Featured
Topic Overview
Updated Jul. 14, 2026

Data
Updated Jul. 21, 2026

Data
Updated Jul. 22, 2026
AI chips are the specialized hardware behind modern AI, designed to handle the massive computational demands of training and running advanced models. They are at the center of a global competition for compute, with performance improving rapidly and demand surging. Epoch tracks trends in AI chip performance, energy efficiency, and price-performance over time, as well as the supply chain dynamics and geopolitical factors shaping who has access to the most advanced hardware.
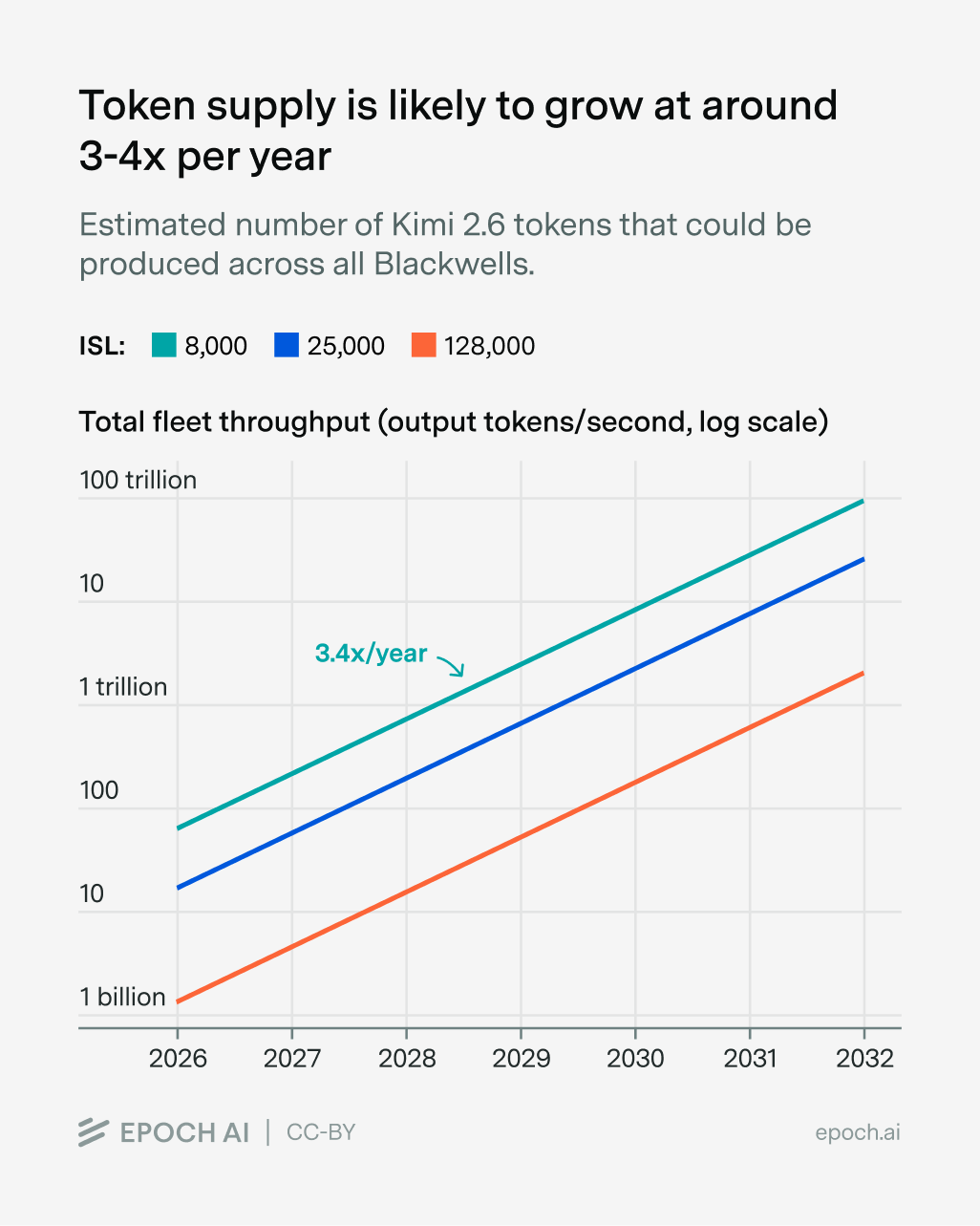
We estimated trends in global inference capacity and found that token demand appears to be growing much faster than supply.
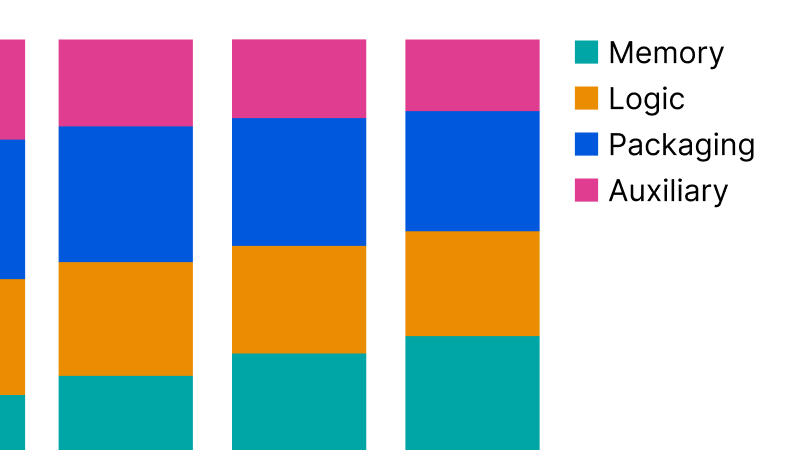
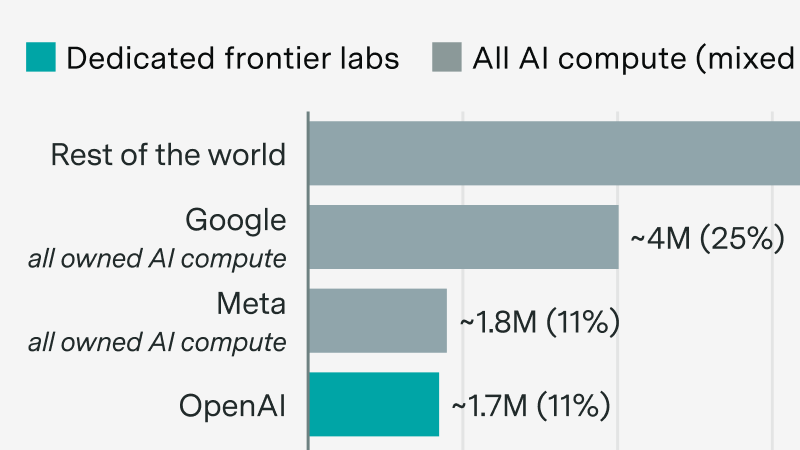
But Anthropic and OpenAI may rapidly grow their compute share in the next few years. After that, continued scaling would require an economic transformation.
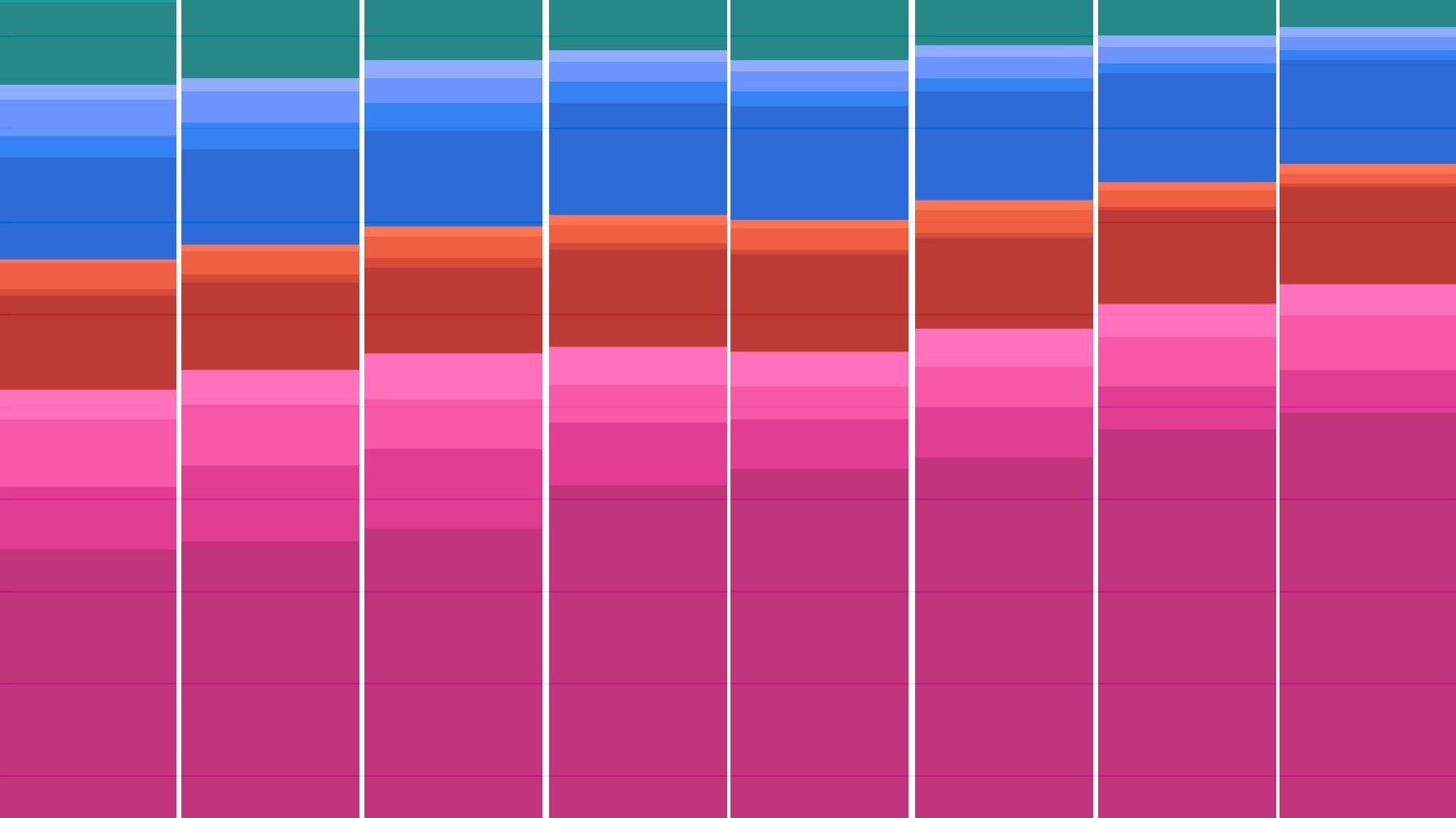
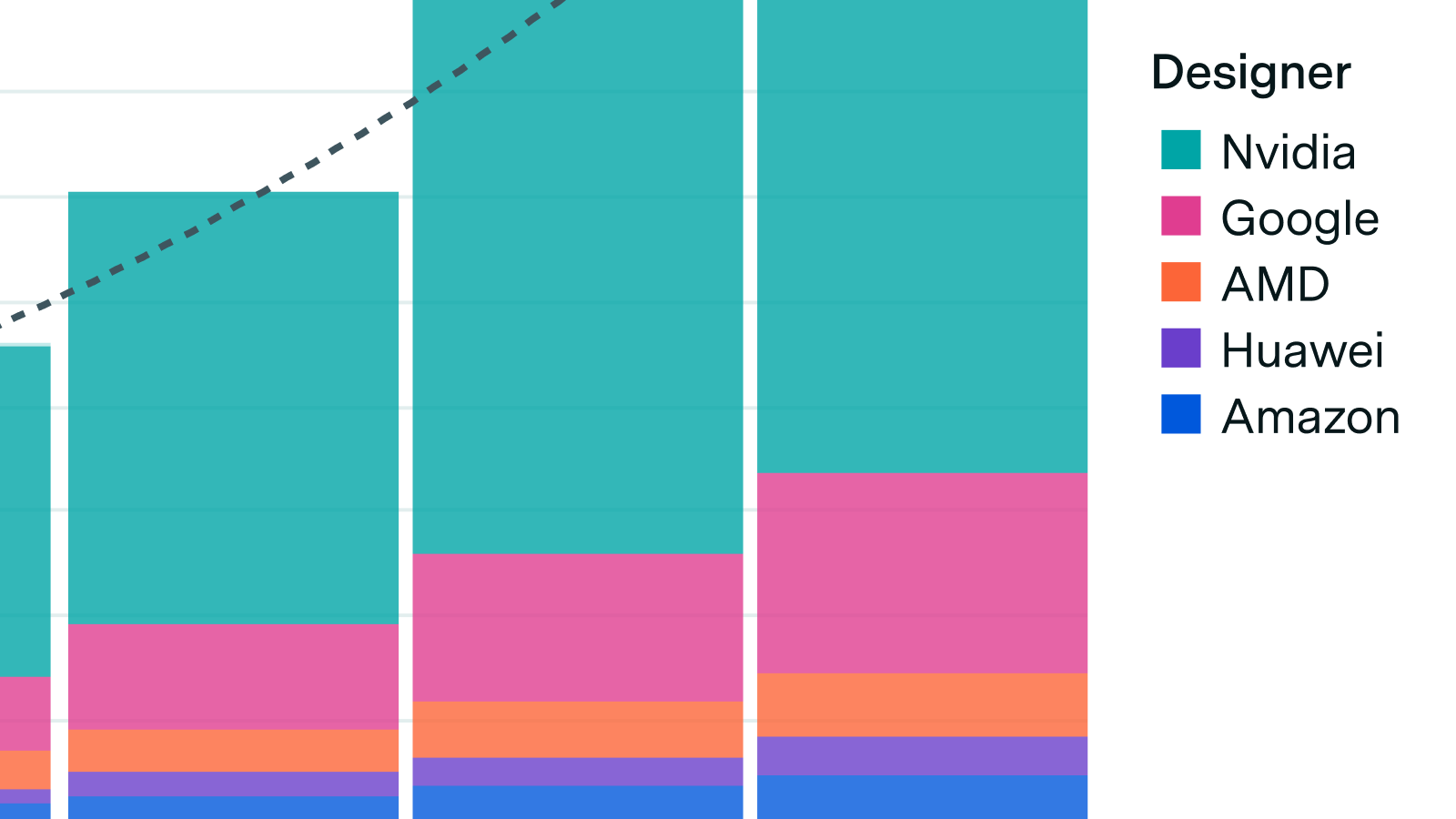
Our new AI Chip Components explorer tracks how much advanced-node logic, memory, and advanced packaging capacity is consumed by leading AI chip designers.
