In recent weeks, there has been widespread speculation about the economic implications of algorithmic progress—improvements to machine learning methods that allow us to develop and deploy models using fewer resources. Many have suggested that algorithmic progress, as observed in DeepSeek’s training of V3 and R1, will reduce demand for high-performance GPUs going forward. Their argument is that it enables AI labs to “do more with less”, and build AI products without needing as much compute.
Here, I argue the opposite: rather than decreasing overall spending, algorithmic progress is likely to increase AI compute spending, both in inflation-adjusted terms and in terms of the share of GDP spent on compute. This is particularly true for forms of algorithmic progress that allow AI labs to improve frontier performance at the same time they can increase computational efficiency, which is largely true for DeepSeek’s recent innovations.
I approach this argument from an empirical perspective. Most directly, data from machine learning trends indicates that algorithmic progress has coincided with a rapidly increasing rate of investment in computers used for training and deploying machine learning models, flatly contradicting the notion that algorithmic progress will always lead to a decreased investment in compute. Nonetheless, it is possible that AI may follow a familiar pattern observed with previous technologies like smartphones and personal computers, where an initial surge in demand for computing hardware eventually plateaus as the technology matures and reaches widespread adoption.
Ultimately, this debate hinges on whether the current AI paradigm is approaching limits in its ability to generate economic value. If you believe that deep learning is hitting a wall, then it makes sense to expect that algorithmic progress will reduce the economic importance of compute. In this scenario, greater efficiency would simply mean that AI labs can achieve similar results with less computational investment, leading to lower overall spending on compute.
However, if you expect, as I do, that continued scaling of compute and further algorithmic progress will unlock entirely new economic opportunities—such as AI agents capable of automating most remote work—then the opposite conclusion follows. In this case, algorithmic progress would not reduce the demand for compute but instead drive higher spending, as investors and AI labs race to exploit these opportunities.
Introduction
Recently, DeepSeek has received widespread praise for the efficiency of its training methods, particularly with its V3 model. Despite being trained on only about one-tenth of the total compute used for comparable models, it has achieved performance levels on par with—or exceeding—those of Llama 3 405B.
While this achievement is certainly impressive, its improvement over prior approaches should not be viewed as highly unusual. Rather, it serves as just one example of algorithmic progress: the long-running, well-documented trend of machine learning models requiring fewer resources during training to reach the same level of performance as earlier models.
Epoch AI and other organizations have documented a remarkable rate of algorithmic progress over the past decade. While there is great uncertainty, the best existing estimates suggest that the amount of compute needed to achieve a given level of pre-training performance for LLMs has been shrinking on average by a factor of approximately 3 each year—significantly faster than Moore’s law. If we were to include improvements to post-training enhancements, the rate would be even more rapid.
While the notion of algorithmic progress is not new, the sudden popularity of DeepSeek’s R1 model—which was built on top of V3—brought the topic to wider attention. Various commentators have claimed that DeepSeek’s development will have significant consequences for the current paradigm of aggressively scaling compute infrastructure to train larger models. Specifically, they predict that with greater computational efficiency, AI firms will choose to spend less on AI compute than they otherwise would.
In response, others, like Satya Nadella, have pushed back on this idea by invoking the Jevons paradox. This concept describes a historical pattern sometimes observed in energy and other resource markets: when technological advancements make resource use more efficient, the resulting drop in resource costs triggers a “rebound effect,” where demand for the resource increases. The net result is to increase resource consumption, rather than to decrease it. Applying this logic to AI, proponents of the analogy argue that if AI training becomes more computationally efficient, companies may actually increase their total compute expenditures rather than reduce them.
However, invoking this paradox can be misleading for two key reasons. First, the application of Jevons paradox to modern energy markets is widely disputed by economists. Most empirical studies suggest that, in today’s world, the rebound effect is typically not strong enough to cause total energy consumption to increase as efficiency improves. Instead, efficiency gains tend to result in a net decrease in energy use.
