Related work

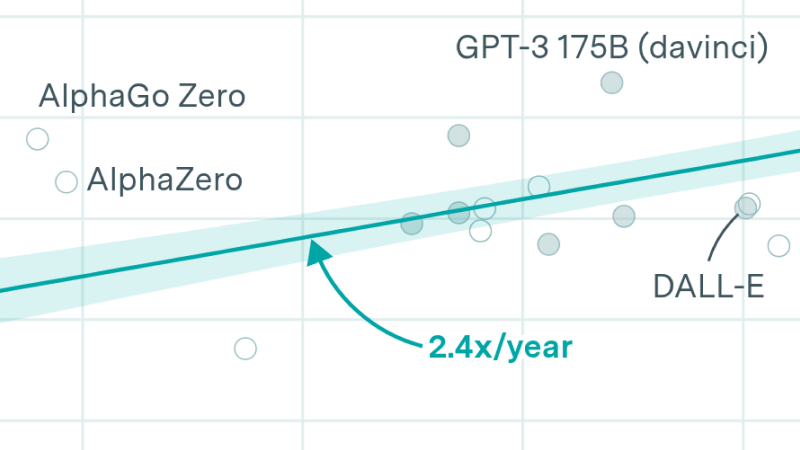
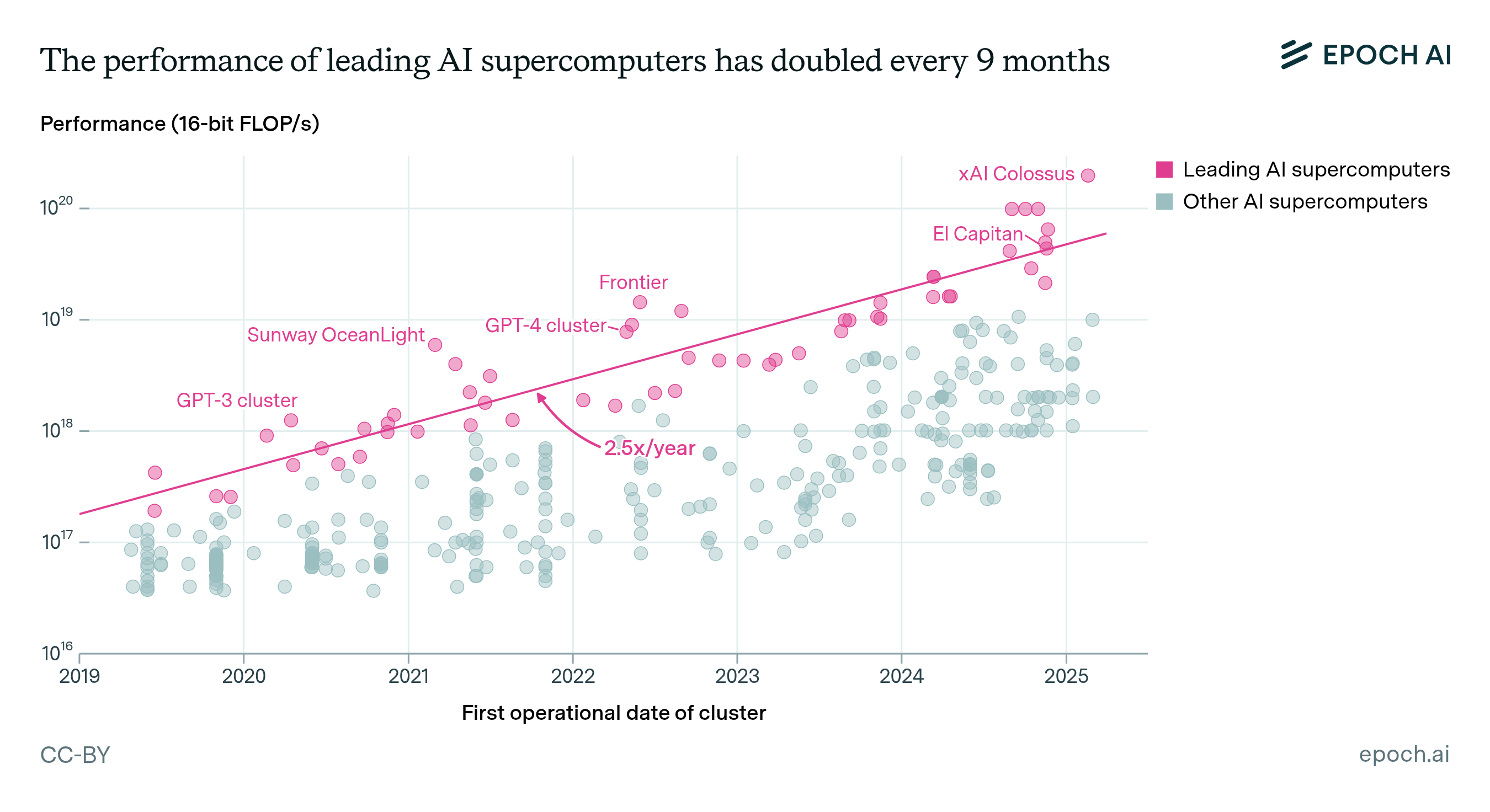
Our open database of AI Chip sales, using financial reports, company disclosures, and more to estimate compute, power usage, and spending over time for a wide variety of AI chips.
The AI Chip Sales hub tracks and estimates sales and shipments of leading AI chips over time, as well as their estimated total computing power, cost, and power draw. The analysis is primarily based on data on chip volumes, revenue, and prices sourced from company earnings commentary, analyst estimates, and media reports.
Epoch AI’s data is free to use, distribute, and reproduce provided the source and authors are credited under the Creative Commons Attribution license.
Our AI Chip Sales data explorer compiles our estimates of the number of dedicated AI accelerators that have been sold or shipped by major chip designers over time. This is broken down by chip manufacturer, by specific chip models, and by time period.
The total quantity of AI chips, and its growth rate over time, is a key factor in the AI field’s ability to conduct research and to train and deploy AI models. Our analysis of total AI chip sales complements our data on the training compute of individual models, as well as our data on large AI data centers and GPU clusters.
Note that our main objective in measuring AI compute is to help understand its implications for AI progress and AI’s societal impacts, not to perform industry or financial analysis.
Our methodology varies by designer based on available data. Please refer to the Documentation section for a detailed overview of our methodology for each chip designer.