A look at the specialized hardware driving modern AI — why chips cost tens of thousands of dollars each, and why demand continues to outstrip supply.
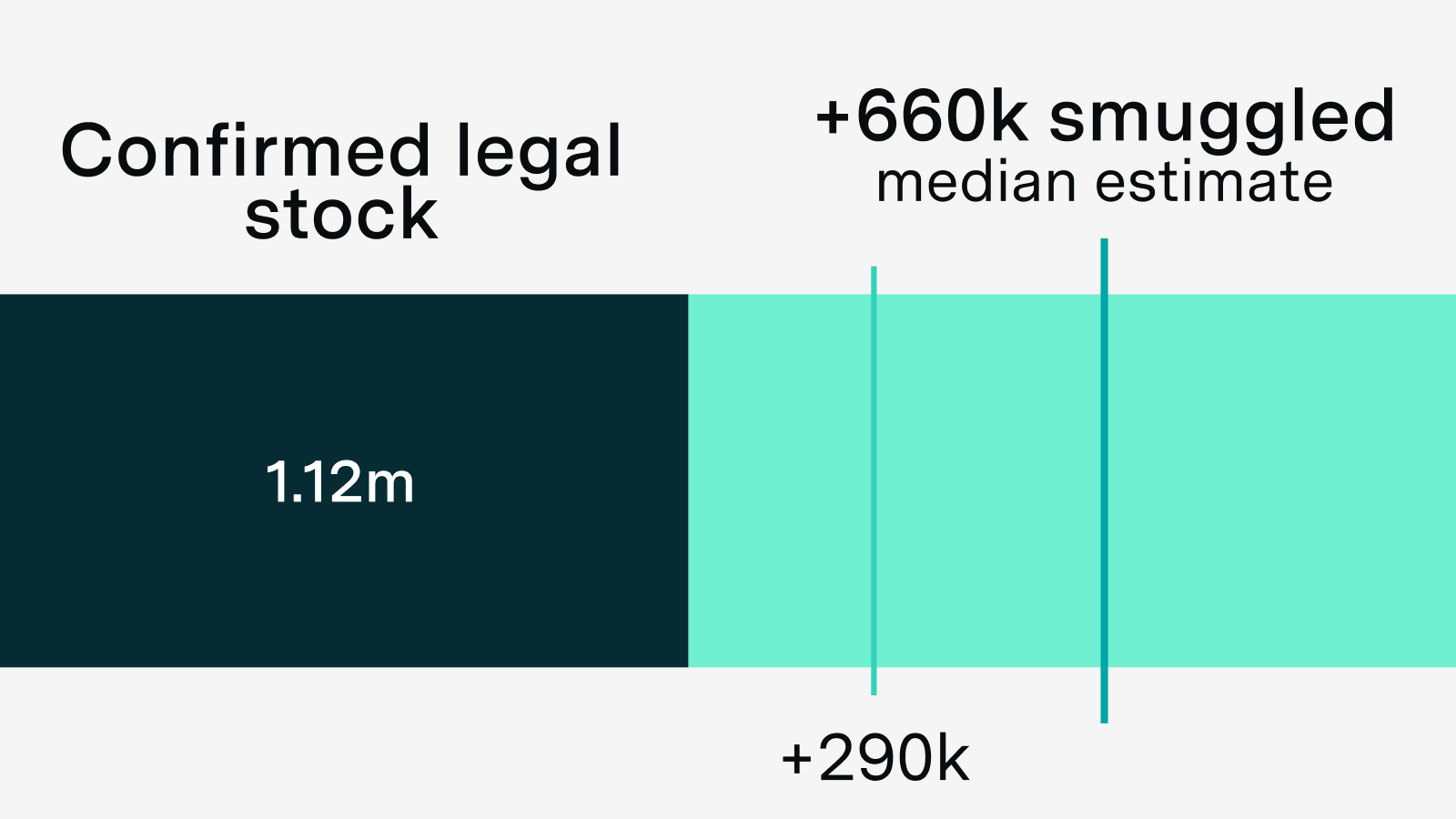
We estimate that between 290,000 and 1.6 million H100-equivalents (H100e) were smuggled to China through 2025. Our median estimate of 660,000 H100e would be roughly a third of China's total compute.
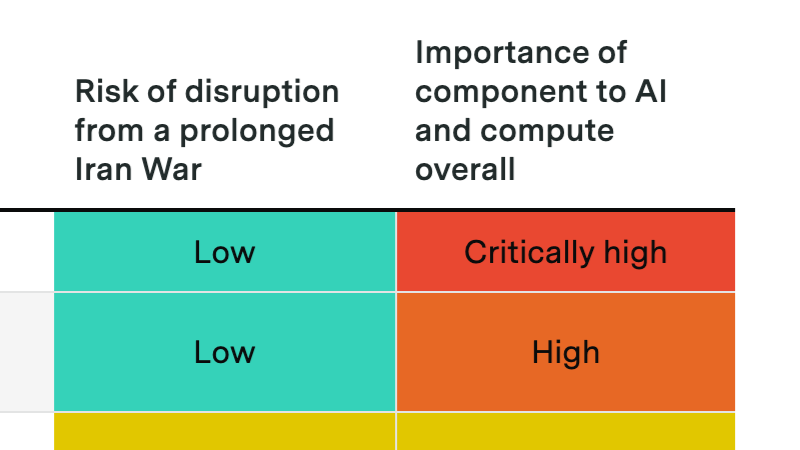
A prolonged Hormuz crisis probably won't derail the compute buildout, but it could slow data center expansion and disrupt Gulf investment flows into AI.
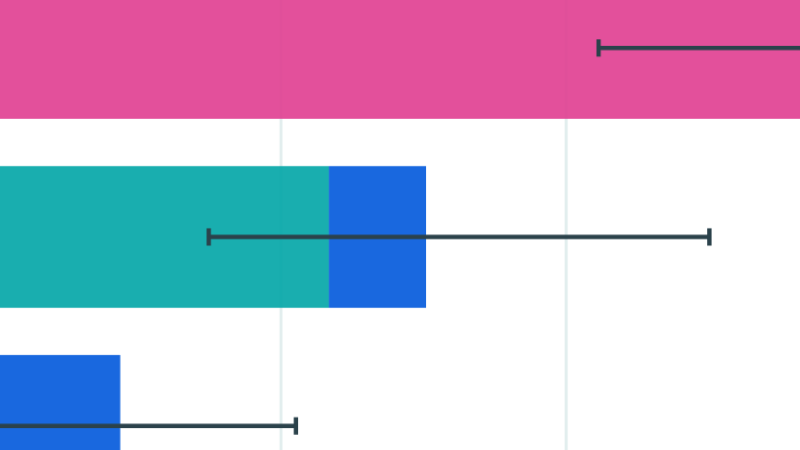

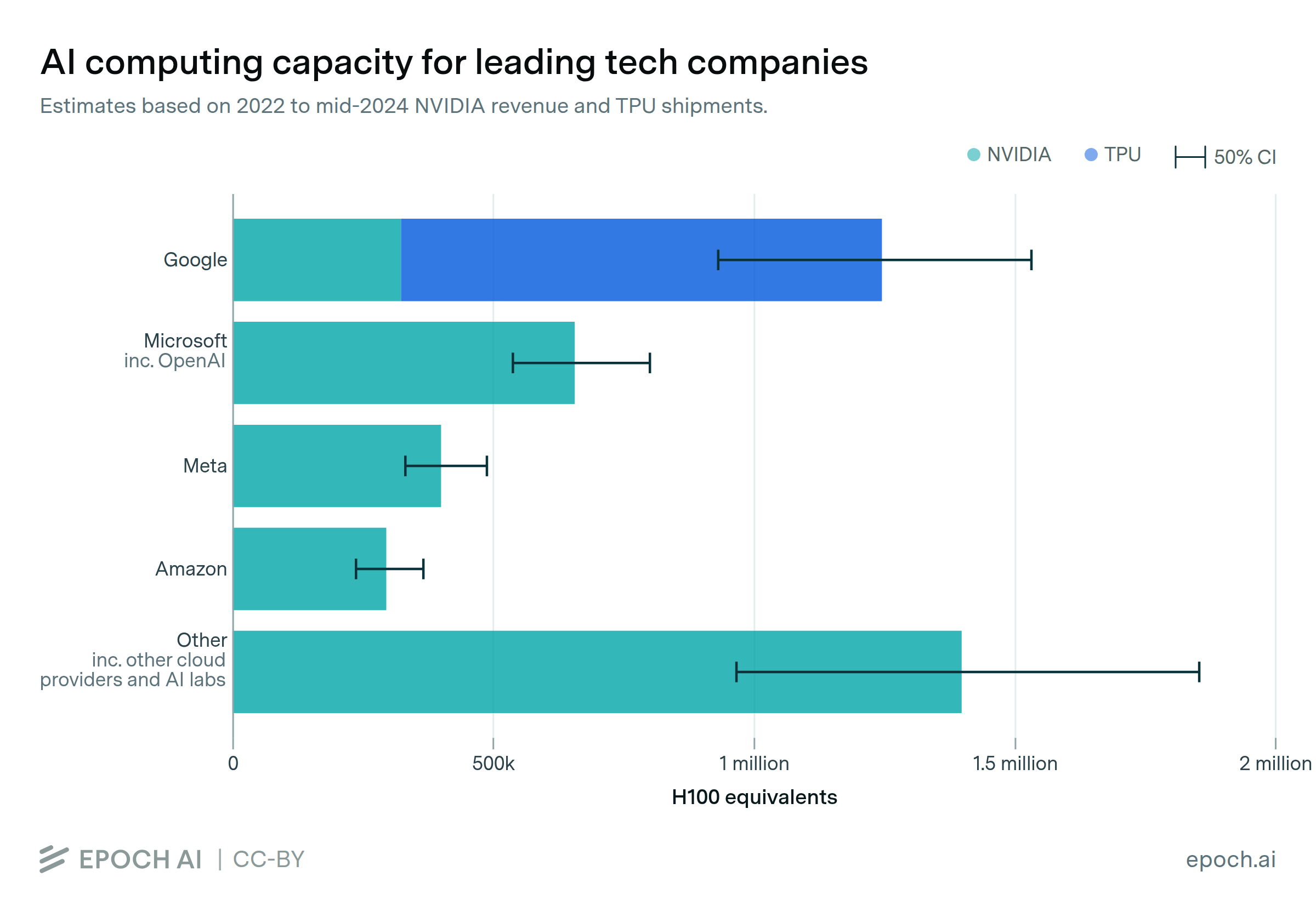
We announce our new AI Chip Owners explorer, showing which companies own the world’s leading AI chips.
