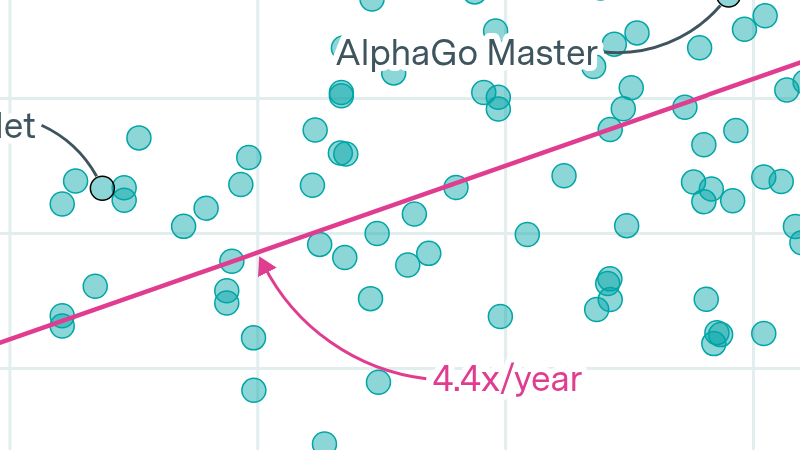
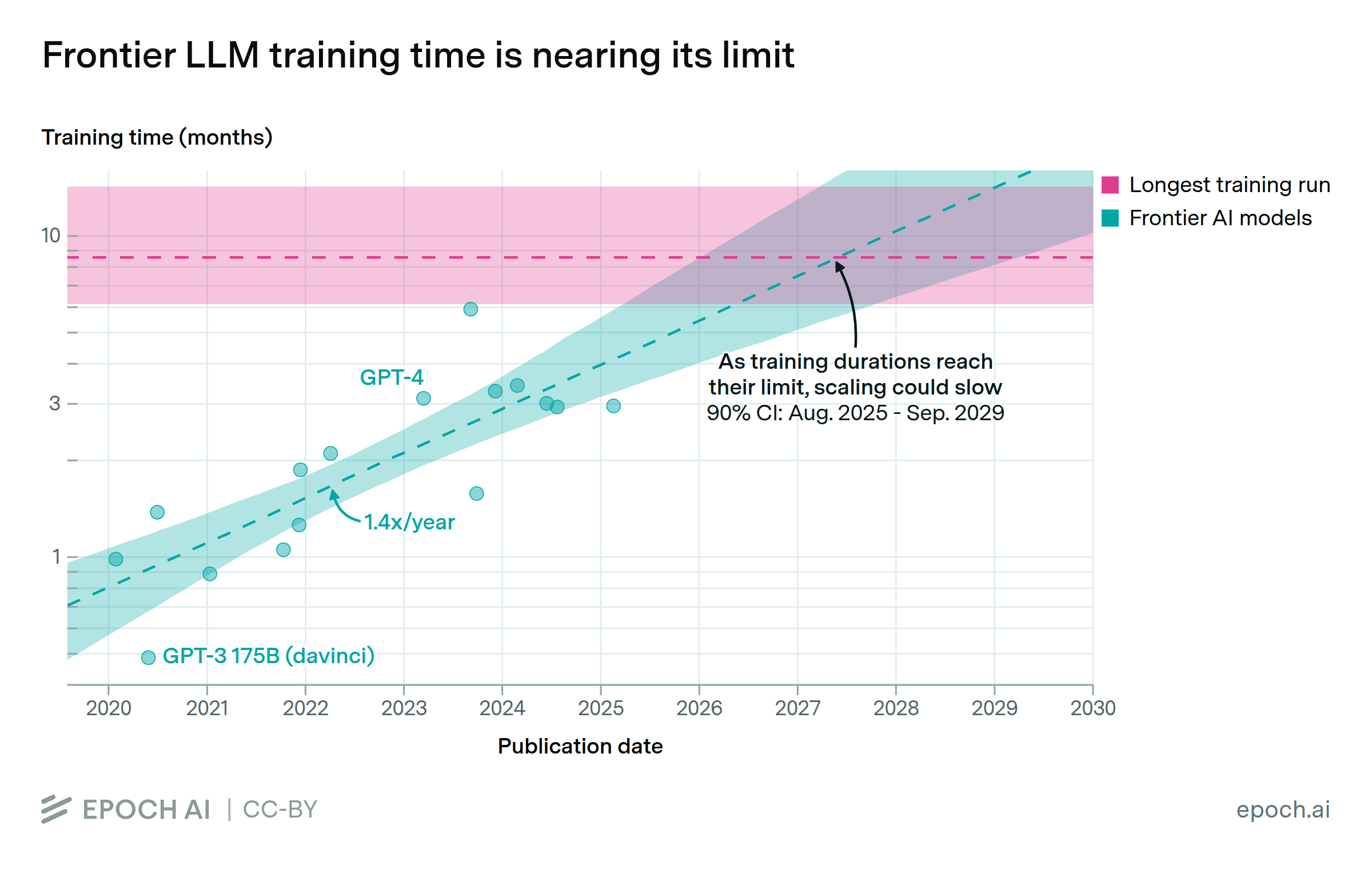
In “The Longest Training Run”, we argue that training runs that last too long are outclassed by training runs that start later and benefit from additional hardware and algorithmic improvements. Based on our latest numbers, this suggests that training runs lasting more than 9 months may be inefficient. At the current pace, training runs will reach this size around 2027 (90% CI: Aug 2025 to Sept 2029).
Longer training runs are a significant driver of the rapid growth seen in training compute. If training time stops increasing, training compute growth will slow – unless developers ramp up hardware scaling even faster. This could be achieved by speeding up the build-out of larger clusters, or by spreading training across multiple clusters.
Epoch's work is free to use, distribute, and reproduce provided the source and authors are credited under the Creative Commons BY license.
Learn more about this graph
We show that, since 2020, the time that frontier LLM systems spend training has grown by about 1.4x per year (90% CI: 1.3x to 1.5x). Separately, there are economic reasons to expect that training runs longer than about 9 months are sub-optimal. On current trends, frontier AI systems will hit this 9 month limit by around 2027 (90% CI: 2025 to 2029).
Since training time has contributed about 1/3rd of total scaling progress since 2018, an end to this trend could mean slower overall compute growth after 2027. Conversely, model developers could respond by increasing the number of chips they train on, either by speeding up their training cluster build-outs, or by distributing training across more clusters.
Data
Analysis
Assumptions and limitations
Explore this data
Our comprehensive database of over 3500 models tracks key factors driving machine learning progress.
Related insights