
Disclaimer: the estimates of frontier developer compute discussed below are more tentative than our standard data work.
OpenAI kicked off the AI boom when it launched ChatGPT in 2022. Frontier LLMs soon accrued hundreds of millions of users and billions in revenue, sparking a massive investment boom in AI compute infrastructure, with Nvidia’s AI-related sales spiking more than fourfold in 2023. Global AI computing power has now grown to the equivalent of around 20 million Nvidia H100s, funded by hundreds of billions of dollars in annual capital expenditures.
Yet while OpenAI launched the compute boom, they don’t dominate AI compute usage. I estimate that the compute OpenAI uses for research, training, and inference as of the end of 2025 made up around 10% to 15% of the world’s operational AI compute supply, and this share was even smaller a year ago. Even after adding the other most well-resourced frontier developers — Anthropic, xAI, and the AI labs within Google and Meta — the combined total is probably still under half of the world total.
In other words, there is a lot of AI compute that top frontier labs are not using. Anthropic and OpenAI have seen rapid growth in revenue and funding, enabling them to grow their AI compute faster than the world overall, and this will continue in 2026.
But the top labs may capture a much larger share of global compute within a few years. At that point, compute growth at top labs would be more directly tied to the pace of total compute production, which could slow down the rapid growth we’ve seen in both model capabilities and AI deployment/revenue. For scaling to continue, the overall compute buildout would need to accelerate. Given that AI capital expenditure (capex) is already approach $1 trillion per year, such an acceleration in compute production would require dramatic economic changes.
Most AI compute probably doesn’t go to frontier AI
More details for each company can be found in the Appendix, and the accompanying research document.
I don’t have a great estimate of the compute used by each of the five most resource-rich frontier developers, but we know enough to estimate their share of world AI compute.1
OpenAI helpfully disclosed the total electric power capacity of its data centers, which can be converted to ~1.7 million in H100-equivalent (H100e) compute. We also know a lot about xAI’s Colossus data centers. I’m less certain about Anthropic, which had significantly less compute than OpenAI at the end of 2025, though probably still over 1 million H100e. The situation at Google DeepMind and Meta Superintelligence Labs is also unclear, since the compute owned by their parent companies (roughly one-third of the world total) is split across frontier AI, cloud, and other internal uses.2 It’s not clear that the frontier labs at Google and Meta use even half of the total. For more details on each lab, see the Appendix.
But it’s still clear that a lot of AI compute isn’t used by the top labs. My best guess, in terms of the equivalent number of Nvidia H100 GPUs, are that OpenAI, Anthropic, and xAI together probably had fewer than 4 million H100e at the end of 2025.
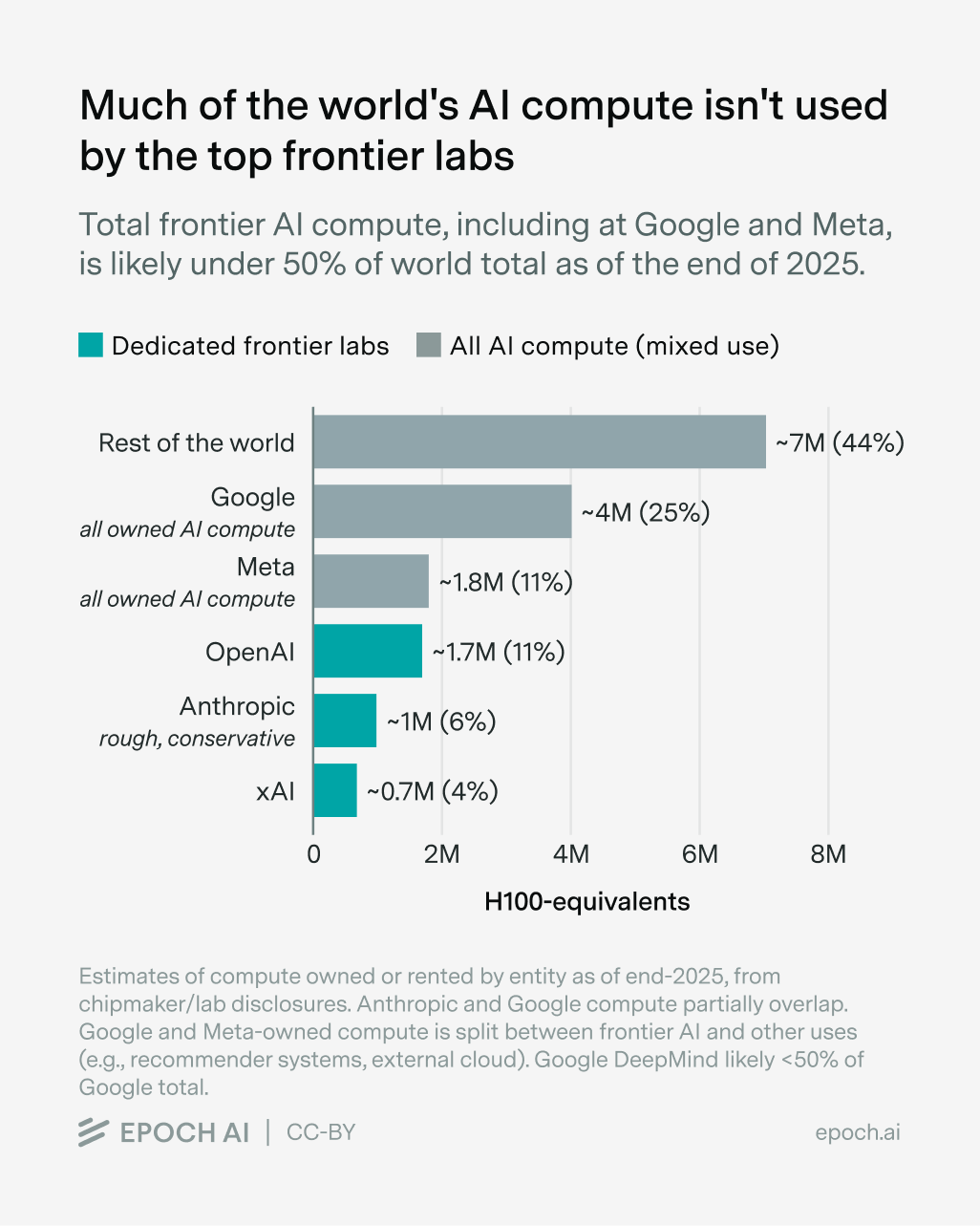
