On January 20th, 2025, DeepSeek released their latest open-weights reasoning model, DeepSeek-R1, which is on par with OpenAI’s o1 in benchmark performance. The release has generated a significant amount of controversy, most notably about the possibility that DeepSeek might have underreported or misrepresented the training cost of their model. I find this claim implausible for reasons that I will explore in this issue.
Aside from the point about the model’s training cost, I also want to clarify what we actually know about the model’s architecture, training process, performance, and pricing.
Architecture
DeepSeek R1’s architecture is identical to DeepSeek v3, an earlier model that the company released in December 2024. I covered the key architectural details of this model in a Gradient Updates issue from two weeks ago, so I will only provide a brief high-level summary here.
Overall, the model is a very sparse mixture-of-experts, with 671 billion total parameters but only 37 billion active per token. The experts are divided into two classes: one “shared expert” which every token is always routed to, and 256 “routed experts” of which 8 are active for any particular processed token and for which model training tries to ensure balanced routing. Most parameters are MoE parameters for the routed experts, and we can confirm this with the following sanity check based on the model configuration file from HuggingFace:
Routed MoE params = (MoE blocks) * (routed experts) * (tensors per expert) * (MoE intermediate dim) * (model hidden dim) = 58 * 256 * 3 * 2048 * 7168 = 653 billion
DeepSeek v3 also uses a novel mechanism called multi-head latent attention (MLA) to cut down the size of the KV cache without the performance loss associated with other popular methods such as grouped-query and multi-query attention. This comes at the expense of increasing the arithmetic cost of attention during decoding, making DeepSeek v3 unusual among other language models in being arithmetic-bound rather than memory-bound during long-context inference. The arithmetic cost of attention becomes comparable to the parameter multiply-accumulates around a past context length of 5000 tokens, compared to e.g. Llama 3 70B where this only happens around a context length of 50,000 tokens.
