
Important caveats about the results in this report
- The cost estimates have large uncertainty bounds—the true costs could be several times larger or smaller. The cost estimates are themselves built on top of estimates (e.g. training compute estimates, GPU price-performance estimates, etc.). See the Methods section and Appendix J for discussion of the uncertainties in the respective estimates.
- Although the estimated growth rates in cost are more robust than any individual cost estimate, these growth rates should also be interpreted with caution—especially when extrapolated into the future.
- The cost estimates only cover the compute for the final training runs of ML systems—nothing more.
- The cost estimates are for notable publicly known ML systems according to the criteria discussed in Sevilla et al. (2022, p.16). The improvements in performance over time are irregular—this means that a 2x increase in compute budget did not always lead to the same improvements in capabilities. This behavior varies widely per domain.
- There’s a big difference in what tech companies pay “internally” and what consumers might pay for the same amount of compute. For example, while Google might pay less per hour for their TPU, they initially carried the cost of developing multiple generations of hardware.
Thanks to Michael Aird, Markus Anderljung, and the Epoch AI team for helpful feedback and comments.
Summary
-
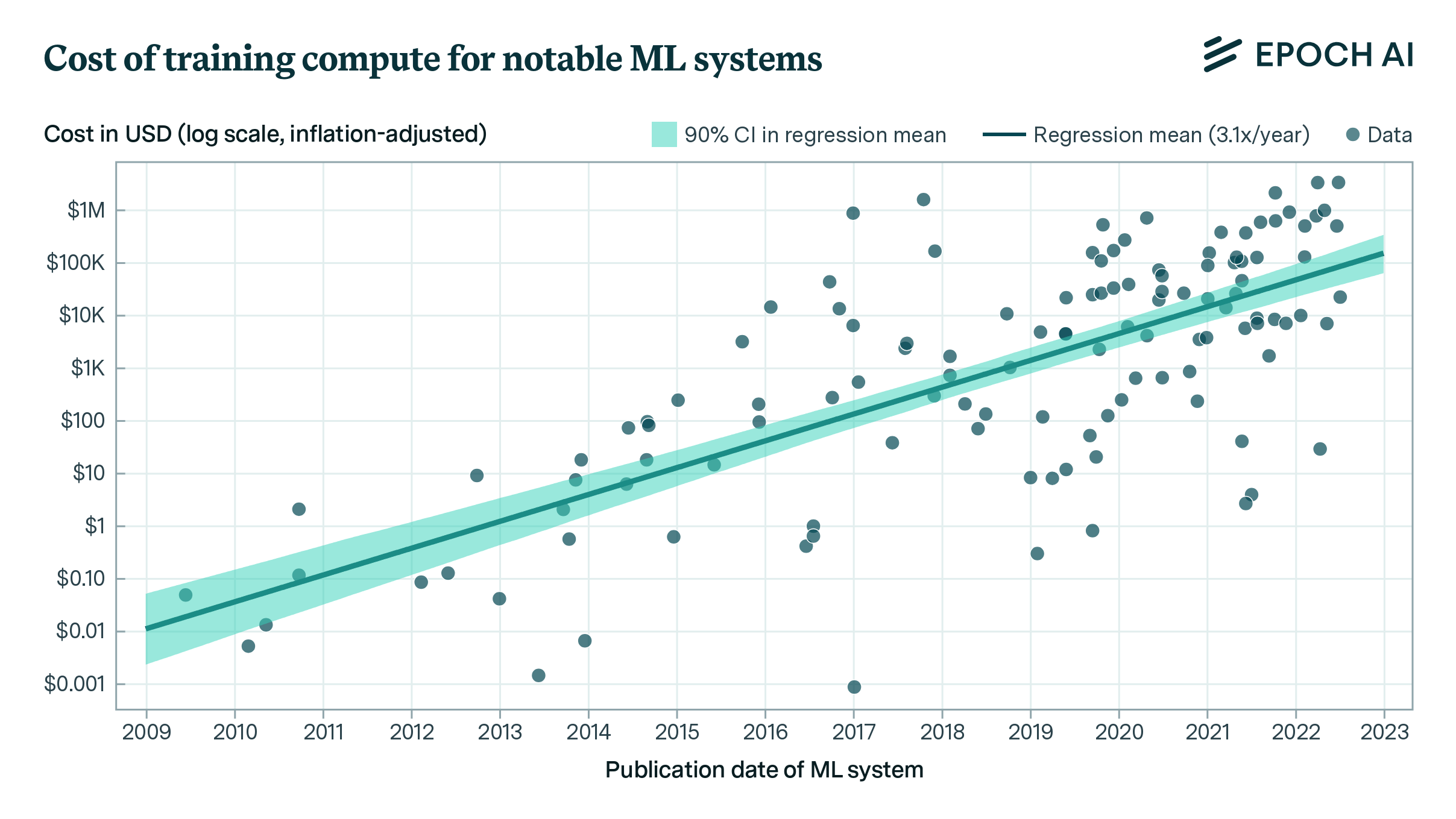
Using a dataset of 124 machine learning (ML) systems published between 2009 and 2022,1 I estimate that the cost of compute in US dollars for the final training run of ML systems has grown by 0.49 orders of magnitude (OOM) per year (90% CI: 0.37 to 0.56).2 See Table 1 for more detailed results, indicated by “All systems.”3
-
By contrast, I estimate that the cost of compute used to train “large-scale” systems since September 2015 (systems that used a relatively large amount of compute) has grown more slowly compared to the full sample, at a rate of 0.2 OOMs/year (90% CI: 0.1 to 0.4 OOMs/year). See Table 1 for more detailed results, indicated by “Large-scale.” (more)
Estimation method | Data | Period | Scale (start to end)4 | Growth rate in dollar cost for final training runs |
|---|---|---|---|---|
(1) Using the overall GPU price-performance trend | All systems (n=124) | Jun 2009– Jul 2022 | $0.02 to $80K | 0.51 OOMs/year 90% CI: 0.45 to 0.57 |
| Large-scale (n=25) | Oct 2015– Jun 2022 | $30K to $1M | 0.2 OOMs/year5 90% CI: 0.1 to 0.4 | |
| (2) Using the peak price-performance of the actual NVIDIA GPUs used to train ML systems (go to results) | All systems (n=48) | Jun 2009– Jul 2022 | $0.10 to $80K | 0.44 OOMs/year6 90% CI: 0.34 to 0.52 |
| Large-scale (n=6)7 | Sep 2016– May 2022 | $200 to $70K | 0.2 OOMs/year 90% CI: 0.1 to 0.4 | |
| Weighted mixture of growth rates8 | All systems | Jun 2009– Jul 2022 | N/A9 | 0.49 OOMs/year 90% CI: 0.37 to 0.56 |
Table 1: Estimated growth rate in the dollar cost of compute to train ML systems over time, based on a log-linear regression. OOM = order of magnitude (10x). See the section Summary of regression results for expanded result tables.
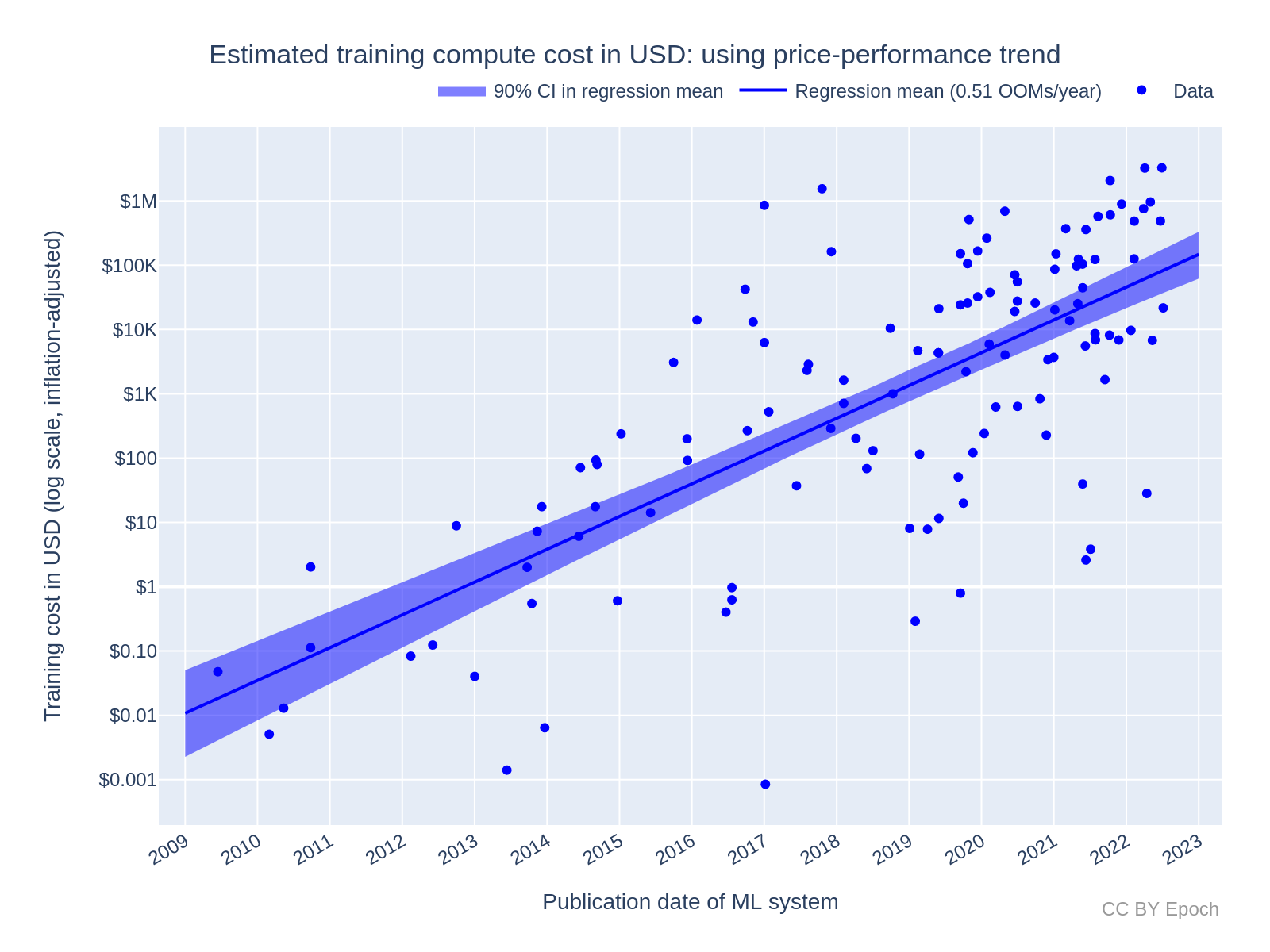
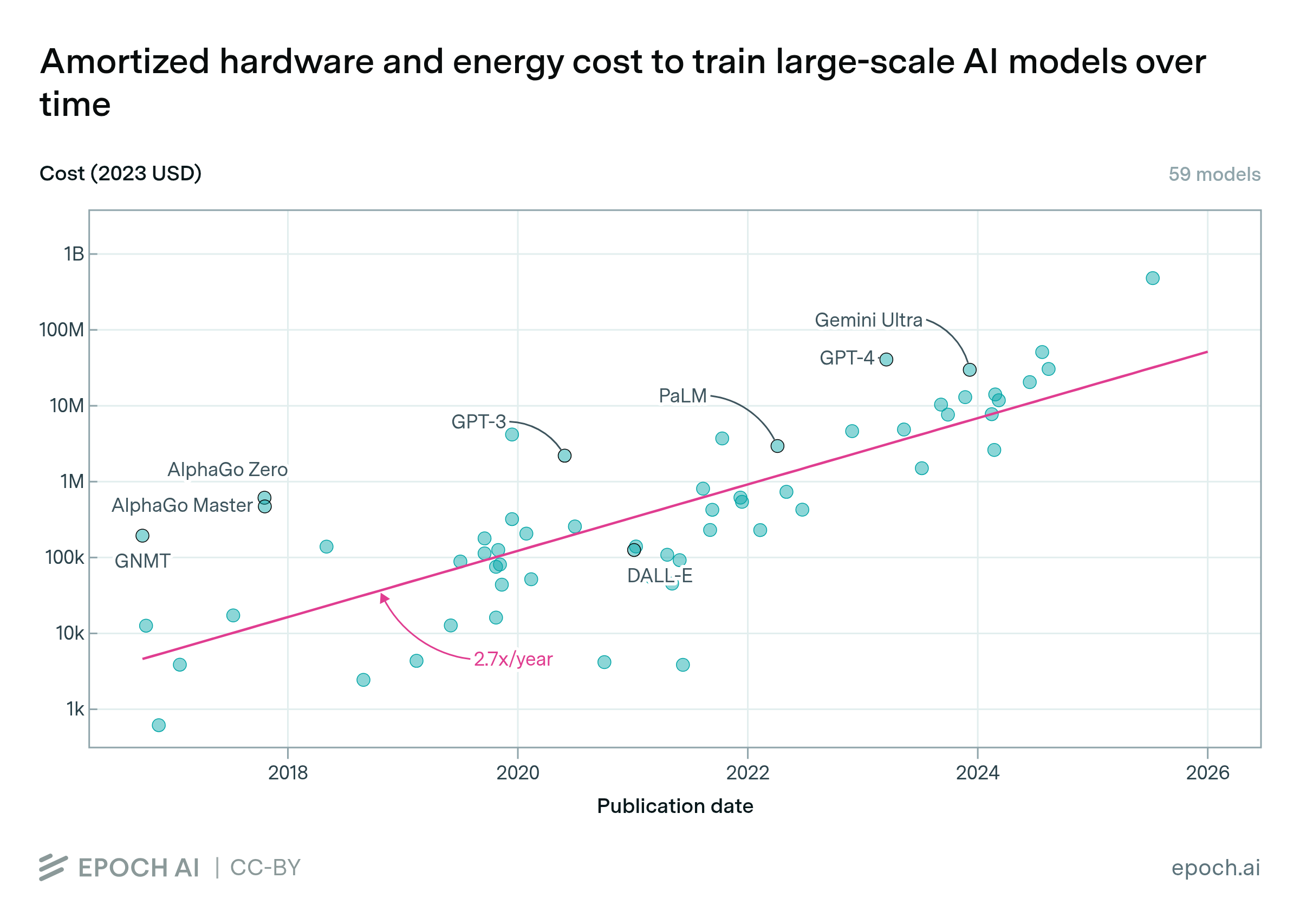
Figure 1: estimated cost of compute in US dollars for the final training run of ML systems. The costs here are estimated based on the trend in price-performance for all GPUs in Hobbhahn & Besiroglu (2022) (known as “Method 1” in this report).
