Out of all the GPT models, GPT-5 is the odd one out. Unlike all previous versions of GPT, it was likely trained on less compute than its immediate predecessor, GPT-4.5.1
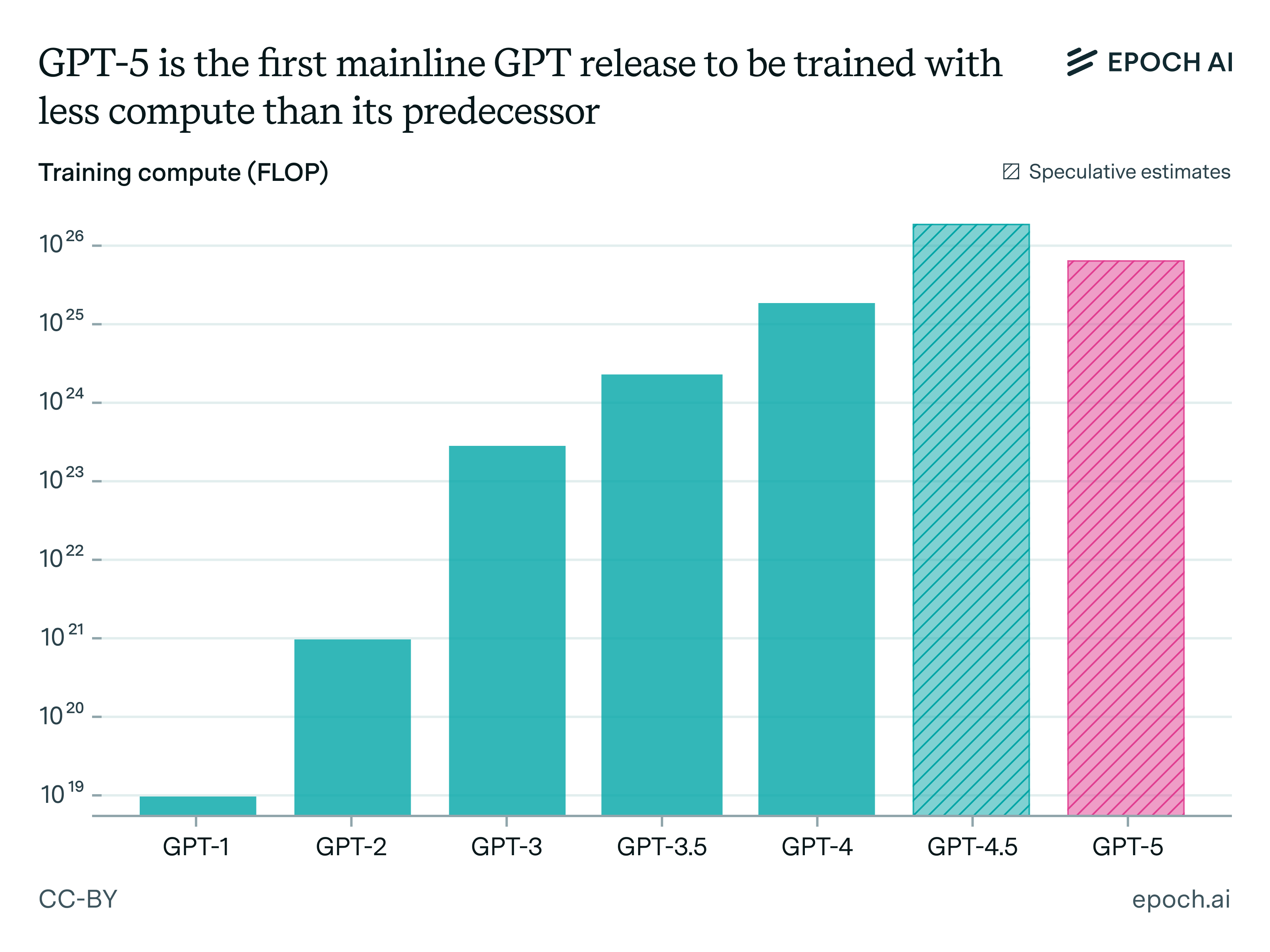
While the exact numbers are uncertain, GPT-4.5 very likely used more training compute than GPT-5.
