This week’s post is a collaboration between writers from Google DeepMind’s AI Policy Perspectives substack, and Epoch AI.
When the EU AI Act was drafted, pre-training compute was a reasonable proxy for model capabilities. At the time, pre-training accounted for 90-99% of total training compute, and the relationship was relatively reliable: more compute meant larger models pre-trained on more data, which consistently translated to stronger capabilities.
This simple proxy has been steadily breaking down. While pre-training compute remains a primary driver of capabilities, modern AI development leans heavily on distillation, synthetic data generation, reward models, and reasoning post-training. These methods can consume significant compute and drive capability gains, yet are often unaccounted for in current regulatory frameworks.1
The standard approach for measuring compute, used by the now-defunct Biden AI executive order, is to sum compute across two stages: “pre-training” and “post-training.” If the sum crosses some predefined threshold, the model is subject to additional scrutiny.2 But as training methods continue to evolve, this metric risks measuring an increasingly narrow slice of the factors that produce advanced capabilities.
The current approach faces three main issues:
- Not all uses of compute contribute equally to model capabilities: For example, recent “reasoning training” methods during post-training often yield higher capability gains compared to other post-training interventions, per unit of computation.
- AI labs can use compute for methods beyond pre/post-training: Besides pre-training and post-training, compute-intensive techniques like distillation and reward model training also directly impact model capabilities.
- When deployed, an AI model’s downstream capabilities depend on more than the compute used to train it: Downstream model capabilities are heavily influenced by the tools and systems available during deployment, such as coding environments and web search access.
These challenges mean that current compute-based AI policies are built on increasingly unreliable proxies for model capabilities. This doesn’t necessarily make such policies moot — they still offer key advantages that many other approaches lack. But compute metrics may need to be periodically assessed to ensure they capture the main drivers of capabilities, and updated if they do not do so adequately. Furthermore, it could help to research better metrics, complement compute metrics with a broader evaluation regime, and focus on governing AI applications or organizations.
1. Not all uses of compute contribute equally to model capabilities
Training frontier large language models can roughly be broken down into several distinct stages. The first is “pre-training,” where models are trained to predict the next token in a large corpus of text, imbuing it with the ability to output sentences in natural language. The second is “post-training,” where various additional techniques are implemented to refine the model. These can help improve the model’s reasoning abilities or prevent the model from responding to user requests in malicious ways.
Importantly, these different training techniques have varying compute-to-capability profiles. The most pertinent example of this is reasoning training, a type of post-training that helps language models develop more sophisticated problem-solving and reasoning abilities. This typically involves multi-stage pipelines that combine techniques like supervised fine-tuning and reinforcement learning (RL), and allows models to think for longer (“inference scaling”).
In current language models released by frontier AI labs, it’s likely that reasoning training yields higher marginal capability returns than pre-training. We can see this by looking at major model releases over the last year.3 Consider the language model GPT-4o and its counterpart o1-high, which has undergone additional reasoning training and inference scaling. Despite using a small amount of extra compute,4 performance jumps from 48% to 77% on the GPQA Diamond benchmark, and from 50% to 95% on MATH Level 5. While the effectiveness of reasoning training relies on a strong pre-trained base model, once that foundation exists, the marginal returns per FLOP are much higher than further pre-training. Had OpenAI instead used the same amount of additional compute to simply continue pre-training, the performance would have barely changed.
