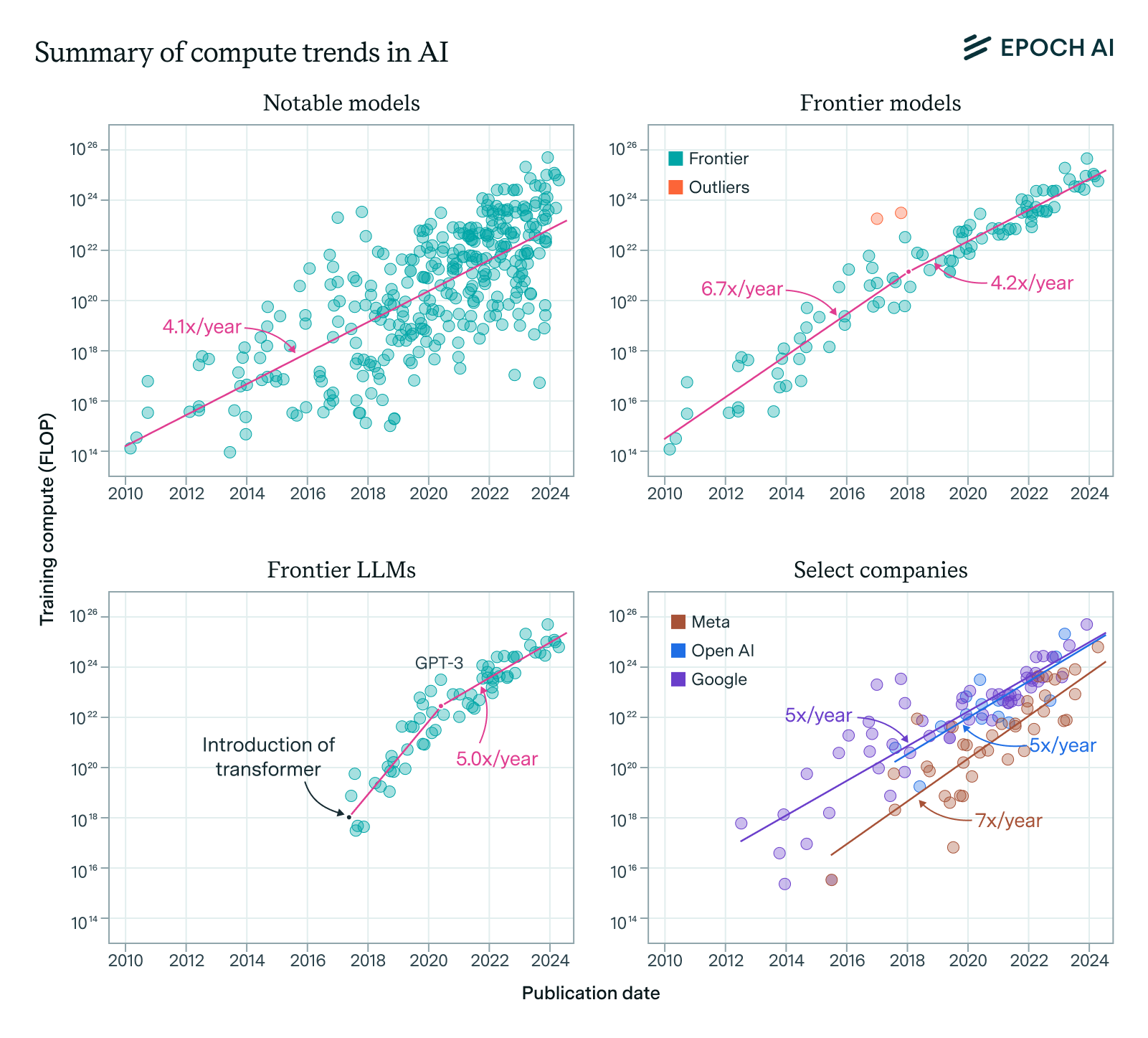
Reasoning models like OpenAI’s o3 are less than a year old, but they’ve already seen rapid improvements on capabilities, and OpenAI researchers are very optimistic that this progress will continue.1 But it’s not clear how much further the techniques used to train reasoning models can scale.
