Introduction
What will happen if AI scaling persists to 2030? We are releasing a report that examines what this scale-up would involve in terms of compute, investment, data, hardware, and energy. We further examine the future AI capabilities this scaling will enable, particularly in scientific R&D, which is a focus for leading AI developers. We argue that AI scaling is likely to continue through 2030, despite requiring unprecedented infrastructure, and will deliver transformative capabilities across science and beyond.
Scaling is likely to continue until 2030: On current trends, frontier AI models in 2030 will require investments of hundreds of billions of dollars, and gigawatts of electrical power. Although these are daunting challenges, they are surmountable. Such investments will be justified if AI can generate corresponding economic returns by increasing productivity. If AI lab revenues keep growing at their current rate, they would generate returns that justify hundred-billion-dollar investments in scaling.
Scaling will lead to valuable AI capabilities: By 2030, AI will be able to implement complex scientific software from natural language, assist mathematicians formalising proof sketches, and answer open-ended questions about biology protocols. All of these examples are taken from existing AI benchmarks showing progress, where simple extrapolation suggests they will be solved by 2030. We expect AI capabilities will be transformative across several scientific fields, although it may take longer than 2030 to see them deployed to full effect.
We discuss some of the report’s findings below.
Scaling is likely to continue to 2030
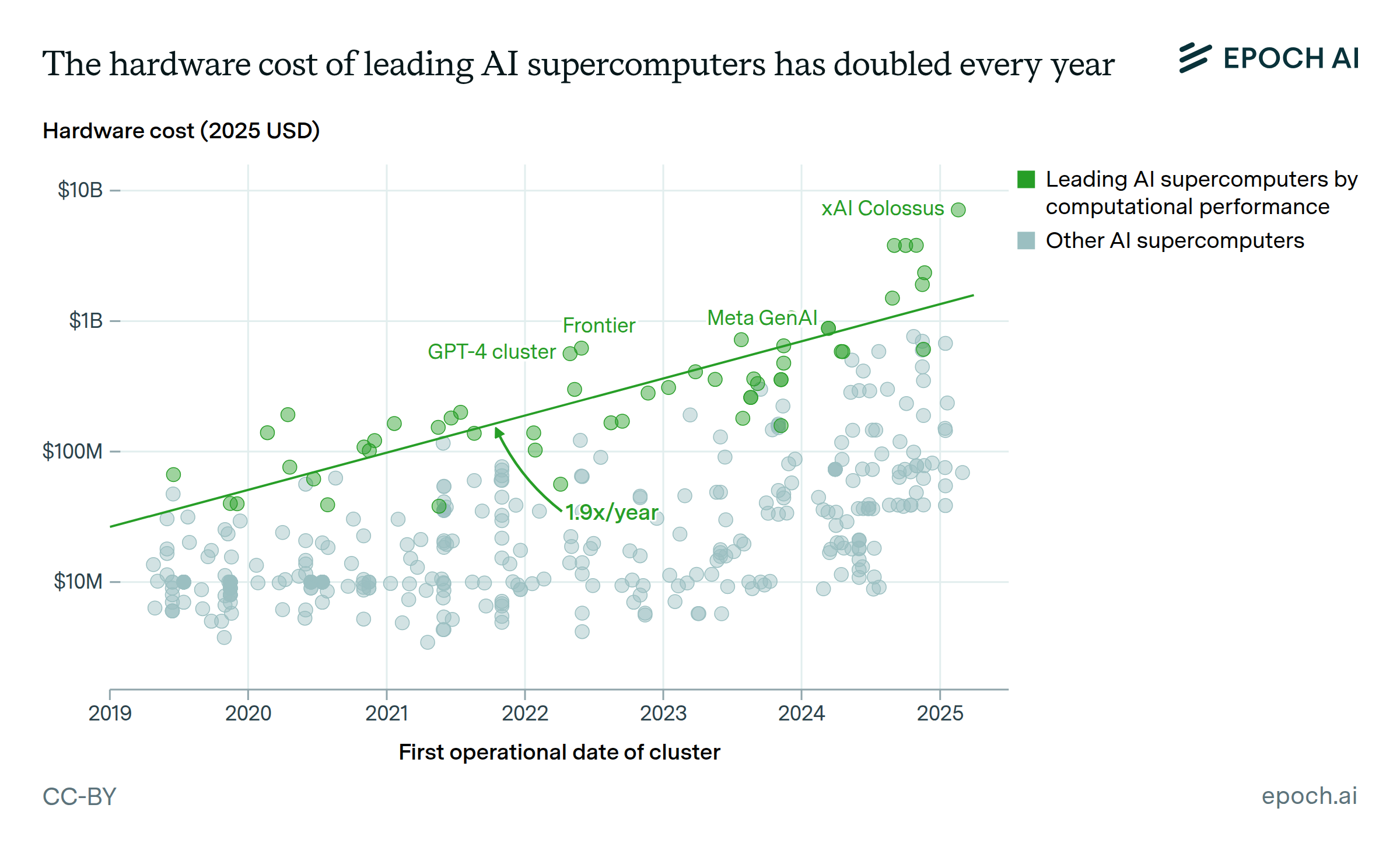
