Perhaps the most significant AI development of the past year has been the rise of reasoning models—LLMs trained via reinforcement learning to solve complex problems, such as OpenAI’s o1, DeepSeek-R1, and Claude 3.7 Sonnet. These models have already demonstrated remarkable success, significantly enhancing AI capabilities in mathematical problem-solving, scientific reasoning, and coding.
In this article, I aim to present a clear conceptual framework for understanding the impacts reasoning models may have on the world. My core thesis is that the primary consequence of reasoning models will be the creation of AIs that are narrowly superhuman at “pure reasoning tasks”—abstract tasks with correct answers that can be cheaply verified. For example, I would guess that in the next three years, AIs will likely be developed that are capable of outperforming top human mathematicians at proving arbitrary mathematical theorems. At the same time, I predict that economically valuable AI capabilities will lag behind, with reliable computer-control agents arriving significantly later than high-quality reasoning models.
I also address some broader speculation about the downstream implications of reasoning models. For instance, one theory suggests that reasoning models have signaled the end of pre-training scaling, giving way to a new focus on dramatically scaling inference externally to serve end users—an approach that could fundamentally reshape the business model of frontier AI labs by decreasing economies of scale in model development. A separate, competing perspective suggests that because we can recursively train reasoning models on the reasoning traces of prior reasoning models, AI labs may race to exploit this feedback loop by spending the vast majority of their compute budget internally on inference to generate reasoning traces, rather than deploying much compute to serve users.
However, I depart significantly from both of these perspectives. While I think each picture has a grain of truth, I don’t currently anticipate that reasoning models will fundamentally disrupt the underlying trends in compute scaling, or unravel the existing business model of frontier AI labs. In my view, reasoning models should likely be interpreted as continuous with prior innovations, which generally did not massively shift the balance between internal compute used for model development and external compute used to serve users.
A brief primer on reasoning models
To understand the technical details behind reasoning models, I recommend reading the admirably transparent paper from DeepSeek outlining how they trained their R1 model. What follows is a brief summary of the primary ideas behind reasoning models, at a high level.
When training an LLM, there are two important stages. The first stage is pre-training, which involves training the model on a large and diverse corpus of curated data, providing it a broad base of knowledge. The second stage involves post-training, such as RLHF, intended to make the model useful to an end user. In both cases, scaling laws demonstrate that, with more computation applied to the model during training, we generally get higher performance out of the model.
Traditionally, when people have discussed scaling AI compute to obtain higher performance, they have tended to focus on these two stages of training, especially pre-training. However, the main idea behind reasoning models is that we can consider an additional pathway to scale compute to increase model performance. Specifically, at runtime, we can let a model think for longer to come up with the right solution to a problem. This could involve, in the simplest case, prompting a model to think step-by-step, showing an explicit chain of thought representing its reasoning process.
Unfortunately, LLMs with modest post-training enhancements—such as the original GPT-4—experience poor scaling behavior when simply asked to think longer. While their reasoning abilities can be improved with better prompting, prompt engineering alone exhibits sharply diminishing returns to reasoning quality for longer chains of thought. To improve the quality of model reasoning, AI labs have recently begun seeing strong success when applying reinforcement learning to model outputs across a wide range of reasoning tasks.
The basic idea is that we can apply policy gradient methods to improve model performance. This involves simply rewarding the model for getting correct answers on problems during an RL phase of training. At least in the case of R1, this occurs in a purely outcome-based framework, meaning that the model is only rewarded for getting the answer correct, rather than whether the model applied correct intermediate reasoning steps, or whether its reasoning trace was “on the right track”. Remarkably, despite the simplicity of this approach, it has led to emergent behavior in which models have learned to generate long chains of reasoning that predictably improve reasoning quality with greater reasoning depth.
Moreover, reasoning models provide a powerful method to create high-quality synthetic training data, since once a reasoning model is determined to have outputted a correct answer to a particular problem, its reasoning trace provides an effective example of how one can arrive at the right answer. This synthetic data can be used to improve not only future reasoning models, but also non-reasoning models. For example, Grok-3’s non-reasoning model performs well on the mathematics benchmark AIME’25, suggesting that it was trained on the outputs from reasoning models.