After looking into the question, I think there is room to scale reasoning training further, but it’s unlikely that OpenAI or other frontier AI developers can scale by many orders of magnitude.
If reasoning training continues to scale at 10× every few months, in line with the jump from o1 to o3, it will reach the frontier of total training compute before long, perhaps within a year. At that point, the scaling rate will slow and converge with the overall growth rate in training compute of ~4× per year. Progress in reasoning models may slow down after this point as well.
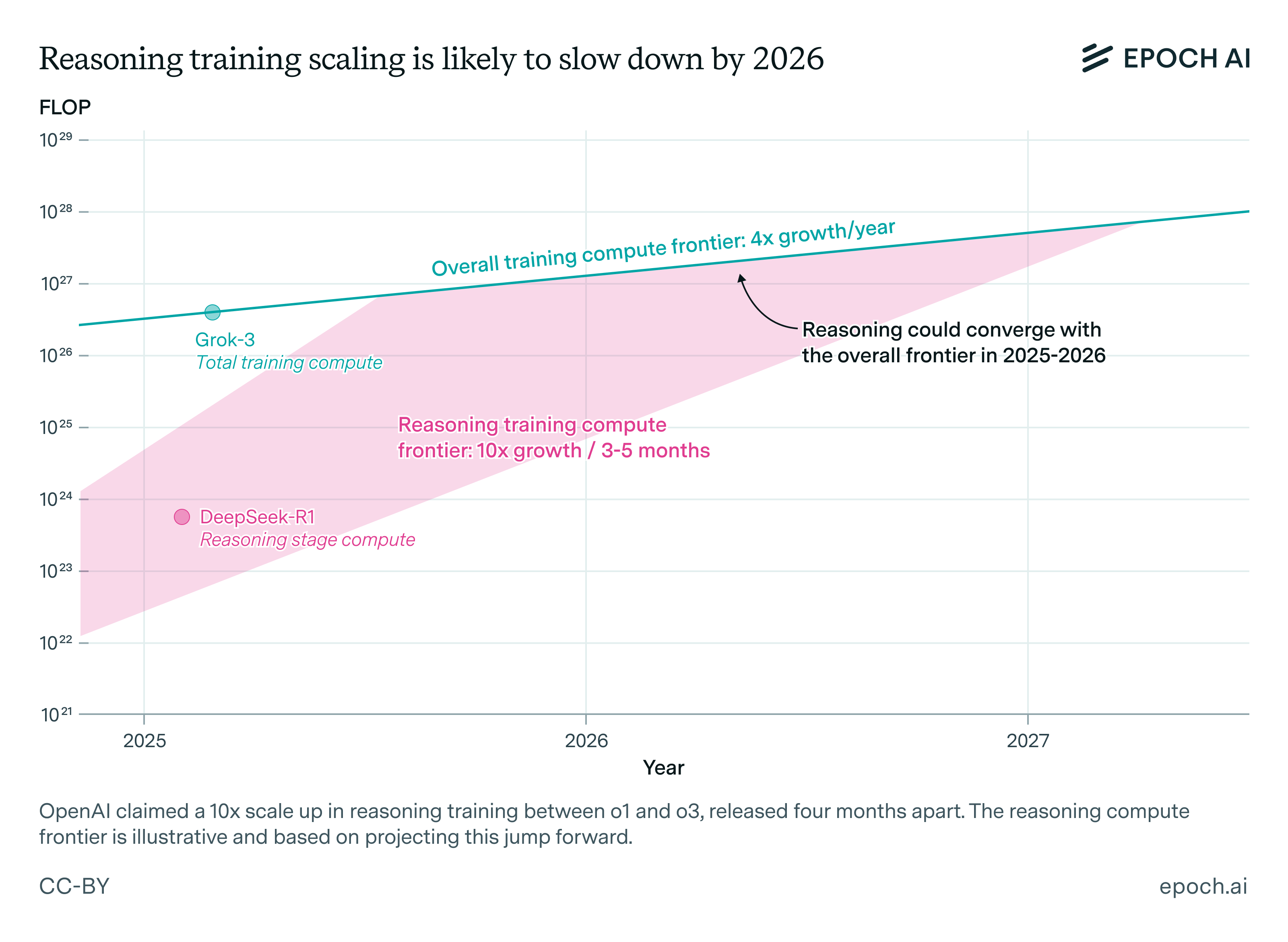
Figure 1: An illustration of a possible trajectory for reasoning compute growth, if scale-ups similar to the jump between o1 and o3 continue.
