AI software progress is one of those things that everyone vaguely knows about, but only a handful of people in the world truly understand its significance. Consider that many of the most fervent debates in AI to date depend enormously on it: How did DeepSeek seem to catch up to OpenAI’s o1 within months while using less training compute? When will the world develop AGI? And if we automate AI research, will AI progress accelerate like crazy a la Situational Awareness and AI 2027?
I don’t know your stances on these questions, but I do know that you can’t have a well-informed opinion on them without understanding software progress. So I figured I should write a post describing the most important things that you need to know, starting from the basics and leading up to the current frontier.
Here are the main takeaways, one for each section of the post:
- AI software progress is about reducing the training compute you need to get to the same level of capability, through better algorithms or data. This is commonly called “algorithmic progress” including by myself, but as we’ll see, this is probably a bit of a misnomer.
- Almost all the evidence points to very fast software progress: each year, the training compute needed to get to the same capability declines several times — possibly even ten times or more. But existing estimates are also incredibly uncertain, because they depend on limited observational data and dubious statistical assumptions. Relaxing some of these assumptions could change some estimates by close to an order of magnitude!
- Recent evidence suggests that these estimates might not measure what we thought they did. Software progress has often been framed as continually finding new algorithmic innovations, which cumulatively bring massive efficiency gains. But most software progress might actually be due to data quality improvements (hence “algorithmic progress” may be a misnomer). And much of the measured efficiency gains might come from scaling up just a small handful of “scale-dependent” algorithmic changes — innovations that have a greater impact at higher training compute scales — rather than from discovering lots of new algorithms. Both of these effects were mostly unaccounted for in prior literature.
- Some argue that automating AI research could lead to a “software intelligence explosion”, with AIs recursively improving themselves. Previous analyses suggest this is plausible but uncertain. However, some of these analyses are based on overly conservative estimates of software progress, which makes an explosion seem more likely when corrected. On the other hand, they also ignore scale-dependent innovations, which pose a compute bottleneck — it may be hard to get fast software progress without also scaling up training compute, potentially making an explosion less likely. The net effect isn’t totally clear: the compute bottleneck argument is suggestive but the empirical evidence is shaky, and there are plausible reasons automated AI researchers could overcome it.
- There are still big open problems about AI software progress, like the rate of progress in post-training, and the strength of compute bottlenecks. I think it’ll be hard to make progress on these questions, but it’s still worth trying to answer them because AI software progress is so overwhelmingly important.
Now let’s dig into the details.
I. AI software progress: Doing more with what we have
First things first, what do we mean by “AI software progress”? You’re probably familiar with some examples: when the field of AI switched from LSTMs to Transformers, that was software progress. When OpenAI released the first reasoning models that took time to think before responding to users, that was software progress. It seems simple enough: with better algorithms and data (“software”), you can train better AI systems.1 There are other kinds of software progress too (like in inference), but for this post I’ll focus primarily on training.