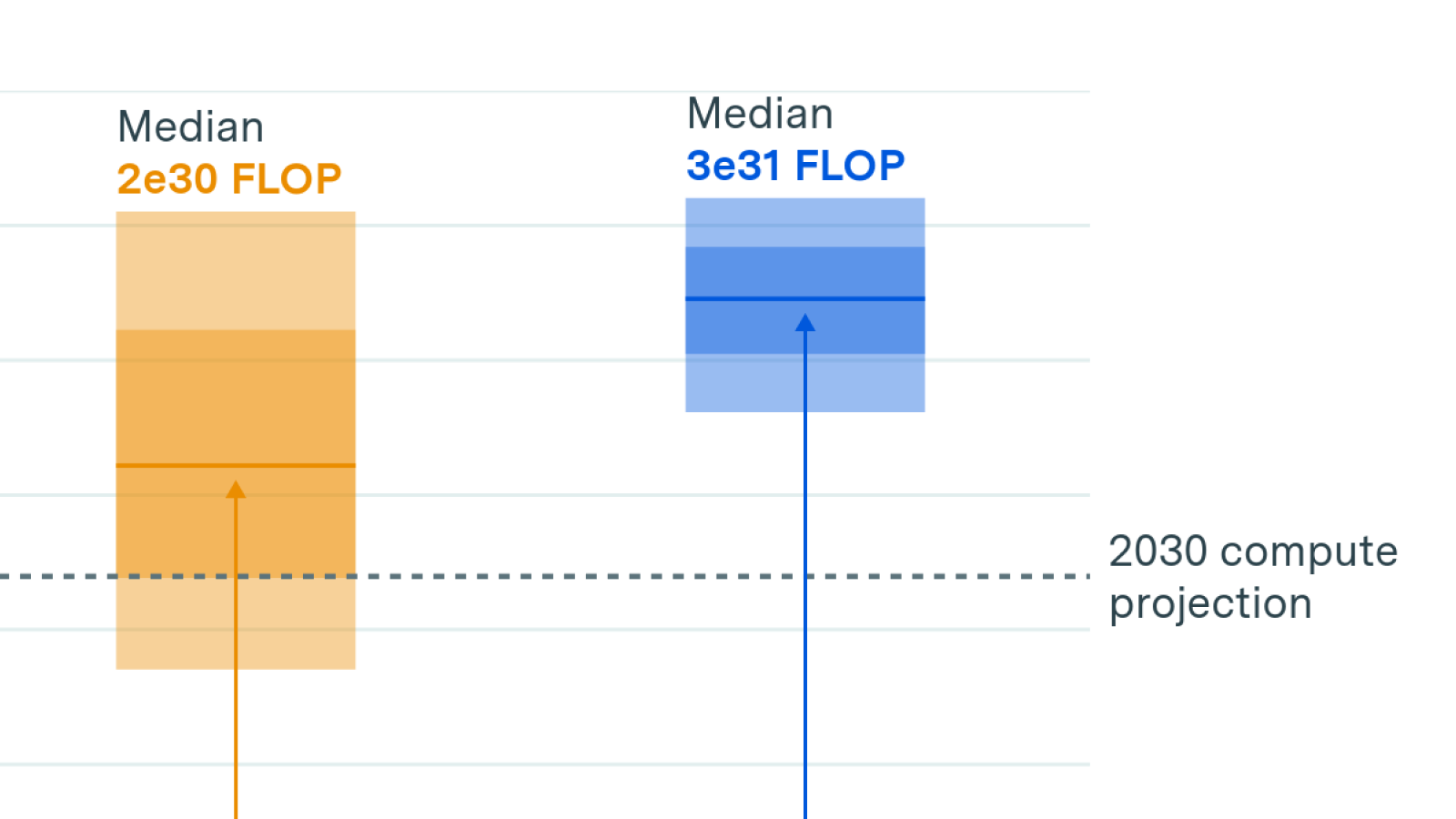
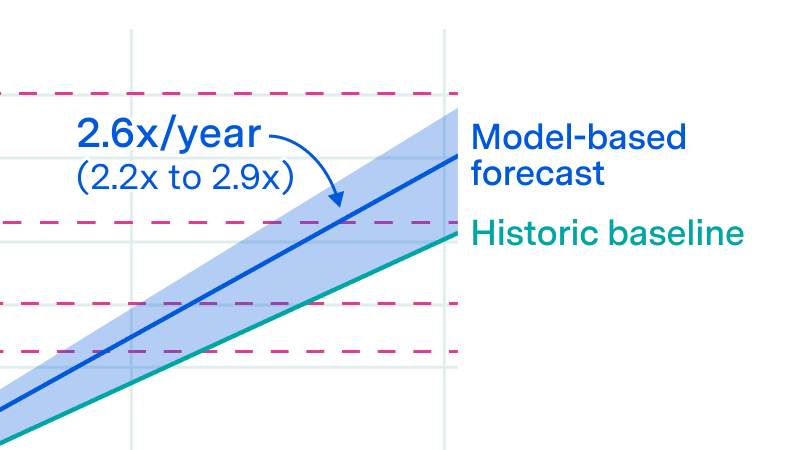
On current trends, the clusters used for training frontier AI would cost over $100B by 2030. Such clusters could support training runs of about 10^29 FLOP – a quantity of compute that would have required running the largest AI cluster of 2020 continuously for over 3,000 years. AI models trained on such clusters would use thousands of times more compute than GPT-4, and require gigawatts of electrical power.
This exemplifies a repeating pattern in our findings: if today’s trends continue, they will lead to extreme outcomes. Should we believe they will continue? Over the past decade, extrapolation has been a strong baseline, and when we investigate arguments for a forthcoming slowdown, they are often not compelling.
Below we recap some of these arguments, and our conclusions from the report:
-
Scaling could “hit a wall”, i.e. AI systems might fail to improve with further scaling. But recent AI models have seen large improvements on benchmarks and revenue. This could happen, but there isn’t obvious evidence of it yet.
-
Data stocks for training might be used up. But there is enough public human-generated text to scale to at least 2027, and synthetic data can be generated in large quantities, and its usefulness is better-established after the invention of reasoning models. It is difficult to fully rule out a data bottleneck, but it seems surmountable.
-
Scaling could be bottlenecked by electrical power. If scaling continues, frontier training runs will require gigawatts by 2030. This would be difficult to supply, but there are ways to rapidly scale up power delivery, such as solar and batteries, or off-grid gas generation. Moreover, frontier AI training runs are already beginning to be geographically distributed across multiple datacentres, which would temper the challenges. Electrical power is unlikely to be a bottleneck before 2028, and seems solvable even after that.
-
Scaling could become too expensive and AI developers stop investing. This is certainly possible, but so far there is little sign of it. If AI developers’ revenues continue to grow on recent trends, they would match the $100B+ investments we extrapolate for frontier training in 2030. AI revenues growing to hundreds of billions may seem extreme, but if AI could improve productivity in a significant fraction of work tasks, it could be worth trillions of dollars.
-
AI development could shift to focus on more efficient algorithms. But algorithmic efficiency has already been improving within the existing compute growth. There is no particular reason to expect algorithmic progress will accelerate, and even if it did, this seems likely to encourage using more compute.
-
AI companies could reallocate compute to inference, e.g. for running reasoning models and other products. But currently training and inference receive comparable compute, and there are reasons to expect training and inference should scale up together. Scaling training creates better AI models, which will be able to do more valuable inference tasks, more affordably. There might be a shift to inference, but it seems unlikely that inference scale-up would slow training scaling.
In light of the above, we believe that extrapolating present trends to 2030 is a strong baseline prediction. And if they do continue, that allows us to extrapolate AI capabilities, which we discuss below.
