

A core problem in assessing trends in AI capabilities is that benchmarks tend to saturate within 1-3 years. The Epoch Capabilities Index allows comparisons across a wide range of model capabilities, by stitching together benchmarks.
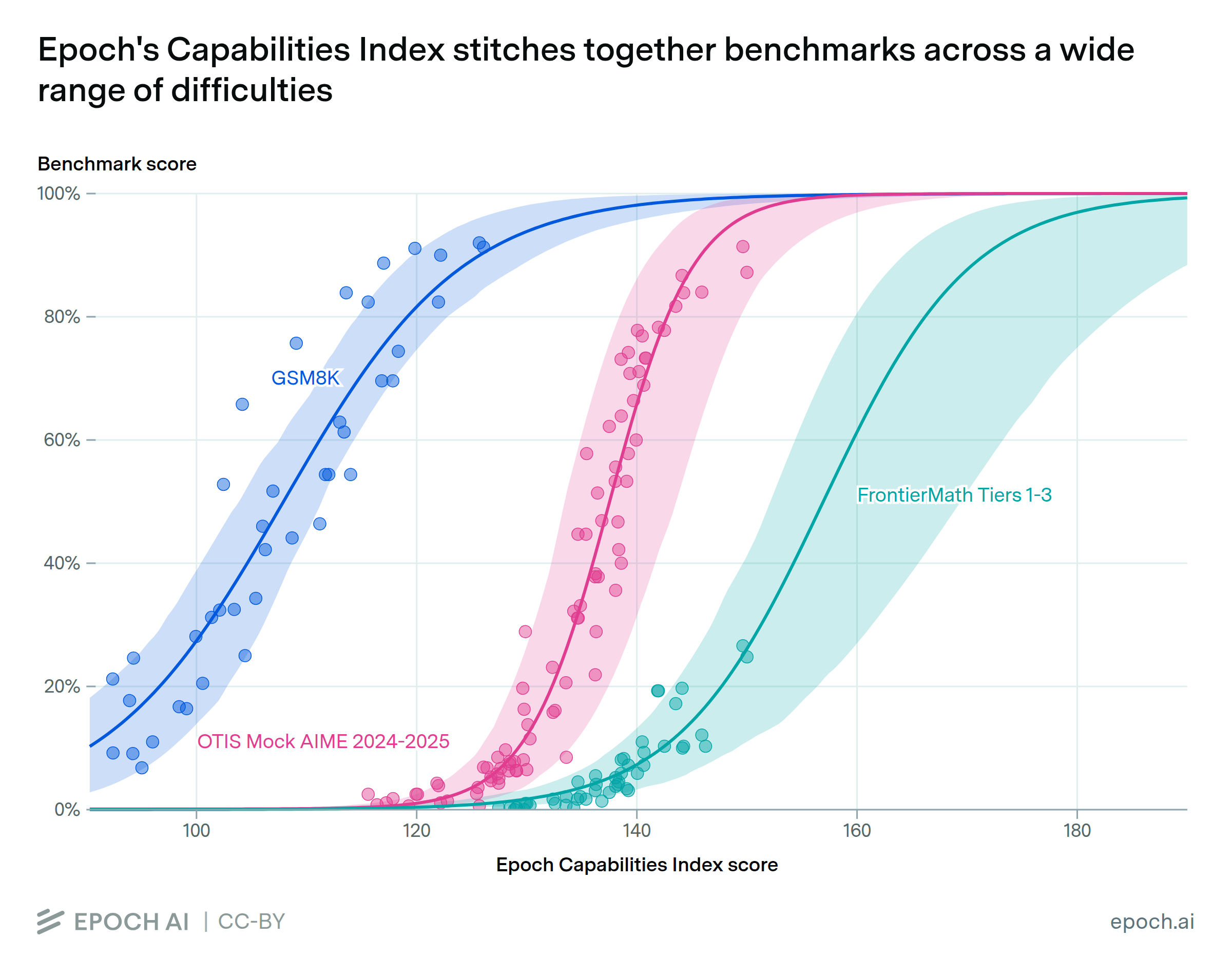
The ECI uses an abstract scale, but scores can be interpreted by calculating the expected performance on individual benchmarks. In the chart above, we show expected benchmark performance across a range of ECI values for GSM8K, OTIS Mock AIME 2024-2025, and FrontierMath Tier 1-3.
Epoch's work is free to use, distribute, and reproduce provided the source and authors are credited under the Creative Commons BY license.
Learn more about this graph
One way of interpreting an Epoch Capabilities Index (ECI) score is by calculating the expected performance on individual benchmarks based only on the ECI score. We plot this relationship for GSM8K, OTIS Mock AIME 2024-2025, and FrontierMath Tier 1-3, three benchmarks that vary considerably in difficulty. We also show 90% confidence intervals as a shaded region.
Data
Analysis
Limitations
Explore this data
Benchmark results featuring the performance of leading AI models on challenging tasks.