The ablation experiments from the DeepSeek v2 paper which introduced the method show significant performance gains from using MLA over GQA and MQA. It’s unclear how much we can trust these results, but this might have contributed to the base model’s high quality at its relatively low inference cost.
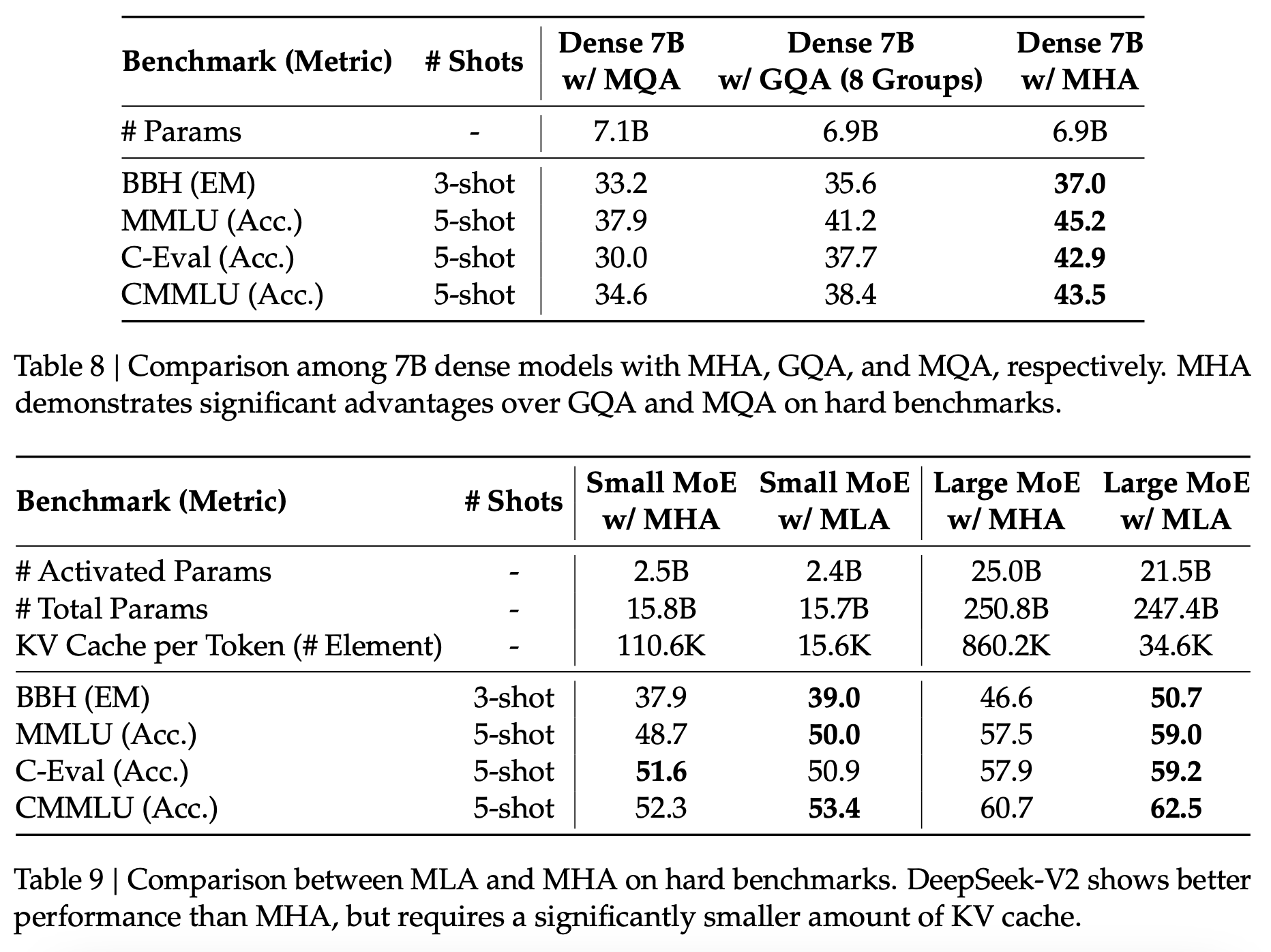
Figure 1: Results of the ablation experiments for attention mechanisms from the DeepSeek v2 paper.
Many of these innovations are quite old: for example, MLA was introduced in the v2 paper which came out in June 2024. The real improvement of R1 over V3 is the use of reinforcement learning to improve reasoning performance, which I will cover in the next section. However, the architecture of the base model still matters because reinforcement learning works much better on base models which already have high intrinsic performance, as this reduces the sparsity of the initial reward signals during RL. So understanding how DeepSeek was able to build a performant base model to build their reasoner on top of is still important.
Training
I’ve seen the public discussion about R1 frequently confuse the pre-training and reinforcement learning phases of the model’s training, so I want to draw a clear distinction between these two phases here.
Pre-training
The pre-training run for DeepSeek r1 was DeepSeek v3. The technical report for v3 gives a remarkable amount of detail about how they trained the model: they used mixed FP8 precision training on a cluster of 2048 H800 GPUs, and processing each trillion tokens of training data took them 3.7 days on this cluster, so about 180,000 H800 hours. They also say that their total training dataset size was 14.8 trillion tokens, implying a training cost of around 14.8 * 180,000 = 2.66 million H800 hours or around $5.3M if we price the cost of an H800 hour at $2.
There’s been a surprising amount of skepticism of these numbers, but they are if anything high for a model with this architecture trained in this way. A dataset size of 14.8 trillion tokens is reasonable and in line with other models of this scale. Assuming that’s valid, the pretraining of this model would have required 6 * (37 billion) * (14.8 trillion) = 3e24 FLOP. If we assume DeepSeek’s training cluster consists of H800s with the PCIe form factor, then each should be capable of 1.5e15 FP8 per second, and the implied model FLOP utilization (MFU) of DeepSeek v3’s 55 day training run ends up being around 23%.
