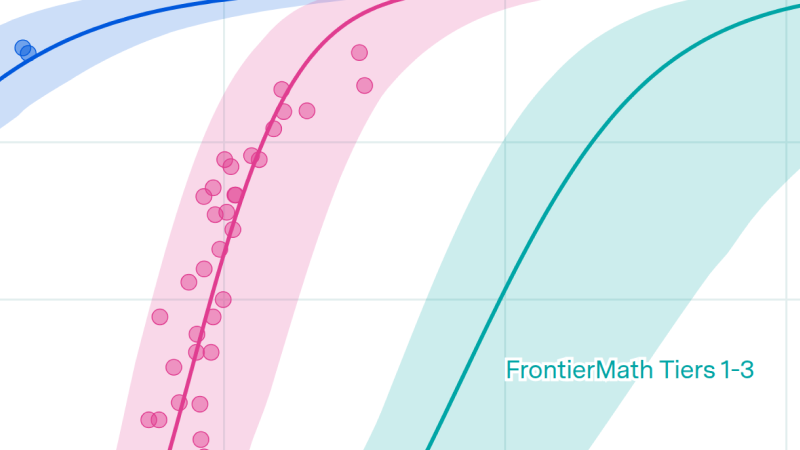
Model rankings are remarkably consistent across most AI benchmarks. Across 15 benchmarks with at least 5 models overlapping, the median pairwise correlation among benchmarks from different categories is 0.68, vs. 0.79 among those from the same category.

These correlations suggest a common capability factor that improves with scale—the intuition behind our Epoch Capabilities Index (ECI). However, this same fact means that correlation estimates are strongly subject to sampling noise: a model released several years after another will win on almost any task, so benchmarks spanning wide time ranges tend to have higher correlations with each other.
Epoch's work is free to use, distribute, and reproduce provided the source and authors are credited under the Creative Commons BY license.
Learn more about this graph
We visualize correlations between benchmarks in our Benchmarking Hub using a pairwise correlation matrix. All correlations correspond to Spearman (rank) correlations.
Across 17 benchmarks with a minimum of 5 models evaluated on each of the other benchmarks, the median rank correlation is 0.73. Correlations are nearly as high across benchmark categories as they are within categories; we find a median correlation of 0.68 among benchmarks from different categories, and 0.79 among those from the same category. This high degree of agreement between benchmarks motivates our Epoch Capabilities Index, which is designed to capture a single capability factor. Unsurprisingly, ECI correlates well with underlying benchmarks.
Data
Analysis
Limitations
Explore this data
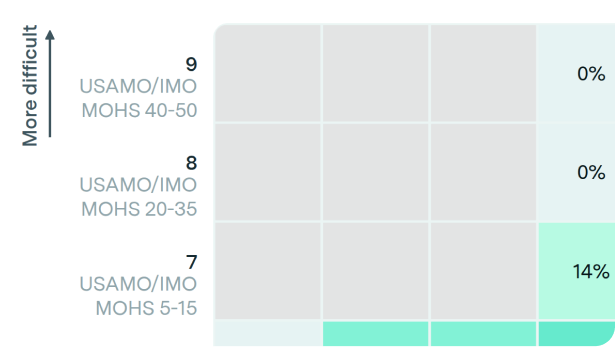
Benchmark results featuring the performance of leading AI models on challenging tasks.
Related insights