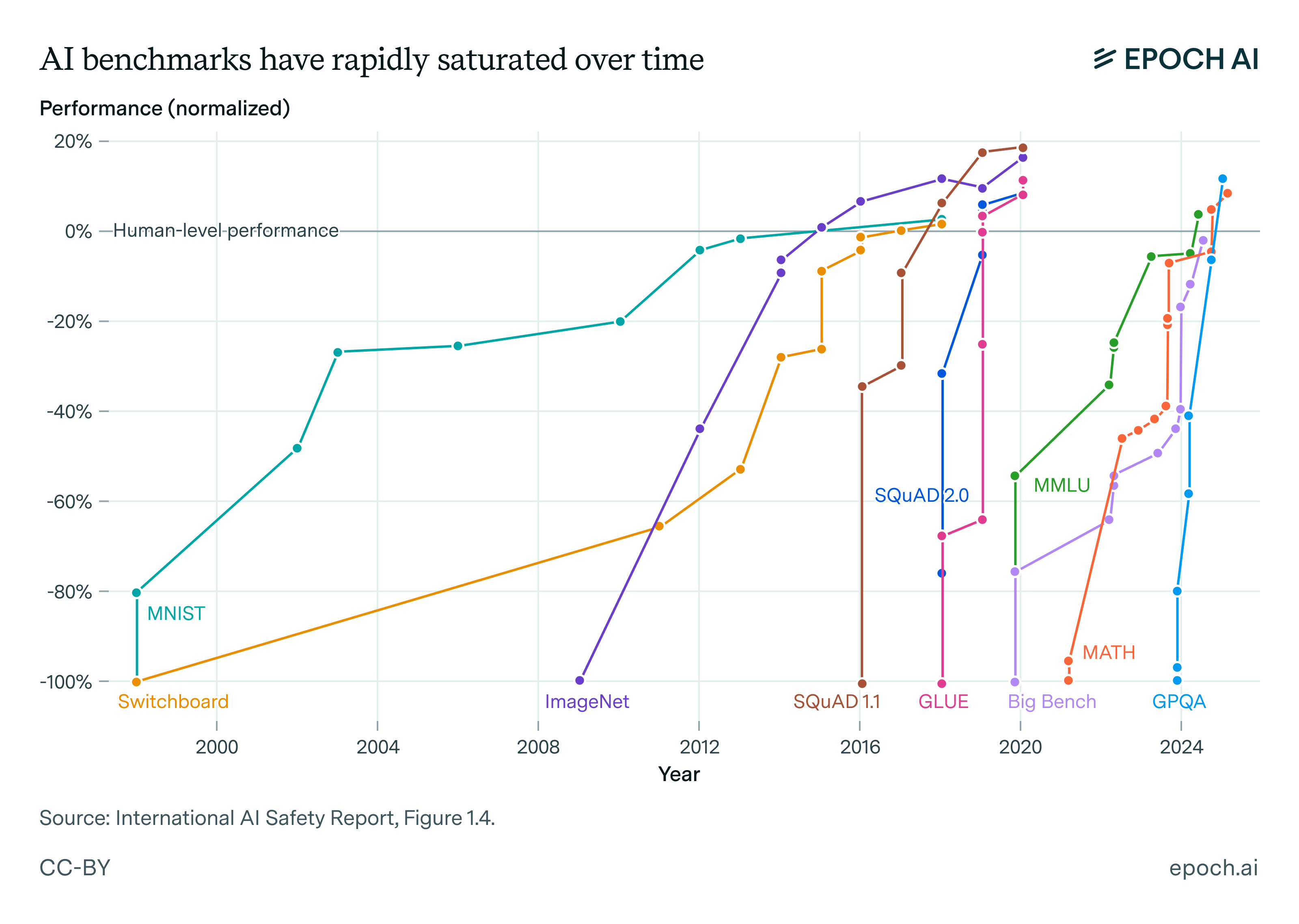
Figure 1: This graph demonstrates rapid AI progress across key benchmarks, which have been useful indicators for driving capabilities forward. However, for most of this period, benchmark realism was not a priority. This explains why high benchmark scores often provide limited insight into AI systems’ real-world impact.
Back in the prehistoric days of March 2023, OpenAI released GPT-4, and its benchmark results raised a lot of questions and speculation about the future of the legal profession.
