Between the release of the original Transformer in 2017 and the release of GPT-4, language models at the frontier of capabilities became much larger. Parameter counts were scaled up by 1000 times from 117 million to 175 billion between GPT-1 and GPT-3 in the span of two years and by another 10 times from 175 billion to 1.8 trillion between GPT-3 and GPT-4 in the span of the next two years and nine months.
If the post GPT-3 trend had continued, given that GPT-4 was released in March 2023, by now we could have expected to see models with close to 10 trillion parameters, around 4 times bigger than GPT-4. However, in 2023, the trend of frontier language models becoming bigger reversed. Let alone reaching the 10 trillion parameter mark, current frontier models such as the original GPT-4o and Claude 3.5 Sonnet are probably an order of magnitude smaller than GPT-4, with 4o having around 200 billion and 3.5 Sonnet around 400 billion parameters.
In this issue, I’ll explain how we know this change has happened despite frontier labs not releasing architectural details, which factors I think were responsible for the trend reversal, and why I don’t expect this reversed trend to continue.
How do we know this has happened?
First, there’s the open weights evidence. According to the model quality index from Artificial Analysis, which is computed by taking many different benchmark scores into account, the best open weights models right now are Mistral Large 2 and Llama 3.3 70B, having 123 billion and 70 billion parameters respectively. These models are dense Transformers, similar to GPT-3 in architecture, but with even fewer parameters. Their overall benchmark performance is better than previous generation models such as the original GPT-4 and Claude 3 Opus, and due to their smaller parameter count they are much cheaper and faster to inference.
For closed weights models we often don’t know the exact number of parameters, but we can still make a guess based on how fast models are served and how much labs charge for them. Focusing only on short context requests, OpenAI serves the November 2024 version of GPT-4o at 100-150 output tokens per second per user and charges $10 per million output tokens, compared to GPT-4 Turbo which is served at most around 55 output tokens per second and costs $30 per million output tokens. GPT-4 Turbo is cheaper than the original GPT-4 which is currently priced at $60 per million output tokens, and GPT-4o is much cheaper and faster than GPT-4 Turbo, so it seems likely GPT-4o is a much smaller model than GPT-4.
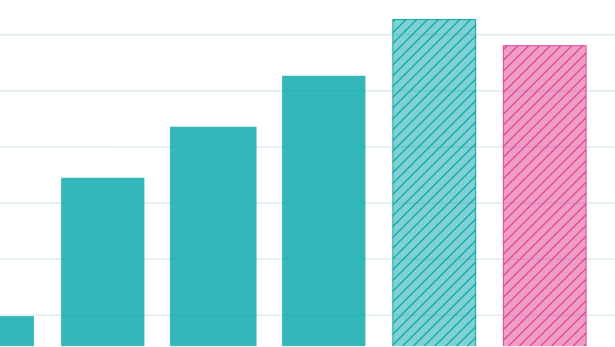
We can also use theoretical models of inference economics to predict how cheaply GPT-4 could be served on H200s. Assuming an opportunity cost of $3 per hour for using an H200 to do inference, the figure below shows how fast we can generate tokens at which price points when serving GPT-4 and hypothetical scaled-down versions of it for inference.