One reason people have been doubting the 3e24 FLOP figure is because the model’s performance seems out of line with other models trained with a comparable amount of resources. For example, Llama 3 70B and its later iterations took around twice the compute to train and they significantly underperform DeepSeek v3 on benchmarks. The reason behind the difference in performance is algorithmic progress: we know Llama 3 70B lacks many of the key architectural innovations that went into creating DeepSeek v3, so it’s not a surprise that it would be less compute-efficient. We know less about what has happened on the data quality side, but I would not be surprised if DeepSeek also improved on the Llama series on that front.
If anything, the unspectacular model FLOP utilization suggests the real mystery about DeepSeek’s training run is not why it was so cheap but why it was so expensive. The obvious answer is that MoE training is hard, but that’s rather superficial and doesn’t address the actual concern, so I’ll instead offer a rough calculation of exactly why we expect orchestrating this training run with high MFU would be difficult.
DeepSeek used 64-way expert parallelism for their training run. In this situation, most experts are located on different GPUs from each other, so we would need inter-GPU communication when entering and exiting the MoE blocks for almost all tokens if we assume expert activations for consecutive layers are uncorrelated. What would be the communication cost of this?
A rough estimate is that because each token is processed by 8 active experts, the residual stream vector of dimension 7168 would have to be sent to each active expert. This would need to happen for every block and for every token, and because the activations are at 16-bit precision, we would need a total activation read volume of
16 bits * 8 * 7168 * 58 * 14.8 trillion = 1e20 bytes
Let’s be pessimistic and suppose that all this communication has to happen over InfiniBand, which in DeepSeek’s cluster probably supports a per-GPU read bandwidth of 50 GB/s. In this case, the time needed for just the MoE entry communications in the forward pass would be
1e20 bytes / (2048 * 50 GB/s) = 11 days 7 hours
This is very bad, because we need to multiply this by a few times for the post-MoE all-reduce and all-to-all operations, and again by two to take the backward pass as well as the forward pass into account. If we make all of these adjustments we can easily end up with the expert parallel communications alone taking up more time than 55 days. DeepSeek realizes this, and they take several measures to address this problem:
-
They implement efficient overlapping of expert parallel communications with arithmetic to hide some of this communication time.
-
They carefully tune their training set-up so that even though each routed expert is active for around 1/32 of the tokens, the expert activations are not independent of each other. Experts close together in the network topology are more likely to get activated together, and this significantly cuts down on the above communication cost by moving much of the expert parallel communication to take place over NVLink.
H800s have slower NVLink than H100s (around 100 GB/s of all-reduce bandwidth compared to 225 GB/s), but their NVLink should still be four times faster than InfiniBand, so this is a big win if it works.
The fact that they are still only able to get MFU up to 23% despite their remarkable efforts at hardware optimization goes to show how annoying it is to train MoE models in practice. They are quite a bit less efficient in the real world than purely arithmetic-based calculations suggest they should be on paper, as I’ve discussed in a past issue focused on MoE inference.
RL training for R1-Zero
We now move on to the contribution made in the r1 paper itself: the reinforcement learning that turns the base v3 model into a reasoner. This paper is less detailed than the v3 technical report, but still contains enough information for us to infer how much computation must have been required for the reinforcement learning phase.
Here is what the core reasoning-based reinforcement learning loop of DeepSeek-R1 (the one that produces the checkpoint Deepseek-R1-Zero) looked like:
- We sample a batch of B questions. For each of these, the model generates G possible answer completions. The model decides when these terminate, but let’s say the completions have an average length of L each over the course of the entire RL training.
- Each completion i = 1, 2, …, G is assigned a reward r_i. This is sometimes done in a rule-based way (e.g. unit tests for code and final answer correctness checks for math problems), and sometimes by using another LLM to perform answer grading.
- We normalize the G rewards by subtracting the mean and dividing by the standard deviation.
- We then do gradient ascent for K steps on a surrogate expected reward objective to make our model more likely to produce high-reward answers and less likely to produce low-reward answers. Because our G rollouts provide worse guidance on the behavior of policies much further from our current model, we penalize deviating too far from our current policy in our objective.
- We repeat the above process N times. This whole reinforcement learning algorithm is called group-relative policy optimization (GRPO), and was introduced by DeepSeek in prior work as a cheaper alternative to the more often used PPO.
