Almost a year ago, OpenAI introduced o1, the world’s first “reasoning model”. Compared to its likely predecessor GPT-4o, o1 is more heavily optimized to do multi-step reasoning when solving problems. So it’s perhaps no surprise that it does much better on common math and science benchmarks.
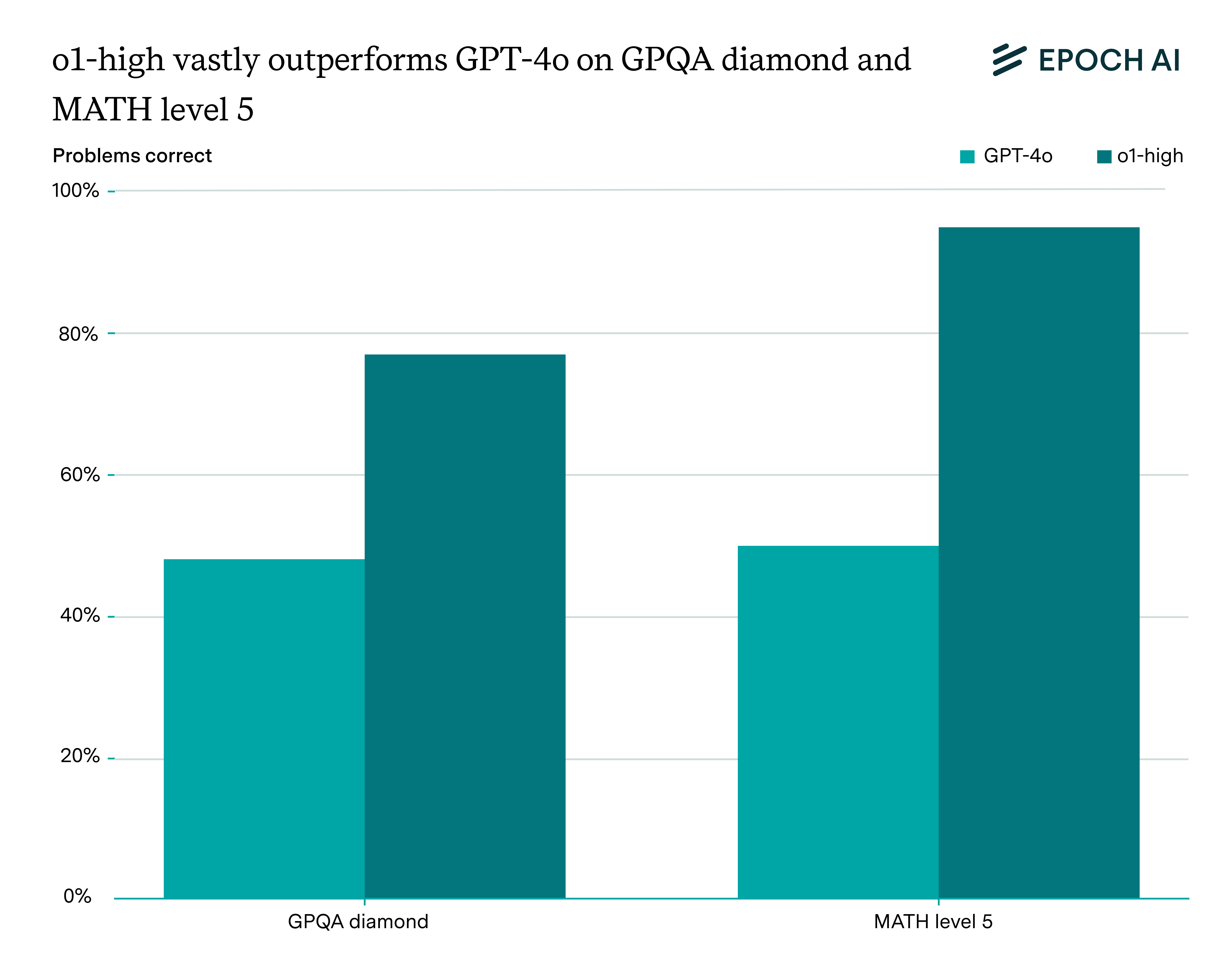
o1 performs far better than GPT-4o on GPQA diamond (PhD-level multiple-choice science questions) and MATH level 5 (high-school math competition problems).1 Data is taken from Epoch AI’s benchmarking hub.
