Robotic manipulation covers a wide range of tasks, from folding laundry to doing electrical work. Despite recent advances in AI, current manipulation models struggle to achieve generality and dexterity in the real world. However, compute doesn’t seem to be the blocker: in our dataset, the largest manipulation models typically train with ~1% of the compute used by frontier AI models in other domains.
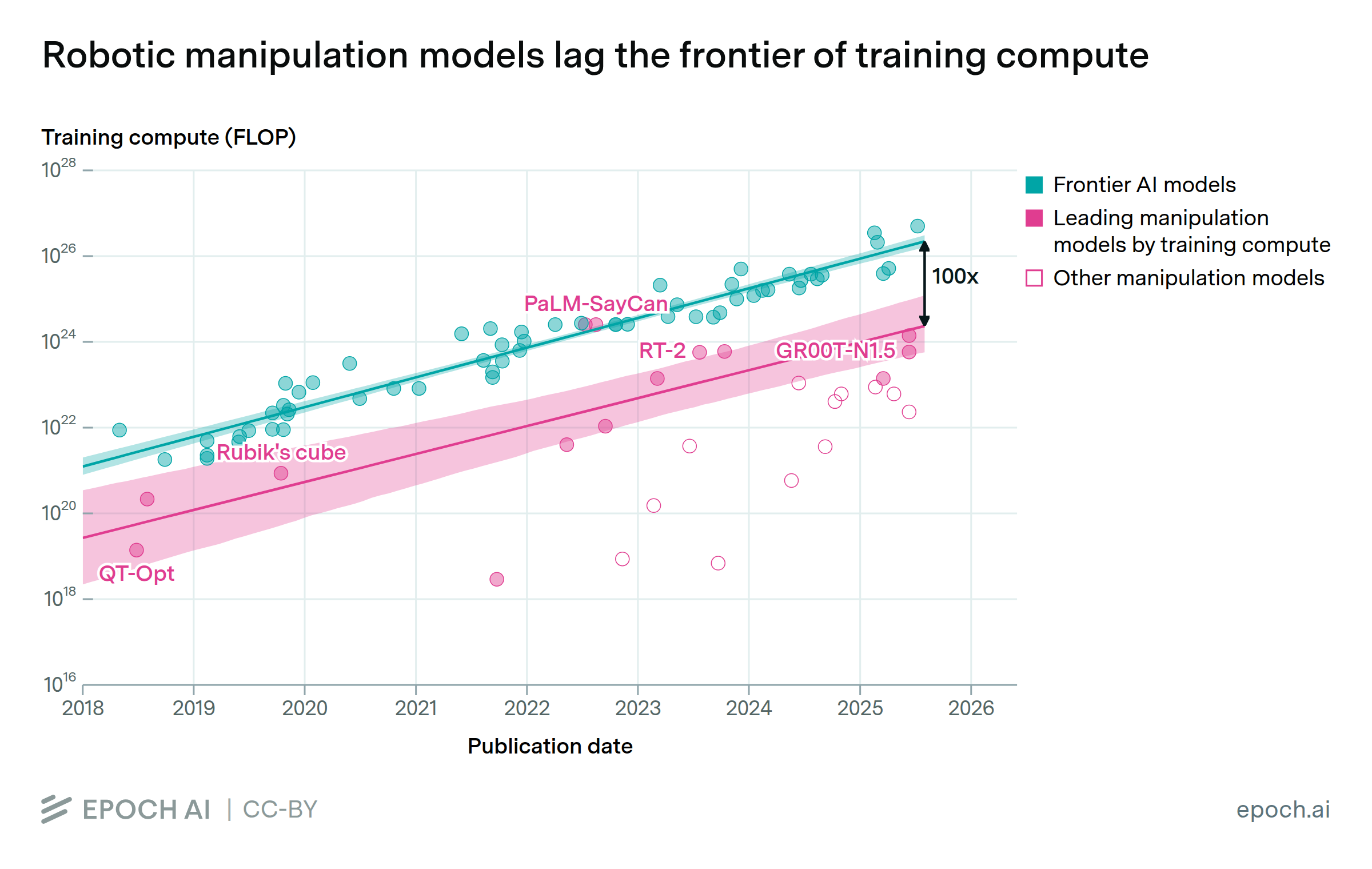
Because many of the strongest manipulation systems come from the same labs that build much larger frontier models, this gap likely reflects limits on how effectively compute can be used under current conditions, rather than a lack of access or willingness to scale. Scarcity of robotics data and hardware constraints may both play a role. If these constraints ease, a large compute overhang could translate into faster capability gains.
Epoch's work is free to use, distribute, and reproduce provided the source and authors are credited under the Creative Commons BY license.
Learn more about this graph
The data on robot manipulation models comes from our new Robotics dataset, and the data on frontier AI models comes from our AI Models database. We used several sources to curate robotic manipulation models: Awesome LLM Robotics, Awesome Robotics Foundation Models, suggestions by two robotics experts, and existing entries in our AI Models database. We also added works that were missed by these sources but seemed notable, e.g. RDT-1B.
After curating works on robotics, we manually filtered to works that show a real-world evaluation on a manipulation task, to ensure the model had real-world relevance. We then estimated the training compute of those models, producing 26 data points. Finally, we filtered to the rolling top-5 points by training compute, leaving 14 “leading” models to fit a trend to. For frontier AI models, we filtered all AI models down to the rolling top-5 and then to models since 2018.
Analysis
Assumptions
Explore this data
Our comprehensive database of over 3500 models tracks key factors driving machine learning progress.
Related insights