If the last decade of AI has taught us one lesson, it’s that scaling compute builds better models. This sounds great — until you realize your competitors have ten times more compute than you.
This is the situation that many Chinese and open model companies find themselves in; relative to frontier companies, they’re “compute-poor”. Just last year, Anthropic spent over ten times more on compute than Minimax and Zhipu AI combined, and the gap is even wider for OpenAI:
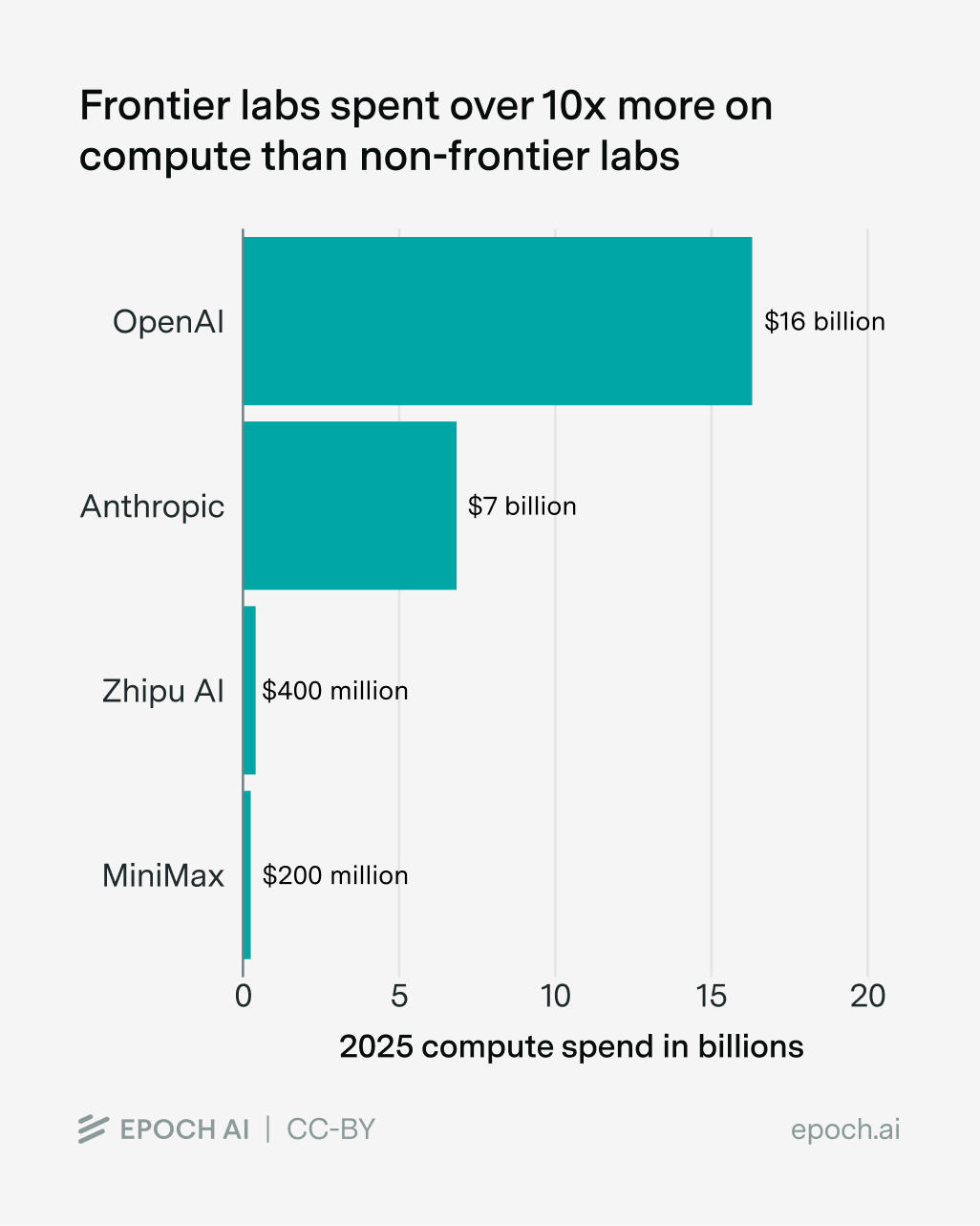
Data from Epoch’s data on AI companies and Data Insights.
You don’t need to be an AI expert to see that this is a huge handicap. With less compute, it’s harder to run experiments, train bigger models, and serve many users.
But compute-poor AI labs have an ace up their sleeve. Even lacking frontier-level compute, they can try to use theirs more efficiently to punch well above their weight. That’s how DeepSeek was on the heels of OpenAI despite using a fraction of the training compute (at least on some benchmarks), driving the stock market bananas.1
The big question is: are these efficiency gains big enough for compute-poor labs to really compete, potentially even leapfrogging the compute-rich labs?
Breaking down the efficiency gains
To figure this out, we need to look at how compute-poor labs can try to boost their compute efficiency. As far as I can tell, there are three main ways to do this:
- Develop new algorithms and improve data faster than compute-rich labs
- Replicate innovations from frontier labs
- Leverage compute-rich labs’ model capabilities — e.g. train on synthetic data generated by rival models
Out of these three approaches, the first is the only one that gives them a shot at overtaking the frontier — the latter two mainly help play catch-up. But catching up could still be important because it makes it easier to leapfrog the frontier later on. So in theory, all three approaches could matter a lot for competition.
Whether they matter a lot in practice depends on one key condition: whether they improve efficiency asymmetrically, helping compute-poor labs much more than compute-rich ones. After all, if both sides benefit equally from the same trick, a ten-fold compute gap stays a ten-fold compute gap. So let’s see how well each holds up.
Approach 1: Innovate faster than the compute-rich labs
If compute-poor companies can’t outspend the compute-rich frontier, maybe they can out-think them. Such labs often have many brilliant researchers spinning up new algorithmic innovations, like DeepSeek’s MLA and GRPO — things that demonstrate great research taste.
Being compute-bottlenecked also pushes these labs to be efficient, experimenting with risky algorithmic “moonshots” that dramatically save compute. In contrast, frontier labs might tend to stick to tried-and-true recipes — if their training runs are many times larger, then it’s also many times more costly for them to take a risk that fails.