Second, and more importantly, there aren’t strong reasons to believe that what’s true about energy or other resource markets will apply straightforwardly to the AI market. In general, there’s no economic law stating that greater efficiency in obtaining or using a resource must lead to increased consumption of that resource. In reality, the strength of the rebound effect varies widely depending on the specific market. For example, in water markets, increased efficiency has often led to greater overall consumption, while improvements in vehicle fuel economy tend to simply reduce costs without driving up total usage.
As a matter of general economics, the most relevant concept for understanding this phenomenon is the elasticity of substitution. The key question is whether AI serves as a gross substitute or a gross complement for other goods in the economy. If AI is a gross substitute, then when the cost of AI training decreases, companies will redirect more of their spending toward AI, increasing the fraction of GDP spent on AI compute. If, on the other hand, AI is a gross complement, then a drop in AI costs would lead companies to spend less on AI overall.
Since algorithmic progress can be interpreted as a decrease in the price of AI—either in terms of the cost of training AI or in serving AI at inference—what fundamentally determines whether algorithmic progress will lead to higher or lower spending on AI compute is the elasticity of substitution between AI and other goods in the economy. If the elasticity of substitution is greater than one—or equivalently, AI is a gross substitute for other economic goods—then greater efficiency will lead to increased overall spending on AI as a share of GDP, rather than a decrease.
Since this is ultimately an empirical question, it should be settled through data rather than relying on an analogy to energy consumption. This is precisely what I examine in the following section.
The empirical data
