
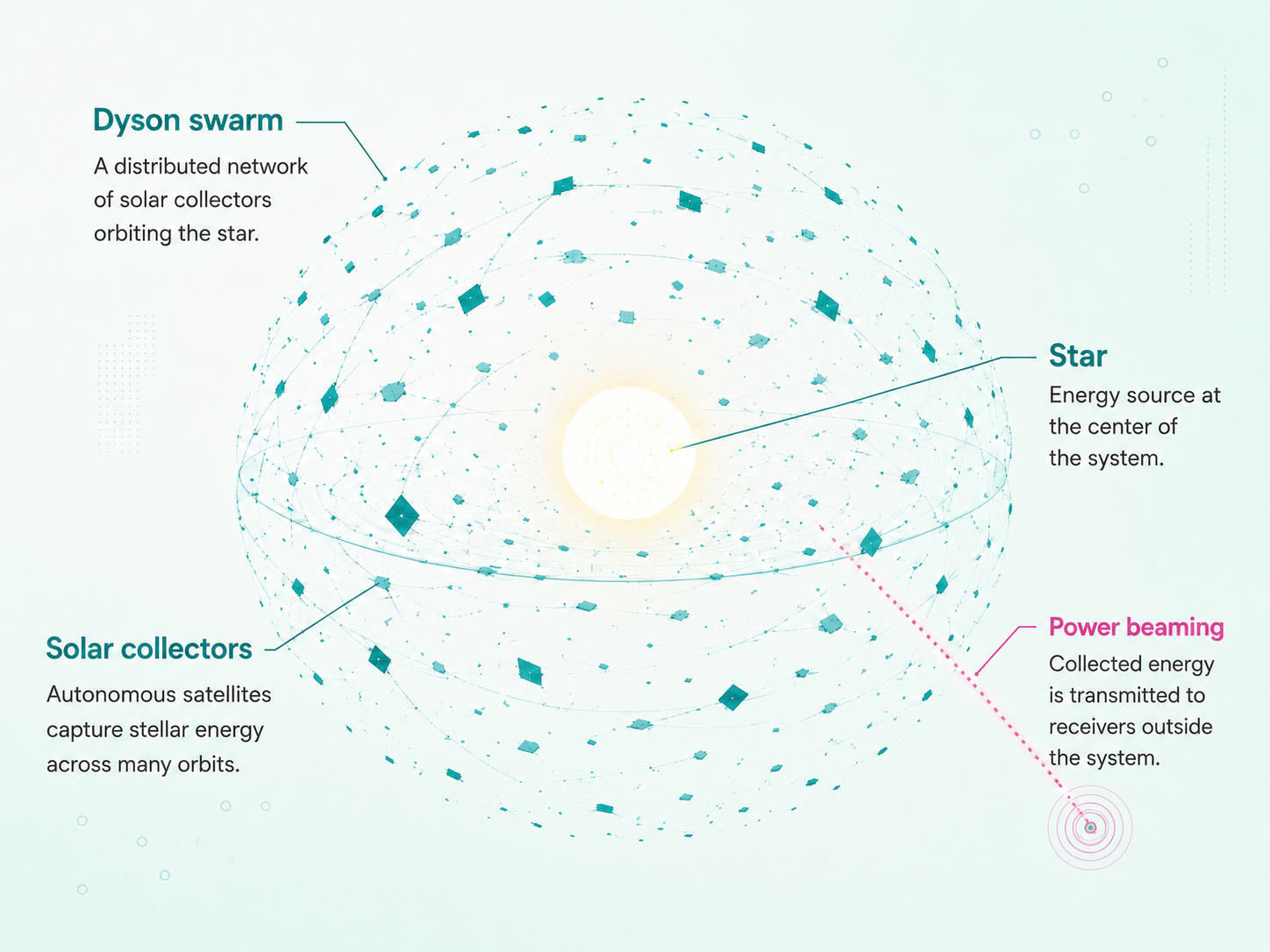
Why we should think a little harder about what it takes to build a Dyson Sphere
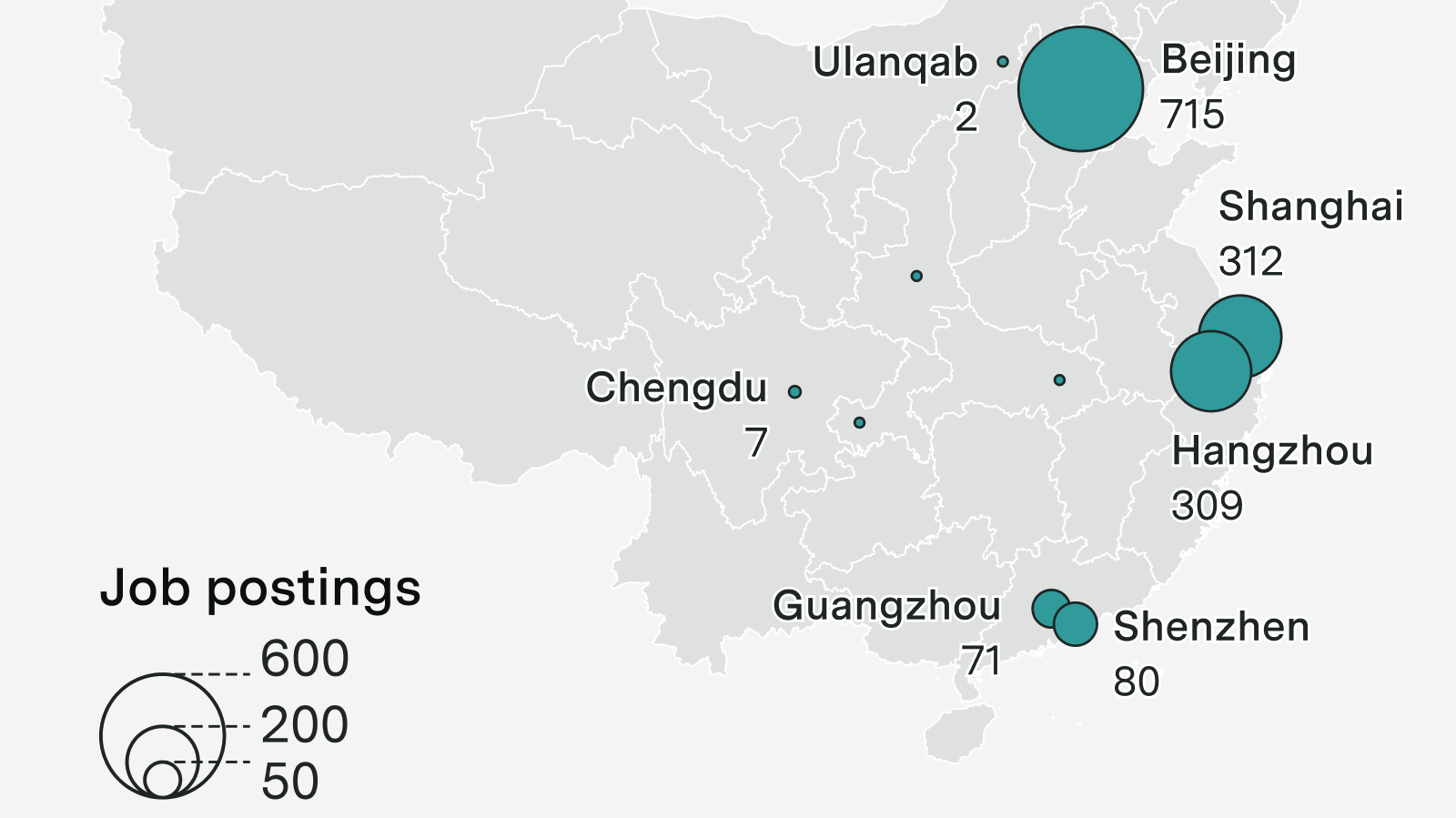
Inferring Chinese AI labs’ strategies from their job descriptions
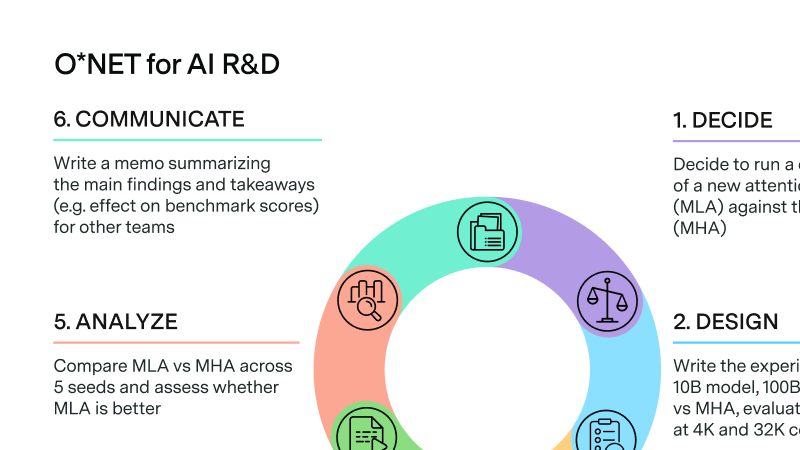
Proposing a new way to track AI research automation
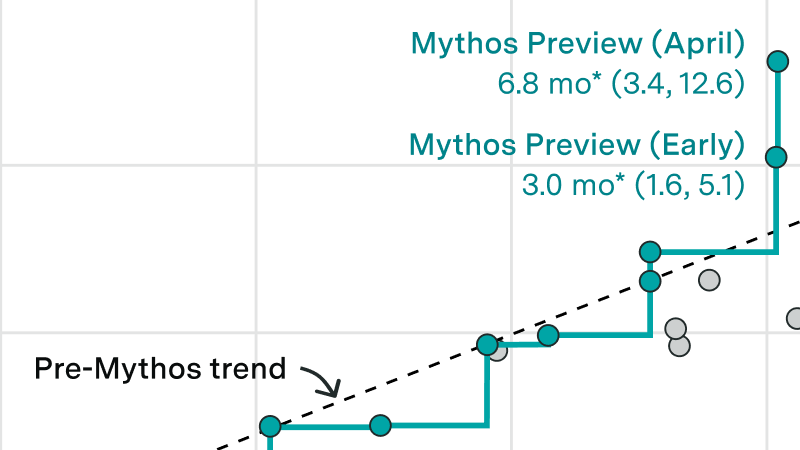
Compiling all the public evidence on Mythos Preview’s cyber abilities

A simple taxonomy of the main proposals for post-AGI universal redistribution.

What might explain AI researcher pay, and why it matters

In this episode, Greg Burnham and Tom Adamczewski join Anson Ho to push back on benchmark pessimism and dig into what the next generation of AI benchmarks could look like.
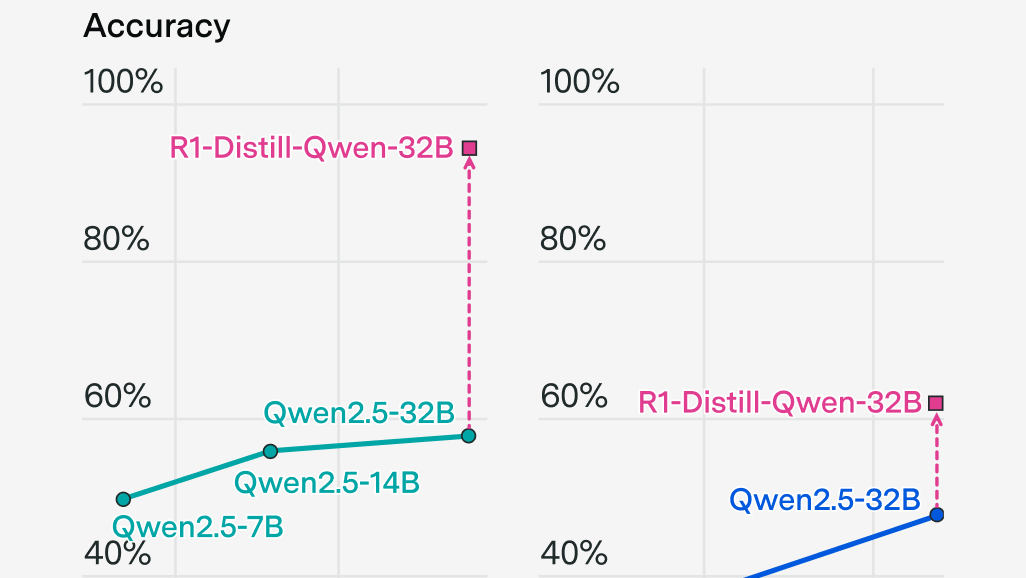
Can Chinese and open model companies compete with the frontier through e.g. distillation and talent?
An opinionated guide to “algorithmic progress” and why it matters