How much compute is used for frontier reasoning training?
OpenAI’s o3 and other reasoning models were developed from traditional LLMs that were trained on a huge volume of human data, in a process called “pre-training”. They then go through a reinforcement learning stage where they receive feedback on their solutions to difficult problems, which improves their reasoning abilities.2 This second stage is what I’m referring to as “reasoning training”.
Historically, the scaling of training compute has been a very important ingredient in AI progress. So it’s worth taking stock of how much compute is currently being used on reasoning training in particular, how far this can scale, and what this implies about how these models will improve.
Unfortunately, public information on the amount of reasoning training compute for reasoning models is sparse, despite their widespread adoption in the AI industry. Here’s what we do know:
- OpenAI has said that o3 is a 10× scale-up in training compute from o1, almost certainly referring to reasoning training compute. o3 was released just four months after o1.
- We don’t know o1’s reasoning training compute, but we have estimated the training compute of DeepSeek-R1, an arguably comparable model.
- We also have information about a few other reasoning models like Microsoft’s Phi-4-reasoning and Nvidia’s Llama-Nemotron.
- We have a potentially informative statement from Dario Amodei of Anthropic.
I’ll go through each of these in turn.
Scaling from o1 to o3
OpenAI has released this graph showing o3 and o1’s performances on the AIME benchmark, plotted against what is most likely the amount of compute used in reasoning training. It shows that the final version of o3 was trained on 10× as much compute as o1.
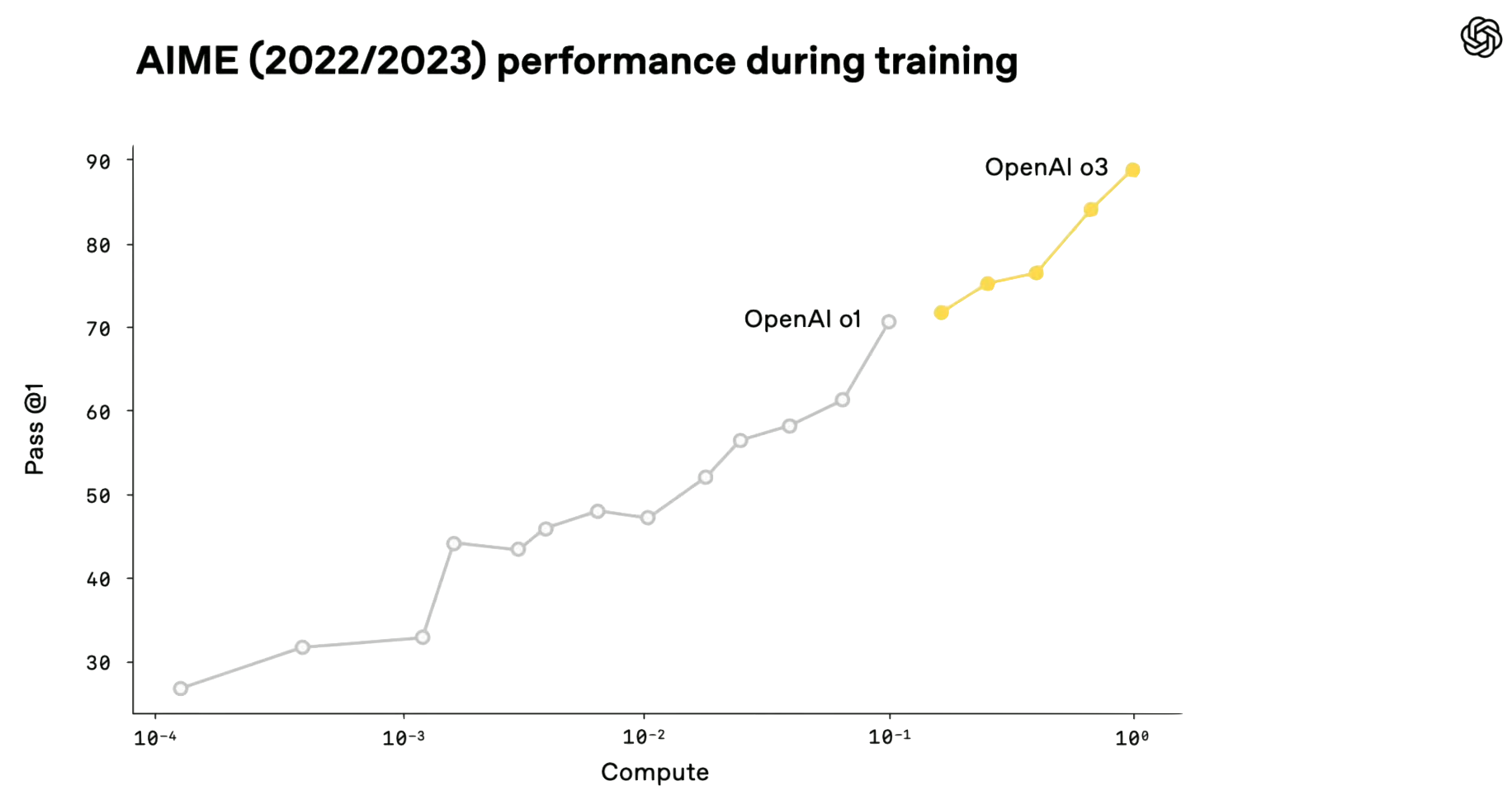
Figure 2. Taken from OpenAI’s o3 livestream announcement (18:45). The presenters did not verbally clarify any details beyond what is shown in the graph.