My best guess is that DeepMind uses slightly under half of Google’s total. Meta also rents external cloud compute (not shown on the graph), starting in late 2025. Estimated world total of 16 million H100e assumes a one-quarter lag between chip sales (est. 20 million) and operations. This is a reference scenario; a longer lag would imply a higher frontier compute share.
Meanwhile, cumulative sold AI compute was roughly 20 million H100e as of the end of 2025. But not all of this was necessarily operational — I don’t know exactly how much, but a rough estimate would look at chip sales at a time lag based on typical installation periods for AI clouds like CoreWeave.3 If there’s a one-quarter lag between delivery and deployment, deployed compute at the end of 2025 would be comparable to sold compute as of Q3 2025, which was ~16 million H100e. If the delay is two quarters, deployed compute goes down to ~12 million H100e.
Under these varying deployment assumptions, Anthropic, OpenAI, and xAI’s total H100e would make up around 20% to 30% of the world total at the end of 2025. If you also count the inference compute that the hyperscalers use to run their own APIs on OpenAI and Anthropic models, this may contribute up to another ~5%.
Meanwhile, we estimate that Google and Meta together own around one-third of the world’s total AI compute. But the compute allocated to Google DeepMind and Meta Superintelligence Labs is substantially less than that, given the large compute demands of Google’s external cloud business and non-frontier uses such as recommender systems. Each lab may use roughly half of their parent companies’ compute as a first-pass guess, for a total of roughly 15% of world compute.
This means that the five most resource-rich AI developers in the world probably had access to less than half of global AI compute at the end of last year.
In other words, frontier AI labs like OpenAI may have kicked off the AI compute buildout, but they are not wholly responsible for it. I won’t attempt a full breakdown of the remainder, but likely candidates include second- and third-tier LLM players and inference of open-weight LLMs. AI/ML models in non-language domains also consume compute: the innovations behind frontier LLMs, such as the transformer architecture, have enabled much better models in audio/visual generation, biology, robotics, and recommender systems, among others.
Will Anthropic and OpenAI absorb the rest of global AI compute?
While much of the world’s AI compute isn’t used by the top labs today, this situation could change significantly in the next few years. In particular, I think Anthropic and OpenAI are the key players to watch.
OpenAI and Anthropic grew compute faster than the industry as a whole, at least in 2025.4 OpenAI tripled its data center power capacity in both 2024 and 2025; after accounting for improved hardware efficiency, their computing power grew around 4× annually.5 Anthropic is probably growing even faster, since they’ve been catching up with OpenAI in revenue and funding. Meanwhile, we estimate that the global stock of AI compute tripled in H100e terms in 2025, and new installed compute grew by 2.7× in 2025 versus 2024.