Beyond benchmarks as leading indicators for task automation

In this episode, Daniel Litt chats with the hosts about AI’s limits in mathematics, accelerating math research, and how to measure progress on open problems.
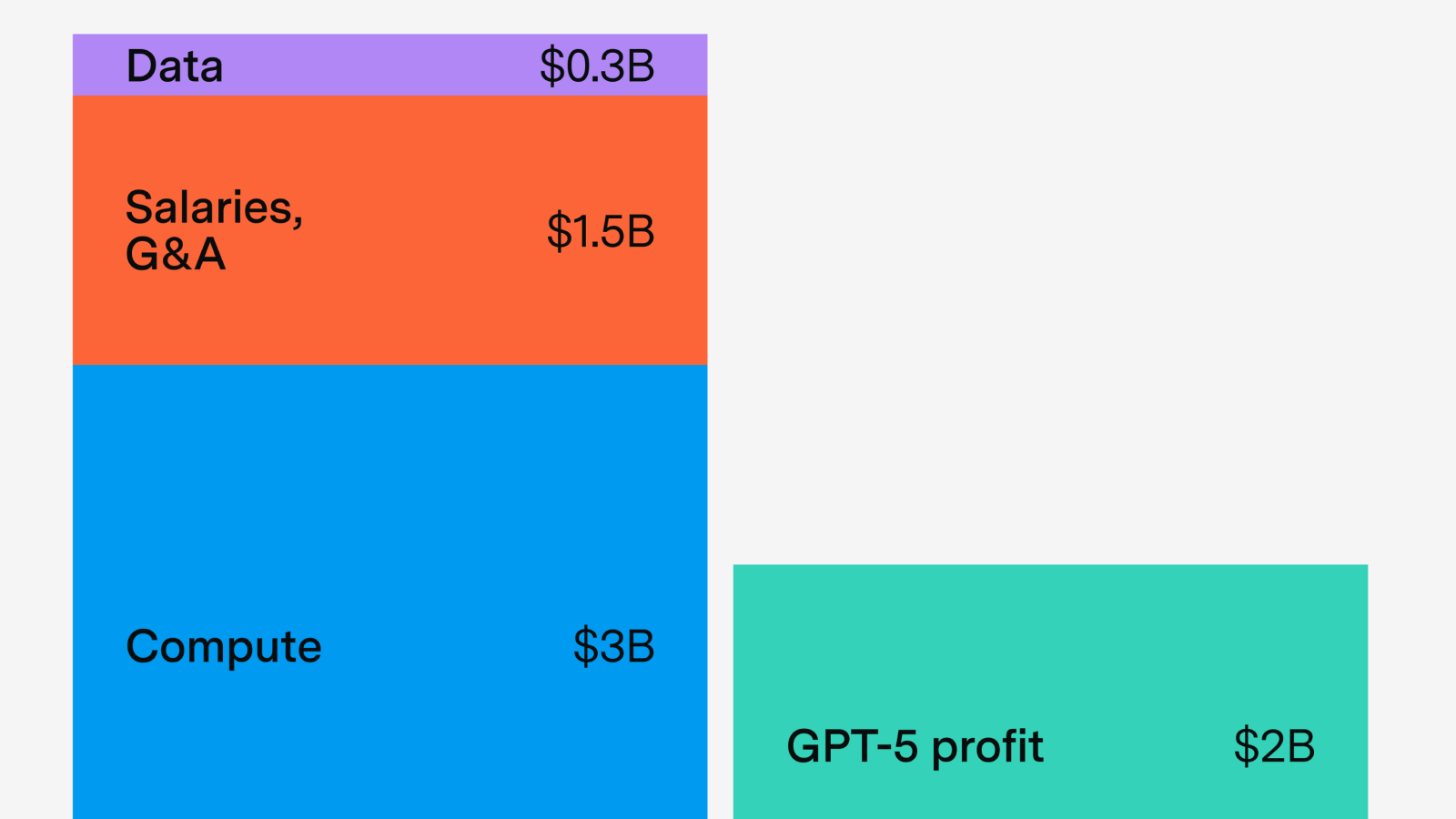
Lessons from GPT-5’s economics
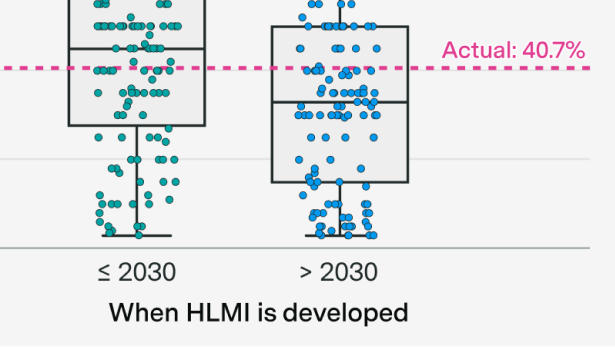
Mostly right about benchmarks, mixed results on real-world impacts
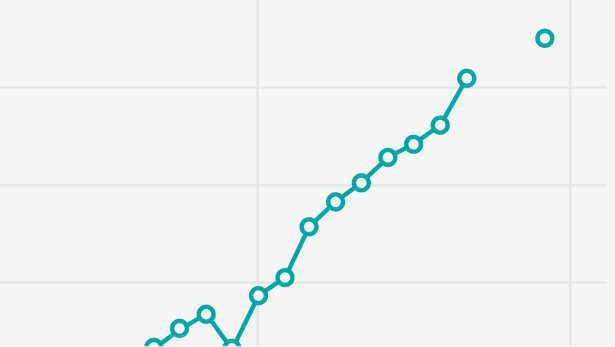
Public data as well as our original polling suggest LLM adoption is roughly on trend, but the underlying drivers are shifting.

In this episode, economist Luis Garicano chats with the hosts about macroeconomic and labor market effects of AI, with a focus on the EU.

Why power is less of a bottleneck than you think.

Most benchmarks saturate too quickly to study long-run AI trends. We solve this using a statistical framework that stitches benchmarks together, with big implications for algorithmic progress and AI forecasting.