But what exactly does it mean to have “better” software? Historically, people have defined this through the lens of AI scaling, where using more training compute is the main thing that increases capabilities. Then you define software progress relative to this: if you have better software, then you need less compute to reach the same level of capabilities.2
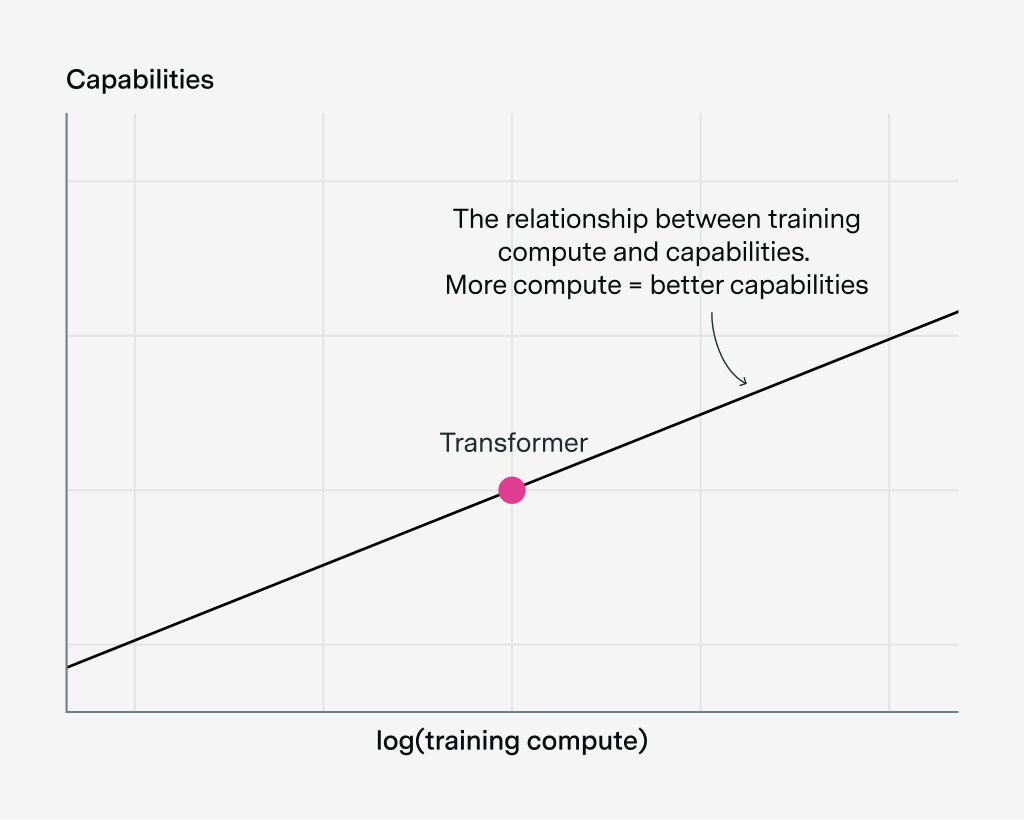
To see what I mean, let’s say we’re training a Transformer with a certain amount of compute, shown as a red dot below. If we change the amount of training compute, we get a relationship between training compute and capabilities, which we can draw as a line:3
Now let’s introduce a new software innovation, say rotary embeddings or training data filtering. Under this definition of software progress, this reduces the training compute we need to reach a certain capability, and so we shift this curve to the left by some factor, shown as the “compute efficiency gain”:
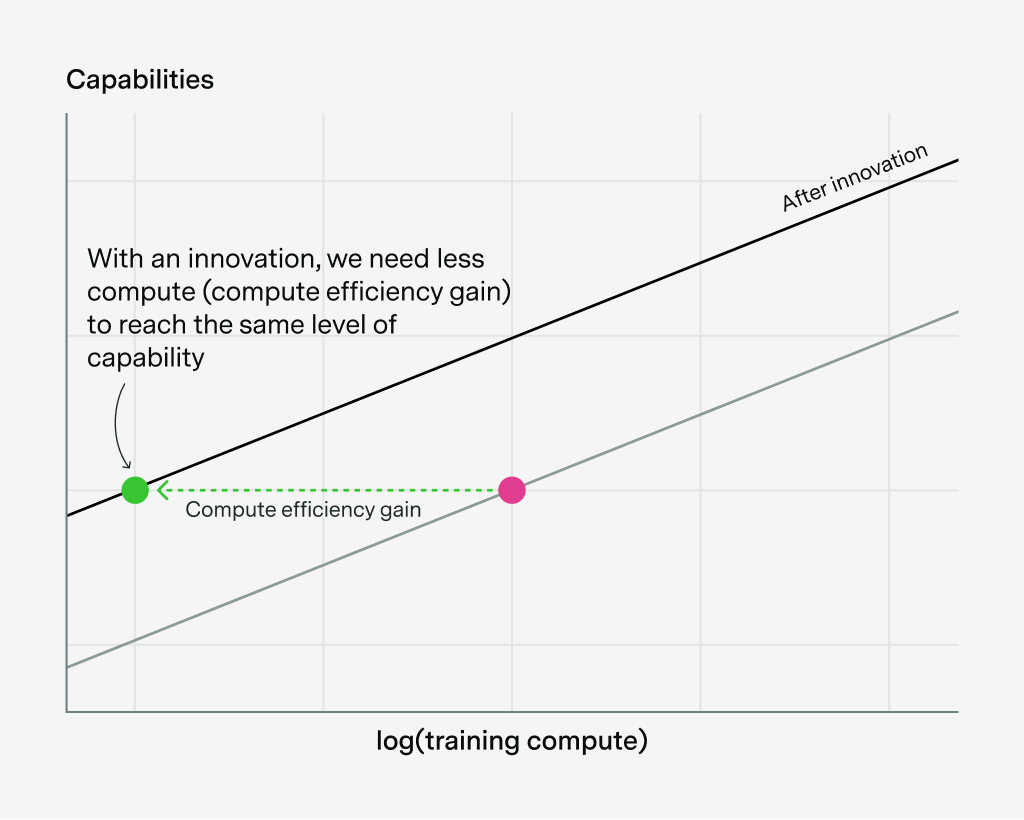
What’s more, this algorithmic shift also means that we can do more with the same amount of compute, reaching the blue level of capabilities:
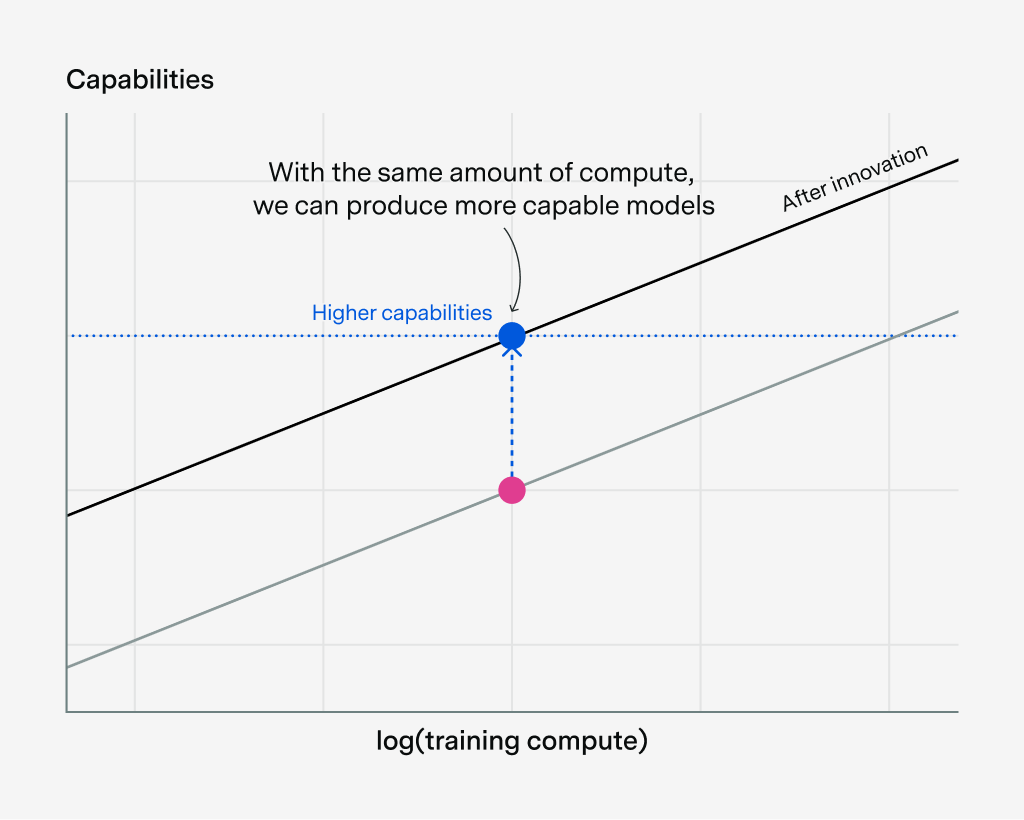
If we had wanted to reach that blue level of capabilities using the original transformer, we would’ve needed to use “compute efficiency gain” times more training compute:
This is why researchers often define the “effective compute” = “compute efficiency gain” × training compute. Because of the software innovation, we in effect have a larger compute budget that we can use to reach higher levels of capability. We can do more with the compute we currently have.4
Of course, this picture is oversimplified. For example, this assumes that the lines are parallel — more on that later. But even though it’s oversimplified, I think it helps clarify why it’s so important to understand software progress. For example, if AI software progress is really fast, then frontier labs could build AGI with much less compute than today’s software, which could mean building AGI much sooner. And if these innovations are easily replicable by many actors, the implications extend further: shortly after one lab makes a big algorithmic breakthrough, another lab catches up. Shortly after frontier LLMs become good enough to help novices develop bioweapons, the novices will have enough compute to train these LLMs themselves. No wonder some people are so nervous about this!
But whether these implications actually hold depends on the numbers. How fast is software progress in practice? If we’re right about this theoretical framing, then this could be one of the most important questions for what AI will look like over the next few years. So let’s take a look at the evidence.
II. How fast is AI software progress?
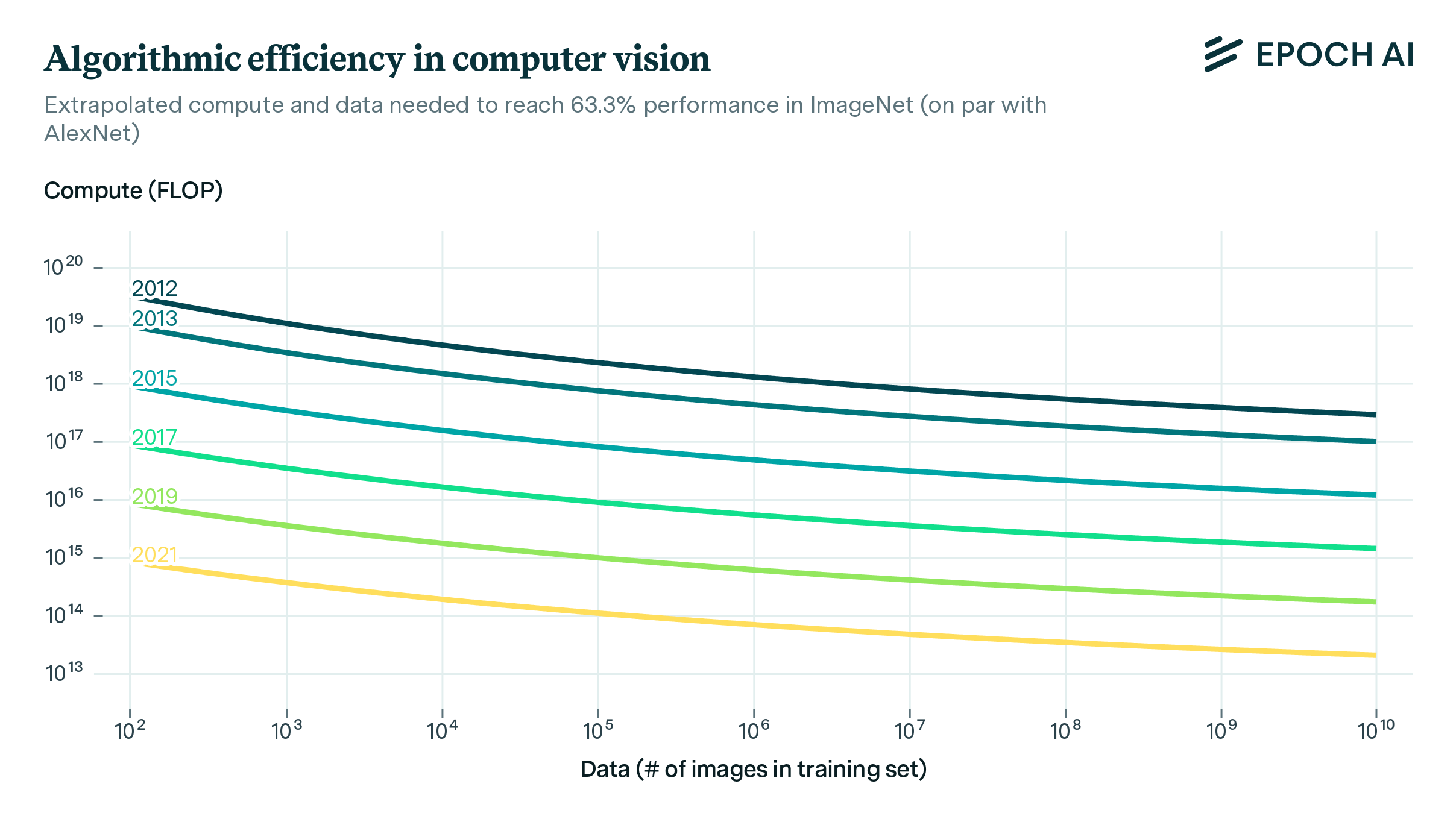
To answer this question, I searched through the literature for AI software progress estimates, some of which I contributed to.5 In the case of pre-training, this looks very fast, on the order of several times per year:
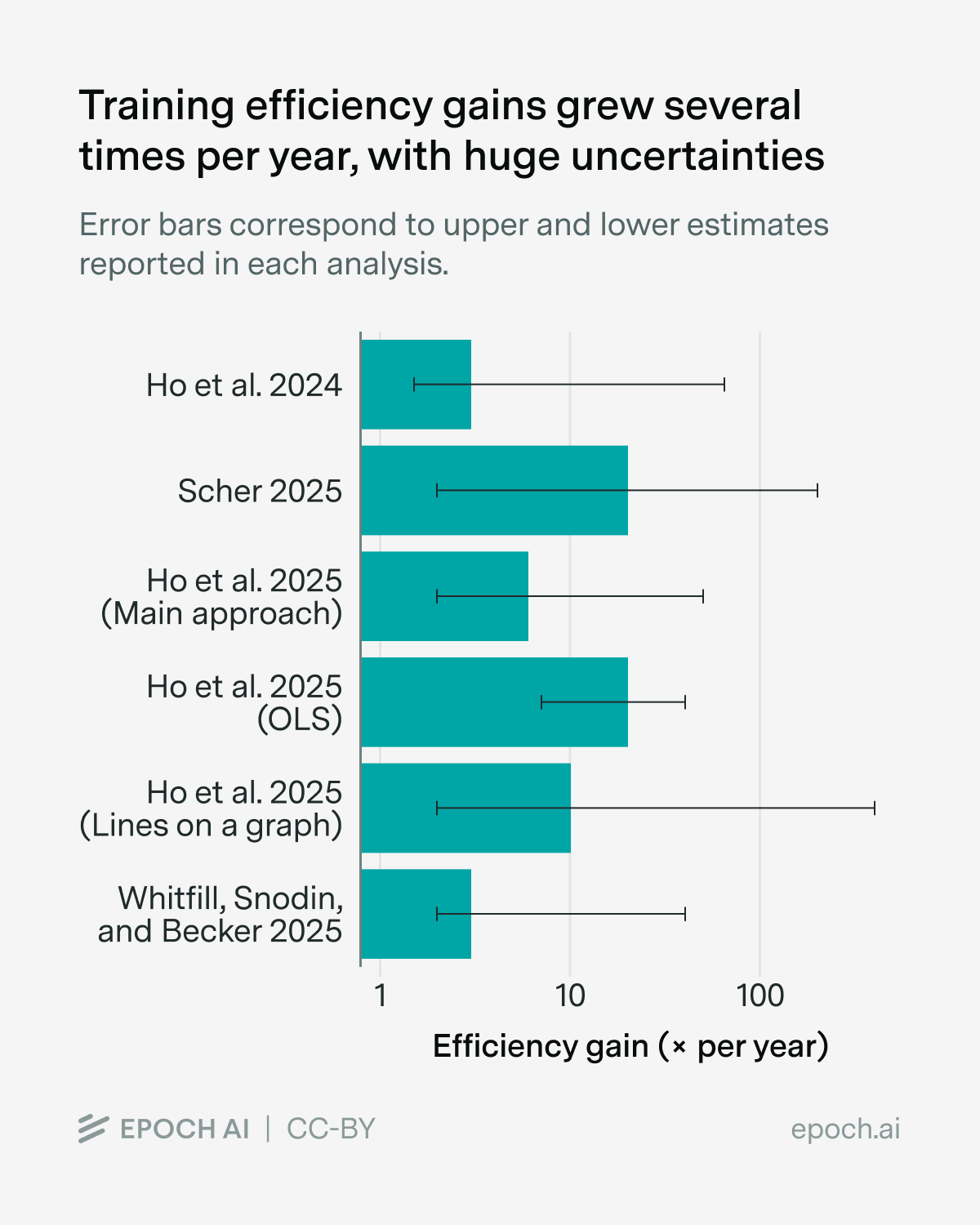
You can find the full data and sources in the Appendix.
Again, this means that we need several times less training compute each year to reach the same capability — that’s super fast! But I don’t think we should trust these specific numbers very much because they’re full of problems, and you don’t have to squint very hard to see them. First of all, the error bars look almost comically wide in the graph above — across the different estimates, they range from around 1.1× to 300× per year! That’s why I say “several times per year” rather than any particular number — it seems pretty plausible based on the range of estimates, but I don’t want to signal too much confidence.