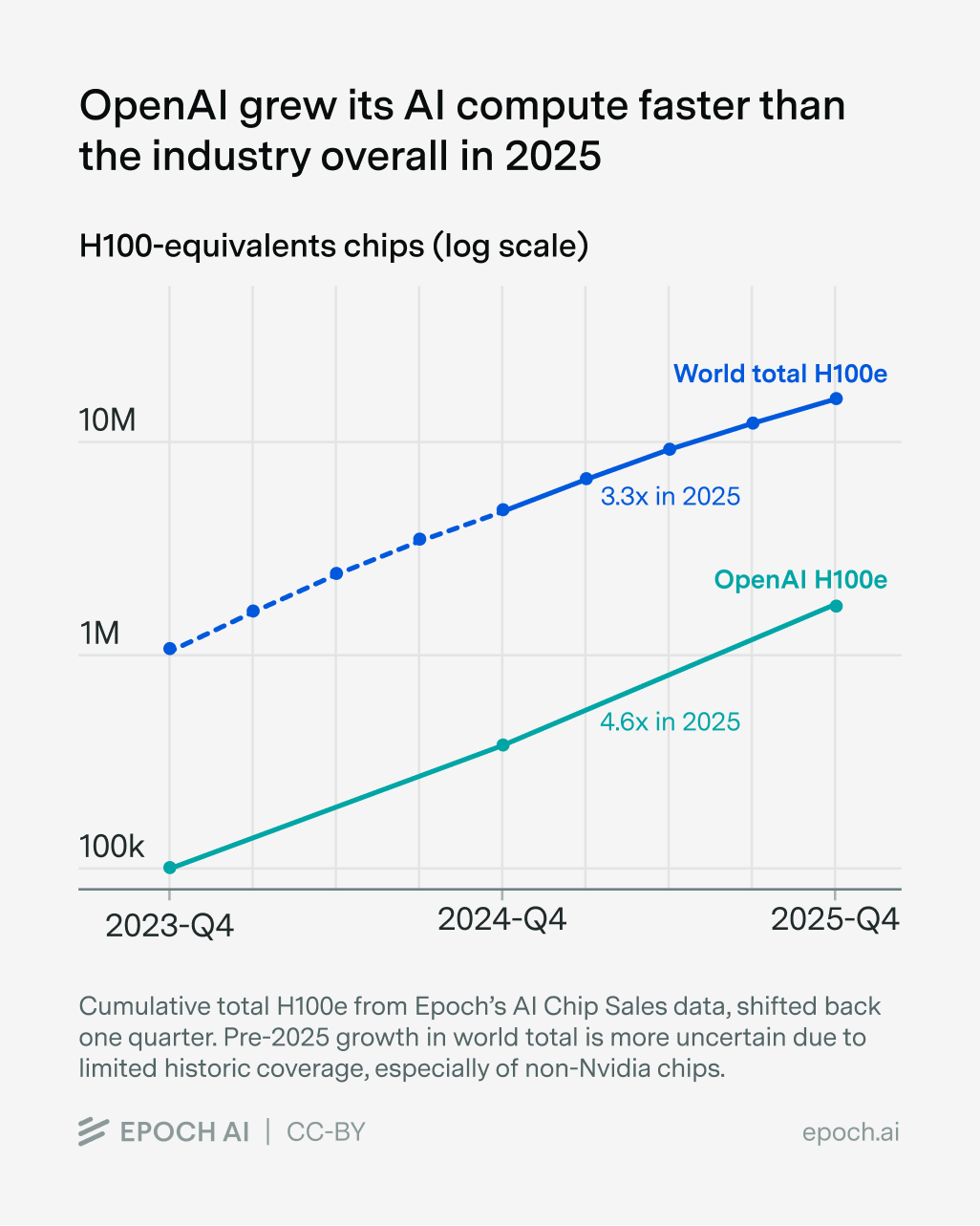
To be sure, this isn’t enough evidence to draw stable trendlines for frontier compute growth and overall AI compute growth.6 But it looks like OpenAI and Anthropic are currently growing their compute faster than the industry as a whole.
This looks likely to continue. OpenAI internally forecasts that its data center capacity will reach “low double-digit” GW in 2027, up from 1.9 GW in 2025. If that means (say) 12 GW by the end of 2027, that would be 2.5× annual growth, a slowdown from 2023–2025’s 3× growth, but still very fast. OpenAI’s president, Greg Brockman, also testified that the company would spend $50 billion on compute in 2026, triple what it spent in 2025. Finally, some third parties forecast that Anthropic and OpenAI will each have 5–6 GW of capacity by the end of this year, or ~2.5–3× growth in power. Because AI chips improve rapidly in price and energy efficiency, this suggests another year of ~4× growth in H100e compute capacity.
The industry as a whole probably can’t match this growth: hyperscalers are growing their capex at a relatively steady 70% per year and guiding similar growth in 2026, suggesting that global compute growth will be similar to 2025’s ~3× growth.7
Industry trends also point to the top labs, especially Anthropic and OpenAI, consolidating the market. Demand for frontier LLMs has grown explosively this year, particularly for coding and agentic tasks. Anthropic has grown at a truly astonishing rate, increasing its annualized revenue run rate from $9 billion to $30 billion in the first quarter of 2026! This is an acceleration from last year’s already-extreme 10x growth rate.8 Recent revenue data is less available for OpenAI, but qualitatively, its coding models and products (e.g., GPT-5.5) have also been well-received. Rapid revenue growth, and the corresponding increase in funding, gives Anthropic and OpenAI the means to secure a larger share of global compute.
Indeed, Anthropic and OpenAI are moving aggressively to secure more compute. In April alone, Anthropic signed multi-gigawatt expansions with Amazon (targeting 1 GW of Trainium online in 2026) and Google, and added CoreWeave as a compute partner.9 And in a fascinating plot twist, Anthropic has agreed to rent xAI’s entire ~300,000 H100e Colossus 1 data center along with part of Colossus 2, paying up to $15 billion per year for the privilege.10 OpenAI has also expanded its cloud roster, signing with Amazon in February and Google last year. So these two labs are the most likely culprits behind the tight compute supply and ~30% increase in GPU-hour prices that the industry has seen this year.