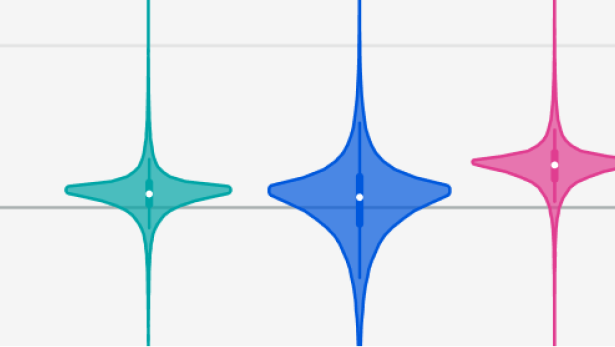
The existing debate rests on data and assumptions that are shakier than most people realize. To make progress, we need better evidence, and experiments are the best way to get it on the margin.

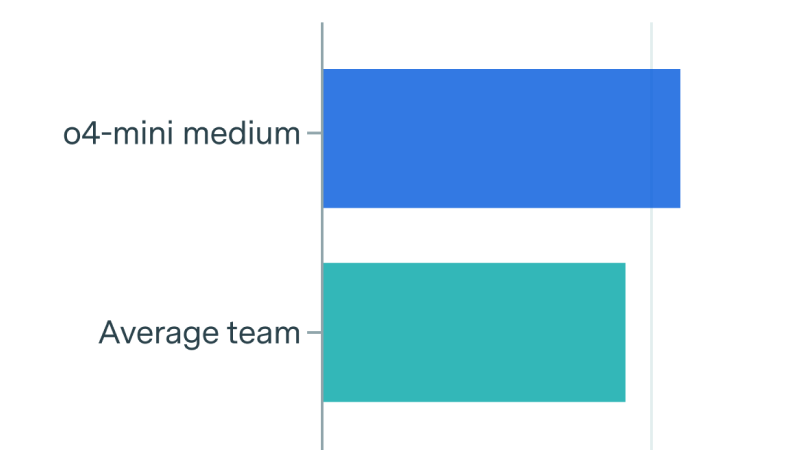
OpenAI has the inference compute to deploy tens of millions of digital workers, but only on a narrow set of tasks – for now.

Stanford economist Phil Trammell joins Epoch AI to explore AGI, growth, GDP limits, and what economic theory can tells us about the future of AI.
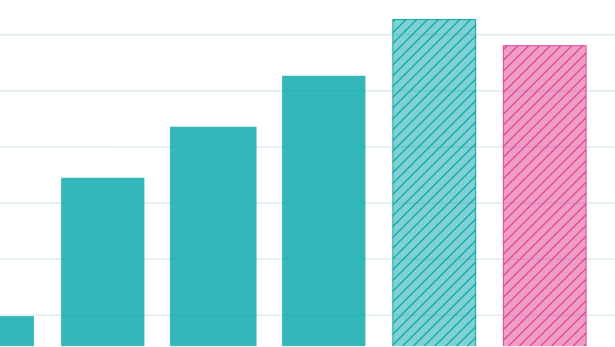
OpenAI focused on scaling post-training on a smaller model
Continual learning, scaling RL, and research feedback loops
'Training compute' is constantly evolving, and compute-based AI policies must adapt to remain relevant

A heavily underappreciated dynamic when thinking about AI timelines.