Why are these estimates so uncertain? I think the biggest reason is that there’s not enough high-quality data out there. All the estimates in the graph above are based on observational approaches, which build a dataset of existing AI models and then try to back out an estimate from that. To do this, each model in the dataset needs three ingredients: (1) a training compute estimate, (2) a measure of its “capabilities”, and (3) a description of when it was released.6 But in practice we often don’t know the training compute, and it’s hard to find a capability metric that’s used for a long time, because things like benchmarks saturate too quickly to capture long-run trends. So we’re left with less data than we’d like, and more uncertainty than we’d want.7
These uncertainties are compounded by how we estimate the rate of progress. For example, one approach is what I like to call the “lines on a graph” approach — pick a capability level, find models that achieve it with less training compute over time, and measure how fast that compute requirement falls.8 That looks like this (hence the name of the approach):
(Source) The “lines on a graph” approach to estimating the rate of AI software progress. The rate of progress is given by the slope of the line.
Unfortunately, because we don’t have large datasets, these “lines on a graph” are fit with only a handful of data points, making the estimates really noisy. On occasion this can yield ludicrously fast estimates, like 30,000× per year or even \(5^{12}\times\) per year!9 We can mark these sorts of cases as obviously dubious outliers and focus more on the median trend across the lines-on-graphs, but it somewhat undermines my trust in this approach.
The other way to estimate the rate of software progress is what I’ll call the “fancy statistics” approach. Here the idea is to have some more complicated model relating compute, capabilities, and time, fit the parameters to the data, and then use that to back out an estimate. The key difference is that it’s more explicit about what this relationship looks like, whereas the “lines on a graph” approach is a bit more agnostic about that. So if the assumed relationship is wrong, that could throw off the estimates.
But for the most part, both approaches share similar weaknesses. For example, in one of my own papers I modeled software progress as growing exponentially and only depending on time. In doing so, I implicitly assumed that the “software quality” is the same across all labs at any point in time, which is clearly false — some labs have better algorithms and data than others. Parker Whitfill argued that this could bias the estimates to be substantially faster or slower — for instance, growth rates might be as much as 9× slower than what my paper estimates! Sadly for me, that’s potentially quite a devastating rebuttal.
Even if we set aside these uncertainties, there are still plenty of problems with all the estimates I showed you. For example, all the estimates fail to fully capture software improvements in post-training,10 which is especially egregious because reasoning post-training is now all the rage among frontier models. But the sad reality is that there’s not enough public post-training compute data to let us reliably work out a growth trend.11
One last problem I’ll raise has to do with how we measure “capabilities”. Typically this means looking at AI benchmarks, but models can be “bench maxxed” to do well on benchmarks in a way that fails to generalize to real-world use-cases. So if we measure software progress using only these metrics, we’d end up overstating growth rates — what if we’re just getting much better on the things that we can easily measure, and not so much elsewhere? My guess is that this should make us slightly more skeptical about fast progress, but not by that much, because we do see models generalizing to some extent. I wish I knew how to be more precise than that.12
Okay, so there are myriad problems and uncertainties with existing software progress estimates, some of them potentially quite devastating. Now what? If we could be so far off the mark, should we trust these numbers at all?