Anthropic and OpenAI are not the only players driving LLM growth. Demand for open-weight models like DeepSeek, which are not too far behind in quality, may also be surging. DeepMind looks behind the top two in agentic coding as of writing, but is definitely not out of the race, and Meta is spending big to try to catch up in frontier AI. But if the agent boom leads to LLMs growing their share of the overall AI industry, this will boost the compute share of the two LLM leaders. And Anthropic’s current revenue trajectory is so extreme that it seems likely to lead to compute consolidation.
In 2023, it was not obvious that OpenAI or frontier LLMs in general would end up dominating the entire AI industry. Three years later, it now appears that the players who kicked off the AI compute buildout will end up leading it.
What happens if frontier labs run out of headroom?
Anthropic and OpenAI probably made up 15–20% of the world’s operational AI compute at the end of 2025. While the headroom for them to grow their share looks big, it can be consumed in just a few years if the frontier labs grow substantially faster than the industry as a whole.11
As a naïve illustration, suppose the top two players together have a 20% share today, and grow their AI compute 33% faster than the world as a whole (e.g., they quadruple their computing power every year, as OpenAI did through 2025, while the global installed base “merely” triples annually). In this scenario, they’ll double their share of world compute in 2.5 years, and use ~80% within five. And if compute is more evenly distributed among the top four or five frontier developers, rather than just Anthropic and OpenAI, the headroom will run out faster than that.
So a key question for the near future of AI is whether Anthropic and OpenAI can continue their recent pace of compute growth, dragging up overall AI compute production along the way, or whether their compute growth slows down because the cloud and semiconductor industry can’t keep up.
At this point, I want to emphasize that total capital expenditures on AI chips and data centers are already very large. Total AI capex will approach $1 trillion annualized in 2026, which would be almost 1% of the gross world product and 3% of US GDP, and capex now consumes most of the operating profits of the hyperscalers that are leading the buildout. There is no guarantee that rapid AI capex growth will continue after 2026.
If the top model developers eat the compute headroom and their compute growth converges with overall AI compute growth, maintaining 4× growth per year would require more than doubling capex annually even after factoring in chip price-performance improvements. From a starting point of perhaps $1 trillion in AI capex in 2027, this sort of growth would only be feasible if AI starts to dramatically accelerate economic growth.
In other words, the AI industry will transition to a new regime in the next few years, with frontier AI slowing its compute growth, or dominating the industry, or both. To be clear, there’s no reason to expect a progress “wall” in 2029 if a frontier compute slowdown happens: flat compute capex can still grow the compute stock for years, AI chips will still improve, and companies can research and train new models with a fixed amount of compute. But the key physical trend driving frontier AI progress, the scaling of compute, is not sustainable unless the world fundamentally changes soon.
Many thanks to Amelia Michael, Ben Cottier, Brendan Halstead, Campbell Hutcheson, Elliot Stewart, Isabel Juniewicz, Konstantin Pilz, Romeo Dean, and Yafah Edelman for helpful feedback.
Appendix: How much compute goes to frontier AI developers?
For more information, see this much longer research preview that sorts through the relevant evidence per company, along with modeling details.
Here, I summarize my estimates of how much AI compute OpenAI, Anthropic, xAI, and the frontier labs at Google and Meta had access to at the end of 2025. These five are probably the most compute-rich developers in the world, though not necessarily the leaders in model quality. I focus on how much compute frontier AI companies rent or use, not how much they own.12 Anthropic and OpenAI predominantly rent their compute from cloud partners like Amazon, Google, and Microsoft; Google and Meta mostly own their AI compute, but much of this is allocated to non-frontier internal uses or, in Google’s case, rented out to external customers.