Many multi-agent setups are based on fancy prompts, but this is unlikely to persist
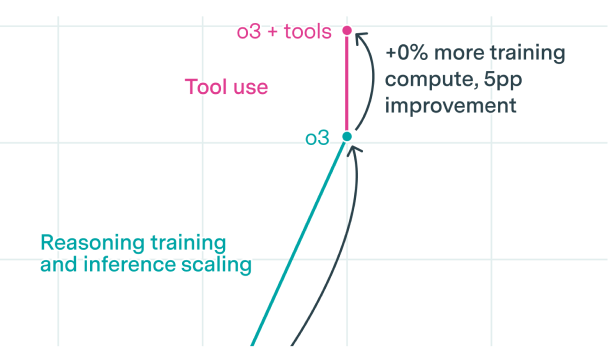
Reasoning models were as big of an improvement as the Transformer, at least on some benchmarks
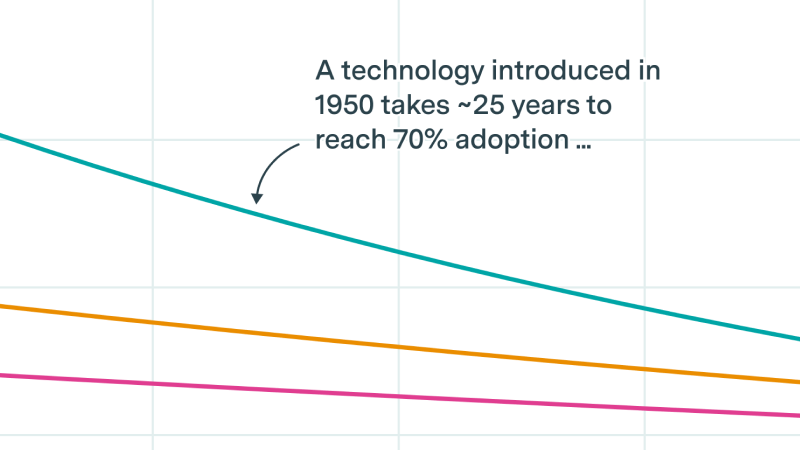
How quickly has AI been diffusing through the economy?
An AI Manhattan Project could accelerate compute scaling by two years.
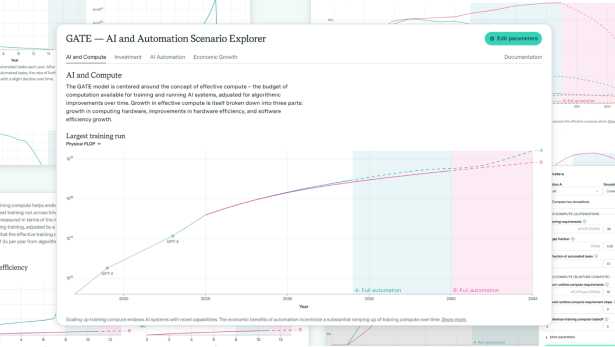
GATE model shows AI-driven growth surges more easily than expected and supports much larger investments—advocating moderate optimism.
Assessing if AI labs' biorisk evaluations effectively measure models' potential to enable amateur bioweapons development.
Examining o3-mini's math reasoning: an erudite, vibes-based solver that excels in knowledge but lacks precision, creativity, and formal human rigor.
How do humans and AIs compare on FrontierMath? We ran a competition at MIT to put this to the test.
Why don't AIs automate more real-world tasks if they can handle 1-hour ones? Anson Ho explores key capability and context bottlenecks.
The real reason that AI benchmarks haven’t reflected real-world impacts historically is that they weren’t optimized for this, not because of fundamental limitations – but this might be changing.

How will AI transform mathematics? Fields Medalists and other leading mathematicians discuss whether they expect AI to automate advanced math research.
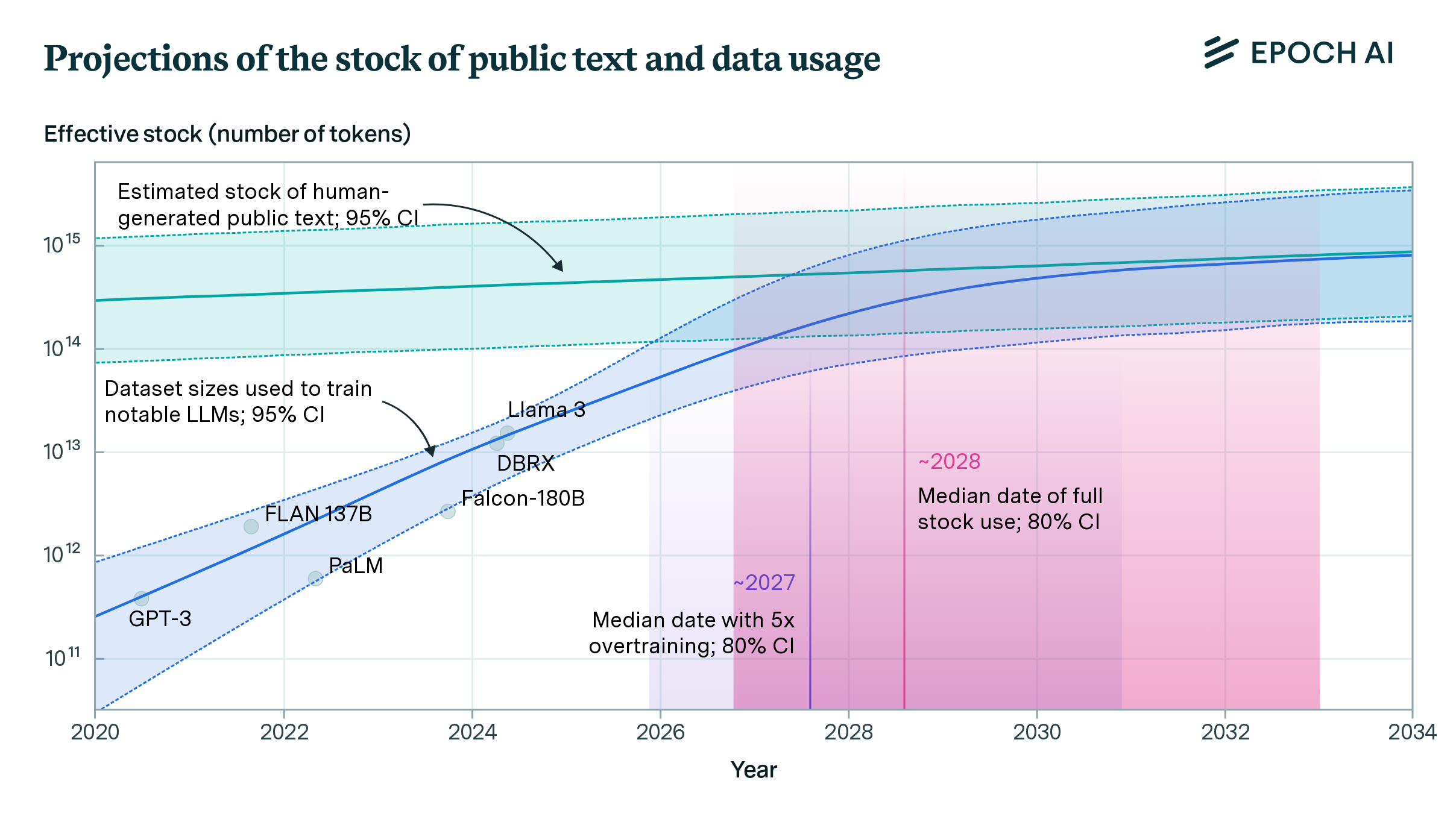
We estimate the effective stock of quality and repetition adjusted human-generated public text for AI training at around 300 trillion tokens. If trends continue, language models will fully utilize this stock between 2026 and 2032, or even earlier if intensely overtrained.
