The massive compute scaling that has driven AI progress since 2020 is likely to slow down soon, due to increasing economic uncertainty and longer development cycles.
While investors could theoretically scale compute by several orders of magnitude, the required hundreds of billions, combined with uncertain returns, will push them toward incremental scaling — investing, deploying products to gauge returns, then reevaluating further investment. Additionally, as the required compute grows larger, the time between project initiation and product deployment (i.e. “lead time”) lengthens significantly, creating a feedback loop that naturally slows the pace of compute scaling.
In particular, our current best guess is that every additional 10× increase in compute scale lengthens lead times by around a year. For example, OpenAI currently likely has over $15 billion worth of compute, and this compute stock has been growing by around 2.2× each year.1 At that pace, current trends would predict a trillion dollar cluster around 2030 — but longer lead times would delay this to around 2035.
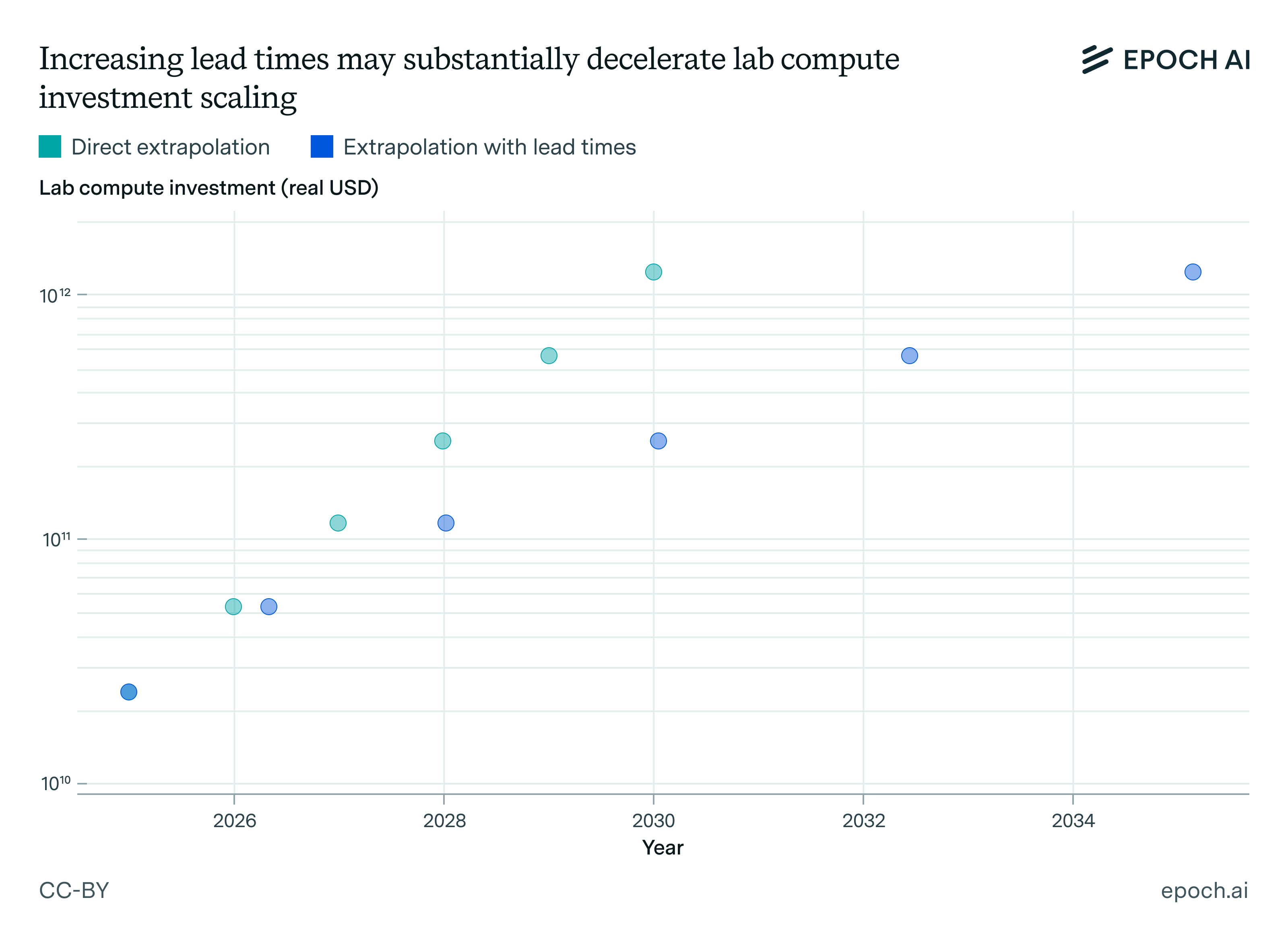
The “extrapolation with lead times” is determined by taking the direct extrapolation, and adjusting it such that each additional 10× increase in compute stock increases lead times by a year. These accumulate so that the total delay is larger at greater compute scales.