But compute-rich labs have their own efficiency advantages. For example, running experiments often requires lots of compute, like to test if algorithms scale well. That’s why most compute spending at AI labs goes to experiments:
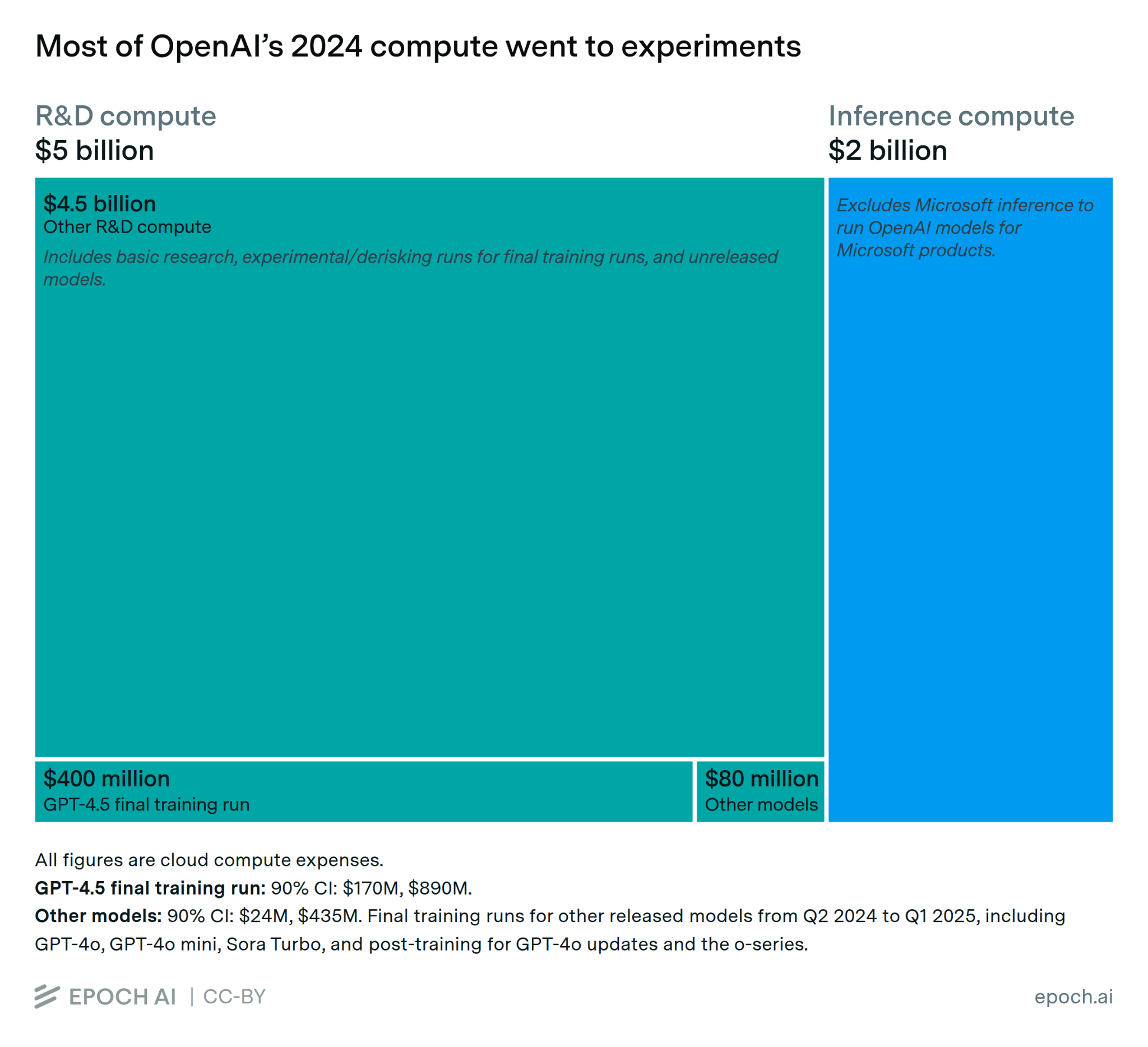
And as I explained in my last essay, some innovations like the Transformer give bigger efficiency gains as you scale up training compute. So these innovations benefit the compute-rich more than the compute-poor.
What’s more, it’s not just the compute-poor labs that have talent — the compute-rich labs do as well, and they probably have the best talent. They can pay exorbitant amounts for the crème de la crème, often poaching researchers from other labs.2 They also seem to be paying more for junior roles. For instance, early-career researcher salaries at OpenAI and Anthropic are around twice as high as at DeepSeek, even after accounting for purchasing power.3 I’d guess this is part of why the vast majority of Chinese AI researchers who go to US institutions tend to stay there. And anecdotally, Chinese AI researchers see the US as the most desirable place to work (at least for now).
In practice, I think this is why many of the most notable innovations have come from those with the most compute. For example, innovations like modern Transformer-based LLMs, scaling laws, and reasoning models were developed by OpenAI and Google — organizations that fall squarely within the “compute-rich” category.4
So I don’t see why I should expect compute-poor labs to find new software innovations much faster than compute-rich labs — on the contrary, I think the opposite is more likely.5
Approach 2: Replicate innovations from frontier labs
If they can’t beat the frontier labs at developing new software innovations, why not replicate them? Knowledge (like algorithms) in frontier AI labs could “spill over” into compute-poor labs, keeping the latter in the competition without needing to pay big R&D costs to find the innovations in the first place. That would be a big deal, because research costs are the main reason why AI companies aren’t yet profitable, and this then makes it easier to leapfrog the frontier with new innovations or by closing the compute gap.
This could work in a few ways, including AI researchers gossiping, researchers moving from compute-rich to compute-poor labs, or researchers at compute-poor labs reconstructing innovations from frontier labs based on public information.
This could lead to especially large and fast spillovers if there are “four minute mile” effects — after one AI lab makes a breakthrough, other labs realise they can do it too, so they pour effort into reimplementation.
There is evidence this already happens, such as case studies of people broadly reimplementing frontier lab breakthroughs: despite limited public information,6 a small team of academics got pretty close to reproducing AlphaFold 2 within seven months of its release.7 Another example is reasoning models: after OpenAI released the first reasoning model (o1), several different AI labs followed suit within months, sometimes using several times less training compute.8
But are these dynamics big enough to bridge the gap? Probably not, for several reasons.
For starters, innovation economists seem to think that these kinds of spillover effects are a big deal,9 but I doubt even they would say these kinds of spillovers are strong enough to make up for a ten-fold difference in compute.10
Moreover, even if compute-poor companies instantly knew how to reimplement a closed model’s innovations upon release, they’d need to launch a new training run that takes (say) three months to finish – three months where the compute-rich labs are gaining further ground. And this is ignoring the time it takes to figure out what things actually work, as in the case of reasoning models and AlphaFold 2. In practice, companies like MiniMax and Zhipu AI are still spending much more on experiment compute than on final training runs, meaning spillovers aren’t enough to cut out those experiment compute costs:11
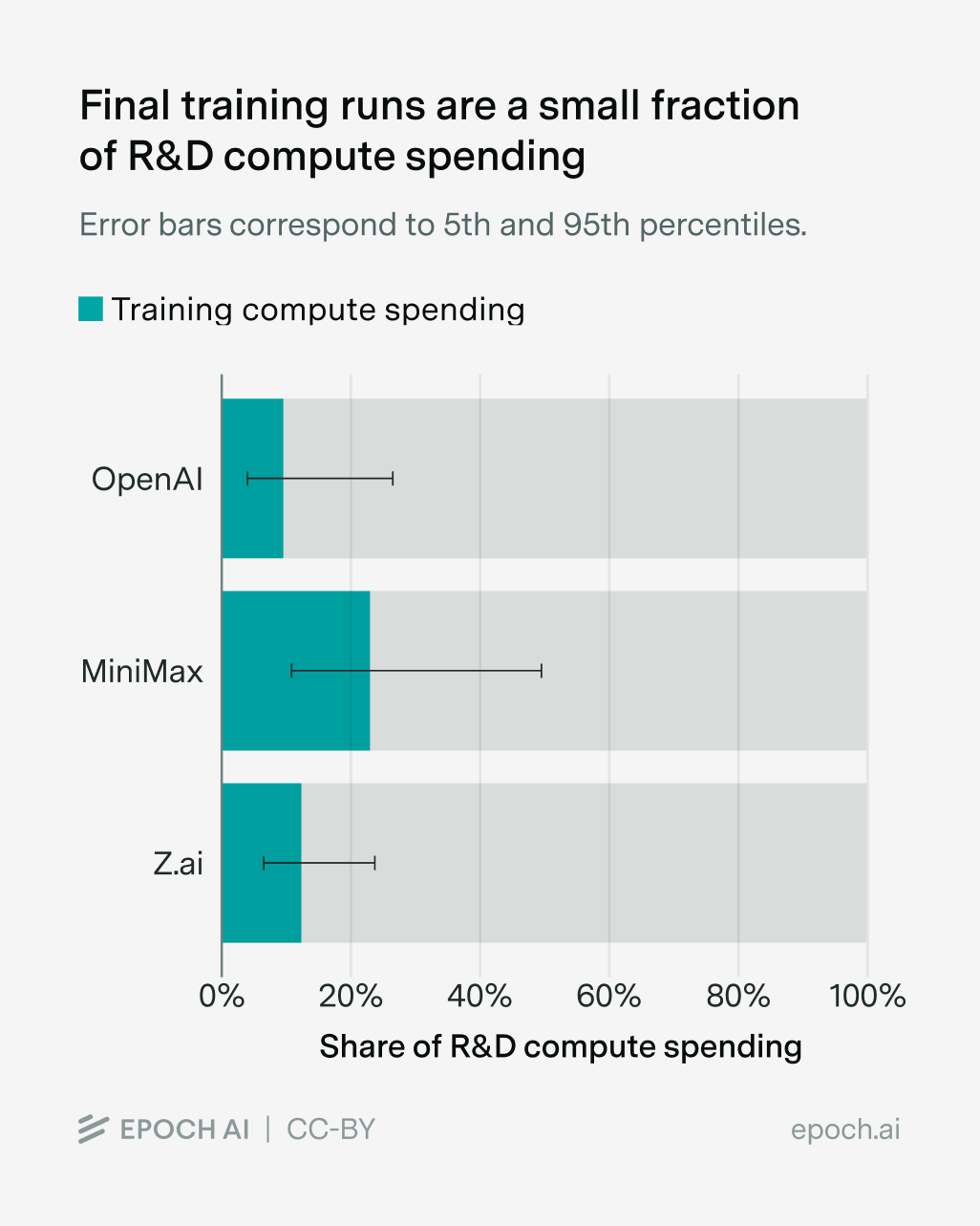
And finally, the mechanisms for these spillovers don’t even favor compute-poor labs that much. Just as the compute-poor can copy the compute-rich, the compute-rich can copy the compute-poor, especially if their models are open — there’s a reason why big AI labs still follow the academic literature. And while researchers often move from compute-rich to relatively compute-poor labs (e.g. from OpenAI to Mistral AI), they also go the other way. This is especially true for people who move from compute-poor academia to compute-rich industry.
