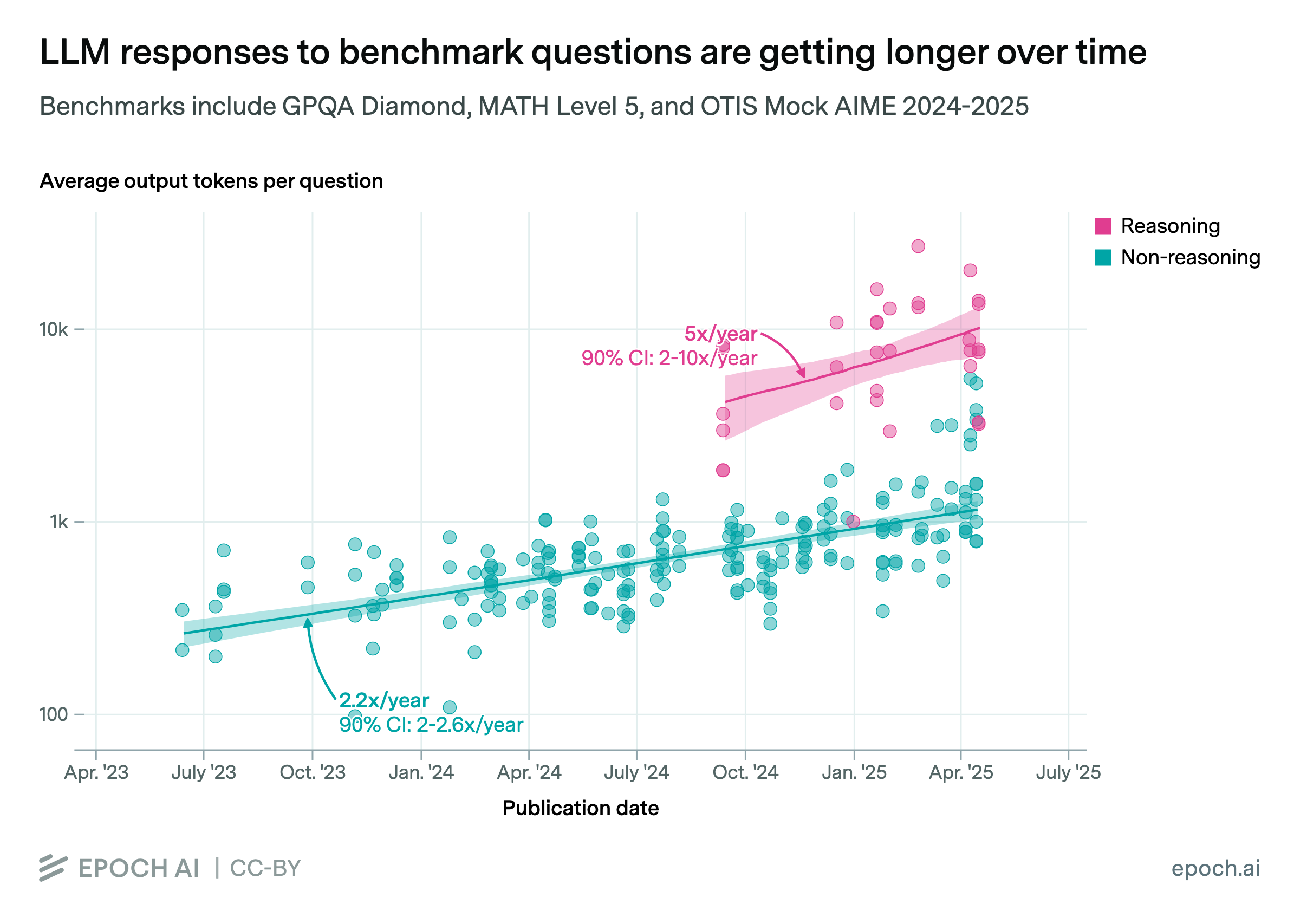
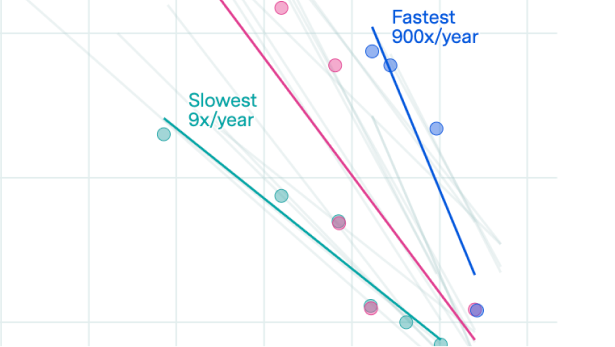
Across major language model providers, the models that achieve higher accuracy on benchmarks also take longer to run. Along the accuracy-runtime trade-off frontier, cutting the error rate in half typically slows the model by roughly 2x to 6x, depending on the task.