The x-axis likely shows reasoning training compute rather than total compute, because the first version of o1, with four orders of magnitude less compute than o3, scores around 25% on AIME, and this would be unlikely if the x-axis meant total compute.3 This chart also wouldn’t make much sense if the x-axis was total compute, because that would imply OpenAI trained many versions of o1 with highly incomplete pre-training stages.
If o3 was trained on 10× as much reasoning compute as o1, what does this imply about its absolute compute scale? We don’t have any hard information here, but we can look for clues from other reasoning models, and statements from AI industry insiders.
Insights from DeepSeek-R1
Most frontier AI developers have disclosed relatively little about how they train reasoning models. The main exception here is DeepSeek and its R1 reasoning model.
In a previous issue of this newsletter, Ege Erdil estimated that DeepSeek-R1 was trained on ~6e23 FLOP (costing ~$1 million) during RL reasoning training, requiring the generation of about 2 trillion tokens. This is about 20% of the cost of pre-training DeepSeek-R1’s base model, DeepSeek-V3.
Though there are many uncertainties in this estimate, it’s helpful because DeepSeek-R1 is a reasoning model with very similar benchmark scores as o1. So it could be reasonable to use it to set a baseline for our estimates of o1’s compute.
However, DeepSeek-R1’s reasoning compute scale could be different from o1’s for various reasons. Their respective parameter counts likely differ (though we don’t know by how much).4 And we don’t know how their reasoning training stages compare in terms of compute efficiency.5
Insights from other reasoning models
Two other reasoning models with training details are Nvidia’s Llama-Nemotron Ultra 253B and Microsoft’s Phi-4-reasoning.