I think there’s still a decent case for software progress being “several times per year”. For one, the estimates above are based on different approaches and all suggest that these rapid growth rates are possible — I doubt that’s just a coincidence. It’s also consistent with numbers in computer vision reported by frontier AI companies, and corroborates Dario Amodei. What’s more, we can just look at example case studies. Here’s one example from last year, which suggests an annual growth rate of 2-5× per year:
(Source) gpt-oss-20b does substantially better than GPT-3 on MMLU, despite using the same amount of training compute. If we look at the relationship between pre-training compute and MMLU performance among non-reasoning GPT models, we can back out a rate of algorithmic improvement from this — this works out to around 2-5× per year.
Overall I’d say that the evidence looks pretty shoddy, so I don’t think it makes sense to confidently declare that “software progress is 3× per year” or any particular number. But I think we have enough evidence to think that software progress might really be several times a year, and to make a best guess contextualized with a lot of uncertainty.
So here’s my best guess: after accounting for all training compute (including post-training), I think we’re seeing software progress at around 10× per year, and my 80% credible interval would probably range from 2× to 50× per year. But again, this is the kind of thing that might change depending on the day and what I had for breakfast that morning.
III. What drives software progress? (Or, why all the estimates we just saw are misleading)
If we think about it a bit more, these estimates seem quite fishy: have model architectures and training algorithms really changed enough to justify something like a 10× per year rate of progress?
Consider GPT-2 and DeepSeek-V3. These two models were released almost six years apart, which at 10× per year would imply a million-fold difference in compute efficiency. That seems crazy, especially because they don’t look that different on an algorithmic level. Sure, DeepSeek-V3 is a mixture of expert model, uses different variants of Attention and positional encoding schemes, and so on — but how is that supposed to explain a factor of one million?
I think there are two plausible factors, both of which play an important role. One is that these improvements aren’t just coming from better algorithms — the bulk of this comes from better data. To my knowledge, the best argument for this position comes from Beren Millidge, who brings several pieces of evidence to the table:
- We’ve shifted from gnarly, uncurated web data to heavily processed and often synthetic data, which is strongly targeted towards the tasks that we want models to do well on. This could include techniques like filtering data and finding the right data mix to get better performance.
- Researchers have been throwing tons of effort into getting better training data. For example, Surge AI had a revenue of over $1 billion last August, and Scale AI was probably in a similar boat. I’d also add that this checks out with how OpenAI and Anthropic are spending in the billions on data-related costs — this includes RL environments, which are now very much a part of the AI zeitgeist.
To my mind, the strongest point here is about synthetic data (and distillation). These are techniques that could help models reach certain capabilities with much less training compute.13 Here’s an illustrative example from an article I co-authored last year:
The efficiency gains from distillation can be dramatic. DistilBERT, an early demonstration of this technique, preserved 97% of its teacher model’s capabilities while using 40% fewer parameters and requiring merely 3% of the compute budget that went into training the original BERT model.
In other words, in this case distillation made it possible to reduce training compute by something like thirty to forty times while keeping roughly the same capabilities.14 Synthetic data can help push beyond this — a good example that Millidge raises is the Phi series of models. So if you stack these kinds of gains, you can sort of see how this could help explain orders-of-magnitude improvements in software efficiency.15 But I’m still not totally sure, because some of the studies I listed in the previous section deliberately (try to) exclude distilled models and synthetic data while still finding absurdly fast rates of software progress. I’m not yet totally convinced that the numbers add up.
This brings us to the second explanation for ultra-fast-software-progress, namely that software improvements depend on the scale of training compute. To see what I mean, let’s go back to the picture we drew earlier to illustrate software progress:
This depicts software improvements as a parallel shift to the left. But what if it’s not parallel? What if the slope changes, for example like this?
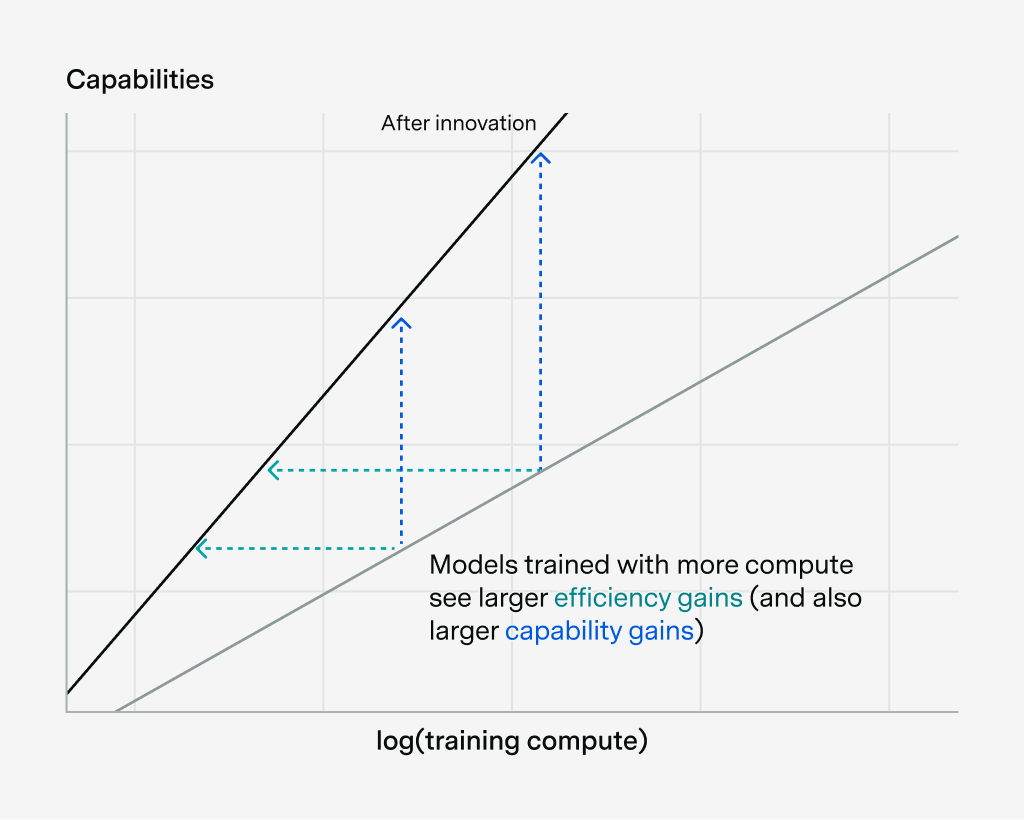
This illustrates how software progress can depend on the scale of training compute — in this case, models trained with more compute see larger efficiency gains (and also larger capability gains).
Now the line could also become less steep, and it doesn’t have to be a straight line — maybe there are some diminishing returns to log(training compute), for example. But the important thing is that the size of the compute efficiency gain could change with scale.
So how might this explain the really fast estimates of software progress? The idea is that software improvements may have made the line steeper, and since we’ve been scaling up training compute, we take advantage of these larger gains at scale. So when we measure software progress, this shows up as rapid efficiency gains.
The most direct evidence for this is the paper On the Origin of Algorithmic Progress in AI.16 Here’s one example where they compare the scaling of a modern Transformer architecture (purple) and an old-school LSTM (green):
This meshes pretty well with the stylized stick-figure diagrams that I’ve been showing you. The main difference is that the y-axis is flipped, where a lower “validation loss” means a higher capability. We can see that the Transformer has a steeper scaling slope, and the efficiency gains grow with training compute scale. At \(10^{15}\) FLOP the efficiency gain is 6.3×, whereas at \(3 \times 10^{16}\) FLOP the efficiency gain is 26×.
And these gains grow a lot as you scale up training compute — if you naively extrapolated the purple line to \(10^{23}\) FLOP the total efficiency gain is over 20,000×! If you work through the numbers more carefully, this works out to an annual improvement of 2.23× per year at \(10^{23}\) FLOP scales — so it’s easier to see how you can measure compute efficiency gains of several times per year.17
To my mind, these results lend quite a bit of weight toward the “scale-dependence” argument for how measured software progress has been so fast. I also think it has some intuitive appeal to it, because there’s been evidence for a while now that some AI architectures scale better than others.