What I find most remarkable about reasoning models is how well this method has worked despite the relatively small amounts of compute that have so far been applied to the RL stage of the post-training process. In a previous Gradient Updates issue, Ege Erdil estimated that DeepSeek spent a total of only around $1 million on the RL phase of R1’s training. This contrasts with the tens of millions of dollars often spent by leading AI labs on pre-training individual foundation models. Since DeepSeek’s paper indicated strong improvements to reasoning with greater training compute during this phase—in line with traditional neural scaling laws—we should expect much better results soon as AI labs scale their RL budgets by another few orders of magnitude. This fact plays a role in Ege’s prediction that 2025 will see an acceleration in AI progress.
What I think reasoning models will be able to do
The most obvious update we should take away from the recent success of reasoning models is that reinforcement learning works well at improving the performance of LLMs. This is a critical discovery, since unlike the practice of pre-training models on existing human-generated data, reinforcement learning has much greater potential to raise model performance to superhuman levels.
Previously, it was already well-known that reinforcement learning was effective at training AIs to solve simple simulated environments, such as abstract strategy games like Go, or video games like Starcraft II. However, it was unclear whether the same success would extend to complex language tasks like mathematical reasoning. Unlike more traditional tasks where RL had been successfully applied, these tasks appear to require broad world knowledge and a degree of creativity beyond the use of memorized heuristics. Since LLMs possess both of these attributes, researchers had long suspected that applying RL to LLMs could be the key breakthrough enabling smarter-than-human reasoning abilities. Yet, until last year, attempts to enhance LLM reasoning with techniques like Monte Carlo Tree Search yielded only modest success. It wasn’t until more recently that AI labs began demonstrating that a pure RL approach can facilitate large improvements to AI reasoning abilities at current levels of compute.
In theory, reinforcement learning can be applied to any problem where performance can be directly measured and translated into a numerical signal that adjusts model parameters. However, in practice, obtaining feedback on a model’s capabilities is often expensive. For instance, training a model to control a robotic arm requires gathering data on whether the arm successfully completes specific tasks—such as placing a dish into a dishwasher or solving a Rubik’s cube. In these cases, a single attempt at performing the task can take several minutes, leading to very sparse reward signals. This scarcity in reward signals makes it difficult to train models effectively, since deep learning fundamentally depends on abundant, informative feedback.
Due to these practical limitations, RL is most effective for tasks where solutions can be verified at a low cost. Such tasks allow for dense reward signals, which facilitate efficient training. For example, the correctness of a mathematical proof can be verified automatically using a proof assistant. Since LLMs can generate potential proofs at scale and in parallel, mathematical proof generation is particularly well-suited for RL.
This reasoning leads me to conclude that we will see very impressive results in mathematical problem solving and proof generation in the next few years, as RL is scaled up aggressively to build better reasoning models. More concretely, I would personally guess that there is a roughly 3 in 5 chance that by the end of 2027, an AI will be capable of autonomously proving arbitrary mathematical theorems at a level that exceeds that of top human mathematicians. To make this prediction more precise, I am imagining that the AI could take an arbitrary mathematical statement, search for a proof or disproof of that statement, and identify a correct one within 30 days at a higher average rate of accuracy than what any individual human mathematician could have done in the same time frame.
While this may seem like a bold claim given the extraordinary talent of top human mathematicians, I see a strong parallel between the current trajectory of reasoning models and the years immediately prior to AlphaGo. In the years leading up to AlphaGo’s win over Lee Sedol, DeepMind made rapid advances in Go-playing AI by dramatically scaling up compute, surprising most forecasters at the time. Similarly, I expect a huge leap in AI mathematical reasoning performance in the coming years as compute used for reasoning-focused RL and runtime inference is likewise scaled up rapidly.
More broadly, I expect reasoning models in the near future will be most successfully applied to tasks that meet two key criteria: (1) LLM pre-training data contains a lot of information relevant to performing the task, allowing effective transfer learning, and (2) their solutions can be verified cheaply and programmatically—such as through unit tests or evaluation by another LLM that can reliably judge quality. I will refer to these as pure reasoning tasks, as they primarily involve performing structured reasoning without requiring difficult-to-obtain empirical feedback.
