This week’s issue is a guest post by Henry Josephson, who is a research manager at UChicago’s XLab and an AI governance intern at Google DeepMind.
In the AI 2027 scenario, the authors predict a fast takeoff of AI systems recursively self-improving until we have superintelligence in just a few years.
Could this really happen? Whether it’s possible may depend on if a software intelligence explosion — a series of rapid algorithmic advances that lead to greater AI capabilities — occurs.
A key crux in the debate about the possibility of a software intelligence explosion comes down to whether key algorithmic improvements scale from small models to larger models. If the most important algorithmic advances need a large amount of compute to demonstrate their effectiveness, then we should think that a software-only intelligence explosion is less likely. And so a fast takeoff could be bottlenecked by compute constraints.
In a recent preprint, my team at UChicago’s XLab — Spencer Guo, Teddy Foley, Jack Sanderson, Anqi Qu, and I — reviewed the literature and performed some small-scale tests to investigate this crux.
We found that, historically, the largest algorithmic advances couldn’t just be scaled up from smaller versions. They needed to have large amounts of compute to develop and validate, making a software intelligence explosion more difficult to achieve than it might seem.
Are the best algorithmic improvements compute-dependent?
In our survey of the literature, we classified algorithmic advances as either:
- Compute-independent, meaning the benefits of the advance appear at small scales and continue or accelerate as scale increases
- Compute-dependent, meaning the benefits of the advance only appear with high amounts of compute, and the algorithmic advance provides little benefit (or even hurts performance) at low compute levels
Our investigation began by examining the architectural evolution of language models, starting around 2017 and getting as close to the present as we could. We focused on well-documented model families where implementation details were publicly available: early GPTs, BERT variants, LLaMAs, and DeepSeek.
We did our best to focus on successive model generations within a family, on the hypothesis that this is as close as we can get to controlling for variations in training data.1 This meant that we could be more confident that increases in performance came from algorithmic advances — especially if we could control for scale.
This approach revealed patterns:
- Within the GPTs, we saw the rise of sparse attention.
- BERT variants showed us how layer normalization evolved into RMSNorm.
- LLaMA iterations demonstrated the progression from standard attention to grouped-query attention.
- DeepSeek’s releases, particularly constrained by hardware limitations, showed algorithms that enabled frontier performance without frontier compute.
These observations helped us build our experimental design. We selected algorithms that appeared repeatedly across model families — the ones that stuck around seemed more likely to represent real improvements. Given our compute constraints, we also picked algorithms that we could feasibly implement and test: multi-headed attention made the cut, but a full mixture-of-experts architecture didn’t.
The literature also informed how we classified an algorithm as “compute-dependent” or “compute-independent.” When we saw that certain algorithms only appeared in the largest models while others showed up in both large and small models, it suggested the compute-dependent vs. compute-independent distinction that we ended up testing.
Take, for example, multi-query attention (MQA), which reduces the amount of memory the attention mechanism needs. As we note in the paper,
At the time of its introduction in 2019, MQA was tested primarily on small models where memory constraints were not a major concern. As a result, its benefits were not immediately apparent. However, as model sizes grew, memory efficiency became increasingly important, making MQA a crucial optimization in modern LLMs (including Falcon, PaLM, and StarCoder).2
MQA, then, by providing minimal benefit at small scale, but much larger benefit at larger scales —is a great example of the more-general class of a compute-dependent innovation.
In contrast, algorithms like layer normalization showed up consistently across model sizes. From our review, we found that it “demonstrated speedups on the much smaller neural networks used in 2016 and is still often used in models today.”3 So layer normalization is compute-independent.