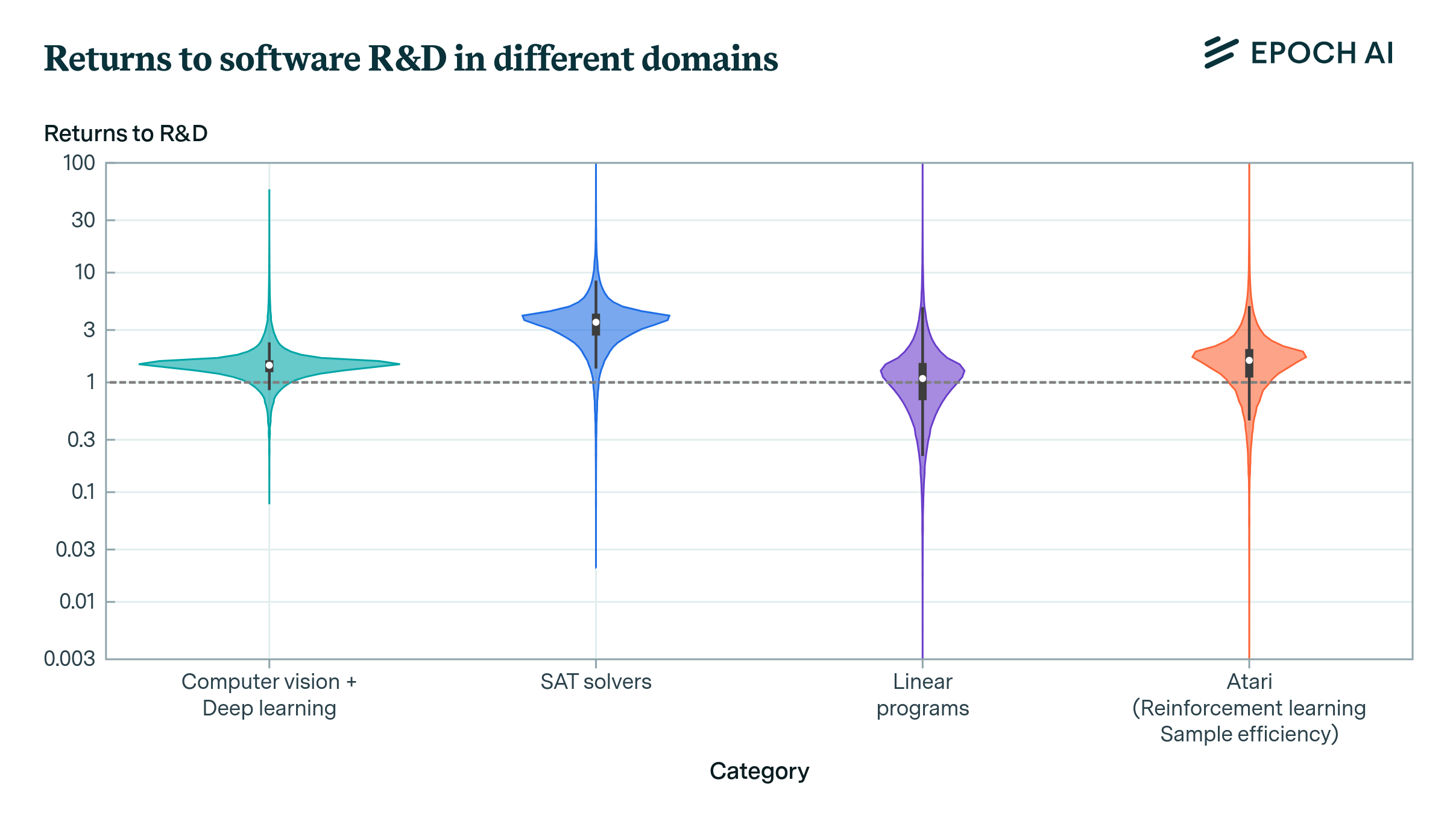
The returns to R&D are crucial in determining the dynamics of growth and potentially the pace of AI development. Our new paper offers new empirical techniques and estimates for this crucial parameter.

Progress in pretrained language model performance surpasses what we’d expect from merely increasing computing resources, occurring at a pace equivalent to doubling computational power every 5 to 14 months.
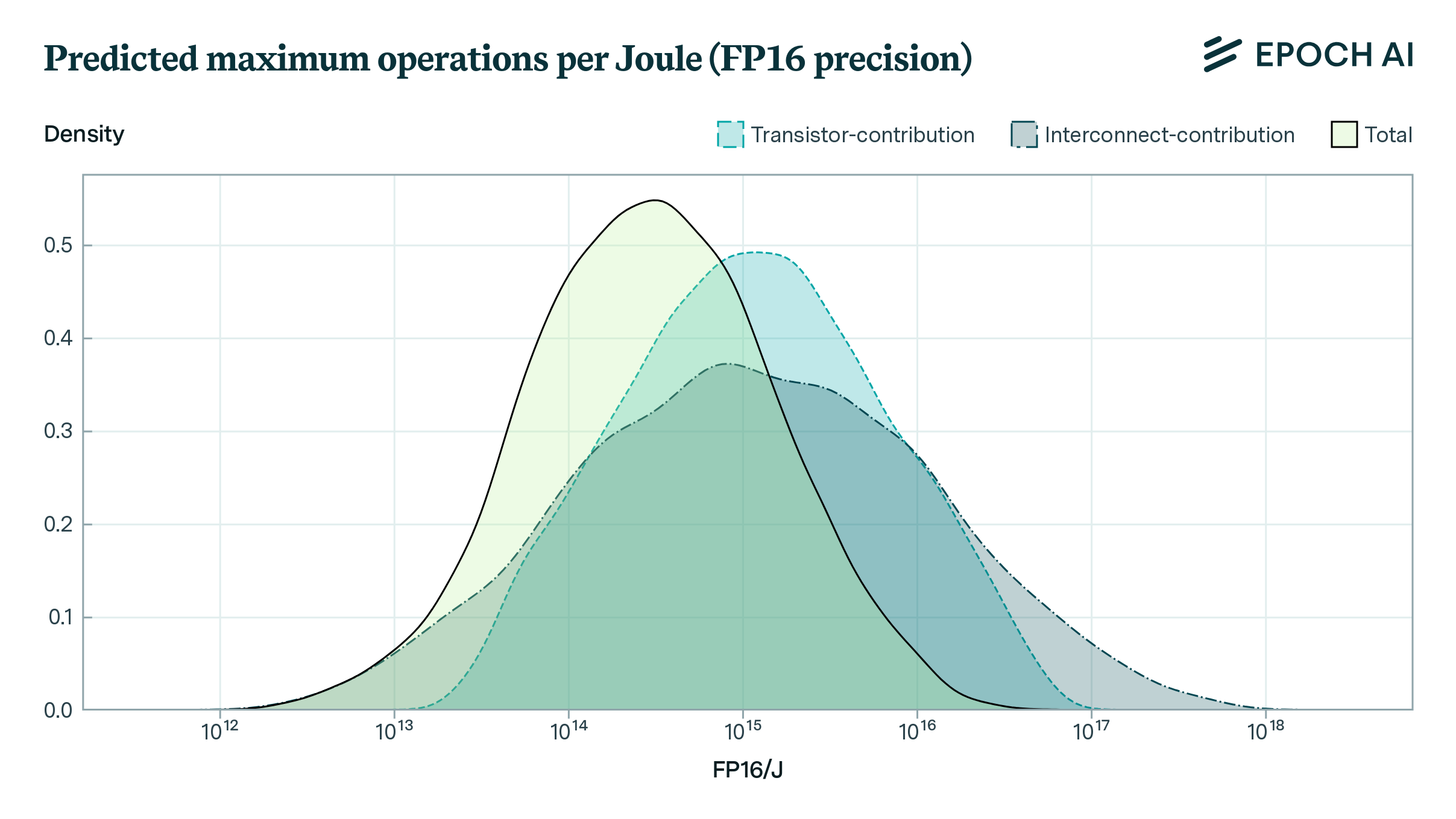
How far can the energy efficiency of CMOS microprocessors be pushed before we hit physical limits? Using a simple model, we find that there is room for a further 50 to 1000x improvement in energy efficiency.