By itself, this performance improvement was already a big deal. But what’s even more important was how it was achieved: This wasn’t achieved by using a lot more training compute. Instead, this was the byproduct of a major algorithmic innovation. o1 went through a period of “reasoning training”, where its chain-of-thought was fine-tuned on reasoning traces and optimized using reinforcement learning. This allows the model to spend more time “reasoning” before responding to user queries.
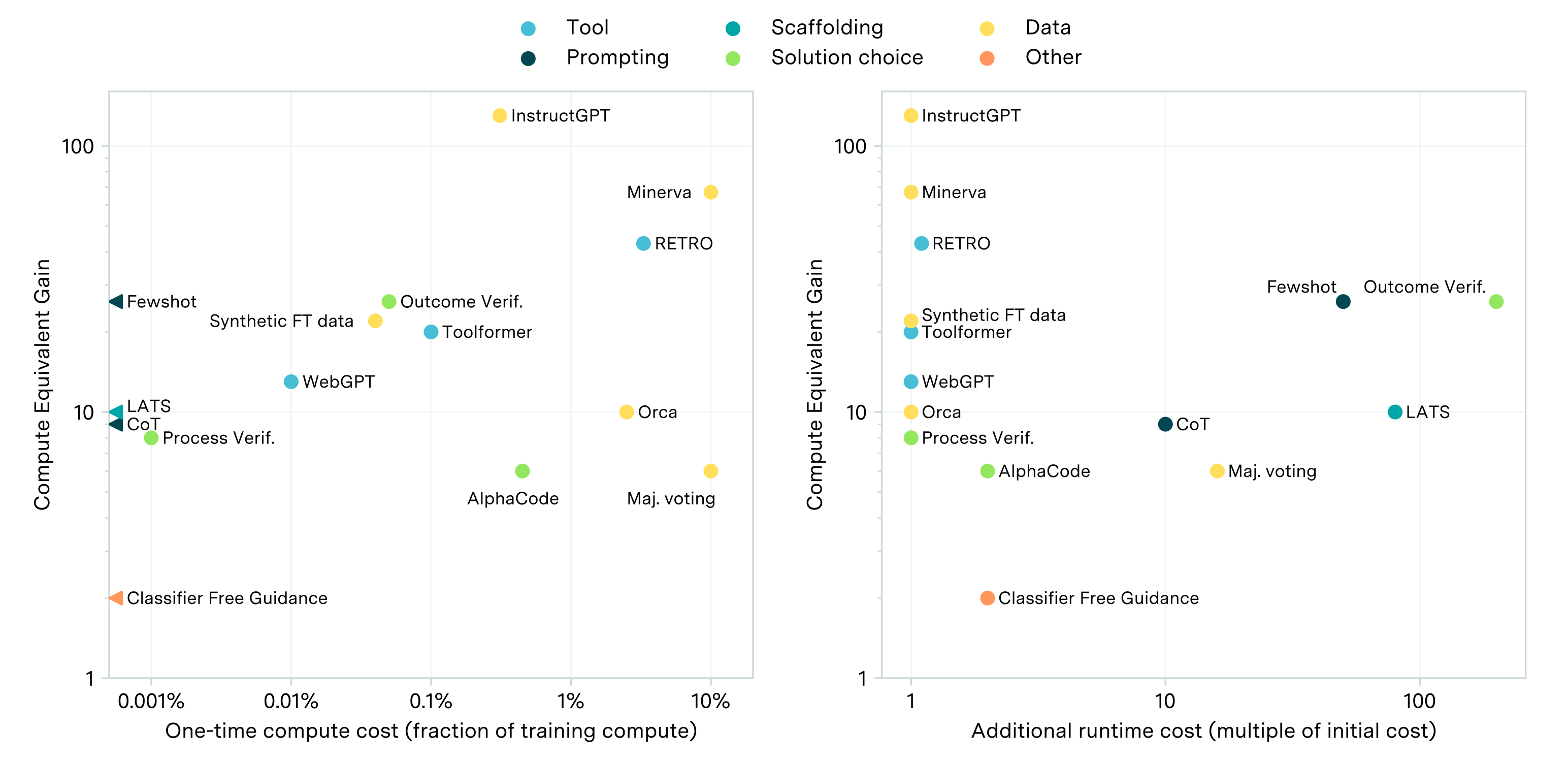
But how can we quantify the importance of this algorithmic innovation? One way to do this is to interpret its importance in terms of a hypothetical increase in training compute. Specifically, we exploit the empirically robust relationship that more pre-training compute leads to better benchmark performance. This relationship allows us to ask a key question: how much more pre-training compute would GPT-4o have needed to match o1’s performance?2 We call this the “compute-equivalent gain” (CEG), and it is a standard way of quantifying the contribution from algorithmic innovations.