OpenAI
We know the most about OpenAI’s compute because they helpfully disclosed the total electrical power capacity of the data centers they rent at the end of 2023, 2024, and 2025. OpenAI ended 2025 with 1.9 gigawatts (GW) of capacity, up from 0.6 GW in 2024 and 0.2 GW in 2023.13
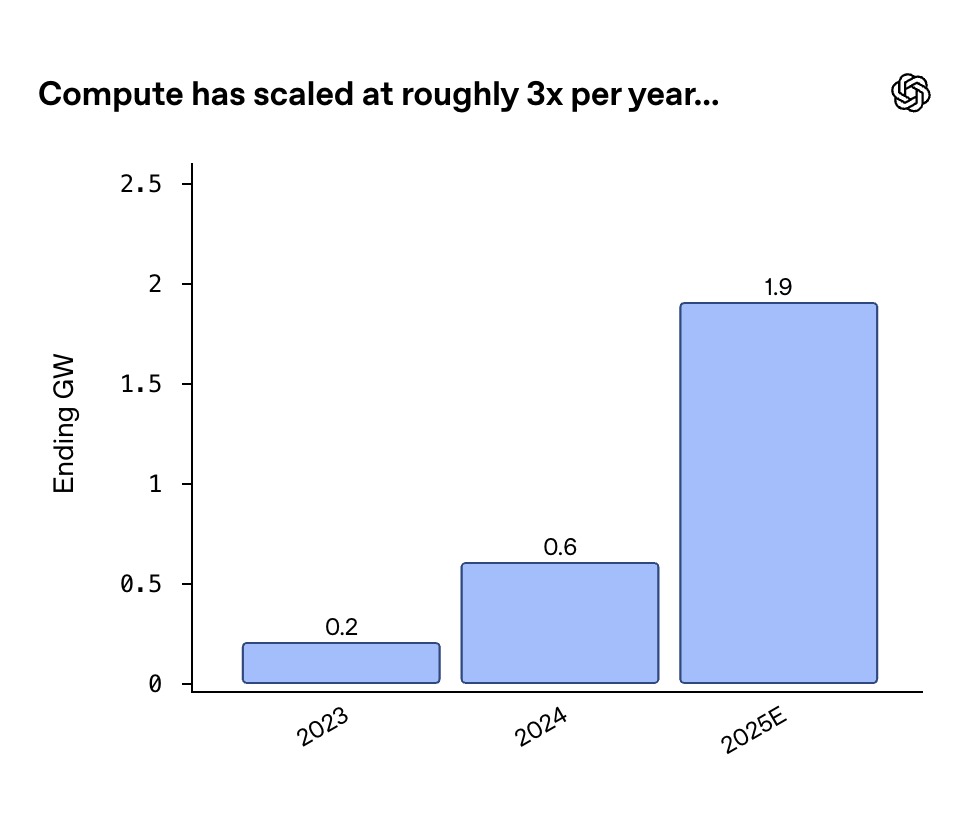
Courtesy of OpenAI.
This power capacity can be converted to computing power using the specs of flagship Nvidia AI GPUs and servers, and some assumptions about the mix of GPUs OpenAI used over time. With this method, I estimate that OpenAI had the equivalent of around 1.7 million Nvidia H100 GPUs (H100e) by the end of 2025, up from around 400,000 in 2024 and 100,000 in 2023 (H100e is based on peak FLOP-per-second specs; actual compute performance may vary). Another approach would be to use media reports that OpenAI spent $16 billion on cloud compute in 2025 and combine this with plausible prices per GPU-hour that OpenAI may have paid. This leads to a broadly similar compute estimate.
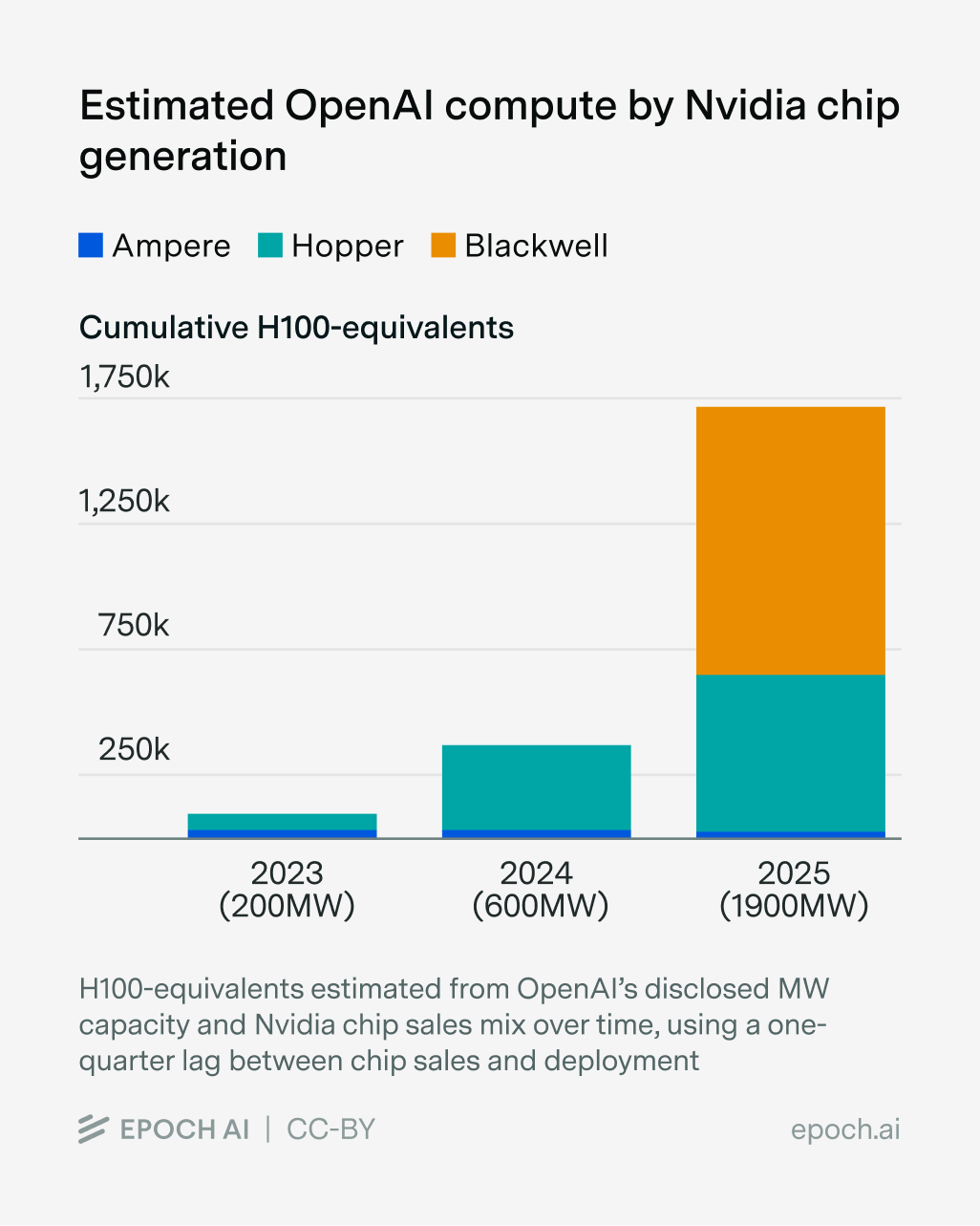
One potentially significant omission is the inference compute used to run OpenAI models on hyperscaler-hosted products like Microsoft’s Azure API (and now Amazon Bedrock); this compute is presumably excluded from OpenAI’s data center and cloud compute figures. It’s debatable whether this should count as “OpenAI compute”: OpenAI does share in some of the revenue from this compute, but doesn’t have operational control over it. Including this Microsoft inference compute may boost the total OpenAI compute by around 25%, with 50% as an upper bound, judging from OpenAI’s revenue and inference compute allocation (more details here).
Anthropic
Anthropic probably had substantially less compute than OpenAI in 2025, but is catching up over time. An internal OpenAI memo estimated that Anthropic had 1.4 GW in capacity at the end of 2025, around 70% of OpenAI’s 1.9 GW total. In both 2024 and 2025, Anthropic’s cloud compute bill was reportedly just over 40% of OpenAI’s. The 2025 ratio is somewhat surprisingly low, but Anthropic’s compute spending may have ramped up towards the end of the year.14