I used the historical results to forecast (albeit with large uncertainty) when the cost of compute for the most expensive training run will exceed $233B, i.e. ~1% of US GDP in 2021. Following Cotra (2020), I take this cost to be an important threshold for the extent of global investment in AI.10 (more)
- Naively extrapolating from the current most expensive cost estimate (Minerva at $3.27M) using the “all systems” growth rate of 0.49 OOMs/year (90% CI: 0.37 to 0.56), the cost of compute for the most expensive training run would exceed a real value of $233B in the year 2032 (90% CI: 2031 to 2036).
- By contrast, my best-guess forecast adjusted for evidence that the growth in costs will slow down in the future, and for sources of bias in the cost estimates.11 These adjustments partly relied on my intuition-based judgements, so the result should be interpreted with caution. I extrapolated from the year 2025 with an initial cost of $380M (90% CI: $55M to $1.5B) using a growth rate of 0.2 OOMs/year (90% CI: 0.1 to 0.3 OOMs/year), to find that the cost of compute for the most expensive training run would exceed a real value of $233B in the year 2040 (90% CI: 2033 to 2062).
For future work, I recommend the following:
- Incorporate systems trained on Google TPUs, and TPU price-performance data, into Method 2. (more)
- Estimate more reliable bounds on training compute costs, rather than just point estimates. For example, research the profit margin of NVIDIA and adjust retail prices by that margin to get a lower bound on hardware cost. (more)
- As a broader topic, investigate trends in investment, spending allocation, and AI revenue. (more)
Why study dollar training costs?
The cost of compute (in units of FLOP) for ML training runs is useful to understand how ML capabilities develop over time. For instance, estimates of compute cost can be combined with performance metrics to measure the efficiency of ML systems over time. However, due to Moore’s Law (and more specifically, hardware price-performance trends), computational costs have become exponentially cheaper (in dollars) over time. In the past decade, growth in compute spending in ML has been much faster than Moore’s Law.12
In contrast to compute, the dollar cost of ML training runs is more indicative of how expensive (in real economic terms) those training runs are, and an actor’s willingness to spend on those training runs. Understanding dollar costs and the willingness to spend can in turn help with forecasting
- The rate of AI progress (due to the dependence of AI development on economic factors, rather than just the innate difficulty of research progress).
- Which actors can financially afford to develop Transformative AI (TAI), which in turn informs which actors will be first to develop TAI.
The primary aim of this work is to address the following questions about training costs:
- What is the growth rate in dollar training cost over time?
- Is the training cost trend stable, slowing down, or speeding up?
- What are the most expensive ML training runs to date?
An additional aim is to explore different methods to estimate the dollar cost and analyze the effect of differences between the methods. I think it is particularly important to explore alternative estimation methods as a way of reducing uncertainty, because there tends to be even less publicly available information about the dollar cost of ML training runs than the compute cost.
Method
Background on methods to estimate the dollar cost of training compute
In this work, I estimate the actual cost of compute for the final training run that produced a given ML system.13 I break down the cost of compute for the final training run into
- Hardware cost: the portion of the up-front cost of hardware spent on the training run.
- Energy cost: the cost of electricity to power the hardware during the training run.
To estimate hardware cost, the simplest model I am aware of is:14
\[ \textit{hardware\_cost} = \frac{\textit{training\_time}}{\textit{hardware\_replacement\_time}} \cdot \textit{n\_hardware} \cdot \textit{hardware\_unit\_price} \]where training_time is the number of GPU hours used per hardware unit for training, and hardware_replacement_time is the total number of GPU hours that the hardware unit is used before being replaced with new hardware.
The model here is that a developer buys n_hardware units at hardware_unit_price and uses each hardware unit for a total duration of hardware_replacement_time. So the up-front cost of the hardware is amortized over hardware_replacement_time, giving a value in $/s for using the hardware. The developer then spends training_time training a given ML system at that $/s rate. Note that this neglects hardware-related costs other than the sale price of the hardware, e.g., switches and interconnect cables.
To estimate energy cost, the simplest model I am aware of is:15
\[ \textit{energy\_cost} = \textit{training\_time} \cdot \textit{n\_hardware} \cdot \textit{hardware\_power\_consumption} \cdot \textit{energy\_rate} \]Where hardware_power_consumption is in kW and energy_rate is in $/kWh. Maximum power consumption is normally listed in hardware datasheets—e.g., the NVIDIA V100 PCIe model is reported to have a maximum power consumption of 0.25kW.
Using cloud compute prices provides a way to account for hardware, energy and maintenance costs without estimating them individually. Cloud compute prices are normally expressed in $ per hour of usage and per hardware unit (e.g., 1 GPU).16 So to calculate the cost of computing the final training run with cloud computing, one can just use
\[ \textit{training\_cost} = \textit{training\_time} \cdot \textit{n\_hardware} \cdot \textit{cloud\_computing\_price} \]However, because cloud compute vendors need to make a profit, the cloud computing price would also include a margin added to the costs of the vendor. For this reason, cloud computing prices (especially on-demand rather than discounted prices) are useful as an upper bound on the actual training cost. In this work, I only estimate costs using hardware prices rather than cloud compute prices.
Estimating training cost from training compute and GPU price-performance
The estimation models presented in the previous section seem to me like the simplest models, which track the variables that are most directly correlated with cost (e.g., the number of hardware units purchased). Those models therefore minimize sources of uncertainty. However, information about training time and the number of hardware units used to train an ML system is often unavailable. On the other hand, information that is sufficient to estimate the training compute of an ML system is more often available. Compute Trends Across Three Eras of Machine Learning (Sevilla et al., 2022) and its accompanying database17 provide the most comprehensive set of estimates of training compute for ML systems to date.18 Due to the higher data availability, I chose an estimation model that uses the training compute in FLOP, rather than the models presented in the previous section.
To estimate the hardware cost from training compute, one also needs to know the price-performance of the hardware in FLOP/s per $. In this work, I use the price-performance trend found for all GPUs (n=470) in Trends in GPU price-performance. I also use some price-performance estimates for individual GPUs from the dataset of GPUs in that work (see this appendix for more information). I only estimate hardware cost and not energy cost. This is because (a) energy cost seems less significant (see this appendix for evidence), and (b) data related to hardware throughput and compute was more readily available to me than data on energy consumption.
The actual model I used to estimate the hardware cost of training (in $) for a given ML system was:
\[\textit{hardware_cost} = \textit{training_compute} / \textit{realised_training_compute_per_\$}\]where realised_training_compute_per_$ is in units of FLOP/$:
\[\textit{realised_training_compute_per_\$} = \textit{hardware_price_performance} \cdot \textit{hardware_utilization_rate} \cdot \textit{hardware_replacement_time}\]Where hardware_utilization_rate is the fraction of the theoretical peak FLOP/s throughput that is realized in training. The hardware_price_performance is in FLOP/s per $:
\[ \textit{hardware\_price\_performance} = \textit{peak\_throughput} / \textit{hardware\_unit\_price} \]There are several challenges for this model in practice:
-
Training compute is itself an estimate based on multiple variables, and tends to have significant uncertainty.19
-
Hardware replacement time varies depending on the resources and needs of the developer. For example, a developer may upgrade their hardware sooner due to receiving enough funding to perform a big experiment, even though they haven’t “paid off” the cost of their previous hardware with research results.
-
Information on the hardware utilization rate achieved for a given ML system is often unreliable.
-
Hardware unit prices vary over time—in recent years (since 2019), fluctuations of about 1.5x seem typical.20
I made the following simplifying assumptions that neglect the above issues:
- The training compute estimate is the true value.
- Hardware replacement time is constant at two years.21
- A constant utilization rate of 35% was achieved during training.22
- For each hardware model, I used whatever unit price I could find that was reported closest to the release date of the hardware, as long as it was reported by a seemingly credible source. (More information on data sources is in this appendix.)
Although the results in this work rely on the above assumptions, I attempted to quantify the impact of the assumptions in this appendix to estimate my actual best guess and true uncertainty about the cost of compute for the final training runs of ML systems.
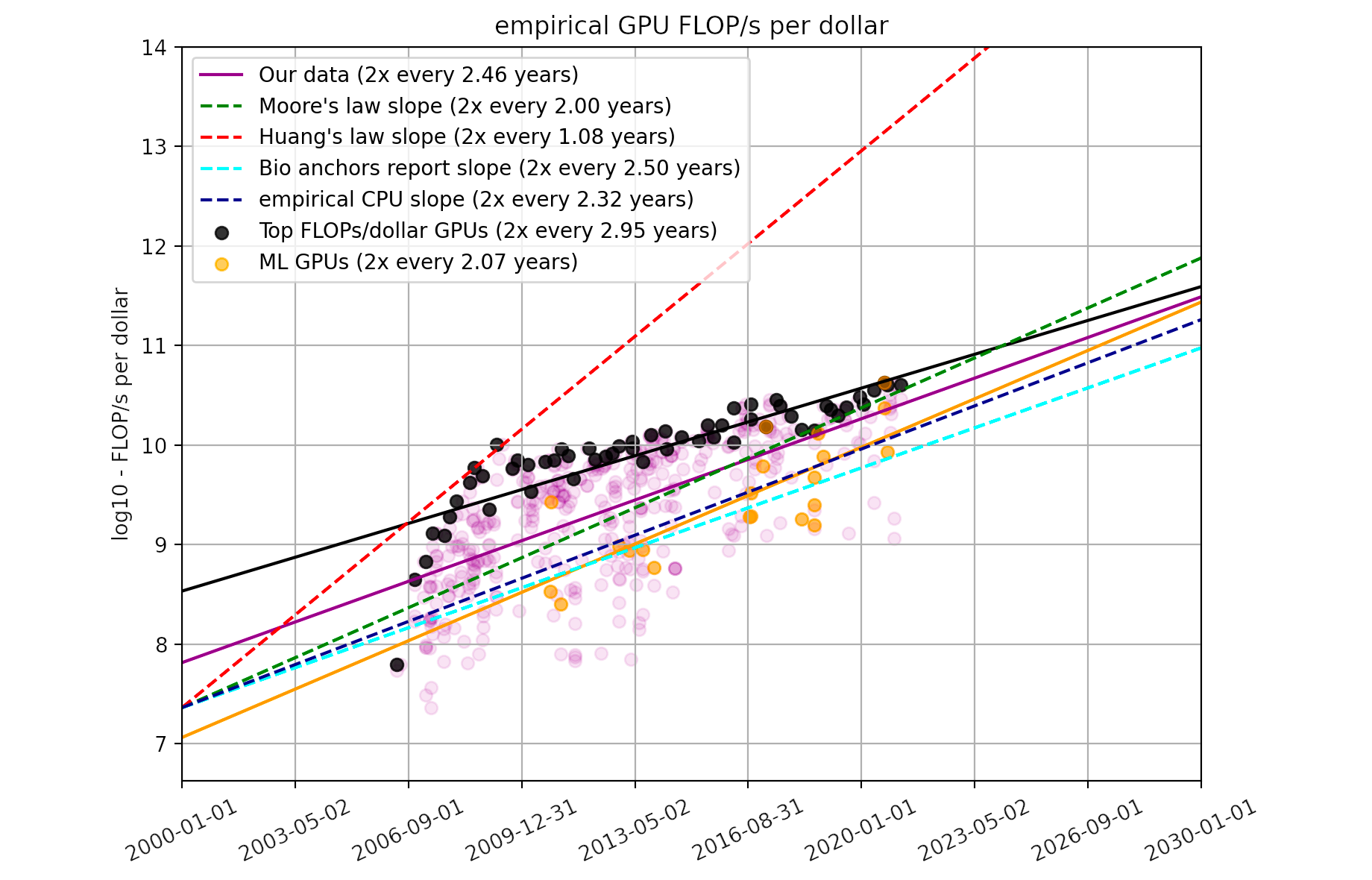
Method 1: Using the overall GPU price-performance trend
One way of estimating the hardware_price_performance variable is to use the overall trend in price-performance over time. This saves from needing to know the actual hardware used for each ML system. Trends in GPU price-performance estimated that on average, the price-performance of GPU hardware in FLOP/s per $ has doubled approximately every 2.5 years. I used this trend as my first method of estimating price-performance. In particular, I calculated price-performance as the value of the trend line at the exact time an ML system was published.