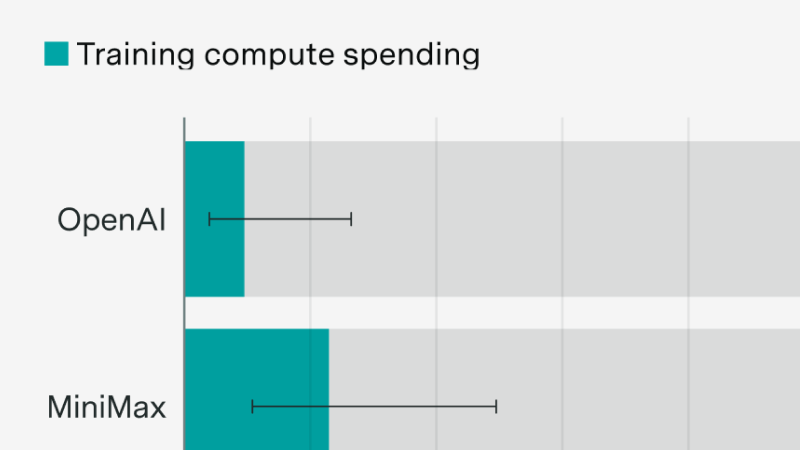
New evidence following the MiniMax and Z.ai IPOs
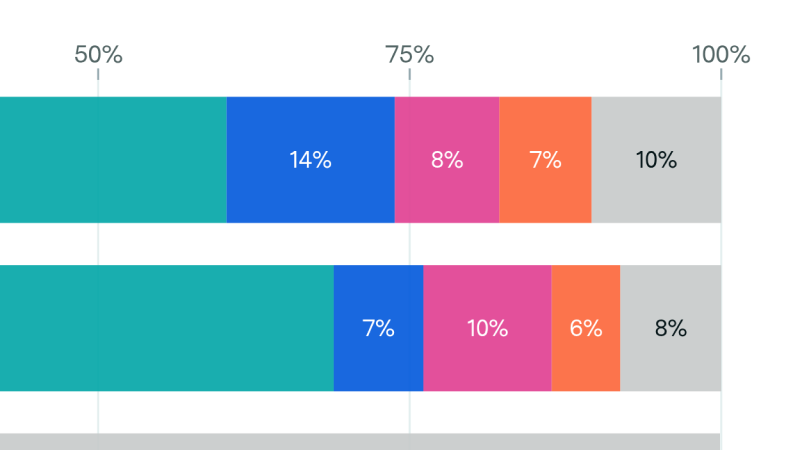
We announce our new AI Chip Sales data explorer, which uses financial reports, company disclosures, and more to estimate compute, power usage, and spending over time for a wide variety of AI chips.
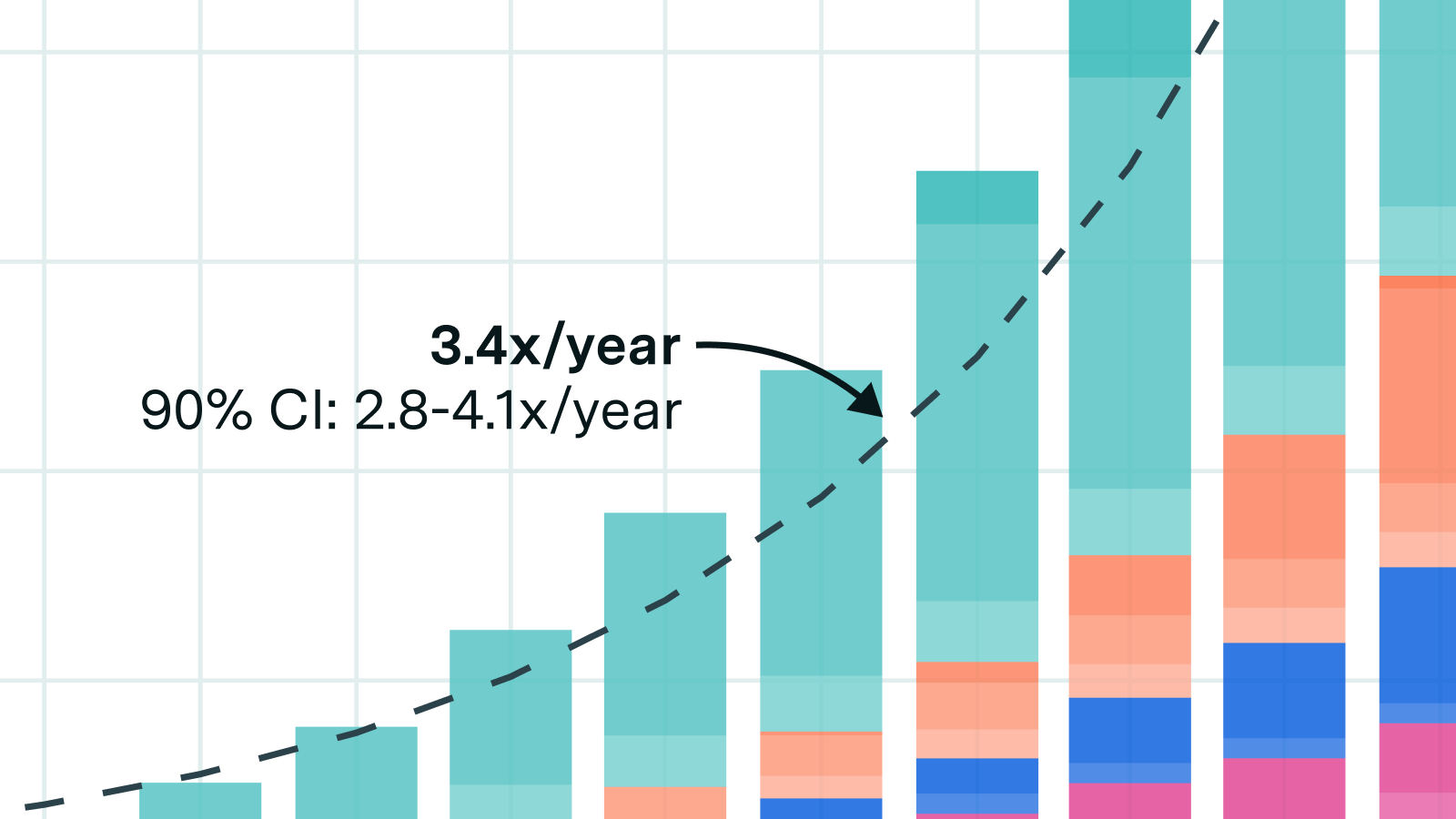
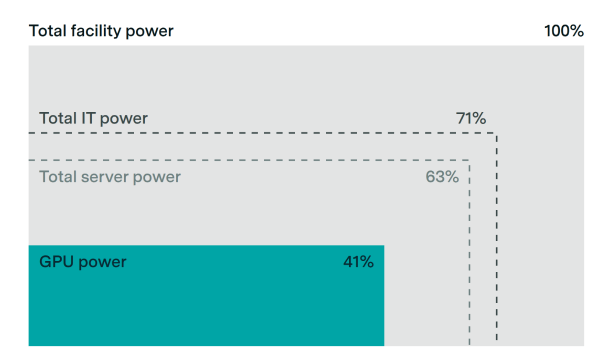


A heavily underappreciated dynamic when thinking about AI timelines.
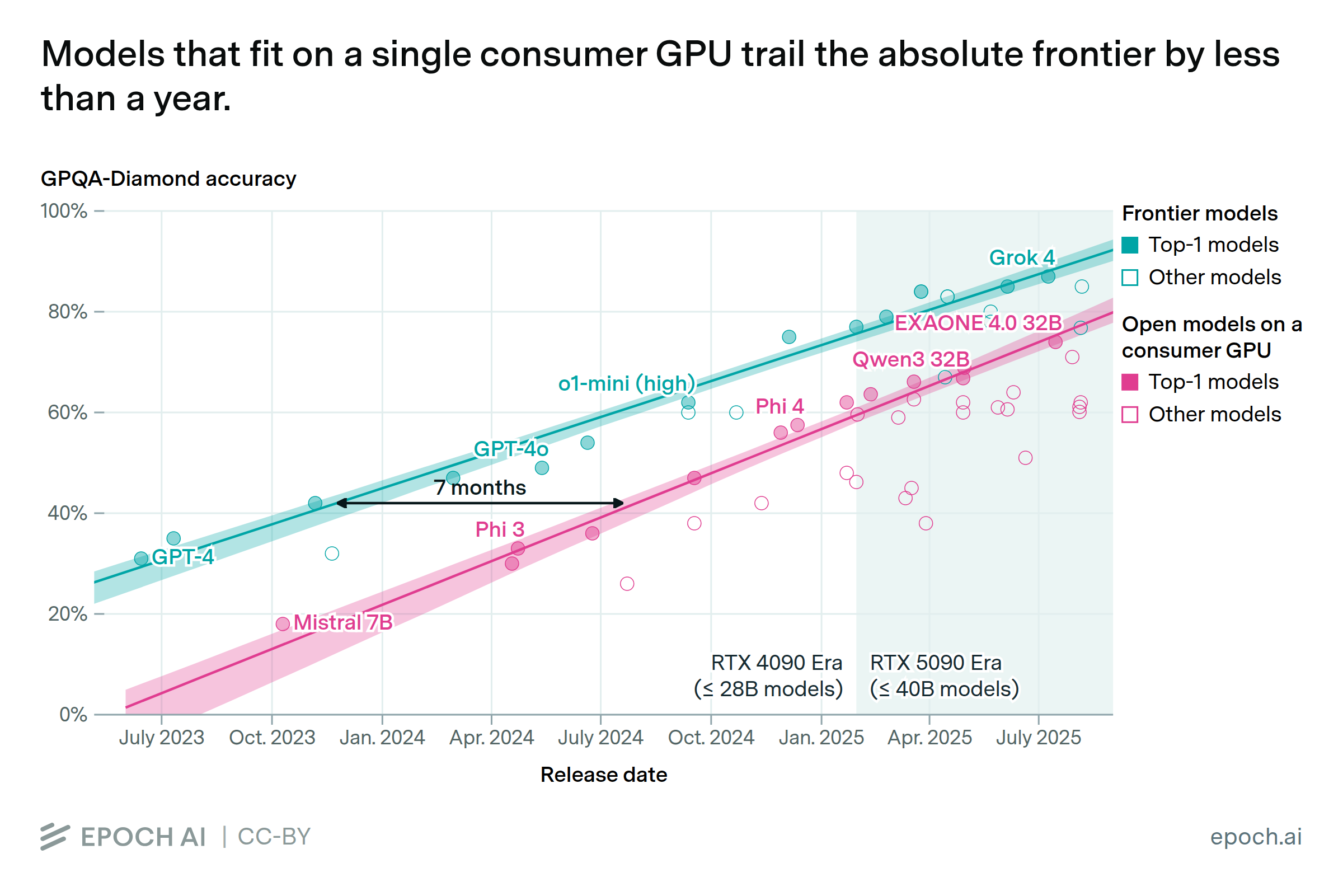