Our figures are estimates, because chip companies do not consistently disclose exact sales, though Nvidia has provided the most informative direct disclosures on total Hopper and Blackwell sales.
When feasible, we model our uncertainty in 90% confidence intervals. These can be viewed in the tooltips and in the table view; most of our intervals span a factor of roughly 2x, or ~1.5x in either direction from the median. We do not always round our estimates for specific chips and quarters, because it is slightly more accurate to aggregate unrounded estimates, but they nevertheless should not be viewed as precise figures.
Our uncertainty, and the robustness of our methodologies, varies by chip designer. And the level of detail in our analysis varies roughly in proportion to the size and importance of each chipmaker.
We have the highest confidence in our Nvidia estimates, which are based on Nvidia-reported compute revenue and extensive media and analyst coverage, and corroborated by direct disclosures from Nvidia of Hopper and Blackwell shipments. We are least confident in our Amazon Trainium estimates; while large-scale Trainium data centers provide a robust floor on volumes, our central estimates rely on indirect evidence and fairly limited analyst coverage.
For more information on how we produce our estimates, see our methodology page.
H100e (H100-equivalent) compute capacity is total computing power measured in terms of the equivalent number of Nvidia H100 GPUs. We divide the peak number of dense 8-bit operations (FP8 or INT8) each chip can perform by the Nvidia H100’s spec, and then multiply this ratio by the number of chips. For example, since a TPUv7 can perform ~2.3x as many operations as an H100, then one million TPUv7s have a compute capacity of 2.3 million H100e.