Method 2: Using the price-performance of actual hardware used to train ML systems
Method 1 is unrealistic in the following ways:
- The purchase of hardware would actually happen before the publication date of the system, perhaps months or years before the training run started.
- The actual price-performance that can be achieved is discrete.
- Firstly, price-performance depends on which GPUs are available at a given time. The time at which new GPUs become available is discrete and somewhat irregular, as seen in the plots in Trends in GPU price-performance.
- Secondly, price-performance depends on the actual choice of hardware. The actual price-performance varies depending on the specific hardware model, and the hardware that was actually used may be older than the latest available hardware on the market.
In an effort to address these limitations, my second estimation method is based on the price-performance of the actual hardware used to train a given ML system. For example, GPT-3 was reported to use NVIDIA V100 GPUs. So to estimate the training cost of GPT-3, I used the actual FLOP/s specification of the V100, and its estimated unit price, to calculate the price-performance in FLOP/s per $. I then used that price-performance value in the hardware cost formula above.
Dataset
My dataset is available at Training cost trends in machine learning. Details of how the data were collected and processed are in this appendix.
Code
All results were produced using the accompanying Colab notebook.
Large-scale systems
The main results presented in Compute Trends Across Three Eras of Machine Learning involved splitting one compute trend into two simultaneous trends from late 2015 onwards. One of these trends was for “large-scale” systems—systems that were outliers above the mean compute trend for all systems (i.e., systems that used an abnormally high amount of training compute). Given the relationship between training compute and AI capabilities,23 the trend for these large-scale systems can better inform what the frontier of AI capabilities will be at future times.
To get a dataset of training costs for large-scale systems, I started with the same set of systems as Compute Trends Across Three Eras of Machine Learning. I then added the following systems that were released more recently, based on visual inspection of the plot presented in this results section:24 ‘Chinchilla,’ ‘PaLM (540B),’ ‘OPT-175B,’ ‘Parti,’ and ‘Minerva (540B).’
Results
Method 1: Using the overall GPU price-performance trend for all ML systems (n=124)
Growth rate of training cost for all ML systems: 0.51 OOMs/year
Figure 2 plots the training cost of the selected ML systems (n=124) against the system’s publication date, with a linear trendline (note the log-scaled y axis). Applying a log-linear regression, I find a growth rate of 0.51 OOMs/year (90% CI: 0.45 to 0.57 OOMs/year) in the dollar cost of compute for final training runs. Notably, this trend represents slower growth than the 0.7 OOMs/year (90% CI: 0.6 to 0.7 OOMs/year) for the 2010 – 2022 compute trend in FLOP for “all systems” (n=98) in Sevilla et al. (2022, Table 3).
Note that this estimate of growth rate is just a consequence of combining the log-linear trends in compute and price-performance. A similar growth rate can be estimated simply by taking the growth rate in compute (0.7 OOMs/year) and subtracting the growth rate in GPU price-performance (0.12 OOMs/year), as reported in prior work.25
Based on the fitted trend, the predicted growth in training cost for an average milestone ML system by the beginning of 2030 is:
- +3.6 OOMs (90% CI: +3.2 to +4.0 OOMs) relative to the end of 2022
- $500M (90% CI: $90M to $3B)
Here, and in all subsequent results like the above, I am more confident in the prediction of additional growth in OOMs than the prediction of exact cost, because the former is not sensitive to any constant factors that may be inaccurate, e.g., the hardware replacement time and the hardware utilization rate.
Figure 2: Estimated training compute cost of milestone ML systems using the continuous GPU price-performance trend. See this Colab notebook cell for an interactive version of the plot with ML system labels.
Growth rate of training cost for large-scale ML systems: 0.2 OOMs/year
After fitting a log-linear regression to the “large-scale” set of systems, I obtained the plot in Figure 3. The resulting slope was approximately 0.2 OOMs/year (90% CI: 0.1 to 0.4 OOMs/year). While this result is based on a smaller sample (n=25 compared to n=124), I think the evidence is strong enough to conclude that the cost of the most expensive training run is growing significantly slower than milestone ML systems as a whole. This is consistent with the direction of predictions in AI and Compute (from CSET), and Cotra’s “Forecasting TAI with biological anchors”26—namely, that recent growth spending will likely slow down greatly during the 2020s, given the current willingness of leading AI developers to spend on training, and given that the recent overall growth rate seems unsustainable.
Clearly, the growth rate of large-scale systems cannot be this much lower than the growth rate of all systems for long—otherwise, the growth in all systems would quickly overtake the current large-scale systems. The main reason that the large-scale growth is much slower seems to be that the selection of “large-scale” systems puts more weight on high-compute outliers. Outliers that occurred earlier in this dataset such as AlphaGo Master and AlphaGo Zero are particularly high, which makes later outliers look less extreme. However, I don’t think this undercuts the conclusion that spending on large-scale systems has grown at a slower rate; rather, it adds uncertainty about the future costs of large-scale systems.
Based on the fitted trend, the predicted growth in training cost for a large-scale ML system by the beginning of 2030 is:
-
+1.8 OOM (90% CI: +1.0 to +2.4 OOM) relative to the end of 2022.27
-
$80M (90% CI: $6M to $700M)
So although the large-scale trend starts higher than the average trend for all systems (see the previous section), the slower growth leads to a lower prediction than $500M (90% CI: $100M to $3B).
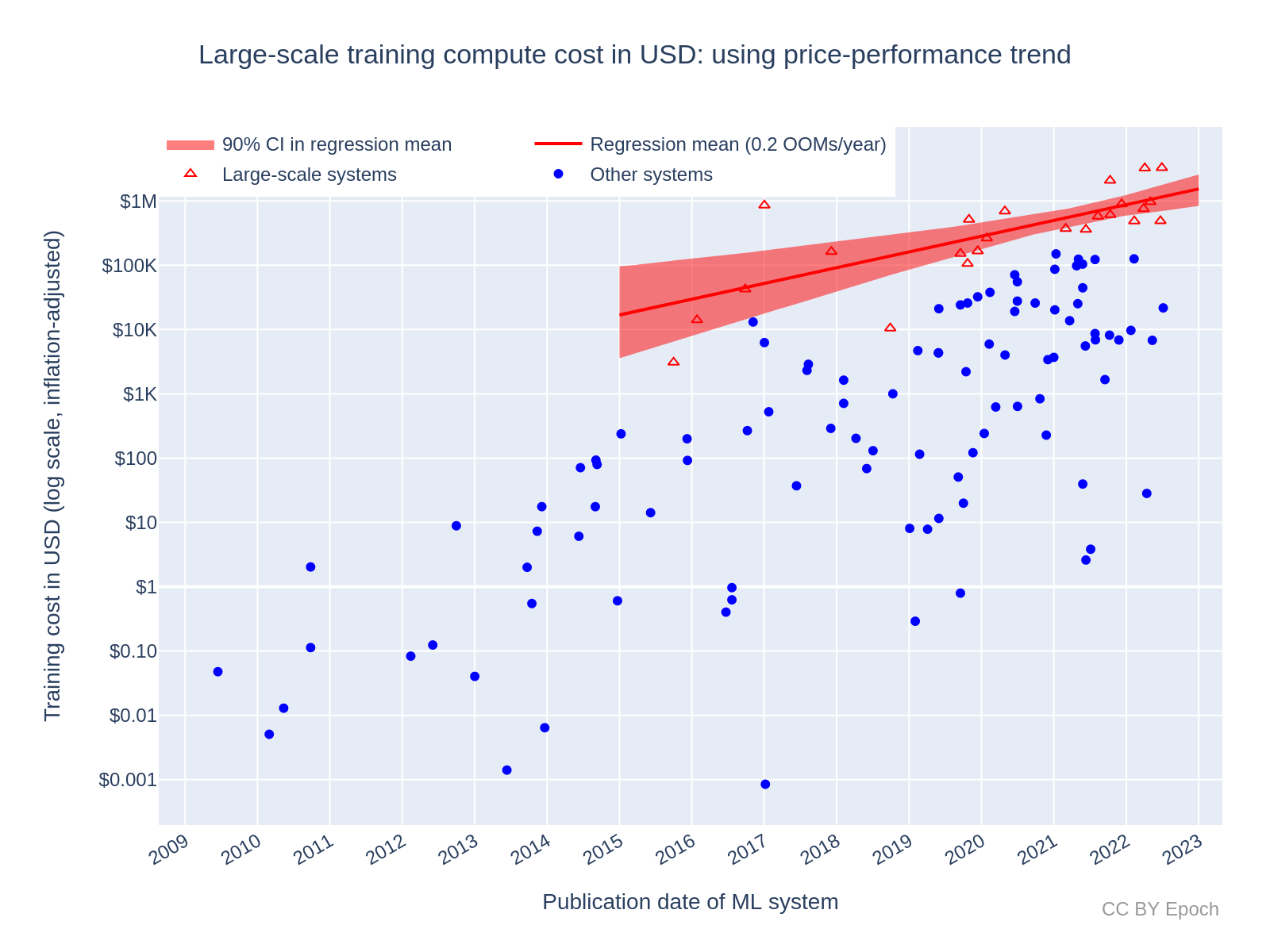
Figure 3: Estimated training compute cost of large-scale ML systems using Method 1. See this Colab notebook cell for an interactive version of the plot with ML system labels.