- Llama-Nemotron Ultra’s RL reasoning stage took 140,000 H100-hours, or around 1e23 FLOP, <1% of the pre-training cost of the original base model.6
- Phi-4-reasoning had a much smaller reasoning stage, generating about ~460M tokens, costing under 1e20 FLOP, or <0.01% the compute cost of pre-training.7
Both have impressive benchmark scores, with Llama-Nemotron’s comparable to DeepSeek-R1 and o1.
However, these estimates might not be informative about reasoning models that advanced the frontier, like o1 or o3, because of synthetic data. The RL stages for Llama-Nemotron and Phi-4-reasoning were preceded by supervised fine-tuning, where they were trained on examples of high-quality reasoning chains, and much of this was synthetic data from other reasoning models.8
What can we conclude?
Overall, it’s unclear if these shed much light on o1 or o3’s training compute.
One takeaway is that reasoning training compute, at least for the reinforcement learning stage, can be relatively low for some models like Phi-4. This doesn’t mean o3 was trained on a similarly tiny amount of compute, but it does mean it’s hard to judge reasoning compute scale just from the fact that a reasoning model benchmarks well.
Also, old-fashioned supervised fine-tuning can play a major role in developing reasoning models, and this diversity of approaches makes it hard to guess the scale of reasoning training for models without disclosed training details. This also makes it ambiguous what should be counted as “reasoning compute” or “reasoning training.” Reinforcement learning training is probably the main driver of improvements at the frontier of reasoning models and so should be the focus, but I’m not too sure about this.
A final hint at the compute scale of existing reasoning models comes from an essay written by Anthropic CEO Dario Amodei in January 2025, following the release of o1 and DeepSeek-R1 and the announcement of o3 (emphasis mine):
Importantly, because this type of RL is new, we are still very early on the scaling curve: the amount being spent on the second, RL stage is small for all players. Spending $1M instead of $0.1M is enough to get huge gains. Companies are now working very quickly to scale up the second stage to hundreds of millions and billions, but it’s crucial to understand that we’re at a unique “crossover point” where there is a powerful new paradigm that is early on the scaling curve and therefore can make big gains quickly.
I’m not sure whether $0.1M or $1M reflect Amodei’s estimates of the training cost of any specific model like o1, o3, or DeepSeek-R1, or are just some general hypothetical. And Amodei’s beliefs about the compute scale of non-Anthropic models are presumably just guesses informed by Anthropic’s own data. But it’s clear that he thinks that the training cost for reasoning models to date is well below “hundreds of millions”, which would be >1e26 FLOP.9
Overall, these estimates and hints suggest that the reasoning compute scale of o1, and most likely o3 as well, are still below the scale of the largest training runs to date.
However, they are probably not many orders of magnitude behind the overall compute frontier, which is >1e26 FLOP, because we have two examples of models trained on over >1e23 FLOP during the reasoning stage (DeepSeek-R1 and Llama-Nemotron Ultra). o1 and especially o3 could have been trained on even more.
What does reasoning compute scale mean for AI progress?
The current compute scale of reasoning models has important implications for near-term AI progress. If the scale of reasoning training is still relatively low, we could see a rapid short-term scale-up in scaling, as well as actual capabilities.
We know that o3 is both a 10× compute scale-up from o1 and is substantially more capable than o1. This includes improved scores in standard math, science, and coding benchmarks. o3 is also much better than o1 at METR’s suite of agentic software and coding tasks.
While I’m not aware of any rigorous research on scaling laws for reasoning training, as there is for pre-training scaling laws, OpenAI has shown scaling curves that look fairly similar to classic log-linear scaling laws (see Figure 3 below and Figure 2 above). The second figure in the DeepSeek-R1 paper also shows accuracy increasing with reasoning training steps in a roughly log-linear way. This suggests that performance scales with reasoning training in a way similar to pre-training, at least for math and coding tasks. So we could see both dramatic and rapid improvements over the next few scale-ups.