When we break down the process in this way, it’s easy to provide a rough expression for the FLOP cost of the first phase of RL training. Normally, we could do this by assuming 6 FLOP per token per parameter for each forward and backward pass, but DeepSeek v3’s uniquely arithmetic intensive attention mechanism raises this cost. At the mean context length of L = 4000 used during their RL, attention FLOP ends up being comparable to parameter FLOP during decoding, so on average we spend 4 FLOP instead of 2 FLOP per active parameter and per token generated. We only need to pay this cost once for the first gradient step taken after each exploration phase, as subsequent steps rely on the trajectories we’ve already sampled previously.
The backpropagation steps are also affected, but it turns out we can ignore this effect without much trouble. Because we take each step over a long sequence length, we can afford to decompress the key and value vectors from their latents and backpropagate through a different computation graph compared to the one we’ve done the forward pass through. This adds some additional cost, but it’s not substantial, so we can approximately assume that backpropagation has its usual cost of 4 FLOP per active parameter per token.
Taking DeepSeek v3’s 37 billion active parameter count into account, we obtain the final estimate
Reasoning RL compute cost = N * B * G * (L tokens) * (37B parameters) * (8 FLOP/param/token) +
N * (K-1) * B * G * (L tokens) * (37B parameters) * (6 FLOP/param/token)
The paper gives us information about the key parameters going into the calculation:
-
N*K is the total number of gradient steps throughout RL training, and we know this is equal to around 8000 from various figures in the paper. In prior work DeepSeek used K = 1, in which case we have N = 8000.
-
We can infer that the average value of L throughout these steps is around 4000 by looking at Figure 3 from the paper.
-
B and G are not explicitly stated in this paper, but in prior work DeepSeek used B = 1024 and G = 64. This is the biggest source of uncertainty in my calculation. For example, it’s quite plausible DeepSeek used B = 512 for R1, in which case all the cost estimates here will be too high by a factor of 2.
I’ll proceed with B = 1024 for the moment, but it’s important to keep this point in mind when interpreting the results.
Combining all of this, we come up with a final cost estimate for the initial reasoning RL phase of 6.1e23 FLOP, or around $1M if the RL phase had a similar MFU to pretraining. This is significantly less than the pretraining arithmetic cost of DeepSeek v3 itself. The MFU during reinforcement learning would have to be 5x worse than in pretraining, around 5%, for the cost of RL to even be comparable to the cost of pretraining when measured in GPU hours.
We can estimate how long the RL phase might have taken to see if such low MFU figures are plausible. The total number of sequential tokens generated is around N * L, which is 32 million assuming K = 1 based on the DeepSeekMath paper. DeepSeek serves R1 for inference at around 50 tokens per second per request, and at that speed 32 million serial tokens can be generated in 7 to 8 days. This is short enough that we wouldn’t expect serial time constraints to be a problem for their RL setup, so 50 tokens per second is a good enough speed. Interestingly, it’s also in line with how much their 2048 H800 cluster would have required for the arithmetic if it were operating at a similar MFU to DeepSeek v3’s pretraining.
How much would the token generation part of RL have cost at this speed? We need to generate a total of N*B*G*L = 2T tokens for the whole RL phase, and DeepSeek’s original undiscounted API price for V3 was $1.1 per million output tokens, so the cost should be at most (2T tokens) * ($1.1/million tokens) = $2.2M. At the current discounted price of $0.3 per million tokens, this estimate is cut down to $600K, which is roughly in line with the $1M estimate from earlier if we also take the cost of backpropagation into account.
All of this suggests that the extremely low MFU figures required to make RL cost comparable to pretraining cost are unrealistic, and the conclusions we can draw from the raw FLOP cost are roughly accurate.