Method 2: Using the price-performance of NVIDIA GPUs used to train ML systems (n=48)
Growth rate of training cost for all ML systems: 0.44 OOMs/year
Figure 4 plots the order-of-magnitude of training cost of ML systems trained with NVIDIA GPUs (n=48) against the system’s publication date, with a linear trendline. I find a trend of 0.44 OOMs/year (90% CI: 0.34 to 0.52). So this model predicts slower growth than the model based on the overall GPU price-performance trend, which was 0.51 OOMs/year (90% CI: 0.44 to 0.59). It turns out that this difference in growth rate (in OOMs/year) is merely due to the smaller dataset, even though the estimates of absolute cost (in $) are roughly twice as large as those of Method 1 on average.28
Based on the fitted trend, the predicted growth in training cost for an average milestone ML system by the beginning of 2030 is
- +3.1 OOM (90% CI: +2.4 to +3.6 OOM) relative to the end of 2022
- $200M (90% CI: $8M to $2B)
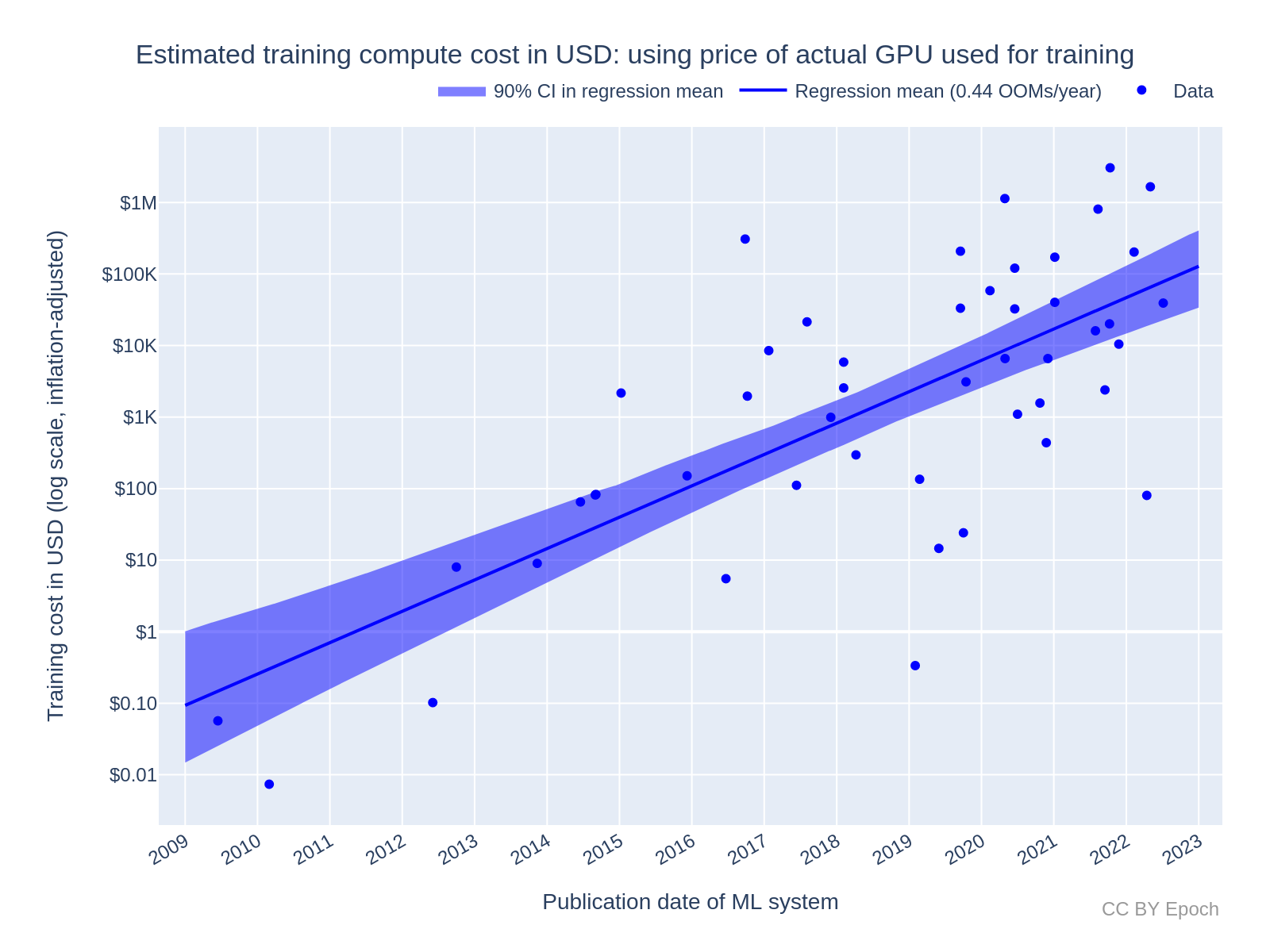
Figure 4: Estimated training compute cost of milestone ML systems using the peak price-performance of the actual NVIDIA GPUs used in training. See this Colab notebook cell for an interactive version of the plot with ML system labels.
Growth rate of training cost for large-scale ML systems: 0.2 OOMs/year
For the trend in large-scale systems, I used the same method to filter large-scale systems as in Method 1, but only included the systems that were in the smaller Method 2 sample of n=48. This left only 6 systems. After fitting a log-linear regression to this set of systems, I obtained the plot in Figure 5. The resulting slope was approximately 0.2 OOMs/year (90% CI: 0.1 to 0.4 OOMs/year). The sample size is very small and the uncertainty is very large, so this result should be taken with a much lower weight than other results. I think the prediction that this regression makes for 2030 should be disregarded in favor of Method 1. However, the result is at least consistent with Method 1 in suggesting that the cost of the most expensive training run has been growing significantly slower than milestone ML systems as a whole.
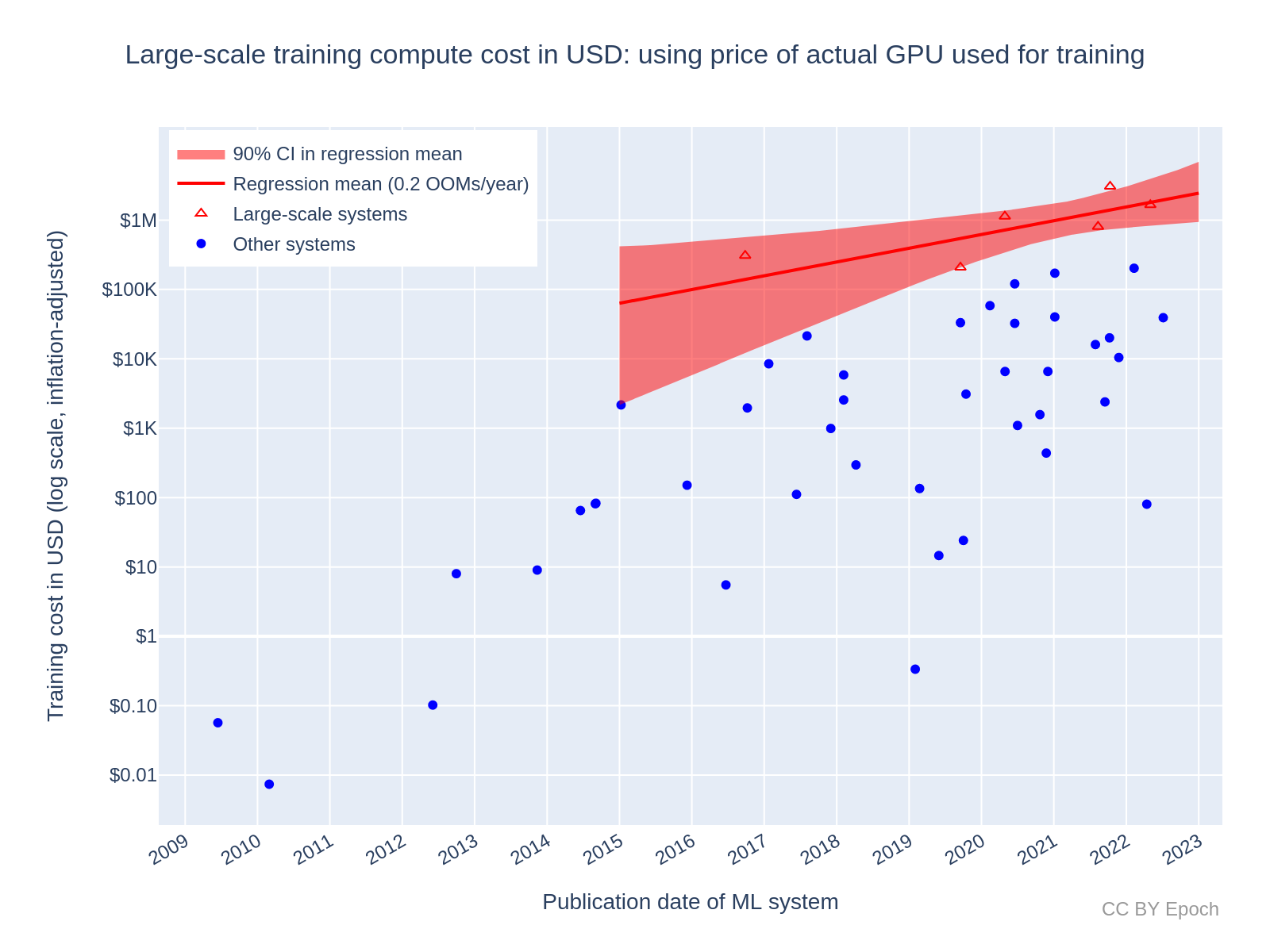
Figure 5: Estimated training compute cost of large-scale ML systems using Method 2. See this Colab notebook cell for an interactive version of the plot with ML system labels.
Summary and comparison of all regression results
Table 2 and Table 3 summarize all of the regression results for “All systems” and “Large-scale” systems, respectively. Based on an analysis of how robust the regression results for “All systems” are to different date ranges, the mean growth rate predicted by Method 1 seems reasonably robust across different date ranges, whereas Method 2 is much less robust in this way (see this appendix for more information). However, I believe that the individual cost estimates via Method 2 are more accurate, because Method 2 uses price data for the specific hardware used to train each ML system. Overall, I think the growth rate obtained via Method 1 is more robust for my current dataset, but that conclusion seems reasonably likely to change if a comparable number of data points are acquired for Method 2. Collecting that data seems like a worthwhile task for future work.
| Estimation method | Period | Data | Growth rate (OOMs/year) | Predicted average cost by 2030 |
|---|---|---|---|---|
| Method 1 (using average trend in hardware prices) | 2009– 2022 | All systems (n=124) | 0.51 90% CI: 0.45 to 0.57 | $500M (90% CI: $90M to $3B) |
| Method 2 (using actual hardware prices) | 2009– 2022 | All systems (n=48) | 0.44 OOMs/year 90% CI: 0.34 to 0.52 | $200M (90% CI: $8M to $2B) |
| Weighted mixture of results29 | 2009– 2022 | All systems | 0.49 OOMs/year 90% CI: 0.37 to 0.56 | $350M (90% CI: $40M to $4B)30 |
| Compute trend (for reference)31 | 2010– 2022 | All systems (n=98) | 0.7 OOMs/year 95% CI: 0.6 to 0.7 | N/A |
| GPU price-performance trend (for reference)32 | 2006– 2021 | All GPUs (n=470) | 0.12 OOMs/year 95% CI: 0.11 to 0.13 | N/A |
Table 2: Estimated growth rate in the dollar cost of compute for the final training run of milestone ML systems over time, based on a log-linear regression. For reference, the bottom two rows show trends in training compute (in FLOP) and GPU price-performance (FLOP/s per $) found in prior work.
| Estimation method | Period | Data | Growth rate (OOMs/year) | Predicted average cost by 2030 |
|---|---|---|---|---|
| Method 1 (using average trend in hardware prices) | 2015–2022 | Large-scale (n=25) | 0.2 OOMs/year 90% CI: 0.1 to 0.4 | $80M (90% CI: $6M to $700M) |
| Method 2 (using actual hardware prices) | 2015–2022 | Large-scale (n=6) | 0.2 OOMs/year 90% CI: 0.1 to 0.4 | $60M (90% CI: $2M to $9B) |
| Compute trend (for reference)33 | 2015–2022 | Large-scale (n=16) | 0.4 OOMs/year 95% CI: 0.2 to 0.5 | N/A |
Table 3: Estimated growth rate in the dollar cost of compute for the final training run of large-scale ML systems over time, based on a log-linear regression. The bottom row shows the trend in training compute (in FLOP) found in prior work, for reference.
Predictions of when a spending limit will be reached
The historical trends can be used to forecast (albeit with large uncertainty) when the spending on compute for the most expensive training run will reach some limit based on economic constraints. I am highly uncertain about the true limits to spending. However, following Cotra (2020), I chose a cost limit of $233B (i.e. 1% of US GDP in 2021) because this at least seems like an important threshold for the extent of global investment in AI.34
I used the following facts and estimates to predict when the assumed limit would be reached:
- US GDP: $23.32 trillion in 202135
- Chosen threshold of spending: 1% of GDP = 0.01 * $23.32T = $233.2B
- This number is approximately equal to 10^11.37
- Historical starting cost estimate: $3.27M (Minerva) 2. This number is approximately equal to 10^6.51 3. Minerva occurs at approximately 2022.5 years (2022-Jun-29)
- Estimated cost at the beginning of 2025: $60M36 4. This is approximately 10^7.78
- Formula to estimate the year by which the cost would reach the spending limit: [starting year] + ([ceiling] - [start] in OOMs) / [future growth rate in OOMs/year] 5. An example using numbers from above: 2022.5 + (11.37 - 6.51 OOMs) / (0.49 OOMs/year) ~= 2032
These were my resulting predictions, first by naive extrapolation and then based on my best guess:
- Naively extrapolating from the current most expensive cost estimate (Minerva, $3.27M) using historical growth rates:
- Using the “all systems” trend of 0.49 OOMs/year (90% CI: 0.37 to 0.56), a cost of $233.2B would be reached in the year 2032 (90% CI: 2031 to 2036). This extrapolation is illustrated in Figure 6.
