Recently, METR released a paper arguing that the length of tasks that AIs can do is doubling every 7 months.
We can see this in the following graph, where the best AI system1 is able to do roughly hour-long tasks at a 50% success rate on average:
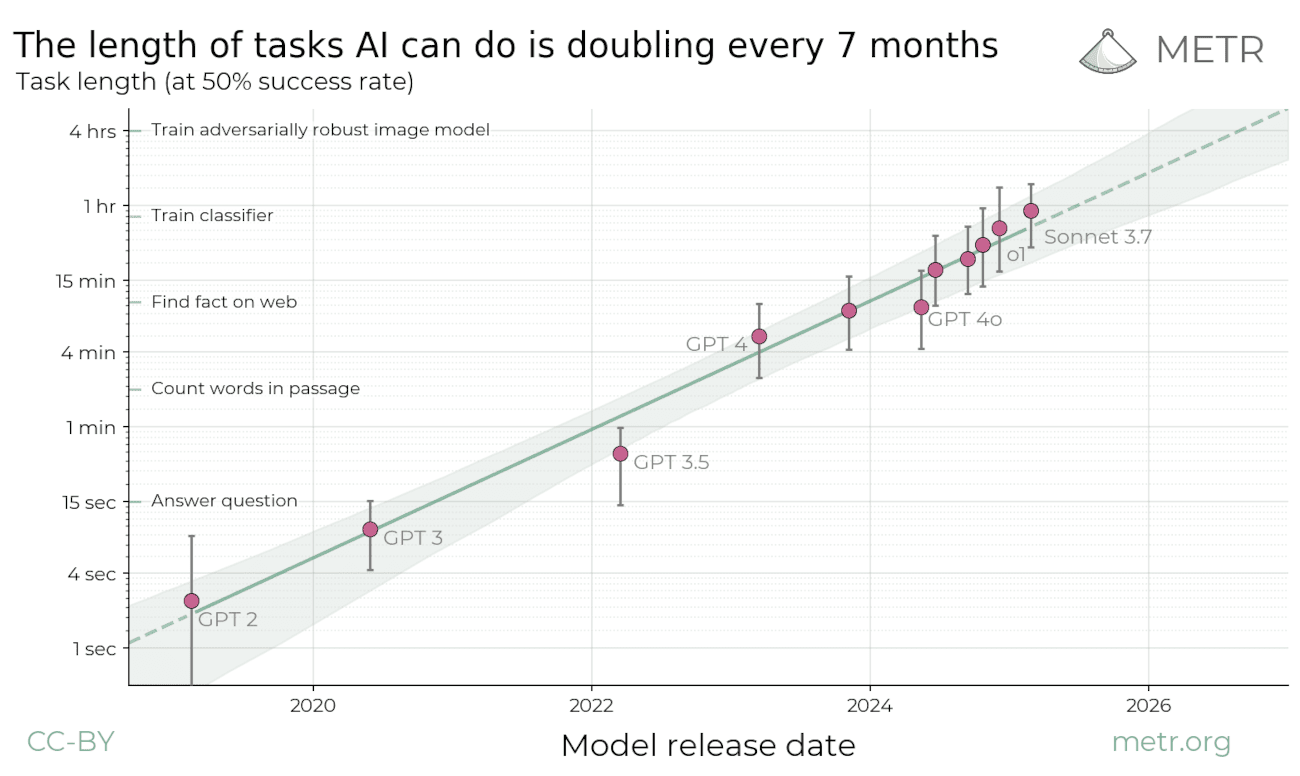
METR’s research finds that AIs are rapidly able to do longer and longer tasks, where length is measured by the time it takes for a human with requisite expertise to do the task.
But there’s a big problem here – if AIs are actually able to perform most tasks on 1-hour task horizons, why don’t we see more real-world task automation? For example, most emails take less than an hour to write, but crafting emails remains an important part of the lives of billions of people every day.
Some of this could be due to people underusing AI systems,2 but in this post I want to focus on reasons that are more fundamental to the capabilities of AI systems. In particular, I think there are three such reasons that are the most important:
- Time-horizon estimates are very domain-specific
- Task reliability strongly influences task horizons
- Tasks are very bundled together and hard to separate out.
While it’s hard to be quantitative about just how much each of these reasons matter, they’re all strong enough to explain why many tasks with 1-hour or even 10-minute horizons remain unautomated.