Much of Anthropic’s compute is housed in Amazon’s Project Rainier campus in Indiana, with around 500,000 H100-equivalents (H100e) in Trainium2 chips at the end of 2025. Anthropic also rents significant numbers of Trainium, Nvidia, and TPU chips from both Amazon and Google elsewhere, so its total must be much larger than this one campus. Alongside the OpenAI memo, I think this points to 1 million or more H100e for Anthropic by the end of 2025. As with OpenAI, including inference compute from third-party cloud APIs would boost Anthropic’s compute total, again by roughly 25%.
xAI
xAI, now part of SpaceX, mostly uses the compute in its Colossus 1 and 2 data centers in Memphis, Tennessee. These two facilities added up to around 550,000 H100e at the end of 2025. xAI reportedly also owns or uses smaller data centers in Portland and Georgia, and they used Oracle as a cloud compute partner at least through 2024. xAI’s total compute usage may have been around 600,000 to 700,000 H100-equivalents at the end of last year, likely less than Anthropic and less than half of OpenAI’s estimated 1.7 million H100e.
This year, xAI has decided to rent Colossus 1 to Anthropic, but is also targeting a major expansion of Colossus 2 to around 1.4 million H100e.15
For Google and Meta,16 I’ll define their “frontier AI” compute as the compute used by their frontier AI divisions — Google DeepMind (henceforth DeepMind) and Meta Superintelligence Labs (MSL) — as well as related inference.17 Clean comparisons with Anthropic or OpenAI are difficult because frontier AI work may bleed into other AI/ML efforts, such as recommender systems.
Google DeepMind
Google (Alphabet) is the most compute-rich firm in the world; in our research on AI chip owners, we estimate Google owned around a quarter of the world total, or roughly five million H100e at the end of 2025, or around 4 million H100e using a one-quarter delay between chip sales and deployment. But much of this does not go to DeepMind: Google says about half of its ML compute goes to Google Cloud.18 For Google, “Cloud” includes enterprise Gemini inference (Vertex API and enterprise subscriptions) in addition to compute for external customers. The other half is split between DeepMind and non-frontier internal uses like recommender systems.