Importantly, this dynamic applies most directly to the overall stock of compute at a lab, not the size of training runs. Even if lead times slow scaling of compute investment, frontier AI labs may still scale training compute at 5× per year for another 1-2 years by allocating a larger fraction of compute to training.
The implications could be huge. It may become harder to obtain the compute needed to run experiments and find novel algorithmic improvements, and at some point training compute scaling will also have to decelerate. Since compute is strongly correlated with model capabilities, we expect this dynamic to slow AI progress.
Uncertainties about investment returns prevent a “YOLO scaleup”
If investors believe the Bitter Lesson, one might expect them to throw everything into expanding the available compute. For example, we see this sort of dynamic in economic models like the GATE model, which (dubiously) predicts that it is optimal to invest $25 trillion in AI today.
But in practice, such massive investment is highly unlikely. This is partly because the returns to scaling are deeply uncertain, while the costs are enormous. For example, the second phase of xAI’s Colossus cluster already required nearly $10 billion in hardware acquisition costs. Scaling compute a thousandfold would likely cost at least a thousand times more,2 making any overestimate of returns extremely costly. This concern becomes ever more important as hardware acquisition costs approach hundreds of billions or even trillions, approaching single-digit percentages of Gross World Product.
This is not merely a hypothetical. A clear example is Sam Altman’s attempts to raise $7 trillion for AI infrastructure in early 2024, which drew disbelief from investors and chip manufacturers. Historically, such unprecedented levels of investment have been met with at least skepticism from investors and analysts.3
Rather than committing to massive investments, investors are more likely to prefer an intermediate approach: break up the scale-up into several smaller chunks and observe the returns each time. Rather than a thousand-fold scale up, compute investment could be grown in 10× increments, with each stage serving as a decision point on whether to continue. This would be much less costly than scaling 1000× and finding out that it was all a waste!4
Lead times are getting longer, causing investments (and hence compute scaling) to slow down
However, scaling up in increments is only part of the reason for why scaling might slow down. The other factor is lead times, or the time between when a project to build a new AI model is planned and when the model is actually deployed.5
In the past, developing frontier AI models only required renting small amounts of compute. But by the 2020s, AI companies needed to buy tens of thousands of GPUs, a process involving lengthy negotiation and delivery times. To scale further, companies need to build new large-scale data centers and expand chip fabrication capacity, projects that take multiple years to execute.
To figure out just how much longer lead times could slow things down, we need to look at specific constraints and their associated lead times. These are summarized in the table below, and we analyze each constraint in turn.
| Primary constraint | Lab compute investment (real USD) | Estimated lead time (years) |
|---|---|---|
| Renting GPUs | <$30 million | ~0 |
| Buying GPUs | $30 million to $1 billion | ~0.5 |
| Constructing a data center | $3 billion | 1-2 |
| Constructing a very large data center/power plant | $10 billion to $30 billion | 2-3 |
| Significantly upgrading a fab | $30 billion | 2 |
| Building a new cutting-edge fab from scratch | $300 billion | 4-5 |
Table 1: Higher levels of investment in compute introduce new major constraints, which have associated lead times (e.g. building a new fab from scratch).
