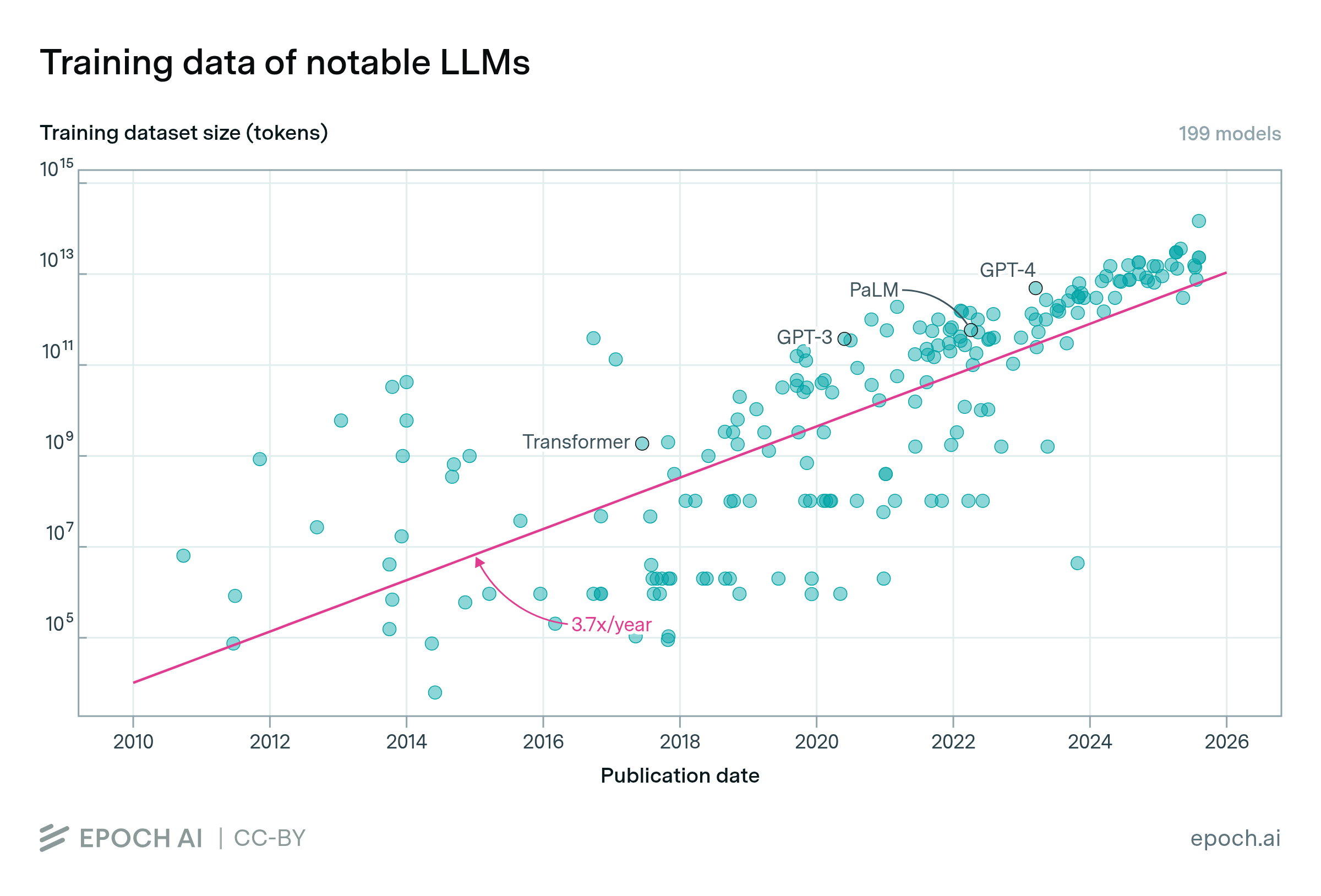
The ratio of training data to active parameters in open-weight LLMs has grown 3.1x per year since 2022. Recent models have been trained with 20 times more data per parameter than the optimal ratio suggested by the 2022 Chinchilla scaling laws. Our analysis focuses on open-weights models, where information on training tokens and parameters is more available.