1. Time-horizon estimates are very domain-specific
Probably the most important reason is that these estimates of time horizons are very domain-specific, and it’s very unclear how much these generalize to broader task automation.
In particular, the time horizon estimates were estimated based on three task sources (HCAST, RE-Bench, and SWAA Suite), all of which are heavily software-related. But it’s not hard to find examples with much shorter (or longer) task horizons, especially if we look into other domains.
For example, Tamay Besiroglu points out that if we’d chosen chess as the relevant task domain, a similar analysis would’ve predicted that AI systems in the early 1990s would’ve been able to operate on hour- or day-long time horizons3:
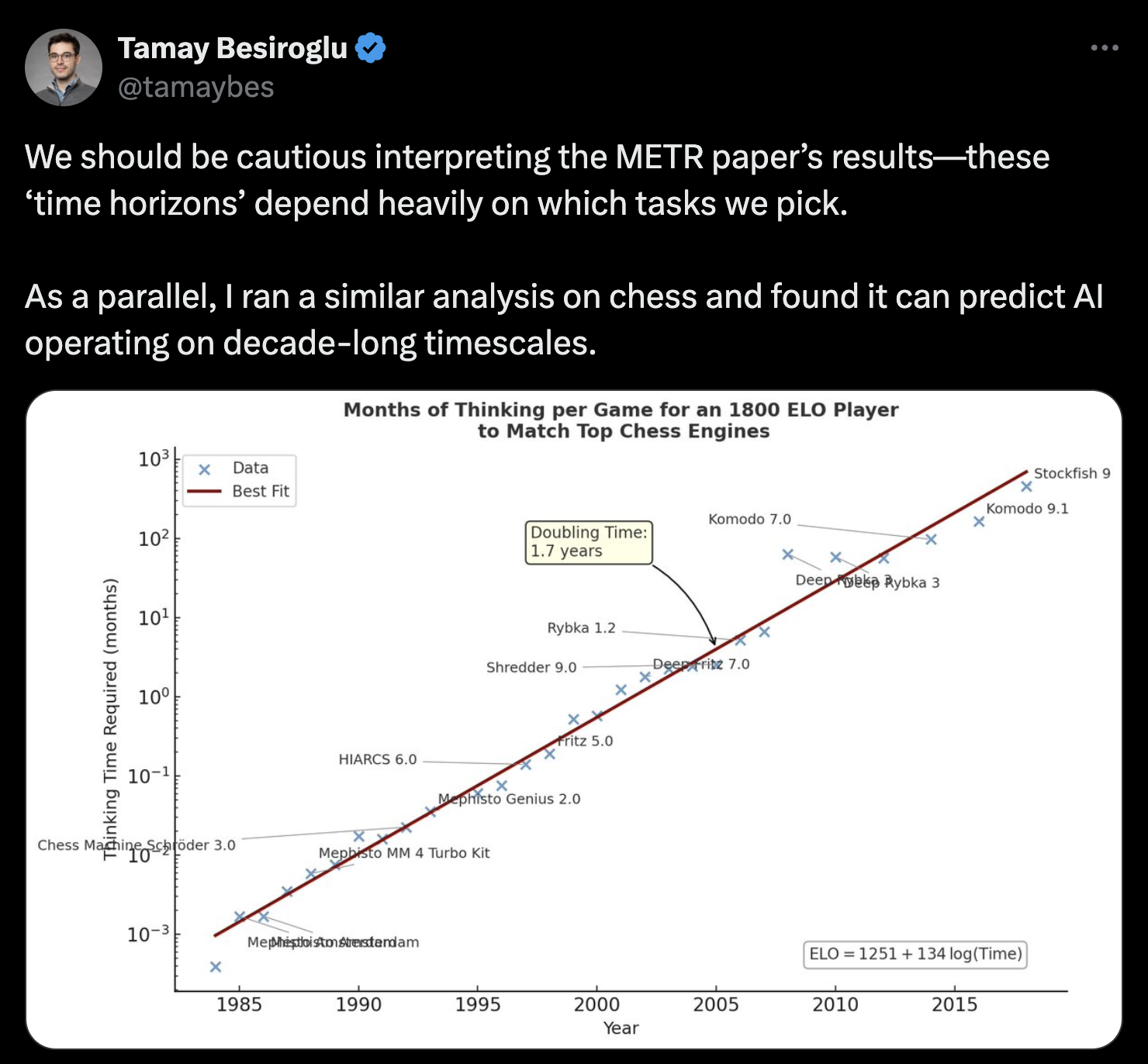
Time-horizon estimates are heavily dependent on the tasks used to make measurements. For example, using chess as the relevant task would’ve led to absurd predictions about the time horizons of AI systems in the 1990s. For modern systems it predicts decade-long timescales, which is likely false but we don’t have empirical evidence for how humans perform on chess over these durations.