On GPQA, MATH, and Mock AIME, early reasoning models yielded on the order of a 10x increase in compute equivalent gain
To quantify this algorithmic improvement, we need a dataset of model scores on some benchmark. In particular, we first get data on training compute and benchmark performance for a specific family of models (e.g. OpenAI’s GPT series of models). We then fit a sigmoid that maps this pre-training compute to performance.
We next choose a pair of models where one is the reasoning-trained counterpart of the other (e.g. o1-high is the reasoning counterpart of GPT-4o).3 We take the performance of the reasoning model, and use the fitted sigmoid to back out the equivalent amount of “pre-training compute” needed to achieve that performance. Finally, we divide this training compute equivalent by the training compute of the non-reasoning model to obtain the CEG.
In the case of GPQA diamond, this approach suggests that reasoning training of o1 yielded a CEG of roughly 9x relative to GPT-4o. We then repeat this process for OTIS Mock AIME and MATH level 5, since these are the benchmarks with most available data, and also look at other plausible pairs of reasoning/non-reasoning models from OpenAI. Below we show the estimated CEGs when GPT-4o is the base non-reasoning model, and o1-preview, o1-medium, o1-high, and o3-high are the corresponding reasoning models.
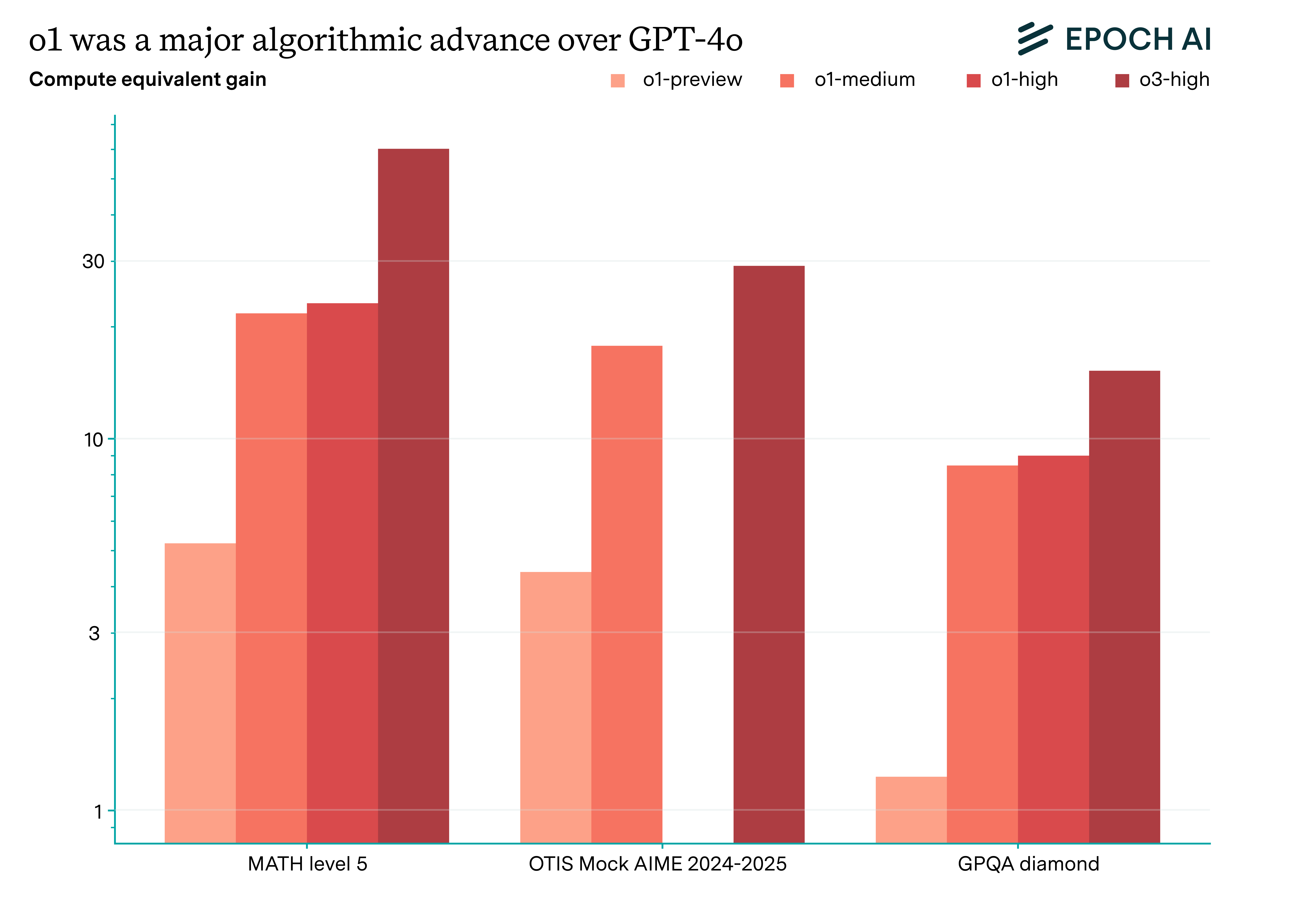
Probably the most speculative pair of reasoning/non-reasoning models here is GPT-4o to o3. For example, it’s very possible that o3 was based on GPT-4.1. Nevertheless, we show the implied CEG assuming that the relevant non-reasoning model is GPT-4o, since we also consider this plausible. Note that we don’t have data on o1-high’s performance on Mock AIME.