In response to these concerns, Naryanan and Kapoor wrote a blog post pointing out that this is an instance of a more general problem, where AI benchmarks fail to reflect the complexities of the real world. And if benchmarks fail at this, it can lead to misleading conclusions about the current and future impacts of AI systems.
This is undoubtedly true, but it seems to only give a partial answer, because it doesn’t tell us why existing benchmarks don’t capture the complexities of the real world. For example, surely people who design AI benchmarks know that real-world tasks aren’t the same as solving multiple-choice questions! So why do they build multiple-choice question benchmarks anyway?
We think that the core reason for this is that people rarely had the goal of measuring the real-world impacts of AI systems, which would require substantial resources to capture the complexities of real-world tasks. Instead, benchmarks have largely been optimized for other purposes, like comparing the relative capabilities of models on tasks that are “just within reach”.
We can see this just by looking at the most popular benchmarks over time:
- Before 2017, benchmarks commonly involved straightforward, short-form tasks such as image classification (e.g., ImageNet, CIFAR-100) and sentiment analysis.
- From around 2018, benchmarks shifted toward multiple-choice question-answering and simple open-ended text generation tasks, spanning various domains like coding and mathematics (e.g., CommonSenseQA, MMLU).
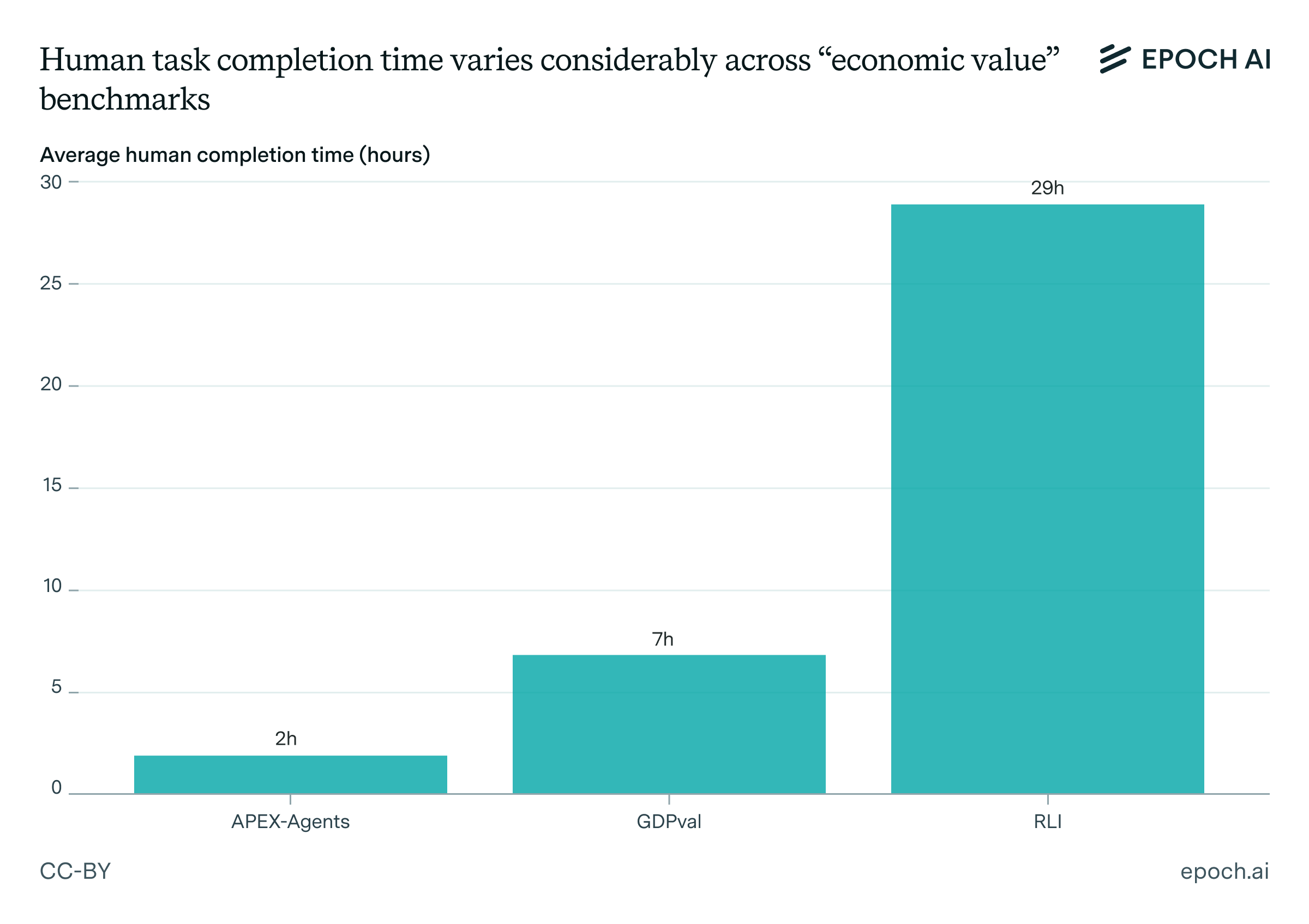
- Only in the past couple of years have we begun to see benchmarks designed to evaluate AI systems on more realistic scenarios (e.g., SWE-Bench, RE-Bench). However, even these recent benchmarks typically involve shorter tasks rather than tasks that accurately represent complex, real-world economic activities.