Algorithmic progress is one way that software—like AI—can get cheaper. However, historically, the clearest way that software has gotten cheaper is through hardware progress, which has lowered the cost of performing computations. Economist William Nordhaus documented that between 1945 and 2006, the inflation-adjusted cost of compute dropped by a staggering factor of more than one trillion.
At the same time that computing became dramatically more affordable, the share of GDP spent on computers increased. In 1959, computers accounted for a negligible portion of the economy, but by 2000, spending on computing infrastructure had grown to approximately 1% of GDP.
However, this trend did not continue indefinitely. As shown in the chart below, after the dot-com crash in 2000, investment in computing infrastructure declined. Over the past 25 years, the computing industry has shrunk relative to the rest of the economy, experiencing only modest growth in absolute terms compared to its earlier trajectory of rapid expansion.
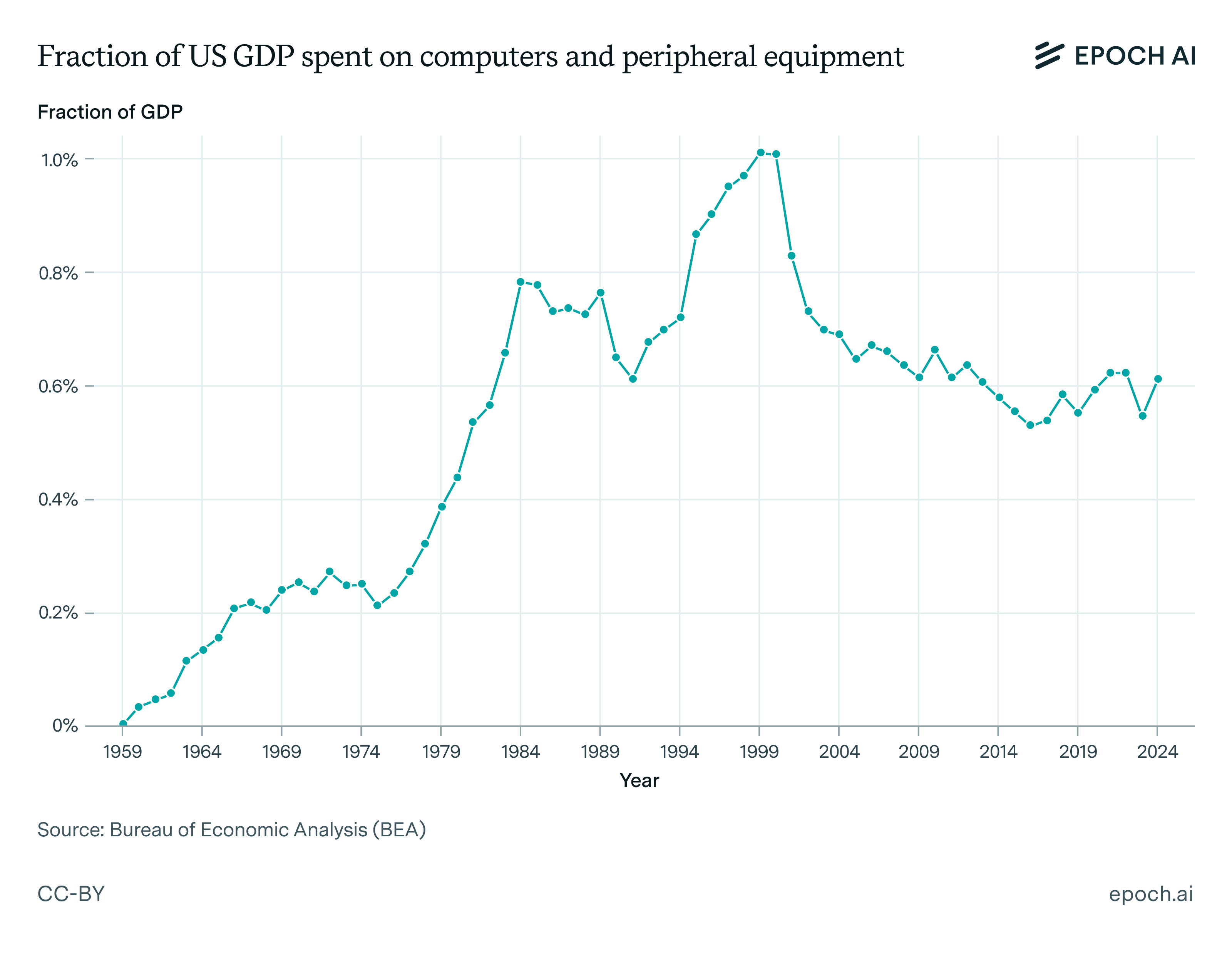
This historical pattern suggests that general computing was a gross substitute for other forms of economic activity in the early decades of its adoption but has since become a gross complement in today’s economy. One possible explanation for this shift is that consumer markets for computing products became relatively saturated over time.
To illustrate, consider cell phones. Before cell phones existed, there was a major opportunity for increased spending on computing equipment as consumers adopted the technology. As smartphones advanced the technology by incorporating new features, this growth continued. However, at a certain point, widespread adoption and technological limitations led to market saturation, slowing the growth of consumer spending on cell phones. In other words, cell phones provide diminishing returns in terms of utility—owning a second one offers little added benefit because an individual can only actively use one at a time.