Chinese hardware is closing the gap, but major bottlenecks remain
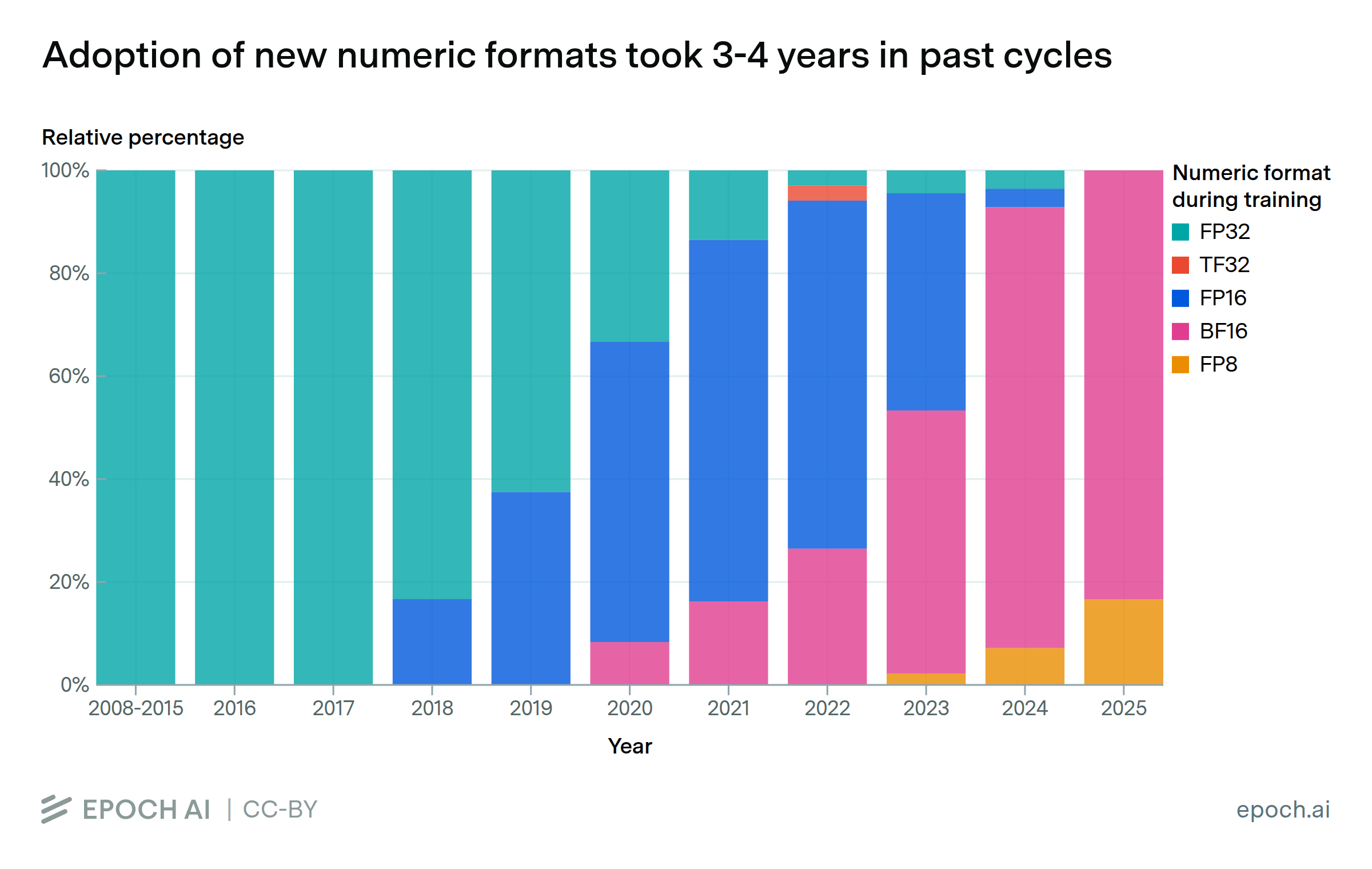
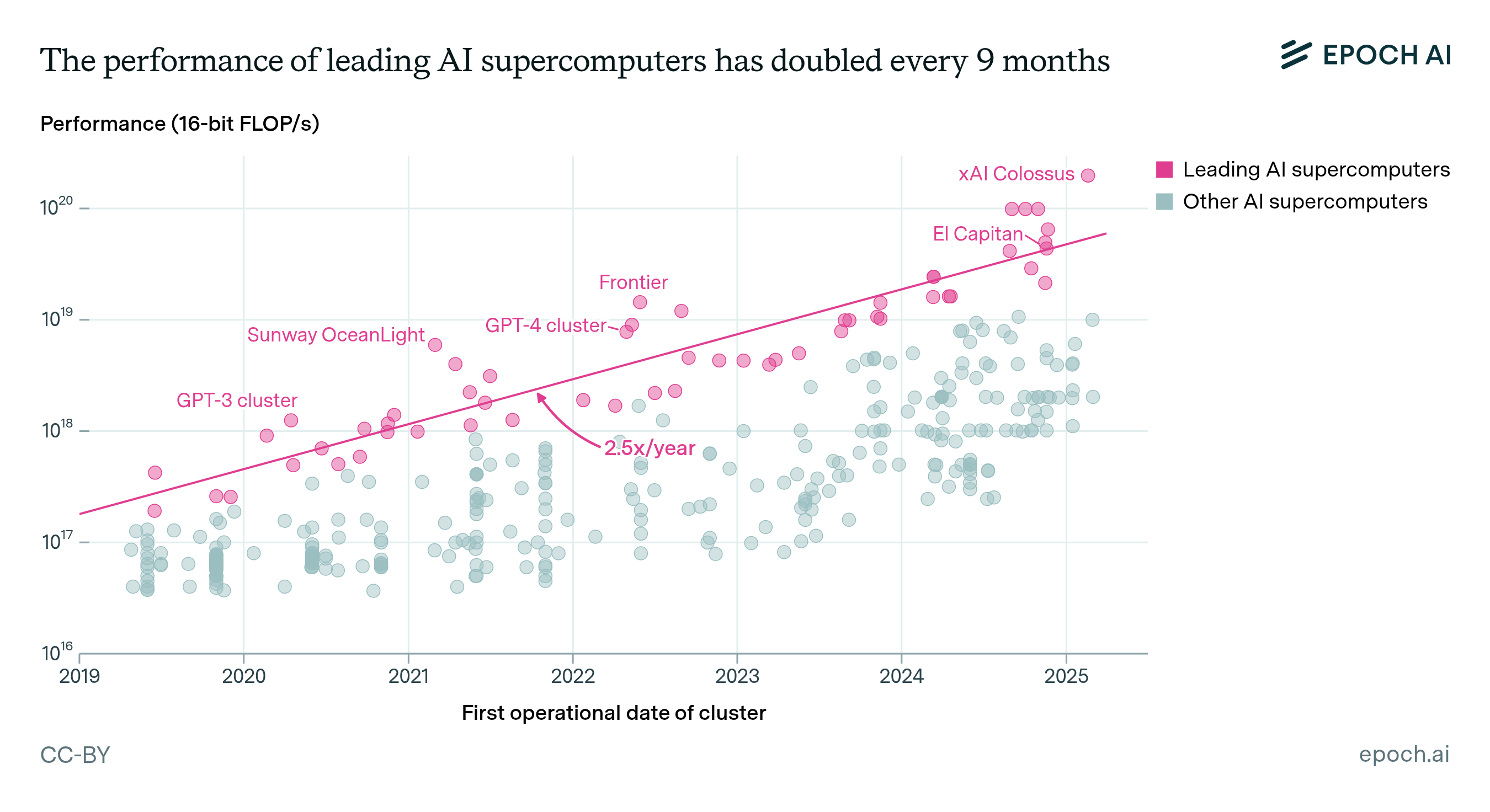
AI supercomputers double in performance every 9 months, cost billions of dollars, and require as much power as mid-sized cities. Companies now own 80% of all AI supercomputers, while governments’ share has declined.
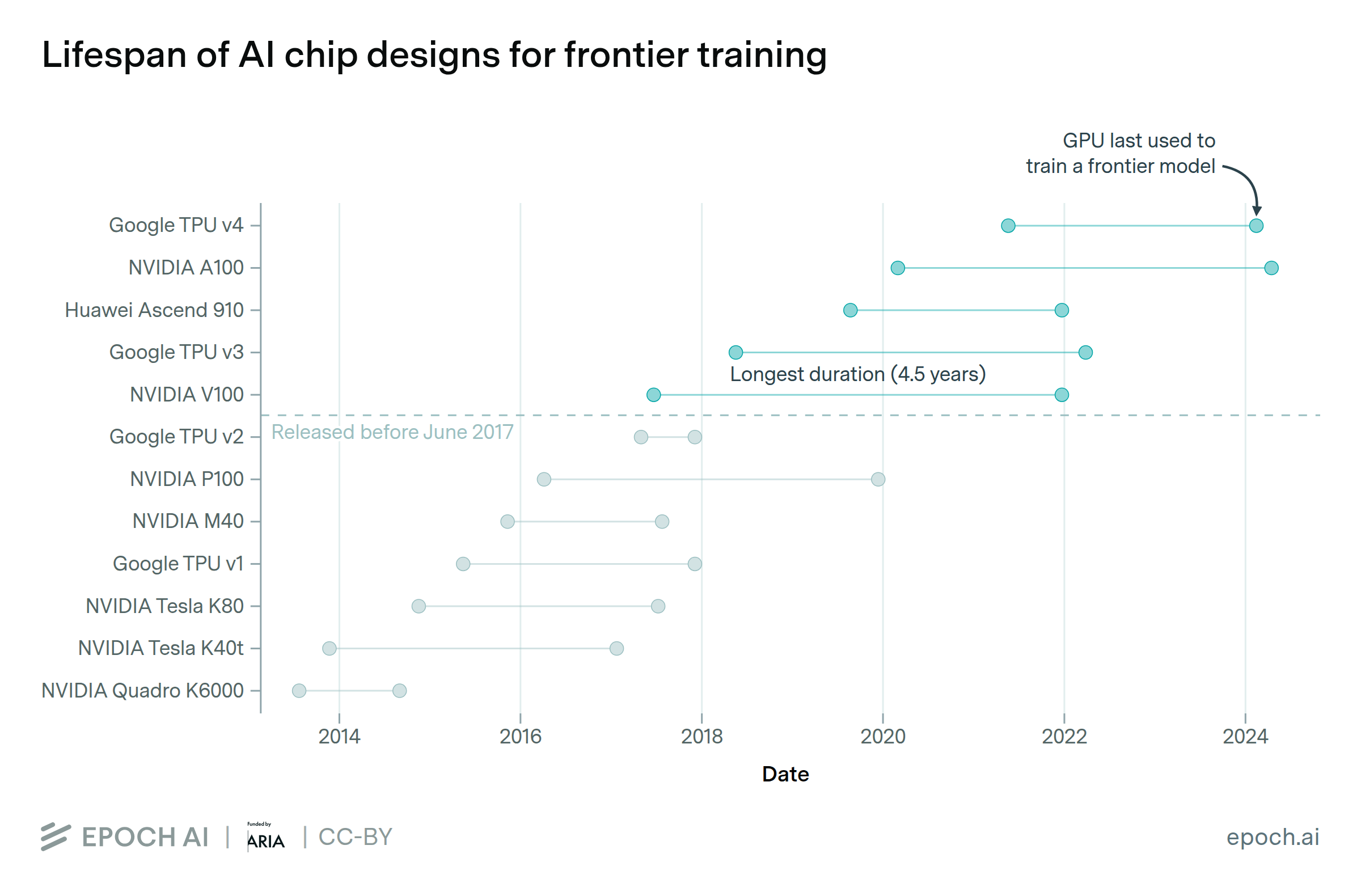
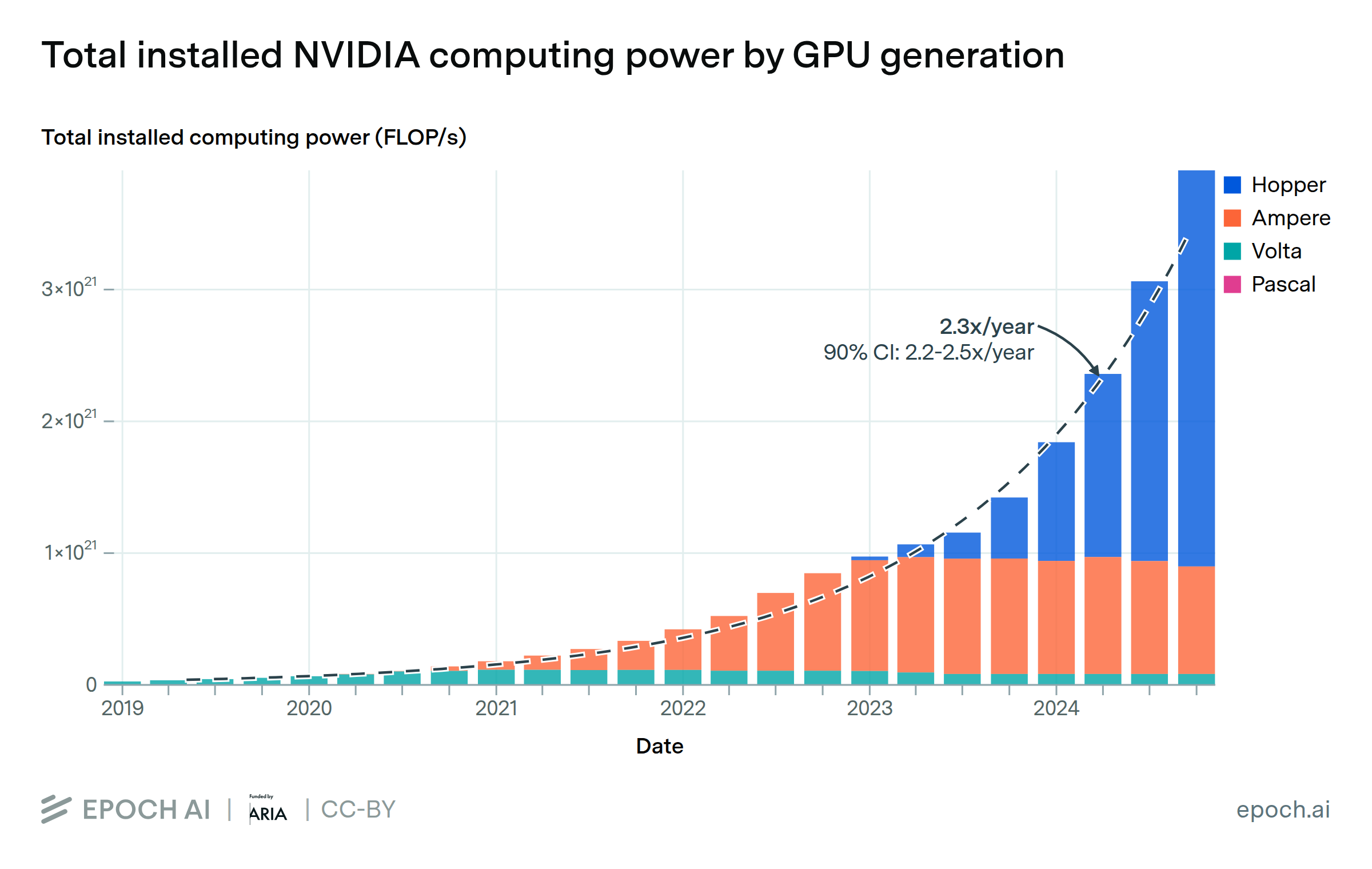
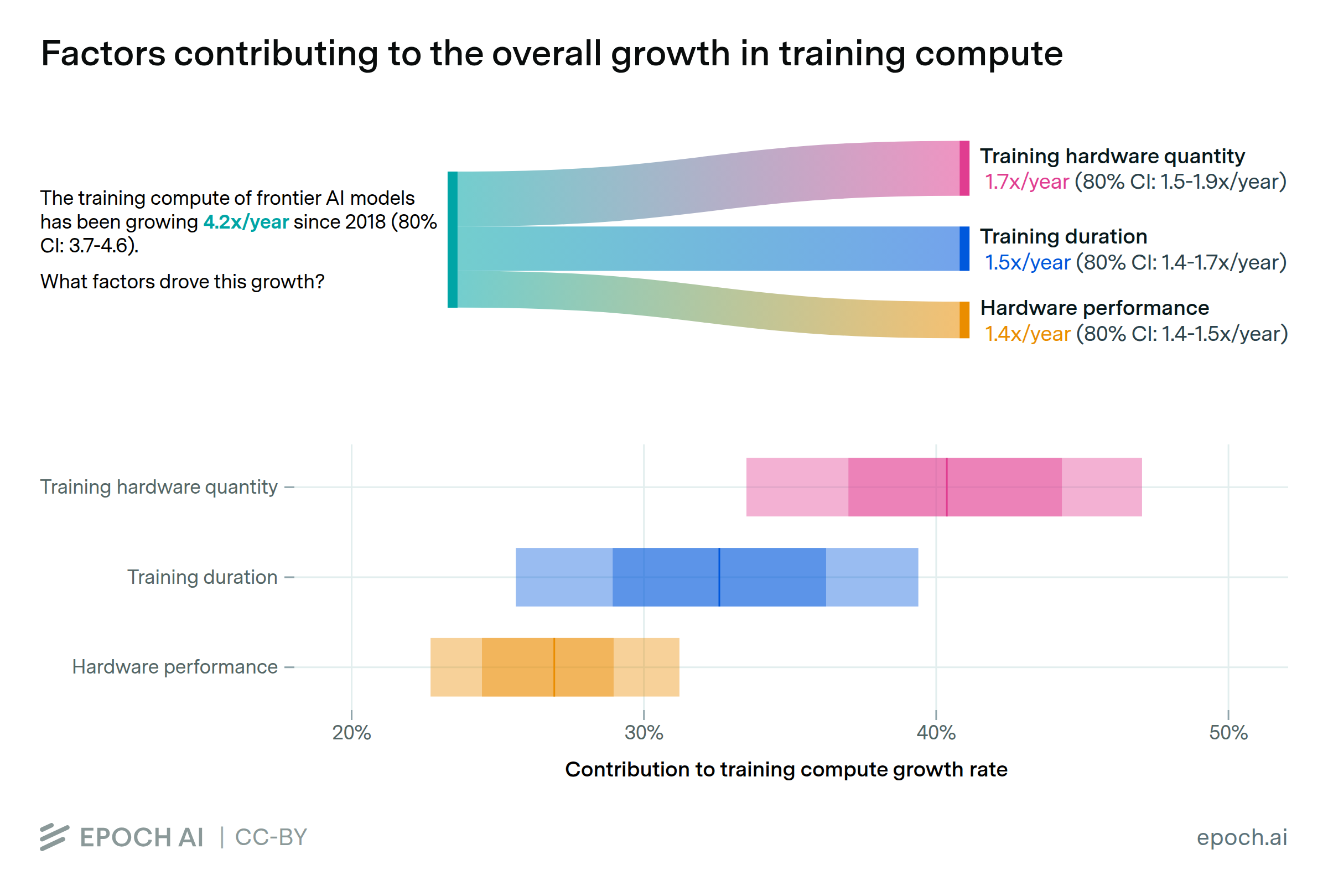