- Using the “large scale” trend of 0.2 OOMs/year (90% CI: 0.1 to 0.4), a cost of $233.2B would be reached in the year 2047 (90% CI: 2035 to 2071).
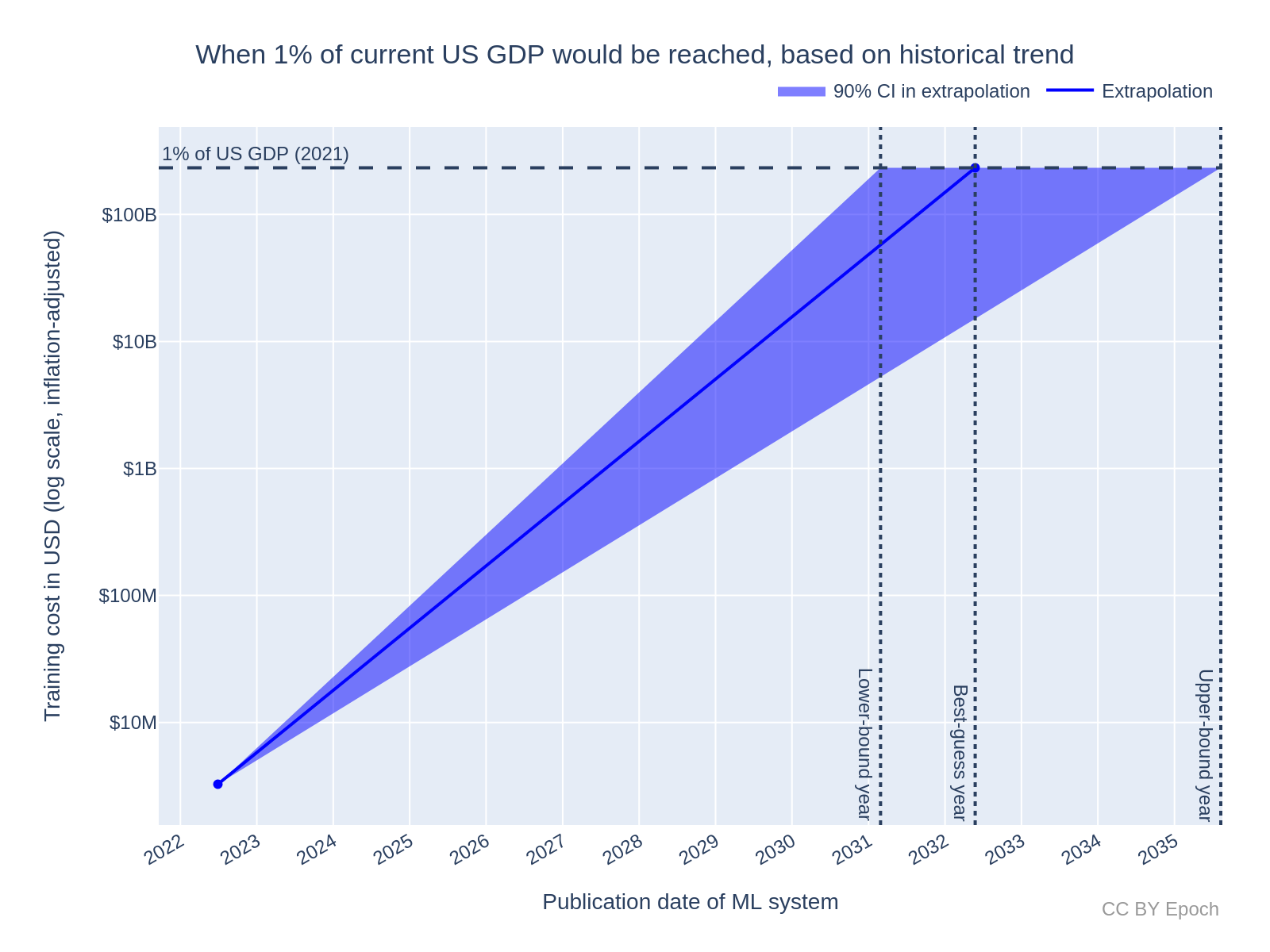
Figure 6: Extrapolation of training cost to 1% of current US GDP, based only on the current most expensive cost estimate (Minerva, $3.27M) and the historical growth rate found for “all systems”.
My best guess adjusts for evidence that the growth in costs will slow down in the future, and for sources of bias in the cost estimates.37 These adjustments partly rely on my intuition-based judgements, so the results should be interpreted with caution. The results are38:
Independent impression39: extrapolating from the year 2025 with an initial cost of $200M (90% CI: $29M to $800M) using a growth rate of 0.3 OOMs/year (90% CI: 0.1 to 0.4 OOMs/year), a cost of $233.2B would be reached in the year 2036 (90% CI: 2032 to 2065).
All-things-considered view: extrapolating from the year 2025 with an initial cost of $380M (90% CI: $55M to $1.5B) using a growth rate of 0.2 OOMs/year (90% CI: 0.1 to 0.3 OOMs/year), a cost of $233.2B would be reached in the year 2040 (90% CI: 2033 to 2062). This extrapolation is illustrated in Figure 7.
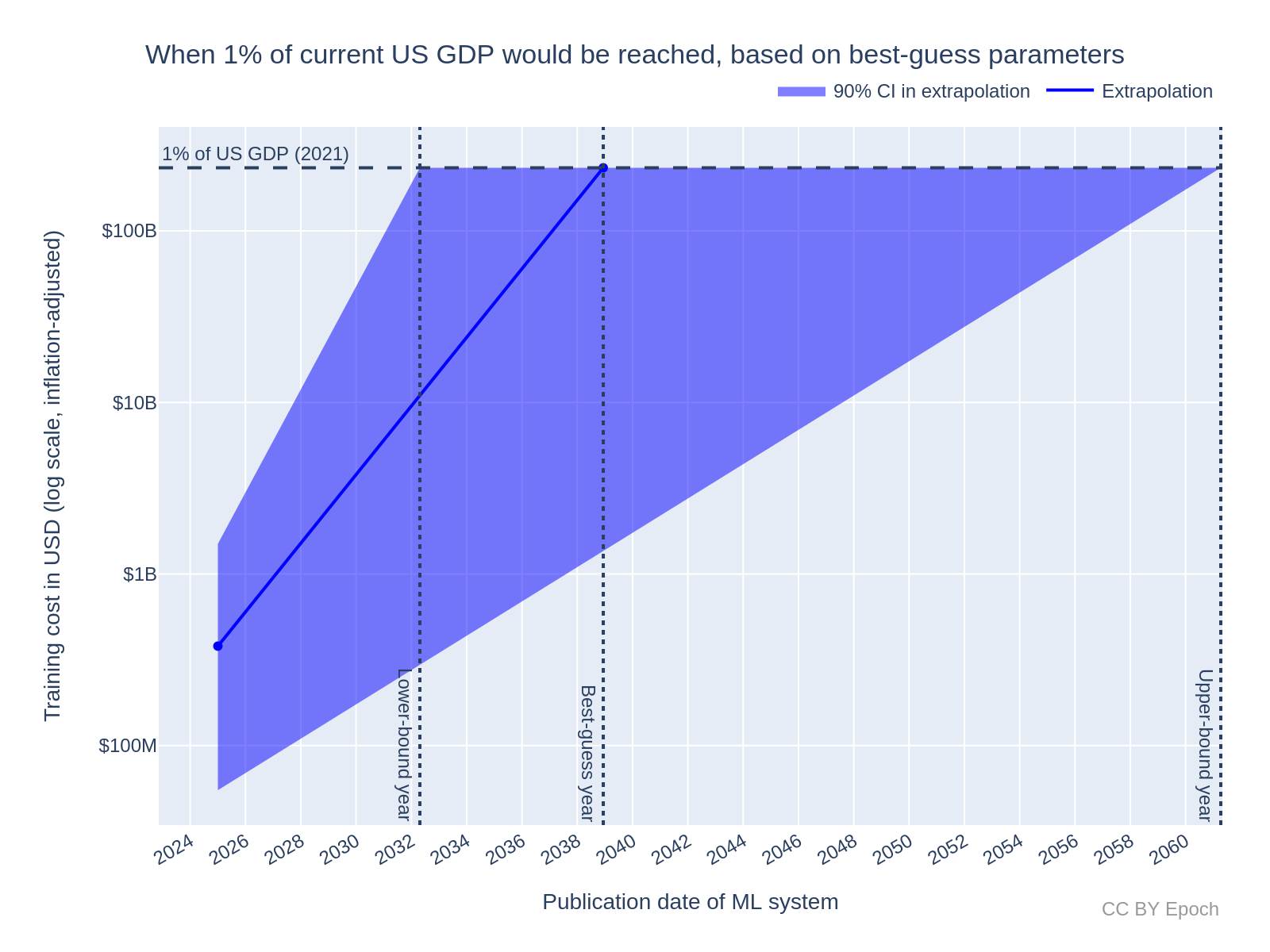
Figure 7: Extrapolation of training cost to 1% of current US GDP, based on my best-guess parameters for the most expensive cost in 2025 and the growth rate. Note that the years I reported in the text are about 1 year later than the deterministic calculations I used in this plot—I suspect this is due to the Monte Carlo estimation method used in Guesstimate.
Recommended future work
Include systems trained with Google TPUs for Method 2
The dataset used for Method 2 only had 48 samples, compared to 124 samples for Method 1. Furthermore, the dataset only included ML systems that I could determine to be trained using NVIDIA GPUs. Future work could include other hardware, especially Google TPUs, which I found were used to train at least 25 of the systems in my dataset (some systems have missing data, so it could be more than 25).
Estimate more reliable bounds on cost using cloud compute prices and profit margins
For future work I recommend estimating more reliable bounds on FLOP/$ (and in turn the hardware cost of training runs) by extending the following methods:40
- FLOP/$ estimation method 1: Dividing the peak performance of the GPU (in FLOP/s) by its price (in $) to get the price-performance. Multiplying that by a constant hardware replacement time (in seconds) to get a value in FLOP/$.
- Extension 1: estimate the profit margin of NVIDIA for this GPU. Adjust the reported/retail price by that margin to get a lower bound on hardware cost (i.e., basically the manufacturing cost). Then use that cost instead of the reported/retail price to get an upper-bound value of FLOP/s per $ which can be used in Method 1.
- This can provide a lower bound on training compute cost, because the hardware is as cheap as possible.
- Extension 2: divide the reported/retail price (or the estimated manufacturing cost, as in Extension 1) in $ by the cloud computing rental prices in $/hour to estimate the hardware replacement time. Then use that value in Method 1.
- If the manufacturing cost is a lower bound on price, and on-demand cloud computing rental prices are an upper bound on price per hour, then this gives a lower bound on hardware replacement time.
- Using the retail price and the maximally discounted rental price (e.g., the discount for a three-year rental commitment) would instead make this estimate closer to an upper bound on hardware replacement time.
- Extension 1: estimate the profit margin of NVIDIA for this GPU. Adjust the reported/retail price by that margin to get a lower bound on hardware cost (i.e., basically the manufacturing cost). Then use that cost instead of the reported/retail price to get an upper-bound value of FLOP/s per $ which can be used in Method 1.
- FLOP/$ estimation method 2: Dividing the peak performance of the GPU (FLOP/s) by its current cloud computing rental cost ($/hour) to get a value in FLOP/$.
- Extension 1: extrapolate from this present FLOP/$ value into the past at time t (the publication date of the ML system), using the overall GPU price-performance growth rate. Here we assume that FLOP/$ and FLOP/s per $ differ only by a constant factor, so the growth rate is the same for FLOP/$ and FLOP/s per $.
- Using the resulting FLOP/$ value then gives an upper bound on training compute cost, because on-demand hourly cloud compute prices have a relatively large profit margin, and I expect that any ML systems in my dataset which were trained with cloud compute were very likely to take advantage of the discounts that are offered by cloud computing services.41
- Extension 1: extrapolate from this present FLOP/$ value into the past at time t (the publication date of the ML system), using the overall GPU price-performance growth rate. Here we assume that FLOP/$ and FLOP/s per $ differ only by a constant factor, so the growth rate is the same for FLOP/$ and FLOP/s per $.