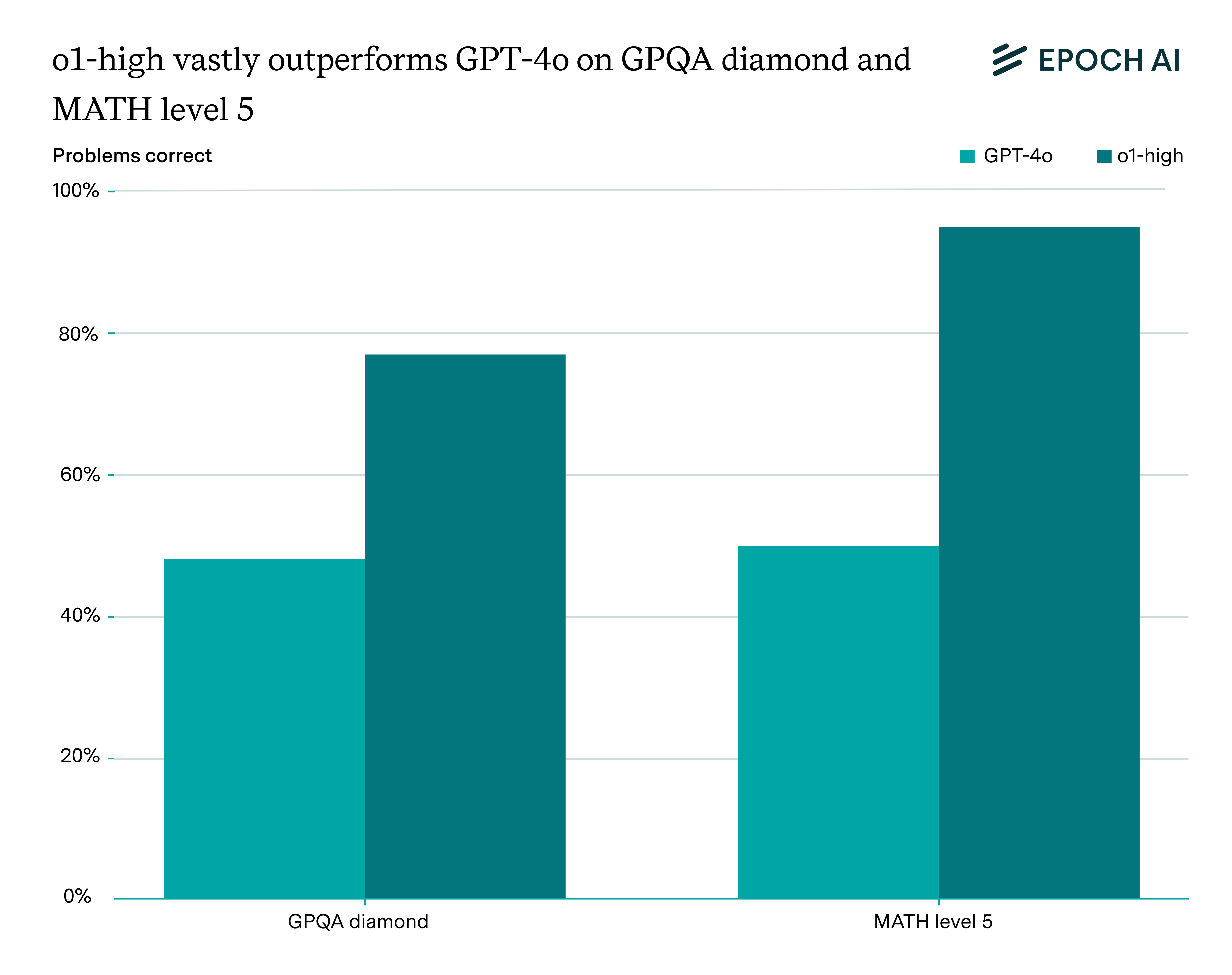
o1-high substantially outperforms GPT-4o on GPQA Diamond and MATH level 5 after a small amount of reasoning training. If this additional compute used for o1 post-training had instead been spent on further pre-training GPT-4o, the capability gains would have been negligible. This suggests that reasoning training FLOP yield far higher marginal returns than pre-training at this scale.
When governance efforts aggregate training FLOP into a single figure, they risk missing this outsized impact per FLOP and underestimating a model’s true capabilities. Importantly, this effect could grow as the share of compute dedicated to reasoning training increases. In the example above, the amount of compute allocated to reasoning training for o1-high was likely less than 10% of the pre-training compute for GPT-4o. But reasoning training compute has grown roughly 10× every three to five months, far outpacing the 4-5x annual growth in pre-training compute, and could soon constitute the majority of total training compute in frontier models.
As this happens, a raw sum of pre-training and post-training compute risks becoming a progressively worse proxy for model capabilities. If post-training continues to yield a strong compute-to-capability ratio at higher compute scales, a future model could be trained with a fraction of the compute specified by existing thresholds, yet still achieve capabilities that far exceed those that the threshold was intended to capture.