Compute is essential for AI performance, but researchers often fail to report it. Adopting reporting norms would support research, enhance forecasts of AI’s impacts and developments, and assist policymakers.
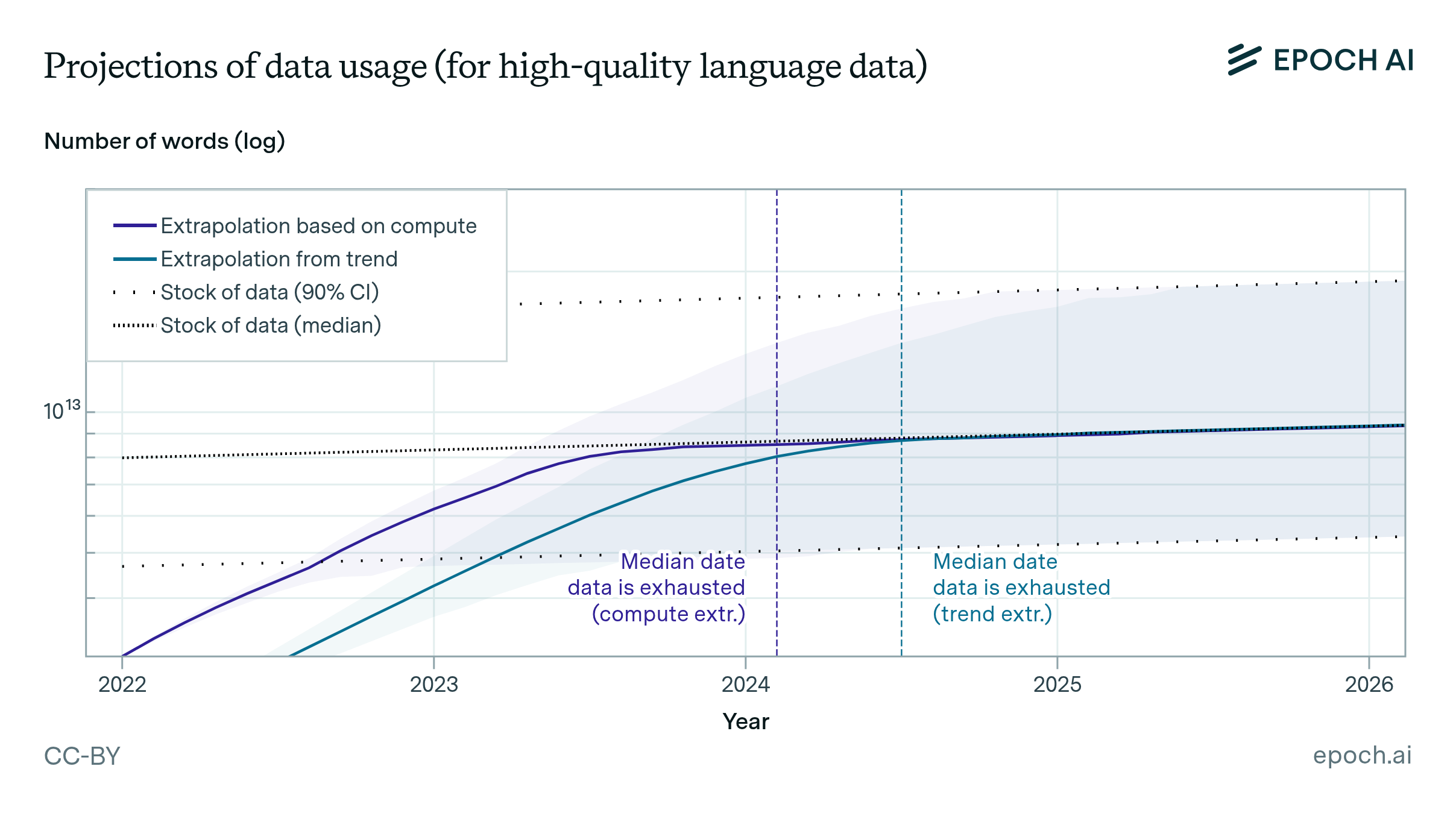
Based on our previous analysis of trends in dataset size, we project the growth of dataset size in the language and vision domains. We explore the limits of this trend by estimating the total stock of available unlabeled data over the next decades.

We collected a database of notable ML models and their training dataset sizes. We use this database to find historical growth trends in dataset size for different domains, particularly language and vision.
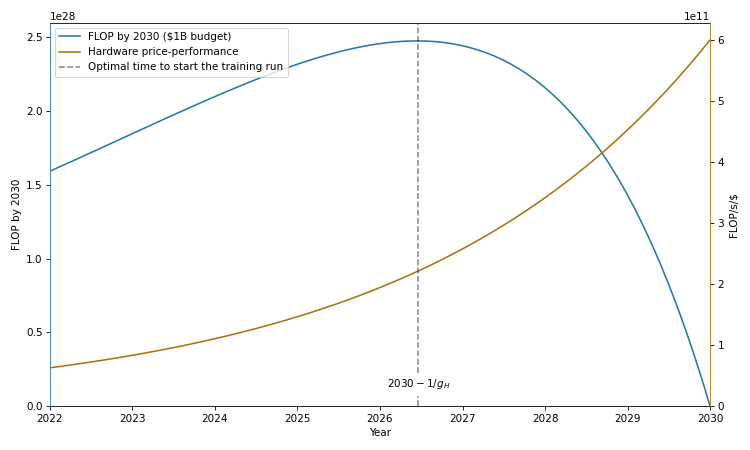
Training runs of large machine learning systems are likely to last less than 14-15 months. This is because longer runs will be outcompeted by runs that start later and therefore use better hardware and better algorithms.
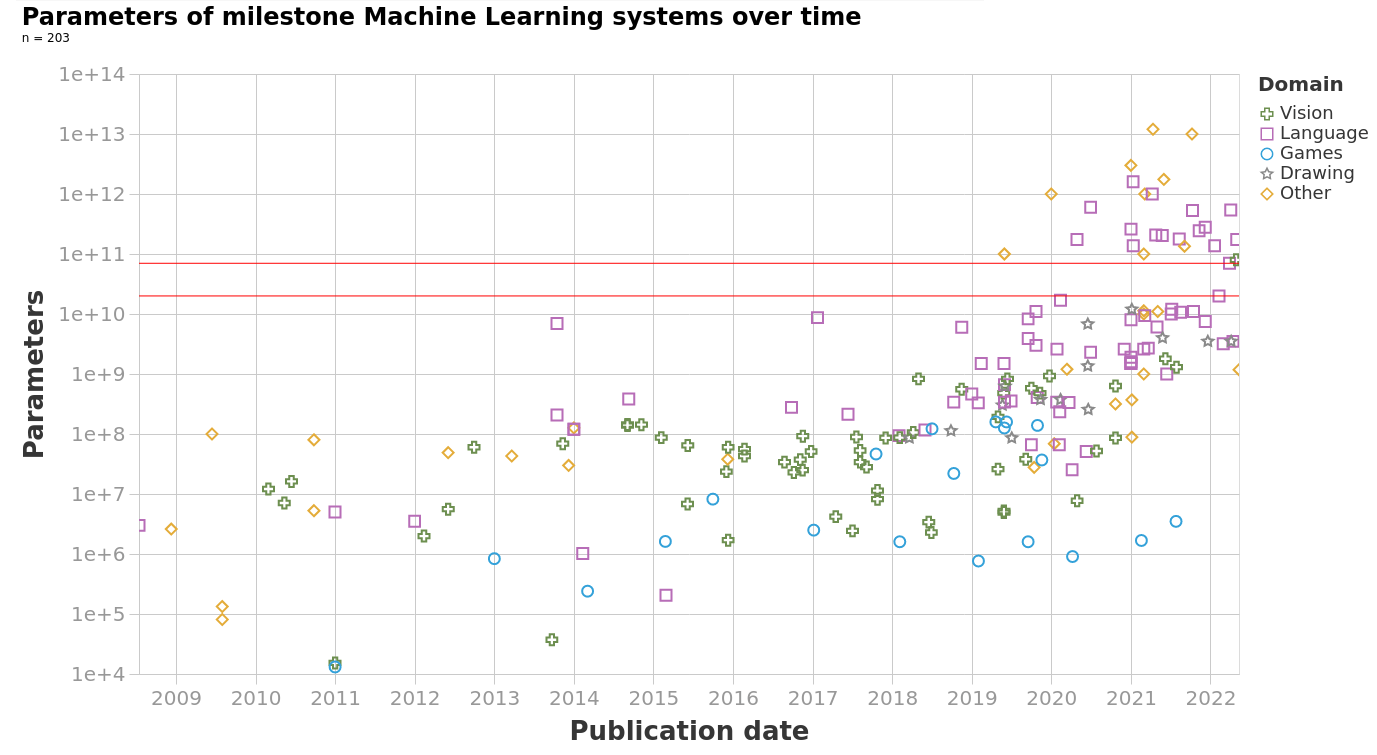
The model size of notable machine learning systems has grown ten times faster than before since 2018. After 2020 growth has not been entirely continuous: there was a jump of one order of magnitude which persists until today. This is relevant for forecasting model size and thus AI capabilities.
