
Introduction
The question of when and how AI might automate AI R&D is crucial for AI forecasting—if AI could automate the tasks involved in AI research, it could drastically accelerate AI progress. There is a long history of researchers considering this question in the abstract, and describing its importance for how AI will shape the future.1 However, AI researchers disagree substantially on timelines for automating AI R&D—for instance, researchers’ predictions for when all AI researcher tasks will be automated vary between years and centuries.2
In this work, we interviewed AI researchers with three goals:
- Characterize AI R&D work tasks in detail, to better understand how automation might take place.
- Clarify the reasoning underpinning researchers’ predictions about automation, to see where and why they disagree.
- Collect their views on evaluations intended to measure how capable AI systems are at performing AI R&D, to better understand how society can track AI progress in this critical area.
To do this, we used qualitative interviews. We asked open-ended questions to eight AI researchers across industry, nonprofit and academic labs who have either published at leading conferences, or had similar experience. We identified recurring themes in their answers, and then summarized these, providing example quotations from participants where relevant.
Participants’ predictions for automation differed greatly, similar to pre-existing survey findings. However, all participants agreed engineering tasks will be the main driver of R&D automation in the next five years. If participants are correct, the question is when engineering tasks will be automated, rather than which tasks are relevant. If AI could solve existing AI R&D evaluations, focused on engineering tasks, most participants believed this would significantly accelerate their work.
Summary of findings
-
Creating hypotheses and planning research are vital for AI R&D, but researchers’ descriptions suggest they occupy relatively little time within a project. Meanwhile, engineering tasks such as coding and debugging are similarly important, but more time-consuming. Engineering tasks are central to participants’ work, even as they become more senior and take on more planning and management responsibilities.
-
Predictions differ greatly for automation pace, but share a focus on engineering tasks as the driver of R&D automation in the near term. Differences in predictions for automation arise mostly from differences in timelines for when engineering tasks will be automated, rather than differing beliefs about which tasks are relevant.
-
Existing R&D AI evaluations, focused on engineering, are a promising starting point. Participants gave feedback on example R&D evaluations about implementing ML experiments and debugging. 6/8 participants predicted that if AI could autonomously solve these, a substantial fraction of researcher work hours would be automated. Researchers offered several suggestions to ensure evaluations would be realistic, including more challenging open-ended tasks and finegrained assessment of AI agent reliability.
Key results
Hypotheses are fast, implementation is time-consuming; both are crucial
