Model information, such as release date and parameter count, is drawn from original model reports, the Epoch AI Models database, and HuggingFace model cards. Benchmark scores are aggregated from the Epoch AI Benchmarking Hub, Artificial Analysis, LM Arena, and developer-reported results.
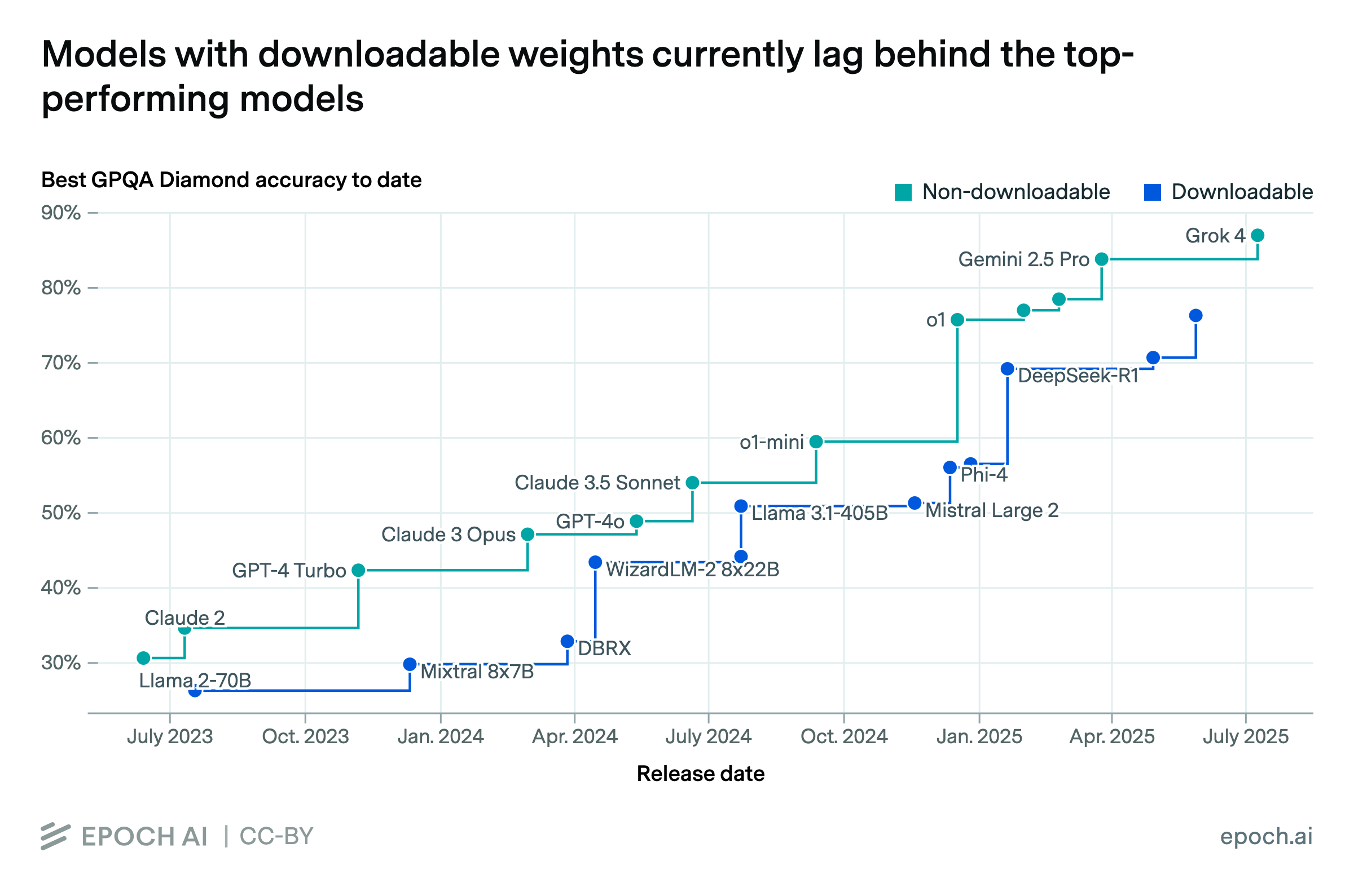
We analyze model performance across four benchmarks/metrics: GPQA-Diamond, MMLU-Pro, the Artificial Analysis Intelligence Index, and LM Arena Elo scores. We selected GPQA-Diamond and MMLU-Pro because they test a broad conception of knowledge and reasoning, have remained unsaturated over a reasonably long period, and have good data availability. We include the Artificial Analysis Intelligence Index as it provides a composite score of model performance. However, this index incorporates GPQA-Diamond and MMLU-Pro, so there is correlation between these metrics. Finally, we include LM Arena Elo scores to capture user preferences, though LM Arena Elo scores have their own limitations.