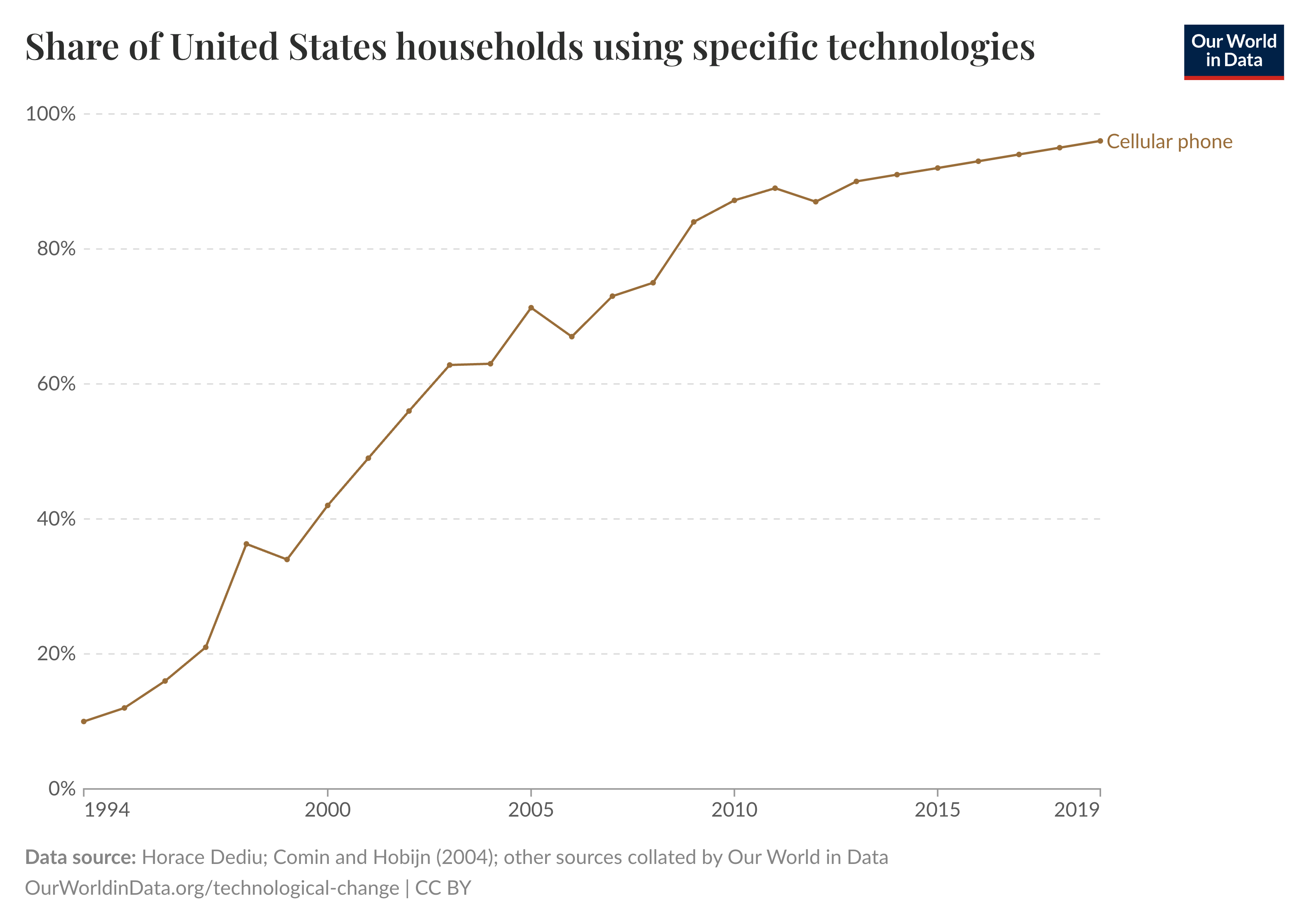
It is plausible that most conventional computing platforms follow a similar pattern, where initial adoption drives rapid spending growth, but eventually, demand stabilizes as the market becomes saturated. This pattern could still drive substantial growth in the computing industry over long periods of time as new products and new types of software are introduced, opening new niches for them to exploit. However, unless these new niches are introduced very rapidly, or they have unusual economic significance, then computing should not grow to be a large part of the economy.
Now consider the case of AI. Historical data demonstrates that during the current deep learning era, algorithmic progress has rapidly decreased the pretraining cost of AI, increasing effective compute. At the same time, the amount of investment in GPUs used for both training AI systems, and building out data centers to serve AI, has similarly rapidly increased.
