions such as protein structure or mutation effects. PLMs are trained using about 10x more compute than specialized models, but still lag about 100x behind today’s frontier language models, which now are trained with over 1e26 FLOP.
Epoch's work is free to use, distribute, and reproduce provided the source and authors are credited under the Creative Commons BY license.
Learn more about this graph
Our Biology AI Models dataset distinguishes between two categories: protein language models and specialized protein models. Protein language models (e.g., ProGen and ESM) are generative models trained on biological sequences, while specialized models (e.g., AlphaFold) predict specific protein properties such as structure and fitness. These categories differ in their architectures, data modalities, and computational requirements—with top protein language models using approximately 10x more training compute than their specialized counterparts. Given these fundamental differences, we separated these model types to avoid conflating potentially distinct scaling trends.
Both sets of models were each narrowed down to the rolling top 4 by training compute, to focus on the frontier of scaling for each model type. The trendlines in the figure are the best overall fit after searching over breakpoints in a two-segment, log-linear regression model, as well as log-linear models with no breakpoints.
Data
Analysis
Explore this data
Our comprehensive database of over 3500 models tracks key factors driving machine learning progress.