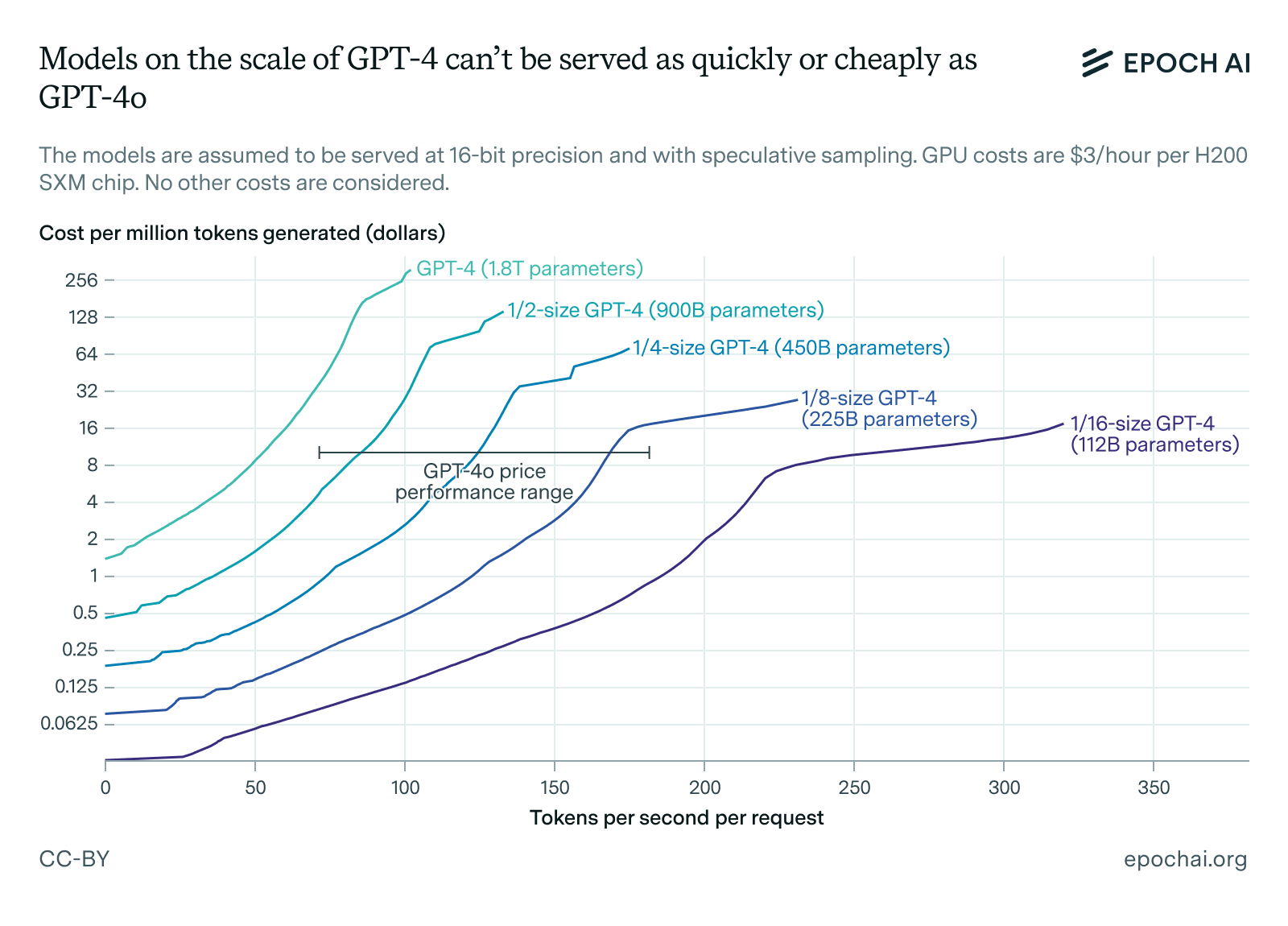
Figure 1: Pareto frontiers for token generation speed per request versus cost per million tokens generated on scaled-down versions of GPT-4. The results are based on an internal Epoch model.
Overall, for us to not only serve a model at speeds over 100 tokens per second per user but to do so comfortably, we need the model to be much smaller than GPT-4. Based on the plot above, depending on the size of the markups we can assume OpenAI charges over GPU costs, GPT-4o is probably somewhere around an eighth of the size of GPT-4. This would put its total parameter count around 200 billion, though this estimate could easily be off by a factor of 2 given the rough way I’ve arrived at it.
There’s some evidence that Anthropic’s best model, Claude 3.5 Sonnet, might be a larger model than GPT-4o. Indeed, Sonnet is served only at around 60 tokens per second and costs $15 per million output tokens, and with a very optimized setup this might be sufficient to serve even the original GPT-4 at breakeven. Because we assume Anthropic likely charges significant API markups, the true size of Sonnet 3.5 should still be significantly smaller than GPT-4. A guess of around 400 billion parameters seems reasonable when we also take into account that Anthropic’s inference speed doesn’t substantially decline even at a context length of 100K tokens.
So this leaves us with a world in which the largest frontier models have around 400 billion parameters, such as Llama 3.1 405B and, speculatively, Claude 3.5 Sonnet; and many have fewer parameters than that. Though the parameter estimates for the closed models are rather uncertain, we can still infer the scale-down from GPT-4 and Claude 3 Opus to current frontier models is probably close to an order of magnitude.
Why did this happen?
Having established how we know models have become much smaller, we can move on to exploring the reasons behind the trend reversal in 2023. There are four major reasons that I see behind this:
The rapid increase in demand for AI products following the release of GPT-4. After the ChatGPT moment in December 2022 and the release of GPT-4 in March 2023, interest in AI products exploded. This led to providers being overwhelmed by an inference demand that likely far exceeded their initial expectations. Previously, from 2020 to March 2023, models were trained based on the criterion of minimizing training compute for a fixed level of capability; and both the Kaplan and Chinchilla scaling laws recommend scaling up models as their training compute increases to accomplish this. However, when inference becomes a substantial or dominant part of your spending on a model, it’s better to overtrain models relative to these recommendations, i.e. train smaller models on more tokens. The result is you can end up scaling training compute without scaling model size, as happened with the jump from Llama 2 70B to Llama 3 70B.