Export controls on China give the US a hardware lead of around 4 years in training frontier models, but essentially no lead in serving those models to users.

Our analysis shows hardware failures won't limit AI training scale. GPU memory-based checkpointing enables training beyond millions of GPUs.
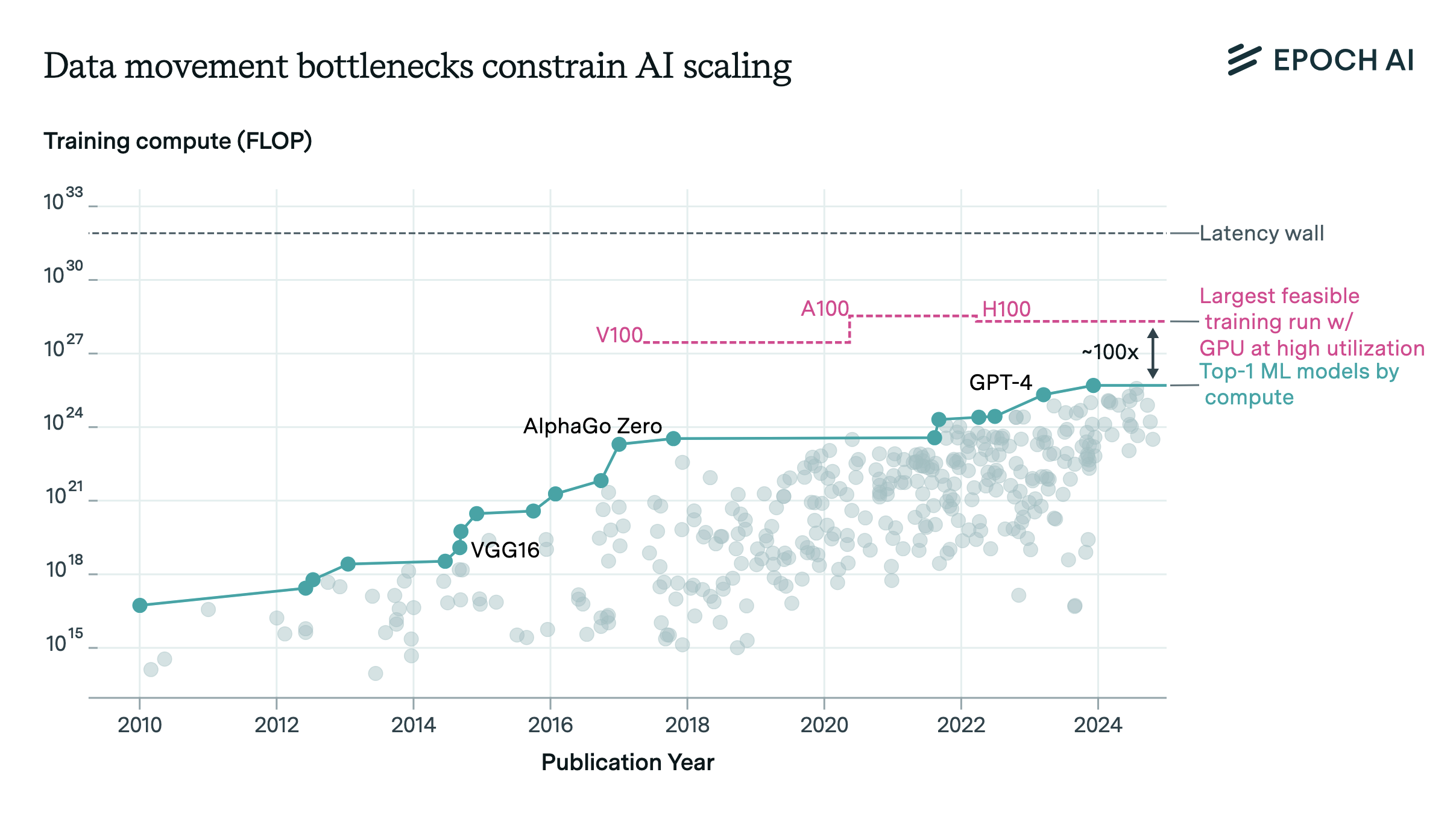
Data movement bottlenecks limit LLM scaling beyond 2e28 FLOP, with a "latency wall" at 2e31 FLOP. We may hit these in ~3 years. Aggressive batch size scaling could potentially overcome these limits.
