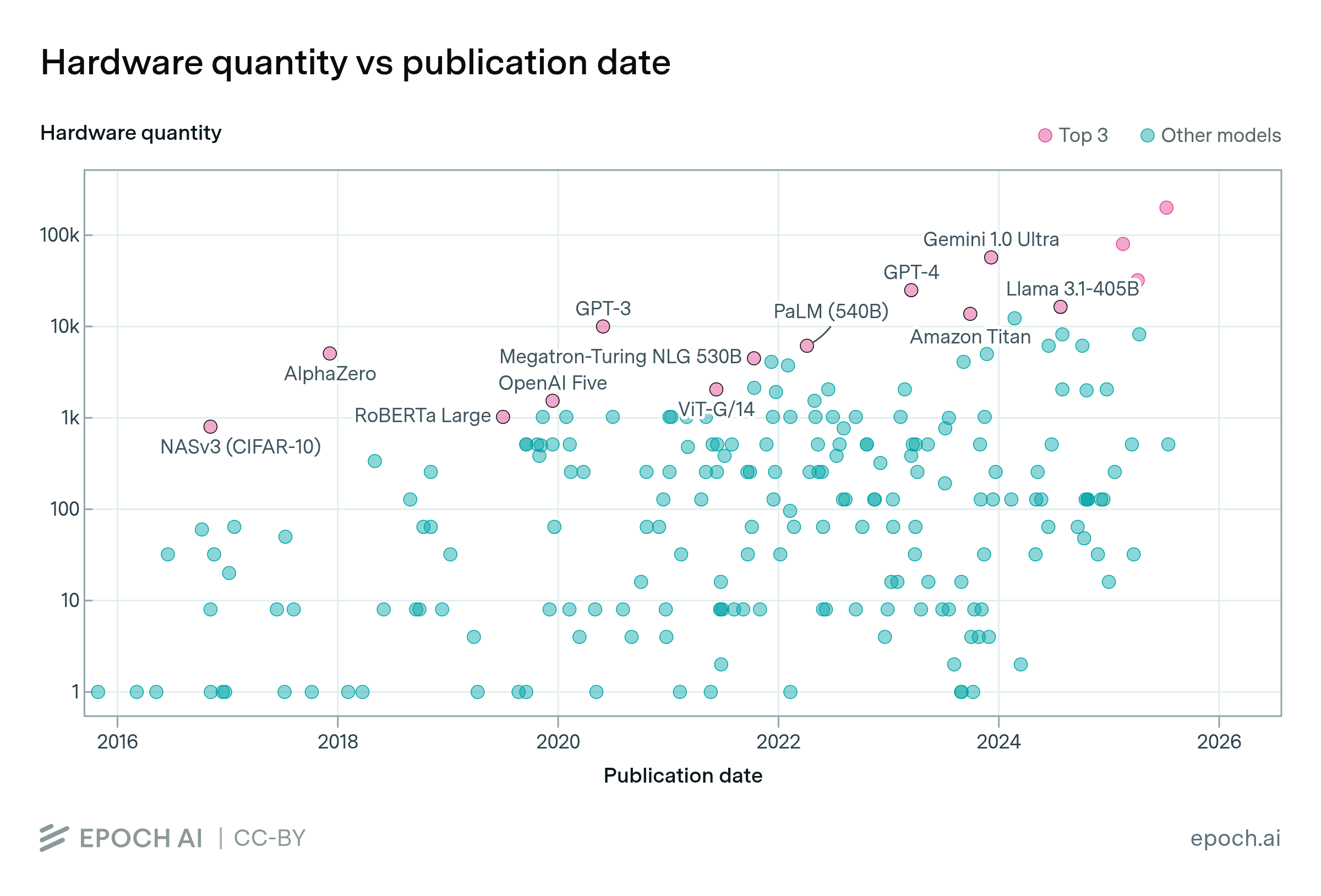
The computational performance of the leading AI supercomputers has grown by 2.5x annually since 2019. This has enabled vastly more powerful training runs: if 2020’s GPT-3 were trained on xAI’s Colossus, the original two-week training run could be completed in under 2 hours.
