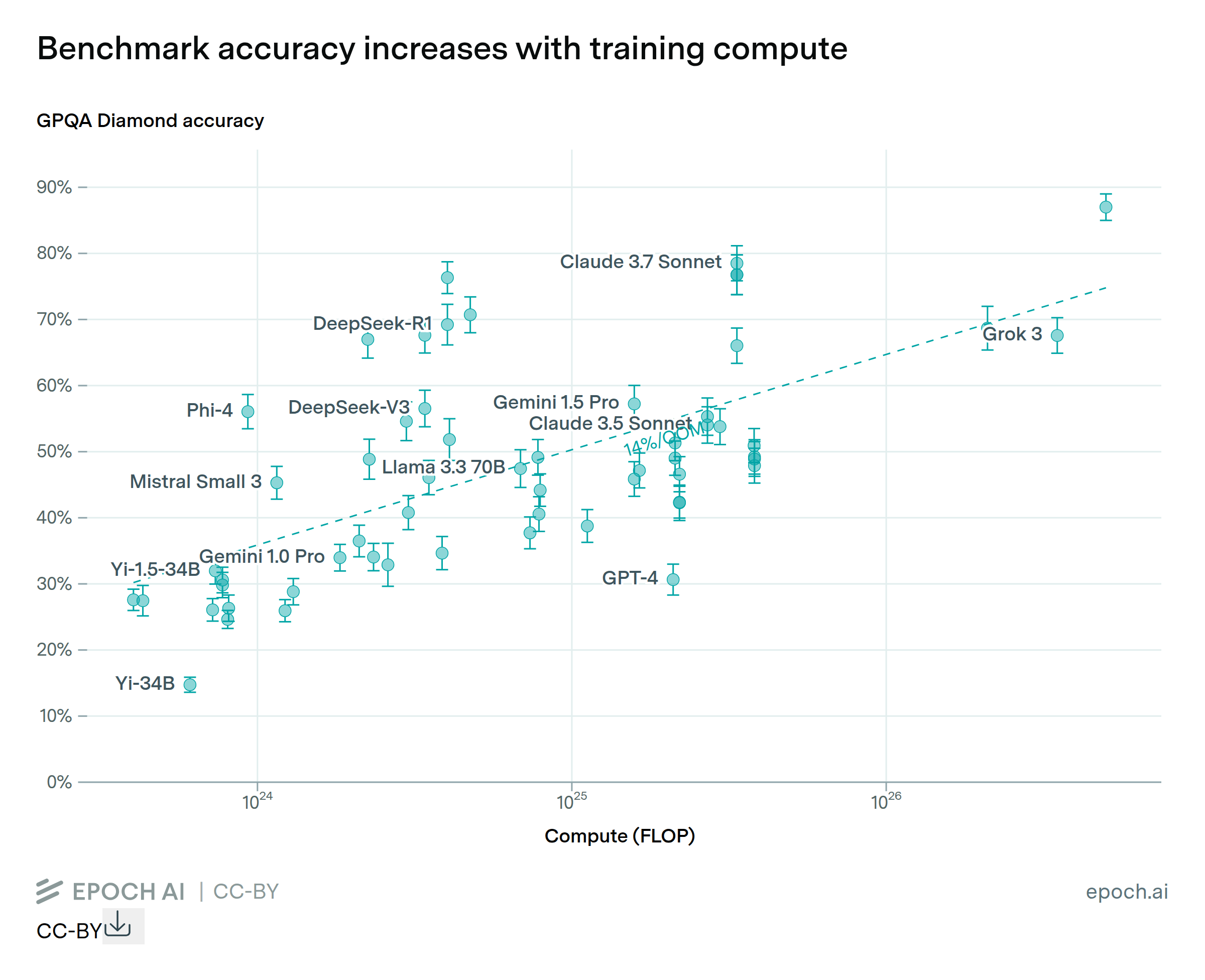
At launch, GPT-4 was widely seen as a step-change over GPT-3, demonstrating the high returns to scaling up training compute. GPT-5 arguably drew a more mixed reception. Yet GPT-5 does far better than GPT-4 in some notable capability benchmarks, similar to how GPT-4 advanced on GPT-3 on the widely-cited benchmarks of its day. While these improvements are not directly comparable, they do suggest that GPT-5 and GPT-4 were both large advances from the previous generation.

However, one major difference between these generations is release cadence. OpenAI released relatively few major updates between GPT-3 and GPT-4 (most notably GPT-3.5). By contrast, frontier AI labs released many intermediate models between GPT-4 and 5. This may have muted the sense of a single dramatic leap by spreading capability gains over many releases.
Epoch's work is free to use, distribute, and reproduce provided the source and authors are credited under the Creative Commons BY license.
Learn more about this graph
We contextualize the advance from GPT-4 to GPT-5 by comparing benchmark gains from GPT-4 to 5 with gains from GPT-3 to 4. While there is no single, objective measure of long-term AI improvements, we observe dramatic improvements on benchmarks for both GPT-4 and GPT-5 on benchmarks that were salient in their respective time periods.
Data
Analysis
Assumptions and limitations
Explore this data
Benchmark results featuring the performance of leading AI models on challenging tasks.
Related insights