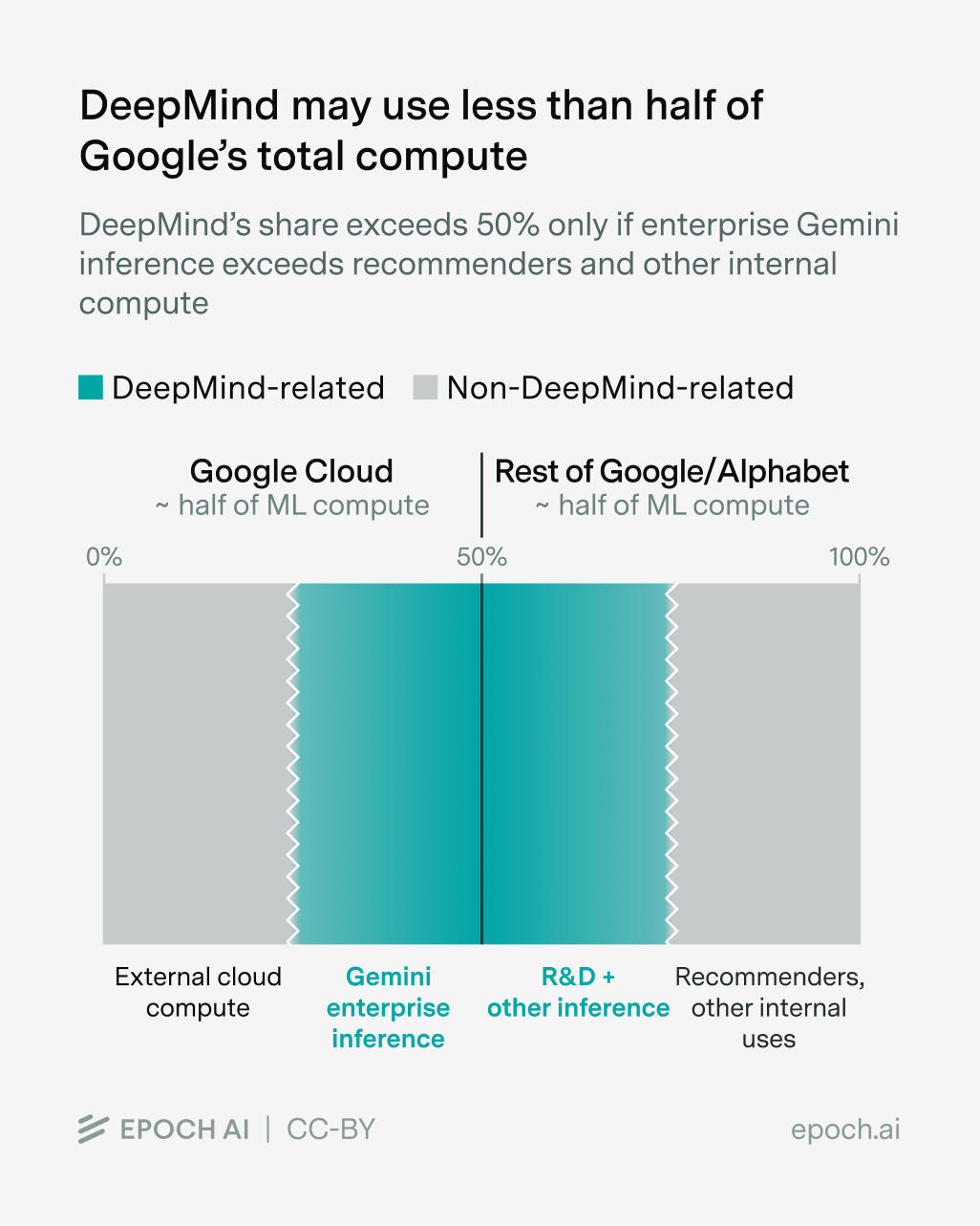
Whether DeepMind compute exceeds half of the Google total depends on whether Cloud-side DeepMind inference compute is greater than non-DeepMind internal compute. My guess is that the latter is bigger, which would mean DeepMind compute is less than half of the total.
This means that despite Google’s large compute lead as a company, it is not clear to me whether DeepMind had more compute than OpenAI at the end of 2025.
Meta
Meta owned roughly 10% of the world’s total AI compute at the end of 2025, more than OpenAI rented in total.19 But translating this to Meta Superintelligence Labs (MSL) compute is tricky.
First, many Meta GPUs support the company’s core business, principally recommender systems for ads and content, rather than frontier AI. The algorithms running your Instagram feed are actually large-scale transformers that are very effective at boosting engagement.20 Third-party estimates put the split between frontier AI and recommenders at roughly 50-50 in mid-2025.
However, Meta pivoted hard to prioritizing frontier AI in late 2025. Mark Zuckerberg hand-delivered soup to top researchers and offered them enormous compensation packages, promising that MSL overall would be equipped with “industry-leading levels of compute”. So it’s plausible that Meta compute has now tilted significantly towards frontier AI.
Second, Meta signed large cloud deals with Google, Oracle, and CoreWeave starting in late 2025; as these deals ramp, Meta will use much more AI compute than it owns. Still, because these cloud deals are relatively new, I think MSL probably had access to significantly less compute than Meta owned in total at the end of 2025. This means MSL probably had less compute than OpenAI, since we estimated Meta only owned 2.3 million H100e in total before accounting for deployment lags, split between MSL and other uses.
-
By “AI compute” I essentially mean the amount of AI chips they have access to that are operational in data centers, weighted by how powerful the chips are. For these five labs, these are predominantly Nvidia data center GPUs (e.g. Hopper and Blackwell), Google TPUs, and Amazon Trainium.

