




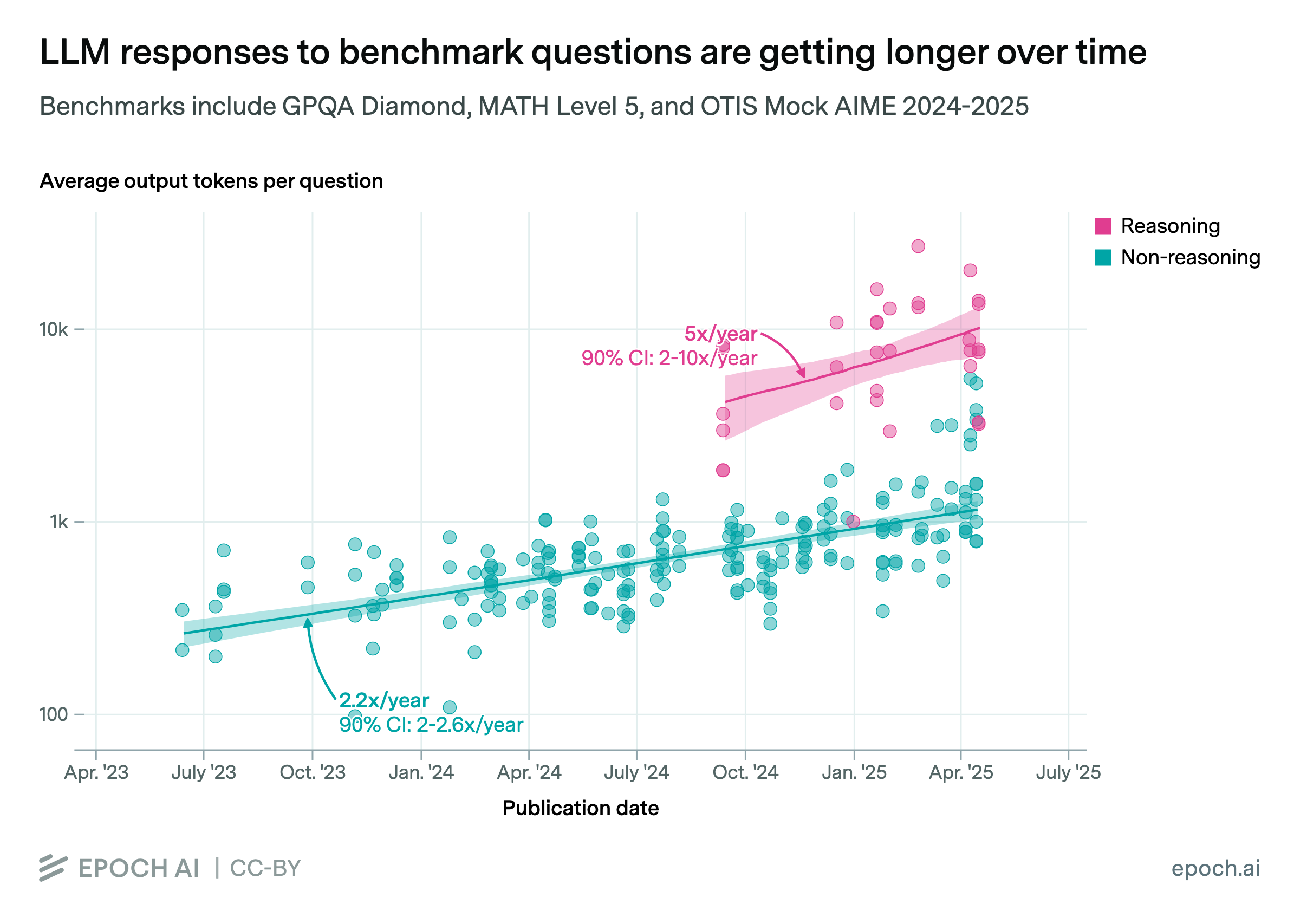
The length of responses generated by language models to benchmark questions has increased over time for both reasoning and non-reasoning models. According to our internal benchmarks, reasoning models’ responses are growing considerably faster (5x per year) than those from non-reasoning models (2.2x per year). Reasoning models also exhibit longer response lengths overall – currently, around 8x more tokens on average, compared to non-reasoning models.
Reasoning models have been shown to produce more reasoning tokens as the amount of RL training is scaled up. The explanation for longer responses from non-reasoning models is less clear, but it may reflect trends toward extended context lengths, judges’ preferences for longer responses when generating RLHF data, or a growing use of context distillation from Chain of Thought prompting. Finally, while today’s models are cleanly separable into reasoning vs. non-reasoning, there are indications that future models (like GPT-5) may blur this line.
Epoch's work is free to use, distribute, and reproduce provided the source and authors are credited under the Creative Commons BY license.
Learn more about this graph
Using data from Epoch’s Benchmarking Hub, we identify the average length of model responses across GPQA Diamond, MATH Level 5, and OTIS Mock AIME 2024-2025, and plot the trend over time. We observe that output lengths from reasoning models have grown significantly faster than their non-reasoning counterparts (5x per year, vs 2.2x). Unsurprisingly, we also find that reasoning models use far more tokens than non-reasoning models.
Code for our analysis is available here.
Data
Analysis
Assumptions
Explore this data
Benchmark results featuring the performance of leading AI models on challenging tasks.