Examples of such tasks include standard programming challenges, like those on LeetCode, as well as potentially less well-defined tasks where high-quality outputs are easy to recognize. For instance, in analytic philosophy, Paul Grice’s argument in his 1975 paper Logic and Conversation is widely regarded as strong, despite not being strictly formal or verifiably correct. This suggests that reasoning models may be applicable to reasoning tasks where quality is evident, even if formal correctness cannot always be strictly defined. On this basis, I find it plausible that reasoning models could greatly improve the quality of legal writing, theory-oriented scientific research, and financial modeling.
What I suspect AI labs will struggle with in the near term
However, despite the many promising applications that reasoning models will soon be applied to, I also think a majority of economically valuable tasks likely fall outside the scope of pure reasoning tasks. In most jobs, the complete set of skills required for high performance neither exist in LLM pre-training data in a way that can be practically extracted, nor are they the type of behavior that can be cheaply verified for correctness. This is most obvious for physical tasks, which can help explain why progress in general-purpose robotics appears to be lagging behind advances in automating knowledge work. However, similar challenges apply to purely digital tasks.
Take video editing as an example. While instructions on how to operate a video editor are readily available online, the nuanced expertise needed to ensure that each keyframe meets human standards for quality is something that arguably does not exist in any legible format. Moreover, this skill is difficult for an AI to learn through trial and error because evaluating the quality of specific editing decisions requires expensive and infrequent feedback. Due to these constraints, I expect that progress in developing autonomous AI workers capable of reliably handling professional video editing work will lag significantly behind AI systems that can perform highly complex mathematical reasoning.
More generally, I suspect that most economically valuable tasks will follow a similar pattern: we will experience major difficulties in automating them for an extended period of time due to difficulties in collecting high-quality data directly tied to how the task can be performed.
As a result, even though I currently anticipate that we will soon have AI mathematicians that surpass top human mathematicians in many ways, at the same time, I expect AI labs will continue facing major challenges developing autonomous computer-control workers capable of fully substituting for human knowledge workers across the economy. Similarly, I expect reasoning models will not be capable of automating the entire AI R&D process end-to-end in the next few years, given that a significant fraction of tasks involved with AI research and development require empirical feedback, and do not appear to be pure reasoning tasks.
This scenario would highlight an almost paradoxical imbalance in AI capabilities: on one hand, AI systems would narrowly surpass the brightest humans on Earth in logical reasoning, structured argumentation, and computer programming—while on the other hand, they would still struggle with seemingly much easier tasks like reliably operating enterprise computer software through a GUI. Yet while such a situation may appear strange, it falls right in line with the pattern we have already observed in AI development: models have become extraordinarily proficient at tasks traditionally associated with intelligence—such as playing chess—while performing almost laughably poorly at tasks that humans find effortless, like using a fork or understanding what’s happening in a video.
Note that while the explanation I provided for this phenomenon has focused on data bottlenecks that prevent AIs from efficiently learning how to perform various tasks, this pattern can also be interpreted through the lens of Hans Moravec’s evolutionary argument, which was the topic of a previous Gradient Update issue.
Will reasoning models upset the business model of AI labs?
In addition to the direct impact reasoning models will have by automating pure reasoning tasks, some have speculated that these models will also reshape fundamental trends in AI development. Toby Ord, for instance, argued that the rise of reasoning models carries significant implications for AI governance.
One specific possibility he raises is that we might be nearing the end of rapid pre-training scaling. His reasoning is that pre-training methods may be approaching their limits, leading AI labs to prioritize scaling runtime compute—allowing models to think longer during inference—rather than scaling compute for training. Ord argues this shift could disrupt the existing business model of AI labs by reallocating compute toward external inference rather than internal development, potentially decreasing economies of scale. In his words:
The LLM business model has had a lot in common with software: big upfront development costs and then comparatively low marginal costs per additional customer. Having a marginal cost per extra user that is lower than the average cost per user encourages economies of scale where each company is incentivised to set low prices to acquire a lot of customers, which in turn tends to create an industry with only a handful of players. But if the next two orders of magnitude of compute scale-up go into inference-at-deployment instead of into pre-training, then this would change, upsetting the existing business model and perhaps allowing more room for smaller players in the industry.
