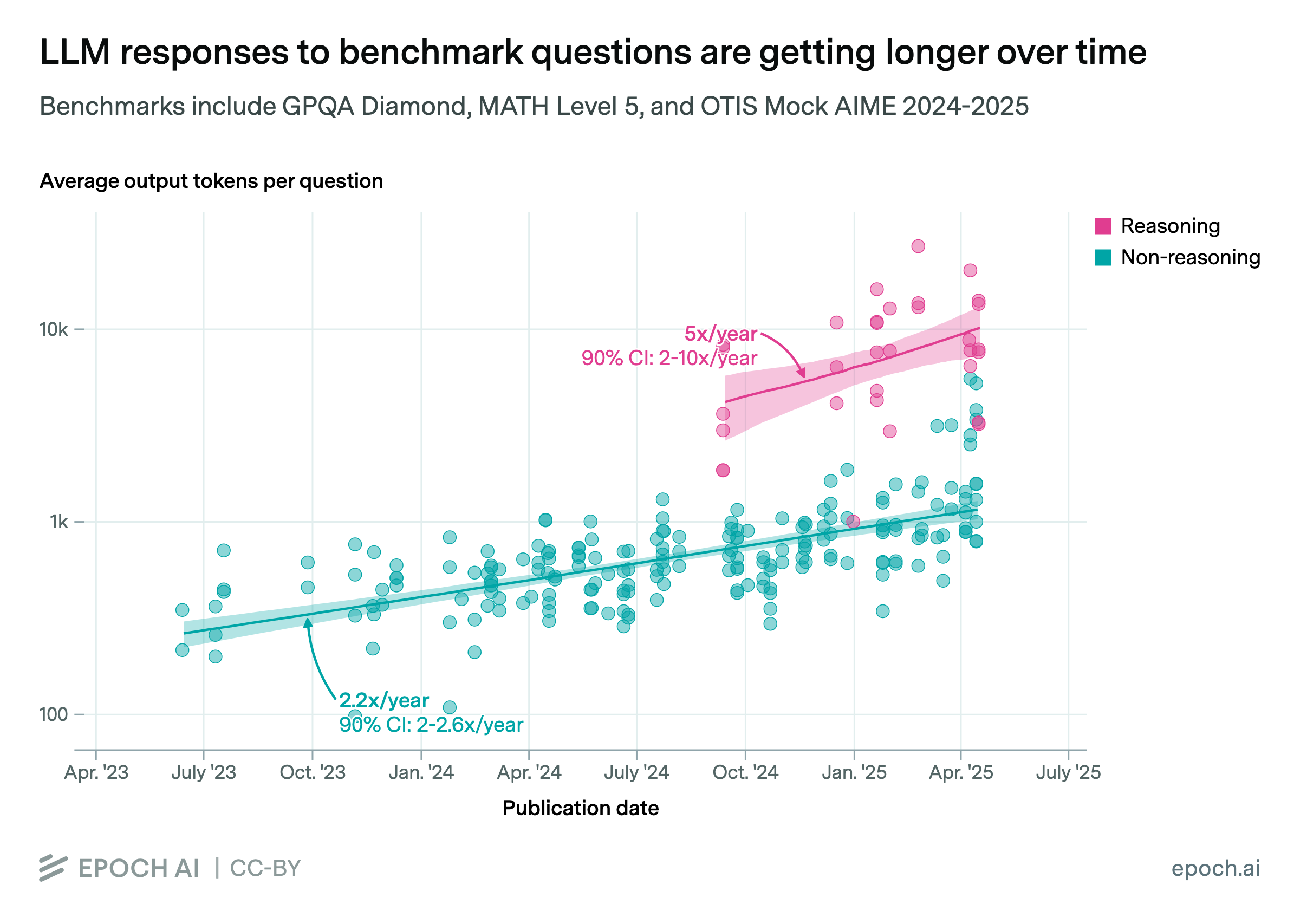
Today’s LLMs can only ingest a limited number of tokens per query, often called the context window. Since mid-2023, the longest LLM context windows have grown by about 30x per year. Their ability to use that input effectively is improving even faster: on two long-context benchmarks, the input length where top models reach 80% accuracy has risen by over 250x in the past 9 months.