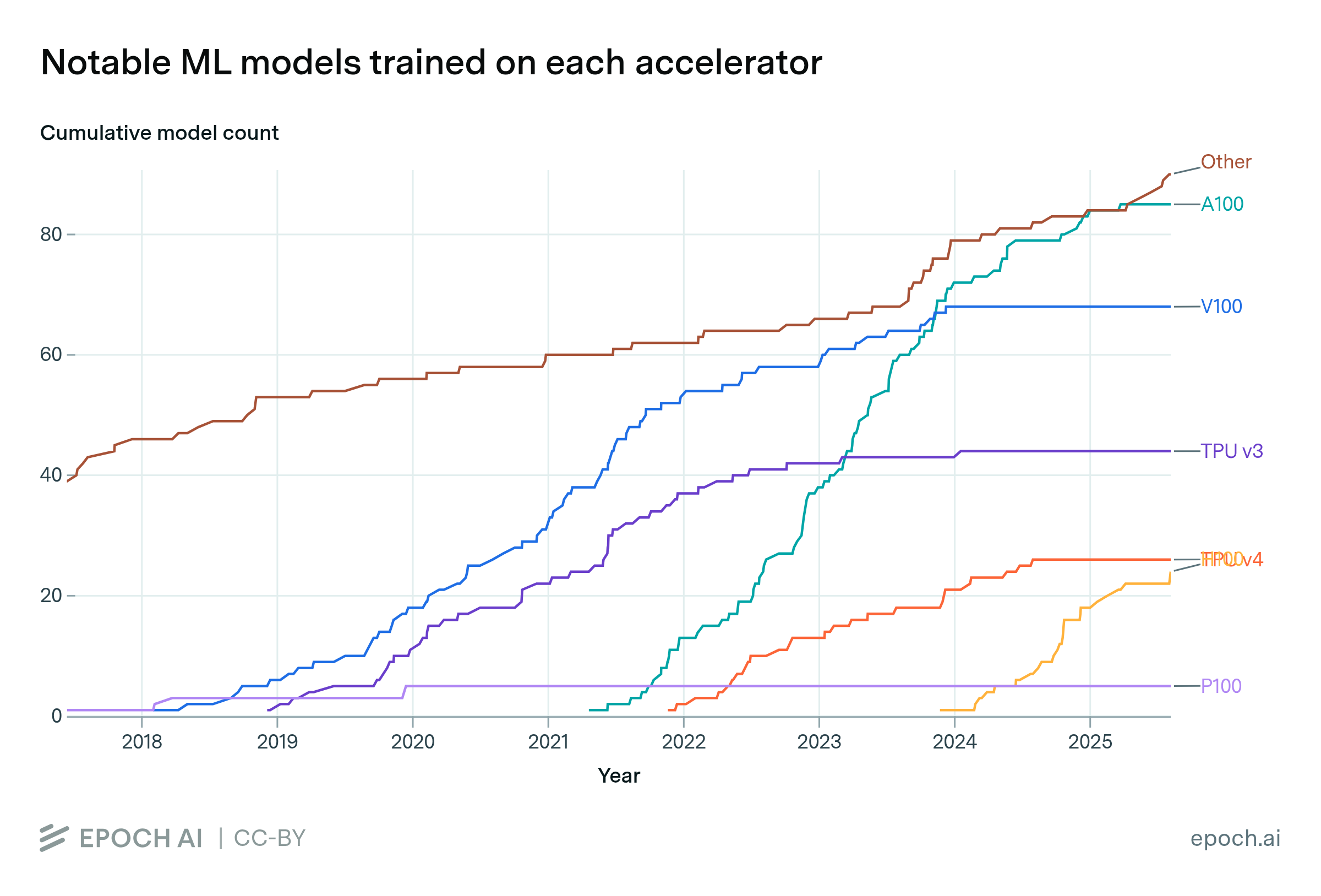
Our new database covers hardware used to train AI models, featuring over 100 accelerators (GPUs and TPUs) across the deep learning era.
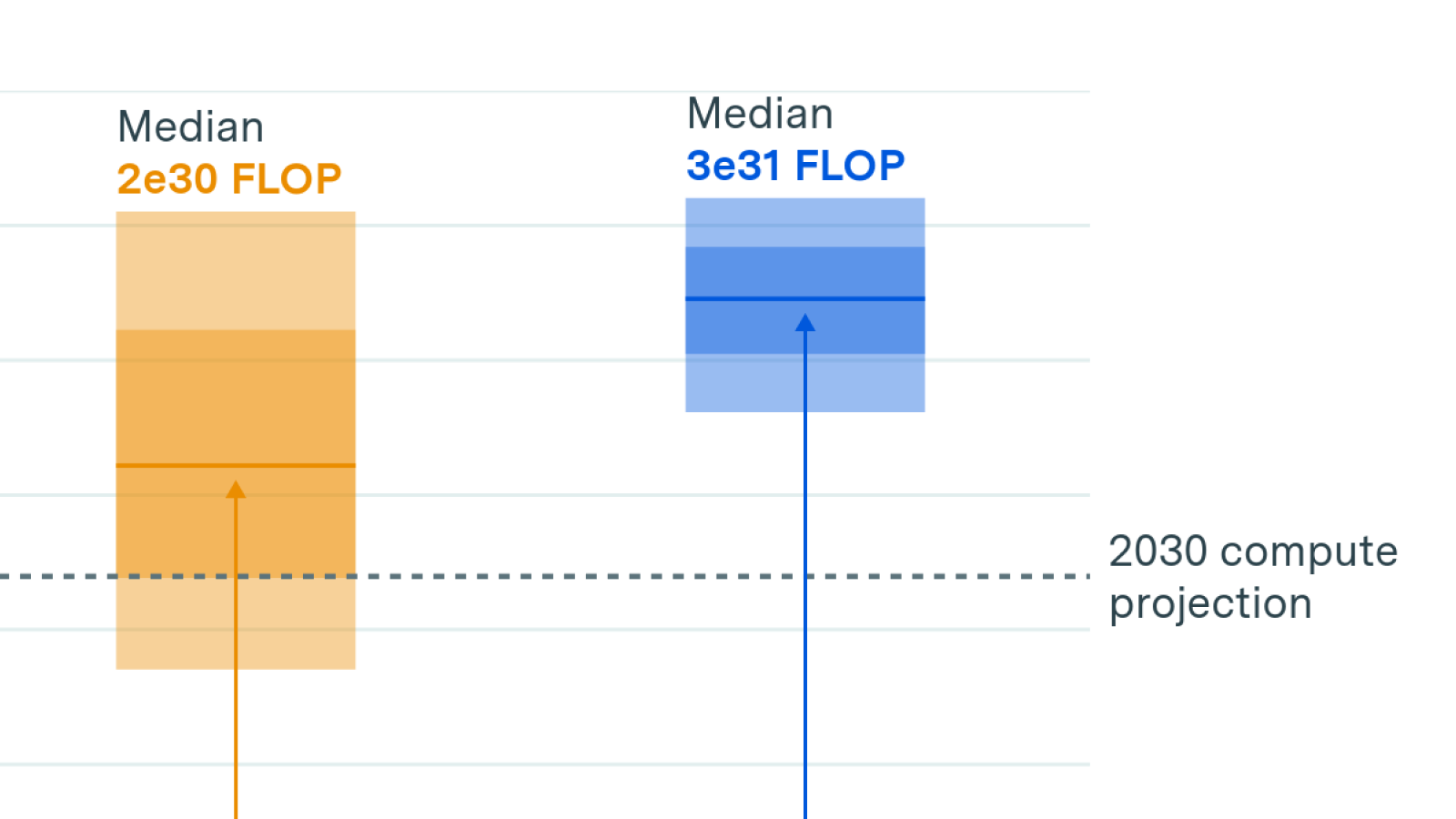
We investigate the scalability of AI training runs. We identify electric power, chip manufacturing, data and latency as constraints. We conclude that 2e29 FLOP training runs will likely be feasible by 2030.
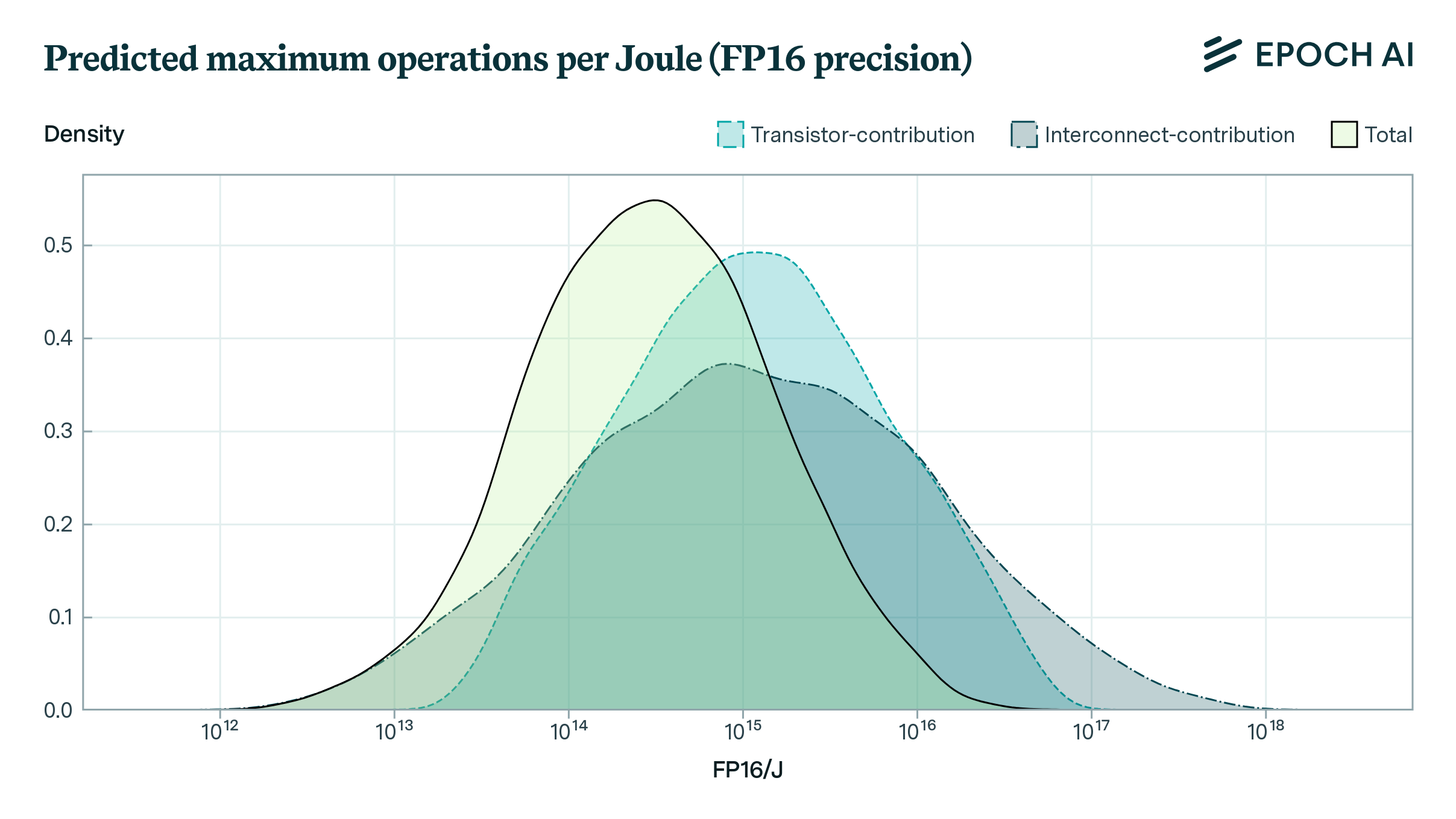
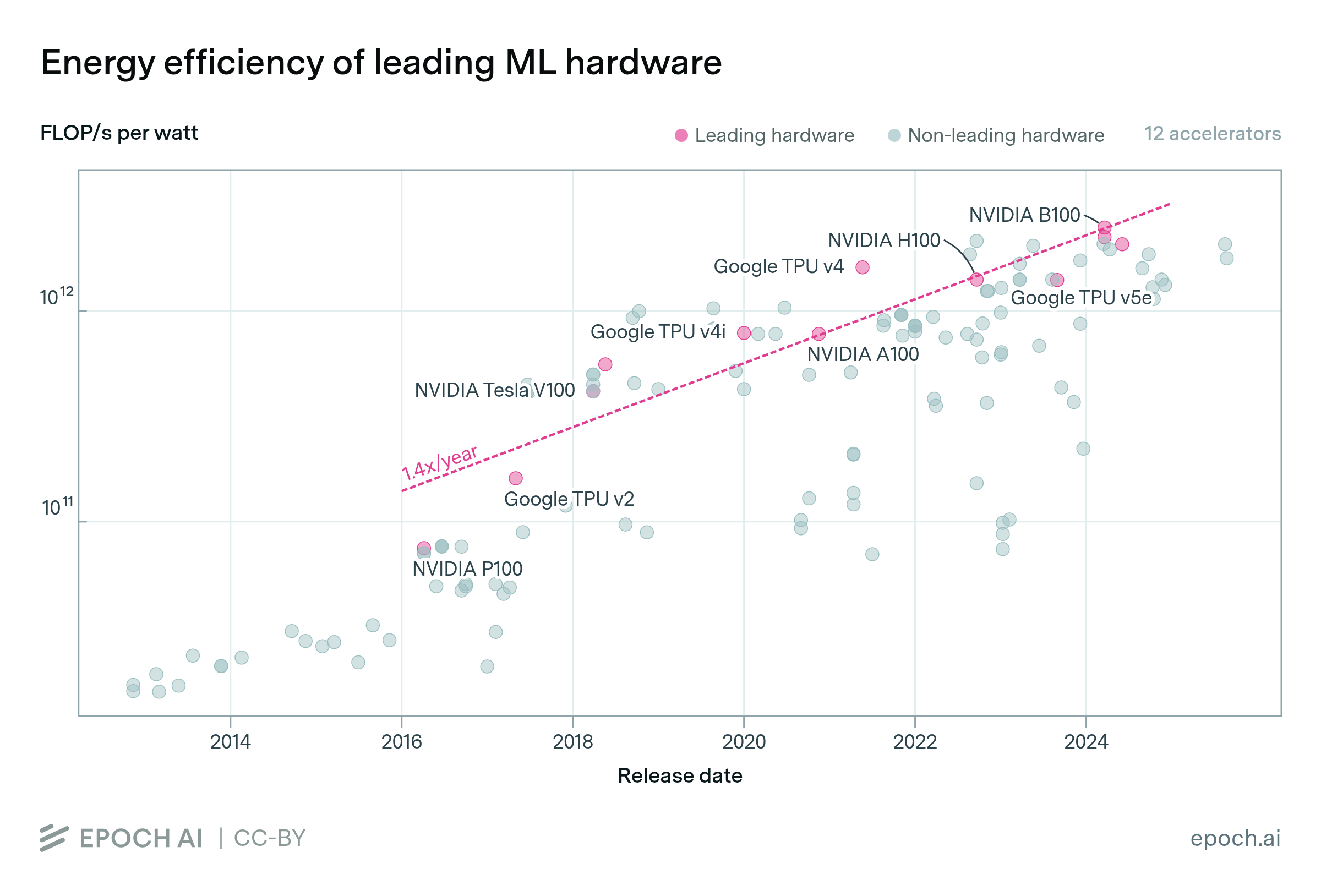
How far can the energy efficiency of CMOS microprocessors be pushed before we hit physical limits? Using a simple model, we find that there is room for a further 50 to 1000x improvement in energy efficiency.