Besides this, we also attempt to perform the same analysis for other model families, but this is bottlenecked by the lack of available data. On model families like Qwen, DeepSeek, and Grok, we don’t have enough datapoints to be able to fit a good scaling curve.4 Other model families like Llama don’t have a clear reasoning model, and we lack compute estimates for the Gemini model family.
That being said, one other case where we can plausibly eke out a CEG estimate is Anthropic’s Claude model family. But this requires reading some tea leaves: we need to assume that Claude 3.7 Sonnet is really just a version of Claude 3.5 Sonnet with some reasoning training.5 We think this is plausible because Anthropic describes Claude 3.7 Sonnet without “extended thinking” (test-time scaling) as an “upgraded version of Claude 3.5 Sonnet”.
The CEG when transitioning from Claude 3.5 Sonnet (Oct 2024) to Claude 3.7 Sonnet, both with and without extended thinking. The versions that include extended thinking specify the token budget, e.g. “Claude 3.7 Sonnet (16K thinking)” has a budget of 16k output tokens.
In this case we find CEGs that are broadly similar as for GPT-4o and its reasoning-trained counterparts, i.e. between 1x and 100x, with a central estimate of around 10x.6 This is pretty substantial – for instance it’s plausibly larger than innovations like the Transformer and Mixture-of-Experts architectures, at least on these benchmarks. And it seems on par with many prior algorithmic enhancements introduced during post-training, though perhaps more generally applicable than on specific benchmarks, and also more of a general paradigm shift.