2. AI labs can use compute for methods besides pre/post-training
Even if we properly account for the relative importance of pre-training and post-training compute for increasing capabilities, issues remain. One such issue is that there are other uses of compute that matter for model performance, but are nevertheless missed by existing compute metrics. In this section, we consider three examples: knowledge distillation, synthetic data generation, and reward models.
Knowledge distillation
The first overlooked method is knowledge distillation. In this process, a smaller “student” model learns from a larger “teacher” model by being trained to mimic the teacher’s intermediate outputs (“logits”). With a strong teacher, this method can deliver higher marginal capability per student FLOP than doing standard pre-training on the same student model.
The efficiency gains from distillation can be dramatic. DistilBERT, an early demonstration of this technique, preserved 97% of its teacher model’s capabilities while using 40% fewer parameters and requiring merely 3% of the compute budget that went into training the original BERT model.
Given the setup, we need to account for three sources of compute: the student’s training, the teacher’s training, and the teacher’s generation of logits. However, current policies typically only count the compute from the student run, ignoring the upstream teacher compute that largely determines what the student model can learn.
Distilling models is increasingly becoming standard practice among frontier AI labs, serving smaller, more efficient models that are distilled from a teacher model. For example, Meta trained the mid- and small-sized Llama 4 models by distilling them from the larger “Behemoth” model.5 The reason for distillation is straightforward: running smaller models is typically faster and requires fewer computational resources. So as this practice becomes increasingly common at the frontier, current regulatory compute metrics risk underestimating model capabilities.
Synthetic data generation
Related to distillation, frontier language models are increasingly being trained on output text generated by other language models.6 If a lot of synthetic data is generated, this can constitute a pretty substantial fraction of total training compute. For example, generating synthetic data for the phi-4 model comprised ~25% of its pre-training compute budget, leveraging a separate stronger model (GPT-4o) to produce the training material.7
While the EU AI Act does include synthetic data generation in training compute, the Biden AI Executive Order did not. Either way, synthetic data pipelines are quickly evolving in ways that simply counting FLOP may not fully capture. For example, Kimi K2 used models to generate entire post-training environments with tool specifications, tasks, evaluation rubrics, etc. These kinds of environments structure how models learn, yet the compute behind them isn’t neatly captured by current FLOP-counting rules. Models can also be used extensively for data curation, such as by assessing data quality, filtering, and augmenting data. This could mean taking a basic math problem and generating individual reasoning steps. These examples illustrate how current compute metrics may miss the full scope of what “synthetic data” entails.
Reward models
Reward models are another compute investment that regulatory frameworks miss. These are individual models that are trained to provide feedback signals for RL algorithms. The quality of these feedback signals directly determines RL effectiveness and what capabilities the models ultimately gain, yet the compute invested in building reward models remains entirely unaccounted for. This process is computationally intensive: labs might generate millions of model responses to prompts, requiring substantial inference and training compute.
We saw the importance of reward models in this year’s International Mathematical Olympiad, where AI systems from OpenAI, Google DeepMind, and Harmonic all won gold medals. Notably, OpenAI researchers credited their success to a robust “universal verifier” and reward models. But despite this importance, the substantial computational investment in training and running these reward models remains invisible to current regulatory compute metrics.
The diversity in training methods challenges standardized compute metrics
The three examples we’ve seen point towards the complicated reality where there are many different forms of training compute. Each of these implementations represents just one approach among many possible variations. For instance, distillation alone can include progressive distillation, multi-teacher setups, and self-distillation, while synthetic data generation can be everything from simple augmentation to complex multi-agent simulations. Each variation has potentially different compute-to-capability profiles, further complicating any attempt to create standardized compute metrics.
Beyond the broad set of techniques, we also need to understand how these training methods interact with each other. For example, the compute-to-capability profile of reasoning training could depend on the strength of the pre-trained model and the reward model. As the complexity of training pipelines grows, we need to account for more and more of these interactions.