Investigate investment, allocation of spending, and revenue
An important broad topic for further investigation is to understand the trends of and the relationships between investment in AI, the allocation of spending on AI, and revenue generated by AI systems. This would inform estimates of the willingness to spend on AI in the future, and whether the growth rate in large-scale training compute cost will continue to decrease, remain steady, or increase. This in turn informs forecasts of when TAI will arrive, and what the impacts of AI will be in the meantime.
Appendices
Appendix A: The energy cost of final training runs seems about 20% as large as the hardware cost
Appendix B: Data collection and processing
Appendix C: Regression method
Appendix D: Inspecting the price-performance of NVIDIA GPUs as a function of ML system publication date
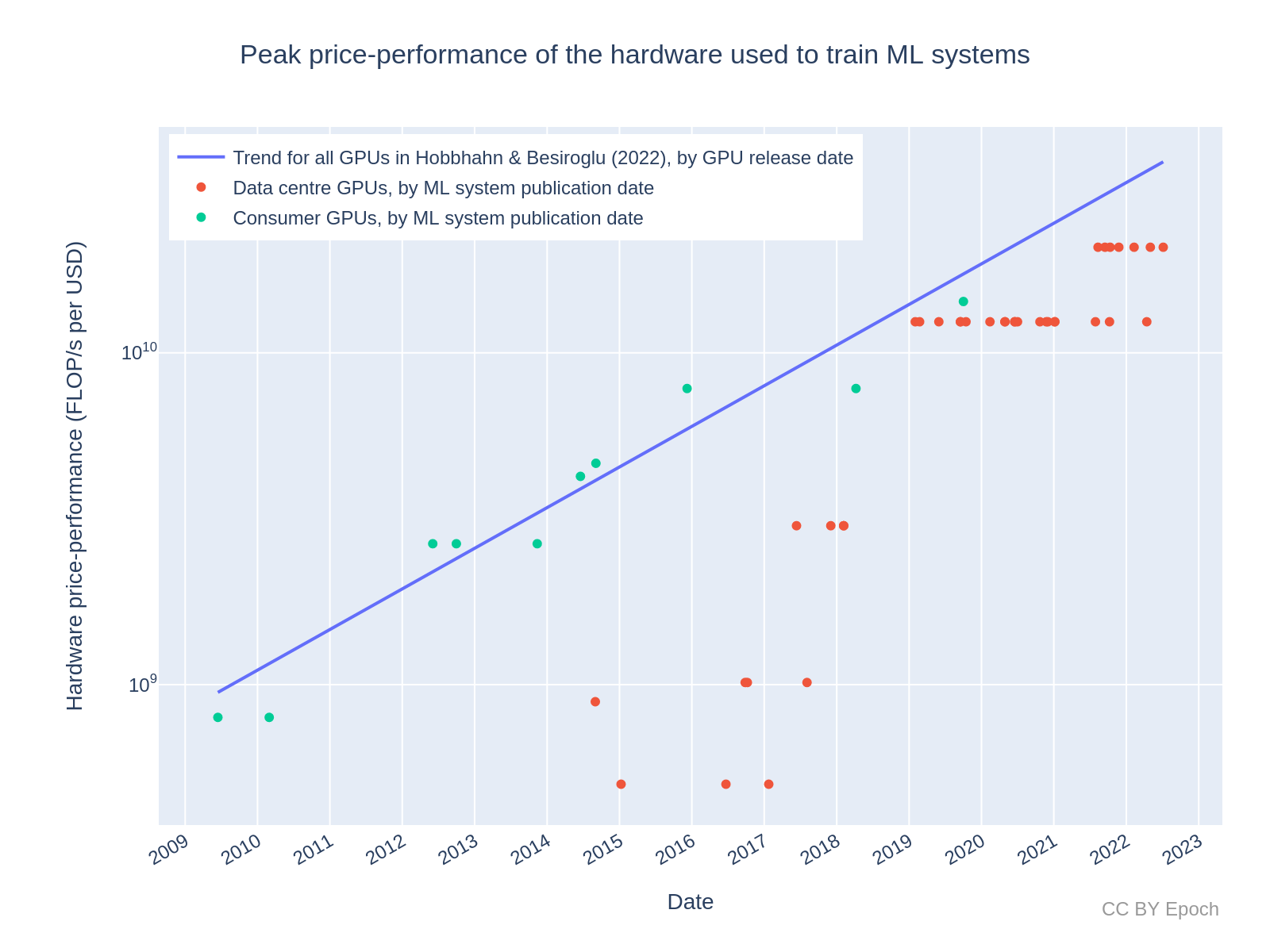
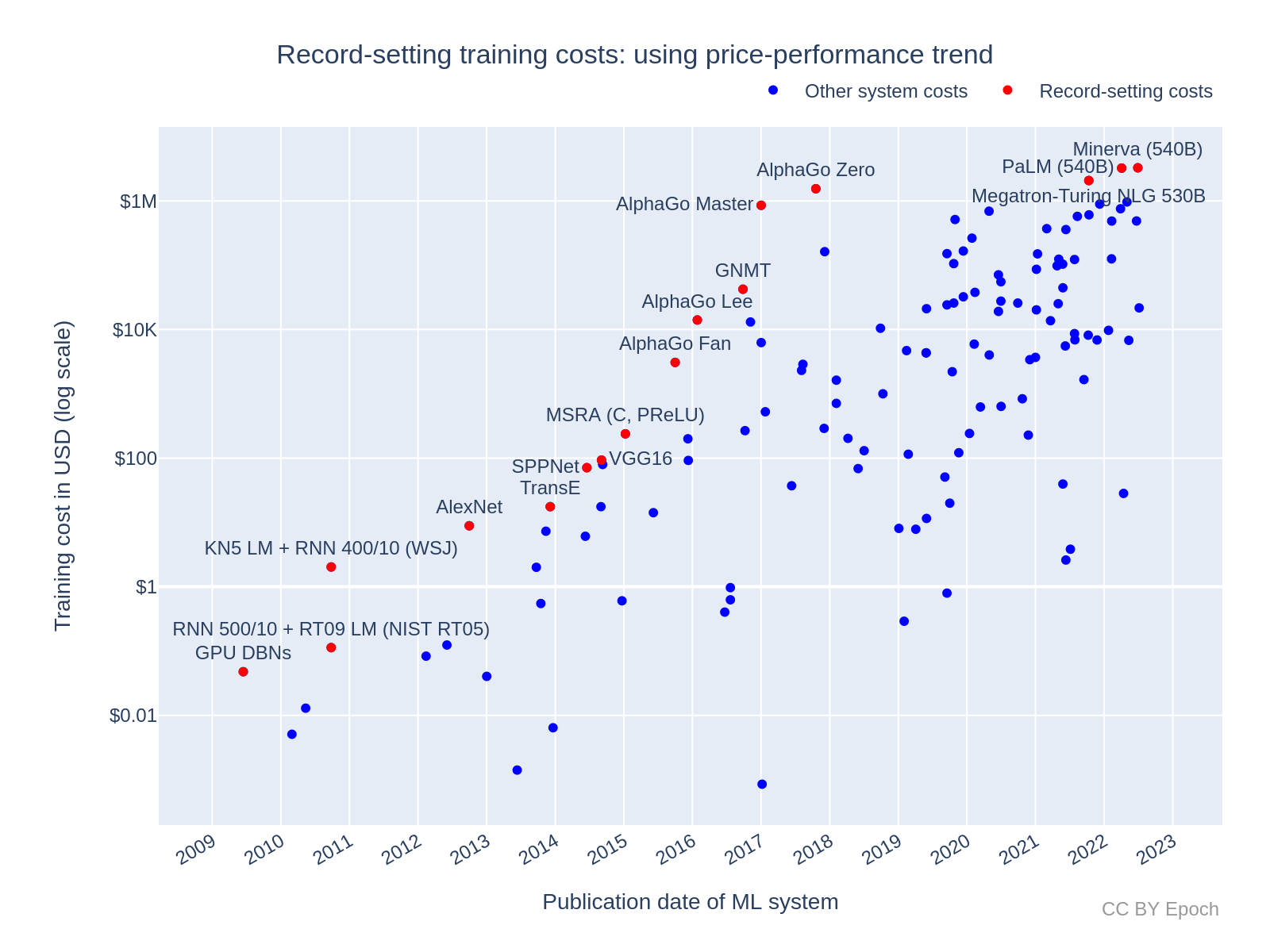
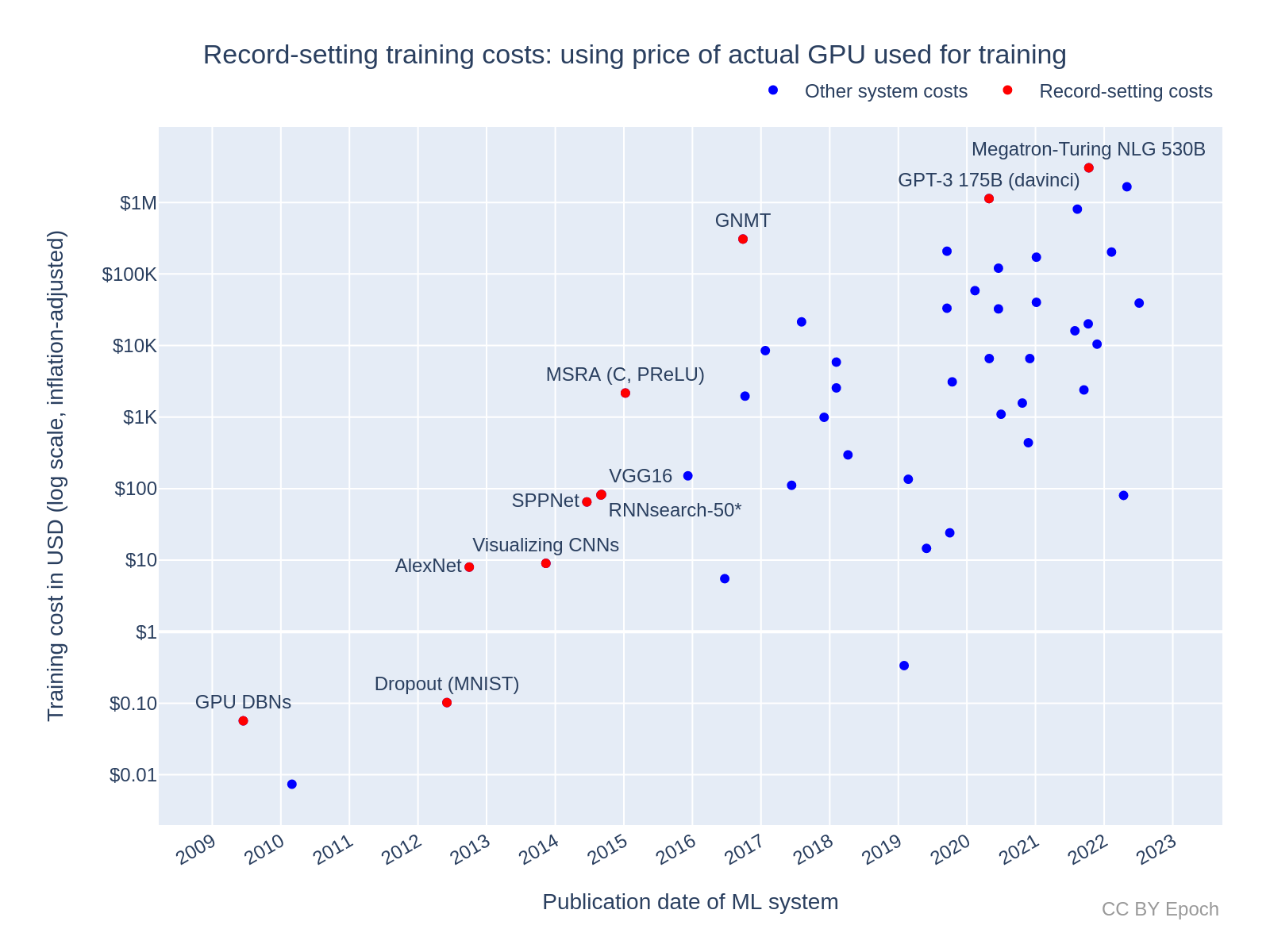
Appendix E: Record-setting costs
Appendix F: Robustness of the regression results to different date ranges
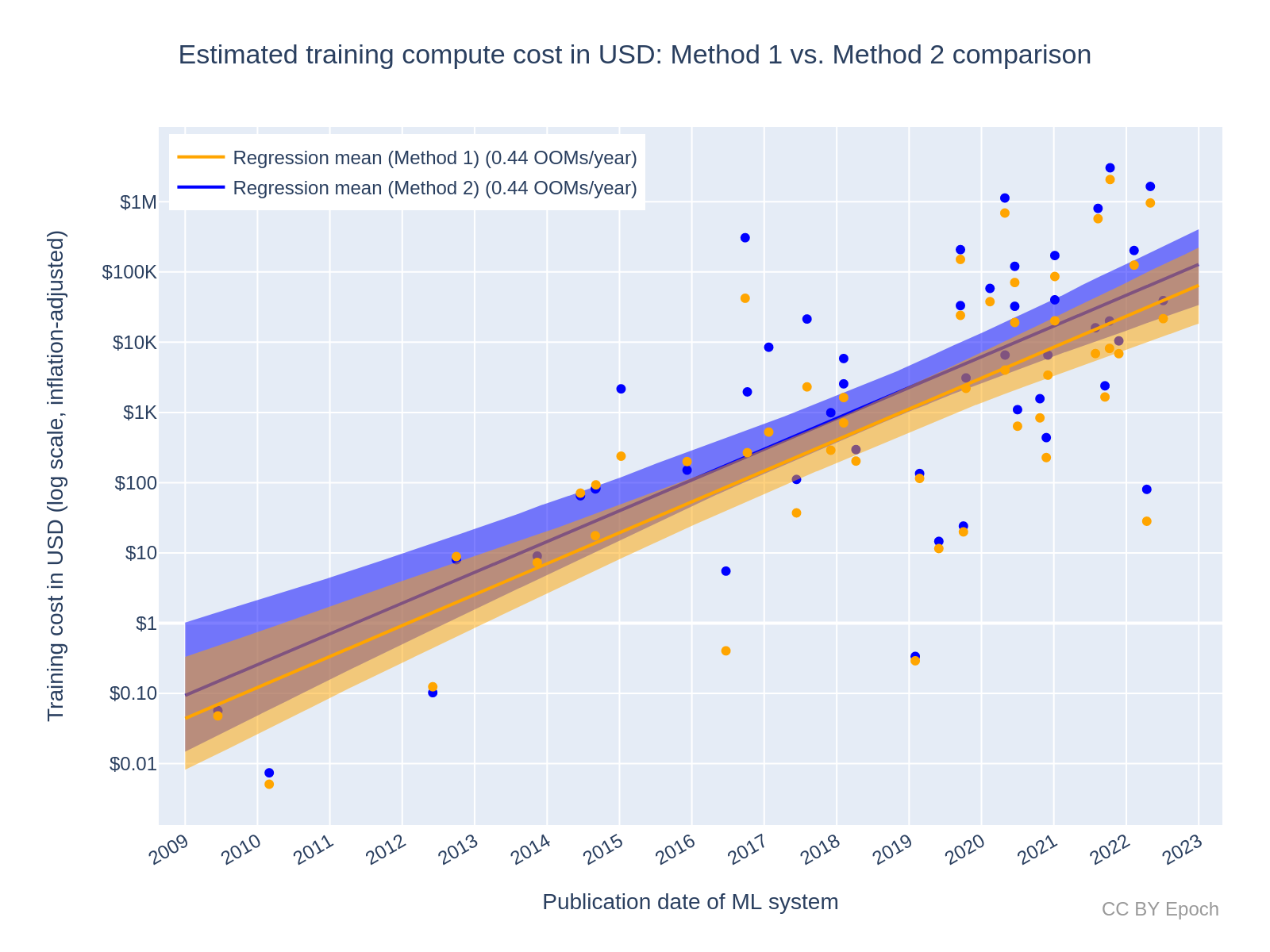
Appendix G: Method 2 growth rate is due to the smaller sample of ML systems, but its estimates are ~2x higher than Method 1 on average
Appendix H: Comparison points for the cost estimates
Appendix I: Overall best guess for the growth rate in training cost
Appendix J: Overall best guess for training cost
-
These are “milestone” systems selected from the database Parameter, Compute and Data Trends in Machine Learning, using the same criteria as described in Sevilla et al. (2022, p.16): “All models in our dataset are mainly chosen from papers that meet a series of necessary criteria (has an explicit learning component, showcases experimental results, and advances the state-of-the-art) and at least one notability criterion (>1000 citations, historical importance, important SotA advance, or deployed in a notable context). For new models (from 2020 onward) it is harder to assess these criteria, so we fall back to a subjective selection. We refer to models meeting our selection criteria as milestone models.”

-
This growth rate is about 0.2 OOM/year lower than the growth of training compute—measured in floating-point operations (FLOP)—for the same set of systems in the same time period. This is based on the 2010 – 2022 compute trend in FLOP for “all models” (n=98) in Sevilla et al. (2022, Table 3), at 0.7 OOMs/year. Roughly, my growth rate results from the growth rate in compute subtracted by the growth rate in GPU price-performance, estimated by Hobbhahn & Besiroglu (2022, Table 1) as 0.12 OOMs/year.
-
These results are not my all-things-considered best estimates of what the growth rate will be from now on; rather, it is based on two estimation methods which combine training compute and GPU price-performance data to estimate costs historically. These methods seem informative but have strong simplifying assumptions. I explain my overall best guesses in point 3 of this summary, but those are based on more subjective reasoning. I base my cost estimates on reported hardware prices, which I believe are more accurate than on-demand cloud compute prices at estimating the true cost for the original developer.# This means my cost estimates are often one order of magnitude lower than other sources such as Heim (2022).
-
This is the mean cost predicted by linear regression from the start to the end of the period.
-
For these large-scale results, I dropped the precision to one significant figure based on an intuitive judgment given the lower sample size and wider confidence interval compared to the “All systems” samples.
-
It turns out that this difference in growth rate to Method 1 is just due to the smaller dataset, even though the cost estimates differ significantly (roughly twice as large as those of Method 1 on average) (see this appendix for further explanation).
-
I included this result for completeness, but given the very small sample size and large confidence interval on the growth rate, I do not recommend using it.
-
The growth rates obtained via Method 1 and Method 2 were aggregated using a weighted mixture of normal distributions implemented in this Guesstimate model. Note that the results given by Guesstimate vary slightly each time the model is accessed due to randomness; the reported value is just one instance.
-
The mixture method aggregates the growth rates rather than fitting a new regression to a dataset, so I did not obtain a mean prediction for this method.
-
See the “Long-run growth” bullet in this section of Cotra (2020) titled “Willingness to spend on computation forecast”.
-
The adjustments are explained further in Appendix I and Appendix J.
-
Sevilla et al. (2022) found that “before 2010 training compute grew in line with Moore’s law, doubling roughly every 20 months. Since the advent of Deep Learning in the early 2010s, the scaling of training compute has accelerated, doubling approximately every 6 months”.
-
Several other significant costs are involved in developing and deploying ML systems, which I do not estimate. These costs include:
- Compute spent on experiments or failed training runs apart from the final training run
- Compute spent on training data collection and pre-processing
- Human labor to do research and implement experiments
- Maintenance of hardware and software infrastructure
- Operational support, including the hiring and management of personnel
- Compute and human labor spent on fine-tuning models for specific deployment applications
