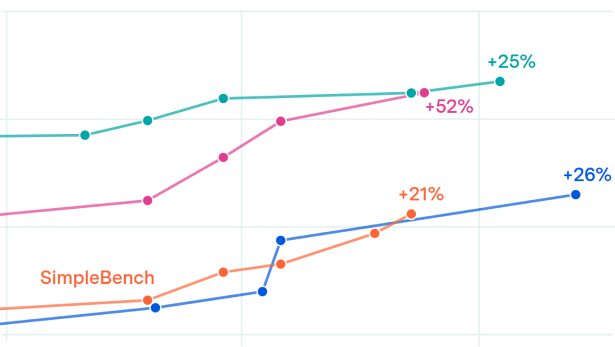
The best score on the Epoch Capabilities Index grew almost twice as fast over the last two years as it did over the two years before that, with a 90% acceleration in April 2024. This is consistent with a similar 2024 acceleration seen in the METR Time Horizon benchmark of 40% in October of 2024. The acceleration roughly coincides with the rise of reasoning models and an increasing focus on reinforcement learning among frontier labs.


In order to provide additional data we include pre-2023 models, which are currently filtered out from the Benchmarking Hub due to the comparative sparsity of benchmark scores during that time. Our conclusions do not change substantially if this data is excluded.
Epoch's work is free to use, distribute, and reproduce provided the source and authors are credited under the Creative Commons BY license.
Learn more about this graph
Using the Epoch Capabilities Index, we compare simple models of AI capability trends, finding that the best-fitting model features an acceleration in improvement around April 2024. The rate of frontier improvement nearly doubled, from about 8 points/year before the breakpoint to 15 points/year after. HCAST-based estimates of this inflection point yield similar results.
Data
Analysis
Assumptions and limitations
Errata
Explore this data
Benchmark results featuring the performance of leading AI models on challenging tasks.
Related insights