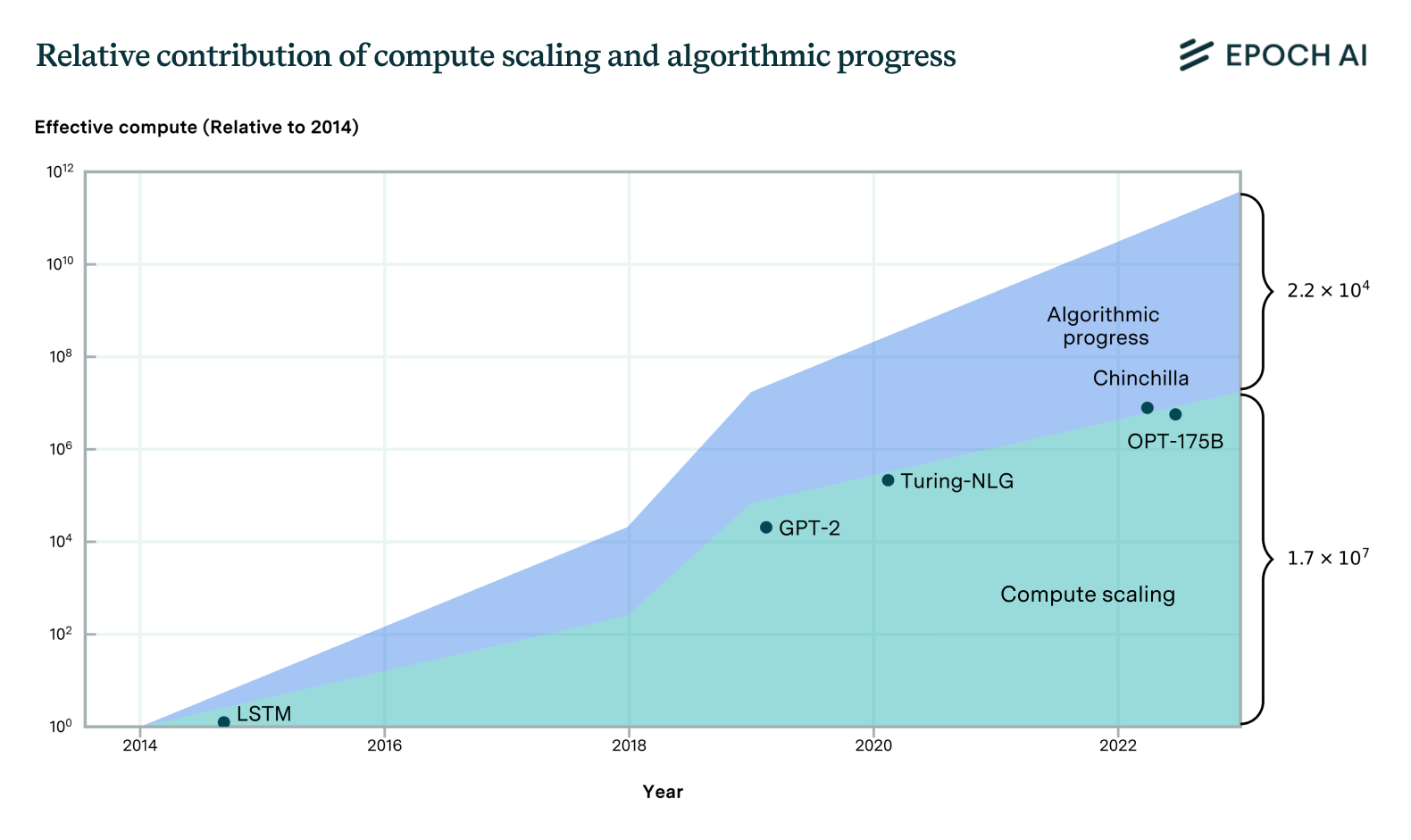
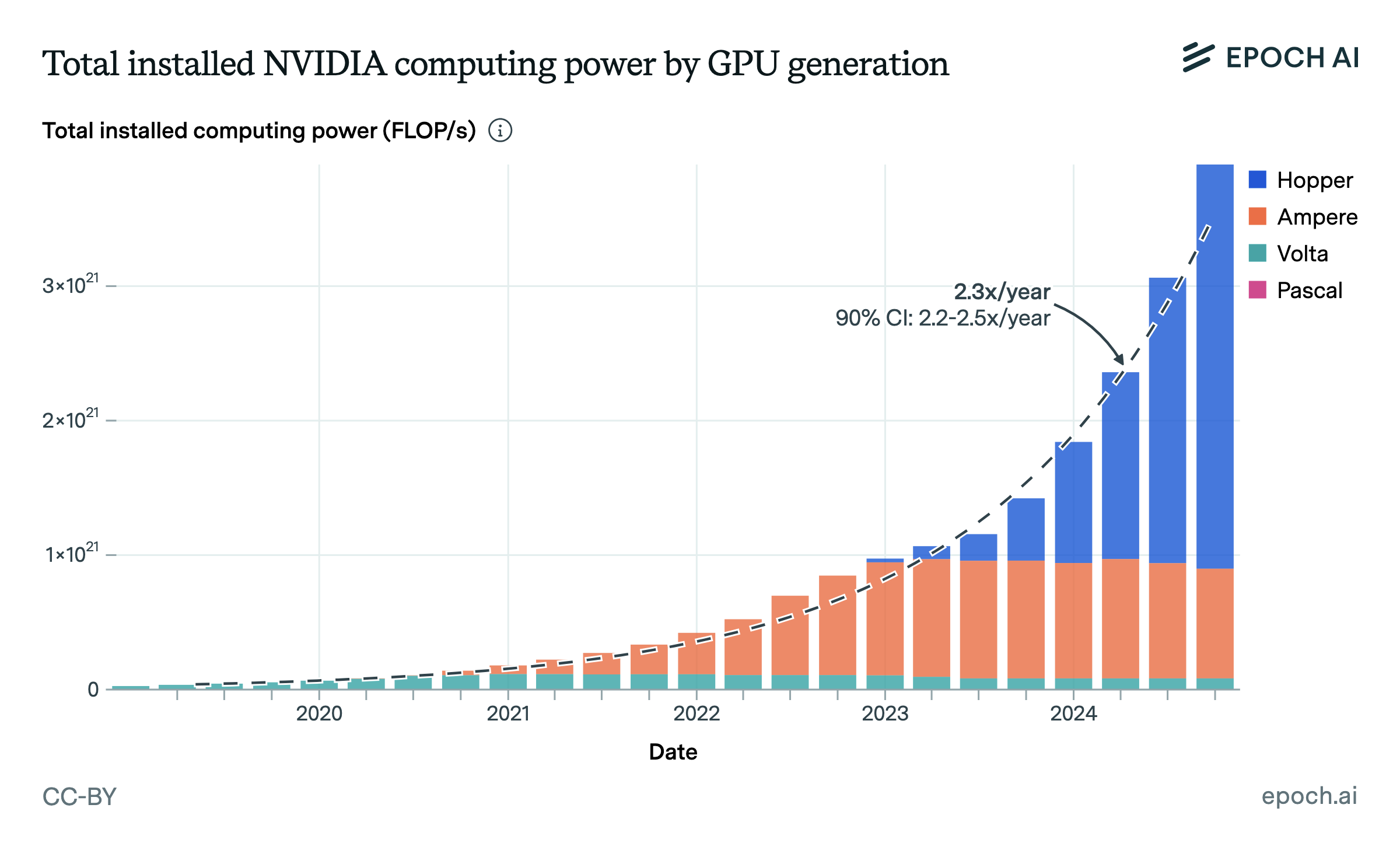
These dual trends directly contradict the idea that algorithmic progress in AI should decrease spending on AI compute. If algorithmic progress had this effect, then rather than observing a dramatic rise in compute investment, we would have seen a decline, given the magnitude of algorithmic progress observed. Instead of seeing a decline, we saw a climb of over 3 orders of magnitude in compute spending.