But this leads to a puzzle: Models trained with more compute tend to be better, so why did OpenAI train GPT-5 with less compute than GPT-4.5? And what will this mean for future OpenAI models?
In this post, we’ll argue that the answers to these questions are the following:
- GPT-5 used less training compute than GPT-4.5 because OpenAI focused on scaling post-training. New post-training techniques made it possible to outperform GPT-4.5 with less training compute, but these methods likely weren’t yet mature enough to be applied at GPT-4.5’s compute scale. Doing so would’ve taken more time (and compute), which OpenAI likely chose not to do due to strong market pressures.
- OpenAI’s next flagship model (“GPT-6”) will probably be trained on more compute than GPT-4.5: When OpenAI figures out how to productively scale post-training, they’ll likely shift back using more training compute.
Importantly, when we say “training compute”, we’re focusing on the compute to perform the final training run of a model. It’s likely that the total compute for developing GPT-5 was higher than for GPT-4.5, if we also account for the compute for running experiments. This is because OpenAI’s (projected) R&D compute spend has grown from ~$5 billion in 2024 to ~$9 billion in 2025.2
Now let’s consider the arguments in turn.
GPT-5 used less training compute than GPT-4.5 because OpenAI focused on scaling post-training
Why did GPT-5 use less training compute than GPT-4.5? We believe this is a combination of two factors. First, OpenAI decided to prioritize scaling post-training, which had better returns on the margin. Second, they couldn’t readily scale post-training compute to GPT-4.5 levels at the time. And if they tried to scale post-training on a model with as much pre-training as GPT-4.5, they would’ve run into timing and experimental compute constraints.
Until recently, most LLMs were trained with 100× more pre-training than post-training compute. However, around September 2024, researchers developed novel techniques used in “reasoning models” that help scale post-training compute effectively. Researchers could now triple post-training compute in a way that was at least as useful as tripling pre-training compute. In fact, these reasoning techniques make it possible to reduce pre-training compute by roughly 10× while getting the same performance!3
This means that, rather than spending around $200 million on pre-training and $2 million on post-training GPT-4.5,4 new post-training techniques made it possible for that $2 million in post-training to achieve the same overall performance with only $20 million in pre-training. That’s roughly a ten-fold decrease in training costs, though this doesn’t imply that total model development costs were lower, due to increases in the compute needed to run experiments. The upshot is that OpenAI was likely able to train a model with less compute than GPT-4.5, while still outperforming it on many useful tasks like coding and search.
However, while this shows that OpenAI could’ve outperformed GPT-4.5 with less training compute, it doesn’t fully explain why they chose this strategy in practice. For example, why not just post-train GPT-4.5? And why not post-train a smaller model on enough data to reach GPT-4.5’s level of training compute?
The core reason is that scaling post-training in this way is challenging. It requires lots of testing and experimentation, which takes time and compute, especially when performed on larger, newer models.5 It also requires a significant amount of high-quality post-training data, which takes time to design and collect.
Crucially, OpenAI faced major time constraints due to market pressures. This came in the form of fierce competition from rival AI labs, which would hurt their revenue – e.g. Anthropic’s models had been consistently outperforming OpenAI’s models at coding. And there was added pressure because many had expected OpenAI to release a model called “GPT-5” as early as November 2023.6
Given these constraints, we believe that OpenAI scaled post-training on a smaller model as much as they could. Scaling further would’ve either required more experiments than they had the compute or time for, or post-training data that they didn’t have. Post-training a GPT-4.5-sized model, let alone starting a larger multi-month pre-training run and doing post-training on top, would’ve taken too much time or too much experiment compute.7
The result of these efforts in scaling post-training was GPT-5, a new state-of-the-art model that OpenAI was able to release by August.
GPT-6 will probably be trained on more compute than GPT-4.5
What does this mean for training compute trends moving forward? Our best guess is that future iterations of GPT will be trained on more compute.
