

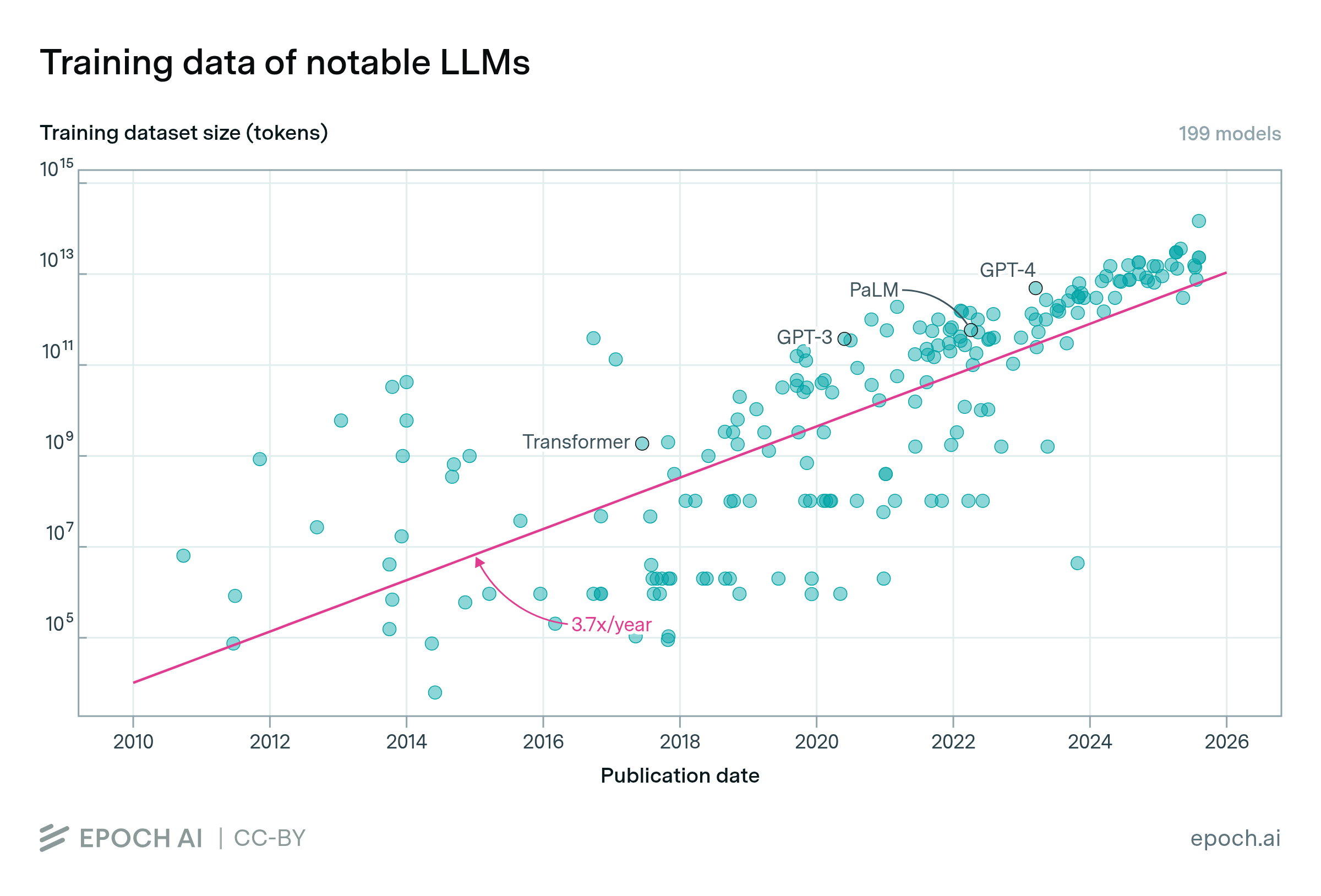
Across all domains of ML, models are using more and more training data. In language modeling, datasets are growing at a rate of 3.7x per year. The largest models currently use datasets with tens of trillions of words. The largest public datasets are about ten times larger than this, for example Common Crawl contains hundreds of trillions of words before filtering.
Epoch's work is free to use, distribute, and reproduce provided the source and authors are credited under the Creative Commons BY license.
Explore this data
Our comprehensive database of over 3500 models tracks key factors driving machine learning progress.