Renting GPUs: ~0 years. Since 2010, lead times have generally been quite negligible – generally well under a year. One reason is that cloud compute has largely been sufficient for doing experiments and training models close to the frontier. Cloud compute providers often allow users to access hundreds or low thousands of GPUs for weeks to months,6 costing up to tens of millions and enabling training runs on the order of 1024 FLOP, the same order of magnitude as for training DeepSeek-V3.7 And this can typically be accessed very quickly – for example, Google Cloud allows users to make reservations 6h to 3 days in advance at the latest. Another example is SFCompute building a spot market for compute access.
Buying GPUs: ~0.5 years. At the scale of tens of thousands of GPUs, it becomes increasingly common for major AI labs to simply buy their own compute, often involving $30 million to $1 billion in compute investment. For example, despite attempting to work with Oracle Cloud for the training of Grok 3, xAI ultimately chose to acquire the compute themselves in order to accelerate model training and deployment.8 Such purchases generally take tens of weeks, very roughly in the range of half a year. For example, Meta’s AI Research SuperCluster had a lead time of 6 months for an expansion of 10,000 A100 GPUs, and analysts report lead times on the order of tens of weeks for NVIDIA H100s.
Constructing a data center: 1-2 years. Scaling to hundreds of thousands of GPUs – which is the size of some of the largest AI supercomputers today – often requires new data centers and several billions of dollars. For example, training Grok 3 first required building out xAI’s Colossus cluster with over 100,000 H100s. Colossus was completed in an astonishing 122 days, but more typical lead times are on the order of 1-2 years.
Constructing a very large data center: 1-3 years. To our knowledge, Colossus is the largest AI supercomputer to date, and requires around 300 MW of power to run. Scaling this up another ten-fold brings us to the scale of very large data centers, potentially involving over a million GPUs and requiring more than 1 GW to run. Such builds are typically multi-year endeavours. For example, Meta’s >1.5GW Hyperion cluster is expected in late 2029 or 2030, constituting a lead time of 4 to 5 years. Crusoe aims to expand their campus in Abilene to 1.2 GW by 2026, two years after construction began. We estimate closer to the low end, because really big data centers are built in phases with multiple buildings, potentially allowing partial parallelization to reduce lead times.9
Significantly upgrading a fab: ~2 years. Supporting these compute investment scales also requires fabricating lots of chips. One way to do this is to significantly upgrade the capacity of existing fabrication plants (“fabs”) with the latest semiconductor manufacturing equipment.10 This equipment is largely from ASML, and has a delivery lead time of around 12-18 months. Adding the time for installation and ramp-up to high yield, we expect a total lead time of about 2 years.
Constructing a very large power plant: 2-3 years. These compute investment scales (tens of billions of dollars) also introduce additional constraints that need to be considered, such as the need to construct large power plants to support data centers. Historically, the largest US power plants (in the 100-1000 MW range) have taken 2 to 6 years to construct. Here we again place our estimate at the low end, since large AI demands may overcome some of the bottlenecks that slowed prior power plant build-outs.
Building a new cutting-edge fab: 4-5 years. If compute demand rises to requiring $300 billion compute investments (possibly requiring tens or hundreds of millions of GPUs), repurposing existing fabs may no longer suffice, and new fabs will be required.11 For comparison, TSMC produced 1 to 2 million H100s in 2024, one to two orders of magnitude below such demand. But building new fabs typically requires substantial lead times – for instance, TSMC Arizona’s expected construction lead time is around 3 years, and US fabs in general have had construction lead times of around 2.5 years between 2010 and 2020. However, this ignores permitting and pre-construction lead times, which could add multiple years.12 For example, NEPA review processes on average took around 4.5 years between 2010 and 2018, though we expect that this would be less of a substantial bottleneck given the current political climate. Overall, we estimate a total lead time of 4 to 5 years, including both construction and other factors.
If we put everything together, the lead time grows roughly one year for every ten-fold increase in compute. As a result, the time increases for investors to get meaningful signals about the economic returns, slowing down the rate of compute scaling.