On the other hand, Ord also highlights the opposite possibility: while reasoning models increase the utility of deploying AIs externally, they also enhance the utility of using inference compute internally because outputs from reasoning models can be reinvested recursively into training, enabling a feedback loop in which reasoning models generate synthetic data to train the next generation of reasoning models, and so on. To take advantage of this feedback effect, AI labs could spend the vast majority of their compute internally. This would include both internal inference compute used to generate reasoning traces, and training compute for models that learn from these traces.
However, I currently think neither of these outcomes is particularly likely. While I think that both perspectives have a grain of truth—for example, I expect labs to invest heavily in generating reasoning traces to improve future models—my claim here is more specifically about whether this innovation signals a fundamental shift in how labs prioritize compute between internal development and external deployment. My view is that reasoning models likely will not cause a major, persistent shift in this balance.
My reasoning is based on the idea that we have already observed several innovations in the past that are similar to reasoning models in relevant respects, and yet these developments did not dramatically restructure the optimal strategy for allocating compute resources between external inference and internal development. In the absence of strong empirical evidence one way or the other, my best guess is that reasoning models will follow this same pattern, and similarly not radically upset this balance.
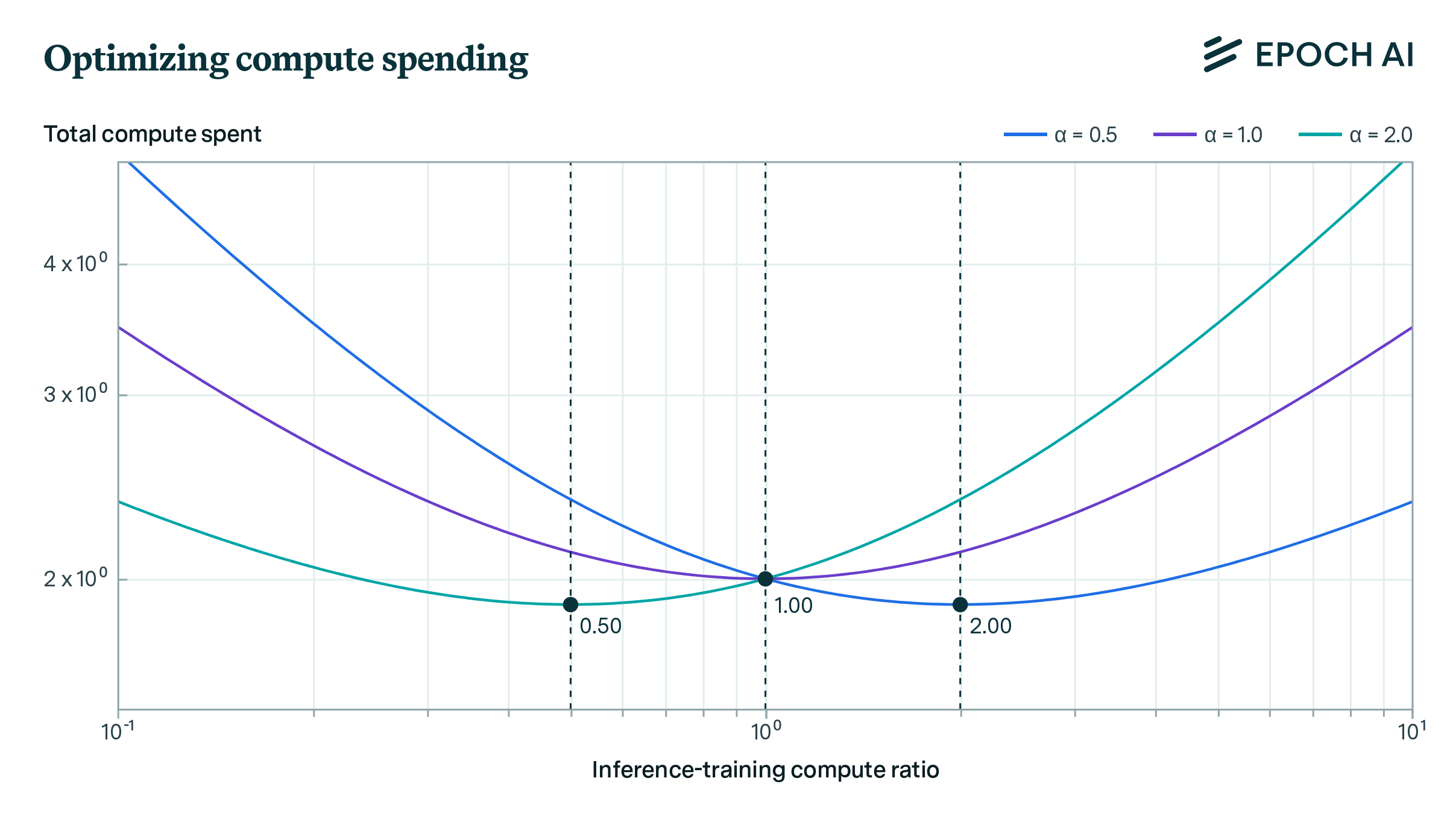
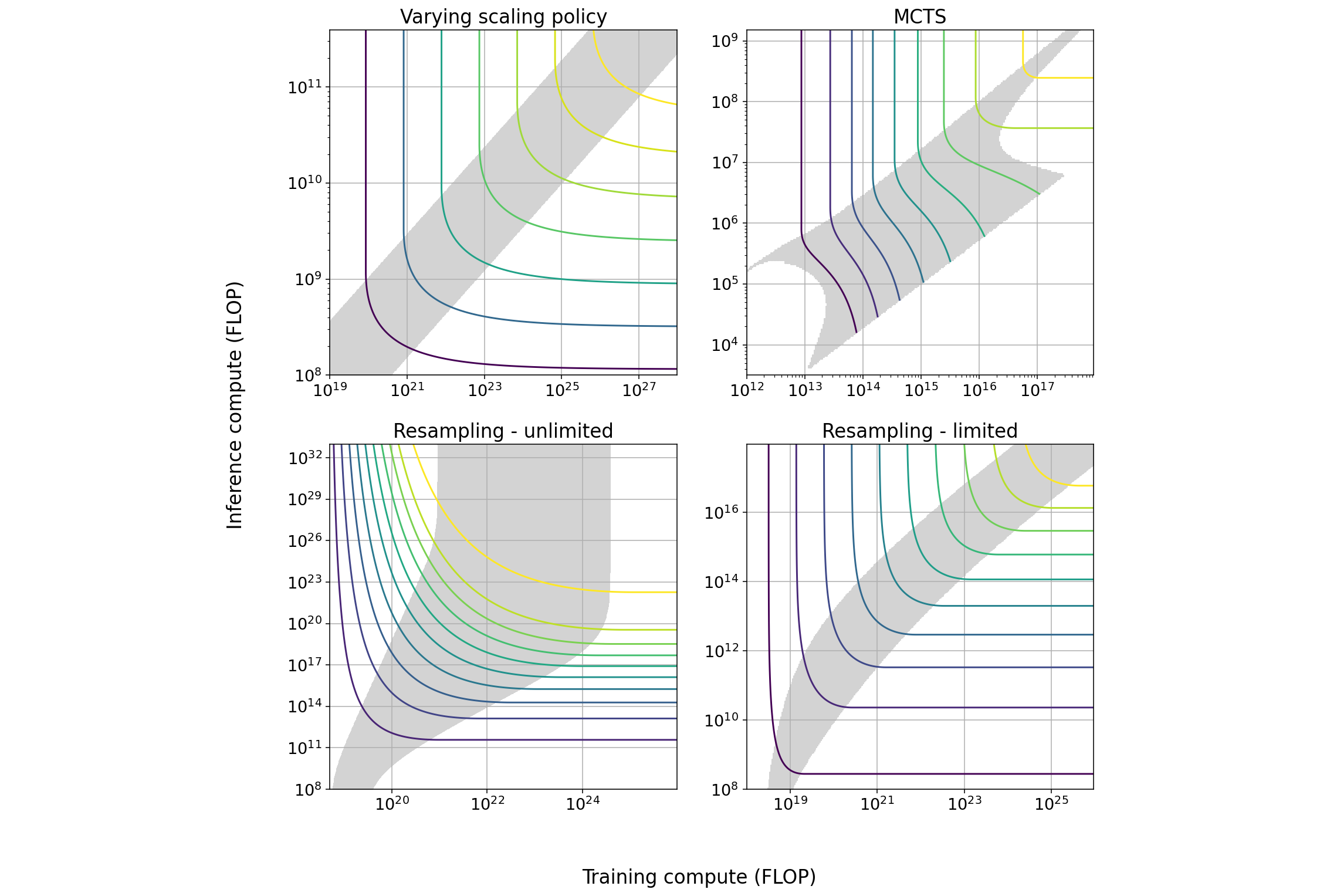
To understand this argument, it is important to first grasp the training-inference compute tradeoff, which refers to the possibility of trading inference compute for training compute or vice versa without significantly changing model performance. For example, scaling laws show how one can allocate more compute to training by training a smaller model on more data, achieving performance comparable to a larger model trained on less data. This reduces inference compute costs since smaller models are cheaper to deploy.