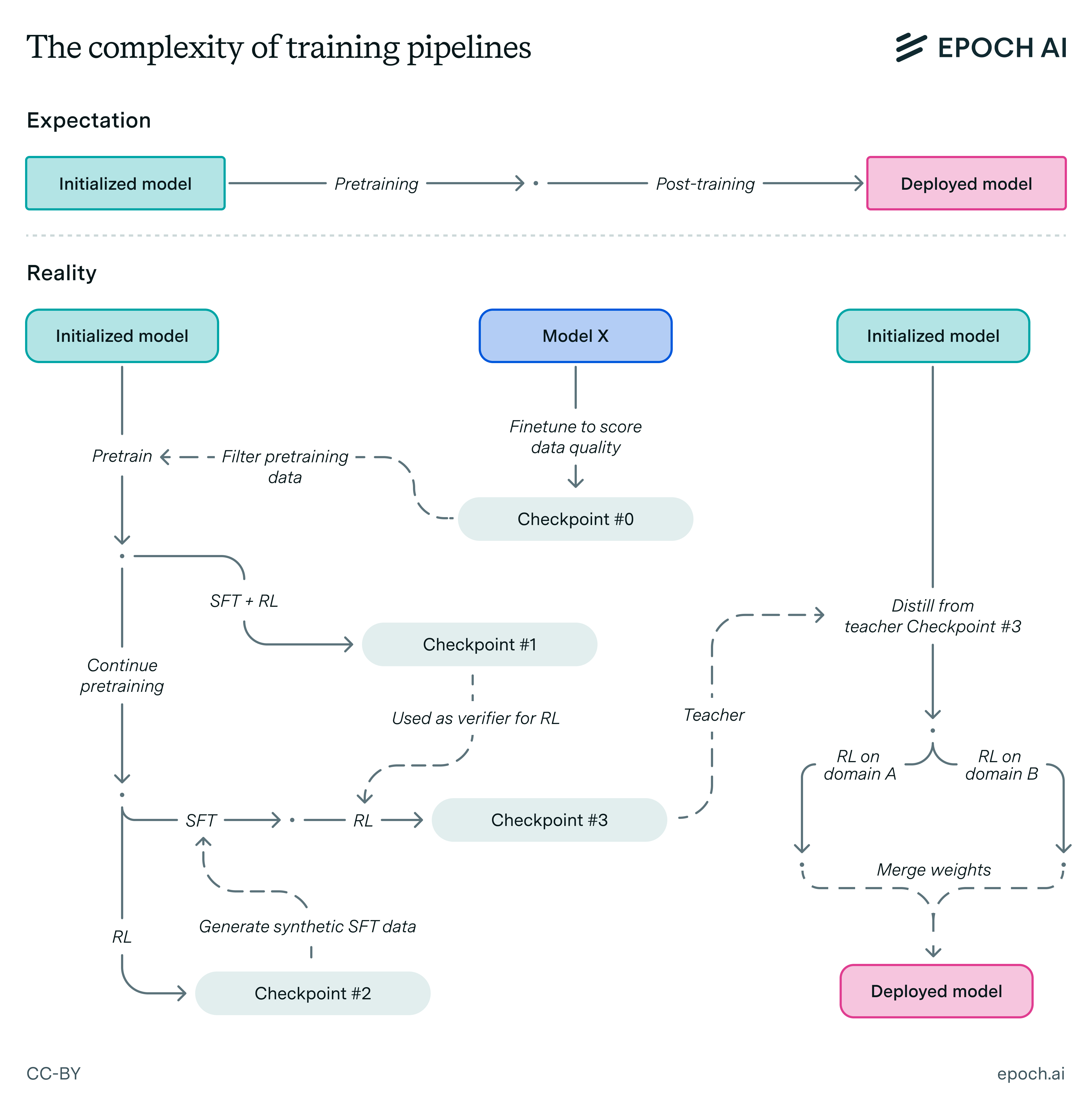
While prior regulations have largely focused on a simple pre/post-training distinction, in practice training compute can come in myriad forms that are intertwined in a complex pipeline.
Even if these additional sources of training compute were accounted for, we still have a poor understanding of how these sources of compute individually contribute to capabilities, let alone how they interact. This makes it difficult to construct robust metrics that appropriately proxy for capabilities, given the information we currently have.
3. When deployed, an AI model’s downstream capabilities depend on more than the compute used to train it
Even if we could address the measurement challenges above, compute would still be an imperfect metric. This brings us to a third and final point: when deployed in the real world, a model’s capabilities depend on more than the amount of compute used to train it. In particular, users are increasingly interacting with products or applications that are built around individual models. This means that the overall observed capabilities will also depend on the inference budget and scaffolding around models, such as tools for coding or web browsing.