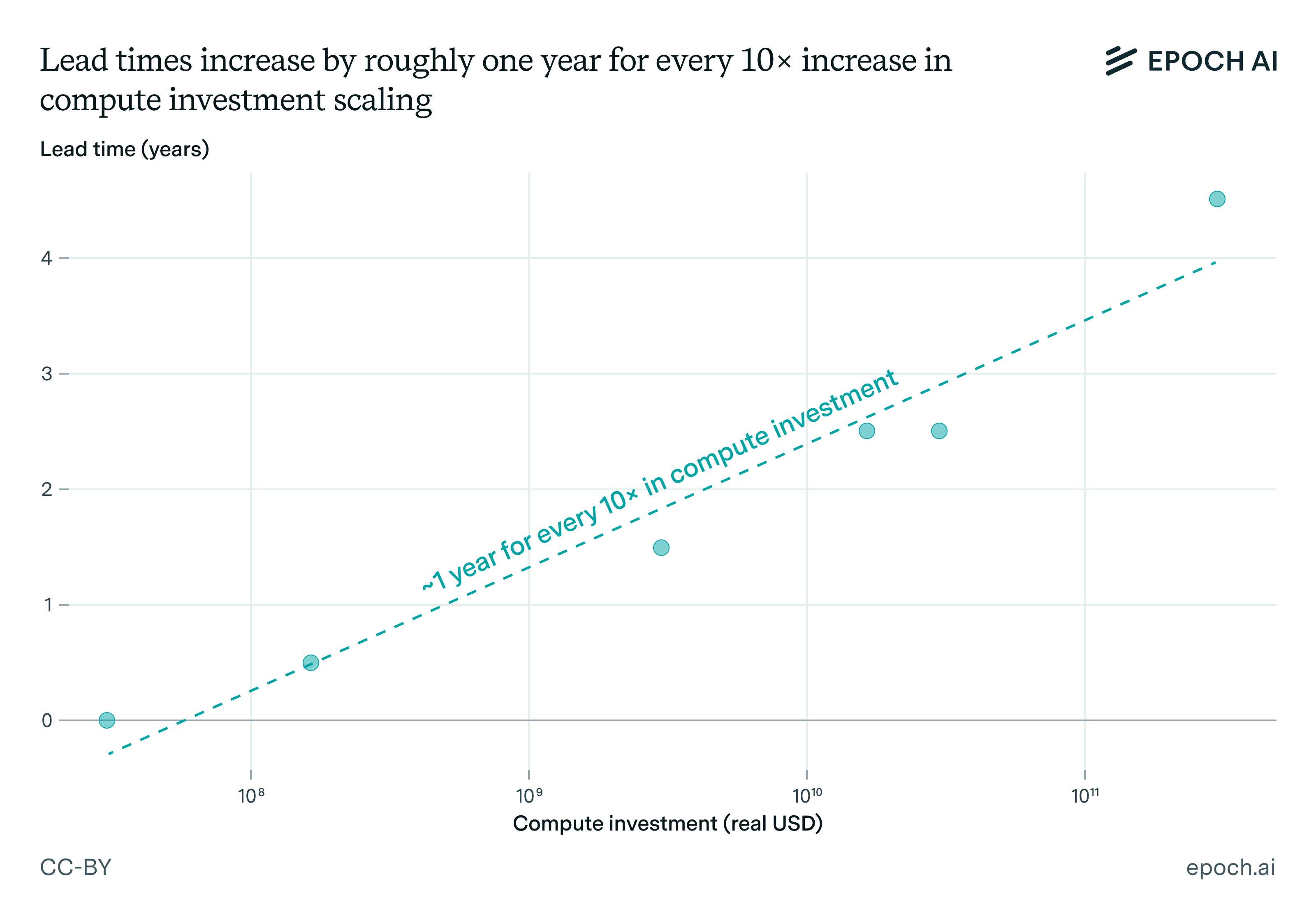
Plot of estimated lead times at different levels of compute investment. Data is shown in Table 1. If a given primary constraint has a range of compute investment, we take the geometric mean.
What does this mean for AI progress over the next few years?