Participants’ descriptions of their work are similar to AI R&D workflows posited in the evaluations literature: a feedback loop of hypothesis, experiments, and results. We show this in Figure 1. All participants offered concrete examples within each high-level task, ranging across a wide array of AI research areas including architecture design, dataset curation, and CUDA optimization.
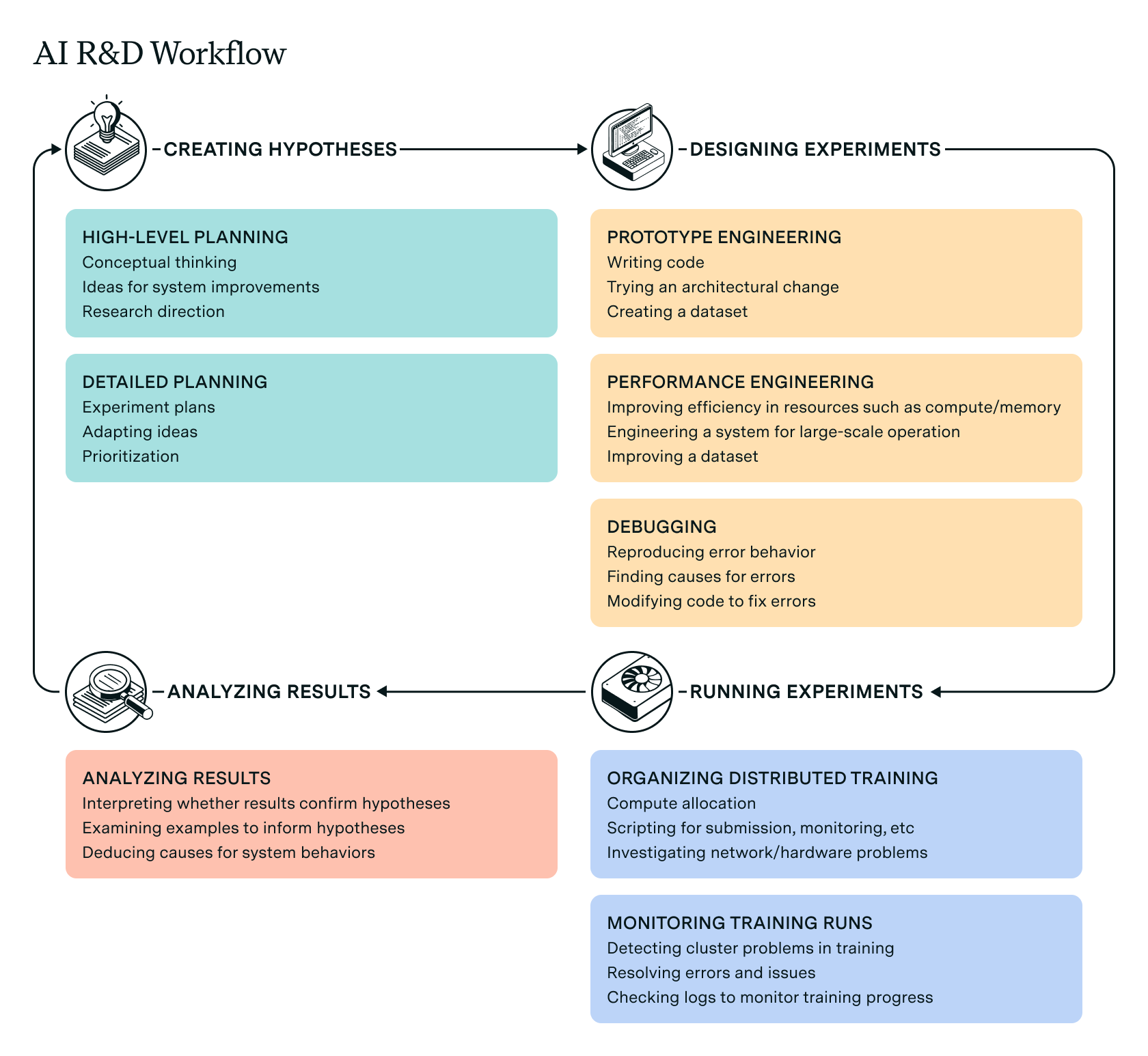
Figure 1: The AI R&D workflow based on participants’ descriptions, expanding on pre-existing descriptions in the evaluation literature. Participants offered examples for each subtask.
Six participants emphasized the importance of planning and hypothesis creation within a project. It is unclear how to specify the time these take, due to their overlap with designing experiments, studying other work, etc. Nevertheless, participants’ descriptions suggest these are quick, compared to the work of implementing their ideas. All participants noted the importance of engineering and debugging, and how time-consuming these can be. This was a core part of participants’ work in all cases, even as they became more senior and took on more responsibilities for research planning and management.
One participant’s description of the AI R&D workflow: “Research goes in cycles where I will spend a bunch of time trying to figure out what I think the important problem is, what I want to work on, and where I think I have some headroom to make some progress. Then I will go and start to think about what it actually is that I want to do to make progress on that area, and that itself looks like a slightly different thing. And then there’s sort of raw execution work…”
Predictions differ on automation pace, but agree that engineering will be the main driver of R&D automation
Predictions for automation of AI R&D differed substantially on pace and extent, but all participants focused their responses on software engineering tasks such as implementation and debugging. Essentially, all participants predicted that automation of engineering tasks would be sufficient to substantially accelerate AI R&D, but they had differing predictions on what level of engineering capabilities would be sufficient. Other tasks, such as data generation or curation, were highlighted as promising automation targets by two participants, but received less dedicated discussion in predictions.
Table 1 shows participants’ predictions for automation of their work over the next five years. Two participants had extremely optimistic timelines for automation, predicting significant automation of R&D engineering over the next five years. These participants predicted that, in five years, AI agents would autonomously implement code and experiments from natural language descriptions provided by researchers. Their later descriptions of time usage suggested this could automate half or more of their current work. These predictions describe meaningful AI self-improvement, through automating ML experiments similar to those of today. At the more pessimistic end, two participants predicted that AI coding assistants and similar tools would continue to improve, but with a modest effect on AI R&D. One participant described a 20-50% productivity improvement in their work as an extremely optimistic upper bound. The remaining four participants fell broadly between these extremes, predicting that AI assistants would improve, and be helpful, but with little potential to fully automate their tasks.
