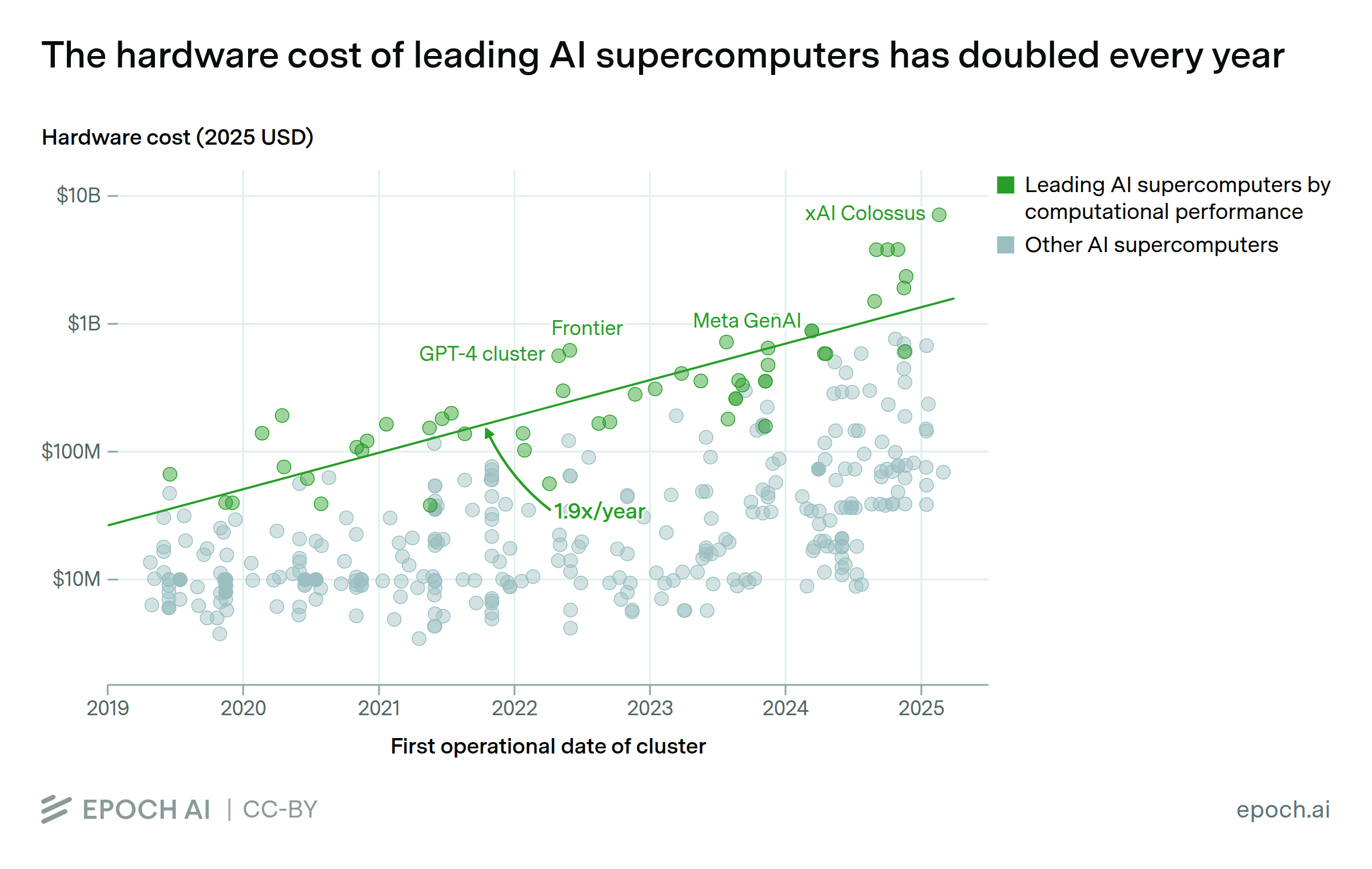
Leading AI supercomputers are becoming ever more energy-intensive, using more power-hungry chips in greater numbers. In January 2019, Summit at Oak Ridge National Lab had the highest power capacity of any AI supercomputer at 13 MW. Today, xAI’s Colossus supercomputer uses 280 MW, over 20x as much.