AI will accelerate scientific R&D across several domains
In the report, we also examine concrete examples of how AI could improve productivity. We focus on scientific R&D, which is a declared focus of several leading AI developers.1 Capabilities trends suggest there will be tremendous progress in AI for scientific R&D, particularly in areas such as software engineering and mathematics, where realistic tasks can be trained on entirely in silico. By 2030, existing benchmark progress suggests AI will be able to implement complex scientific software from natural language, assist mathematicians formalising proof sketches, and answer complex questions about biology protocols.
By 2030, we predict that many scientific domains will have AI assistants comparable to coding assistants for software engineers today. There will be differences compared to software engineering, for example more of a focus on reviewing and synthesising large and heterogeneous literature, whereas existing AI coding tools are primarily limited to the context of a single project. Nevertheless, there are important similarities: offering suggestions in response to context, finding relevant information, completing smaller closed-ended tasks in their entirety.
We predict this would eventually lead to a 10-20% productivity improvement within tasks, based on the example of software engineering.2 Even if the work tasks of a mathematician or a theoretical biologist are less amenable to automation than a software engineer, we already have evidence from relevant benchmarks improving, and anticipate many more years of progress still to come. We expect AI capabilities will be transformative across several scientific fields, although it may take longer than 2030 to see them deployed to full effect.