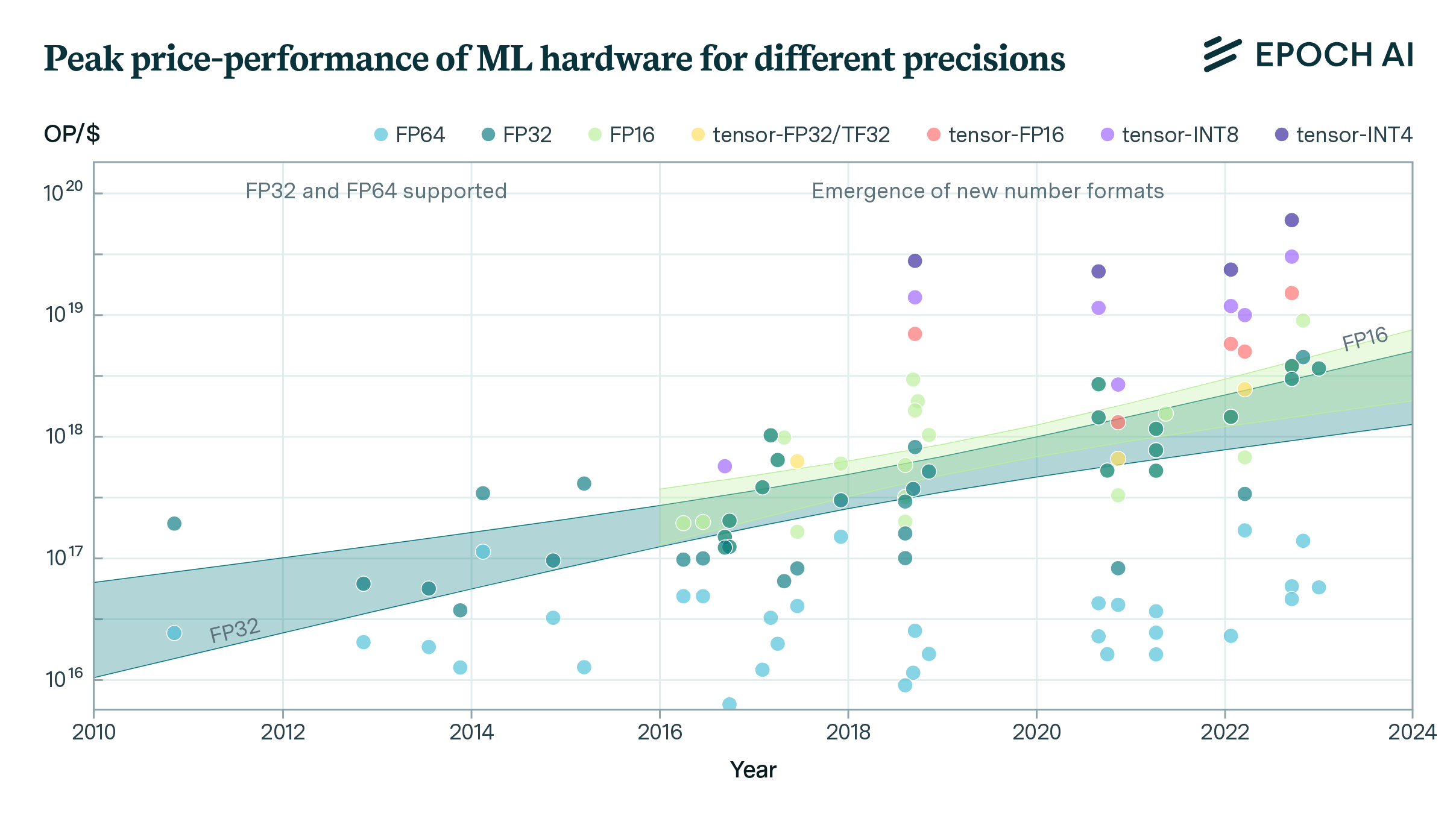
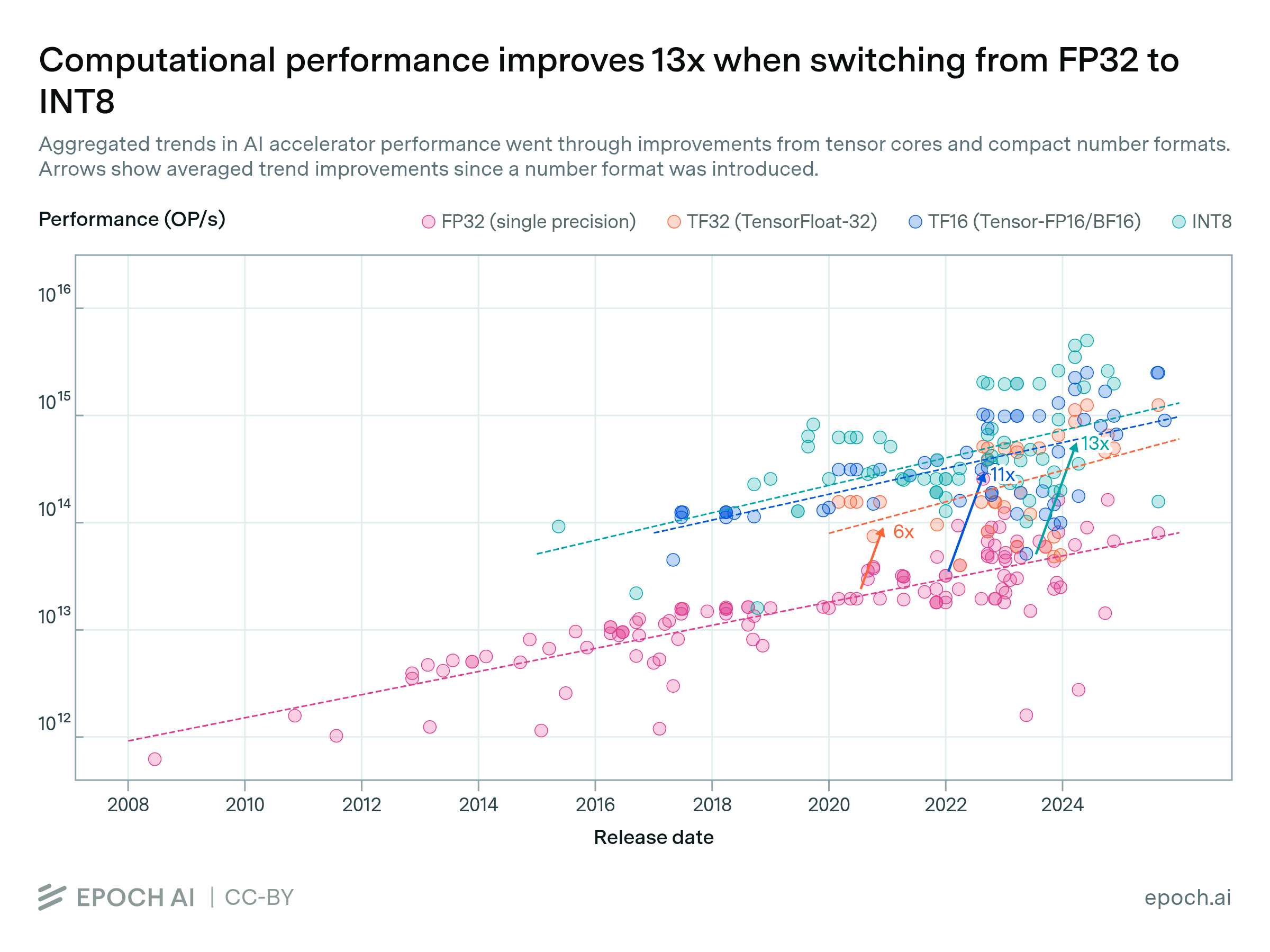
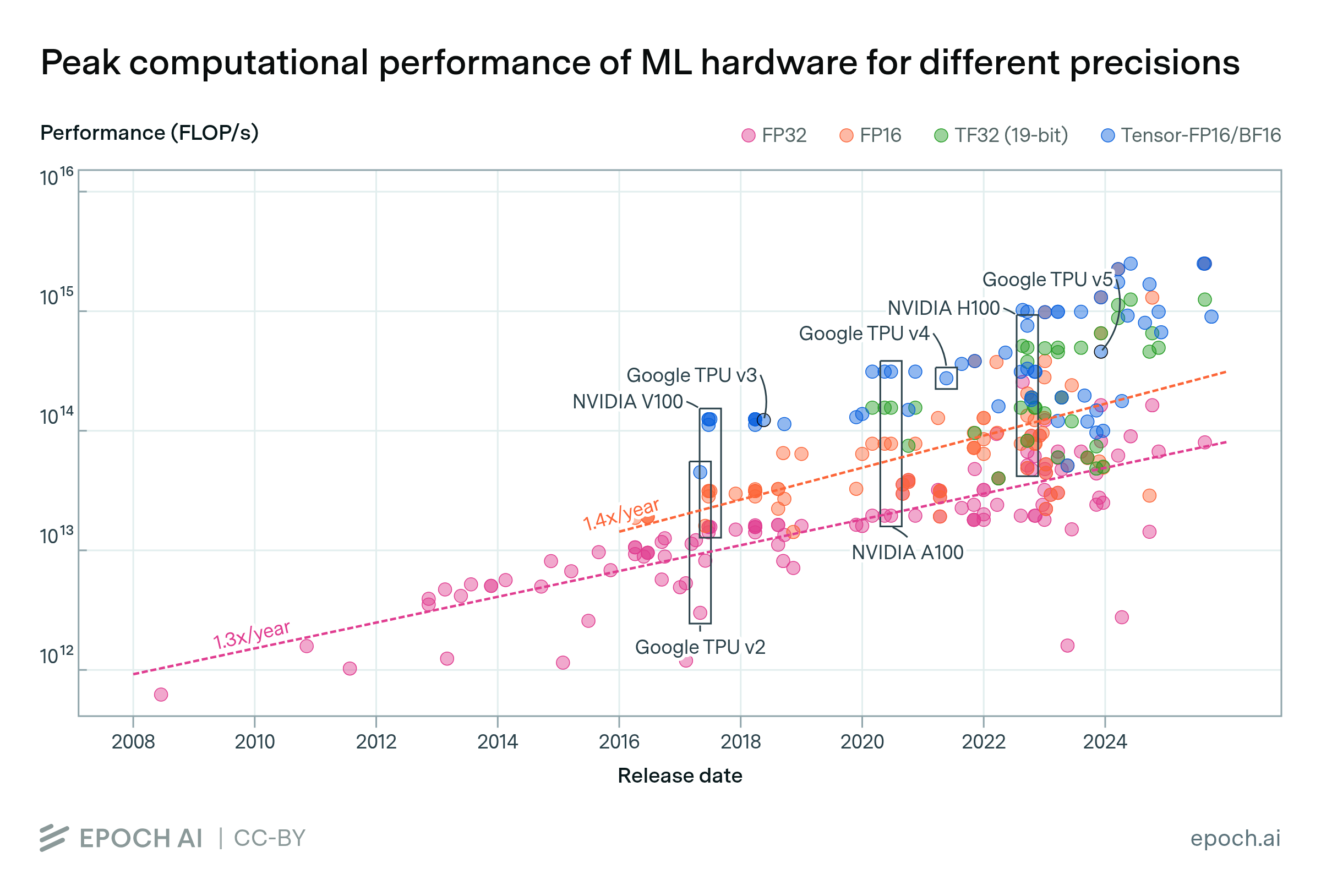
FLOP/s performance in 47 ML hardware accelerators doubled every 2.3 years. Switching from FP32 to tensor-FP16 led to a further 10x performance increase. Memory capacity and bandwidth doubled every 4 years.