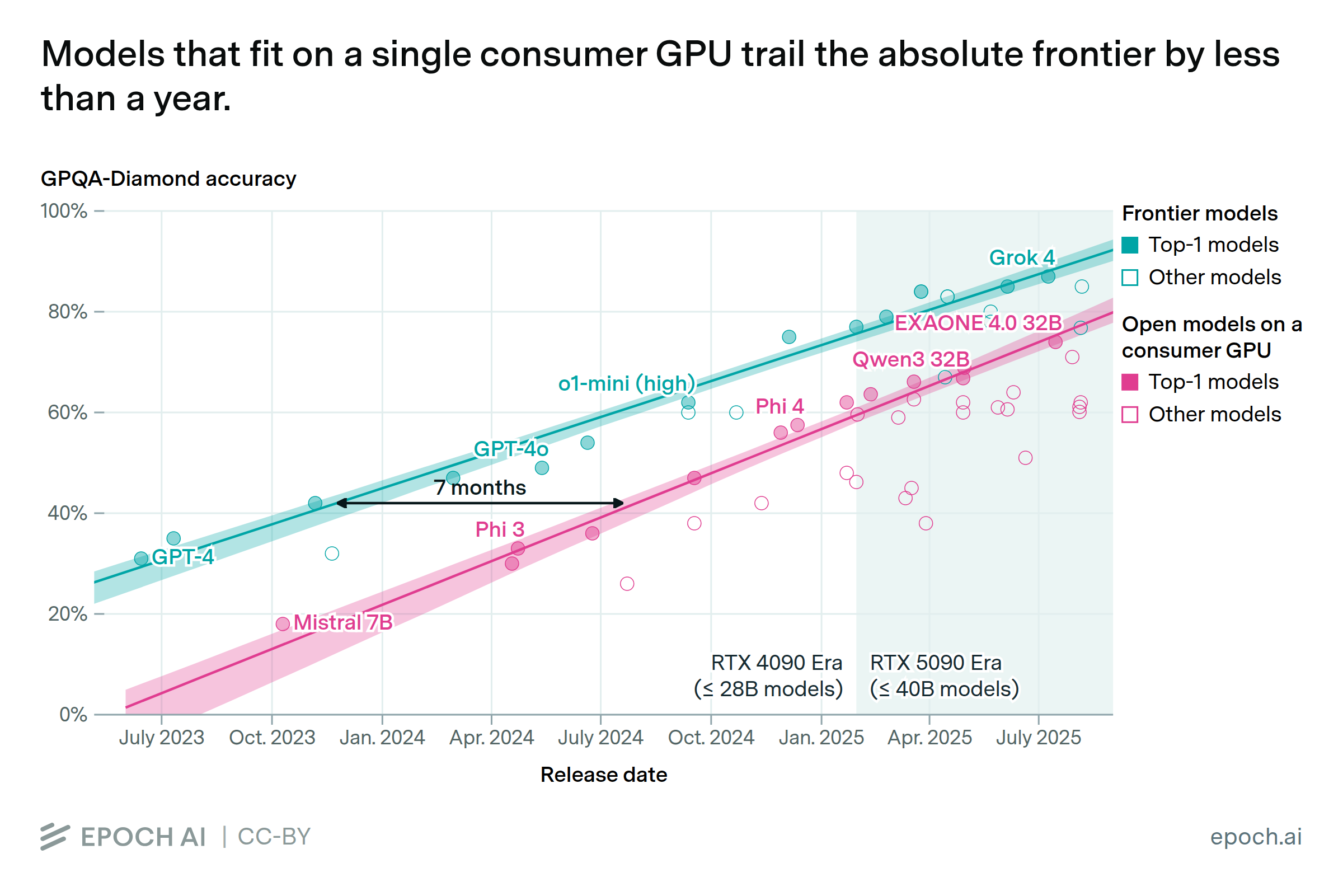
Epoch’s Benchmarking Hub prioritizes models at or near the frontier of capabilities, and thus tends to underrepresent small, open models. To identify models that push the frontier of the capabilities available on a consumer GPU, we use the following steps:
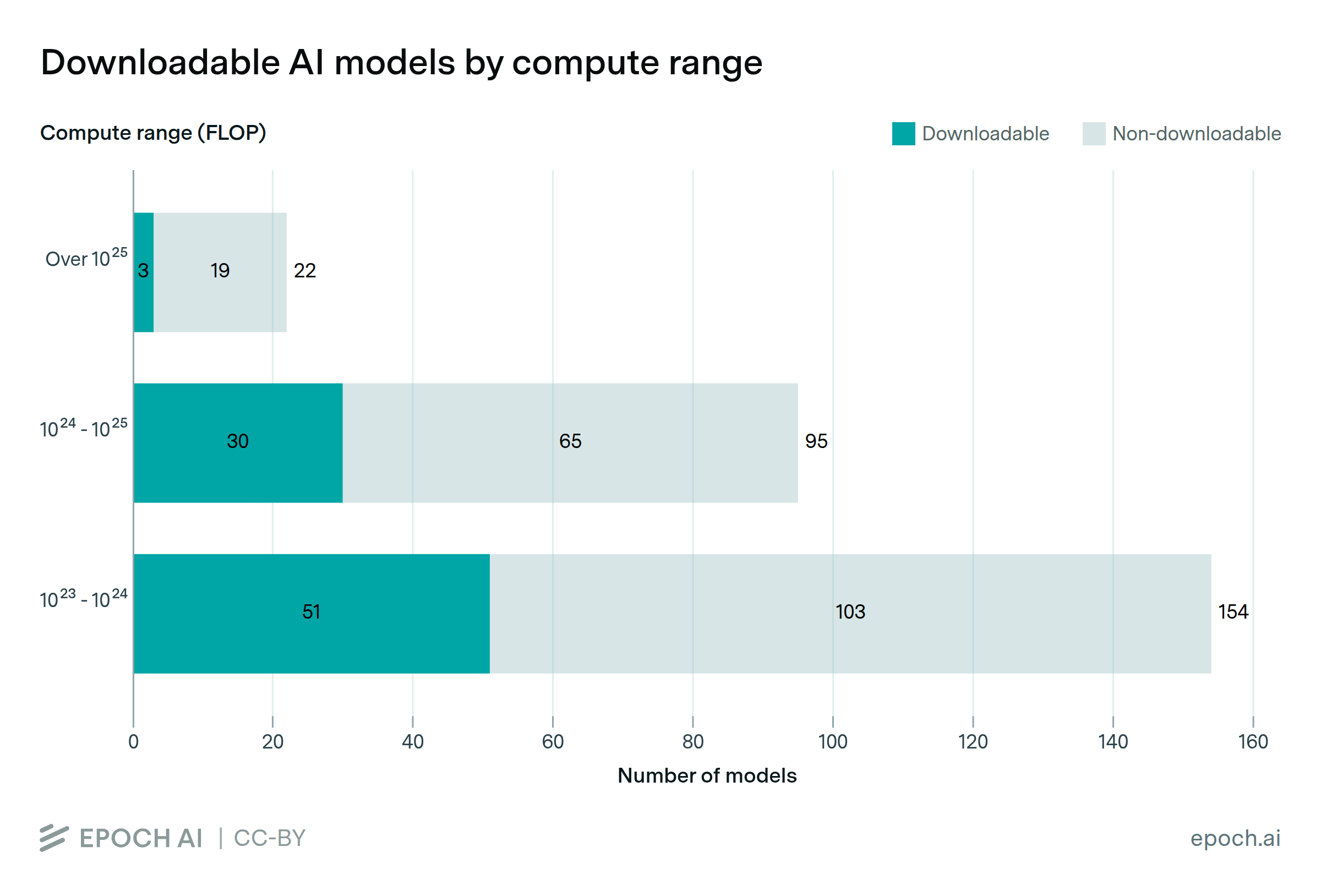
- Defining Hardware Constraints: We first establish the largest parameter size model that can be run on the NVIDIA consumer GPU at the time. Based on memory capacity and common quantization schemes, we defined this limit as ≤ 28B parameters for the NVIDIA RTX 4090 era and ≤ 40B parameters for the subsequent RTX 5090 era.
- Identifying SOTA Open Models: To create a candidate list of high-performing open models within these size constraints, we analyzed evaluation data from sources like the OpenLLM Leaderboard and Artificial Analysis. OpenLLM leaderboard has comprehensive coverage of open models and provides a strong signal for identifying which models were pushing the frontier of capabilities over time. However, the initiative ended in February 2025 so we supplemented and cross-checked this with data from Artificial Analysis to create a set of open models that were at or near the performance frontier for their respective time periods.
- Collecting and Prioritizing Scores: For each model, we sought a reliable benchmarks score. We consider multiple sources and employ a hierarchy for collecting scores. Our prioritization was as follows: 1) Artificial Analysis benchmarking, as they have the most extensive GPQA-Diamond and MMLU-Pro coverage for small models, 2) Epoch AI Benchmarking Hub, and 3) developer-reported results (which tend to be slightly higher than third-party evaluations). For many older models, we relied exclusively on third-party evaluations. Some potentially significant open models are excluded from the analysis due to a lack of available scores from any of the sources. For model Elo values, we pull the style-controlled scores from the LM Arena Text leaderboard.
We use data from Epoch AI’s Benchmark Hub to plot the absolute frontier on GPQA-Diamond . For plotting absolute frontier on MMLU-Pro and AA Intelligence Index, we use data from Artificial Analysis.