One additional thing we can try and infer from the Claude models is the relative CEG contributions from reasoning training and test-time scaling. We take the CEGs for the three transitions to models with extended thinking, and divide them by the CEG for the transition without extended thinking.7 This works out to a roughly even contribution to the CEG from reasoning training and test-time scaling. In the graph above, this looks like the 3.5 Sonnet to 3.7 Sonnet bars being around half the height of the other bars.
How much should we believe these estimates?
While we’ve managed to obtain a couple of rough estimates of the CEG from reasoning models, several things about our methodology are quite suspicious, making the estimates hard to interpret.
For one, reasoning models perform better than non-reasoning models in part because they think for longer at test-time, not just because of reasoning training. So both the total CEG and the relative contributions of training and extended thinking depend on the amount of test-time scaling performed. Indeed, versions of 3.7 Sonnet with larger output token budgets tend to have larger CEGs, and they also tend to use more tokens on average in practice. For example, Claude 3.7 Sonnet outputs around 2-3x more tokens than Claude 3.5 Sonnet, and doing extended thinking increases the 3.7 Sonnet’s output tokens by 10-20x depending on the amount of reasoning.
Data on the average number of output tokens is taken from Epoch’s benchmarking runs.
Another issue is that we’ve neglected other algorithmic improvements. Even without reasoning models, algorithmic progress in pre-training would reduce the amount of compute for models to reach a given performance, and that would change the sigmoidal fit we obtain between compute and performance. And in particular, this runs the risk of underestimating the CEG from reasoning.
These problems only add to existing uncertainties. For example, we have a major lack of data to work with, and the data we have could be contaminated. Furthermore, there are debatable interpretations of reasoning/non-reasoning model pairs, like whether Claude 3.7 Sonnet is really “just Claude 3.5 Sonnet with reasoning training”. All this is to say that these estimates are highly uncertain, though we think they provide fairly strong evidence of a very large algorithmic improvement – at least on some benchmarks.
A wide range of common benchmarks saw performance improvements due to reasoning
In the previous section, we saw that there was variation in the CEG across different benchmarks. For example, Claude 3.7 Sonnet (64K thinking) had a 4x higher CEG on Mock AIME than on GPQA diamond. But just how large is this variation in CEGs?
At the very least, we should expect that some tasks have seen almost no benefit from reasoning training or test-time scaling, making the CEG effectively one.8 For example, OpenAI reportedly found minimal improvements in personal writing and editing text from o1-preview, as compared to GPT-4o.
However, we think that the fraction of benchmark tasks where we see almost no benefit is likely to be quite small. To see this, we can look through all the benchmarks in Epoch’s benchmarking hub, and identify the performances of all the reasoning/non-reasoning model pairs.9 If we average the performances of the reasoning models and the non-reasoning models separately, we can see which benchmarks tended to be amenable to reasoning.
