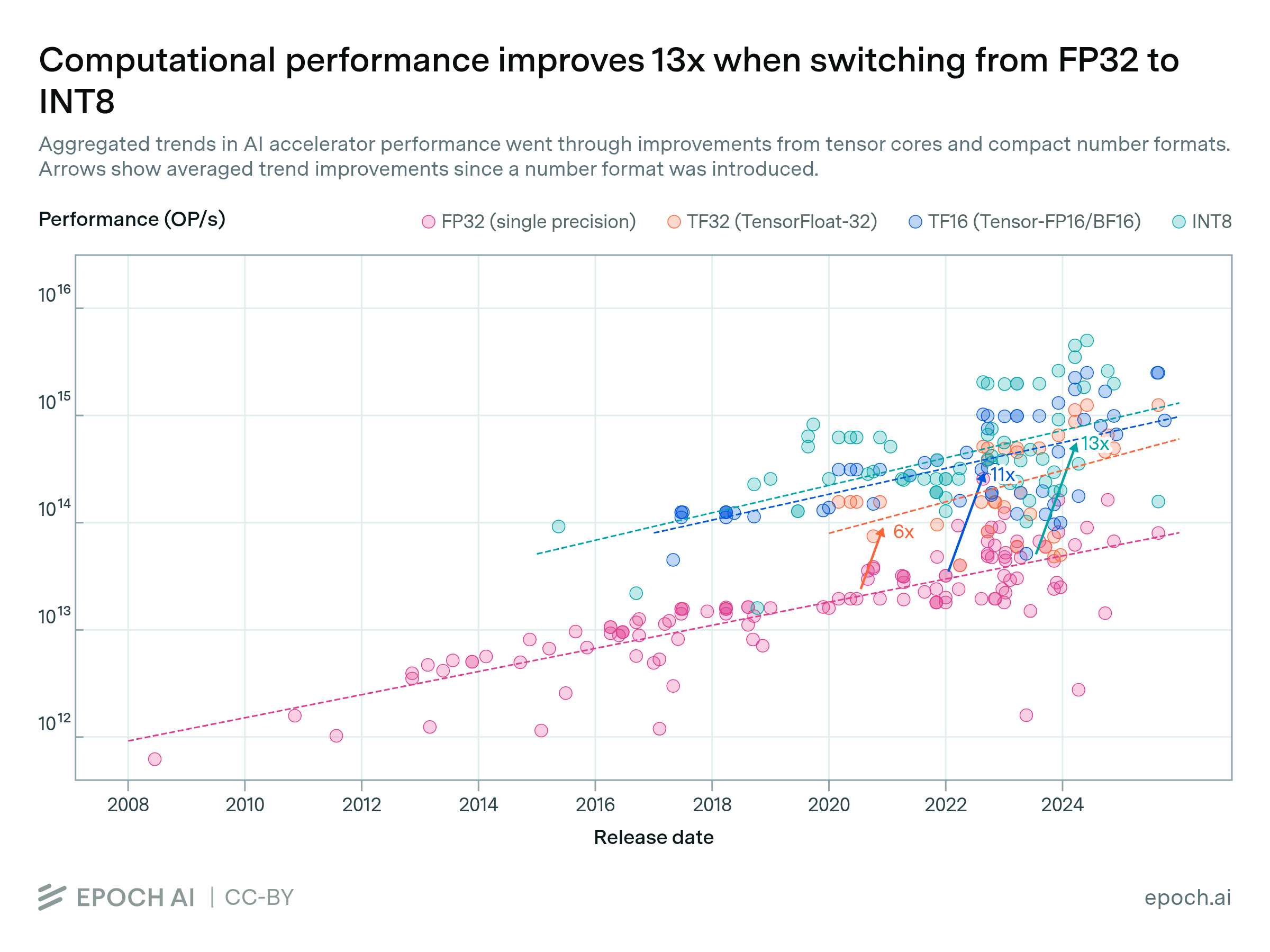
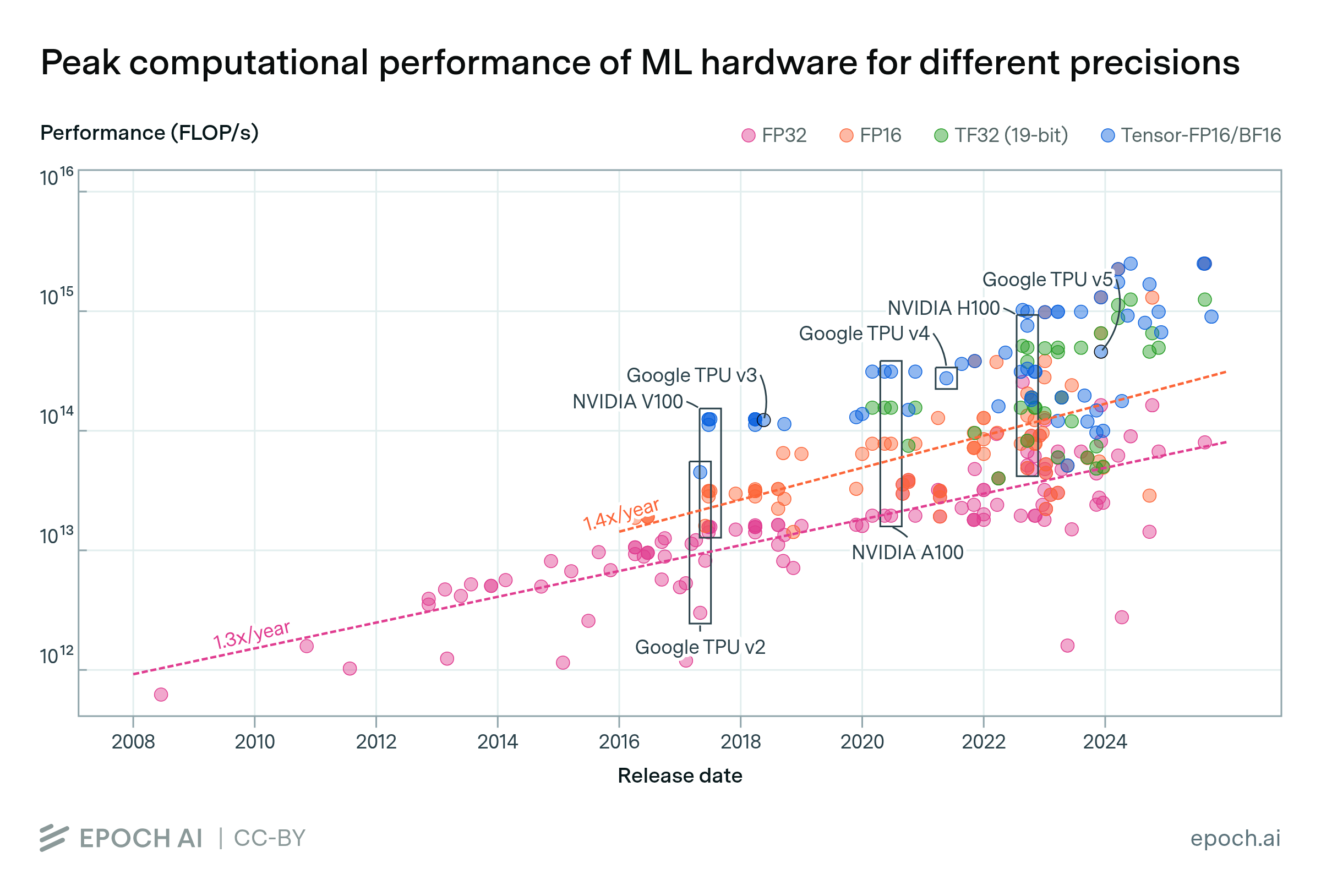
In the past, it has taken up to four years for new numerical formats to reach widespread adoption in model training. Both FP16 and BF16 gained early traction in the first two years, reached 50% adoption by around year three1, and became the default within five years. Shifting to these new formats provided gains in computational performance and training stability, but were contingent on hardware support.