So once again, I’m skeptical that “copying” innovations boosts compute efficiency that much more for the compute-poor than compute-rich — at the very least I doubt it’s enough for a ten-fold gap in compute.
Approach 3: Leverage the capabilities of frontier models
Compute-rich labs have already developed expensive frontier models, and they’re letting people use them. So why not use them to improve compute-poor models?
In practice, the biggest “oomph” here probably comes from getting frontier models to generate lots of outputs, and then training on that data. This is often (inaccurately) called “distillation”,12 and it lets you transfer the capabilities of frontier models into smaller models. A notable recent example comes from Anthropic, who accused DeepSeek, Moonshot, and MiniMax of distilling from Claude’s outputs.13
The question is, just how much of a difference does distillation make in practice? The evidence is patchy, but if we squint at the numbers I think they weakly suggest that companies can potentially get several-fold compute efficiency gains.
One piece of evidence is what happens when you distill DeepSeek-R1 into Qwen2.5 models:14
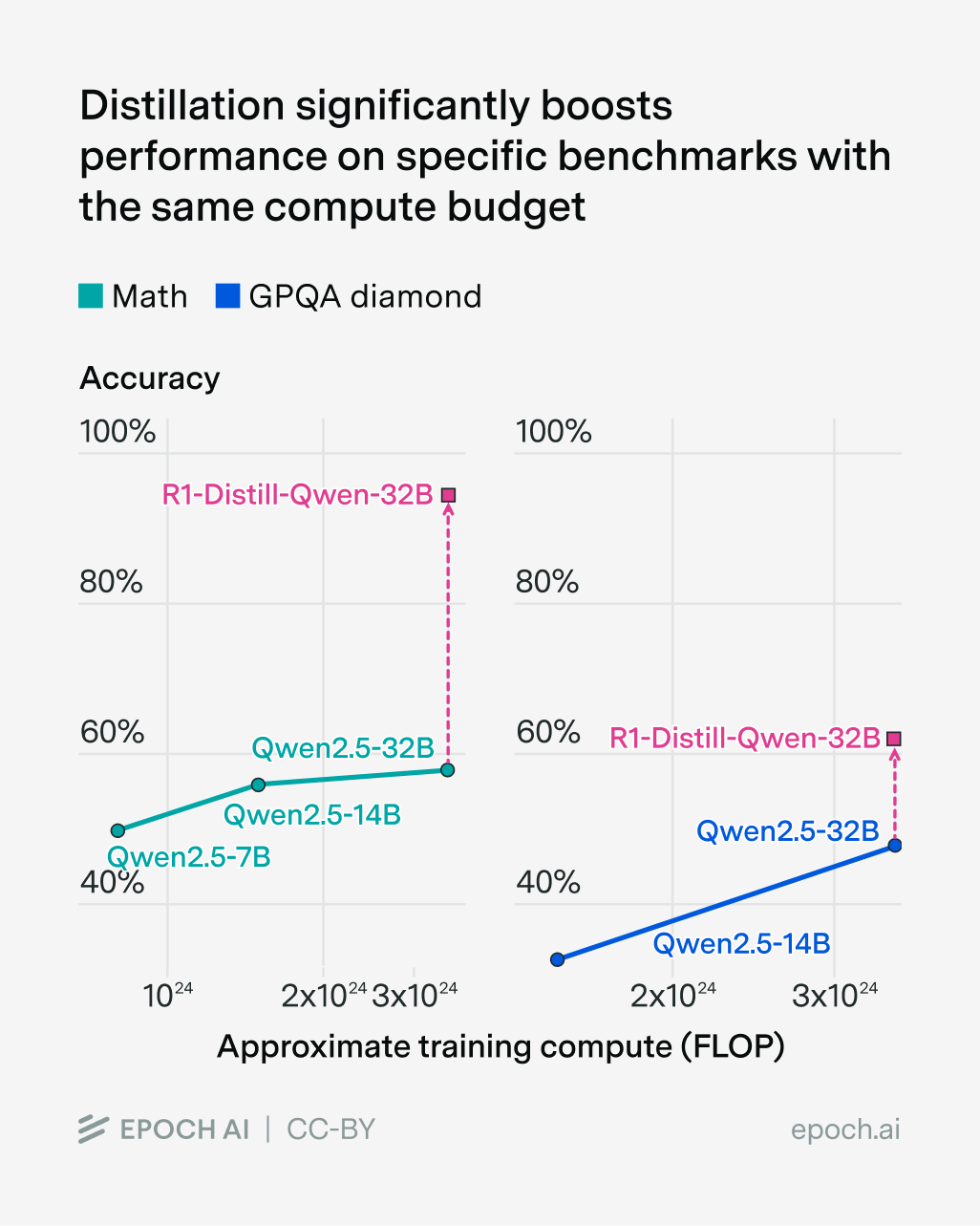
On MATH and GPQA Diamond, we see enormous efficiency gains — requiring several times less pre-training compute for GPQA, and multiple orders of magnitude less for MATH. So at first glance, distillation seems like it could be a huge deal for crossing the ten-fold compute gap to the frontier.
The problem is that this anchors too much on specific benchmarks. It’s suspicious that the efficiency gains vary dramatically between MATH and GPQA. So what if we retain capabilities across a range of benchmarks?15 Once again the evidence is shoddy:
- Olmo 3 was able to outperform the best open models at its scale across multiple benchmarks, while using 6x fewer tokens. This involved a pipeline that included distillation, so we can interpret this as an upper bound of the efficiency gains in the paper.
- Based on how quickly they’re run, it’s plausible that OpenAI mini models had several times fewer parameters than the original models they were distilled from. At the same time, they arguably perform only slightly worse on various benchmarks, and are just edged out in head-to-head comparisons. For example, human voters preferred GPT-5 to GPT-5-mini around 56% of the time. (That said I think this framing is a bit optimistic — there are other benchmarks where the mini models are quite a bit worse.)
It’s not clear to me how comparable these examples are — the exact efficiency gains depend on how much data was used, how comprehensive the benchmarks are, and so on. Annoyingly they’re also based on different metrics — one helps you use less data, the other fewer parameters, and it’s not clear exactly how this maps onto compute savings. But I think they weakly suggest that you can potentially get several-fold compute efficiency gains, even if we account for a broad set of benchmarks or domains.