And we shouldn’t understate just how vital this domain-dependence is for how well we can predict automation impacts. For instance, we know that remote-work tasks comprise roughly 35% of tasks in the US economy by some measures, and the fraction is smaller still for things related to software in particular. This already means that the time-horizon estimates may not be representative of most tasks in the economy.
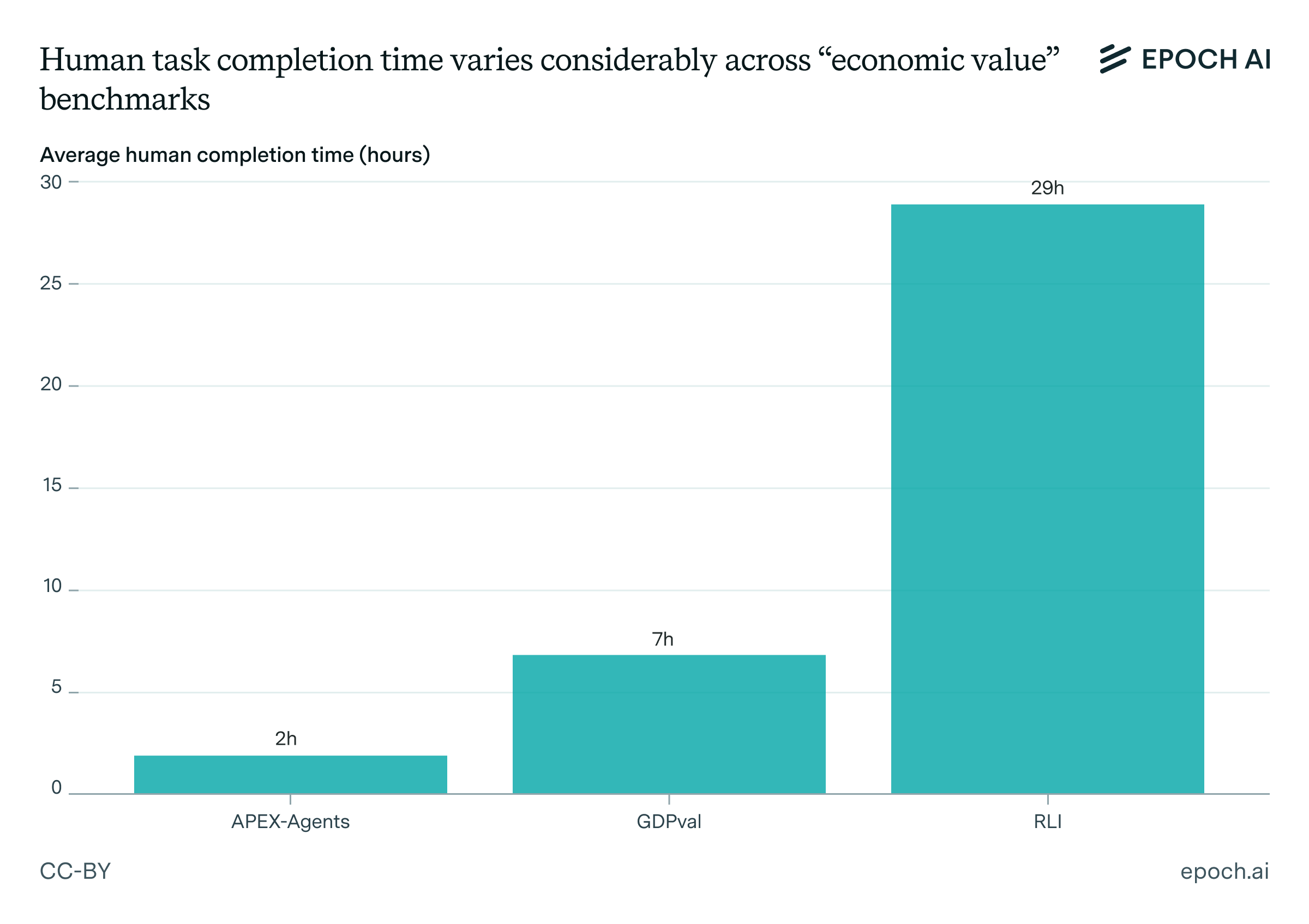
Similar problems persist even within software-related tasks. For example, the OSWorld benchmark consists of simple computer use tasks, but while humans score ~73% with a median time of ~112 seconds, current state-of-the-art systems score a little over 40%.4 In the other direction, AI systems are now capable of quickly retrieving information from long texts that would take most humans days to read.5
All this is to say that depending on the task, the estimated task time horizon can vary by many orders of magnitude! As a result, we shouldn’t be very surprised to see real-world tasks with time horizons substantially shorter than 1 hour but have yet to be automated.