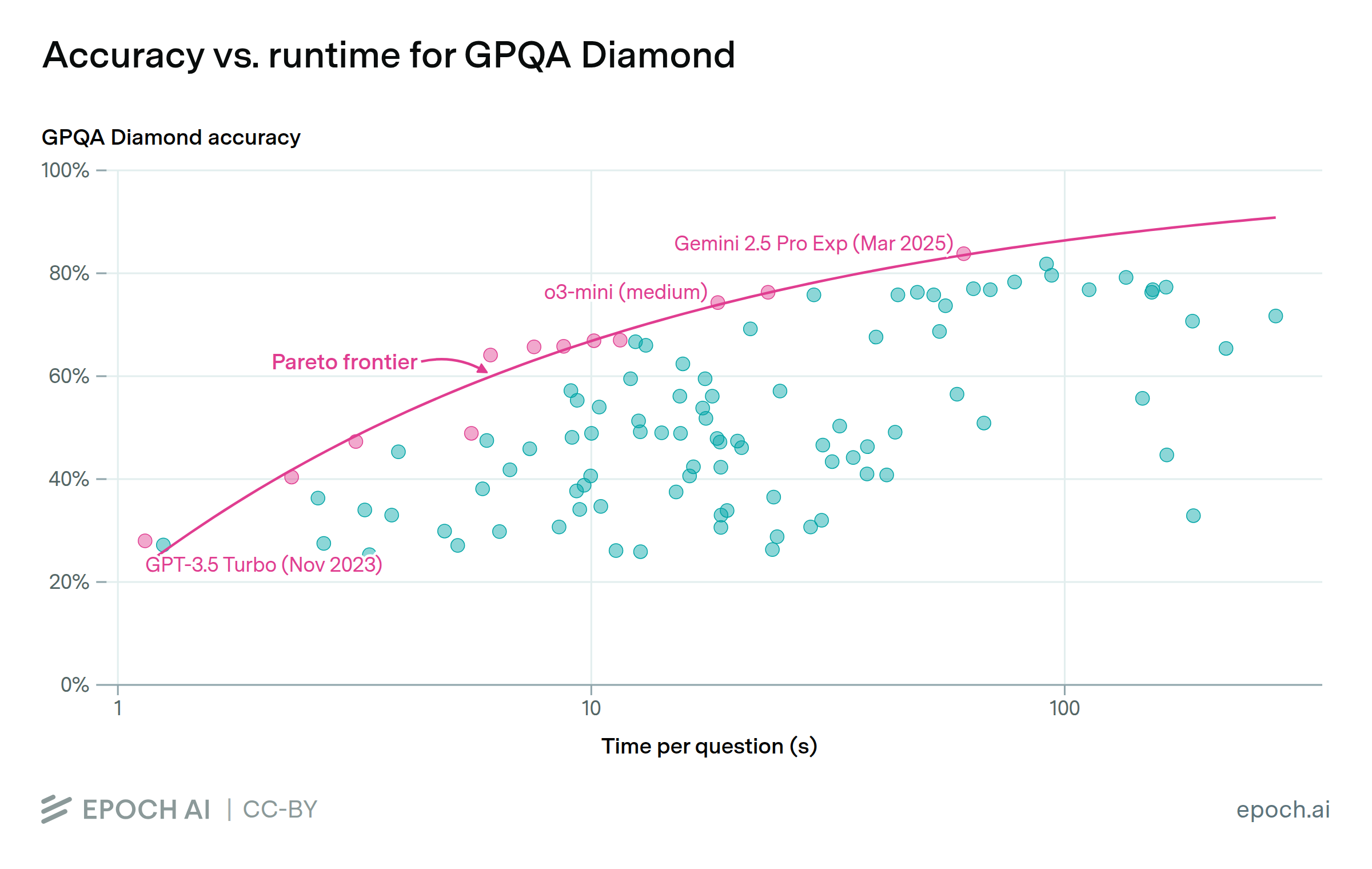


LLM providers have several ways to balance performance against cost, such as model size, query batching, and quantization. Many of the models on the speed-accuracy trade-off frontiers appear to have been designed with efficiency in mind: over half of them are labeled turbo, flash, mini, or nano. The models on this frontier are mostly from two providers: OpenAI and Google.
Epoch's work is free to use, distribute, and reproduce provided the source and authors are credited under the Creative Commons BY license.
Learn more about this graph
Using Epoch’s internal benchmarking data, we measure the average time taken to answer a question across several benchmarks: GPQA Diamond, MATH Level 5, and OTIS Mock AIME 2024-2025. We plot this against each model’s accuracy on that benchmark. We focus on the Pareto frontier of models, i.e. those that are faster than all more accurate models, or more accurate than all faster models. We model the trade-off as an exponential decay in error rate with respect to the log of runtime. We observe a halving of error rate as being associated with a 6.0x, 1.7x, and 2.8x increase in runtime, respectively.
We also note that, of models appearing on at least one of these frontiers, 12/19 have “flash”, “mini”, or “nano” in their names. These generally correspond to smaller versions of larger models that are specifically optimized for speed and cost, using techniques like distillation.
Code for our analysis is available here.
Data
Analysis
Assumptions and limitations
Explore this data
Benchmark results featuring the performance of leading AI models on challenging tasks.
Related insights