And you don’t need much data to make this work: it’s possible to distill DeepSeek-R1 with around 4 billion tokens.16 For comparison, MiniMax may have been able to get 100 billion tokens of data from interactions with Claude.17 Nathan Lambert points out that this much data could “meaningfully improve a models’ post-training”, which sounds about right to me. So this is probably the most compelling of all the potential explanations we’ve seen for how compute-poor AI labs could try to keep up with the frontier.18
That said, there are several caveats to bear in mind. First, there are limits to how well distillation works. As the model gets smaller it’s much harder to distill capabilities into it. We can see this when distilling DeepSeek-R1 into different versions of Qwen2.5 — performance on benchmarks like AIME, MATH, and GPQA fall as the model gets smaller:
| Model | Model size (active parameters) | AIME | MATH | GPQA |
|---|---|---|---|---|
| DeepSeek-R1 | 37 billion | 79.8% | 97.3% | 71.5% |
| R1-Distill-Qwen-32B | 32 billion | 72.6% | 94.3% | 62.1% |
| R1-Distill-Qwen-14B | 14 billion | 69.7% | 93.9% | 59.1% |
| R1-Distill-Qwen-7B | 7 billion | 55.5% | 92.8% | 49.1% |
| R1-Distill-Qwen-1.5B | 1.5 billion | 28.9% | 83.9% | 33.8% |
To be more concrete, I’d be pretty surprised if a distilled model could be a hundred times smaller but still capture the same broad set of capabilities as its “teacher” model.
A second caveat is that distilled models may be more likely to be “benchmaxxed” — they’re optimized for a specific set of benchmarks, and don’t do so well in general. For example, OpenAI’s “mini” models often do worse on things that involve lots of knowledge recall.
Third, compute-rich frontier labs could keep the most powerful models to themselves or select customers, making it hard for the compute-poor to keep up via distillation.
Fourth and finally, it’s hard for distillation to be the full story for how models develop reasoning capabilities on a range of environments. As Nathan Lambert points out, this typically requires large-scale RL where the model learns from its own trial-and-error, rather than purely distilling from a stronger model. So while distillation certainly helps reasoning, compute-poor labs will probably still need to establish RL environment infrastructure and do the RL training itself.
Overall, leveraging frontier model capabilities probably does meaningfully boost efficiency for compute-poor labs relative to the compute-rich. I’d weakly guess that it doesn’t get them all the way to covering a 10x compute gap — probably it narrows the gap several times.
Putting things together
Here’s where I land on the three approaches:
- Coming up with new software innovations: This doesn’t seem to asymmetrically favor compute-poor AI labs — in fact it might favor the compute-rich.
- Replicating innovations from frontier labs: Spillovers often go in both directions, and in general I’m skeptical that the effects of this are large enough to make up for a ten-fold difference in compute.
- Distilling frontier model capabilities: This could help the compute-poor get very close to broad frontier capabilities with several times less compute. I doubt this is enough to save ten times less compute, but this is a meaningful efficiency boost, and you can get much bigger savings if you only care about specific narrow capabilities.
So if we put everything together, I think compute-poor labs probably can’t fully make up for their 10x compute disadvantage to compete at the frontier. The compute gap is just too large, and most approaches don’t help the compute-poor that much more relative to the compute-rich.
But it’s not something that we can totally rule out, especially if there are big algorithmic breakthroughs like reasoning models. And of course, I’m basing my opinion on pretty limited evidence — I’d love to hear if people know of good data or arguments for or against my position.
What does this mean for the future of AI?