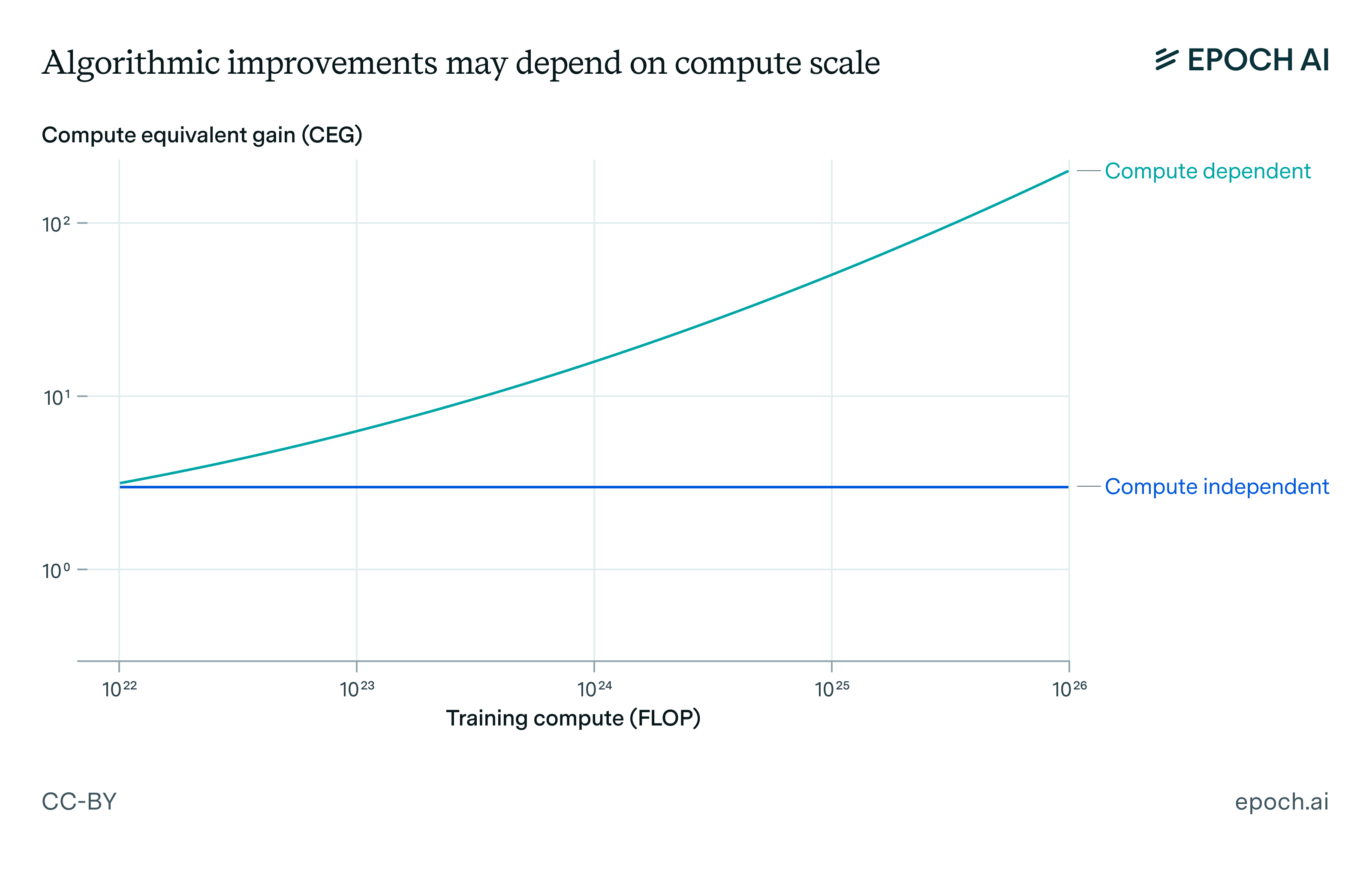
To test our hypothesis that key algorithmic advances are compute-dependent, we implemented the above algorithmic improvements on a scaled-down version of GPT-2 (about 165M parameters instead of the full 1.5B). We measure compute-equivalent gain (CEG) by comparing how much additional compute would be needed to achieve the same cross-entropy loss on OpenWebText without the algorithmic improvement. For instance, a CEG of 2x means the algorithm lets us achieve the same loss with half the compute.
Here are our estimates of the compute-equivalent gain for each of the following algorithmic advances:
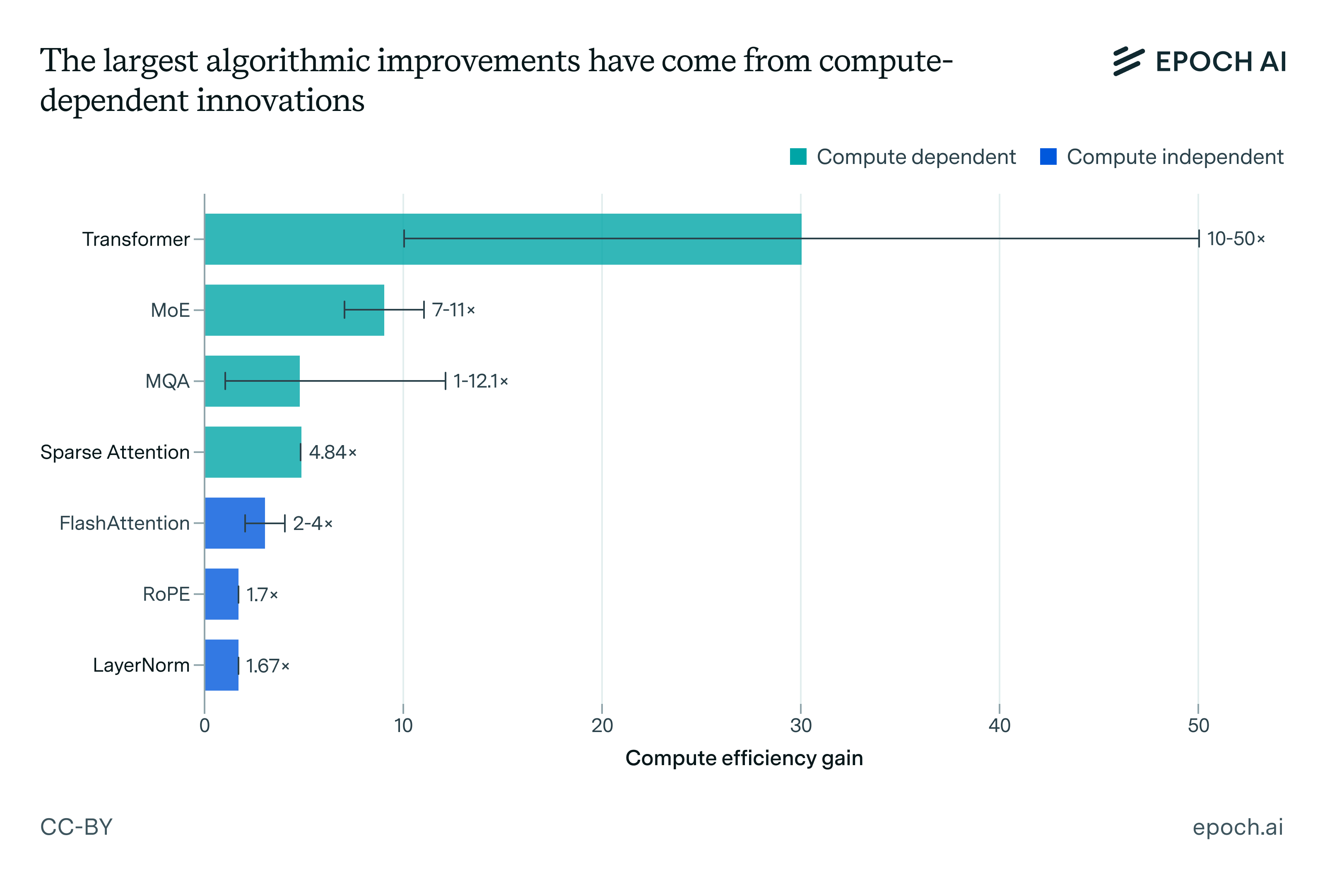
To put these numbers in context, Dario Amodei has noted that “every frontier AI company regularly discovers many of these compute-equivalent multipliers: frequently small ones (~1.2x), sometimes medium-sized ones (~2x), and every once in a while very large ones (~10x).”4
When we combined the compute-independent improvements (LayerNorm + RoPE + FlashAttention), we achieved an experimental CEG of about 3.5x, even on our small-scale model.
This improvement is far smaller than the documented returns from compute-dependent advances, which can deliver much larger improvements (10-50x or more) — but only for those with the compute budget to unlock them.
It’s also important to note that, while we’ve so far been using a nice clean binary between compute-dependent or independent, the reality is messier: the degree of compute-dependence varies.
Compare the modest gains from multi-query attention (1x for training) with the field-changing impact of the transformer architecture itself (10-50x at large scale). Even within compute-dependent innovations, some show near-linear scaling while others exhibit strongly super-linear improvements with scale, and compute-dependent improvements showed minimal benefit or actually hurt performance. This supports the hypothesis that some algorithmic advances only really shine when you scale them up.