Importantly, these shifts in benchmark design have closely mirrored the evolving capabilities of AI systems themselves. This suggests that people primarily focused on building benchmarks that were “just about within reach” of contemporary AI capabilities.
But why have researchers focused on tasks that are “just within reach”? One practical reason is that benchmarks have largely been constructed to provide effective training signals for improving AI models – tasks that are too easy or too hard don’t generate useful feedback. And if all you care about is whether one model outperforms another, you don’t need realistic tasks – just benchmarks for which differences in score correlate with differences in a broader range of capabilities.
A suggestive piece of evidence comes from the 2023 benchmark SWE-Bench, which contains actual GitHub issues, and evaluates coding abilities. When it was first released, it was viewed by some people as overly challenging. But once SWE-agent was released and achieved over 10% on the benchmark, further performance improvements followed swiftly.
Relatedly, another part of the story may be that researchers underestimated the rate of AI progress. For instance, researchers working on autoregressive language models in 2016 tended not to think of AI systems as performing “economically useful tasks”, thinking of these systems as insufficiently capable of doing so. As such, benchmarks may have been deliberately designed to be relatively cheap proxies for real-world tasks, and also relatively simple.
Even in cases where researchers didn’t underestimate the pace of AI progress or explicitly focus on providing training signals, researchers have frequently optimized for things besides realism. Many evaluations comprise tasks that are challenging for humans, such as playing Go or solving multiple-choice science questions, making it especially impressive when AI systems are able to solve them. But as Naryanan and Kapoor point out, what’s challenging for humans may not correlate with what’s challenging for AIs, further complicating the relationship between benchmark scores and real-world impacts.
Note that we don’t think the primary reason for the lack of benchmark realism was practical or fundamental limitations. While it can be challenging to build benchmarks to capture the complexities of the real world, it doesn’t seem like this was a binding constraint in historical benchmarks.
For instance, one popular benchmark in 2021 was HumanEval, which contains short and self-contained problems that can be solved with a few lines of code – hardly representative of real world programming. If the authors had instead focused on realism, they could instead have built something like SWE-Bench. The only issue would be that SWE-Bench tasks would’ve been “out of reach” for the best models at the time.1 Realism wasn’t a bottleneck – it simply wasn’t the priority, which suggests we shouldn’t be too pessimistic about the realism of future benchmarks.
Of course, this isn’t to say that both current and future benchmarks can easily be made to capture real-world impacts. On the contrary, recent attempts at building realistic benchmarks have run into a litany of practical and fundamental problems. For example, the machine learning task environments included in RE-Bench often had to be simplified to make sure it’s easy to verify model performance. This makes the task environments lose some of the complexities of actual machine learning research, which may be riddled with slow feedback loops and unclear task instructions.
So what does this mean for the future of AI benchmarks? We think this is determined by a clash between two forces. As AI systems become increasingly capable and are used in more sectors of the economy, researchers have stronger incentives to build benchmarks that capture these kinds of real-world economic impacts. On the other hand, designing such realistic benchmarks faces growing practical and fundamental challenges.
In our view, it remains an open question which of these two forces will win out, and we’ll explore this question more in future posts. Resolving this tension isn’t just an academic question – it has crucial implications for our understanding of AI progress, and preparing for the future impacts of AI.
-
For example, GPT-3 would likely have attained 0% on the benchmark.

About the authors
Related work