So far, I’ve mostly been talking about “compute-poor” AI labs, which have around ten times less compute than those at the frontier. This framing helps us analyze the efficiency gains from things like distillation and replicating innovations, and helps us show that compute is the dominant factor in who “wins” in AI competition. But we still need to address a big question: who exactly are these “compute-poor” labs?
Compute-poor = Chinese AI labs?
One type of “compute-poor” AI lab, at least today, is Chinese AI companies. For example, we saw earlier that MiniMax and Zhipu AI collectively spent under ten times the compute of Anthropic in 2025.
So does this mean that Chinese labs are destined to be relegated to the sidelines, unable to compete with American AI companies? Not necessarily, because it depends on how much compute American and Chinese AI labs can get their hands on. If the compute gap narrows, it becomes easier to compete with the frontier. If it widens, the opposite is true.
This of course hinges on a huge open question: how will the compute gap evolve over time? So far I think it’s not grown massively, and I think this is why they’ve not fallen far behind in capabilities to the frontier, as measured by the Epoch Capabilities Index (a fancy aggregation of benchmark scores):
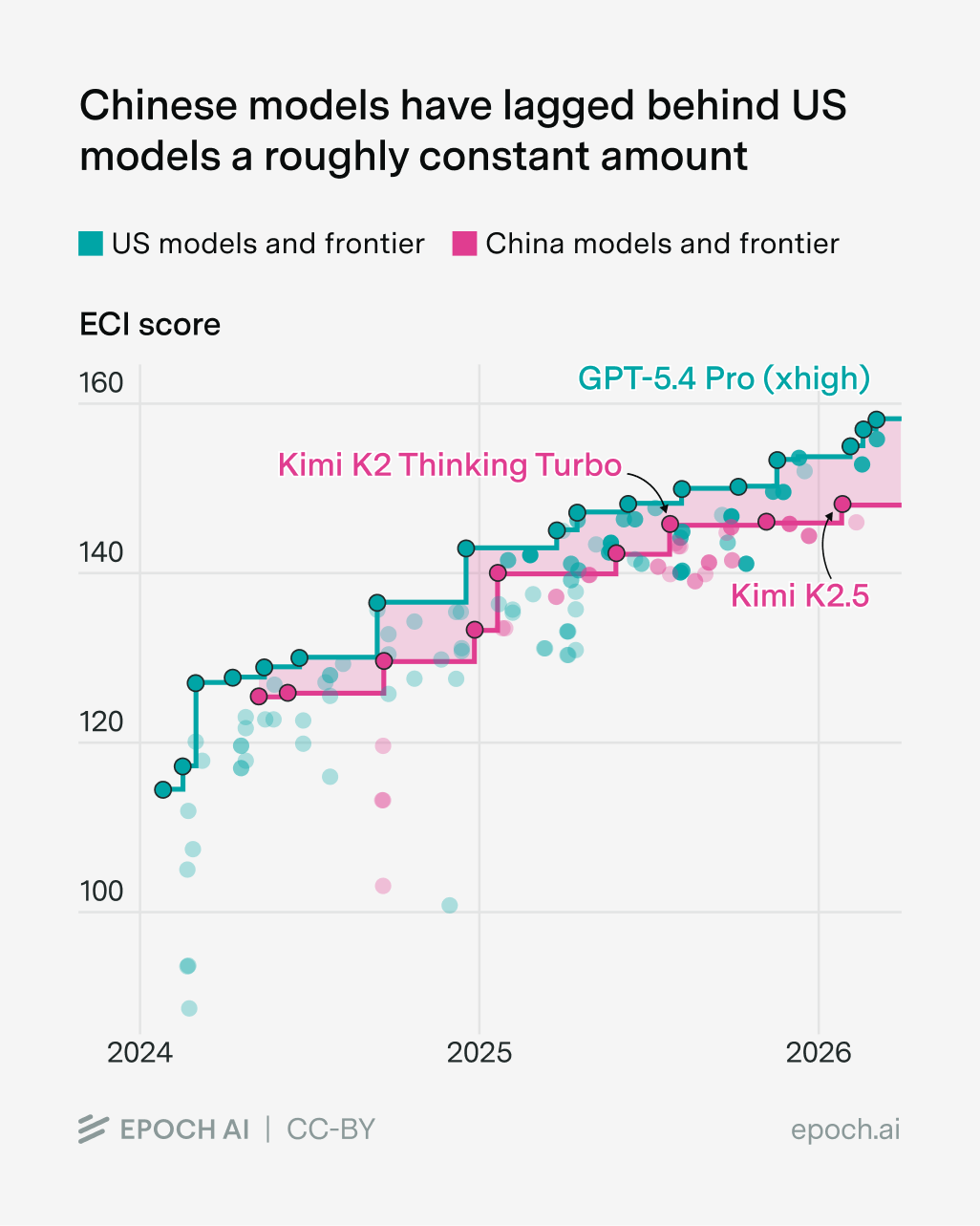
But this interpretation is a little debatable. For example, the gap in training compute has grown, though not dramatically so:
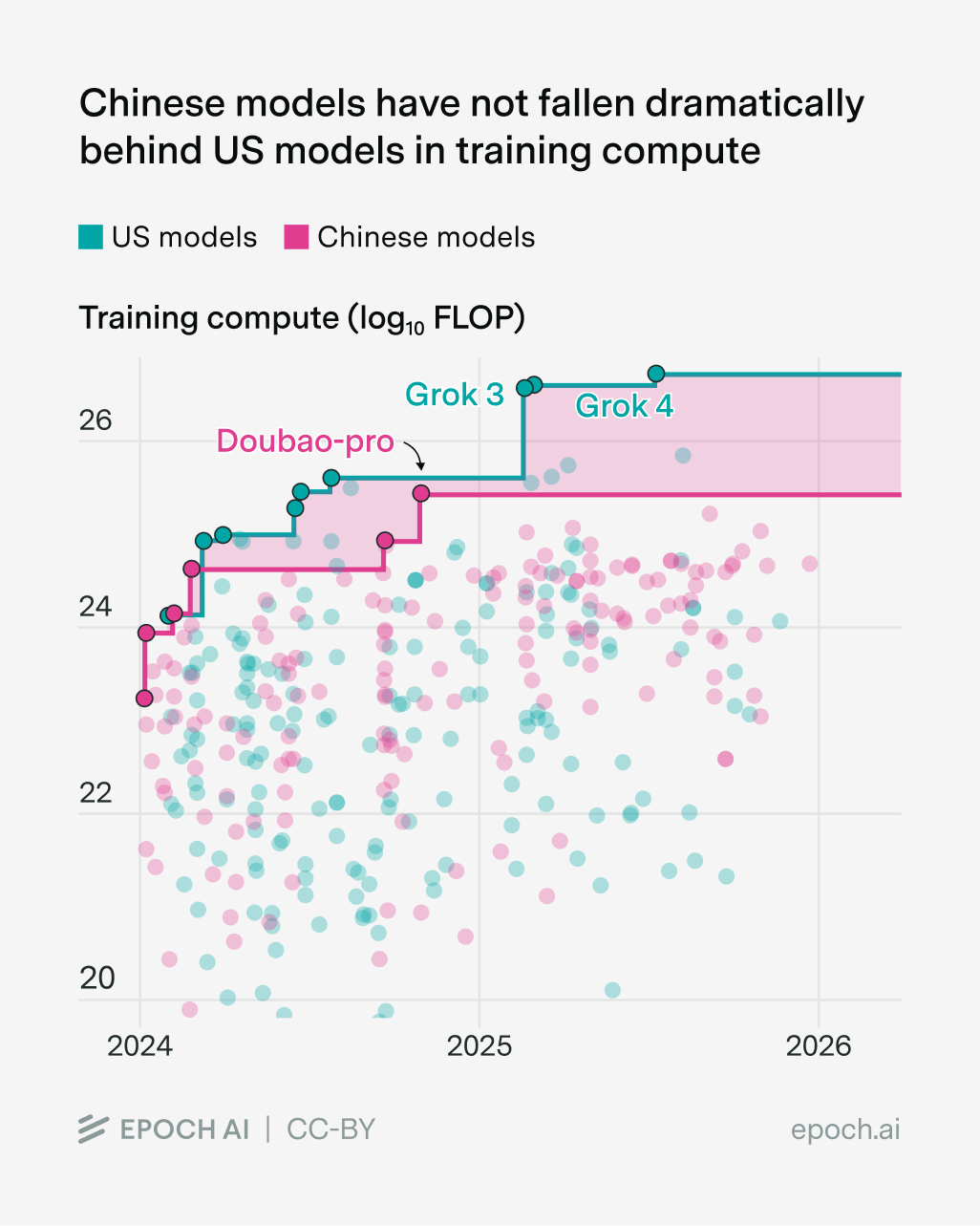
But it’s rather confusing for a couple of reasons:
- The best US and Chinese models aren’t always trained with the most compute. For example, Grok 3 and 4 are probably also inefficient for their size, and I’d guess the same is true for Doubao Pro.
- This is looking at training compute rather than overall compute budgets. I’ve mostly been talking about the latter throughout this essay, but sadly we don’t have enough data on it.
- Another confusing thing is that different AI labs were scrambling to figure out reasoning, which gives a much larger efficiency boost compared to most other innovations.
Overall I’d weakly guess that the overall compute gap hasn’t changed much over time, and this is why the capabilities gap hasn’t changed much either.
But there are some reasons to think that the gap will grow. As I’m writing this, American hyperscalers are driving a data center buildout that’s larger than the Manhattan Project and Apollo Program at their peaks. As part of this, frontier labs will soon have data centers that each cost tens of billions of dollars and contain millions of GPUs. In contrast, Chinese AI companies are hampered by export controls, and being behind in domestic AI chip production. This could widen the compute gap in the near term, and hence lead to a divergence in the capabilities of US and Chinese AI models. On some measures this is already happening, and Tang Jie (CEO of Zhipu AI) even recently said the following:
“The truth may be that the gap [between US and Chinese AI] is actually widening.”
On the other hand, Chinese AI labs could continue to get more compute by smuggling chips, or by renting it through the cloud. And the further we look into the future, the greater the odds of China catching up in domestic AI chip production.
So in my book, the overall picture of US-China AI competition looks like this: in the short run (say 2-3 years), I think it’s unlikely that the gap will narrow much, because of export controls and challenges in rapidly scaling up domestic chip production. But it’s more uncertain in the longer run. It depends on hard-to-predict chip export controls. It depends on how hard it is to smuggle and rent chips. It depends on how much China wants to really push for AGI, scaling up their compute stocks — and there are signs that the winds are shifting in this direction from China’s most recent Five-Year Plan.
And there’s an additional wildcard that makes things even more uncertain — frontier AI companies can run more of the best AIs to speed up their own AI research, relative to their competitors. Right now these gains are maybe noticeable but not game-changing, but that’ll probably change in the next few years. If so, this could widen the capability gap between the compute-rich and compute-poor, even if the compute gap stays fixed.
Compute-poor = Open models?