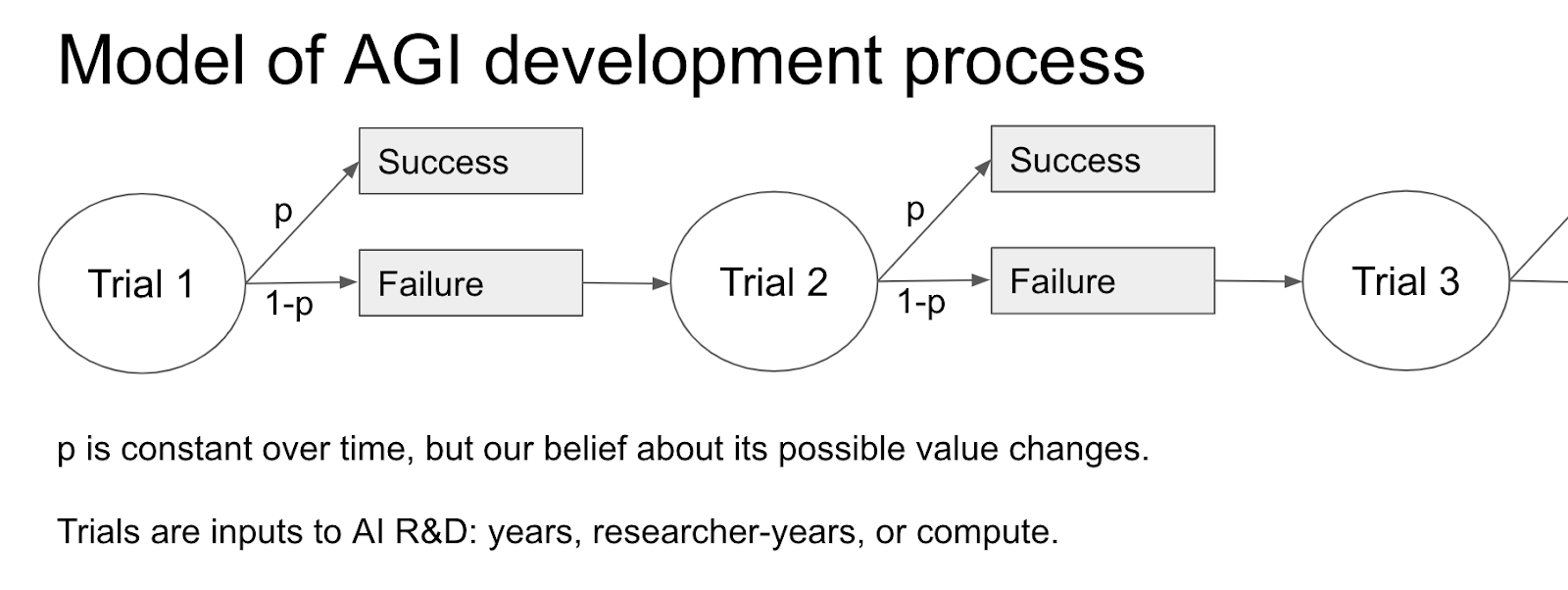
I give visual explanations for Tom Davidson’s report, Semi-informative priors over AI timelines, and summarise the key assumptions and intuitions
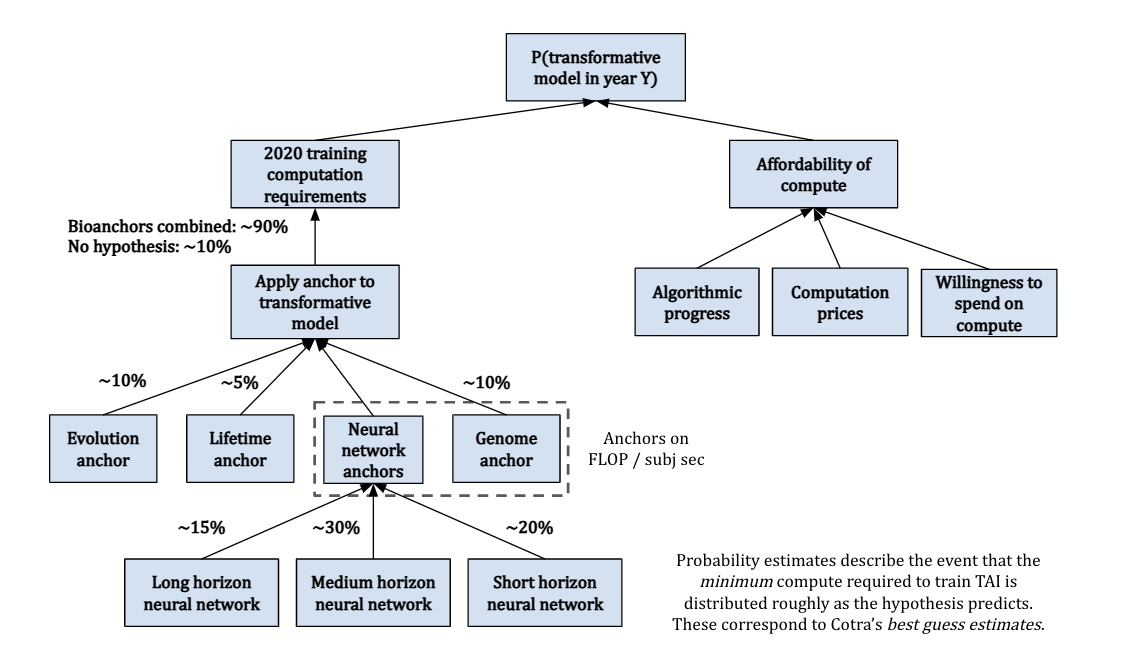
I give a visual explanation of Ajeya Cotra’s draft report, Forecasting TAI with biological anchors, summarising the key assumptions, intuitions, and conclusions.