In addition to overtraining, labs have also used another method called distillation to make their smaller models punch above their weight. Distillation means trying to get a smaller model to match the performance of a larger model that has already been trained. There are many ways to distill large models into smaller ones. A simple one is to use the large model to generate a high-quality synthetic dataset for the small model to be trained on, and there are more complex methods that rely on having access to the large model’s internals (such as its hidden states and logprobs). I think both GPT-4o and Claude 3.5 Sonnet have likely been distilled down from larger models.
The shift from Kaplan to Chinchilla scaling laws. In general, the Kaplan scaling laws from Kaplan et al. (2020) recommend a far higher parameters to training tokens ratio than the Chinchilla scaling law from Hoffmann et al. (2022). Because training compute is roughly proportional to active parameters times the number of training tokens, the shift from Kaplan to Chinchilla led to models that were smaller but trained on more data. The effect of this was similar to overtraining, but the underlying driver is a change in our understanding of how to do pretraining scaling as opposed to an unanticipated increase in inference demand.
Test-time compute scaling. Over time, improved in-context reasoning methods have increased the value of doing more and lower latency token generation during inference. The old benchmark for whether a model was “fast enough” used to be around human reading speed, but when a model generates 10 reasoning tokens for each output token that is shown to the user, it becomes substantially more valuable to have models that can generate tokens more efficiently. This has driven labs pursuing test-time compute scaling as a way to improve complex reasoning performance, e.g. OpenAI, to shrink their models more aggressively.
Synthetic data generation. Labs are increasingly interested in training their models on expensive synthetic data, providing yet another reason to make the models smaller. Synthetic data opens up a new avenue for training compute scaling beyond the usual means of increasing model parameter counts and training dataset sizes (in other words, beyond pretraining compute scaling). Instead of getting the tokens used for training from internet scraping, we can instead generate the tokens that we will later use in training, much like AlphaGo generated the games that it was simultaneously trained on through self-play. This way, we can maintain the compute-optimal tokens-to-parameters ratio from the Chinchilla scaling law, but pack a lot more compute into each of our training tokens when we’re generating them, increasing training compute without increasing model size.
Should we expect frontier models to keep getting smaller?
The short answer is probably not, though it’s harder to say if we should expect them to get much bigger than GPT-4 in the near term.
The shift from Kaplan to Chinchilla scaling laws is a one-time effect, so we have no reason to expect it to keep making models smaller. The jump in inference demand we’ve seen after the release of GPT-4 is also probably faster than the rate of growth in inference spending we can expect in the near future. Test-time compute scaling and synthetic data generation have not yet been fully incorporated by all of the labs, but even with high-quality training data there are likely limits to how much can be achieved by models that are very small.
In addition to this, continuing hardware progress probably makes optimal model sizes bigger even if we take synthetic data and test-time scaling into account, because if two models of different sizes are given the same inference budget, we expect the larger one to do better as the budget is scaled up. The smaller model could lose coherence over longer contexts or lack the more complex pattern recognition skills needed to solve harder problems, making its performance scale worse with inference compute even though it performs better when inference budgets are very limited.
The next generation of models, corresponding to GPT-5 and Claude 4 (or Claude 3.5 Opus) will probably return to or slightly exceed the size of the original GPT-4. After this, it’s difficult to say if we will have another period where frontier model sizes plateau or not. In principle, even our current hardware is good enough to serve models much bigger than GPT-4: for example, a 50 times scaled up version of GPT-4, having around 100 trillion parameters, could probably be served at $3000 per million output tokens and 10-20 tokens per second of output speed. However, for this to be viable, those big models would have to unlock a lot of economic value for the customers using them.
My guess is the budget of most customers will be small enough that models in the 1 to 10 trillion parameters range will use test-time compute scaling to beat out 100 trillion parameter models even if the big models produce that much economic value. This is mostly because I think the 100 trillion parameter models are getting close to the expense of hiring a human to do the task you want done even if we ignore test-time compute scaling. However, this is only speculation and I wouldn’t put too much weight into it.
To summarize the discussion, here’s where I land:
-
There’s around an 80% likelihood that most next generation models—probably due in the first half of next year—will have more parameters than GPT-4.
-
After the initial release of these next-generation models, there’s about a 60% probability that frontier model sizes will expand by less than a factor of 10 over the subsequent three years, indicating a slower growth rate compared to the jump from GPT-3 to GPT-4.
About the authors

Related work