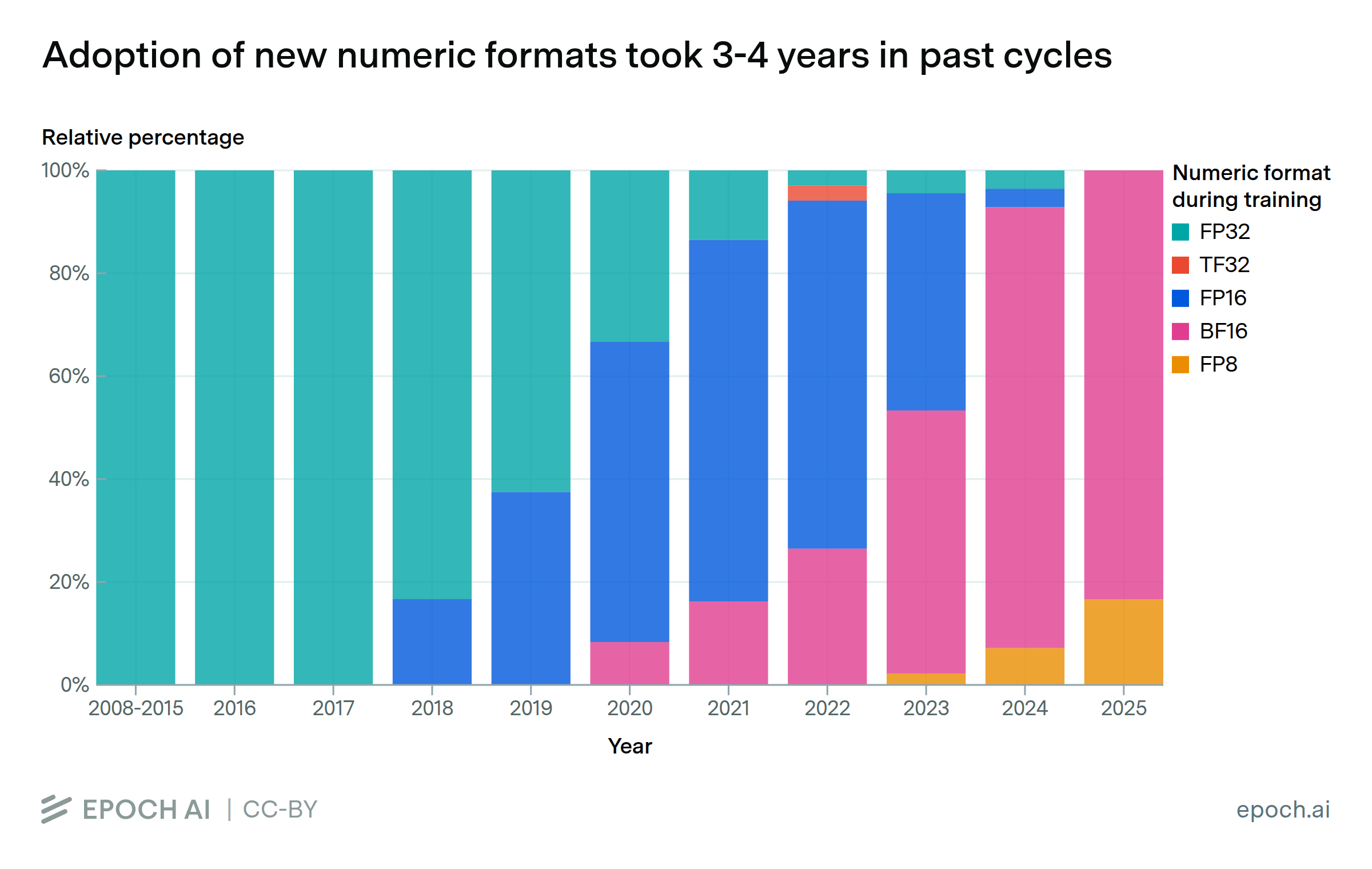
BF16 is on the latter end of its 4 year cycle, and FP8 training is now emerging. If adoption patterns hold, FP8 could be the standard by around 2028. Extending this further, 4-bit training may follow and eventually become the primary numerical format, but training stability at such low precision remains a challenge.
Epoch's work is free to use, distribute, and reproduce provided the source and authors are credited under the Creative Commons BY license.
Learn more about this graph
We analyze historical adoption trends of numerical precision formats (e.g., FP32, FP16, BF16) used in AI models’ original training. To determine these precisions, we automatically extract relevant text and code concerning training configurations from the models’ GitHub repositories and technical reports. A two-stage LLM analysis then interprets this extracted text to assign a final precision label to each model, provide evidence, and cite its sources. This process yields the dataset of training precisions used to map adoption cycles over time.
Code for this analysis is available here.
Data
Analysis
Assumptions and limitations
Explore this data
Our comprehensive database of over 3500 models tracks key factors driving machine learning progress.
Related insights