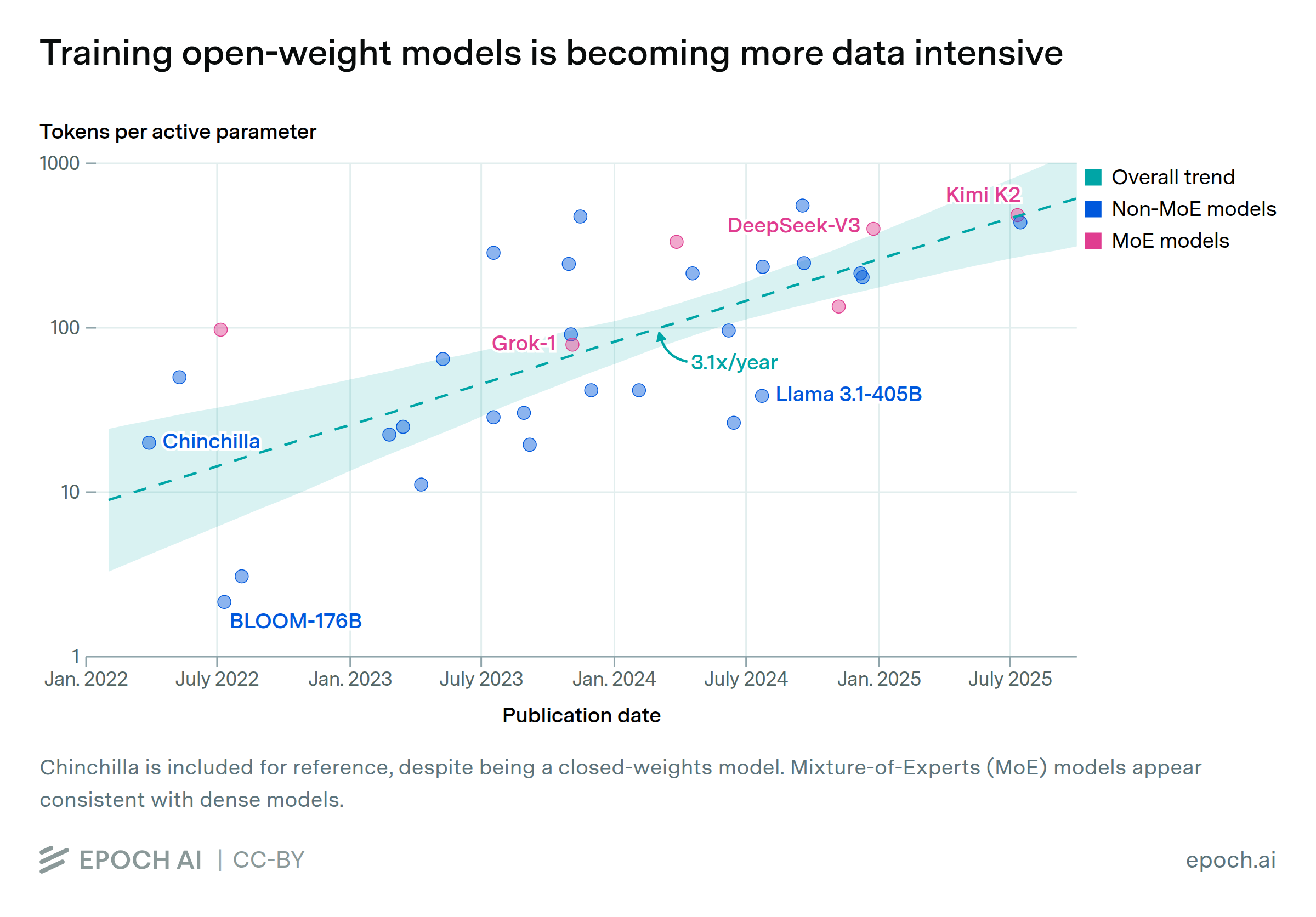
This trend could be driven by economic incentives: models trained on higher tokens per parameter ratios can achieve comparable performance with fewer parameters, making them less expensive to serve at inference time. Open-weight developers may also favor scaling data rather than parameters to keep their models accessible for users to run on their local infrastructure.
Epoch's work is free to use, distribute, and reproduce provided the source and authors are credited under the Creative Commons BY license.
Learn more about this graph
We explore trends in the number of tokens per active parameter used to train notable open-weight language models. Tokens per parameter is the total number of training tokens - calculated as dataset size multiplied by epochs - divided by the number of activated parameters on a forward pass. Our analysis shows an upward trend: the average tokens per parameter was approximately 10 in 2022 and climbed to around 300 by 2025.
However, it is important to note that this trend may not hold for closed models, which include many current frontier models. We lack public data to estimate their token-to-parameter ratios.
Code for this analysis is available here.
Data
Analysis
Assumptions
Explore this data
Our comprehensive database of over 3500 models tracks key factors driving machine learning progress.
Related insights