- Compute spent on model inference
-
As an extension for future work, one could use a non-linear model where soon after its release date, the hardware price is more expensive than the price closer to the end of the hardware’s life-span. Such a model could be based on empirical data on hardware price over time.
-
This formula neglects energy costs associated with cooling the hardware. Based on the reasoning in this appendix, I think that total energy cost is generally small compared to hardware cost.
-
For example, see Google Cloud GPU pricing: https://perma.cc/M5P3-MZF7
-
Parameter, Compute and Data Trends in Machine Learning. CC-BY Jaime Sevilla, Pablo Villalobos, Juan Felipe Cerón, Matthew Burtell, Lennart Heim, Amogh B. Nanjajjar, Anson Ho, Tamay Besiroglu, Marius Hobbhahn Jean-Stanislas Denain, and Owen Dudney.
-
Since I estimate cost based on compute, my methods are similar to Sevilla et al. (2022). See this appendix for a list of differences in our methods.
-
As one indication of the uncertainty, two different estimation methods were found to differ by up to a factor of 1.7x - see Estimating Training Compute of Deep Learning Models Appendix B.
-
The 1.5x number is based on Morgan (2022): “…it is important to remember that due to shortages, sometimes the prevailing price is higher than when the devices were first announced and orders were coming in. For instance, when the [NVIDIA] Ampere lineup came out, The 40 GB SXM4 version for the A100 had a street price at several OEM vendors of $10,000, but due to heavy demand and product shortages, the price rose to $15,000 pretty quickly. Ditto for the 80 GB version of this card that came out in late 2020, which was selling for around $12,000 at the OEMs, and then quickly spiked to $17,500.” 15,000 / 10,000 = 1.5, and 17,500 / 12,000 ~= 1.5.
-
This and the utilization rate estimate are the same as Ajeya Cotra used in the work “Forecasting TAI with biological anchors.” See Grokking “Forecasting TAI with biological anchors” for a summary, and in particular, this cell titled “Convert from LINPACK FLOP/s to total FLOP in training run” in this Colab notebook analyzing compute price trends.
-
Based on Estimating Training Compute of Deep Learning Models recommending “30% for Large Language Models and 40% for other models.” I used the average of 0.3 and 0.4 given that my dataset includes Large Language Models and other models. The 0.35 value may be too low given that Large Language Models seem to make up a minority of the systems in the dataset.
-
Scaling Laws for Neural Language Models provides evidence of this relationship in the language domain—empirically, the loss of a language model on the validation dataset improves as training compute scales, according to a power law.
-
Compute Trends Across Three Eras of Machine Learning also initially used visual inspection to decide outliers—see p.16: “[W]e first decided by visual inspection which papers to mark as outliers and then chose the [Z-score] thresholds accordingly to automatically select them.”
-
There is a slight discrepancy here which may be due to rounding. Starting with the doubling time of 5.6 months in Sevilla et al. (2022, Table 3), equivalent to log10(2) / (5.6/12) = 0.65 OOMs/year, the growth rate would be 0.65 - 0.12 = 0.53 OOMs/year. That number seems similar enough to the result of 0.51 OOMs/year here to be explained by the differences in which data are included—see this appendix for more information about differences to Sevilla et al. (2022).
-
See the section “Affordability of compute” in this summary. Cotra’s predicted growth in spending after 2025 has a 2-year doubling time, equivalent to 0.15 OOMs/year.
-
For these calculations, I used the trend values with higher precision before rounding: 0.25 OOMs/year (90% CI: 0.16 to 0.34)
-
See this appendix for further explanation
-
The growth rates obtained via Method 1 and Method 2 were aggregated using a weighted mixture of normal distributions, implemented in this Guesstimate model.
-
See this Guesstimate model. The predictions for Method 1 and Method 2 were combined in the same manner as the growth rates.
-
See the “Long-run growth” bullet in this section of Cotra (2020) titled “Willingness to spend on computation forecast”.
-
Source: https://data.worldbank.org/indicator/NY.GDP.MKTP.CD?locations=US
-
I estimated this cost in this section of Appendix H: $3.27M * 10^(2.5 years * 0.5 OOMs/year) ~= $60M.
-
These adjustments are explained in Appendix I and Appendix J.
-
See this Guesstimate model for the calculations. To calculate the 90% CI in the year, I just substituted the lower and upper bound of the growth rate into the model, and then took the upper bound and lower bound of the resulting year estimate (respectively). I resorted to this because I got nonsensical results when I used the original distribution that I calculated for the growth rate (e.g. predictions of 100 years). This means that the 90% CIs in the year may be wider than optimal.
-
Thanks to Lennart Heim for suggesting some of these ideas.
-
One indication of the profit margin is that discounts of 37%–65% (relative to on-demand prices) are offered by Google Cloud for longer rental commitments. See GPU pricing on Google Cloud in 2022.
-
See Table 4 (p.6) of Patterson et al. (2021)
-
See Patterson et al. (2021)—the 11th row of Table 4, and the formula in section 2.5 (p.5), as well as section 2.3 (p.4).
-
CC-BY Jaime Sevilla, Pablo Villalobos, Juan Felipe Cerón, Matthew Burtell, Lennart Heim, Amogh B. Nanjajjar, Anson Ho, Tamay Besiroglu, Marius Hobbhahn and Jean-Stanislas Denain.