In 2023, my colleagues Pablo Villalobos and David Atkinson identified five methods to achieve this tradeoff, including varying scaling policies, Monte Carlo Tree Search, and model distillation. Last year, Ege Erdil noted that despite variations in techniques for achieving the inference-training tradeoff, empirical data across these methods suggests that AI labs should typically allocate compute between internal training and external inference such that these two expenditures remain roughly comparable in magnitude—with neither clearly dominating the other by a large margin.
These tradeoffs for other methods are broadly similar to what Toby Ord pointed out with reasoning models, both allowing one to trade compute used for external deployment with compute used for internal development, and vice versa. Without much information about how this tradeoff will play out in practice for reasoning models, it seems reasonable, based on prior experience, to expect a similarly balanced effect from reasoning models, with both internal compute and external compute balancing roughly equally. Importantly, this would leave the dominant business model of AI labs intact, wherein labs incur high upfront development costs to produce products that can ultimately be served to users at low marginal costs.
That said, data informing how reasoning models specifically should affect optimal compute allocation strategies is currently very limited. As mentioned previously, there are competing effects: reasoning models could drive more compute spent on external inference due to better performance with longer runtime thinking, while they could simultaneously incentivize more internal inference compute for generating synthetic training data. While I’m inclined to guess that these competing effects will roughly offset each other—based loosely on comparing reasoning models to prior innovations—this guess remains speculative, and I am open to revising this view as more information becomes available.