There appear to be two main reasons that, when combined, can explain why overall spending on AI compute would rise following algorithmic progress. These are:
- The performance effect: Algorithmic progress typically makes it more lucrative to do larger training runs, as it increases the anticipated performance of a model trained at a particular level of compute.
- The substitution effect: Algorithmic progress typically enables people to afford more AI services, and at a higher quality than they otherwise could afford. When AIs can substitute well for other inputs in production—such as human labor—the overall effect of algorithmic progress is to spur higher spending on AI deployment, despite the decreased cost of purchasing AI services.
The performance effect is well-supported by neural scaling laws, which predict that as the inputs to machine learning models are increased—most significantly, compute—the performance of the model will increase. This allows AI labs to improve frontier model performance by conducting training runs at unprecedented scales. This occurs even while algorithmic progress expands the set of actors who can train models to reach a particular level of performance—what has been termed the “access effect”.
Notably, the primary innovations introduced by DeepSeek in their V3 model—specifically, multi-head latent attention, auxiliary-loss-free load balancing, and shared experts—are expected to improve performance even at unprecedented scales. This means that, unlike some other approaches—like model distillation, which largely just produces an access effect—these innovations exhibit a strong performance effect, creating strong incentives for AI labs to scale up their compute even more than they had previously planned to. This is because, at the highest levels of compute, these innovations allow for performance gains that exceed previous expectations, making large-scale scaling even more attractive and worthwhile.
Yet it is important to keep in mind the earlier discussion about computing paradigms. Before 2000, it also seemed natural to assume that aggregate spending on computer hardware would continue rising alongside advances in computing hardware, a belief that was supported by decades of data. Yet, following the dot-com crash and later stagnation in computer adoption, this trend reversed, and the share of GDP devoted to computing began to decline.
This precedent suggests the following scenario may unfold for AI. In the near term, AI compute spending would continue rising as firms train new models and expand AI-driven services to a growing user base. But eventually, the economic utility of AI would reach saturation. For example, at some stage, nearly everyone will already have access to a high-quality language model for routine tasks. Beyond this point, additional compute investment would yield sharply diminishing returns. If researchers discover a way to run an AI system using half the compute, the primary effect will be to reduce total computation rather than to meaningfully expand AI adoption.
In order for AI to break out of this pattern, it must be fundamentally different from conventional computing products in an important way. Specifically, it must be capable of opening up an entirely new economic niche that would allow its value to grow by far more than its current market reach. And in fact, I think there is a good case that AI is unique in this regard, since AI has the potential to automate labor on a massive scale. If AI reaches the point where it can substitute for human workers across a wide range of industries, then its economic importance will likely expand enormously, rather than plateauing like traditional computing platforms did.
The case for AI as an unusual computing product
While current AI products are only useful for a small proportion of tasks in the economy, it is plausible that their economic importance will grow enormously over the next 10 years by becoming more general. Fundamentally, this expectation comes from simply extrapolating progress that we’ve already seen in the field in the last 10 years. Compared to a decade ago, current AIs are enormously more competent in a range of domains, not merely scoring higher on narrow performance metrics, but expanding the set of qualitative capabilities that computers can perform.
Prior to about 2020, AIs were fundamentally incapable of having coherent, long-form conversations in natural language. These days, AI models like o1 and R1 can engage in eloquent, thoughtful, and knowledgeable discussions with users, in addition to writing code snippets, solving mathematics problems, and engaging in rudimentary research. Similar groundbreaking progress has been observed in image generation, image recognition, speech-to-text abilities, and game-playing.
Currently, AI labs are focused on unlocking a number of new capabilities that, if achieved, could open the door to enormous amounts of economic value. This includes building multimodal AI agents with the ability to autonomously act in digital environments over long time horizons, and general-purpose robots that could perform a wide range of physical tasks in industrial and residential environments. Success in either of these domains would enable the creation of AIs that act more like generalist workers than limited AI assistants. Such AIs could work in the background on useful projects with reduced oversight compared to today’s chatbots, enabling the creation of a genuine AI workforce.