We use H100e because citing a reference chip is much more intuitive than total operations per second. The H100 is chosen because it was the most widely-used AI chip in 2023 and 2024.
We choose 8-bit number formats since our understanding is that they are now widely used for inference, and for training at major AI labs (see more on number format trends here). Alternative metrics such as different bit counts or total processing performance (operations x bit width) can lead to different performance ratios between chip types, but in most cases this choice does not matter because peak operations per second usually scales inversely with the bit width of the number format.
No, this is an imperfect proxy based on specifications on paper. While operations/second is the single most useful metric because the basic purpose of AI chips is to perform computer operations, real-world performance can diverge from paper specs for several reasons:
Chip costs are based on approximate average purchase prices for each chip type, multiplied by the number of chips. This price is the price paid by the final customer or user, not the underlying production cost to the chip designer or manufacturer. These are intended for useful reference, and we don’t currently implement confidence intervals for total chip costs.
For AI chips that are sold directly to external customers, such as Nvidia’s and AMD’s, this is the price paid by those customers, synthesized from reports or analyst estimates. For custom chips such as Google’s TPU, this is the estimated price paid to the relevant supply partners (e.g. Broadcom). This is a fair comparison while Google is the sole direct customer of TPU, but once TPUs are sold to external customers such as Anthropic in 2026, future chip costs will be adjusted to account for the average price paid by all TPU customers.
Note that chip prices do not represent the full capital cost of AI hardware, due to the substantial overhead costs of servers, compute clusters, and data center facilities. You can find more information about AI capital costs here.
The power figures are based on each chip’s thermal design power (TDP), which is a specification that roughly means the maximum possible sustained electric power draw of the chip. This is multiplied by the total quantity of a given chip.
Importantly, the total power draw of an AI data center is typically much higher (roughly twice as high) than the total TDP of the chips inside, due to overheads at the server, cluster, and facility level.
We strive to track the total number of chips that are delivered and ready for installation or use, but not necessarily already online in a data center. This can vary by designer in practice due to differences in available evidence:
In all cases, delivered chips may take additional time to be installed and brought online in data centers.
No. We focus on the largest designers of dedicated AI accelerators: NVIDIA, Google (TPUs), Amazon (Trainium/Inferentia), AMD (Instinct series), and Huawei (Ascend series), prioritizing both overall volume and geographic diversity. Together, these account for the large majority of global AI compute capacity.
We do not currently track:
We may expand coverage as other manufacturers scale production or more data becomes available.
Our data and estimates date back to 2022 for Nvidia, 2023 for Google, and 2024 for other chip designers. This is mainly due to greater availability of information over time. In addition, given a trend of rapid growth in the stock of computing power over time, the last two years of shipments would make up a large majority of the total compute stock even if chips had infinite lifetimes. We may later expand our coverage to earlier years.
We show estimates of chip sales by calendar quarter. However, some of the underlying information used for our estimates don’t line up with calendar quarters, usually because they’re based on fiscal quarters that don’t line up with the calendar (this applies to Nvidia as well as Google TPUs, which are estimated using Broadcom fiscal quarters). In other cases, our estimates are initially broken down by years or half-years rather than quarters.
In these cases, we interpolate our numbers to fit calendar quarters by assuming a constant rate of sales per time period. This method is simple but slightly imperfect since chip sales have usually grown over time in recent years (or shrunk when a new generation is introduced).
We do not explicitly account for chip retirements. AI hardware generally lasts for several years, though exact figures are a matter of controversy, so many chips sold in 2023 or earlier are likely still in service. Given growth in chip deployments over time, chip retirements likely have only a small impact on the cumulative stock.
Epoch AI’s data is free to use, distribute, and reproduce provided the source and authors are credited under the Creative Commons Attribution license.
Have a question? Noticed something wrong? Let us know.
Our open database of AI Chip sales, using financial reports, company disclosures, and more to estimate compute, power usage, and spending over time for a wide variety of AI chips.