Another type of “compute-poor” AI lab is the labs developing open models. Like Chinese AI companies, their training compute hasn’t fallen super far behind the frontier, though the gap has grown…
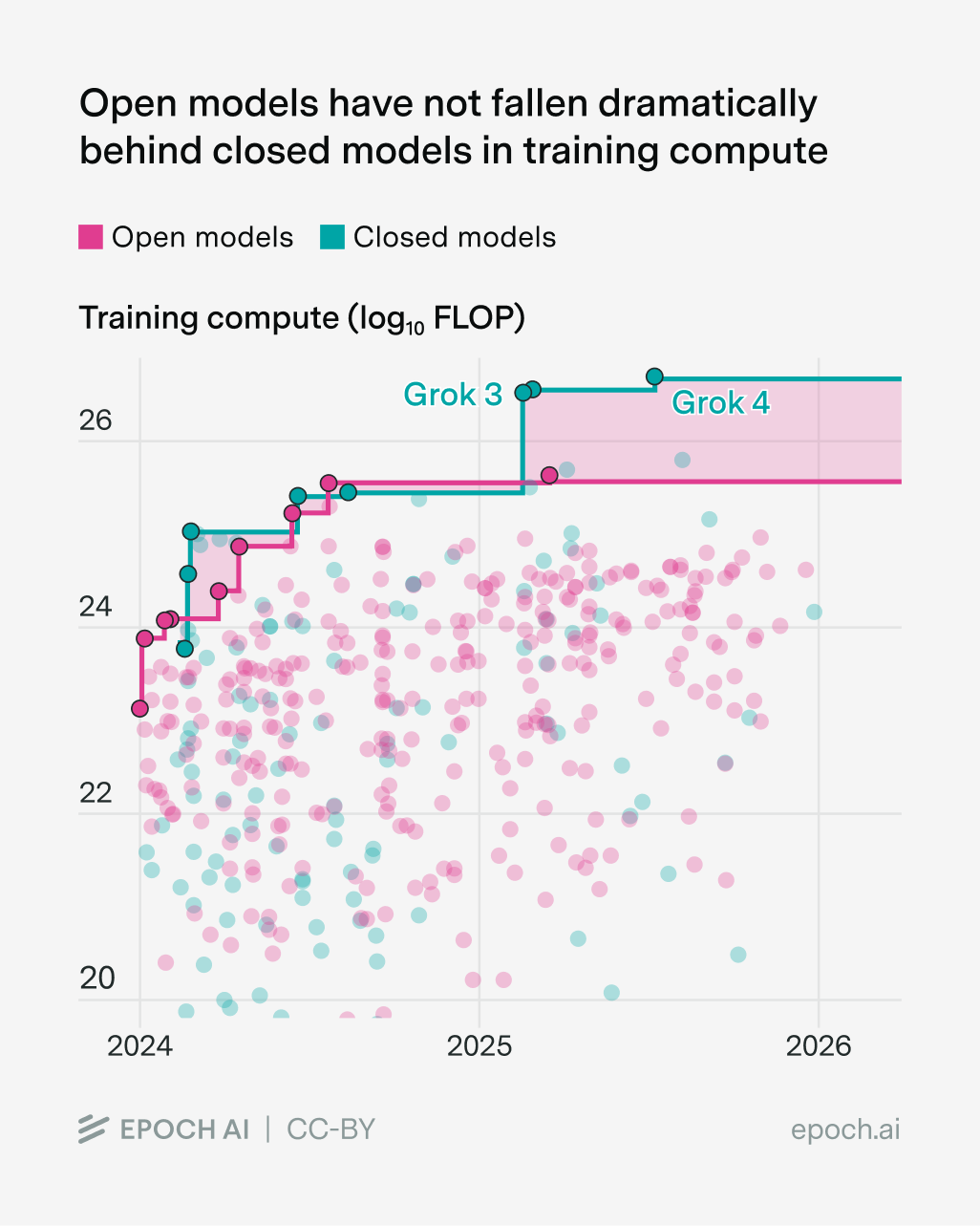
…and the capabilities gap looks like a constant-ish lag:
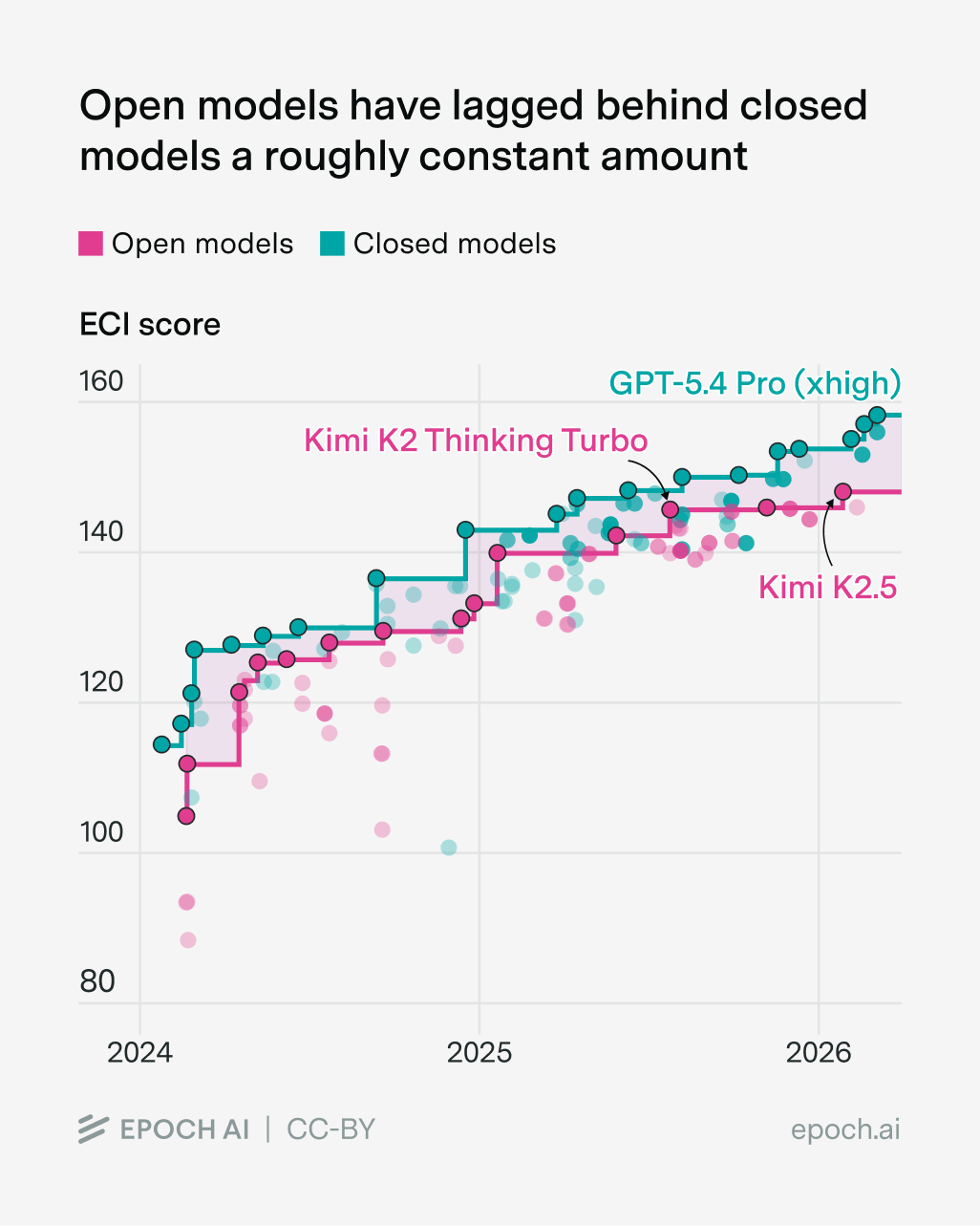
Perhaps this isn’t so surprising. There’s quite a lot of overlap between open model labs and Chinese AI companies, so we should expect a lot of their challenges to be the same. For example, a big open question is how the compute gap between open model labs and frontier companies will change over time, just like what we saw with Chinese labs.
But the future of open models at the frontier depends on a separate open question (no pun intended): will future AI models be open-weight?
This is probably even harder to answer than the question about compute scaling. One issue is that companies seem to flip-flop on whether to release open models. For example, Alibaba has recently shown signs of tilting further toward closed releases.19
But my favourite example of this has got to be Meta — in July 2024, Mark Zuckerberg wrote an essay called “Open Source AI is the Path Forward”. He raised multiple arguments for open models, like privacy, safety through lots of scrutiny of AI models, and leveraging the broad AI community to improve Meta’s models. Now they seem to be backing away from this strategy — first with reported discussion about abandoning the open-weight Llama 4 Behemoth in favor of a closed model, and now with their next-generation “Avocado” model allegedly to be released closed-weights. Someone has even written an article called “Open Source AI was the Path Forward”. (Last-minute pre-publication edit: apparently Meta now plans to “eventually” offer open versions of their next generation of AI models, so maybe Open Source AI is eventually the Path Forward).