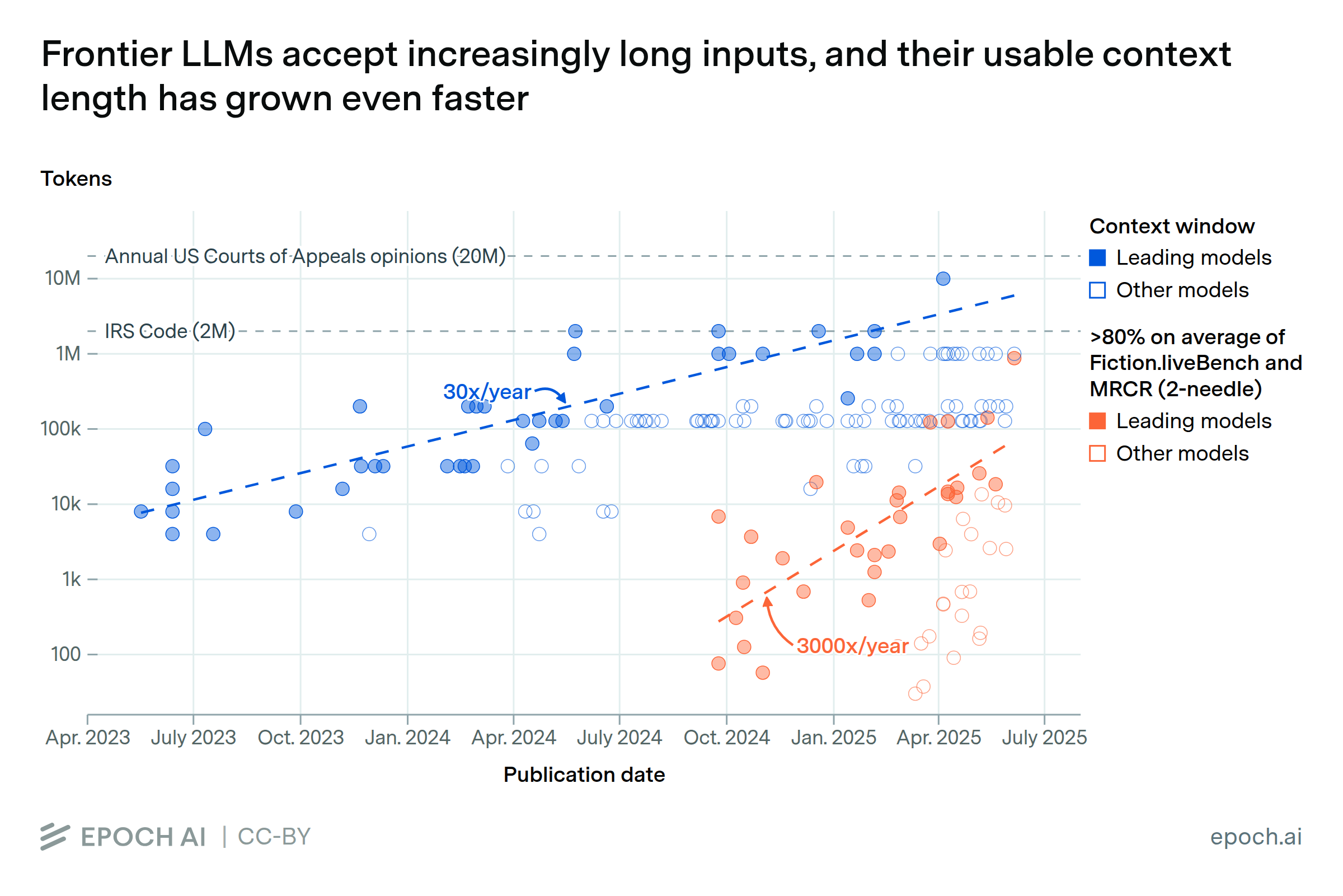



Still, headroom remains. Many long-context tasks are likely more difficult than these benchmarks, and some relevant content does not fit into even the longest available windows.
Epoch's work is free to use, distribute, and reproduce provided the source and authors are credited under the Creative Commons BY license.
Learn more about this graph
We collect context window size from Artificial Analysis. Model release dates are from Epoch’s AI Models database. This yields data for 123 models.
The two long-context benchmarks we use are Fiction.liveBench, which measures narrative comprehension, and MRCR, which measures the ability to retrieve context-dependent information. For MRCR we use the 2-needle setting. Data for Fiction.liveBench is available on Epoch’s Benchmarking Hub. MRCR data is from Context Arena. Thanks to the creators of both benchmarks, kas and Dillon Uzar, respectively, for their assistance in accessing this data.
Benchmark data is only available for newer models. We have data from Fiction.liveBench for 37 models and MRCR for 49 models, with 30 models in the intersection.
Analysis
Assumptions
Explore this data
Benchmark results featuring the performance of leading AI models on challenging tasks.
Our comprehensive database of over 3500 models tracks key factors driving machine learning progress.
Related insights