We present four examples from the report below: software engineering, mathematics, molecular biology, and weather prediction. Although the selected benchmarks can’t capture the full scope of challenges in each domain, they offer insight into AI’s increasing capabilities, and the tasks that may soon be automatable. Scores are collected from leaderboards and model cards, limiting fits to top-performing models.
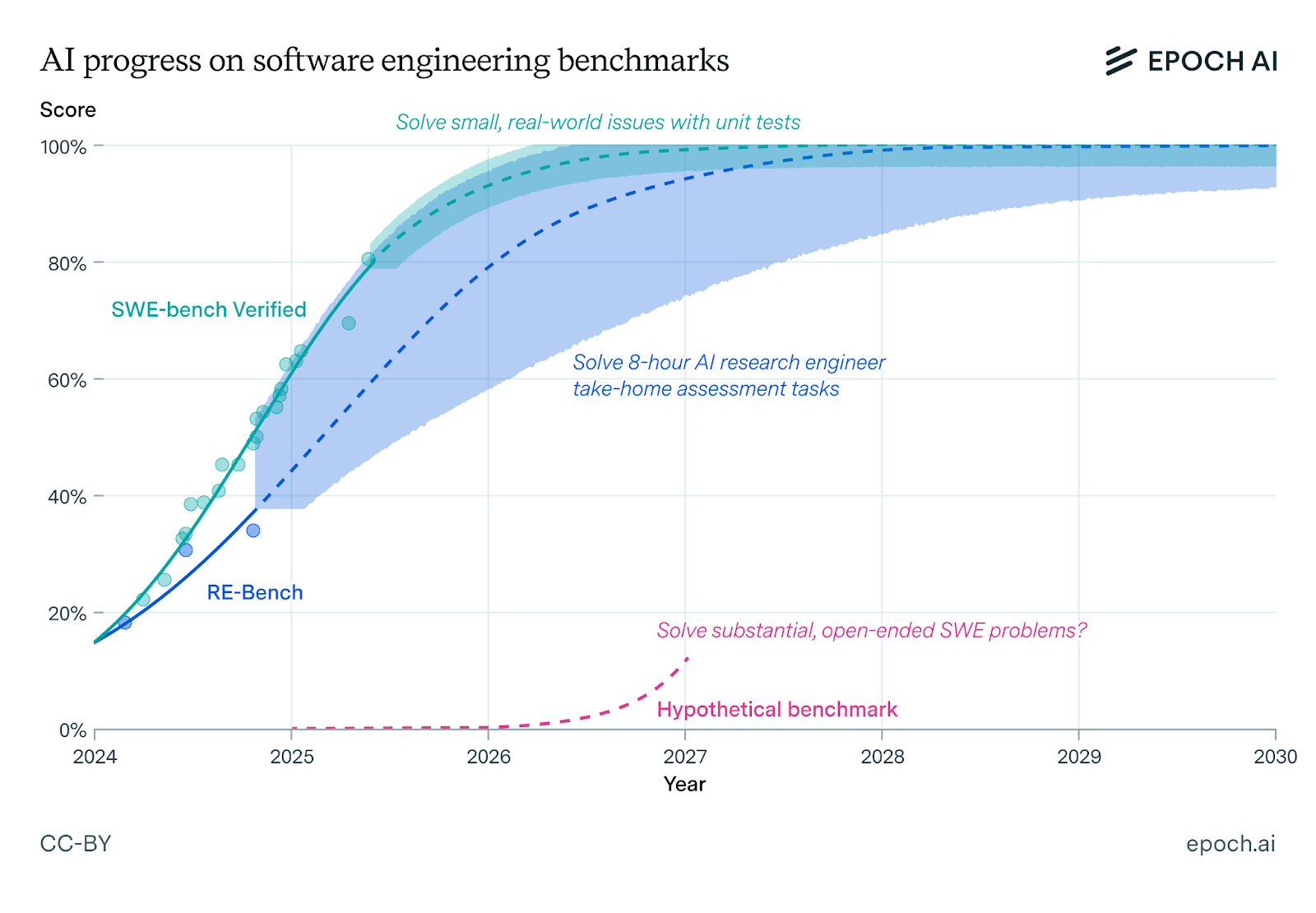
SWE-Bench-Verified: a coding benchmark based on solving real-world GitHub issues with associated unit tests. Results include those reported from model cards, including those with private methodology such as Claude Sonnet 4.
RE-Bench: a research engineering benchmark based on tasks similar to take-home assessments for job candidates, taking approximately eight hours for humans.
Software engineering: AI is already transforming software engineering through code assistants and question-answering. By 2030, on current trends, AI will be able to autonomously fix issues, implement features, and solve difficult (but well-defined) scientific programming problems.
Results show general-purpose LLMs only, excluding domain-specific systems like AlphaProof and AlphaGeometry2.
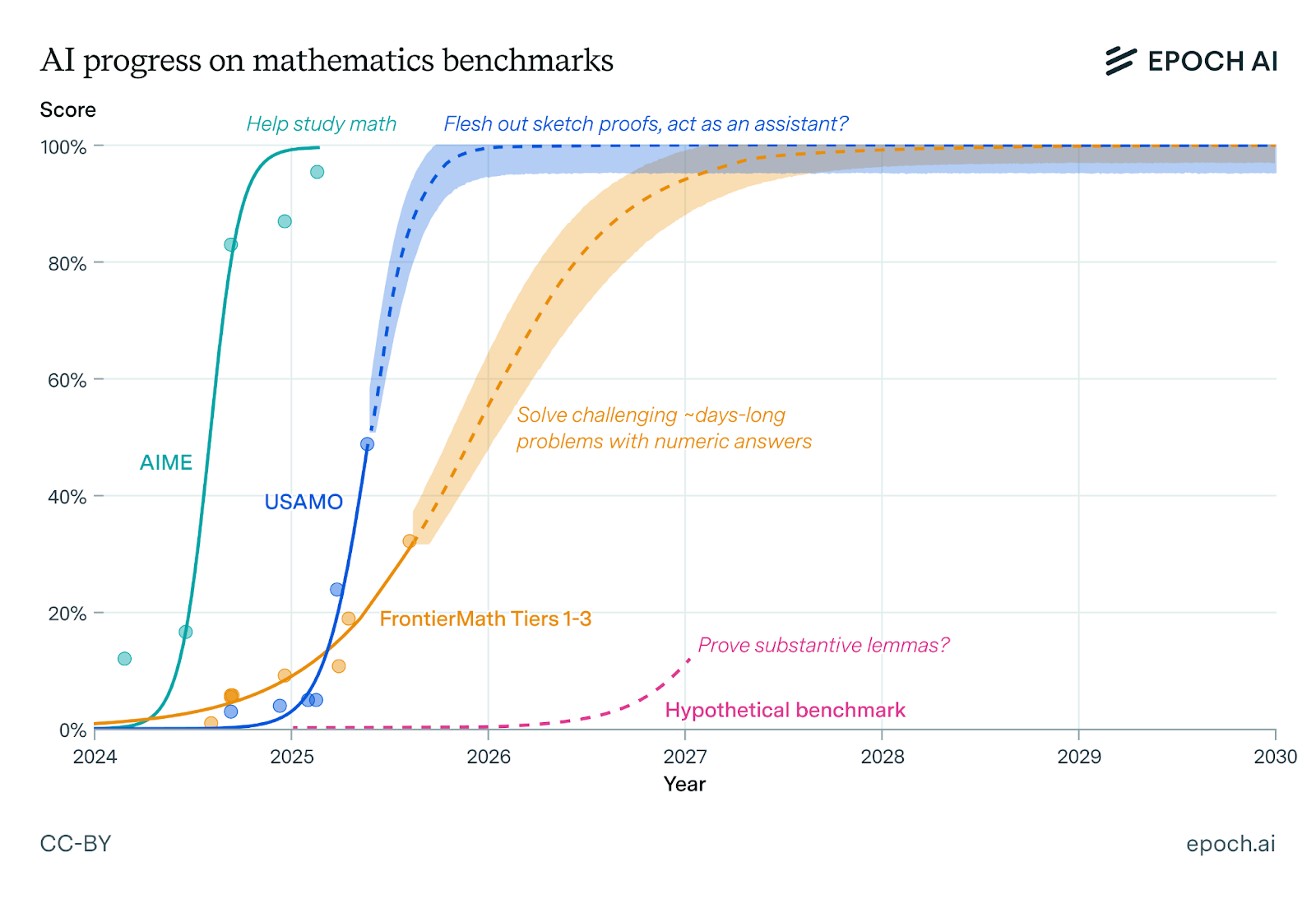
AIME: a high school mathematics exam used for determining entry to the US Mathematical Olympiad, integer answers.