-
I also don’t know much about the scale of Microsoft’s or Amazon’s internal frontier AI efforts; it’s possible these are quite compute-rich at this point, given the massive size of the parent firms. In any case, I think the fact that the most salient frontier developers probably add up to less than half of all AI compute is interesting.
-
CoreWeave disclosed in May 2025 that its hardware goes through a “~3 month installation time” between delivery and monetization. By late 2025, this had decreased to “within weeks”. But Nvidia and other chip sellers may recognize revenue before clouds take delivery, e.g., when selling to server OEMs.
-
I don’t know enough about Meta Superintelligence/Meta AI or DeepMind’s compute to measure their growth trajectory, but MSL has probably grown its share of Meta’s total AI compute since the middle of last year.
-
This roughly mirrors the 4-5× growth trend in the total training compute of frontier LLM training runs, though we have limited data for closed frontier models beyond early 2025.
-
For one, Nvidia’s AI sales spiked discontinuously in 2023 before settling to a ~70% annual growth rate.
-
A more detailed forecast of total compute is outside of scope, but ~70% growth in AI spending suggests something like 2-3× growth in computing capacity: AI chips have historically become ~30% more cost-effective per year. And compute ~tripled in 2025, supported by 70% growth in hyperscaler capex last year.
-
We write a lot about big numbers and growth rates here at Epoch AI. But seriously, it is difficult to adequately convey how bananas that Anthropic’s revenue curve is. If sustained, tripling revenue in one quarter implies ~80-fold growth per year; this is almost certainly not sustainable, but it’s still crazy that they saw a growth spurt like this from a starting point close to $10 billion/year. And we’ve gotten another data point consistent with this accelerated trend, with Anthropic reportedly approaching $45 billion by May! This is a dramatic acceleration from Anthropic’s 10× annualized growth rate in 2025, which was already the fastest any company of this size has grown in history. See additional commentary from Jesse Richardson.
-
Amazon and Google were already Anthropic’s main compute partners, so these contracts are additive. The incremental capacity will ramp over multiple years.
-
This is more than Anthropic spent on compute last year, and almost as much as OpenAI did, though Anthropic may be renting Colossus at a large price premium. Anthropic will reportedly double its compute spending between Q1 and Q2 of this year, from around $3B per quarter to $6B.
-
I don’t mean to imply that the remainder of the current and upcoming cloud compute market is “free real estate” for Anthropic and OpenAI. It may be very difficult and expensive for them to continue growing their share of global compute! Much of it is committed in long-term cloud contracts, though the top labs may buy out compute currently used by others, as with Anthropic and Colossus. But while the headroom exists, rapid growth at these companies doesn’t mechanically require an acceleration in AI semiconductor production.
-
I’ll use possession-like language like “OpenAI’s compute” throughout, but unless I use the word “own”, by default I mean the amount of compute the company or lab rents or uses.
-
(More methodology details can be found in the full research document; code here). I assume that OpenAI is measuring the IT power of its data centers (the total power drawn by computing equipment like chips, servers, and networking), not total facility power. The tech industry tends to measure data center power in IT power, and using IT power leads to an estimate that is more consistent with my other GPU-hour based estimate. If I assumed OpenAI was quoting total facility power, my compute estimates would be up to ~30% smaller.
-
When converting from the power and dollar figures to compute, the power-efficiency and cost-efficiency of Anthropic’s compute fleet can differ from OpenAI’s fleet. This may close the gap somewhat: Anthropic uses lots of Amazon Trainium2 chips, which are less energy-efficient than newer chips like Nvidia Blackwells, but are also relatively cheap.
-
xAI has also formed a major partnership with Cursor where xAI and Cursor will share Colossus compute to co-develop models. This situation is in between a cloud compute deal with Cursor and an acquisition of Cursor (SpaceX acquired a call option on Cursor as part of this deal).
-
Microsoft and Amazon also develop large foundation models, though these efforts seem less mature than Google’s or Meta’s.
-
This can include product-level inference of frontier models that is not managed by the lab itself; for example, the DeepMind team may not be directly involved in all Gemini-powered products.
-
One article reports that “In 2025, Google expected to allocate around half of its computing capacity to Cloud, [Google CFO Anat] Ashkenazi said at a Morgan Stanley conference this spring.” Google will maintain a similar ratio in 2026, according to its Feb 2026 earnings call: “And for 2026, just over half of our ML compute is expected to go towards the Cloud business.”
-
This doesn’t include Meta’s custom MTIA chips, which were relatively low volume in 2025. I’m also eliding the difference between Nvidia and AMD compute; AMD is about 20% of the estimated total. Meta is reportedly the single largest customer of AMD’s Instinct AI chips, but I’m not sure what Meta uses them for.
-
In the linked earnings call, Meta attributes much of the 5% year-on-year increase in time spent on Facebook and 30% on Instagram videos to AI recommendations. So the revenue impact of scaling recommender systems at Meta over the past few years could easily add up to tens of billions per year. Recommenders are presumably also a very big deal at Google, the other online advertising giant.
About the authors
Related work