2. Task reliability strongly influences task horizons
Another issue here is reliability. Reading the fine print on the METR graph suggests that the best AI systems of today are able to roughly do hour-long (software-related) tasks, at a 50% average success rate. But what happens if you change the success rate threshold?
To see what happens, we need to look more closely at the paper’s methodology. For each AI model, the authors fit a sigmoidal relationship that relates the model’s success rate on some task to the time it takes for humans to complete the task. They then pick a particular success rate (namely 50%) to get the associated ~1h task time-horizon for current frontier models.
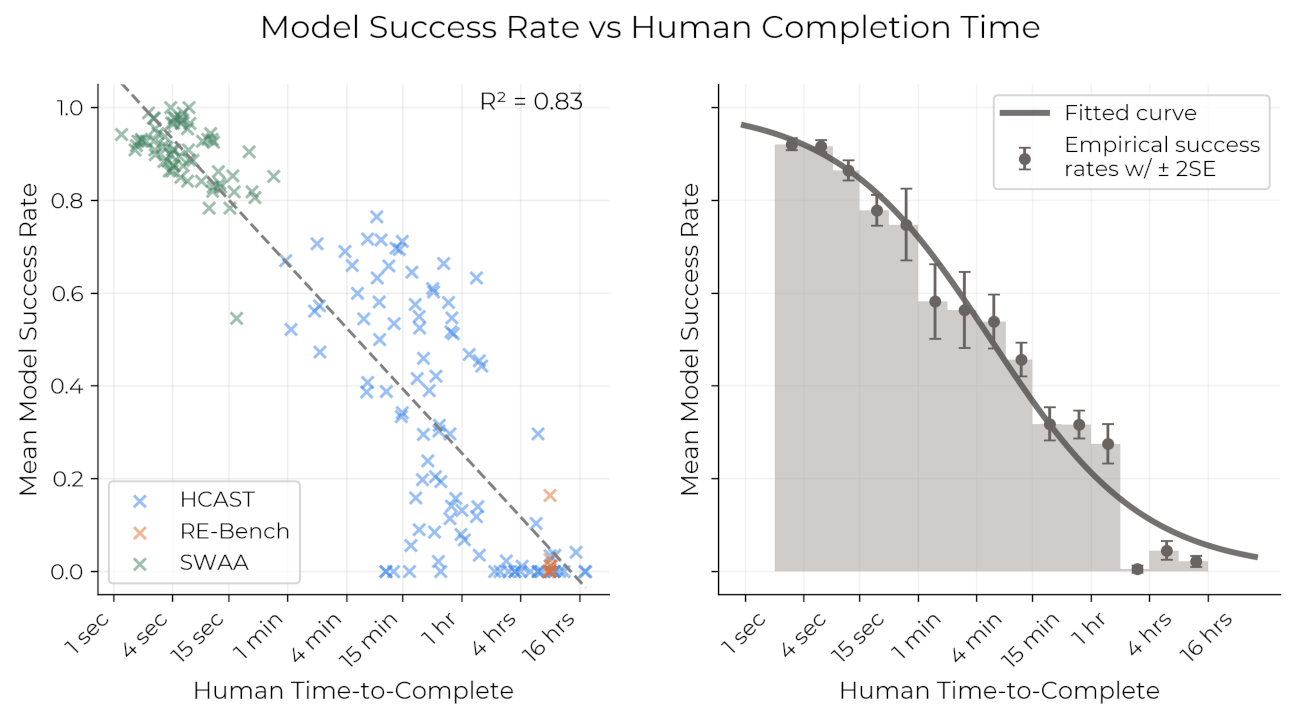
Time horizons were estimated by gathering data on human task completion times and model success rates, and doing curve-fitting. It does not represent the minimum of the human completion times across all tasks.