Subsequent training for R1
The RL loop that produces R1-Zero is the core of the reasoning training, but it’s not the only step before the final R1 model is trained. Building on this checkpoint, DeepSeek curates a cold-start dataset (partly including cleaned up R1-Zero outputs) to fine-tune the base v3 model before doing another phase of RL training, similar to what produced R1-Zero. This cold-start prevents the early instability of RL training and ensures that the model’s outputs and chain-of-thought are human readable. We have less details about this second RL phase in the paper, but if we want to be conservative we can assume it had a similar cost to the first one and double our initial cost estimates to take it into account.
Once this is done, DeepSeek creates a supervised fine-tuning dataset of around 600K reasoning samples from this last checkpoint and 200K samples that went into the post-training of v3 itself before fine-tuning v3-base on all of this data for two epochs. If the average length per sample is around 8K, which is in line with what R1-Zero achieves by the end of training, this SFT dataset has a total of 800K * 8K = 6.4B tokens and so the fine-tuning itself has a negligible cost. This step is interesting because it shows that a limited amount of fine-tuning on reasoning traces is sufficient to turn a base model into a competent reasoner, which explains why labs such as OpenAI might be interested in keeping their reasoning traces secret.
Overall, I think a reasonable ballpark estimate for the dollar cost of the GPU time that went into training R1 starting from V3 is around $1M, on top of the $5M that went into the pretraining of V3 itself. The reason I don’t simply double the $1M figure from earlier is because I don’t know if the choice of B = 1024 is right or whether the second RL phase indeed had the same cost as the first. At a total cost estimate of $1M, I think I’m about equally likely to be wrong in either direction, so it seems like the right number to go with.
As a final note, all of these numbers ignore the compute costs of experiments, personnel costs, administrative overhead, et cetera. They are strictly the hardware time cost of the training runs that went into the training of R1 in the sense that I’ve elaborated on above.
Performance and pricing
DeepSeek-R1 appears to have a similar performance to OpenAI’s o1 on benchmarks where we have scores available for both. On the 11 benchmarks that DeepSeek quotes results for both models, o1 beats R1 in 6, which is about as close of a result as we could expect. I think o1 should still be better than R1 in overall performance due to the usual publication bias when labs publish benchmark scores of their own models, but the difference is not large, and for most use cases the models should be comparable.