Can Capabilities Advance With Frozen Compute? DeepSeek-V3
One real-world example that illustrates this dynamic is DeepSeek-V3, a recent frontier model from China. Despite facing export controls that limited their access to high-end chips, the final training run for 671B-parameter DeepSeek-v3 took just 2.788M H800 GPU hours. For comparison, the final training run for LLaMA 3.1-405B-Instruct5 used about 30.84M hours on more powerful H100 GPUs.
How did DeepSeek achieve such strong performance while being so compute-constrained?
Algorithmic improvements, including multi-headed latent attention, a mixture-of-experts architecture, and mixed-precision training. This suggests that even with hardware limitations, algorithmic improvements can still drive meaningful advances. Tellingly, the most impactful innovations DeepSeek used were compute-dependent — they work best at scale.
What This Means for AI Progress
Our findings paint a nuanced picture of algorithmic progress. While both compute-independent and compute-dependent innovations drive capabilities forward, they play distinct roles with significant implications for the future trajectory of AI.
Our literature review and analysis reinforce that the most transformative algorithmic shifts, like the transformer architecture itself, have been compute-dependent. These innovations often yield minimal or no benefit at smaller scales but unlock order-of-magnitude improvements (10-50x CEG or more) when sufficient compute is available, accounting for the vast majority — perhaps ~99% — of the cumulative CEG impact historically. Hardware and algorithms are complements: frontier compute doesn’t just enable larger models, it unlocks new algorithmic paradigms.