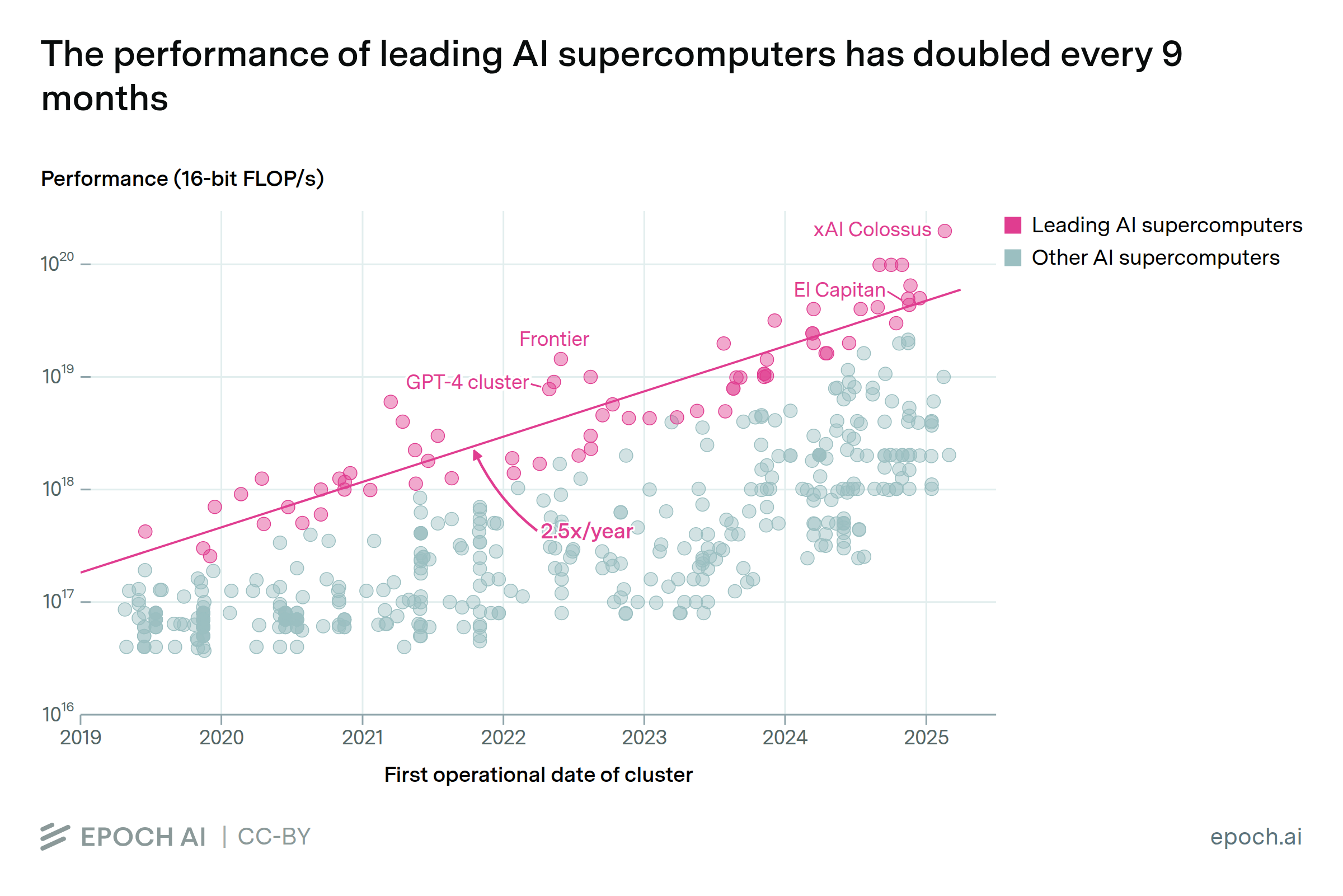
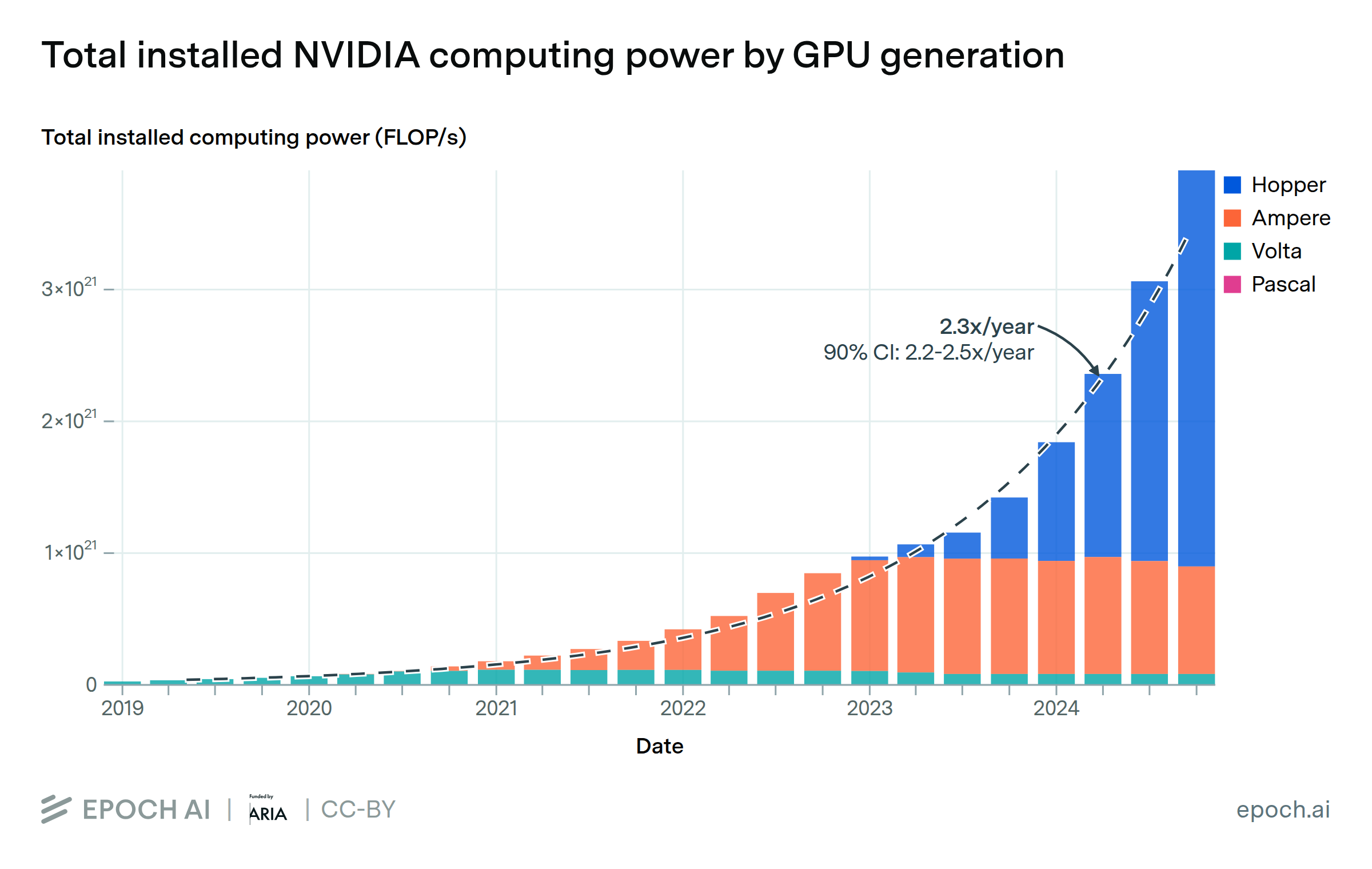
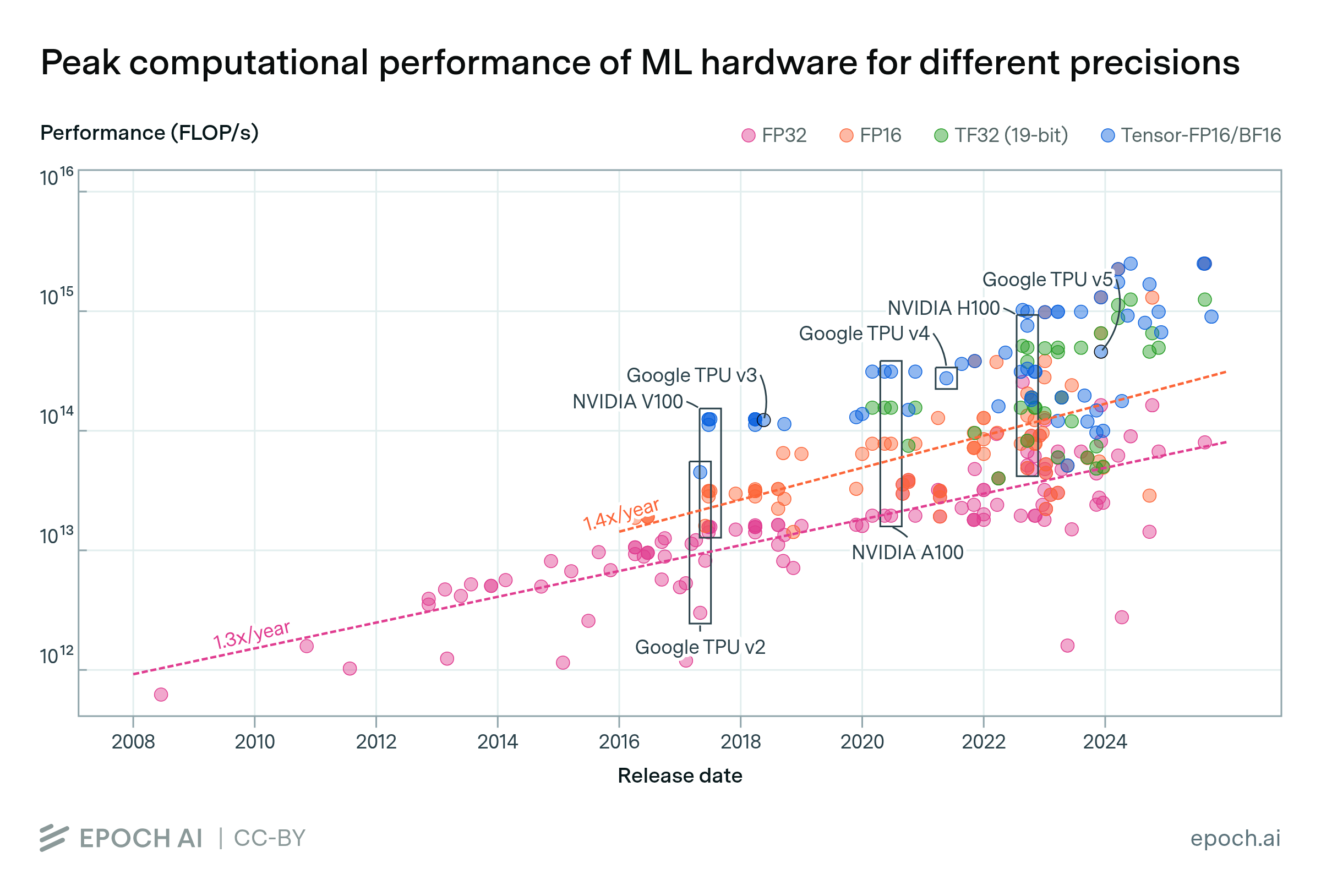
This growth was enabled by two factors: the number of chips deployed per cluster has increased by 1.6x per year, and performance per chip has also improved by 1.6x annually.
Epoch's work is free to use, distribute, and reproduce provided the source and authors are credited under the Creative Commons BY license.
Learn more about this graph
Data come from our AI Supercomputers dataset, which collects information on 728 supercomputers with dedicated AI accelerators, spanning from 2010 to the present. We estimate that these supercomputers represent approximately 10-20% (by performance) of all AI chips produced up to January 2025. We focus on the 501 AI supercomputers which became operational in 2019 or later, since these are most relevant to modern AI training.
For more information about the data, see Pilz et al., 2025, which describes the supercomputers dataset and analyzes key trends, and the dataset documentation.
Analysis
Assumptions
Explore this data
Over 500 GPU clusters and supercomputers, including those used for AI training and inference.
Related insights