They also consider 80% reliability and find that the time horizon drops from 1h to around 15 minutes. But we probably want to push things even further – real world tasks often require success rates to be 95% or higher, and this reduces the time horizon even further (a classic example is autonomous vehicles, but overall it’s not clear to me what the “right” accuracy should be in general, and that makes this argument less forceful). For example, a 99% success rate corresponds to a task horizon below 1 minute, based on a naive extrapolation of the sigmoidal model.6
That being said, the authors note that estimating time horizons at such extreme success rates is unreliable due to insufficient high-quality data at these accuracies. Furthermore, one could also argue that we shouldn’t just consider the success rates for the AI systems; we need to compare this to the success rates of humans as well! And there’s certainly some truth to this – Appendix B.1.1 of the paper shows that human success probability also drops quite a bit for longer tasks. For instance, while 4-second tasks have ~100% success rate, 1h-tasks have ~50% success rates among the human baseliners.
However, the same appendix also lists important reasons against such a counterargument. Most pertinently, a substantial fraction of the human failures seemed to be due to reasons that aren’t applicable to AI models, such as lacking expertise, and giving up on the task due to interruptions or boredom. This was likely in part due to the way human baseliners were paid, which incentivized making quick guesses or giving up early, in order to move to tasks where expected earnings were higher.
All things considered, I think the evidence is sufficiently strong for my argument here to follow through. Namely, task reliability strongly influences the associated time horizon, enough to shrink the 1h time horizon by more than ten-fold.
3. Real-world tasks are bundled together and hard to separate out
Besides being task-specific, the tasks considered in the METR paper also tend to be close-ended tasks that don’t require additional context. But that’s very different from the nature of real-world tasks, even if we restrict ourselves to the purview of software.7
Ajeya Cotra captures this issue quite succinctly, based on an interview of AI researchers:

To see why this is so important for task automation, let’s go back to the example of email – why hasn’t this been fully automated yet? Current LLMs seem perfectly capable of crafting reasonable-sounding emails, and can do so much faster than even the quickest human writers.
So what gives? The answer to this becomes much clearer if we concretely consider what writing emails involves. So to illustrate this, here are some emails that I’ve received over the last year, and reasons that I think these emails weren’t automated.
| Type of received email | Bottlenecks to automation |
|---|---|
| Email about a potential job + chat about it |
|
| Following up about a previous conversation about a project |
|
| Requesting feedback on work |
|
| Providing advice for people interested in Epoch’s line of work |
|
The common patterns across these examples seem to be that (1) AI lacks some kind of data or context, (2) it lacks context about my preferences. On top of this, AI systems might not successfully execute the task even if it had the relevant data or context, though I think the argument follows through even without this additional complication.
But suppose we really wanted to fully automate email – what would that entail? While some things are easily fixed (like allowing AI systems to access my schedule), other things are much more complicated and open up a can of worms. We might need a lot of infrastructure to be set up to regularly record in-person conversations, while dealing with numerous potential security and privacy issues, as well as shifts in societal norms (e.g. around having much of peoples’ daily lives recorded). AIs would also need to have sufficient context about the user’s preferences on communication style, what kinds of opportunities they’re interested in, and so on.
This isn’t just an isolated example – these kinds of context dependencies are ubiquitous throughout the economy. It’s an important reason why task automation has historically required a lot of workflow reorganization.
Discussion
To my mind, everything I’ve said so far is just part of a broader issue about AI benchmarks – namely, why don’t AI benchmarks reflect real-world task automation? I previously wrote about why this has been the case historically, and this time I’ve discussed three fundamental reasons that apply to the present and future as well.