Simultaneously, algorithms like Layer Normalization, RoPE, and FlashAttention provide tangible benefits across scales. Our experiments showed a combined 3.5x CEG from these even on our small model. Meaningful progress can occur even with fixed hardware. Such advances lower the bar for achieving a certain capability level and can be discovered and validated with less compute, potentially accelerating progress in resource-constrained environments.
But they remain small peanuts compared to the capability gains from compute-dependent algorithms, whose dominance suggests that access to large-scale compute confers a significant research advantage. It lets organizations test and validate the very algorithms that provide the largest gains — algorithms that might look unpromising or even detrimental at smaller scales.
Tom Davidson challenges this,6 arguing that researchers might extrapolate from smaller experiments and noting that algorithmic progress hasn’t slowed despite fewer truly frontier-scale runs globally. This is a fair point, but I suspect it overlooks how much the definition of “small” has shifted for leading labs. Experiments on dozens or hundreds of H100s, while “small” relative to a full GPT-4 training run, represent vast compute resources compared to just a few years ago or what independent researchers can access. These “mid-scale” experiments likely provide enough signal — guided, as Davidson notes, by researcher taste and theoretical understanding — to identify promising compute-dependent innovations without needing constant frontier runs. Compute-rich labs maintain an edge not just through scale, but by efficiently exploring the algorithmic space at scales large enough to reveal compute-dependent effects.
The path to recursive self-improvement, then, seems likely to depend more on how easily AI systems can discover the compute-dependent advances that constitute the heavy tail — note that nearly all the compute-dependent advances we could find was the transformer and some of its derivatives.7 Compute-dependent advances are hard to find and non-trivial to verify, but give the biggest returns on performance. The pace of takeoff, then, depends on the relative difficulty and infrequency of discovering them.
If you take one thing from our work, then, let it be that shorter timelines depend not only on algorithmic advances in the abstract being easier to find, but on compute-dependent algorithmic advances being easier to find.
Hardware controls (like export restrictions) will slow progress by hindering the discovery and validation of major compute-dependent breakthroughs, like those DeepSeek-V3 relied on. They likely won’t halt progress entirely, though, as compute-independent improvements will continue to accrue. Furthermore, the existence of compute-independent paths makes defining compute thresholds for regulation increasingly difficult, since significant capability gains might occur below anticipated FLOP levels. The rise of test-time advances only complicates this.
Limitations
Before closing, we should emphasize limitations. Our experiments used a relatively small model (165M parameters), and classifications relied on combining these results with literature analysis rather than multi-scale empirical tests. We measured CEG via pretraining loss, not downstream capabilities.
We didn’t analyze inference-time techniques, like chain-of-thought, best-of-k sampling, retrieval augmentation, etc., which likely have unique scaling properties. Epoch’s analysis offers some CEG estimates here, though potentially dated.
By focusing on pre-training, we also excluded post-training/RL techniques like fine-tuning, RLHF, DPO, etc. These often use smaller models but significant experiment counts, which means their compute dynamics will differ substantially from pre-training.
We treated data as fixed. The interaction between algorithmic improvements and dataset quality/composition is vital, and papers like “Scaling Data-Constrained Language Models” may offer data to study this.
Future work should investigate these areas, test classifications across domains (vision, biology), and ideally, replicate findings at larger scales.
Conclusion
Algorithmic progress interacts significantly with compute scale. While compute-independent advances offer a path for progress even with hardware constraints, the largest historical gains have come from compute-dependent innovations requiring substantial scale to develop and validate. Understanding this distinction is crucial for designing effective governance and forecasting AI progress — based on our experiments, we expect that the rate of progress will depend on how easily labs can find and validate compute-dependent algorithmic advances.
-
That is, we assume that e.g. LLaMA 3.2 is pretrained on ~the same data mix as LLaMA 3.1 — or at least the difference between the two’s data is negligible when you compare them to, say, BERT’s pretraining data.

-
p7.
-
p9.
-
Thank you to David Owen for flagging this — Also, Amodei cites Epoch work in the next sentence: “Because the value of having a more intelligent system is so high, this shifting of the curve typically causes companies to spend more, not less, on training models: the gains in cost efficiency end up entirely devoted to training smarter models, limited only by the company’s financial resources.”
-
Which, in case it isn’t clear, has 405B non-embedding parameters.
-
Thanks to Anson Ho for bringing this to my attention!
-
For further discussion on the tradeoffs between using compute for experiments, using compute for training, and using compute to run inference, see Jack Wiseman and Duncan Clements’s piece in Inference Magazine here.
About the authors

Related work