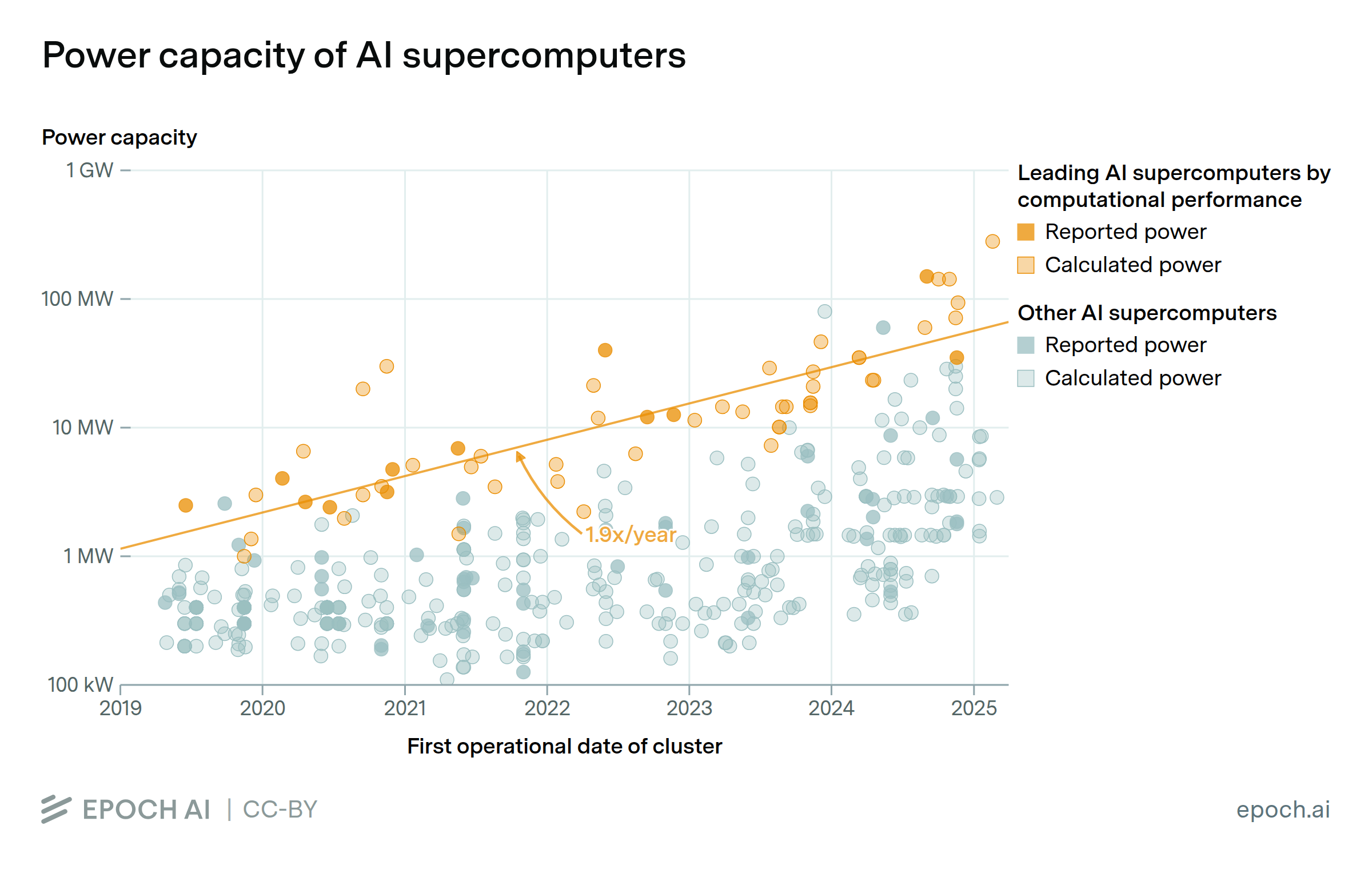
Colossus relies on mobile generators because the local grid has insufficient power capacity for so much hardware. In the future, we may see frontier models trained across geographically distributed supercomputers, to mitigate the difficulty of delivering enormous amounts of power to a single location, similar to the training setup for Gemini 1.0.
Epoch's work is free to use, distribute, and reproduce provided the source and authors are credited under the Creative Commons BY license.
Learn more about this graph
Data come from our AI Supercomputers dataset, which tracks 728 supercomputers with dedicated AI accelerators, spanning from 2010 to the present. By our estimate, these systems account for roughly 10-20% of all AI chip performance produced before 2025. We focus on the 502 AI supercomputers which became operational in 2019 or later, since these are most relevant to modern AI training.
When available, we use the power capacity reported by an AI supercomputer’s owner. When we cannot find a reported figure, we estimate the maximum theoretical power requirements of each AI supercomputer with the following formula:
Chip TDP × number of chips × system overhead × PUE
Chip Thermal Design Power (TDP) represents the maximum power a chip is designed to operate at. This value is public information for most AI chips, but information is not available for some Chinese chips and custom silicon, such as Google’s TPU v5p; we omit these systems from our analysis.
System overhead represents the additional power needed to run non-GPU hardware. We apply a value of 1.82 for all systems, based on NVIDIA DGX H100 server specifications. See the Assumptions section for more details on this figure.
Power Usage Effectiveness (PUE) represents the overhead associated with non-IT equipment (e.g. air conditioning and power conversion inefficiencies). PUE has diminished over time as data centers have improved their efficiency; we obtain annual figures from Shehabi et al. (2024). We subtract 0.29 from the overall PUE in each year, since the same report finds that specialized data centers (like AI supercomputers) have an average PUE that is 0.29 lower than the overall average.
When power usage is reported by the TOP500 list, which provides average power draw during benchmarks, we multiply this figure by 1.5 to approximate peak power consumption, based on comparisons from cases where both peak and average values are known.
Analysis
Assumptions and limitations
Explore this data
Over 500 GPU clusters and supercomputers, including those used for AI training and inference.
Related insights