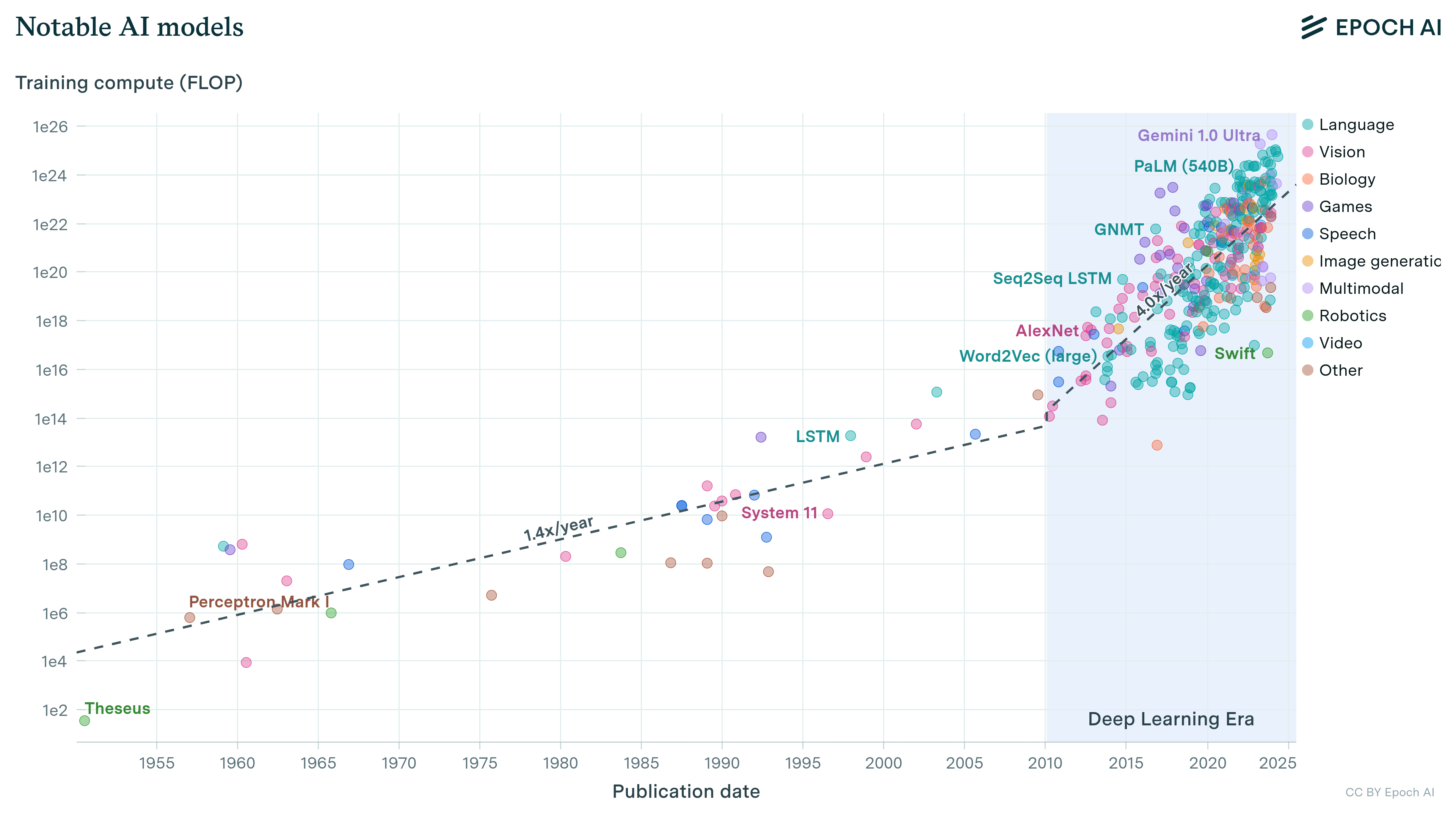
We’ve compiled a dataset of the training compute for over 120 machine learning models, highlighting novel trends and insights into the development of AI since 1952, and what to expect going forward."
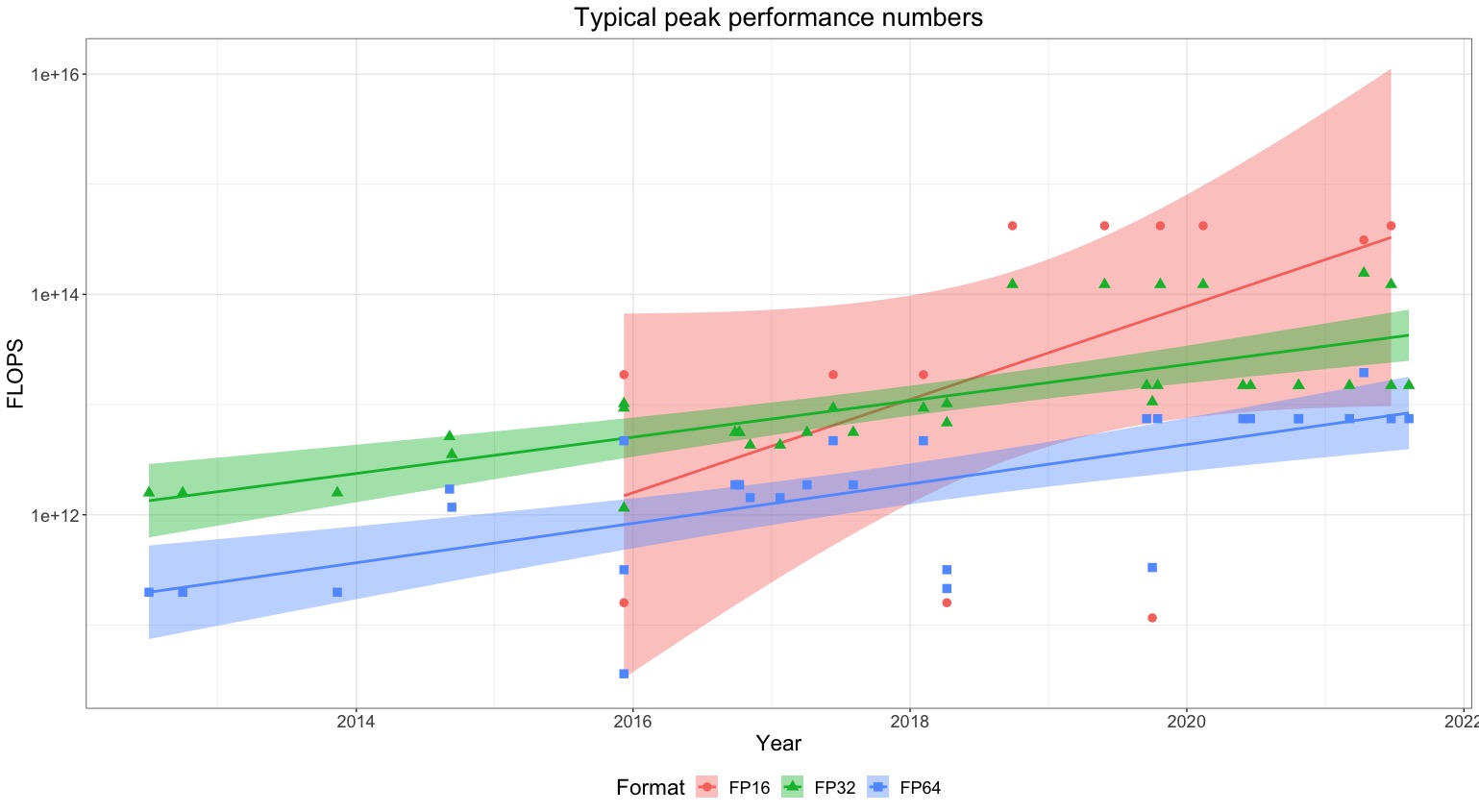
We describe two approaches for estimating the training compute of Deep Learning systems, by counting operations and looking at GPU time.