To see why, consider the bigger picture. Training GPT-5 with less compute than GPT-4.5 is part of a broader trend, where the training compute of state-of-the-art models has grown more slowly than one might’ve expected a year ago.8 Since post-training was just a small portion of training compute and scaling it yielded huge returns, AI labs focused their limited training compute on scaling it rather than pre-training.9
In fact, these reasoning post-training techniques have scaled much faster than pre-training compute.10 At this rate, tripling post-training compute will soon be akin to tripling the entire compute budget – so current growth rates likely can’t be sustained for much more than a year.
That means that this broader trend is likely to end – we may see a reversion to the original trend of training compute growth. If this is right, GPT-6 is likely to need much more training compute than GPT-5, and probably more than GPT-4.5. Not to mention, OpenAI plans to significantly expand their compute stock, with many more GPUs brought online by the end of the year,11 and major clusters like Stargate Abilene coming out in phases.
On the other hand, it’s possible that the bottlenecks to scaling training compute are harder than we anticipate, e.g. due to limits in the availability of high-quality pre-training data and post-training RL environments. It’s also just hard to pin down how to measure “training compute”. For instance, it’s plausible that a larger model could be used to generate synthetic data for a smaller one – so should the total “training compute” for the smaller model include the compute for training the larger model?
Overall, we think we’ll likely revert back to the trend of training compute growth – though perhaps not for long.12 Moreover, while training compute scaling has slowed, infrastructure buildout has continued. This means more compute availability relative to the size of training runs – so training compute scaling could come back with a vengeance.
We’d like to thank Josh You, Lynette Bye, and David Owen for their feedback.
-
OpenAI has historically scaled up training compute by around 100× with each (integer) generation of GPT, and GPT-5 is an exception to this trend.

-
There are several things to note about these numbers. First, R&D compute accounts for both running experiments and the final training run. Second, these are estimates based on The Information’s projections of OpenAI’s spending, and are thus quite uncertain. Third, the 2024 R&D compute cost is reported as two separate numbers: $3 billion in the “compute to train models”, and $1 billion in “research compute amortization”. It’s not entirely clear what this means, but GPUs are typically amortized over several years. For simplicity we assume amortization over two years, leading to $2 billion + $3 billion = $5 billion in total R&D compute, but our point stands even if we assume amortization over four years.
-
The exact number here should be taken as a rough estimate to illustrate the magnitude of the savings, in part because they were estimated using limited data, and in part because the effect size depends on the specific benchmark.
-
For illustration, the cost of training Grok 4 was around $500 million, and we expect GPT-4.5 to be in a similar ballpark (but slightly lower).
-
One reason this is harder for larger models is that more time and compute is needed to run the model in post-training environments, a crucial part of post-training.
-
GPT-4.5 was likely also an attempt to develop a model called “GPT-5”.
-
One more reason that OpenAI likely chose to focus on scaling post-training without increasing pre-training compute for GPT-5 is to reduce inference costs. But it’s not clear how much of a role this played – for example, if OpenAI were worried about inference speeds or costs, they could’ve distilled a larger model into a smaller one, making it both faster and cheaper to run.
-
For instance, in the 2.5 years since GPT-4 was released, most state-of-the-art models used less than 3× more training compute than it, such as Claude 3.7 Sonnet and o3. This seems slow given other trends – the training compute for the most compute-intensive models has been expanding at 5× per year. The reason for this discrepancy is that models trained with the most compute aren’t necessarily state-of-the-art in performance. For example, while models like Llama 4 Behemoth exceeded this 3× threshold, they didn’t clearly outperform the best models from competing labs on benchmarks.
-
There are also other practical factors that we’ve alluded to, which also contribute to this trend. For instance, it’s also easier to scale novel reasoning techniques on smaller models, such that labs have temporarily focused on releasing relatively small models compared to further pre-training scaling.
-
One estimate is that this post-training compute can be scaled up 10× every 4 months. This probably doesn’t go faster still because of scaling bottlenecks, such as in how quickly the RL environments can be built for RL post-training.
-
While Sam Altman tweeted that OpenAI would have “well over 1 million GPUs brought online” by the end of the year, this is unlikely to be purely top-end GPUs. For example, it plausibly includes a mix of A100s, H100s, and Blackwell GPUs.
-
For example, this could happen through further pre-training scaling or RL post-training scaling.
About the authors




Related work