One notable example of this is Anthropic’s product Claude Code. This transforms the base Claude model into a far more capable coding assistant through sophisticated scaffolding, giving it access to external tools and databases. These capabilities were enhanced through design and integration choices rather than from additional training compute.
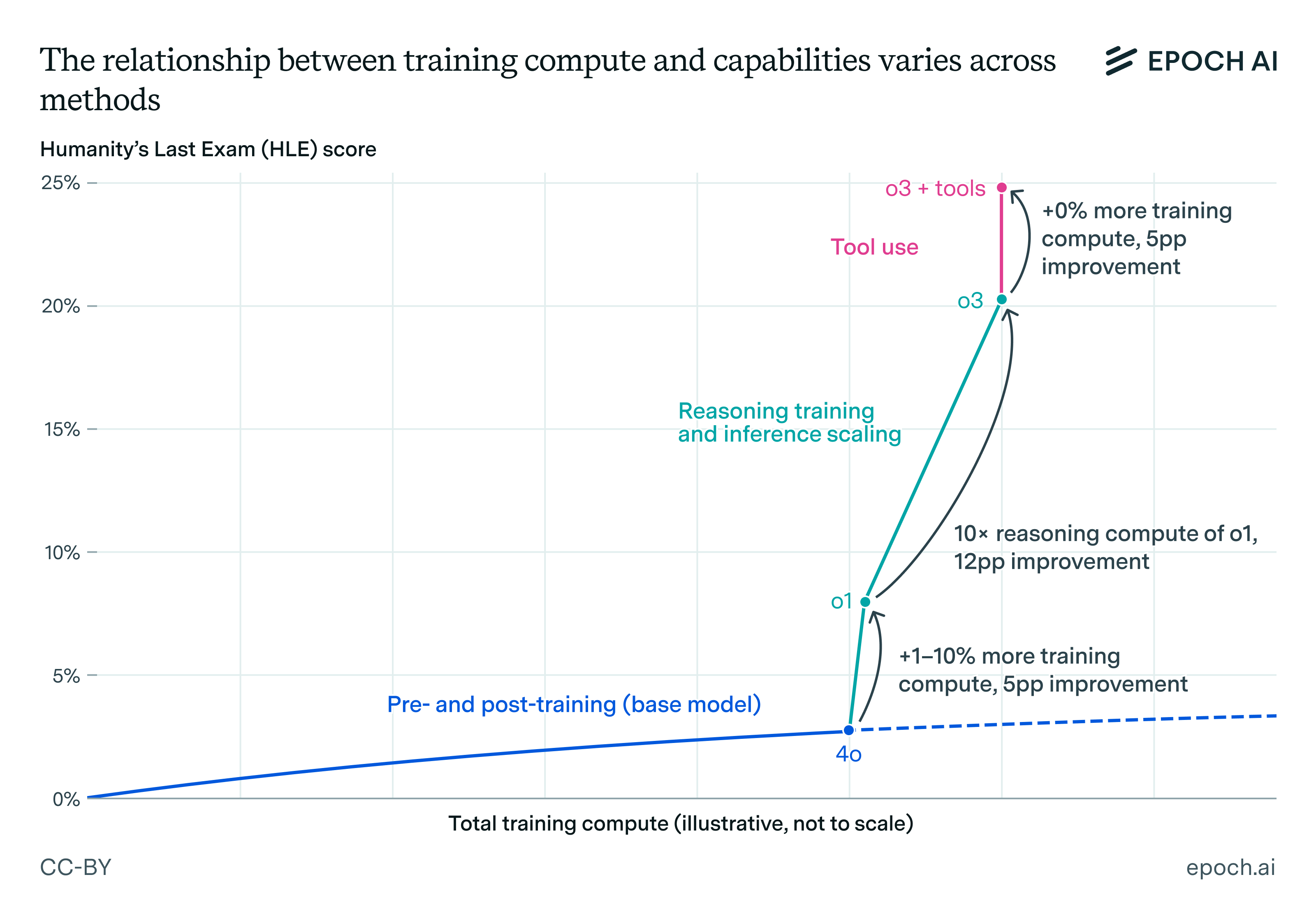
Tool use boosts model performance without additional training compute. As shown here, o3 + tools significantly outperforms o3, highlighting how compute-based thresholds miss the impact of scaffolding and tools. Note that the estimates of training compute are speculative.