Due to these reasons, I think we should not interpret METR’s paper as saying “AIs can do most tasks that humans can do in 1 hour”. I don’t think researchers at METR would believe this claim either, though unfortunately I’ve seen some people interpreting things this way on Twitter. However, I do think that METR has found evidence for exponential improvements on the kinds of tasks that are usually captured by software-related benchmarks. As I alluded to earlier, the emphasis is more on the 7-month doubling time, and less on the current task time horizon that AIs can do.
Understanding the benchmark limitations I described above, and AI’s current time horizon on real-world tasks, is important when we’re talking about forecasts of future AI capabilities. For example, the approach of thinking about increasing task time horizons is the basis of the “time horizon extension” timelines forecast in the recent AI 2027 report.8 These limitations partly explain why some researchers have substantially longer timelines than the AI 2027 authors. But it doesn’t explain everything – another crucial factor is the extent to which AI R&D progress is bottlenecked by experimental compute (but that’s a topic for another post).
This understanding is also important for thinking about task automation itself. For instance, one might naively argue that if you were able to automate every 1 second task, you’d be able to automate the entire economy, since you can in principle split bigger tasks into shorter-horizon subtasks. This of course seems absurd, because this task decomposition introduces a ton of context dependence and difficulty in credit assignment.
But it does raise some interesting empirical questions. How context-dependent are different tasks, and how does this change depending on the time horizon? More generally, how hard is it to get AI systems to have access to the relevant data or context? How often do people use AI systems to perform “1 minute tasks”, “10 minute tasks”, and so on?9
I hope that the answers to questions like these will shed light on the importance of the bottlenecks I’ve outlined in this post. This’ll require good empirical evidence that may be hard to get, but it’ll also help us better understand the gaps between benchmark task horizons and real-world task automation.
-
Here the best AI system is shown as Claude 3.7 Sonnet, though note that a more recent evaluation finds that OpenAI’s o3 may be above trend, also broadly at a 1-2h time horizon.

-
For example this can be due to humans being highly miscalibrated about the capabilities of AI systems. One illustrative example here is the results from Nicholas Carlini’s GPT-4 Capability Forecasting Challenge, where the median participant seems to have performed worse than the strategy of “guess every task has 50% chance of success”. However I’m not sure to what extent this is really the main thing at play, based on the (weak) evidence we have from survey data. For instance, out of the 27% of the respondents in Lockey et al. 2025 reportedly never used AI intentionally at work, the majority (58%) said this was because “AI tools are not helpful, required or used for their work”. In comparison, reasons like “Not understanding how to use AI tools” and “Not trusting AI tools” were stated by 14% and 12% respectively.
-
While it might seem absurd in retrospect to generalize time horizons from chess to other domains in retrospect, some researchers saw solving chess as highly relevant to building AGI and thus a good proxy to optimize for. At a minimum, it raises the question of whether the focus on closed software-related tasks is an instance of the same phenomenon. Note also that the analysis in Tamay’s tweet is based on a speculative relationship between chess ELO and time horizon, but I think the broader point stands true.
-
At the time of writing, the top position on OS-world’s leaderboard is held by UI-TARS-1.5 with a score of 42.5%. Note that this example is merely meant to illustrate that there’s a lot of benchmark task-dependence, and we expect that OS-world will be close to saturated (>85%) by the end of the year.
-
For instance, Gemini 2.5 Pro scores 83.1% on the MRCR long-context benchmark, which requires maintaining context over synthetically-generated conversations that in principle could be made arbitrarily long.
-
Going from 50% to 80% is both a 4x change in odds and a 4x decrease in task horizon. Achieving 99% accuracy should correspond to a roughly 100x decrease in task horizon relative to 1h. This results in a task horizon below 1 minute, if the sigmoidal model is correct.
-
The authors of the METR paper were of course well aware of these kinds of issues, and one way they attempted to address them was to define a task “messiness” metric. This involves identifying 16 separate factors that might make real world tasks systematically different from benchmark tasks, and are relevant to AI performance (e.g. “Not purely automatic scoring” and “Dynamic environment”). The total messiness score is then determined by summing the number of such factors that are present.
-
This in particular is a forecast of the timelines until a “superhuman coder” is reached, that is “an AI system that can do any coding tasks that the best AGI company engineer does, while being much faster and cheaper”, instead of broad task automation.
-
Ajeya Cotra’s tweet thread includes some brief discussion of this in the context of AI research.
About the authors
Related work