Sometimes labs also go the other way too. After DeepSeek-R1’s release as an open-weights model, several Chinese labs followed suit. For example, Baidu abandoned their commitments to closed models with their ERNIE 4.5 model, citing DeepSeek as a motivator driving this decision.20
The upshot is that the capability gap between open models and the frontier depends a lot on which labs choose to be “open”. This depends on things like government strategies, the ideologies of company CEOs, and also business incentives, as Nathan Lambert points out:
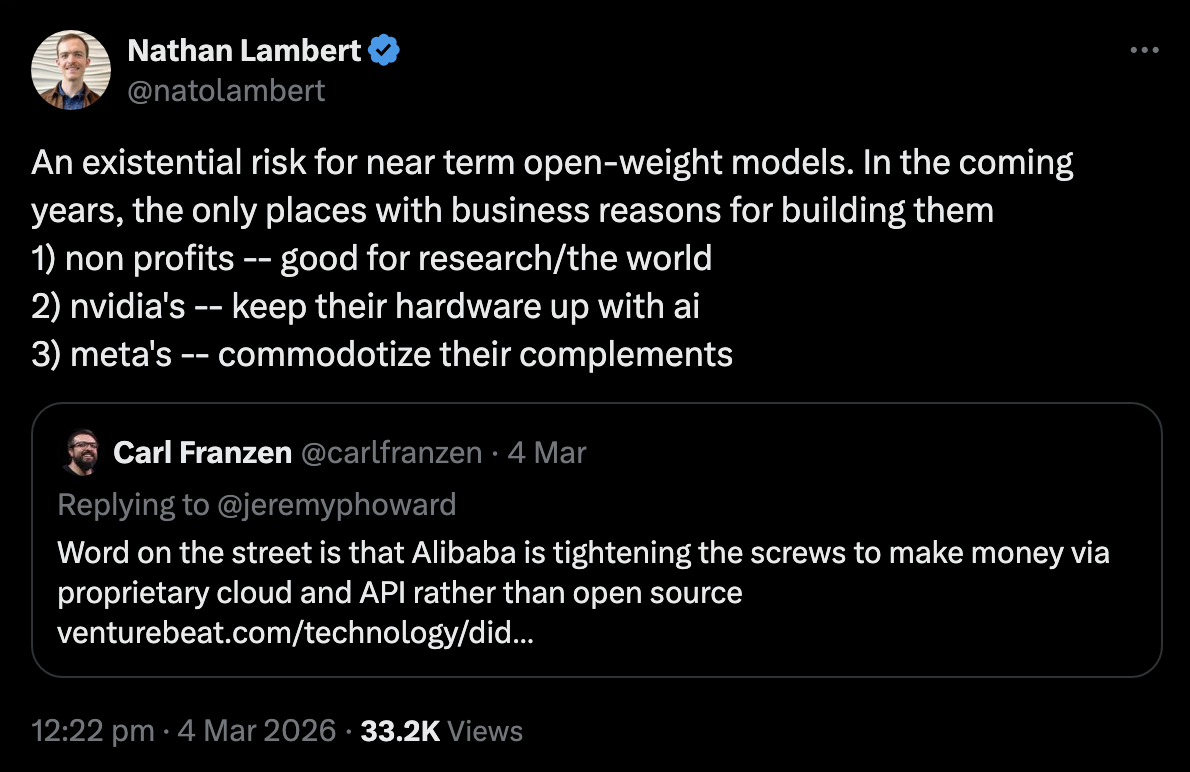
The bottom line
So what have we learned from all of this discussion? For me the primary takeaway is this: compute is the biggest factor for which companies can compete at the capabilities frontier — efficiency matters too, but it’s probably not enough to make up for ten times less compute.
At first glance this seems to paint a gloomy picture for Chinese and open model labs, but I think it’s not so clear cut. This is because the label of “compute-poor” may not map onto them very cleanly in the future. Maybe it’s hard for them to compete with the “compute-rich” frontier labs today, but in the future this’ll depend on how much compute they have, and which labs choose to be “open” or “closed”.
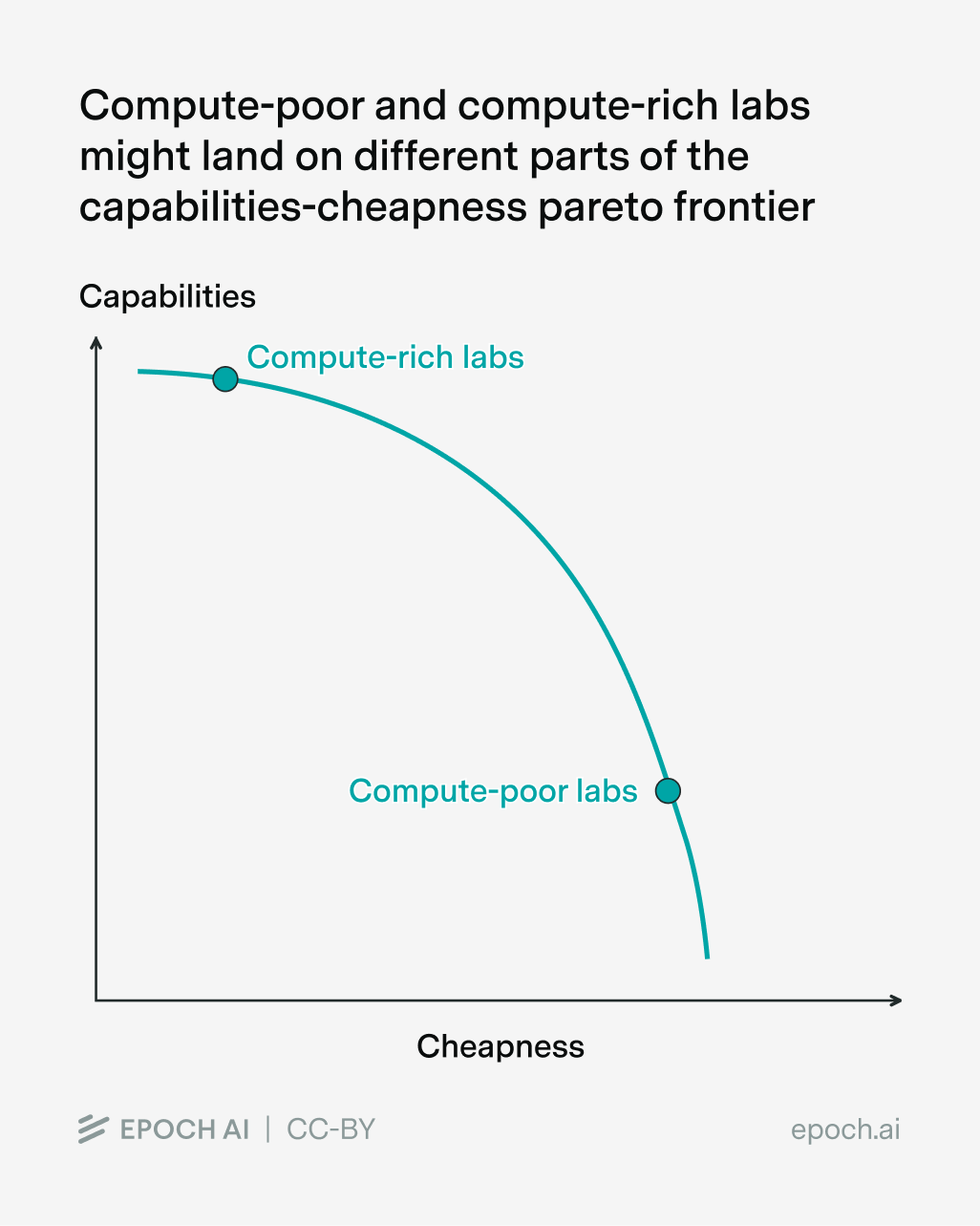
Moreover, I’ve been framing the whole analysis around competition at the frontier of capabilities, but strictly speaking that might not even be the only priority of these AI labs! For example, we could imagine Chinese models simply finding a different part of the “capabilities vs cheapness” pareto frontier:
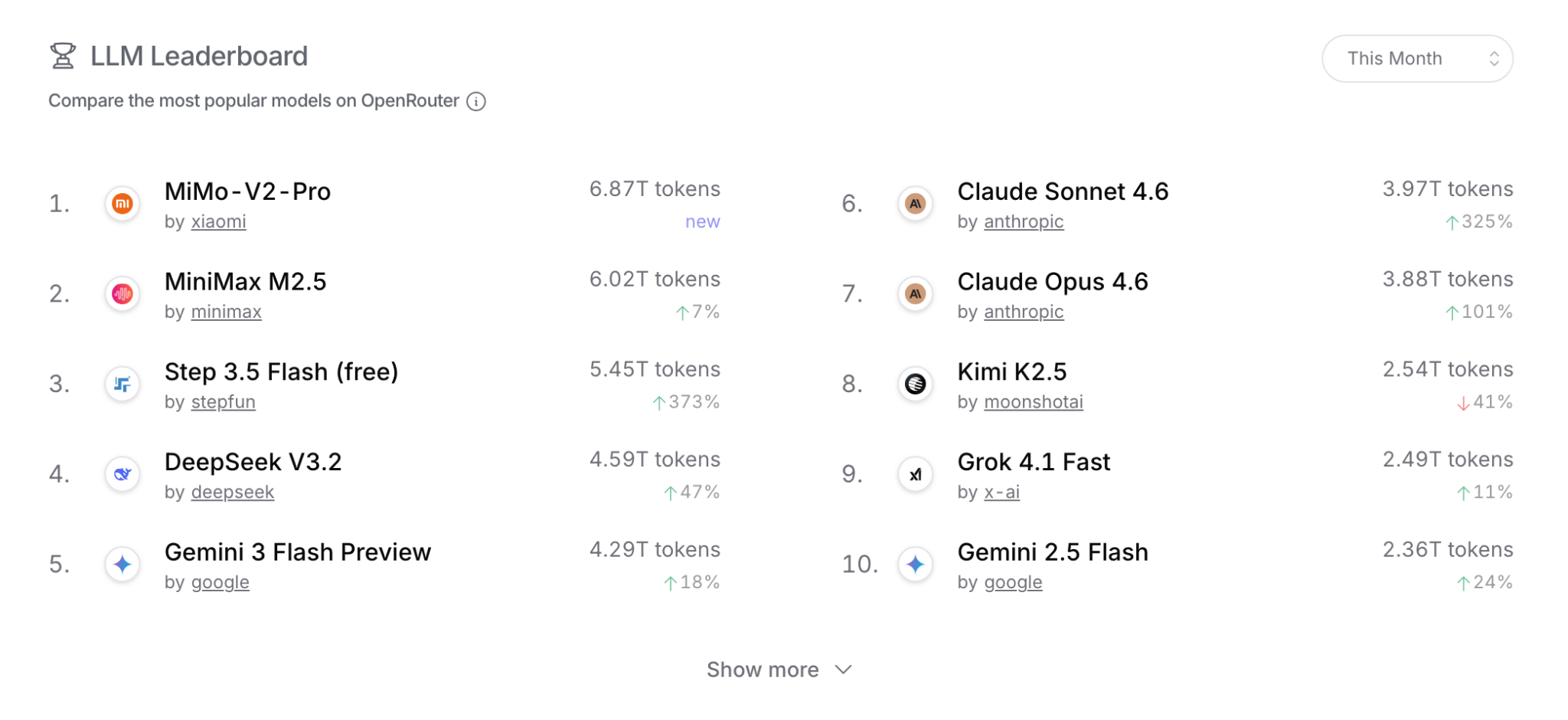
In fact, if you look at token usage on OpenRouter, you’ll notice that a bunch of the most popular language models are actually Chinese (though this is kinda misleading — for example, most people who use Claude probably don’t use it through OpenRouter):
I happen to think that competing along the dimension of raw capabilities matters a ton as the world gets closer and closer to building AGI. But it’s not the only thing that matters, and it’s very possible that different AI labs might not even be “racing” toward the same thing at all.
I’d like to thank JS Denain, Jaime Sevilla, David Owen, Ben Cottier, Luke Emberson, Lynette Bye, and Stefania Guerra for their feedback and support on this post.
-
Notably, my colleagues at Epoch estimate that DeepSeek-R1 was trained with 4 x 10^24 FLOP, compared to a speculative guesstimate of 4 x 10^25 FLOP for o1, assuming the base model is GPT-4o and post-training compute costs are relatively small. That said, it’s worth saying that many claims about how DeepSeek-R1 was super cheap are overstated.

-
Though I suppose we still need to see what happens with Meta Superintelligence Labs after their big hiring spree.
-
For example, junior research scientists at OpenAI and Anthropic tend to earn in the ballpark of $350,000 per year. In contrast, junior researchers at DeepSeek earn around ¥50,000-100,000 per month, which in US dollars works out to $100,000-200,000 per year (note that the annual compensation is for 14 months rather than 12, because there are two extra salary-equivalent payments, e.g. at year-end or from bonuses).
-
Perhaps there’s a counterargument that you didn’t necessarily need a lot of compute to come up with these innovations in the first place. But even if that’s true, it’s still telling that the innovations were developed by compute-rich AI labs in actuality.
-
But even if I’m wrong about this, a ten-fold gap in compute is a lot, and it’s rare to find original software innovations that can make up for it. One exception might be reasoning models, but notably these were invented by OpenAI — hardly a compute-poor AI lab!
-
As I understand it, the main thing that was known was some high-level details about the model architecture. RoseTTAFold was developed knowing that AlphaFold 2 used end-to-end prediction from MSAs with attention and an equivariant structure module, but not the specific architecture, loss functions, or training innovations, which were only revealed when the AlphaFold2 paper was published on the same day as RoseTTAFold (July 15, 2021).
-