But I don’t think this is really a slam-dunk argument either. For starters, I don’t want to over-index on one paper. The estimate of 2.23× per year is also substantially lower than my 10× per year best guess earlier, though this could change if the authors look at a broader set of innovations, or if they consider higher compute scales.18 There are also some suspicious aspects to this study: for example, it uses scaling experiments between \(10^{13}\) FLOP and \(10^{18}\) FLOP (or under \(10^{17}\) FLOP for LSTMs) to infer efficiency improvements as far as \(10^{23}\) FLOP — so it involves heroically extrapolating out five orders of magnitude. This is a problem because the result about scale-dependence might itself depend on which compute scale we’re looking at, which is very meta.19 Ideally, it’d be great to do something like this experiment but at larger compute scales, and also experimentally accounting for the gains from better data and post-training. Both of these are things that the paper glosses over.20
Overall, I’d say that both data quality improvements and scale-dependence play an important role — it’s not clear to me that the numbers totally add up with either approach. And each approach fails to explain certain observations — for example, capabilities have improved in the last year without much training compute growth. I think this is probably better explained by data quality improvements than scale-dependent innovations (though these aren’t mutually exclusive, since better data could itself change the scaling slope).
This means that almost all existing estimates of software progress were misleading. Many efficiency gains that we thought were from algorithmic improvements actually came from better data. And many efficiency gains that we thought came from continually inventing lots of new algorithms could’ve come from scaling up a tiny handful of algorithmic innovations!
In fact, this seems to be the case in practice, if you break down the 20,000× gains between the LSTM and Transformer that we saw earlier:
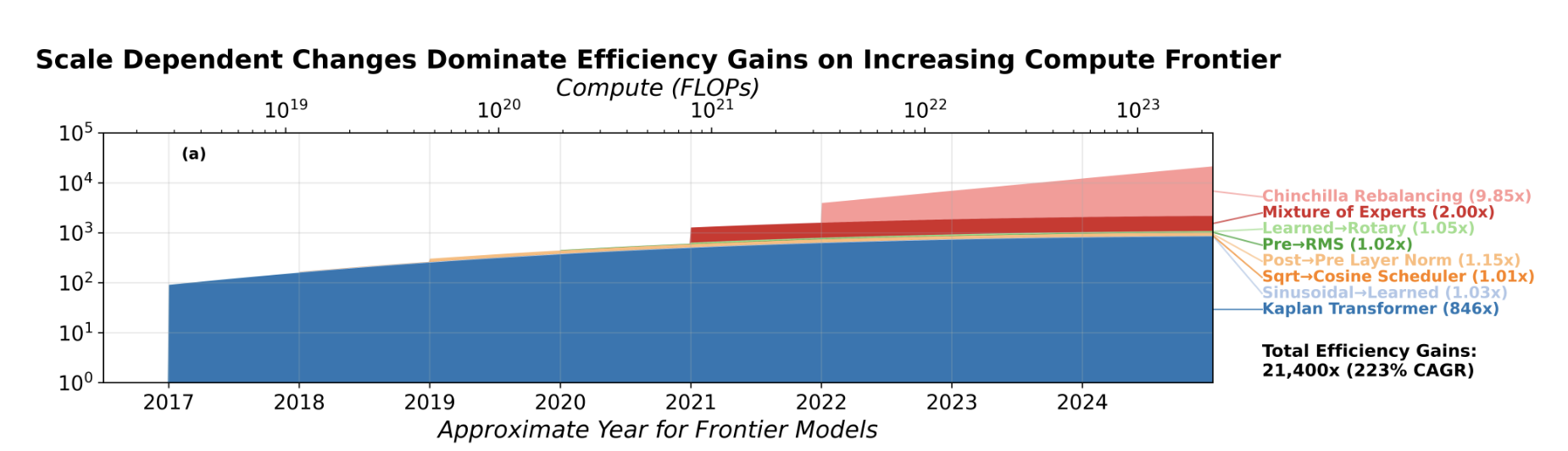
Note that the paper in question uses the Deep Learning Era trendline from Epoch’s “Notable AI models” dataset as the frontier of training compute. This is why the “compute frontier” is close to \(10^{23}\) FLOP in 2024-2025.
Here you can see that most efficiency gains came from two scale-dependent innovations — (1) the shift from LSTMs to the Kaplan Transformer, and (2) “Chinchilla Rebalancing”.21 Other innovations seem scale-independent and also contribute very little overall — they barely shift the curve to the left and don’t change the slope. So even if we measure fast software progress, it might just be because we’re scaling quickly — it may not have much to do with making further innovations.
IV. How this impacts the software intelligence explosion debate
Everything we’ve seen so far bears on one of the most important debates in AI — namely, how likely is a software intelligence explosion? The idea is that once you automate AI research,22 you’ll get a rapid feedback loop: the AIs get smarter (or more numerous), their research efforts drive more AI software progress, making the AIs even smarter (or more numerous) still, and so on.23
This matters a lot because if it’s true, it could engender an enormous amount of AI and societal change in the span of years. What does “enormous” mean? Well opinions on this vary a lot, but they often include things like eliminating most cancers, compressing a century of technological progress into a decade, or the extinction of humanity. Saying that the stakes are high would be the understatement of the century.
So how do the results we’ve seen — about the rate of software progress and its drivers — impact this debate? The short answer is that some existing analyses of the software intelligence explosion are based on overly conservative estimates of software progress, and essentially all of them are based on faulty assumptions.
To see why, consider the model that people usually use to study the software intelligence explosion, which relates AI research effort to AI software progress. The core parameter that relates these two is the “returns to AI software R&D”, which tells you how well you can turn more research effort into more software progress.24

This parameter has a key threshold: if it’s greater than 1, then you get a software intelligence explosion. And in practice, literature estimates suggest that might be the case (though it’s really uncertain):
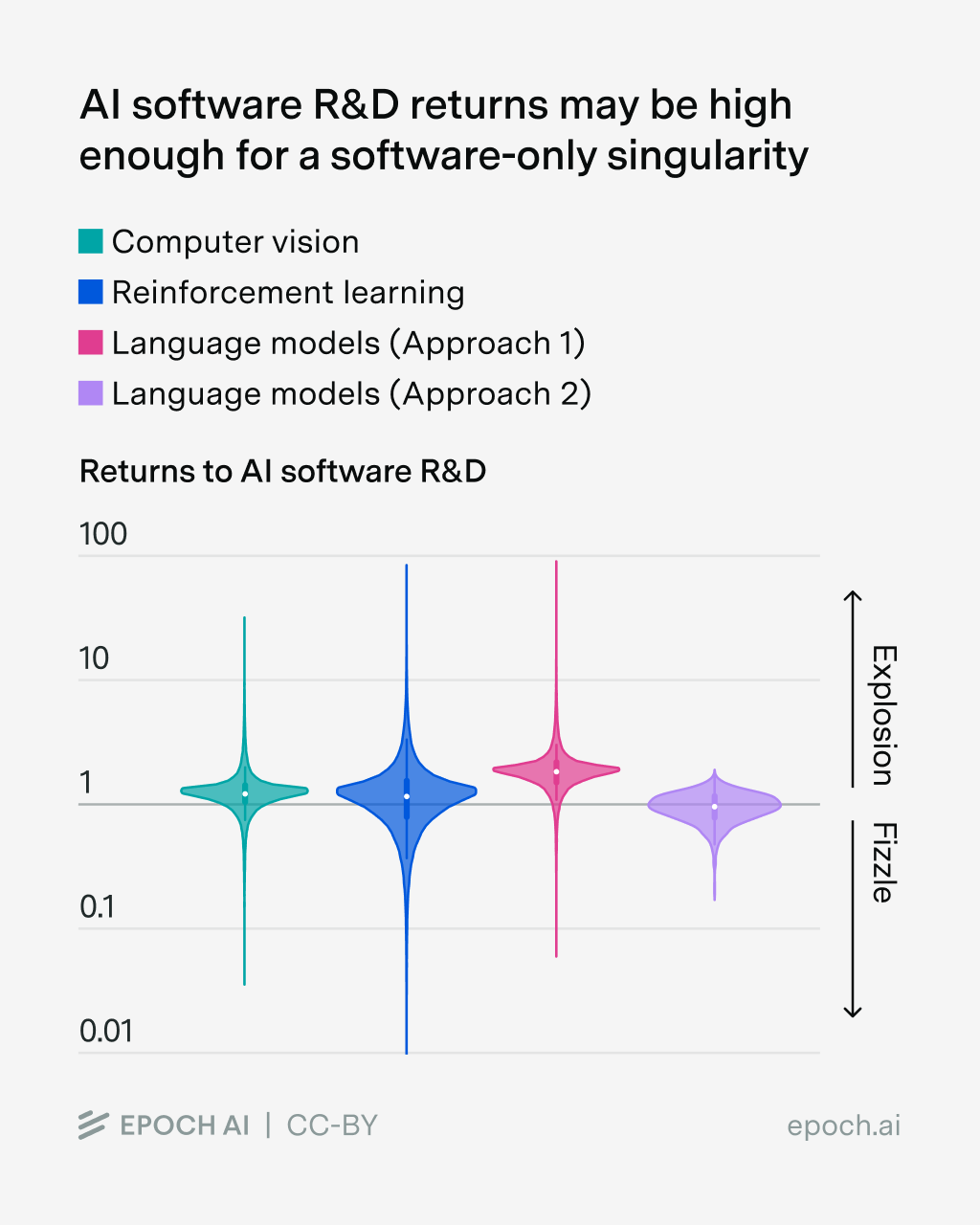
(Source) Estimates of the returns to AI software R&D are very uncertain but straddle 1. This suggests that an intelligence explosion is plausible, but it’s also plausible that the feedback loop of AIs improving themselves simply fizzles out.