USAMO: US Mathematical Olympiad, a high school mathematics exam with proof-based answers.
FrontierMath: a mathematics benchmark focused on challenging questions up to expert level, but still offering straightforwardly-verifiable answers (numeric or simple expressions).
Mathematics: AI may soon act as a research assistant, fleshing out proof sketches or intuitions. Early accounts already document AI being helpful in mathematicians’ work. Notable mathematicians differ greatly in how relevant they think existing mathematical AI benchmarks are for their work, as well as in their predictions for how soon AI will be able to develop mathematical results autonomously, rather than as an assistant.
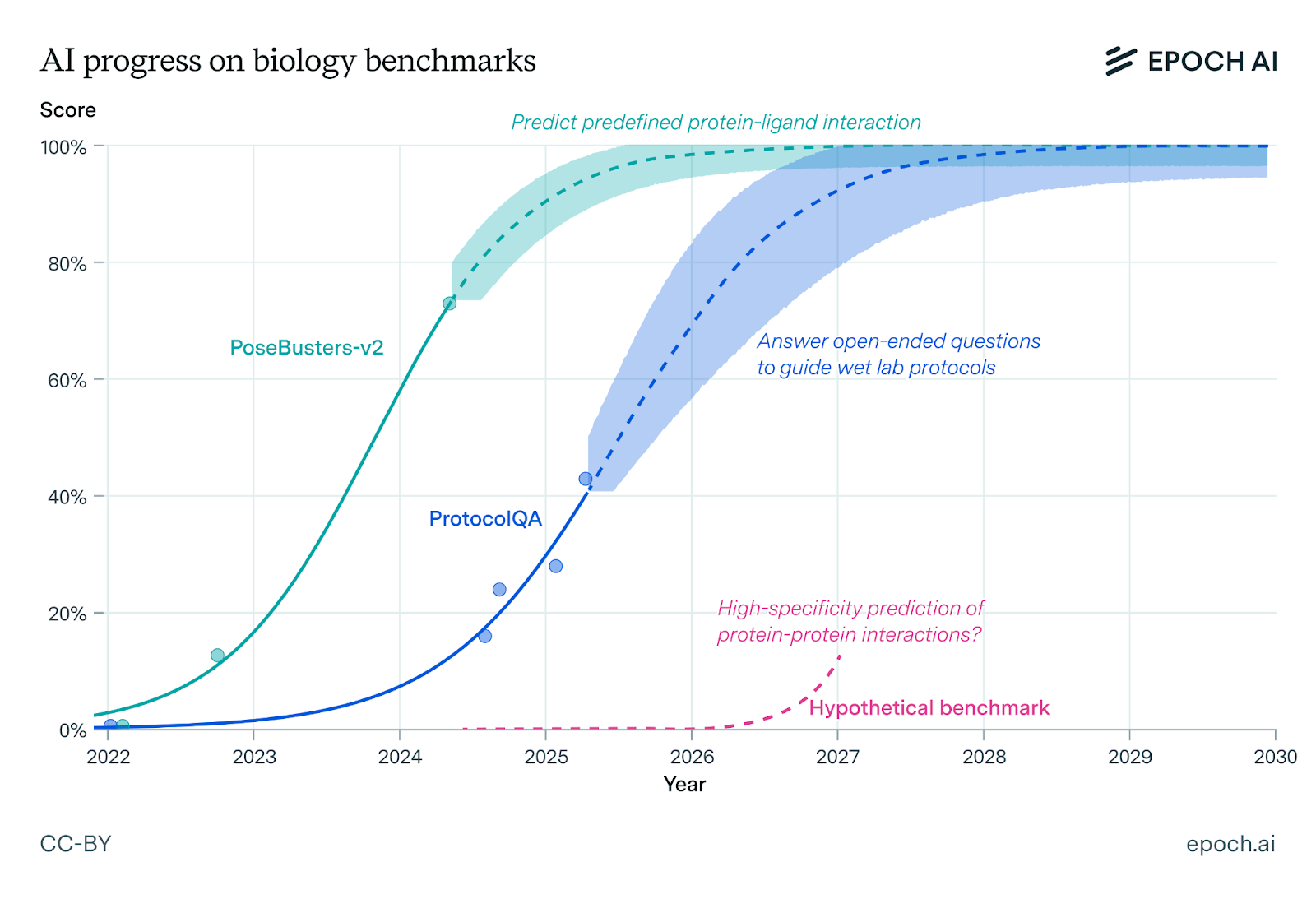
PoseBusters-v2: a benchmark for protein-ligand docking (spatial interaction). We only include blind results, where the protein’s binding pocket is not provided.
ProtocolQA: a benchmark for questions about biology wet lab protocols, here evaluated without multiple choice answers.
Protein-protein interactions: there is significant progress predicting protein-protein interactions, but predictions for arbitrary pairs have a high false positive rate. Our illustration of progress is highly uncertain, and would depend on benchmark details.
Molecular biology: Public benchmarks for protein-ligand interaction, such as PoseBusters, are on track to be solved in the next few years, although the timeline is longer (and uncertain) for prediction of arbitrary protein-protein interactions. Meanwhile, AI desk research assistants for biology R&D are coming. Existing biology protocol question-answering benchmarks should be solved by 2030. While these benchmarks don’t represent the full scope of challenges in molecular biology, their trends offer a specific window into AI’s growing capabilities in the field.