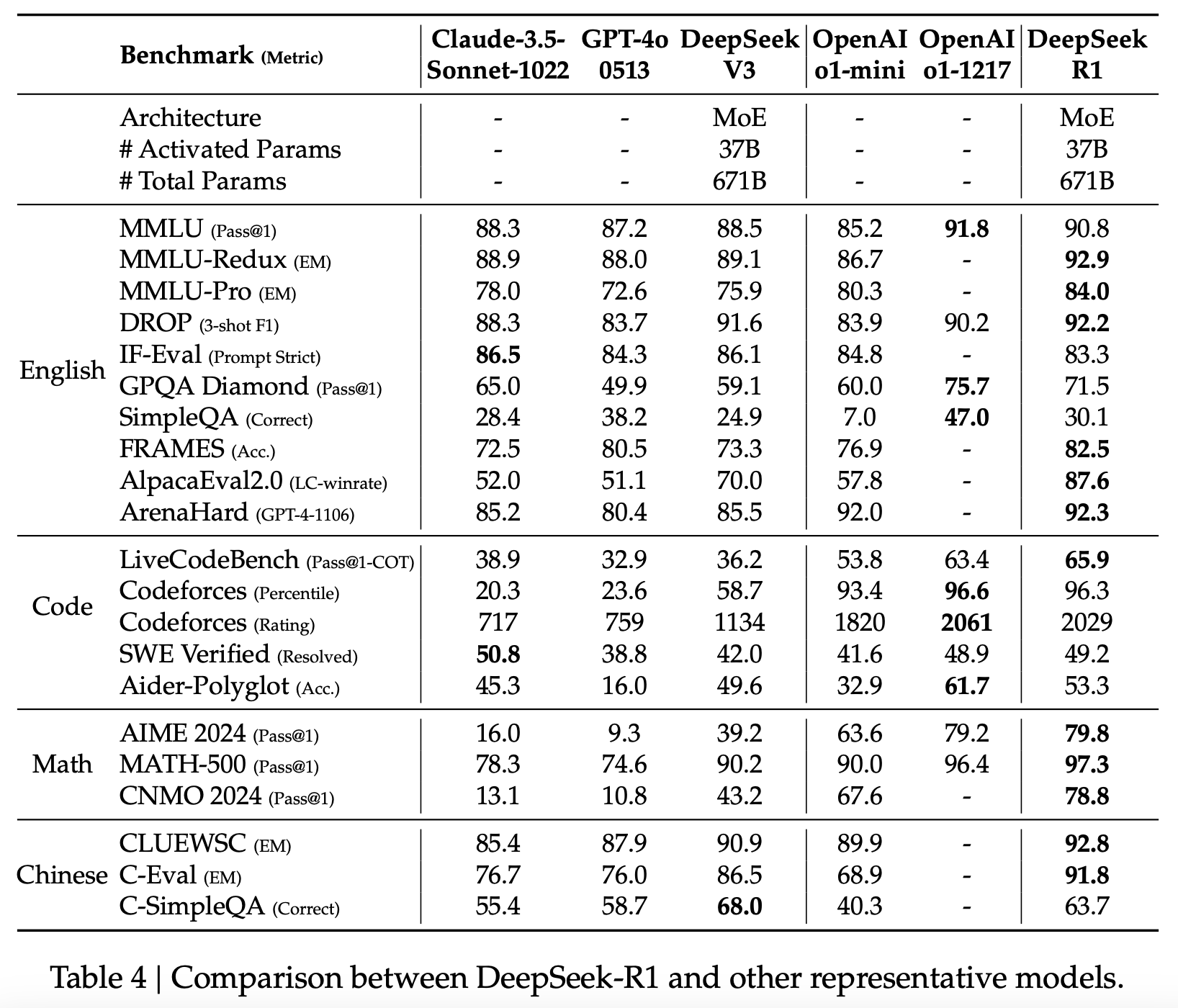
Figure 2: Table comparing DeepSeek-R1 and other representative models. From the DeepSeek R1 technical report.
However, while the performance difference between the two models is small, the pricing difference is definitely not. R1 is priced at $2.2 per million output tokens compared to $60 per million output tokens for o1, and R1 is also not slower in inference. This vast difference means when adjusted for the price to the consumer, R1 is simply a superior model to o1.
I don’t think this difference is arising from R1 being intrinsically more efficient as a model, but rather because DeepSeek is serving the models with very little gross margin compared to the large margins charged by OpenAI. R1 might also have shorter reasoning traces on average, though this is less clear. It remains to be seen to what extent cost competition from DeepSeek and other Chinese labs will affect the API profit margins of US labs, but I don’t think it’s good news for them.
Conclusion
Here are the main points I’d like readers to take away from this issue:
-
While public interest in DeepSeek’s models has exploded following R1’s release, from a technical point of view most of the ingredients that went into R1’s success have been gradually developed by DeepSeek in 2024. Having a high-quality, cheap, and fast base model such as v3 is most of the difficulty in making this RL setup work.
-
DeepSeek’s reported cluster size and training cost estimates for v3 align with what we would expect for the pretraining of a model with v3’s architecture, and there’s no evidence they are underreporting costs.
-
While DeepSeek has not made any explicit statements about the cost of the RL that went into DeepSeek-R1, based on the information disclosed in their papers I would estimate it’s around $1M.
-
DeepSeek-R1 is approximately on par with the best version of o1 OpenAI serves via API while being around 30 times cheaper to the consumer. This difference is probably mostly due to OpenAI’s large markups, though we can’t rule out some of it being due to R1 simply being a more efficient model.
My best guess is that DeepSeek remains behind frontier US labs like OpenAI and Anthropic when it comes to software efficiency. However, the distance is not far: I would estimate DeepSeek is behind by around six months based on comparing the base DeepSeek v3 model to models we’ve seen from frontier labs. In addition, DeepSeek’s willingness to serve their models close to marginal cost makes them a much more attractive option to users overall.
About the authors

Related work