| Outlook | Quote |
|---|---|
Pessimistic AI assistance might be useful for easier software engineering, but not much for R&D. | P1: “I don’t see effort being applied as much in terms of how do we get AI to lift the simplest truth out of all of the dirty mess that the data provides […] next token prediction seems a far cry away from that behavior and I think that’s the behavior that would really unlock both research abilities for AI, for self-improvement, as well as mathematical abilities, and top-notch software engineering, and all sorts of other things.” |
Somewhat optimistic AI assistance will keep improving, and this will be helpful for AI R&D, but few tasks will be fully automated. | P4: “Coding is definitely something that people are working on right now, and they are making significant progress. This is something that is a very big part of people’s lives, and it’s taking up all the time from people. So if coding is accelerated… I think it’s mainly about acceleration of the code.” |
Extremely optimistic AI assistance progresses to full automation of significantly many tasks. | P7: “Humans will just be talking in natural language to this huge model, and the model would both manage the code base and run the experiments, and basically it might also manage the upcoming training run.” |
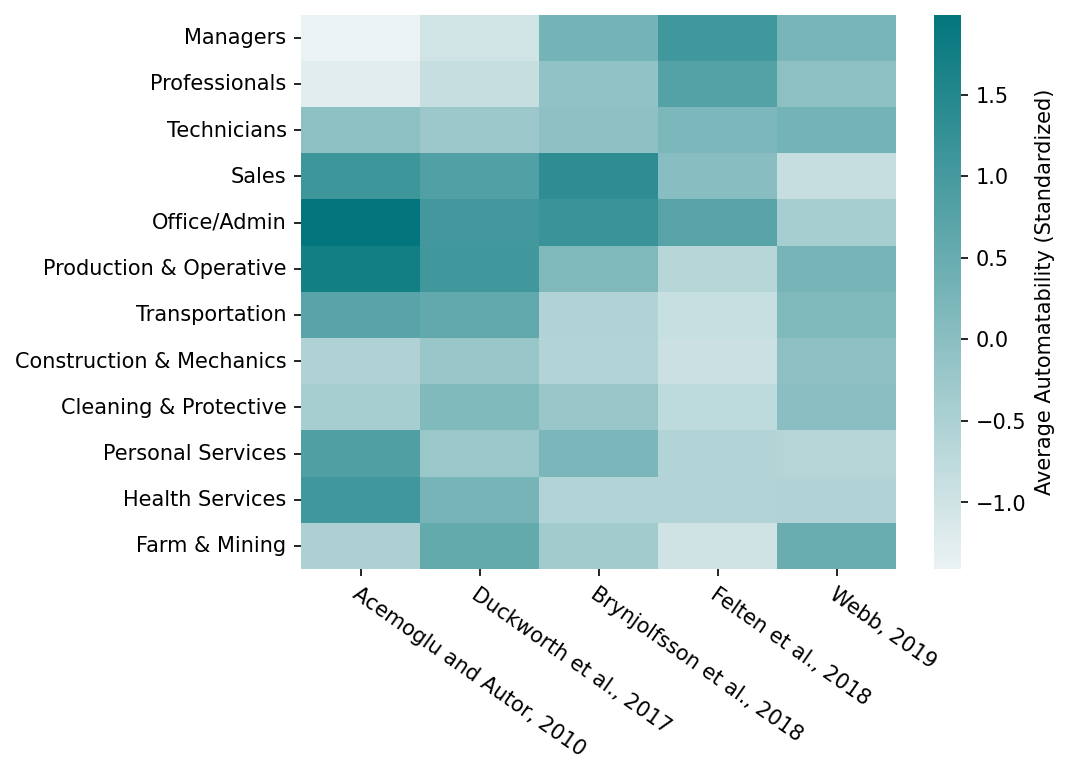
Participants identified several challenges that AI systems must improve upon before they can automate AI R&D work: reliability, open-ended planning, long-context reasoning, deep reasoning, and novelty. Several other factors might prevent automation in practice, such as researchers needing to be closely familiar with implementation details, or high compute requirements for running agents, particularly if they run their own ML experiments. A summary of these AI limitations, with example descriptions from researchers, is provided in Table 2. These limitations have some similarity to pre-existing research on automatability, which rated work tasks across the economy according to suitability for ML systems. However, the limitations identified in this work are specifically about AI R&D work tasks, and derived from researchers’ descriptions rather than predefined.
