

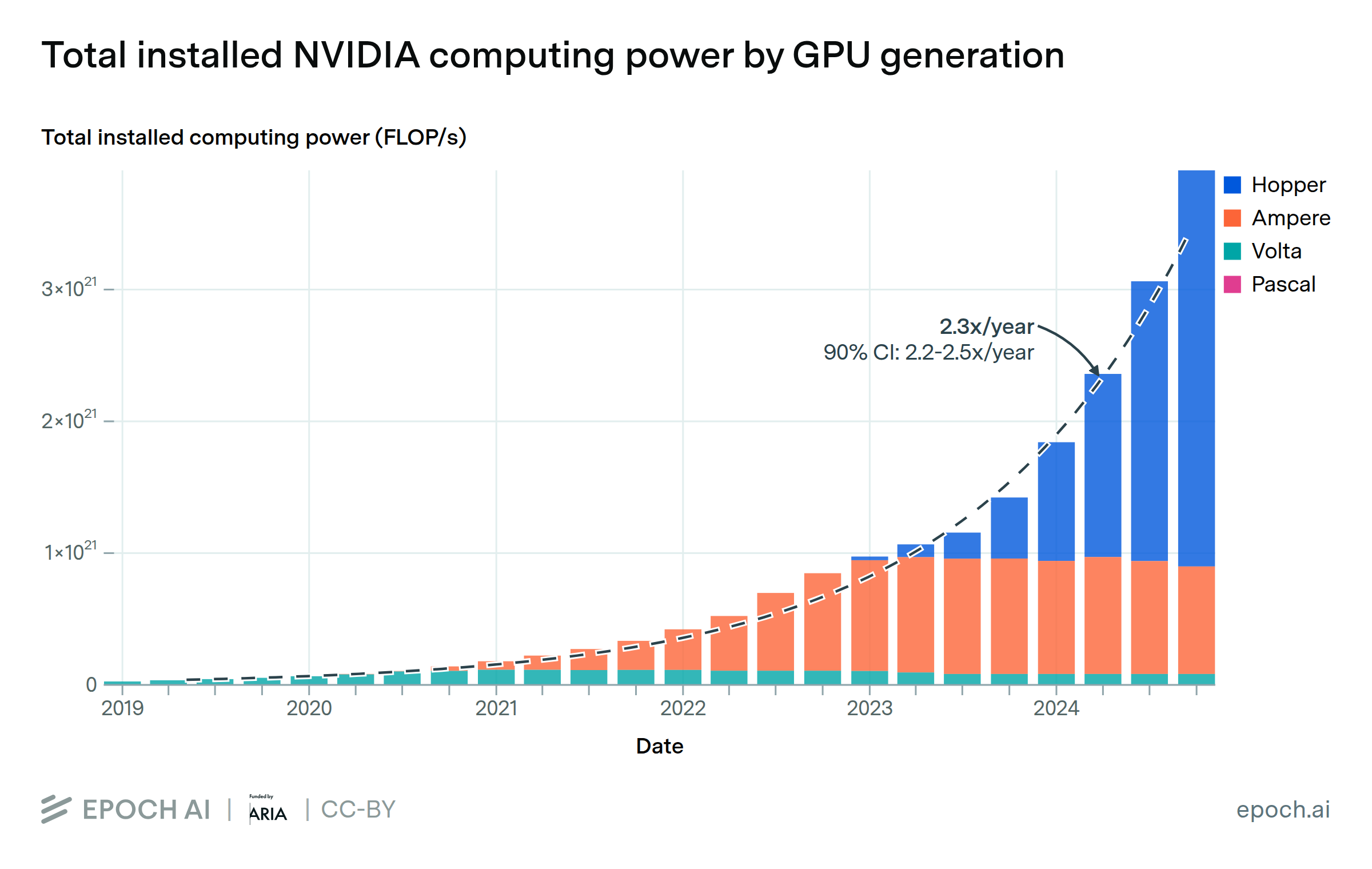
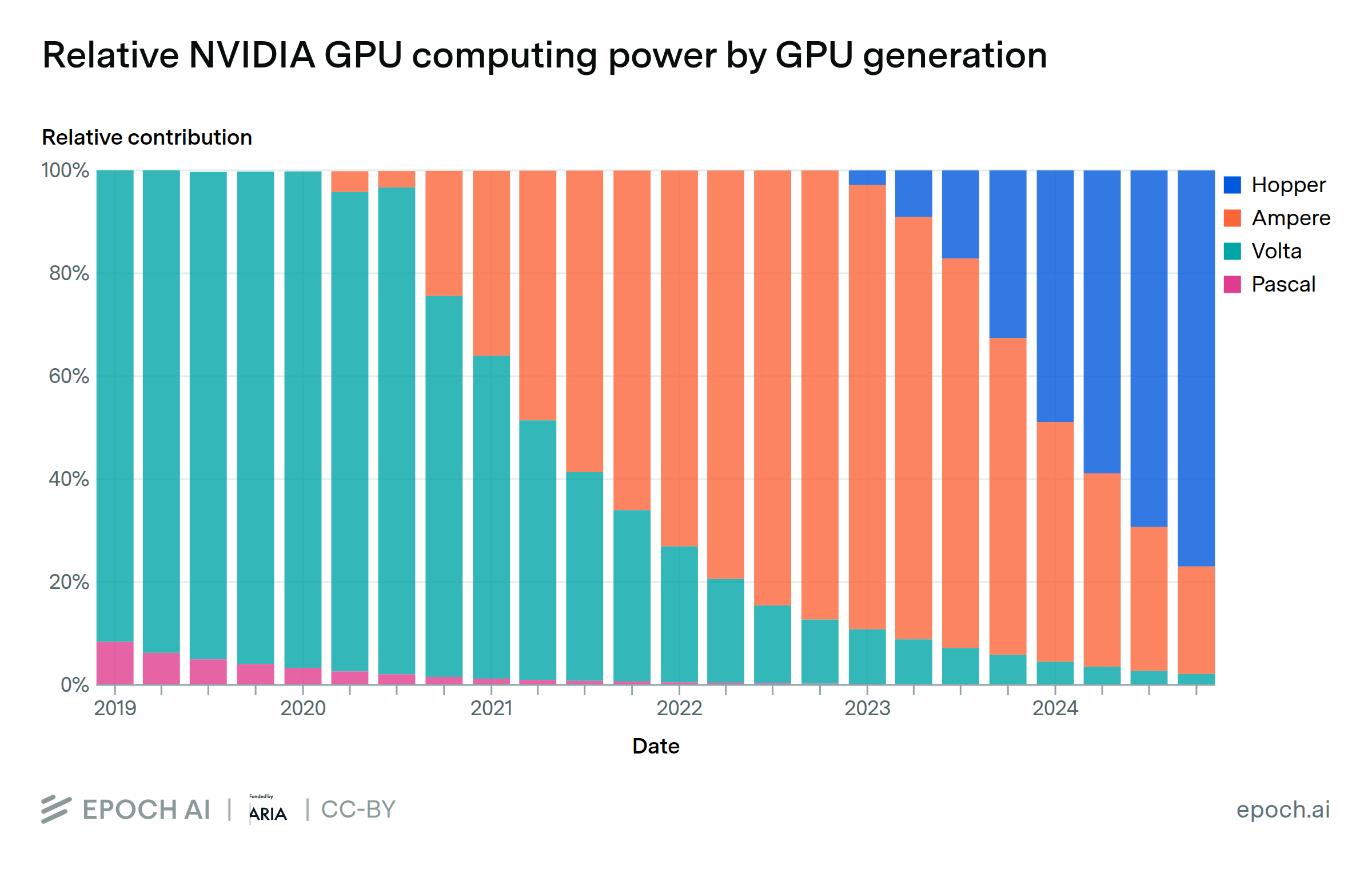
Total available computing power from NVIDIA chips has grown by approximately 2.3x per year since 2019, enabling the training of ever-larger models. The Hopper generation of NVIDIA AI chips currently accounts for 77% of the total computing power across all of their AI hardware. At this pace of growth, older generations tend to contribute less than half of cumulative compute around 4 years after their introduction.
Note this analysis does not include TPUs or other specialized AI accelerators, for which less data is available. TPUs may provide comparable total computing power to NVIDIA chips.
Epoch's work is free to use, distribute, and reproduce provided the source and authors are credited under the Creative Commons BY license.
Learn more about this graph
We estimate the world’s installed NVIDIA GPU compute capacity, broken down by GPU model. These estimates are based on NVIDIA’s revenue filings, by assuming that the distribution of chip generations over time follows the same pattern as in a dataset of AI clusters. We estimate that there are currently 4e21 FLOP/s of computing power available across NVIDIA GPUs, or approximately 4M H100-equivalents. Additionally, we find that the cumulative sum of computing power (accounting for depreciation) has grown at 2.3x per year since 2019. We consider only data center sales, omitting the computing power available attributable to “Gaming” sales in NVIDIA’s revenue reports.
Code for our analysis is available in this notebook.
Data
Analysis
Assumptions
Explore this data

Key data on over 170 AI accelerators, such as graphics processing units (GPUs) and tensor processing units (TPUs).
Over 500 GPU clusters and supercomputers, including those used for AI training and inference.