This point is essentially missed by current compute thresholds, which instead focus more on the model’s structure (i.e. its training compute) rather than on its function (i.e. what the overall model can do given access to tools). The risk is that this blind spot will only grow, as system design itself improves over time and the capability gap between a raw model and the same model integrated into a well-designed system progressively widens.
What does this mean for AI public policy?
Given the rapidly evolving relationship between compute and capabilities, does this mean that compute metrics are moot? Not necessarily. Training compute offers compelling advantages. It is roughly allocated before training begins, auditable after, and comparable across organizations. Moreover, frontier capabilities will likely continue to arise at the top of compute spend. For governance purposes, the goal of compute metrics could be to identify which models deserve scrutiny rather than precisely predicting their capability levels.
However, as training pipelines evolve, factors beyond pre- and post-training could increasingly drive capabilities while remaining invisible to current compute metrics. The risk is that current compute metrics may become progressively worse proxies for even identifying which models are pushing the frontier, if the compute we’re counting represents a shrinking portion of what actually drives model capabilities.
If policymakers want to continue using compute metrics as part of a broader AI governance portfolio, they could consider several ways to address the aforementioned issues.
- Researching better compute metrics and thresholds. At present, our understanding of the relationship between compute and capabilities lacks a robust empirical foundation, and it’s possible that this will continue as different ways of using “compute” become common. At a minimum, updating these regulatory frameworks would require a better understanding of this relationship. The goal of course isn’t to create a perfect proxy, but with proper data collection and analysis, we can better understand to what extent current metrics need to be modified, discarded, or reserved only for frontier models.
- Building a more robust and expressive evaluation regime. Training compute doesn’t need to be the only input for determining downstream capabilities. For example, it can be combined with a range of other evaluations, such as automated benchmarks and expert-teaming. These help generate a more reliable portrait of a model’s capabilities, especially those of greatest concern to policymakers.
- Focus on application- or organization-level regulation. While a lot of emphasis has been placed on regulating individual AI models, policymakers could also consider focusing on regulating AI systems in the applications where the most significant risks could materialize. Regulation could also be done at the level of an organization, abstracting away from issues about the precise definitions of certain kinds of compute.
These approaches may help directly improve compute metrics, or at least make them less load-bearing in policy decisions. What policies make the most sense is also likely to evolve over time, so it’s crucial to continue monitoring the changing relationship between compute and capabilities. Policies can then be adapted based on updated evidence.
We would like to thank JS Denain, Conor Griffin, Jaime Sevilla, Alexander Erben, and Zhengdong Wang for their feedback and support.
-
If the only change were algorithmic progress in pre-training, policymakers could address it by periodically updating compute thresholds. The core issue we highlight, however, is that the training pipeline itself is evolving and new vectors are driving model capabilities. We lack a clear understanding of these methods’ compute-to-capability profiles and of how their interactions affect overall capabilities, making simple threshold updates likely insufficient.

-
Epoch AI estimates a model’s training compute the same way, taking an unweighted sum of its pre-training and post-training compute while excluding ancillary compute uses like synthetic data generation.
-
Another example of how reasoning training can yield large performance improvements is DeepSeek R1-Zero: at the beginning of RL training, it scored just 10% on AIME 2024, but after 8,000 RL steps achieved an impressive 71%. Despite the RL compute representing only one-fifth of the base model’s pretraining compute, the capability gains from that relatively small compute investment were transformative.
-
It’s not certain that o1-high was based on GPT-4o, and we lack public information about how much compute o1-high required relative to GPT-4o. However these reflect our best guesses, as outlined in previous posts.
-
Unlike knowledge distillation, this uses actually generated tokens, rather than intermediate output “logits”.
-
That being said, phi-4 is a relatively extreme example of the relative costs which is famous for being trained on a particularly large fraction of synthetic data.
About the authors



Related work