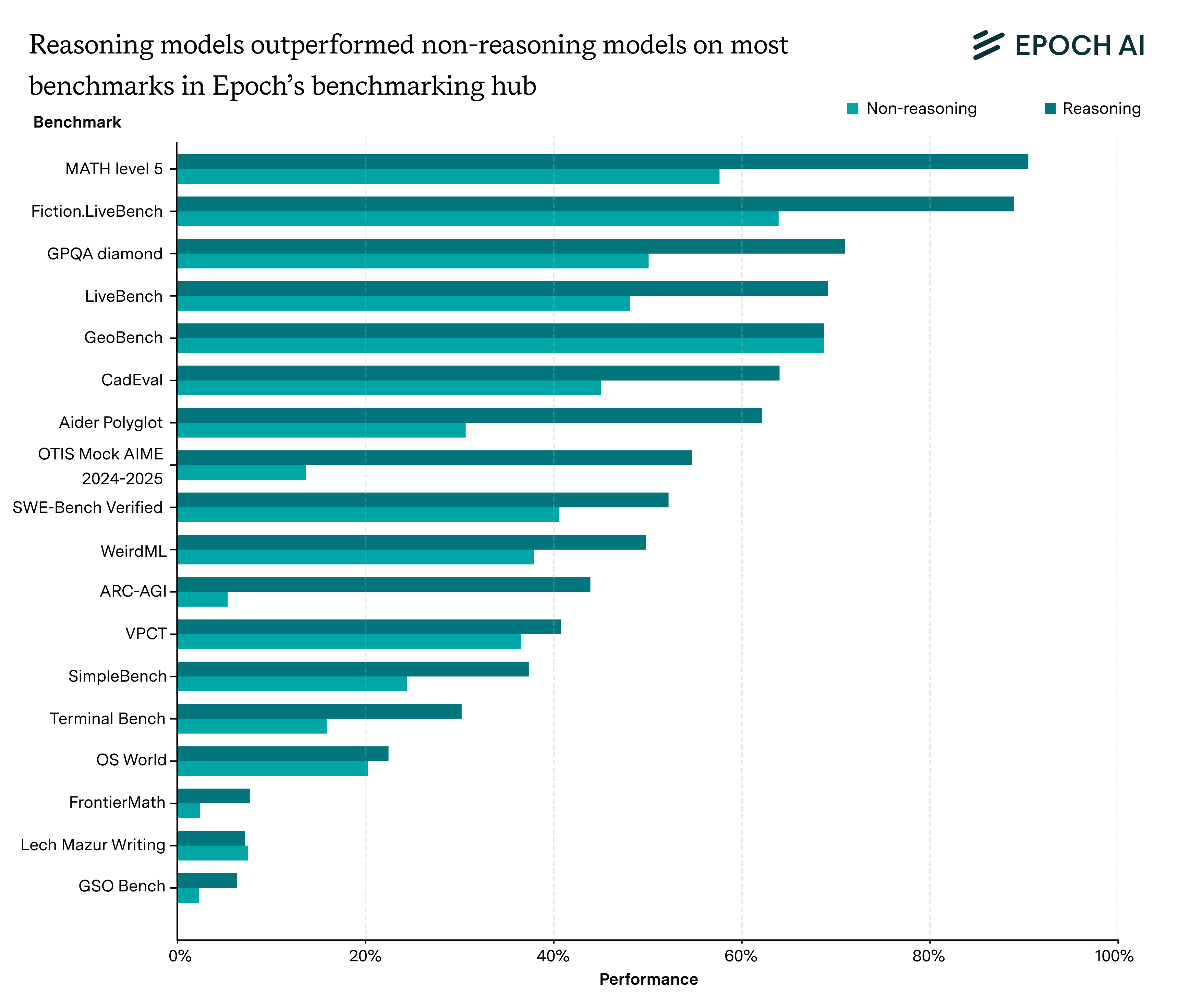
What we see is that a fairly small fraction (~10%) of these benchmarks with pair performances showed essentially zero improvement.10 In most other cases, we saw a >5 percentage point improvement on the relevant benchmark, for a small increase in total compute cost from reasoning training and scaling.
Another way to think about reasoning improvements is to look at trends in reasoning and non-reasoning model performance over time. On benchmarks like Mock AIME, non-reasoning models seem to be making fairly slow progress, and reasoning models substantially exceed them. In contrast, benchmarks like GeoBench and Lech Mazur’s Writing seem to barely show reasoning improvements at all.