However, as pointed out by Daniel Eth and Tom Davidson, these estimates rely on an overly conservative estimate of software progress of 3× per year (this is the Ho et al. 2024 estimate that we saw earlier). I now think that software progress is closer to 10× per year, so this change should increase the estimates of this parameter several-fold,25 making a software intelligence explosion seem much more likely.
But there’s also a good reason to think that these are drastic overestimates. That’s because existing models of the software intelligence explosion don’t account for how a lot of software progress could come from scaling training compute. Recall how scaling up training compute for just two innovations led to most observed efficiency gains between LSTMs and Modern Transformers, rather than humans discovering tons of new innovations.
Instead, existing models either assume that research effort is the only thing that matters, or assume that it depends on a mix of research effort and the compute used to run experiments.26 But to my knowledge, none explicitly account for training compute scaling being a source of software progress, so they could heavily overstate the importance of research effort.
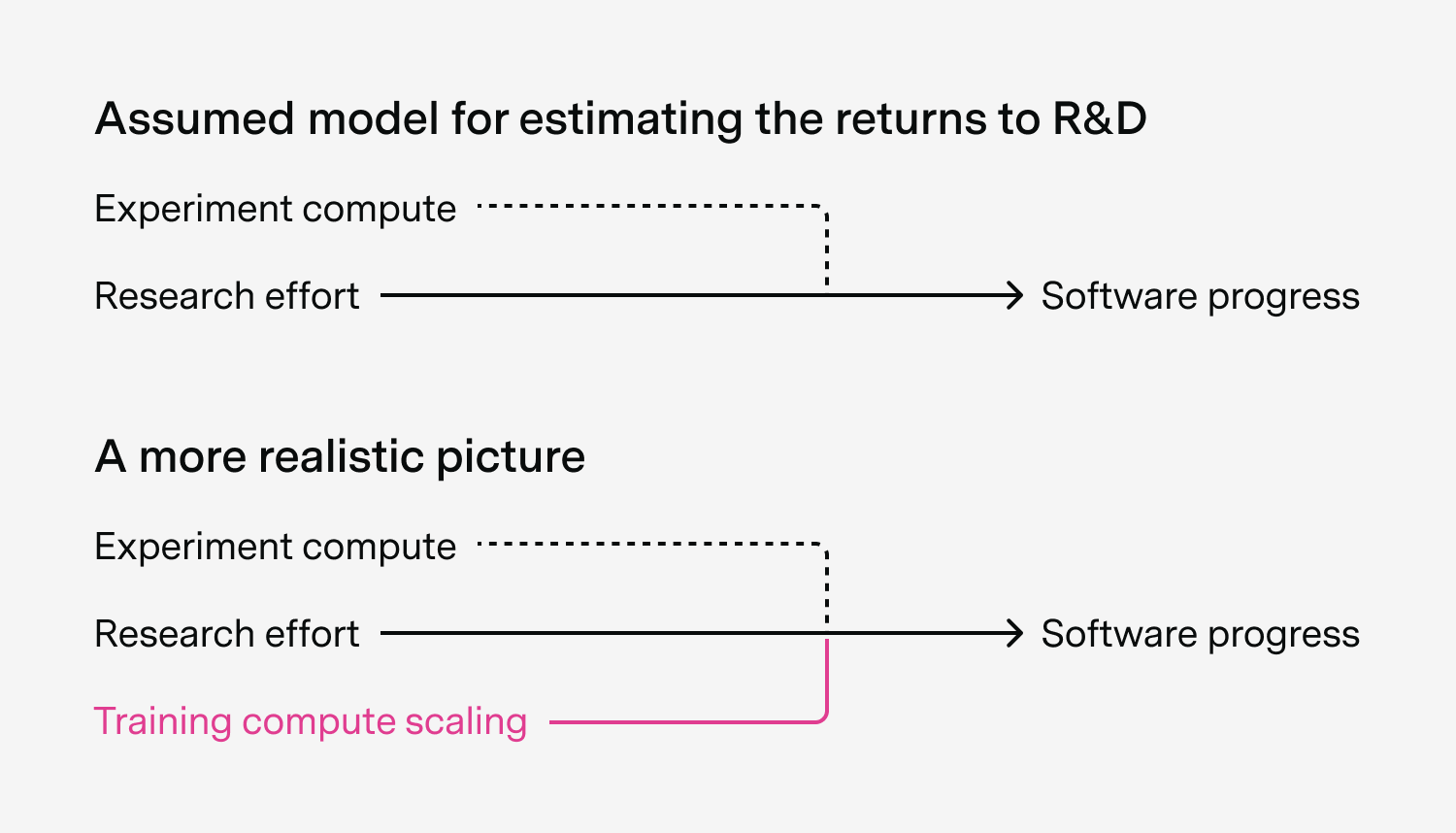
In effect, this means that existing estimates overstate the returns to software R&D, and makes the software intelligence explosion seem much less likely. One way to think of this is as a “compute bottleneck” — it’s hard to make super fast software progress without also scaling up training compute.