| Challenge | Description |
|---|---|
Reliability | P5: “You ask it to implement this method from this paper and test it out and report back, but then if it fails by producing code that doesn’t compile, and then returns that it failed this task, are you willing to assume that architecture doesn’t work, or do you think that it’s just the agent made a mistake?” |
Open-ended planning | P6, offering an open-ended example: “Our model is only at 75% on this score. That’s not acceptable, we need to get up to 80%. I’m going to leave it to you [the agent] to figure out how to do that. [Tasks like this] will be much more common in the world and also harder to automate.” |
Long-context reasoning | P2: “We’re seeing a lot of marketing about, ‘Hey our context window is three million, ten million tokens, just throw your entire code repository in and now we can implement functions, you can effectively do updates on an entire repository.’ But my counter-argument to that would be that I think that the ability to process a larger context length is orthogonal to your ability to actually use that context.” |
Deep reasoning | P1, describing the design of CUDA code: “What is the abstraction that both captures most of what I want to do with deep learning while also respecting what the hardware is looking for? […] That’s something I think we’re pretty far away from, in both context ingestion but also just reasoning. There’s a bunch of reasoning that you need to do to make that work and in GPT-4 the reasoning seems a little bit too shallow.” |
Novelty | P6, describing how AI R&D involves novel methods that wouldn’t work at smaller scales: “Most things an AI has done, some human has done […] for the frontier tasks, figuring out how to make things run at extremely large scales or coming up with new training methods for AI, they haven’t ever worked on small models, but now work.” |
Existing R&D evaluations may be a promising start
We provided the participants with several example tasks from AI R&D evaluations that are currently under development, covering experiment implementation and debugging, and asked about the implications if AI systems were able to solve these tasks. Six participants predicted that AI systems that can pass these evaluations would be capable of significantly automating AI R&D. Table 3 provides further detail on evaluations, participant predictions, and reasoning. Example descriptions suggested that agents capable of performing these tasks might automate half of current researcher work hours.
| Well-defined experiments | Debugging errors | |
|---|---|---|
Evaluation | Replace attention with sparse attention in a provided model codebase and set of pretrained weights. Finetune and evaluate performance. | Debug a provided ML codebase with a CUDA stream concurrency error. |
How much AI R&D automation (optimistic) | P4: “60% of my time would be automated if there was a model that is doing that” | P3: “If everything after the time it doesn’t work counts as debugging then it’s probably like 70% [of time spent coding].” |
Why this might have significant impact | P4: “Some of my project was specifically on that, basically implementing different kinds of attention […] I spent at least a month doing different variants of sparse attention.” | P5: “Sometimes [errors] are very difficult to reproduce or don’t always appear, and those are definitely very tricky to find […] but I don’t think those need to be automatically solved for it to be helpful.” |
How much AI R&D automation (pessimistic) | P8: “hours or days in a multi-month project” | P8: “If none of your code’s throwing an error anywhere […] that is much harder to debug but I think would be infinitely more useful, in that case.” |
Why this might not have significant impact | P8: “That particular bit of implementation is not that complicated, not that complex.” | P8: “There’s no explicit CUDA bug, but I’m getting the wrong results and I can see mathematically they’re wrong results, and that’s very hard to debug.” |
A caveat to this finding, emphasized by one participant, is that the overall effect of automation could vary greatly across different individual instances of these research tasks. Hence, the overall impact might be different than an estimate of researcher work hours suggests. Two participants were simply skeptical of the evaluations, objecting that their work relies on more open-ended, challenging tasks. They predicted that AI capable of passing these evaluations, but not more challenging tasks, would have little value for automating AI R&D.
Suggestions for improving evaluations came in two forms: suggestions for other tasks, including more difficult, open-ended tasks; and suggestions for evaluations to operate differently. For example, five participants stated they would prefer evaluations to be based on partial automation, rather than autonomously completing tasks end-to-end. Similarly, two participants stressed that full automation of tasks would likely require high reliability, and evaluations would need to assess this in depth. We discuss these suggestions further in the full report.
Discussion
Our interviews, covering participants’ descriptions of their work and predictions about automation, illustrate how researchers think about automatability in AI R&D. Our work unearths points of agreement, even among researchers with differing predictions about short-term automation. Most researchers predict that AI agents capable of implementing well-defined experiments and debugging errors would significantly accelerate their work. Their disagreements are primarily about when such agents might become feasible, and whether partial automation will have a significant impact in the meantime.
Evaluation design is a closely related problem. To what extent should evaluations focus on full automation, as opposed to assistive AI tools? Our findings paint a mixed picture. Most participants predicted there would be significant impact if AI could automate example tasks such as implementing sparse attention or debugging CUDA errors. However, 6/8 participants were skeptical that AI would achieve this level of capabilities in the near future. This suggests that evaluations focused on full automation might be most useful for detecting an extreme outcome: rapid and substantial automation of AI R&D. Our work offers several suggestions for evaluation design, based on firsthand suggestions from AI researchers. We hope these suggestions may be useful for designing evaluations across a range of tasks and difficulties. Such evaluations, already being developed by leading labs and governmental institutions, have the potential to track AI progress in this critical area.
For more details, check out our full report.
Acknowledgements: This work was funded by the UK AI Safety Institute to build the evidence base on AI’s contribution to AI research and development.
-
Alan Turing, in 1951, predicted “[…] it seems probable that once the machine thinking method had started […] they would be able to converse with each other to sharpen their wits”.

-
The AI Impacts 2024 survey asked several questions relevant to AI R&D automation, such as predicting the year for automating the job of an AI Researcher, all human tasks, or all human jobs.
About the authors
Related work