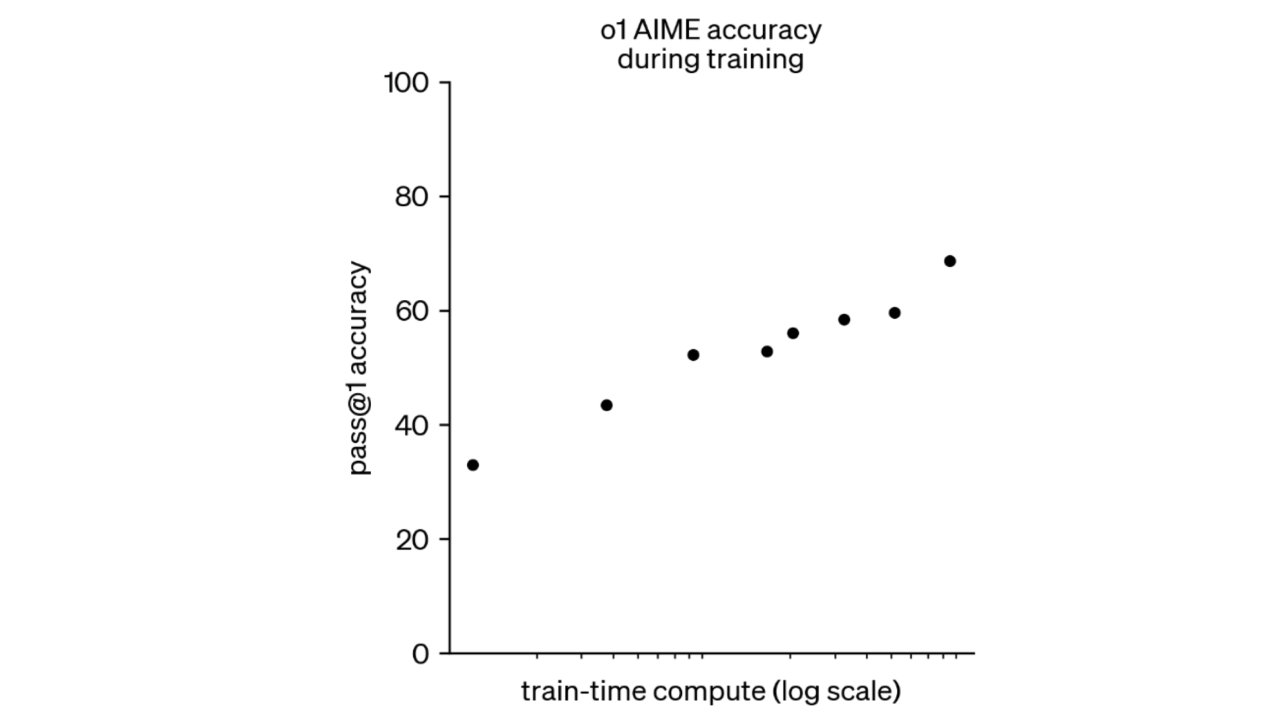
Figure 3. o1’s AIME performance vs training compute. Source: OpenAI
If reasoning compute reaches the scale of overall training compute, its growth rate will converge with the overall growth rate, which is currently around 4× per year, rather than 10× every few months (as with the o1 to o3 jump).
So if reasoning training is only a few (say, less than three) orders of magnitude below the overall frontier, this growth rate could slow down within a year or so.10
Can reasoning actually scale?
To be sure, scaling reasoning is not as simple as just allocating more GPUs. Scaling could stall due to data constraints. Reasoning training involves training models to answer difficult problems, but there isn’t an unlimited set of suitable problems out there, and it might be hard to find, write, or synthetically generate enough diverse problems to continue scaling.