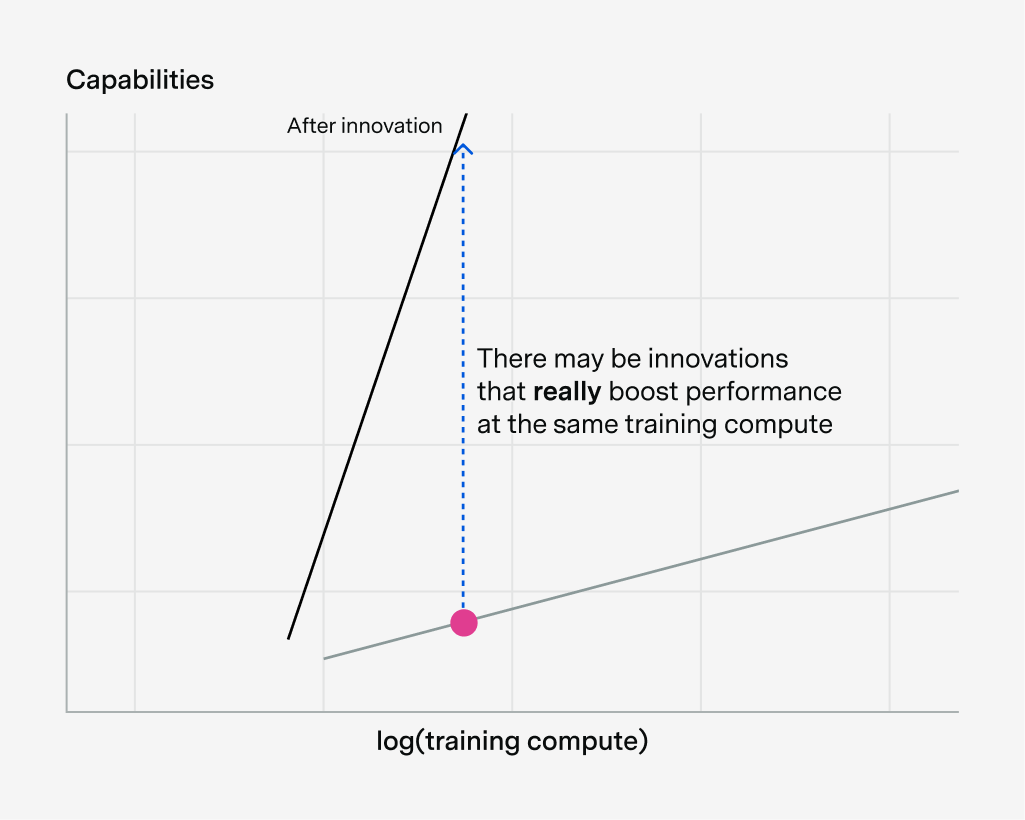
There are some reasons to expect that this training compute bottleneck can be overcome. For example, in principle there may be innovations that really boost performance at the same training compute, hence driving a lot of software progress. This could look like software innovations that scale really well, even if they don’t look great at small scales:
Alternatively, you could in principle find a ton of scale-independent innovations with big capability gains:
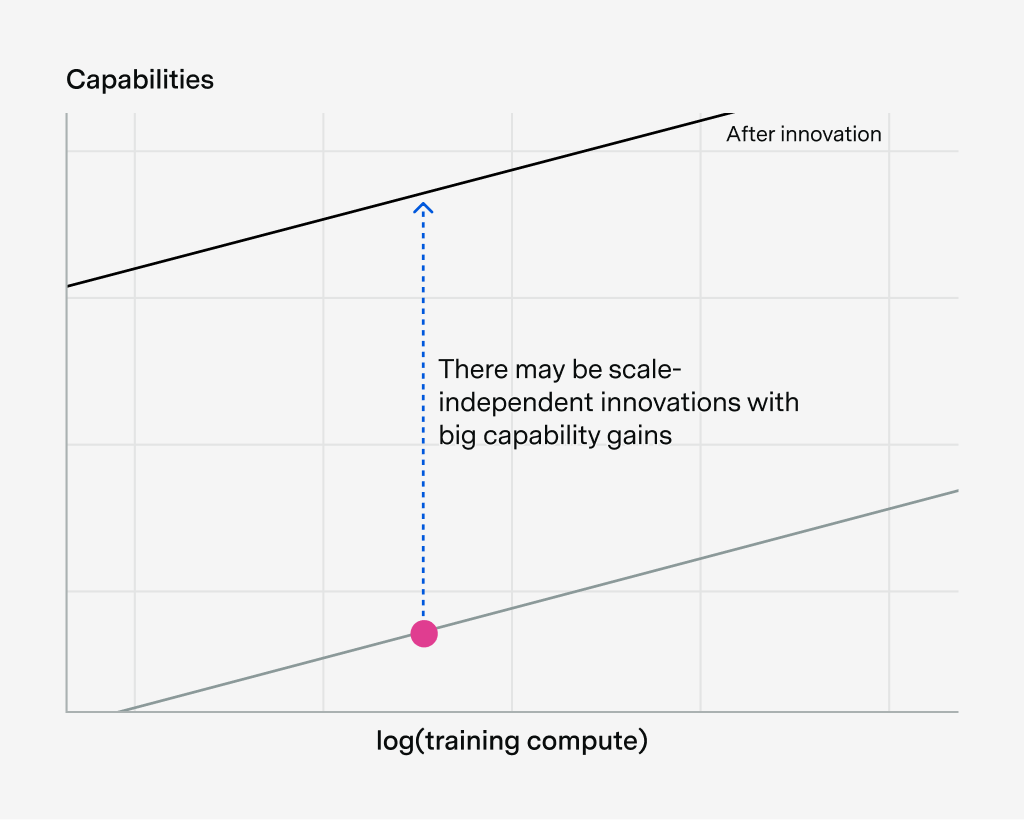
And of course you could get huge capability gains from a combination of scale-dependent and scale-independent improvements. If doing these things is easy, then you could skyrocket capabilities without increasing training compute very much.
My personal inclination is to say that these things are probably quite hard — otherwise, why haven’t we found these innovations already? But I can’t theoretically rule it out, and you could always say “maybe you can’t find these innovations, but if you had a country of geniuses in a data center, they certainly would! Not to mention what would happen if AGI is as smart as Von Neumann+++…”.
Moreover, the strength of training compute bottlenecks depends on the “scale-dependence” explanation for rapid AI software progress. But it may apply less well to software progress that’s driven by data quality improvements — perhaps you could have a software intelligence explosion just by building better RL environments! I don’t know to what extent this is possible, and in principle data quality innovations could also be scale-dependent, but I think it’s still a very important consideration.
There’s a lot more to the debate about the software intelligence explosion and its bottlenecks which is too long to get into here. But overall I think the upshot is this: some prior work on the software intelligence explosion is based on outdated estimates of software progress, which make an “explosion” seem more likely. On the other hand, essentially all existing work is also based on a heavily flawed model, making the “explosion” seem less likely. Personally I now think the software intelligence explosion is less likely than before looking into this, though I also think that the bottlenecks aren’t strong enough to preclude it altogether.
V. Conclusion
Let’s recap all the main things that we’ve seen:
- Software improvements are about reducing the training compute you need to get to the same capability, or doing more with the training compute you have.
- It progresses very quickly, with efficiency gains increasing several times per year. But these estimates have gigantic error bars, due to data limitations and statistical assumptions.
- The numbers might also be somewhat misleading. Much of the measured progress is plausibly driven by data quality improvements rather than algorithmic innovations. And it’s likely that a large share of measured efficiency gains reflects scaling up a small handful of scale-dependent innovations, rather than the continual discovery of new algorithms.
- If most efficiency improvements came from a small handful of scale-dependent innovations, then existing models of the software intelligence explosion may be flawed. Correcting for underestimated software progress makes an explosion seem more likely, but accounting for training compute bottlenecks from scale-dependent innovations pushes in the other direction.
Given all of this background, we finally have enough ammunition to answer the three questions I raised at the start of the essay:
Q: How did DeepSeek seem to catch up to OpenAI’s o1 within months, despite being trained with less compute?
A: If software really improves several times a year, it’s less of a mystery why DeepSeek was able to get close to o1 after a few months, especially if there was a lot of distillation involved.27 Peter Wildeford describes this in more detail here.Q: When will the world develop AGI?
A: No one knows for sure, but it’s likely that software progress matters tremendously. For example, one of the most prominent models of AGI timelines is Ajeya Cotra’s bioanchors model, which originally had a median timeline of around 2050. But as Scott Alexander points out, this may have been over a decade too long because Cotra underestimated AI software progress (Cotra’s most recent estimate is probably somewhere in the 2030s).Q: If we automate AI research, will AI progress accelerate like crazy a la Situational Awareness and AI 2027?
A: The answer is essentially Section IV. That is, nobody really knows, but you can form your opinion on it by answering two subquestions: (1) “What are the returns to AI software R&D?”, and (2) “Will compute be a major bottleneck to the software intelligence explosion?”. I lean towards the answer being “no” because I’d guess compute bottlenecks will be strong, but I think there’s quite a lot of room for disagreement.28
I hope these questions also help reiterate why AI software progress is such a big deal. These are foundational questions about competition between AI firms, and what happens to the world if we develop what would be the most influential technology in history. And the answers to them can be enormously swayed by the speed and nature of software progress — the problem is that we understand it so poorly that we can’t narrow down our uncertainty.
So what should we do? As a starting point, I want people to truly appreciate just how important software progress is. After that, we can try to do the best we can to understand it better. Perhaps that means running ablation experiments at larger compute scales, seeing what happens to software progress if researchers are compute-bottlenecked, or estimating software progress in post-training. And maybe some AI researchers already have good answers to some of this stuff, what do I know?
I think it’s going to be very hard to reduce our uncertainty, but at least in my mind, this topic is important enough that it’s worth giving it a shot.
I’d like to thank Aaron Scher, JS Denain, Josh You, Luke Emberson, Jaime Sevilla, David Owen, Parker Whitfill, Hans Gundlach, Brendan Halstead, Joshua Turner, Eli Lifland, Alex Fogelson, and Lynette Bye for helpful feedback and support. Special thanks to Aaron inspiring me to write this post in the first place.
