

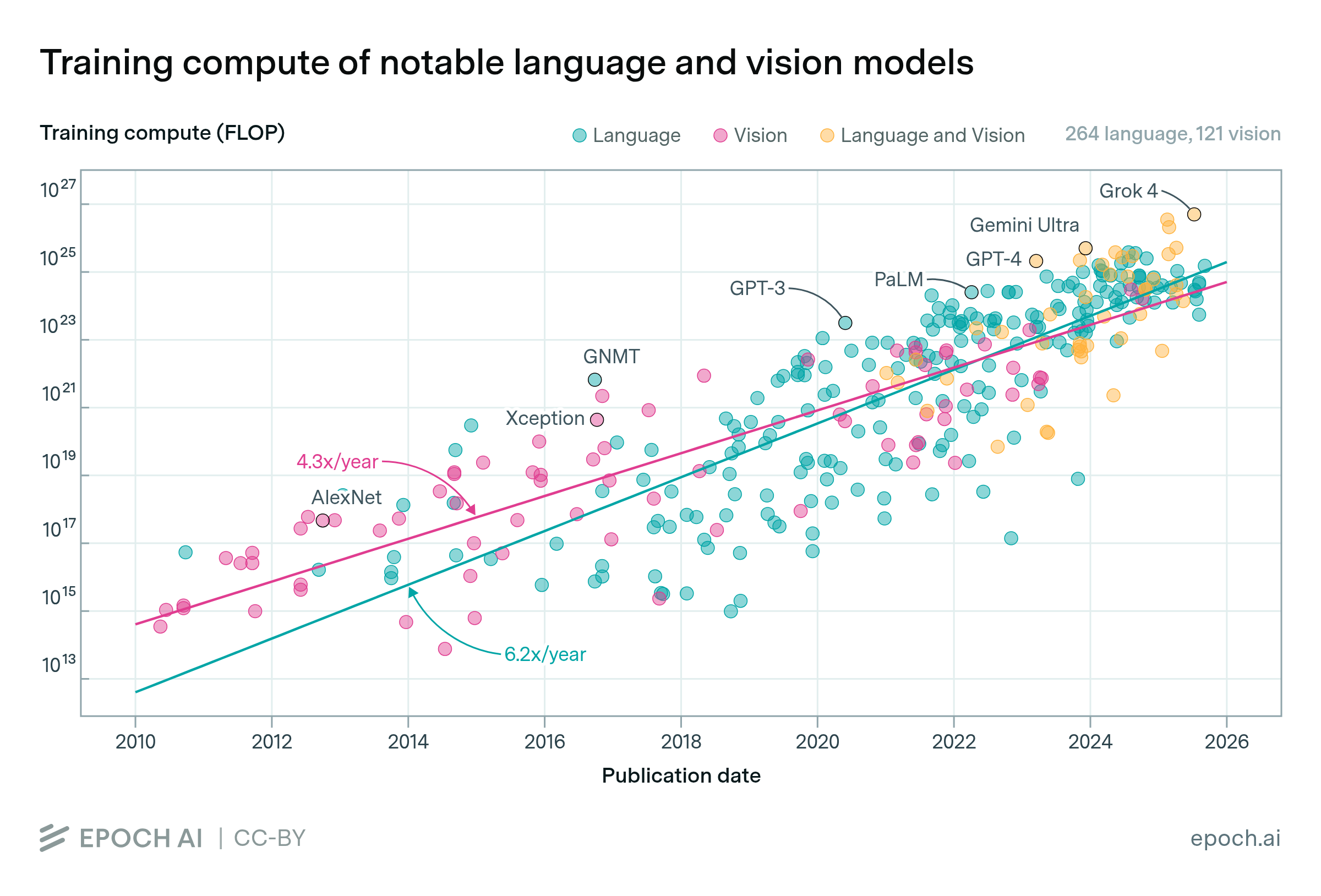
Before 2020, the largest vision and language models had similar training compute. After that, language models rapidly scaled to use more training compute, driven by the success of transformer-based architectures. Standalone vision models never caught up. Instead, the largest models have recently become multimodal, integrating vision and other modalities into large models such as GPT-4 and Gemini.
Epoch's work is free to use, distribute, and reproduce provided the source and authors are credited under the Creative Commons BY license.
Explore this data
Our comprehensive database of over 3500 models tracks key factors driving machine learning progress.