I say “pretty close” because their attempt (RoseTTAFold) doesn’t quite match AlphaFold 2’s performance — if we fish out the numbers using WebPlotDigitizer, we see that RoseTTAFold scores 80.3% compared to AlphaFold 2’s 90.2% on the “Average TM-score” metric in the CASP14 competition. On the other hand, RoseTTAFold may have used several times less compute — according to the paper’s supplementary material, it was trained for 4 weeks on 64 NVIDIA V100 GPUs. Assuming 16-bit precision and a utilization of 30%, this works out to 1.4e21 FLOP. In contrast, my colleagues estimate that AlphaFold 2 needed 3e21 FLOP, which is around twice that. I don’t know how the performance of AlphaFold 2 and RosettaFold scale with more training compute, but I’d guess that AlphaFold 2 was more compute-efficient overall.
-
A caveat: I’ve heard through word of mouth that Anthropic was actually able to reimplement reasoning models within about two weeks of o1’s announcement, which doesn’t sound crazy to me. I’m not sure what this means in terms of the time lag between o1 and other reasoning models though — probably OpenAI had “finished” developing o1 some time before they announced it.
-
Note that I’m referring to spillovers between firms in the same industry (“technological spillovers”) rather than spillovers from firms in the same region (“geographical spillovers”). Both matter, and in fact the latter probably differentially benefits the cluster of compute-rich AI labs in the Bay Area relative to other AI companies.
-
It’s not directly comparable to the metrics we’re looking at here, but we can try to get a sense of the effect sizes. According to one paper, if other firms working on similar tech increase their total R&D by 10%, your own firm’s market value also grows by 2-3%. That doesn’t sound like the kind of thing that means you can compete with ten-fold less compute!
-
If it did, it would also disincentivize frontier labs from doing R&D a la Kenneth Arrow.
-
Strictly speaking this is an abuse of terminology — distillation as originally defined means training a smaller model on a “teacher” model’s full probability distribution over all possible outputs, not just its final generated outputs.
-
Another piece of evidence is “slop forensics” to figure out which models were related to one another (and hence which models inherited capabilities from frontier models). This works by looking at which words or phrases show up disproportionately frequently in some models, to pick up on its “signature”. Then it compares these signatures to see the relations between models, which gives something like an evolutionary tree. If you stare at the outputs, you could conclude that DeepSeek switched from training on synthetic data from OpenAI models, to synthetic outputs from Gemini. I’m not sure how much to update on this kind of evidence though. For example, I’ve also heard suggestions that Anthropic’s models might be trained on data from DeepSeek’s models! So what’s the overall picture?
-
Note that this is using the more accurate definition of “distillation”, with access to probability distributions over tokens, rather than just final output tokens.
-
Here the constraint is to maintain around 95% of original benchmark performance, and broad capabilities across a range of different domains. You can probably do a lot better than that if you only keep capabilities on a particular set of benchmarks.
-
The paper describes using 800,000 examples with around 5,000 tokens each, which works out to around 4 billion tokens.
-
MiniMax allegedly had at least 10 million exchanges with Claude to gather its data. If each “exchange” had around 10,000 tokens, as Nathan Lambert suggests, this works out to 100 billion tokens in total.
-
Some kinds of distillation involve much more data. For example, some Llama 4 models were trained with “codistillation”, where the smaller model is trained alongside a much larger one that’s still learning itself, so it sees as much data as the larger model. This kind of distillation is probably much harder for compute-poor labs to replicate just by externally accessing frontier models.
-
As far as I can tell, it’s not the case that Alibaba now only releases closed models — they have a hybrid structure where most models are open, but their best models are closed. This isn’t totally new either — it’s been the case since mid-2024.
-
Though I’m not sure if they’ve reverted back to a closed-weight approach with ERNIE 5.0.
About the authors
Related work