-
Milestone systems are defined in Compute Trends Across Three Eras of Machine Learning. On p.16: “All models in our dataset are mainly chosen from papers that meet a series of necessary criteria (has an explicit learning component, showcases experimental results, and advances the state-of-the-art) and at least one notability criterion (>1000 citations, historical importance, important SotA advance, or deployed in a notable context). For new models (from 2020 onward) it is harder to assess these criteria, so we fall back to a subjective selection. We refer to models meeting our selection criteria as milestone models.”
-
Based on the “Deep Learning Trend” beginning in 2010 in Compute Trends Across Three Eras of Machine Learning
-
See this cell of their Colab notebook
-
This is as far as I could tell, from searching the publication for relevant keywords for about two minutes. My keywords were “GPU,” “TPU,” “CPU,” “NVIDIA,” “processor,” “Intel,” and “AMD.” For some publications where I suspected certain hardware might have been used, I searched terms such as “V100” (which refers to NVIDIA Tesla V100). Some publications only mentioned terms like this without mentioning any other keywords. Due to time constraints, for the last 30 systems in the dataset I did not search the publication because it either (a) was from Google (which would likely use TPUs that I didn’t have data on), (b) the system was from the Chinese sphere (so it is less likely to use hardware I have data on), (c) the system was not as notable (e.g., the GPT-Neo language model, which is much less powerful than contemporary language models like GPT-3).
-
Some systems have missing data, so the number of systems could be higher than 25.
-
Data on each hardware unit price often came from multiple sources. NVIDIA does not release suggested retail pricing for data center GPUs, so the price information I have for NVIDIA data center GPUs comes from reports in press releases, news articles, and expert estimates, e.g., Morgan (2022). I applied logical rules to select which data source to use case-by-case, rather than average the values from multiple sources, because the sources usually had similar values. To see how I selected which data source to use, check the formulas in the “Real price (2020 USD) - merged” column in the database.
-
See this cell of the accompanying Colab notebook for the calculation of price-performance.
-
To be precise, when these factors were present, the bounds of the 90% CI for the regression on “all systems” changed by 0.01 at most, but that could have been merely due to random variation in the bootstrap sample rather than the presence of the factors.
-
See p.16 of Sevilla et al. (2022) for how the low-compute outliers were excluded: “Throughout the article, we have excluded low-compute outliers from the dataset. To do so, we compute the log training compute Z-score of each model with respect to other models whose publication date is within 1.5 years. We exclude models whose Z-score is 2 standard deviations below the mean. This criteria results in the exclusion of 5 models out of 123 between 1952 and 2022. The models excluded this way are often from relatively novel domains, such as poker, Hanabi, and hide and seek.”
-
See Figure 5 on p.18 of Sevilla et al. (2022).
-
See this Colab notebook cell for the calculation.
-
Price information is not included with datasheets, e.g., the NVIDIA A100. See also Morgan (2022): “Nvidia does not release suggested retail pricing on its GPU accelerators in the datacenter, which is a bad practice for any IT supplier because it gives neither a floor for products in short supply, and above which demand price premiums are added, or a ceiling for parts from which resellers and system integrators can discount from and still make some kind of margin over what Nvidia is actually charging them for the parts.”
-
This is my understanding from talking to a few experts and reading some machine learning papers about training the largest neural networks to date (e.g., Google’s PaLM system from 2022). Sid Black, who was the leading contributor to developing the GPT-NeoX-20B language model, told me in conversation (paraphrasing) that “Large language model training is bottlenecked by interconnect. If you don’t set up the software stack properly, it’s really slow.” In the paper for PaLM (on p.8), it says “An interesting aspect of two-way pod-level data parallelism is the challenge of achieving high training throughput for cross-pod gradient transfers at the scale of 6144 TPU v4 chips attached to a total of 1536 hosts across two pods.” (This quote is heavy on jargon, but my understanding is that “cross-pod gradient transfers” involve transferring data between hardware units in different “pods,” which are groups of hardware units.)
-
See Figure 5, p.18 of Sevilla et al. (2022). This is not surprising given that Method 1 just divides the training compute by the value of the trendline in GPU price-performance. But hypothetically, if training compute had grown at a slower rate than it actually did, we might have seen later systems set a compute record but not a cost record.
-
The existence of a separate category of “Large Scale” systems is argued in Sevilla et al. (2022, p.22)
-
See this Colab notebook cell for the calculation.
-
Calculation: (7 months / 12 months per year) * 0.44 OOMs/year ~= 0.26 OOMs = 10^0.26 ~= 2.
-
I quote Method 1 estimates for PaLM and AlphaGo Zero because, although I believe Method 2 is more accurate on average, I did not have data for PaLM and AlphaGo Zero to use in Method 2.
-
Footnote 6 of the post states “We double V100’s theoretical 14 TFLOPS of FP32 to get its theoretical 28 TFLOPS of FP16.” This number is very close to the actual number of 25 TFLOPS reported by Patterson et al. (2021, Figure 5) (on behalf of GPT-3’s developer, OpenAI). The theoretical peak performance listed for the V100 (PCIe version) by NVIDIA is 112 TFLOPS, so 28 TFLOPS corresponds to a utilization rate of 25%. In contrast, I assumed a utilization rate of 35% for all systems.
-
I used a price of $9,029.66 (for one NVIDIA V100 GPU, inflation-adjusted), amortized over two years, which results in $9029.66 / (2 years * 365 days/year * 24 hours/day) ~= $0.52 / hour. Footnote 1 in the LambdaLabs post specifies a price of $1.50/hour.
-
See PaLM paper, p.66: “We trained PaLM 540B in Google’s Oklahoma datacenter…”
-
See the table in Footnotes in the post. TPU is $6.50/hour while GPU is $0.31/hour. The table says the GPU is “best,” but I’m not sure if this means it is the highest performance GPU available, or the cheapest GPU available.
-
I find this source relatively untrustworthy because it does not provide a direct source for the information, but I still give it significant credence.
-
This cell note says “Paul estimated 1e17 operations per dollar for pure compute used highly efficiently; I’m assuming 1e16 here to account for staff costs, failed experiments not included in the paper, inefficiency, etc.” But the number in the spreadsheet calculation is actually 1.2e17, so I’m not sure whether this is a typo or the note is not actually relevant anymore. If the assumption of one order-of-magnitude lower is right, then this is another reason my estimate differs: I’m excluding staff costs and failed experiments from my definition of “training compute cost.”
-
The peak price-performance trend in Figure 7 is at about 1e10 FLOP/s per $ in 2017. 1e10 FLOP/s per $ * 35% utilization * (2 * 365 * 24 * 60 * 60 seconds) = 2.2e17 FLOP/$.
-
See the section Willingness to spend on computation forecast in the draft report
-
For this calculation, I’m using the more precise growth rate of 0.24 OOMs/year rather than the rounded final result of 0.2 OOMs/year.
-
I will explain why I find more than 7.5 OOMs (~$32M) unlikely. Most of the compute to produce Minerva was used to train PaLM first—Minerva was trained with an additional 8% of PaLM’s compute in FLOP (see the “Training compute (FLOPs)” column for “Minerva (540B)” in the Parameter, Compute and Data Trends in Machine Learning dataset). This blog post by Lennart Heim estimated PaLM’s training cost using cloud computing (assuming you are not Google) at between $9M and $23M. Increasing that by 8% would raise the cost to about $10M to $25M. But it would cost less for Google because they used their own hardware (the PaLM paper states on p.66 “We trained PaLM 540B in Google’s Oklahoma datacenter”), so they don’t have to pay the profit margin of clouding computing from another vendor. For these reasons, I think it’s more than 90% likely that the actual cost of compute to train Minerva was less than the value of $32M that I use here. Furthermore, I think it’s more than 70% likely that Minerva was actually the most expensive training run in 2022 (including training runs that haven’t been publicized yet—I assume Cotra was also including those). This leads to my stated overall probability bound of 0.9 * 0.7 = 0.63 ~= 60%.
-
In the section Willingness to spend on computation forecast of the draft report, Cotra writes: “I made the assumption that [the growth] would slow to a 2 year doubling time, reaching $100B by 2040.” Cell B7 in Cotra’s “best guess” calculation spreadsheet currently lists a doubling time of 2.5 years, but this may have been a later update. I am assuming that the report is the source of truth for Cotra’s best-guess estimates in 2020, rather than the spreadsheet.
-
In the section Willingness to spend on computation forecast of the draft report, Cotra writes “Beyond ~$1B training runs, I expect that raising money and justifying further spending would become noticeably more difficult for even very well-resourced labs, meaning that growth would slow after 2025.”
-
Note that this is not exactly a novel result. Compute Trends Across Three Eras of Machine Learning already noted this slowed growth in the training compute (in FLOP) of large-scale systems. The dollar cost of that training compute has similar characteristics because the trend in FLOP/$ is relatively reliable.
-
This growth rate was sourced from OpenAI’s “AI and Compute”. I confirmed with the authors via email that this is the growth rate that was used for the cost estimates and projections.
-
See Figure 2 (p.13) of their report.
-
This subtraction of the growth rates corresponds to FLOP being divided by FLOP/$ in log-space to get the cost in $.
-
I used the more precise estimate of 0.24 OOMs/year in this calculation, even though I don’t trust the value to that level of precision: 5 OOMs / 0.24 OOMs/year = 21 years.
-
On p.10: “By the end of 2021, the trendline predicted several more doublings, for an anticipated model of just over one million petaFLOPS-days. Training such a model at Google Cloud’s current prices would cost over $450 million.” It is evident that they use this cost as the start of the projection in Figure 2 of their paper (on p.13), since the line starts roughly halfway between 10^8 and 10^9.
-
The authors explained to me via email that this estimate was intended moreso to make the point that recent historical growth in compute is unsustainable (because that conclusion isn’t particularly sensitive to the choice of initial cost), rather than to be an accurate estimate of the highest cost in 2021.
-
The mixture model was a weighted mixture of normal distributions, implemented in this Guesstimate model.
-
See the section Willingness to spend on computation forecast in the draft report
-
The answer returned by the Google search for “united states gross domestic product” is 23.32 trillion USD for 2021.
-
On p.12–13: “Figure 2 shows that if we assume that compute per dollar is likely to double roughly every four years (solid line), or even every two years (lower bound of shaded region), the compute trendline [quickly] becomes unsustainable before the end of the decade.” Figure 2 shows extrapolated training compute costs equalling US GDP by about 2027.
-
I’m uncertain how to measure “major impact on the economy,” but for illustration, automating 1% of all current human-occupied goods-and-services jobs plausibly seems like enough to increase the growth rate in spending on training runs.
-
The 2x factor is based on the following reasoning. In this section I said “A 55% discount on the estimate for PaLM [that] is most similar to my method ($23.1M) is $10.4M, which is much closer to my [Method 1] estimate of $3.2M but still far apart.” If I defer somewhat to the reasoning behind the external PaLM estimate, I think the value after a 55% discount is applied is the most accurate value that I have readily available. However, I also believe the Method 1 estimate is 2x too low as mentioned previously. So as a very rough calculation, the ratio compared to Method 2 would be 10.4M / (2 * 3.2M) = 1.625. I round this up to 2 given the imprecision of my calculations.
-
The 90% CI was obtained by multiplying the bound of the 90% CI derived in this section by 2. Note that this interval is reflective of the variation in how much any given ML system in my dataset cost, rather than my uncertainty in the average cost of all the ML systems.
-
See the appendix on NVIDIA GPU price-performance for my reasoning
-
See this cell of the data spreadsheet.
-
The article says: “…when the Ampere lineup came out, The 40 GB SXM4 version for the A100 had a street price at several OEM vendors of $10,000, but due to heavy demand and product shortages, the price rose to $15,000 pretty quickly.” I’m assuming that the V100 price increased in 2020 for a similar reason.
-
As of August 26, 2022, Google Cloud offers a 55% discount on the on-demand TPU V4 price for a three-year rental commitment. Presumably, Google Cloud still makes a profit even when the 55% discount is applied. So I increased from 55% to 67%, mostly because I don’t think the profit margin would be drastically larger, but partly to use a convenient number (roughly two thirds).
-
The formula is cost = compute / ((peak_hardware_throughput / hardware_price) * hardware_replacement_time * hardware_utilization_rate)
-
The code is in this cell of the Colab notebook.
-
The exception was the hardware utilization rate, which was sampled from a normal distribution.
About the authors
Related work