Conclusion
Reasoning models are poised to play a major role in AI over the coming years, given their potential to automate pure reasoning tasks. However, their importance should not be overstated. While we will likely soon see remarkable progress in mathematics, general reasoning, and computer programming, reasoning models are perhaps best understood as part of a broader, longer-term trend in which AI systems incrementally take on new tasks they were previously incapable of handling.
For years, algorithmic innovations have steadily expanded the range of tasks AIs can perform. While these advancements have made AIs more general, enabling greater task automation, none have, on their own, fundamentally upset the existing business model of AI labs or provided the final building block needed to automate all essential economic tasks. In my view, additional breakthroughs in multimodality, autonomy, long-term memory, and robotics are still required before AI can fully unlock its potential to automate all valuable work in the economy.
As a final point, I expect there will be more developments in the future that will unlock interesting new pathways for scaling our inference compute, similar to the opportunities unlocked by reasoning models. For example, I predict that future models will be trained to perform effectively in multi-agent settings, where multiple AI systems collaborate in parallel. This would introduce a new avenue for scaling inference compute, analogous to how human organizations scale up by increasing their headcount.
If we want to anticipate the next big paradigm shift in inference scaling, it might be useful to think carefully about ways in which humans routinely scale up their cognitive resources to be more productive, and then consider how we will eventually design AIs to take advantage of these possibilities just as humans do.
About the authors

Related work