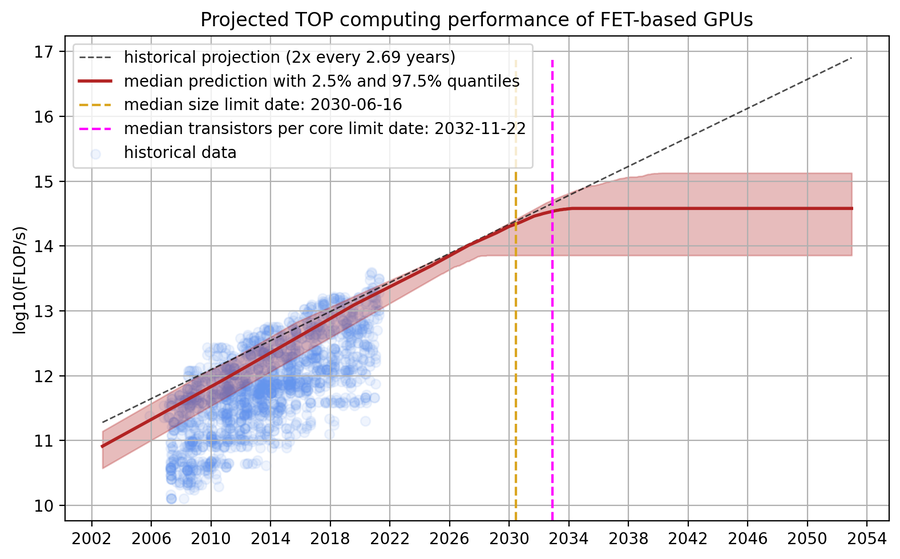
We develop a simple model that predicts progress in the performance of field-effect transistor-based GPUs under the assumption that transistors can no longer miniaturize after scaling down to roughly the size of a single silicon atom. Our model forecasts that the current paradigm of field-effect transistor-based GPUs will plateau sometime between 2027 and 2035, offering a performance of between 1e14 and 1e15 FLOP/s in FP32.
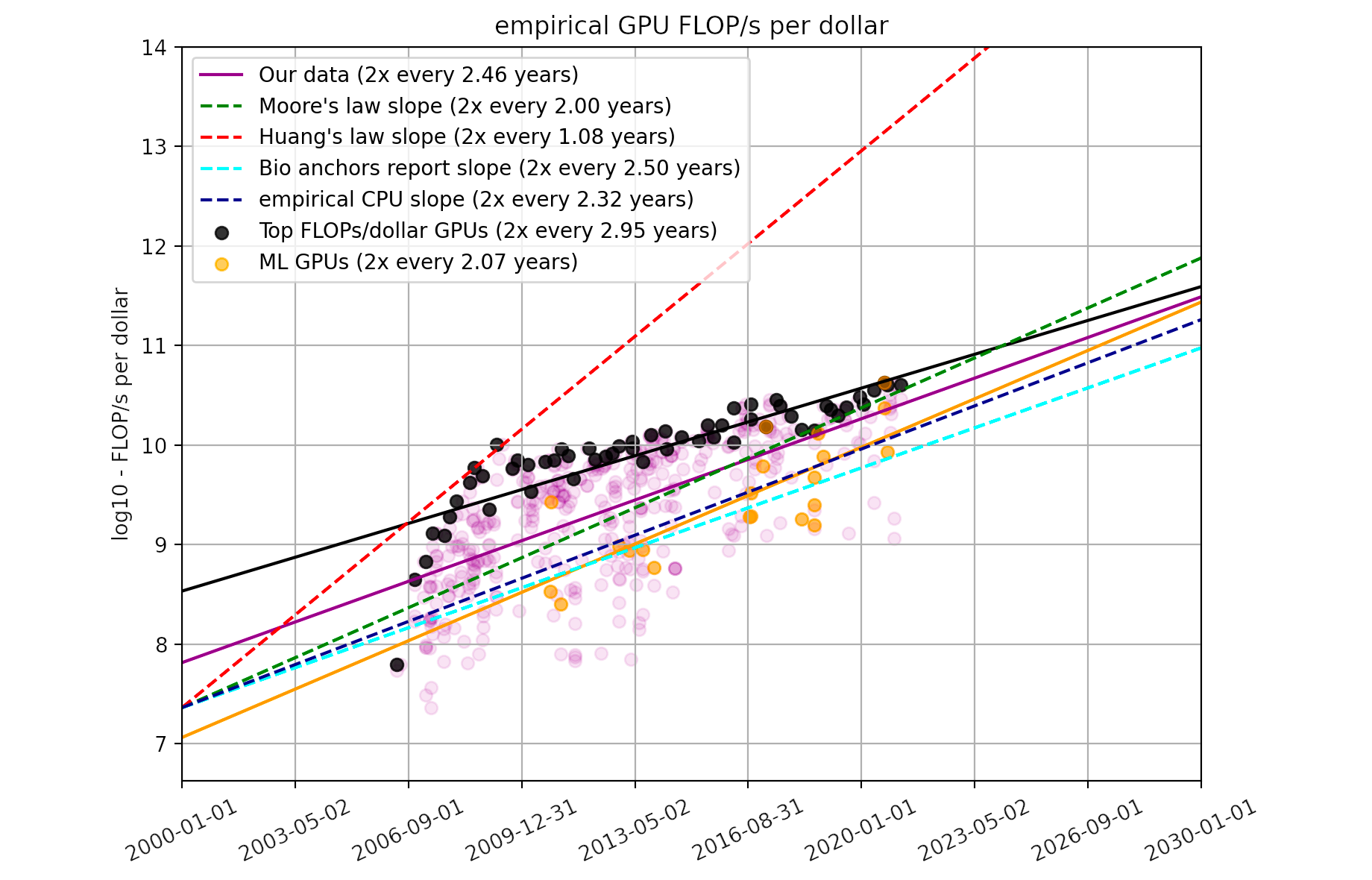
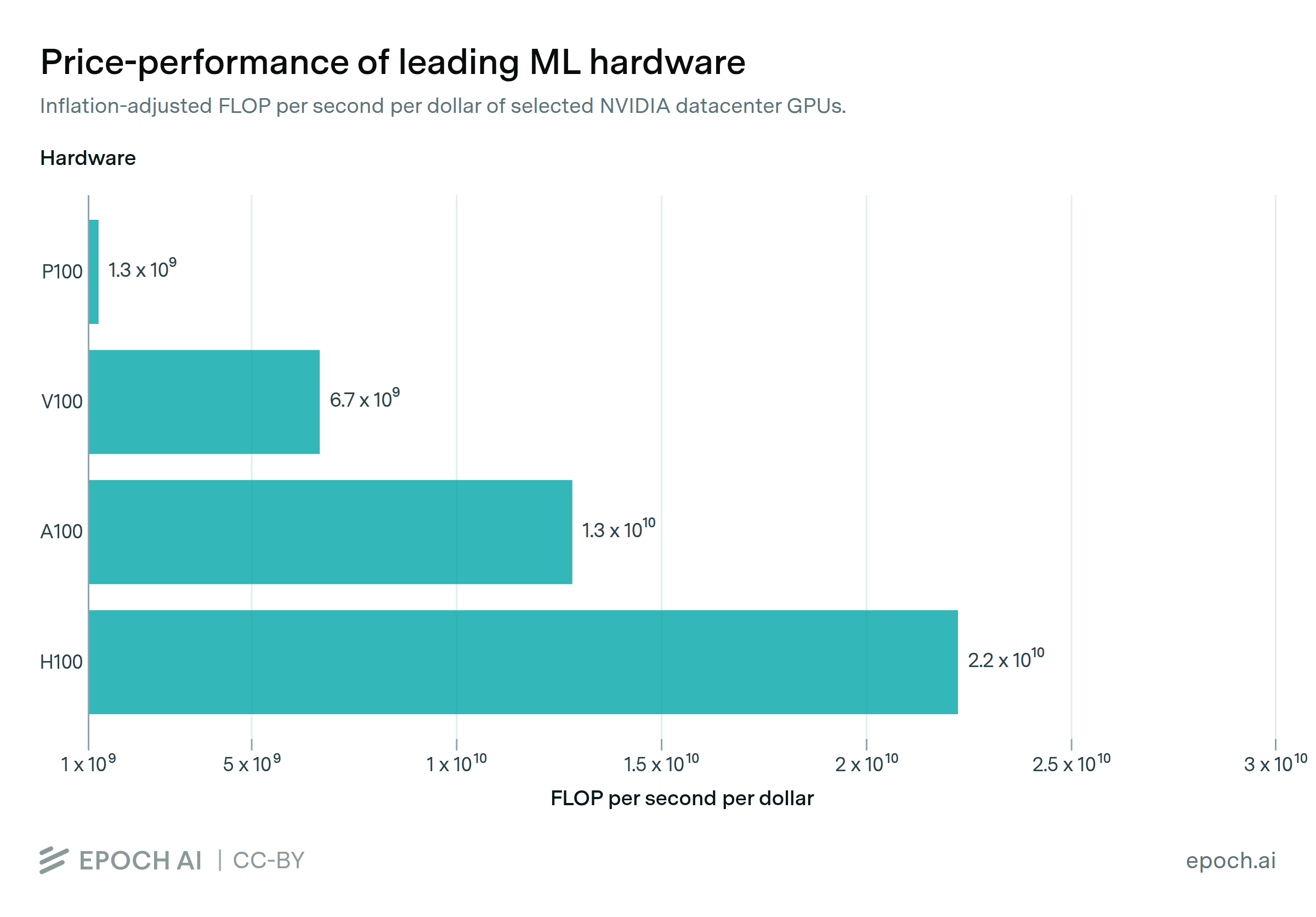
Using a dataset of 470 models of graphics processing units released between 2006 and 2021, we find that the amount of floating-point operations/second per $ doubles every ~2.5 years.