It’s also highly uncertain how well reasoning training generalizes to fuzzier domains outside math and coding.11 And there could be other unforeseen problems.
A related issue is that the total compute cost of developing reasoning models might be far greater than the direct training cost of the main training run. This might be the case if AI labs have to do many parallel experiments to see which problems, reward models, and other techniques actually work.
So far, I’ve been trying to estimate the direct cost of reasoning training throughout this post, but we don’t actually know how OpenAI is measuring training compute for reasoning models. And we don’t have any information on research costs, even from the relatively transparent developers.
These costs will probably converge somewhat as the reasoning paradigm matures. And the cost of research doesn’t invalidate the relationship between direct compute scale and capabilities. But if there’s a persistent overhead cost required for research, reasoning models might not scale as far as expected.
On the flip side, reasoning models might continue improving quickly even after compute growth slows down. Maybe most of the progress in reasoning models to date has actually been caused by innovations in data or algorithms. But rapid compute scaling is potentially a very important ingredient in reasoning model progress, so it’s worth tracking this closely.
For what it’s worth, researchers at OpenAI (along with Dario Amodei, as noted above) are currently projecting confidence that they can rapidly scale up reasoning models and drive further improvements. Since these insiders have direct knowledge of the next iteration of reasoning models, I think it’s very likely that o3 isn’t at the ceiling in either scale or capabilities.
-
If we consider o1-preview the first reasoning model, though there are arguably precursors. o1-preview popularized the term “reasoning model” and was the first to show big gains in benchmark scores from the previous frontier.

-
Reasoning and non-reasoning models also go through other forms of post-training, such as RLHF, to shape their abilities and character.
-
AIME is a difficult math competition that frontier models struggled with until late 2024, so a model trained on that little compute in total would likely be inept at AIME, especially if it’s a checkpoint of a full-sized o1 model rather than smaller and more efficient model. See our benchmark results for OTIS Mock AIME, which is a test meant to emulate AIME.
-
o1 is probably bigger, since its inference costs are much higher. This would make reasoning training more expensive, holding token volume constant.
-
DeepSeek may have better training efficiency: they have less access to compute than OpenAI, which would push them to be more efficient. But OpenAI pioneered reasoning models and has reportedly worked on them since 2023, so OpenAI might be more efficient.
-
Nvidia says the RL reasoning stage took 140,000 H100-hours. H100s can do ~1e15 16-bit FLOP per second and 2e15 8-bit FLOP/s. Nvidia says that generation was done in FP8 and weight updates in BF16. If we use the 16-bit figure, and assume a 30% utilization rate (large-scale training tends to be 30-40% but utilization rates for RL reasoning could be different), 140k H100-hours would be 1.5e23 FLOP. Llama-Nemotron Ultra was originally developed from Llama 3.1 405B, which was trained on 4E25 FLOP.
-
Per the technical report, Phi-4 was trained over 90 RL steps, generating 8 trajectories for each of 64 problems per step. If the average response length is 10k tokens, this is only 90648*10000 = 460M tokens. Using the heuristic of 6 FLOP per parameter and token, this implies around 6 * 14b * 460m = 4e19 FLOP of RL compute. 10,000 tokens is the visual midpoint of the token length graph in Figure 7, but it’s unclear whether this is the actual average.
-
Llama-Nemotron was trained on data generated by DeepSeek-R1, and Phi-4-reasoning on data from o3-mini.
-
The amortized compute cost to train DeepSeek-V3 (3e24 FLOP) was around $6 million, using a typical cloud price of $2 per GPU-hour, so hundreds of millions of dollars would be a ~100x greater scale, or on the order of 1e26 FLOP.
-
This is illustrated in Figure 1. If the current frontier is somewhere near DeepSeek-R1, and continues to grow by 10x every 3-5 months, then reasoning training compute will probably converge with the overall frontier by 2026.
-
See Matthew Barnett’s previous GU issue and this blog post from Helen Toner for more discussion on this point.
About the authors
Related work