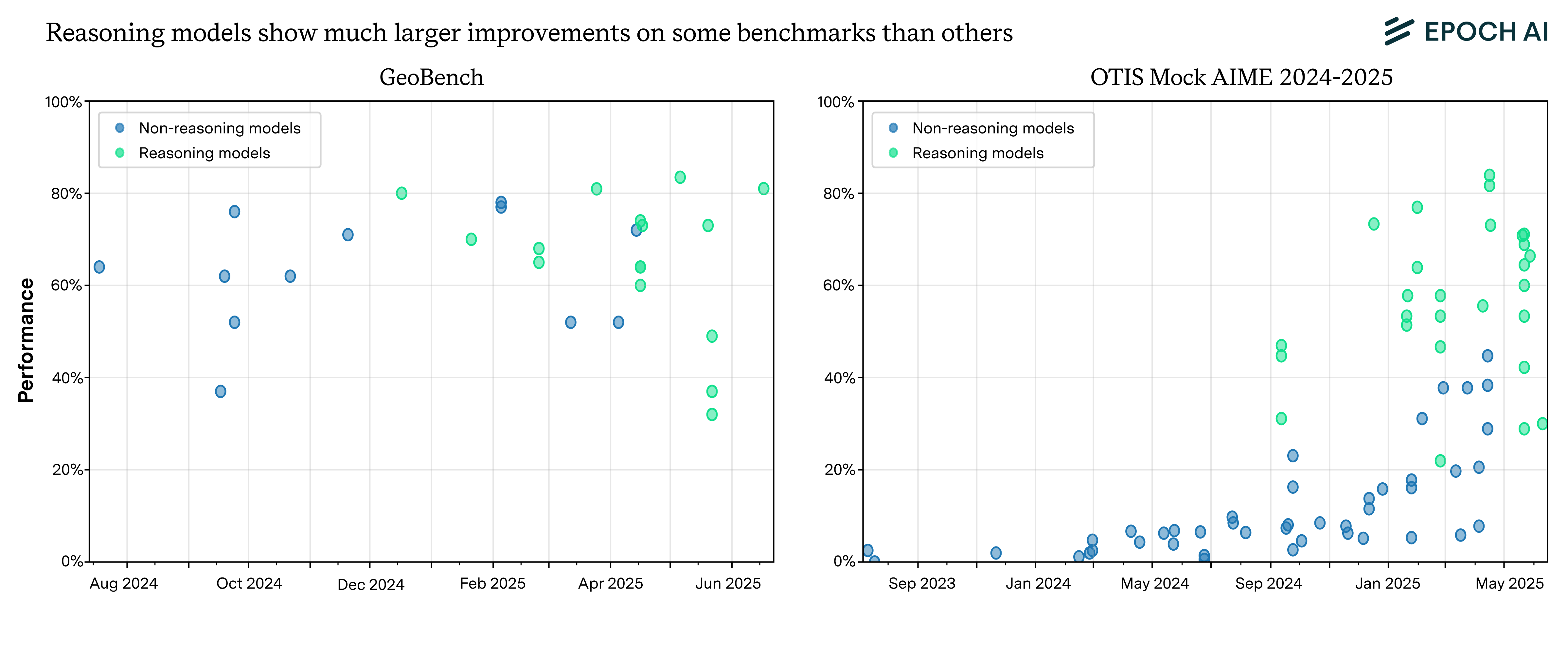
Reasoning models seem to show little improvement on GeoBench, but substantially exceed the non-reasoning model trend on OTIS Mock AIME 2024-2025.
So what makes these benchmarks so different from Mock AIME? One possible reason is that it is harder to optimize current models for them. Mock AIME is a math test, where model outputs can be verified in a fairly clear-cut fashion. This makes it easier to provide a clear training signal for improvement, not to mention that AI labs have generally devoted a lot of effort toward progress in AI math capabilities. In contrast, Lech Mazur’s Writing benchmark involves writing creative fiction in a coherent and engaging way – a task that seems harder to evaluate and train on. GeoBench involves guessing the latitude and longitude where a photo was taken, which is perhaps bottlenecked in part by multimodal capabilities, and was likely less optimized for compared to math.
But it’s hard to be confident that this is right. Some benchmarks like VPCT do also involve multimodal capabilities, but reasoning models still do notably better on average. AidanBench tests creative open-ended answer generation, but the current leaderboard shows o1, o3-mini-medium, o3-mini-high, and Gemini 2.5 Pro outperforming GPT-4.5. This is despite GPT-4.5 being known for good writing abilities, and likely being trained on more compute!