Merely creating non-physical, autonomous digital workers could be sufficient to induce a massive economic transformation. I have previously argued that AI capable of automating remote work would likely more than double GDP under even very conservative assumptions. If this occurred over a period of a decade, it would lead to a faster rate of economic growth than we have seen in the United States in recent memory. Extrapolating further, if the labs succeed in creating AGI—a technology capable of substituting for human workers across all labor tasks, both digital and physical—the consequences would be even more profound, with credible economic analyses indicating that GDP could grow by more than 30% per year.
Of course, there is no guarantee that AGI will arrive soon. The likelihood of AI labs achieving these milestones in the near future depends heavily on whether they can maintain the rapid progress we have seen in AI over the past decade. Nonetheless, there are a few reasons to believe that the rate of improvement we have observed could continue for a while.
Perhaps the most basic justification for this expectation comes from the observation that a large part of AI progress over the past 10 years appears to have been driven simply by increasing compute budgets. As previously mentioned, neural scaling laws indicate the ability to boost frontier model performance, with new capabilities emerging as developers have scaled to increasingly higher levels. This pattern has been evident across multiple areas, including pre-training improvements, post-training enhancements, and, more recently, test-time scaling using long chains of reasoning.
According to an analysis of potential bottlenecks to compute scaling by my colleagues at Epoch AI, the historical rate of compute scaling can likely be sustained until at least 2030, at least if investors are willing to fund the necessary infrastructure that would allow scaling to continue. If this analysis is correct, then it suggests that we might continue to see rapid progress in the field for years to come, so long as AI products are sufficiently commercially successful to justify the necessary financial investments. Since algorithmic improvements can enhance frontier model capabilities through the performance effect, they may be the key factor enabling labs to achieve the breakthroughs needed to secure further funding.
If AI labs do end up achieving AGI, then businesses would have a strong financial incentive to increase their spending on compute at least up to a level comparable to what is currently spent on human wages. This is because AGI would serve as a direct substitute for the human labor they are already employing, making it rational for businesses to reallocate their spending on wages to AI services. In this case, compute spending could rise to roughly match the labor share of GDP—the portion of economic output that is spent on worker compensation.
For context, the labor share of GDP in the U.S. is currently about 60%, whereas today, spending on all computing hardware accounts for only about 0.6% of GDP. If compute spending were to rise to match the labor share of GDP, it would represent a 100-fold increase. Since this shift could happen alongside a simultaneous, giant surge in overall economic growth, the combination of these two factors would likely drive a dramatic, and unprecedented rise in real compute spending. Rather than undermining this prediction, algorithmic progress would largely contribute towards it, by enabling AI developers to unleash advanced AI capabilities onto the market sooner than they otherwise could.
Conclusion
The expectation that compute spending will decline as algorithms improve makes sense if you believe that AI is already largely a finished product and that the primary challenge moving forward is simply expanding access to existing AI tools. For example, if you think deep learning is hitting a wall and that AI development will stall at approximately the level of existing chatbots, then continued algorithmic progress would primarily serve to make chatbot production cheaper. As the market for chatbots becomes saturated, total spending on compute would naturally decline.
However, if you believe that the next major step in AI development is creating systems that can automate many forms of human labor, then the potential for compute spending to rise is far greater. This perspective is supported by the past decade of AI development, during which scaling laws led the way towards AI systems acquiring entirely new qualitative capabilities, continuously expanding the range of tasks AI could handle. Throughout this period, spending on AI compute skyrocketed, even as algorithmic progress significantly reduced the costs of training and deploying AI models.
The expectation of a dramatic rise in compute spending ultimately aligns with the clear trend of the past decade: as AI capabilities expanded, so did the demand for compute, even as efficiency improvements lowered costs. If further algorithmic progress, combined with compute scaling, enables AI developers to continue unlocking new and useful AI capabilities, there is a strong reason to expect compute spending to grow rather than shrink.
About the authors

Related work