Appendix: Estimates of software progress
The table below shows all the estimates used to generate the bar chart at the beginning of section II, as well as some additional estimates from post-training.29
| Reference | Stage | Software efficiency improvement | Approach |
|---|---|---|---|
| Ho et al. 2024 | Pre-training | 3× per year (95% CI: 1.5× to 64×) | Statistical model, lines on a graph |
| Scher 2025 | Mostly pre-training | Median estimate of 16× per year. Their all-things considered guess is 20× per year (80% CI: 2× to 200×) | Lines on a graph |
| Ho et al. 2025 | Mostly pre-training | Main approach yields 6× per year (95% CI ranges from 2× to 50× across different model families). An alternative approach using OLS yields 20× per year (95% CI: 7× to 40×). A “direct observation” approach yields a central estimate of 10× per year, with estimates ranging from 2× to 400× per year. | Statistical model, lines on a graph |
| Whitfill, Snodin, and Becker 2025 | Mostly pre-training | 3× per year (95% CI: 2× to 40×) | Statistical model |
| Davidson et al. 2023 | Post-training | Usually 5× to 30× for individual post-training algorithmic innovations | BOTEC |
| Anthropic RSP | Post-training | 3× per year (Informal estimate with no reasoning) | Unknown |
| Ho and Berg 2025 | Post-training | Roughly 10× efficiency gain from early reasoning models on benchmarks like GPQA and MATH | Lines on a graph |
-
Sometimes people call this “algorithmic progress” but I want to account for the possibility that these improvements are due to better data.

-
There are other ways to define “software progress” besides looking at training compute, which I’ll get to later in the post.
-
Here I’m just using “capabilities” as an abstract concept to illustrate what I mean in a simple way. But if you want something more concrete, you can consider the Epoch Capabilities Index, or log(METR time horizon). You could also consider something like benchmark performance, but then the assumption of a straight-line relationship doesn’t make that much sense there.
-
This definition of effective compute breaks down somewhat if you include distilled models — that’s because the compute efficiency gain largely comes from being able to use data from an existing larger model. In particular, if you’ve only trained models up to \(10^{25}\) FLOP, distillation would shift the curve left, but it doesn’t allow you to access higher capabilities with the same \(10^{25}\) FLOP.
-
I’ll primarily focus on LLMs for this post, because these are the most prominent AI systems (e.g. ChatGPT probably has close to a 1 billion weekly active users by now), and are the main kind of model that are pushing towards “AGI”.
-
Strictly speaking, Ho et al. 2024 uses data on the parameters and data rather than the training compute (which is related to the product of the two).
-
It’s also hard to get data about counterfactuals just from observational data — for example, it doesn’t really tell us what happens if we scale up GPT-4 by ten times, using the techniques available at the time. We could try to figure this out by running experiments, but that’s a different approach altogether.
-
Specifically we consider a narrow range of capabilities rather than a single capability level, otherwise we wouldn’t find any models at all!
-
The 30,000× number comes from the “Results table” in the post, with a capability threshold of 45. The \(5^{12}\times\) per year improvement arises due to the following problem: GPT-5 was released about a month after Grok 4 and used around 5× less training compute, while achieving similar performance, implying a rate of \(5^{12}\)× per year. But it’s not clear that this actually reflects genuine software progress.
-
Whitfill, Snodin, and Becker 2025, Ho et al. 2025, and Scher 2025 include some gains from post-training, whereas Ho et al. 2024 explicitly only considers pre-training. In practice, all papers may reflect pre-training to a large extent, because there is little public data on post-training compute, which is needed to properly estimate post-training software progress.
-
The main estimate I know of is one from Anthropic’s Responsible Scaling Policy, which incidentally is also 3× per year. Sadly this number doesn’t look like it’s meant to be taken seriously — Anthropic describes it as an “informal estimate”, and gives no reasoning for it.
-
Incidentally, this is one of the reasons that Ajeya Cotra shifts her estimate of software progress downward in her bioanchors report, and Tom Davidson employs a similar argument in his work on takeoff speeds.
-
This depends on how exactly we measure “training compute”. For example, both model distillation and synthetic data generation often rely on using a larger model to help develop a smaller one. But typically when we count training compute, we focus only on the small model, which neglects the compute needed to train the large model. When we then use these (understated) training compute estimates to measure software progress, we then pick up a big efficiency gain.
-
This is probably less relevant for frontier models, though I’m not sure that’s universally true. For example, I think there’s some chance that o3 was in part distilled from GPT-4.5.
-
Interestingly enough, my coauthors and I tried decomposing software progress in language models and found that most of it comes from data efficiency improvements (as opposed to parameter efficiency), which is consistent with this hypothesis. But I think this is pretty weak evidence because the confidence intervals are super wide, and sometimes the fit would suggest most gains were from parameter efficiency instead, after making small tweaks to the optimization setup. The overall compute efficiency result seemed a lot more stable though.
-
Another example that shows scale-dependence of software progress in RL is Figure 2 in Khatri et al. 2025, which shows how improvements to RL algorithms change the slope of training curves.
-
Unfortunately, existing estimates just don’t really account for this. The “fancy statistics” approaches tend to assume away scale dependence, and the “lines on a graph” approaches don’t have enough high-quality data to reliably identify it. I only know of two exceptions to this, that try to account for efficiency contributions in a very granular way.
-
My current impression is that there’s no clean way to directly compare the numbers from existing estimates (which ignore scale-dependence) and the numbers from this paper — they’re measuring somewhat different things. The paper instead proposes a plausible justification for several-times-per-year estimates of software progress.
-
Having spoken with the first-author of the paper (Hans Gundlach), my impression is that the project was pretty compute-constrained, hence the small-scale experiments. Somebody give them more compute!
-
Specifically, the paper doesn’t account for post-training improvements, and it uses a literature estimate for data improvements (rather than accounting for this experimentally).
-
The latter refers to the shift from using Kaplan scaling laws to Chinchilla scaling laws in Transformers — Chinchilla uses a different ratio of training data and parameters to get higher performance with the same compute.
-
I think the proponents of this view also think that AI will lead to substantial speedups well before AI research is fully automated, but the real hyperspeed feedback loop really comes when AI can fully do AI R&D, removing the last human bottlenecks in the chain.
-
Note that the case of more numerous AIs involves improvements in inference efficiency, which is separate from the training efficiency estimates I discussed earlier.
-
Technically speaking, this parameter tells us how compute efficiency changes when you double cumulative research effort. If doubling cumulative research effort also doubles compute efficiency, then the returns to R&D are 1. If it quadruples, then the returns are 2. In general, if the output increases by \(2^r\), then the returns are \(r\).
-
One caveat is that I’m uncertain what the rate of software progress was prior to the recent rise in post-training. I think it’s possible that progress has sped up in recent years.
-
Why include experiment compute at all? The idea is that if you don’t scale up your innovations, you don’t know how it’s going to work, so you need a lot of compute to do large-scale scaling experiments to test this out. This would thus pose a big compute bottleneck, and it seems to be backed up by claims from frontier lab AI researchers. For example, Alex Paino (who helped pre-train GPT-4.5) describes how lots of software innovations “look good at small scale, but don’t look good at large scale.” Relatedly, some innovations like RLHF and reasoning training plausibly would’ve been a waste of time with small models like GPT-2, but likely become very important at the scales of GPT-4 and GPT-5. The ideas for both of these could’ve come about (or actually did come about) at smaller scales, but scaling up was essential to seeing if they would actually work.
-
Though catch-up between US and Chinese models isn’t all about distillation either, as Nathan Lambert recently argued.
-
It also depends on what “accelerate like crazy” means — I think AI progress would definitely speed up, but I’m more skeptical of something like “5 orders of magnitude of software progress in a year”. I’d probably still give it something like a 15% chance though!
-
Note that Parker Whitfill noticed a bug in the code for Ho et al. 2024, although this didn’t change the numbers very much. Moreover, the reported confidence interval for this study was calculated after using updated data, so it’s wider than the numbers shown in the original paper (although the original central estimate remains the same).
About the authors
Related work