Given how important compute scaling has been for AI progress, a slowdown would likely be a big deal. It means running fewer experiments (or only smaller-scale experiments), making novel algorithmic innovations harder to discover. It also breaks from previous trends in training compute scaling that have been so central to AI capabilities improvements over the last few years.13 And the slowdown might be even greater than we predict, if we’ve missed particular bottlenecks.14
However, there are also reasons why this dynamic might matter less than we predict. Our argument assumes investors must wait for deployment to gauge economic returns, but one could push back on this. Perhaps future benchmarks will better reflect real-world economic impacts, or we will have better-developed scaling laws for economic productivity.
Another possible reason for skepticism is that lead times can be shortened. For example, the Colossus data center was built in just 122 days — far faster than the typical 2 years for a project of that scale. With enough political will, massive upfront spending could further compress timelines, such as through an “AI Manhattan Project”. It may also be possible to avoid some portions of investment lead times – for example, permitting can be started prior to funding. How well these approaches work depends hugely on the trade-off between lead times and investment, which we currently have little evidence on.
In a world with substantial automation, lead times could shrink even further. Expanding robotics might accelerate construction, or AI systems could optimize project designs – though these dynamics are necessarily very speculative.
Our overall expectation is that lead times cannot be sufficiently reduced to prevent a slowdown. The effect size could be smaller than stated, e.g. it’s plausible that lead times only increase by 4 months instead of 8 months for each ten-fold increase in compute. However, we feel confident that directionally, the dynamic we’ve outlined is heavily underappreciated, and our best guess is that we’ll see increasingly large lead times over the next few years, with major implications for compute scaling.
Yafah Edelman would like to thank the Long-Term Future Fund for supporting preliminary research on this topic prior to joining Epoch AI.
-
For example, OpenAI’s compute spend in mid-2024 was around $6 billion, compared to roughly $13 billion mid-2025. This leads to a factor increase of around 2.2×.

-
Factors like hardware adjustment costs could make the overall acquisition costs even higher than one might naively expect, by multiplying the costs by a factor of 1,000×.
-
For example, see the discussion around when Brett Simpson says “I’ve never seen that type of roadmap before from TSMC.”
-
There are other potential reasons for not scaling up 1,000× straight away. For example, scaling in increments may be quite important from an algorithmic (e.g. compute efficiency) standpoint – it’s useful to know how well an algorithm scales with more compute before launching a much larger training run or building out much more compute infrastructure around it.
-
It’s tricky to define “lead time” more precisely. For example, with fab yield times, we start counting from when investors can credibly signal that they will invest in the fab’s construction – but this is fairly vague. We stop counting somewhere between the literal start of chip production (where yields may be terrible), and production at full capacity, which adds to the ambiguity. But regardless of how we operationalize “yield time”, they still get substantially longer with higher compute investment, so our core thesis still stands.
-
This is true for common cloud compute providers like Crusoe, Amazon Web Services, and Google Cloud. For example, Amazon Web Services allows users to reserve 512 GPUs for up to 2 weeks initially (with later extensions), and Google Cloud allows users to reserve up to 1024 TPUs.
-
For illustration, a two month training run with 100 H100s (1015 FLOP/s) and 30% utilization would involve around 1023 FLOP. If we instead use 1,000 H100s this would instead reach around 1024 FLOP.
-
Another example is that Llama 3 was trained on the order of 20k GPUs owned by Meta. But there are also some plausible counterexamples, such as GPT-4, which was trained on a Microsoft Azure cluster with 25,000 A100s.
-
That said, there are reasons for it to not be so parallelizable – for example, earlier buildings might be constructed so as to de-risk future buildings, entailing a serial bottleneck.
-
This is somewhat analogous to using power plants that have already been or would otherwise be shut down, such as Three Mile Island’s reopening to power AI data centers.
-
Moreover, the chips produced by TSMC may need to be split across multiple AI labs, further increasing the burden on TSMC’s manufacturing.
-
Another important dynamic is that the yield rates of fabs typically increase over time.
-
Additionally, it moderates the predicted economic impacts from models like GATE, which do not very explicitly model serial time bottlenecks like the ones that we’ve detailed in this post.
-
For example, we’ve not considered lead times associated with training enough workers to support major AI chip buildouts.
About the authors


Related work