Personally, we think that these issues around the ease-of-verification and multimodality are probably directionally correct. But it’s still hard to say in advance how much reasoning will help on a specific benchmark, even though we think that most common language model benchmarks should see some improvement.
Big open questions remain about generalization and test-time scaling
So what does this all mean for AI progress?
This depends hugely on the returns to further reasoning training and scaling, which we personally think will continue to be quite high over the next year. It seems like there’s further room to scale, and given just how new the reasoning paradigm is, it’s likely that a lot of low-hanging fruit has yet to be picked.
What’s less clear is how much of this low-hanging fruit relates to generalization to different tasks. Given that reasoning models outperform non-reasoning models on most of the benchmarks we looked at, it’s tempting to conclude that reasoning models will help a lot on a wide range of tasks in the real-world. This does seem plausible, but it’s hard to be certain because benchmarks tend to involve close-ended and easily verifiable tasks.11 This results in a selection bias: these tasks are exactly the ones that reasoning models excel most at!
Still, seeing reasoning improvements on a wide range of benchmarks is not to be sniffed at. This is still a broader impact than a decent chunk of previous post-training enhancements, which often (but not always) only applied to a narrow set of tasks or benchmarks.
And serious efforts are being made to expand the range of tasks that reasoning has a big impact on. For example, OpenAI’s recent work on the International Mathematical Olympiad involved developing techniques to improve language models on hard-to-verify tasks in a general fashion. And similar efforts and techniques arguably already serve as proofs-of-concept that further expanding the range of tasks is possible.
We still do expect the returns to reasoning to be higher on easy-to-verify tasks, and this is what we’ve seen so far. Moreover, we think people are going to continue throwing a lot of effort into relatively verifiable tasks like math and programming, since we tend to find AI success on these tasks impressive. In the case of programming, it’s also economically valuable!
Based on current evidence, our current impression is therefore that there will continue to be high algorithmic returns to reasoning over at least the next year. Reasoning currently probably yields some benefits on a fairly wide range of tasks, but the returns are much larger on domains like math and programming. The benefits of reasoning will spread, though we still expect it to disproportionately benefit domains where verification is easier. But the extent and rate of this remains to be seen.
-
Note that this is referring to the version of GPT-4o from November 2024, rather than the ones from May and August 2024. The latter two versions of GPT-4o both score around 49% in Epoch’s evaluations on both GPQA diamond and MATH level 5.

-
Note that when the CEG is very large the implied pre-training compute could end up being a purely fictional hypothetical – there (currently) isn’t enough pre-training data to truly support a frontier pre-training run that is many orders of magnitude larger than say Grok 4. Synthetic data could be used, but this would likely substantially change scaling behavior.
-
For the reasoning models we look at here, they’ll most likely be trained on <20% more compute than the non-reasoning model.
-
There are also other issues with these model families. For instance, it’s tricky to estimate the CEG when transitioning from DeepSeek-V3 to DeepSeek-R1, because V3 was partially distilled from a version of DeepSeek-R1 that was based on DeepSeek-V2.5. Moreover, DeepSeek-R1 also includes techniques like supervised finetuning which might not be grouped under “reasoning training”. These kinds of issues would make the resulting CEGs harder to interpret, even if we could estimate them.
-
Note that we’re referring to the October 2024 version of Claude 3.5 Sonnet, which is sometimes informally referred to as “Claude 3.6”, distinguishing it from the original Claude 3.5 release in June 2024.
-
Interestingly, for the GPT models the CEG is larger on Mock AIME than on MATH, but the reverse is true for the Claude models.
-
This calculation depends on the fact that 3.7 Sonnet with and without extended thinking uses the same model.
-
The CEG could also be less than one, if the reasoning model performs worse than the non-reasoning model!
-
Note that the data used to create this figure includes internal Epoch data that hasn’t been published yet.
-
Of course, this could simply be the result of a selection bias. But note that the benchmarks included on the benchmarking hub are typically chosen for their importance for AI progress or their relevance to economic impacts.
-
Not to mention, benchmark tasks may not reflect the messiness of real-world ones.
About the authors


Related work