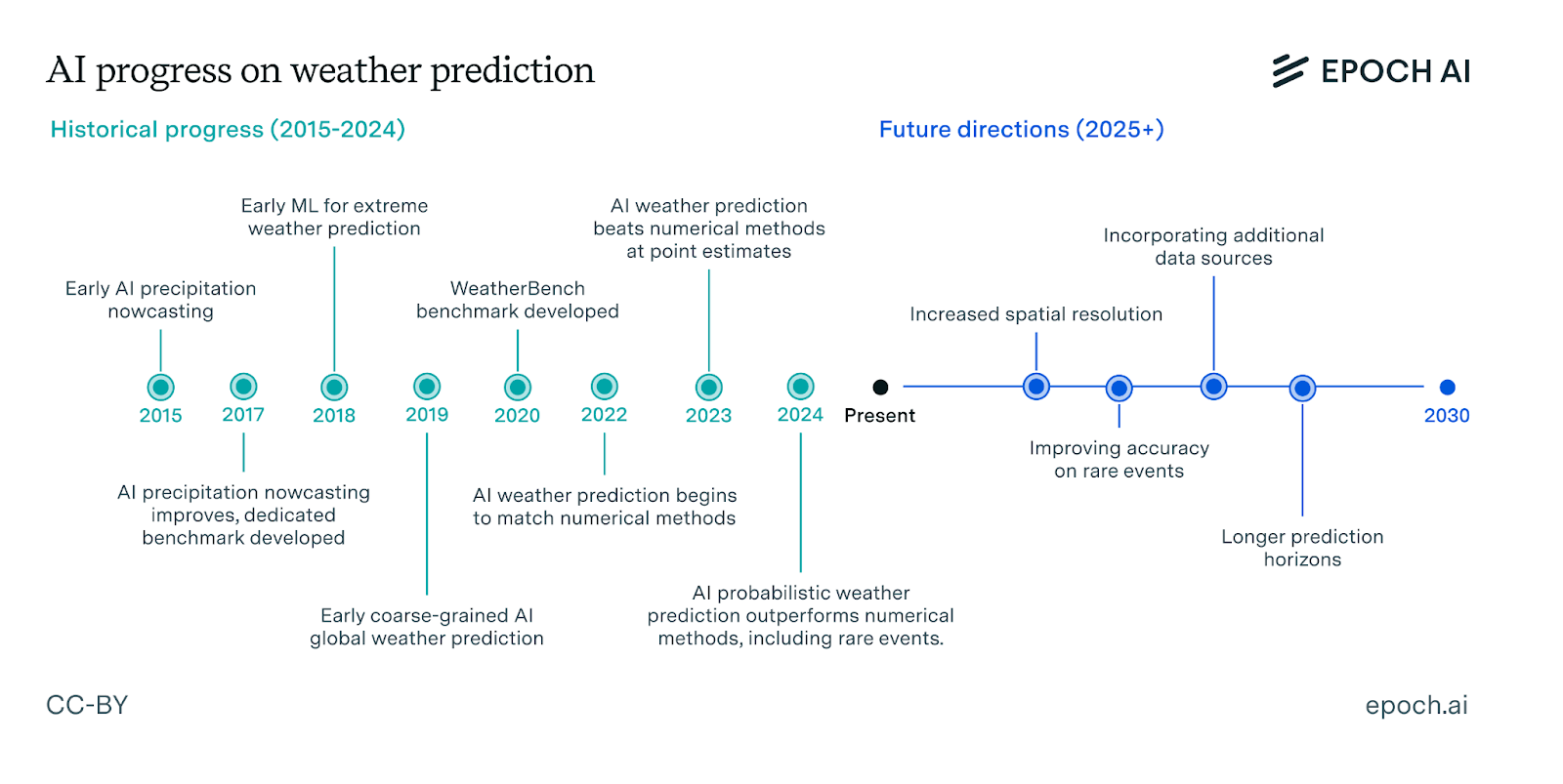
Weather prediction: AI weather prediction can already improve on traditional methods from hours up to weeks. Moreover, AI methods are cost-effective to run, and could improve further with more data. The next challenges lie in improving existing predictions, especially rare events, and making use of improved predictions to achieve benefits in the wider world.
A recurring theme in the work is that deployment and societal impact may significantly lag capabilities. For example, compared to pharmaceutical R&D, software engineering has shorter iteration cycles, does not require wet lab experiments or clinical trials, rarely involves safety-critical systems, is often easy to check for approximate correctness, and has abundant training data. For these reasons, we expect that few if any of the drugs approved for sale by 2030 will have benefited from today’s AI tools, let alone those of 2030. However, early-stage development is likely to be seeing significant effects from AI by then. In comparison, we expect software engineering will have changed dramatically, and we expect there will be a flourishing of software for scientific R&D and more broadly.3
Conclusion
By 2030, AI is likely to become a key technology across the economy, present in every facet of people’s interaction with computers and mobile devices. If these predictions come to pass, then it is vitally important that key decisionmakers prioritise AI issues as they navigate the next five years and beyond.
To learn more, read the full report here.
-
Of course, there is much more to the economy than scientific R&D. Much of AI’s economic impact could come from broad automation of many tasks across the economy. However, scientific R&D tasks are more prone to have benchmarks, tend to be high value, tend to have rapid technology adoption, and see a lot of dedicated research. And, as mentioned, scientific R&D is an explicit focus of leading AI labs. We hence expect R&D tasks will be a useful testbed for examining AI capabilities.

-
This prediction comes with significant uncertainty, even within software engineering itself. In a recent study of AI’s effects on software engineering, literature review identified seven empirical studies. 6/7 found 20-70% speed-ups or increases in output. The remaining study found a surprising 20% slowdown, although it has a claim to the most thorough methodology. We take 20% productivity improvement as the starting point for the effect of current AI tools, but we caveat that there is considerable uncertainty in current evidence.
-
For software and biology, and in general, substantial technological change makes our predictions increasingly uncertain. For example, entirely new biomedical processes might be facilitated by AI design and organisation, conceptually similar to processes such as mRNA vaccines, which can be safely renewed year-to-year without having to undergo approval from scratch.
About the authors
Related work